---
tags: dribdat
title: DATAFUGE - a next-gen data portfolio
---
# D A T A F U G E
### *DATA PORTFOLIO FOR DD+A*
This working paper proposes the development of a repository to collect references and documentation about datasets curated and created by [Data Design + Art](https://www.hslu.ch/en/lucerne-school-of-art-and-design/degree-programmes/bachelor/data-design-and-art-1) students, faculty and staff.

## Introduction
`DATAFUGE` (from data + refuge; a working title) will be a next generation Data Portfolio developed at the HSLU. Behind-the-scenes of our data skills accelerating programs, this will be the new home of data collection efforts and experimental prototypes, complementing the visual and coding work of our students.

Our data portfolio builds on and connects to existing websites like the 2022 📘 [DD+A DATA FOLIES](https://blog.hslu.ch/ddapark/) Wordpress site, which documents the final projects of students - the 📘 [DataDesignandArt.ch](http://datadesignandart.ch/) online showreel (shown above), [Instagram](https://www.instagram.com/datadesignart_hslu/) social media channel, and other 📘 [public references](https://www.hslu.ch/en/lucerne-school-of-art-and-design/degree-programmes/bachelor/data-design-and-art-1/was-lerne-ich-im-studium/).
It should connect well with student's own websites, as well as with modern 3rd-party design portfolios - as well as being useful in next-generation Web, Metaverse, and IRL design publications. Created on global principles of [data journalism](http://toolbox.schoolofdata.ch/overview.html) and activism, DATAFUGE should offer our students support in running their own data gathering and exploration efforts.
## What is (a) data refuge?
Our inspiration for the data portfolio are efforts to collect threatened and undervalued data on the Internet for humanitarian and activist purposes, such as [Data Refuge](https://www.datarefuge.org/about) that became famous at the beginning of the Trump administration, or more recently [SUCHO](https://db.schoolofdata.ch/project/177) in the wake of the war in Ukraine.

> **Data Refuge** (or [DataRescue](https://datarefuge.github.io/workflow/)) is a public and collaborative project designed to address concerns about federal climate and environmental data that is in danger of being lost.
-- [Wikipedia](https://en.wikipedia.org/wiki/Data_refuge)
## Project-based exploration
A good data refuge initiative uses collaborative tools and easy-to-use repositories, designed to automatically track and generate data about the whole process. But how do we get this started?
Having a low barrier to entry combined with hands-on activities in short sprints can be used to quickly fill out a 'data space' for the project, categorizing data sources according to topic, process, administrative level, etc. This is typically done in a series of "sprints", inspired by [hackathons](https://de.wikipedia.org/wiki/Hackathon).

Using DATAFUGE, the students should be empowered to participate in [Data Expeditions](https://dda.schoolofdata.ch/project/13) and hackathons, and learn to set up their own. More than just a 📘 [trending way](https://hub.hslu.ch/informatik/hackathon-im-team-zu-erfolgreichen-losungen-tipps-hacks/) to 📘 [get recruited](https://hub.hslu.ch/informatik/hackathon-im-team-zu-erfolgreichen-losungen-tipps-hacks/), these [public laboratories](https://towardsdatascience.com/hacking-data-art-at-an-ai-genomic-hackathon-62e16efb49ce) for experimentation in a social setting leverage open collaboration akin to [focus groups](https://www.sari.uzh.ch/en/events/7th-swiss-open-cultural-data-hackathon-reference-data-workshop.html), enable civic engagement through [ethical hacking](https://www.zentralplus.ch/technologie-digitales/keiner-versammelt-hacker-so-verlaesslich-wie-dieser-luzerner-2508245/), stimulate more [diversity in tech](https://forum.opendata.ch/t/hackathon-as-a-method-hack4socialgood/498/1) (see preprint [Hevenstone et al 2023](https://web.tresorit.com/l/PthTF#9oSJZ45zuqosGY-_GdjXgg&viewer=Wx1JxluUjazyTDdaoJXDnp3BpszVI8ZK)), and use pop-up events for [corporate social responsibility](https://www.mckinsey.com/capabilities/mckinsey-digital/our-insights/demystifying-the-hackathon).
The use of [Hackdays](https://opendata.ch/projects/hackathons/) or Hackathons for social impact (rather than for performance & prizes) and to promote data activism has led to many "bootstraps": tools and data resources, capabilities to track progress of teams, documentation of results in real time from across online repositories like [CKAN](https://ckan.io), [GitHub](https://github.com) and [GitLab](https://gitlab.com).
## What is (a) data portfolio?
It is the pride and responsibility of professional data designers and artists to include references to their sources, or "facts", that are at the foundation of their generative process.

_Screenshot from portfolio of [Kirell Benzi](https://www.kirellbenzi.com/art)_
We will develop a storybook, design system, and/or set of code components, that can be used by students to reference their works online - with a reference that can be pasted onto a blog, webpage, online profile, etc. - and offline, via (short)link or QR code. The way that datasets are linked today from scientific publications can serve as a basic reference.

_Screenshot of a dataset on [Zenodo](https://zenodo.org/record/7011072#.Y-GLvNKZOXA)_
These components will have a consistent visual identity and set of metadata. They need to be easy to use, and easy to read. The information must be reliable, and back the work up with authenticity and reproducibility. A good example are the Creative Commons badges, which have been adopted by millions of content creators around the world.

Closer to home, we can build on the work of opendata.swiss, which has provided a legal and technical basis, and visual vocabulary, for discovering Open Government Data in Switzerland since 2016.

_Screenshot of [opendata.swiss search](https://opendata.swiss/de/group/culture?q=luzern&sort=score+desc%2C+metadata_modified+desc)_
This portal is based on [CKAN](https://ckan.org), an open source platform developed by the open data community to assist with data publication efforts, used by thousands of institutions around the world. We are already helping to deploy CKAN for the 📘 [NADIT project](https://www.hslu.ch/de-ch/hochschule-luzern/forschung/projekte/detail/?pid=6089), and will use this opportunity to test it for our needs and contrast with alternatives.
## What concerns us
Inspired by Data Refuges, we aim to propose a set of tools for use as a Data Portfolio, with a focus on these five concerns:
#### 1. How to make sure we don't lose our data?
Filesystems inevitably become messy over time. A single search engine based on the context of use will help us to quickly retrieve our data references and links when we need them.
#### 2. Who is who in collecting, managing, applying data?
Keeping track of sources and ownership, as well as knowing who (for example, through a student project) has experience with a particular dataset or type of data will be extremely valuable down the road.
#### 3. What factors impact the accessibility of data?
In addition to basic metadata, we will expand on factors - from financial and legal to technical and ethical - that present barriers to the use of certain data sources, representing our experience...and as a reminder, to revisit and test our assumptions in the future.
#### 4. Which projects and topics are linked to what data?
Being able to see how data is being used across domains, and quickly reference and expand on these in a knowledge base, will allow us to map the landscape of data usage across topics, sources, and collection methods.
#### 5. Which datasets are of value to other communities, and why?
It is not only interesting to us how we use data, we also want to keep track of other interesting projects across academic, industrial and citizen science communities. These may be local to our region or halfway across the world. We would like to document some of the similarities and differences in our respective contexts of use.
## Hello, dribdat
These powerful instruments on top of methods like Data Pipelines to structure the conversion of 'raw' data discoveries to maintainable data artifacts, make for a great learning environment for budding data wranglers. We therefore propose to build DATAFUGE on the foundation of the open source tool [dribdat](https://dribdat.cc) - which has been running in alpha form at [DDA.schoolofdata.ch](https://DDA.schoolofdata.ch) since 2021 within DD+A and familiar to our students.
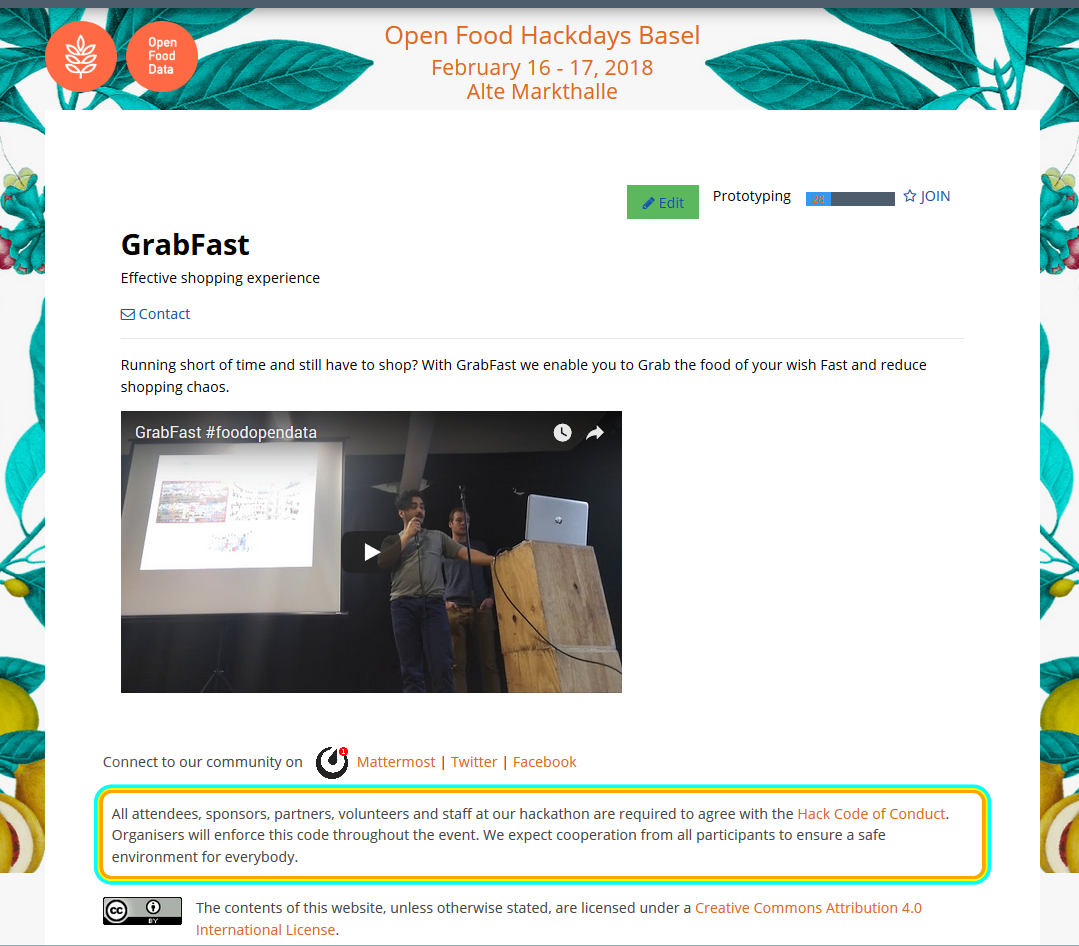
`DRIBDAT` (from "driven by data") is an [open source](https://github.com/dribdat) application, inspired by the design sharing site [Dribbble](https://dribbble.com/), and developed within the Swiss [open data](https://opendata.ch) community. It is maintained by [@loleg](https://github.com/loleg), DD+A lecturer and one of the top [GitHub committers](https://commits.top/switzerland.html) in Switzerland. See more history in the [Whitepaper](https://docs.dribdat.cc/whitepaper).

## Initial experiments
To better understand the context of DATAFUGE, we can look at their semester and final projects, to see how data is referenced in their notes. We can survey them to find out which tools (Dropbox Paper, Notion, etc.) and sites (Behance, Instagram, etc.) are most popular destinations to get inspired by other data artists. We will ask their perspective on the topic of a data portfolio, and involve them in the R&D process.
<img width="50%" src="https://i.imgur.com/VxoXuX5.png"><img width="40%" src="https://i.imgur.com/2d1y1L4.png">
_Two Frictionless [Data Packages](https://dda.schoolofdata.ch/project/8) attached to notes on dribdat._
Students of DD+A 20, 21 & 22 have already used the dribdat platform to share progress of their work, embed open data and Data Packages in their notes. They have provided interesting feedback and [had an impact](https://github.com/dribdat/dribdat/releases/tag/v0.6.6) on the development of the project.
<img width="36%" src="https://i.imgur.com/RoNTEo3.jpg"> <img width="62%" src="https://i.imgur.com/OfScZA6.jpg">
_Screenshots of a [Data Pipeline](https://dda.schoolofdata.ch/event/11/stages) showing class progress, and an individual [student profile](https://dda.schoolofdata.ch/user/holyMoly) on dribdat._
Students need to be able to experiment with digital publication in a safe setting. They should be able to attach glimpses into their visual exploration, concepts, design and production process. It should be possible to see the data analysis go through stages. These are represented with colours and progress bars.

In this sense, the [School of Data Pipeline](http://toolbox.schoolofdata.ch/overview.html) as built into dribdat has now been evaluated in both an activist setting, and adopted in the classroom. We will discuss with DD+A faculty and lecturers to get their opinions on what methodological and pedagogical aspects are relevant to this project. By having direct access to the development of open source software, we can create a custom-tailored solution for our department.
## Are you for Real?
Students tend to complain, avoid, and procrastinate on their process logs. If the environment within which they are developed was more smart, if it would actually enhance their work in some way, they may form a better relationship to it.
Recent discussions such as 📘 [Race against the machine](https://www.hslu.ch/de-ch/wirtschaft/ueber-uns/news/2023/02/03/race-against-the-machine/) with Prof. Dr. Peter Kels & Kai Dröge point to the urgency with which machine learning technolgoies are adapted to 'human' problems. What about tools for note-taking and documentation?
- You could say that Dropbox Paper is usable.
- You could say that Notion is flexible.
- But what tool today gives you *superpowers?*...
We asked A.I. for help with our task, and here is the suggestion:

_Screenshot of [OpenAI / ChatGPT](https://chat.openai.com/)_
_A strong data art portfolio should include a variety of projects that demonstrate the artist's **technical skills, creative vision**, and **ability to use data** in a **meaningful and thought-provoking way**. Some key elements that can help make a portfolio stand out include:_
- Diverse projects: _Showcase a range of projects that demonstrate your ability to work with different types of data and create a variety of data-driven visualizations and interactive experiences._
- Technical skills: _Show that you have a strong understanding of the technical tools and methods used to create data art, such as programming languages, data visualization libraries, and machine learning techniques._
- Creativity: _Showcase your ability to use data in a way that is both visually interesting and meaningful. Highlight projects that explore unique perspectives and push the boundaries of what's possible with data._
- Attention to detail: _Make sure that your portfolio is well-organized and easy to navigate, with clear explanations of the data and techniques used in each project._
- Ethical considerations: _Be transparent about any biases or limitations in your data, and highlight projects that explore ethical and social issues related to the use of data._
- Storytelling: _Showcase your ability to tell a story with your data and how it can be used to convey a message or a meaning._

To what extent the originality, wit and provocativeness of a data project can be expressed in this way still needs to be defined. Questions about the ethics of the use and application of A.I. can in this way be directly addressed in the design of the platform.
## X-A.I.
In a later stage of our research, we will look into ways of complementing data publications with deep searching, made possible today using the Web of Linked Data and Deep Learning. A major present-day challenge is how to render [A.I. explainable](https://de.wikipedia.org/wiki/Explainable_Artificial_Intelligence), rather than having a black-box solution.

_[IBM XAI Toolkit](https://research.ibm.com/topics/explainable-ai)_
On one hand, this is a question of having an open source approach: working with modular components that are transparent to the user, with well attributed open data sources a "[no brainer](https://open-brain-consent.readthedocs.io/en/stable/)" - to be able to reproduce and modify every part of the system. On the other hand, this means responding to a set of [ethical constraints](https://ethix.ch/index.php/en/tools) around [how data is collected](https://www.bfh.ch/de/forschung/forschungsprojekte/2022-470-842-714/), whom it (does or does not) represent, and how a healthy [level of privacy](https://cups.cs.cmu.edu/privacyLabel/) is respected.

In that sense, our DATAFUGE should have a kind of "Nutri-Score" that represents a subjective and objective evaluation of the substituent qualities of data ingredients. There are strong methodologies and compelling projects in this area, such as [Open Data Badges](https://certificates.theodi.org/en/) and [Open Science Framework](https://osf.io/tvyxz/wiki/1.%20View%20the%20Badges/) that we can leverage. It will also be interesting to study how these indicators correlate with 📘 [digital marketing](https://www.hslu.ch/de-ch/wirtschaft/weiterbildung/weiterbildungskurse/ikm/data-driven-content-marketing/) data.

_Screenshot of an [Altmetric score](https://unimelb.libguides.com/altmetrics/home)_
An initial prototype of this is the [dribdat check it](https://github.com/dribdat/design/blob/main/dribdat%20check%20it%20-%20dataletsch%201.0.pdf) worksheet created as a classroom support at DD+A last year.

Such self-assessments could form an integral activity, and provide the basic content for the DATAFUGE.
# Resourcing
To launch the project we define in the next section
- Target audience
- Milestones and Time budget
- Cloud and Tech budget
- Deliverables
## Target audience
Specific user groups to be detailed as personas:
- Students
- Teachers
- Staff
- Visitors
- Public
## Milestones
(1) **Content**
- Create a DD+A theme for the platform
- Set up project template for our students
- Improve and expand the resource library
- Customize and tweak the stage rules
(2) **Interface**
- Simplify updating of project logs with drag and drop
- Use notifications to push advice and reminders
- Implement gamification elements and progress reports
- Wrap into a mobile app for easier access by sudents
(3) **Integration**
- Create an easy access for staff to update the site
- Write documentation for fellow lecturers and staff
- Record screencast, run a training session
- Install with official IT support
(4) **Magic**
- Run a hackathon to develop further improvements in-situ
- Evaluate project logs with NLP for structural analysis
- Extrapolate content with predictive AI like ChatGPT
- Futuristic portrayal of a data portfolio in the year 2050
### Time budget
1. Content 3 - 5 days
2. Interface 4 - 7 days
3. Integration 2 - 5 days
4. Magic 3 - 8 days
Total: 12 - 25 working days
## Cloud and tech budget
- Hosting a Wordpress website on HSLU infrastructure is free, but we may be limited in the kinds of plugins and themes we can install.
- A typical small website and domain hosting package is around 100 CHF per year.
- Dribdat requires a small server and set of cloud services at about 500 CHF per year for a commercial service. It remains to be defined if this could be deployed on HSLU infrastructure, and at what cost.
- Deploying a CKAN instance requires commerical server infrastructure for at least 1000 CHF per year. Lower cost alternatives like JKAN or Datacentral should be considered.
- A cloud data science environment for training GPT models could have a high hourly cost and needs to be appropriately budgeted. Offline hardware (graphics workstations) or university infrastructure (datascience.ch) can be used instead.
- For other collaboration needs free open source code projects and planning boards will be sufficient.
# Further reading
- [Dribdat intro](https://hackmd.io/@oleg/dribdat-intro)
- [Pitch deck](https://hackmd.io/@oleg/HJB1jxAlI)
- [EvalHack intro](https://hackmd.io/@oleg/H1k94i4kw)
- [On Fair Co-creation](https://hackmd.io/@oleg/HJzVtAEjQ)
- [Feedback sessions](https://hackmd.io/@oleg/dribdat-010721q)
- [Hackathon ramblings](https://hackmd.io/@oleg/S1kGpaOt8)
# Inspiration
- [Enzyklopädie - Visual Communication](https://visualcommunication.zhdk.ch/schwerpunkte/information-design/sammlung/) (ZHdK)
- [Digitale Leistungsnachweise](https://ella.zhdk.ch/spaces/leistungsnachweis-online/) (ZHdK)
- [PAUL FAQ](https://paul.zhdk.ch/mod/glossary/view.php?id=141) (ZHdK)
- [Räumlicher Daten in der Lehre ](https://teachingtools.uzh.ch/de/tools/analyse-und-visualisierung-raeumlicher-daten-in-der-lehre) (UZH)
- [Game-based learning](https://www.gbl.uzh.ch/kb/) (UZH)
- [Unintended Consequences](https://toolbox.hyperisland.com/unintended-consequences) (HyperIsland)
- [How to Cite a Database](https://www.easybib.com/guides/citation-guides/mla-format/how-to-cite-a-database-mla/) (EasyBib)
- [Citing Data](https://guides.nyu.edu/datasources/data-citation) (NYU)
_ _ ___ _ __ ___ _ __:last_quarter_moon: :first_quarter_moon: __ __ _ __ _ __ __ __ __
