# 2024q1 Homework1 (lab0)
contributed by < [yc199911](https://github.com/yc199911) >
### Reviewed by `yenslife`
- [ ] 共筆
除非要討論特定行數,否則程式碼區塊不該出現行號,將 \`\`\`c= 的 `=` 刪除即可。
:::info
已改進
:::
- [ ] git commit message
一個 commit 只能說明一個改動,在 commit [66da54e](https://github.com/yc199911/lab0-c/commit/66da54e282e0b595d9867d9e336af7617d12cf2b) 中,雖然 commit 標題為 "Fix q_delete_mid",實際上卻涉及了 `q_sort`, `MERGE_TWO_LISTS`,以及 Makefile 的修改。可以使用 `git rebase` 來修改 commit message。
:::info
謝謝提醒,等達到 95/100 後會先來將我的 commit message 符合老師所要求的規格。
:::
- [ ] Lima
因為我也是安裝 Lima,之前遇過無法讀寫的問題,如果你有遇到可以參考[在 Mac 上使用 lima 作為 Linux 環境](https://yenslife.top/2022/07/05/use-lima-on-mac-as-linux-environment/)。
:::info
謝謝,我會去使用。
:::
- [ ] 註解
使用英文來撰寫註解,讓全世界都看得懂台灣人寫的程式碼。
#### `q_remove_tail` / `q_remove_head` , `q_insert_head` / `q_insert_tail`
直接在 `q_remove_tail` 中呼叫 `q_remove_head` 即可,減少重複程式碼。注意 `list_first_entry` 會回傳 `head` 的下一個節點,所以要傳入 `head->prev->prev` 才是指向尾端節點。
```graphviz
digraph main {
node[shape=plaintext]
head [fontcolor="red"];
l [label="list_first_entry(head->prev->prev, ...)",fontcolor="blue"];
node[shape=box]
s0 [label="1"];
s1 [label="2"];
s2 [label="3"];
s3 [label="4"];
s4 [label="5"];
s5 [label="6"];
{
rank="same";
s0->s1
s1->s0
s1->s2
s2->s1
s2->s3
s3->s2
s3->s4
s4->s3
s4->s5
s5->s4
s5->s0
s0->s5
}
head->s0
l->s5
}
```
`q_insert` 函式也是相同的道理。
#### `q_reverse`
利用 list API 來簡化 `q_reverse` 實作:其實可以用 `list_move` 直接將走訪到的節點移到開頭,減少程式碼數量。
```diff
struct list_head *node;
struct list_head *safe;
list_for_each_safe (node, safe, head) {
+ list_move(node, head);
- node->next = node->prev;
- node->prev = safe;
}
- node->next = node->prev;
- node->prev = safe;
return;
```
### Reviewed by `yeh-sudo`
#### Git commit messages
Git commit message 的標題要用祈使句撰寫,另外,內文要清楚地描述什麼東西改變以及為什麼,以 commit [25ef64e](https://github.com/yc199911/lab0-c/commit/25ef64e2de46ffb9949db62a8730b8f7acdc5d0e) 為例,標題為 Q_delete_mid, q_delete_dup, q_swap, q_reverse ,並沒有以祈使句作為標題,也沒有內文,可以使用 `git rebase -i` 來作修改,撰寫 commit message 的部份可以參考〈[How to Write a Git Commit Message](https://cbea.ms/git-commit/)〉。
#### 註解
使用英文撰寫註解。
- [ ] `queue.c`
```c=47
INIT_LIST_HEAD(&new_node->list);
// 分配足夠的記憶體來容納字串 s,包括結尾的空字符 '\0'
char *new_char = malloc((strlen(s) + 1) * sizeof(char));
if (!new_char) {
free(new_node);
return false;
}
// 複製字串 s 的內容到新分配的記憶體中
strncpy(new_char, s, strlen(s));
new_char[strlen(s)] = '\0';
```
#### `q_sort`
`q_sort` 中有錯誤,沒辦法以降序的方式排列,每次排序的結果都是升序。
- [ ] 錯誤範例測試
```shell
cmd> option descend 1
cmd> new
l = []
cmd> it RAND 1000
l = [hudumqb bdppnzl wymtypi sebldew azpxz pjhiq rcslvl zubsom yjqbkzisf dqewwj pivroo mewgkppc mtvkwln tpudayxj qmmcnqjvm qgglpj gcubqk qnkdrlyj jcfmfruo mmzzgionr dqojg ejpqojx dyonu cplkfmbny bkiwhjnc wkuzcm hdzho jqzuceg lpozuth avmhgnoao ... ]
cmd> sort
ERROR: Not sorted in descending order
l = [abosmmy adsyvvzxx aftbathc ageuvu agijmnf agokvor agxldjnsd ahtwb aizpiwar ajnpj ajyxzlynx akantgjci aksymuk allhocnn alxmzytep amxunj anhekvive aomsd aoxgokvp arzfsu aseea asfxyx asurtc atjgaayyh atnetaig auomwt avmhgnoao axbsry axclmhhk axuabkixn ... ]
cmd> free
l = NULL
cmd> quit
Freeing queue
```
#### 共筆
時間複雜度或是數學式可以使用 Latex ,像是這樣 $O(n^2)$ ,會比較好看懂。
### 系統安裝
一開始用實驗室電腦想要安裝 ubuntu 系統,但照著影片的方法都一直無法成功,後來看了許久才發現原來實驗室電腦老舊,沒有現在常用的 UEFI 讀取,而只有 legacy ,導致一開始一直誤以為是 usb 的 ubuntu 系統沒安裝好(這種狀況使用隨身碟開機會顯示"沒有讀取到東西,請按鍵繼續")
而我本身是 mac air m2 有找過網路好像也沒辦法使用雙系統,想問老師有其他方法嗎?
(目前已有一台電腦能夠順利跑 ubuntu 系統)
:::warning
請愛用 [lima](https://github.com/lima-vm/lima),作業說明已提過。
:::
### 開發環境
$ gcc --version
gcc (Ubuntu 11.4.0-1ubuntu1~22.04) 11.4.0
Copyright (C) 2021 Free Software Foundation, Inc.
This is free software; see the source for copying conditions.There is NO
warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 48 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 16
On-line CPU(s) list: 0-15
Vendor ID: AuthenticAMD
Model name: AMD Ryzen 7 7700X 8-Core Processor
CPU family: 25
Model: 97
Thread(s) per core: 2
Core(s) per socket: 8
Socket(s): 1
Stepping: 2
CPU max MHz: 5573.0000
CPU min MHz: 400.0000
BogoMIPS: 8982.75
### 閱讀文章吸取到的想法
原本看 list.h 後面所提及的程式都沒有太大的概念,再重看幾次[你所不知道的 C 語言: linked list 和非連續記憶體](/YA7RMqd6RE2UL8OmmjU9PQ) 這張圖讓我對於 list.h 裡的結構更加清楚,我們可以把 list_head 想成是將每個物件串連起來的鉤子, `list_head *node` 就是這個物件的<s>名子</s> ???,而像 int `value;char *s` 這種就像是物件裡面的內容,讓我對於 linked list 結構的閱讀更加迅速也<s>更有畫面</s>
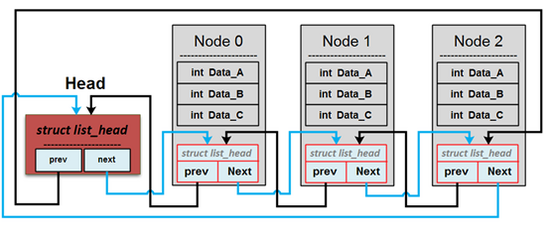
:::danger
改進你的漢語表達。
:::
### 指定佇列操作
#### q_new
這是第一個開始寫的 function ,對於怎麼去使用 list.h 裡的函數很不熟悉,我處理的步驟是:
1. 看 queue.h 裡的介紹
2. 想好如何產生一個節點
3. 去 list.h 找所需使用到的函數
```c=
struct list_head *head = malloc(sizeof(struct list_head));
if (head == NULL)
return NULL;
INIT_LIST_HEAD(head);
return head;
```
雖然這個程式想法很單純,但對 linked list 不熟的時候還是需要花時間想
我覺得 [你所不知道的 C 語言: linked list 和非連續記憶體](/YA7RMqd6RE2UL8OmmjU9PQ) 的圖讓我對理解幫助很大
```c=
struct list_head {
struct list_head *prev;
struct list_head *next;
};
```
```graphviz
digraph list_head {
rankdir=LR;
node[shape=record, style=bold];
head [label="{<prev>prev|<next>next}"];
}
```
#### q_free
寫完 q_new 後對 list.h 比較了解後,q_free所花的時間就少很多
但目前僅僅是讓 ./qtest 執行上沒有出錯。
透過 ./qtest 後發現
ERROR: There is no queue, but 3 blocks are still allocated
發現我原本這樣寫只會 free element_t *entry 物件裡的指標,但因為 element_t 是一個包含 value 跟 list_head的結構,所以要使用 list.h 裡的 q_release_element 才能將 element_t 裡的結構移除,之後只剩下空的 list 在使用 free 將它移除
```diff
- list_del(&entry->list);
- free(entry);
+ q_release_element(entry);
+ }
+ free(l);
```
#### q_insert_head
```c
+++ TESTING trace trace-01-ops:
# Test of insert_head and remove_head
ERROR: Need to allocate and copy string for new queue element
ERROR: Need to allocate and copy string for new queue element
ERROR: Need to allocate and copy string for new queue element
ERROR: Attempted to free unallocated block. Address = 0x561689a59a30
ERROR: Attempted to free unallocated or corrupted block. Address = 0x561689a59a30
ERROR: Corruption detected in block with address 0x561689a59a30 when attempting to free it
Segmentation fault occurred. You dereferenced a NULL or invalid pointer--- trace-01-ops 0/5
```
在編譯完成後 做 make test 發現只有一題拿到分數
我從最上面開始檢查,看到我需要 "copy string for new queue element"
我去規格書上搜尋 copy copies copying 這些關鍵字接著在裡面發現 strcpy() , strncpy()
我就拿著這兩個關鍵字去規格書中搜尋, 因為 strcpy() 的資料型態沒有 size_t ,所以我選擇 strncpy()
接著重翻 [你所不知道的 C 語言:指標篇](/hqJBzualRcOrb2wMhheKCQ)發現其實下面的範例就有使用到
規格書裡 7.21.2.3 The strcpy function
```c
char *strcpy(char * restrict s1,const char * restrict s2);
```
> strcpy()
> The strcpy function copies the string pointed to by s2 (including the terminating null character) into the array pointed to by s1. If copying takes place between objects that overlap, the behavior is undefined.
7.21.2.4 The strncpy function
```c
char *strncpy(char * restrict s1,const char * restrict s2,size_t n);
```
> The strncpy function copies not more than n characters (characters that followanull character are not copied) from the array pointed to by s2 to the array pointed to by s1.
> If copying takes place between objects that overlap, the behavior is undefined.
原本的 q_insert 雖然能夠成功編譯,但當我執行 ./qtest 時會得到 "l = [dolphinU���]" 參考過之前同學的文件後,有可能是記憶體問題,所以我將要以這個方向去檢查。
```diff
+ new_char[strlen(s)] = '\0';
```
<s>
</s>
:::danger
文字訊息避免用圖片來表示,否則不好搜尋和分類
:::
因為原本 ih 一直會有亂碼,所以我打算用 `make SANITIZER=1` 去強化執行時期的記憶體檢測,接著照終端執行報錯進行更正,成功讓 ih dolphin 不再有亂碼。
覺得自己學到使用規格書的方法:在腦袋中思考步驟後將不知道如何實作的語法去搜尋再到規格書去確認正確性!
#### q_remove_head
#### q_swap
目前我自己的程式碼會導致
"ERROR: Time limit exceeded. Either you are in an infinite loop, or your code is too inefficient"
```diff
- for (; curr && curr->next != head; curr = curr->next)
- list_move(curr, curr->next);
+ list_for_each_safe (first, second, head){
+ if (first == second)
+ break;
+ list_move(second, first);
+ head = first;
+ second = first->next;
+ }
+ }
改進後 commit 顯示這兩行沒有使用到
+ head = first;
+ second = first->next;
```
:::danger
使用 `git diff` 或 `diff -u` 命令去產生程式碼之間的變異,不要憑感覺填入。
:::
後來一直無法通過測試,我改使用更改每個結構的 `prev` 和 `next` 去達成 swap的效果。
一開始只想到兩個點將他們互換,而後來發現忽略了這兩個點的前後。
```c
second->prev = first->prev;
first->next = second->next;
first->prev = second;
second->next = first;
first = first->next;
```
而當我補上要被交換的前後兩個點的 `prev` 和 `next` 後發現一樣無法通過測試,我丟到 chatgpt 上詢問有沒有語法或是哪裡錯誤時, Chatgpt 指出:
```c
second->next->prev = first;
```
應該在 `second` 和 `first` 節點交換位置之後,而不是之前。因為在交換位置之前,`second->next` 指向的節點可能已經被更改為 `first`,如果直接在這裡訪問 `second->next->prev`,可能會導致訪問到無效的內存,從而引發未定義的行為。
但後來我發現問題其實不是在那裡,是因為我初始化 `list_for_each_safe` 的條件用錯了,因為 `list_for_each_safe` 執行完一次本來就會將 `first = first->next` 而因為經過 swap 後 `first` 已經在 `second` 之後,所以只需要更新 `second` 的條件。
```diff
- first = first->next;
+ second = first->next;
```
#### q_del_mid
這題是看到 [分析「快慢指標」](/NDN4SlBNQvCVZZ1YgYBtHg) 裡學到使用一個fast指標再用一個 slow 指標
而再透過 for 迴圈後先執行的是 slow 指標,使 slow 指標會是 (floor(fast) / 2) + 1
這裡有發現 queue.h 裡面這兩句敘述有錯,但後來看到 leetcode 上面敘述
* ⌊n / 2⌋th node from the start using 0-based indexing.
* If there're six elements, the third member should be returned.
如果有六個元素,應該是第四個要被輸出。
但現在的寫法會發生執行過久或無法跳出迴圈。
```diff=
-while (fast && fast->next)
+while (fast->next != head && fast != head)
```
中途有改一個判斷式結果只是因為條件很多所以自己在測試的時候會過,後來進行 make test 一直無法順利通過,我使用 valgrind 去看每個步驟,跑出segamentation fault 還有記憶體沒有釋放,一開始一直誤以為是有什麼地方忘記,但在重新看 q_release_element 發現他就已經有釋放記憶體,看了整整一個下午最後發現是 while 迴圈就已經出了問題。
Debug 時可以先檢查 while 或 for 迴圈裡面的條件再去逐一檢查其他的程式
#### `q_sort`, `q_merge`
一開始我使用最好想的方法:
1. 使用 list_for_each_safe
2. 將每個值去做 if else判斷
3. 再進行 merge
這樣就可以排序完成。
當初我有想到要用 merge sort ,但因為寫了很久,我參考 [chloe0919](https://hackmd.io/@Chloexyw/linux2024-homework1#%E9%96%8B%E7%99%BC%E7%92%B0%E5%A2%83),並將寫法學習起來。
[git commit](https://github.com/yc199911/lab0-c/commit/7ae3b7a3bb701e7fb2efa413a7274e739a3e6b03)
```diff
- list_move(Rnode, Lnode->prev);
+ list_move(Rnode->prev, Lnode->prev);
```
因為一開始一直沒注意到前一行 Rnode = Rnode->next
所以一直沒發現這裡寫錯 `list_move(Rnode, Lnode->prev)`
在這之中發現自己總是能想到程式大概怎麼樣能完成題目所需,但總是會東缺西漏,認知到自己基礎程式語言能力的不足。
目前已有去將 [C 語言入門](https://www.youtube.com/watch?v=yWPGumB64tM&list=PLY_qIufNHc293YnIjVeEwNDuqGo8y2Emx) 大部分內容看完。
#### q_descend
```c
list_for_each_entry_safe (first, second, head, list) {
if (second->value > first->value)
list_del(&first->list);
```
一開始誤以為這樣就能達成題目要求,後來發現如果題目為 [5, 1, 2, 4, 3 ] 那就不會是題目所要求的答案。
:::danger
改進你的漢語表達
:::
```c
max = list_entry(head->next, element_t, list);
list_for_each_entry_safe(tmp, safe, head, list) {
if (strcmp(max->value, tmp->value) < 0) {
max = tmp;
}
}
for (tmp = max; &tmp->list != head; tmp = safe) {
safe = list_entry(tmp->list.next, element_t, list);
if (strcmp(tmp->value, safe->value) < 0) {
if (strcmp(max->value, safe->value) < 0) {
list_del(&max->list);
q_release_element(max);
max = safe;
}
list_del(&tmp->list);
q_release_element(tmp);
}
}
return q_size(head);
}
```
後來我想先找到這個串列裡面的最大值 max ,接著將 max 之前的 element 都刪除,之後再從 max 之後的串列中進行比大小,但發現這樣會導致時間複雜度到 O(n^2) ,我參考 leetcode 的提示,發現如果一開始就將串列反轉,就可以省去很多不必要的重複比較,例如[5, 1, 3, 2, 4] 這個例子中,我就不需要再比較 3, 4 中哪一個比較大。
#### q_delete_dup
改進後,目前 TESTING trace trace-06-ops 出現以下問題,發現是 `q_delete_dup` 這個函式尚有問題。
Test of insert_head, insert_tail, delete duplicate, sort, descend and reverseK
ERROR: Duplicate strings are in queue or distinct strings are not in queue
ERROR: There is no queue, but 1 blocks are still allocated
ERROR: There is no queue, but 1 blocks are still allocated
ERROR: Freed queue, but 1 blocks are still allocated
原先 `temp` 指標誤配置了記憶體,導致 `There is no queue, but 1 blocks are still allocated`,修正完成後,這個 `error` 已經修正完畢,但還是有 `ERROR: Duplicate strings are in queue or distinct strings are not in queue` 這個問題,發現判斷式也出現了問題,我參考 [vax-r](https://hackmd.io/@vax-r/linux2024-homework1) 的作業進行調整。
調整後目前 qtest 分數為 95/100
### 論文〈Dude, is my code constant time?〉
一開始看到[dudect.h](https://github.com/oreparaz/dudect/blob/master/src/dudect.h) 的程式碼想說能不能直接套用,但套用進去後執行會發現
```
/usr/bin/ld: qtest.o: in function `queue_remove':
/home/allen/linux2024/lab0-c/qtest.c:302: undefined reference to `is_remove_tail_const'
/usr/bin/ld: /home/allen/linux2024/lab0-c/qtest.c:302: undefined reference to `is_remove_head_const'
/usr/bin/ld: qtest.o: in function `queue_insert':
/home/allen/linux2024/lab0-c/qtest.c:190: undefined reference to `is_insert_tail_const'
/usr/bin/ld: /home/allen/linux2024/lab0-c/qtest.c:190: undefined reference to `is_insert_head_const'
collect2: error: ld returned 1 exit status
```
之後我參考 [vax-r](https://hackmd.io/@vax-r/linux2024-homework1) 同學的筆記,發現原來老師已經將這些用一個函式將這些 `simulation` 裡需要的函式精簡的寫在這個 marco。
```c
#define DUT_FUNC_IMPL(op) \
bool is_##op##_const(void) \
{ \
return test_const(#op, DUT(op)); \
}
#define _(x) DUT_FUNC_IMPL(x)
DUT_FUNCS
#undef _
```
`DUT_FUNC_IMPL` 它接受一個參數 op,並將其用作函數名的一部分。這個定義了一個返回布爾值的函數,其名稱格式為 `is_op_const`,其中 `op` 是傳入的參數。
`#define _(x) DUT_FUNC_IMPL(x)`:定義將 _(x) 替換為 `DUT_FUNC_IMPL(x)`,這意味著當您使用 `_` 並提供一個參數時,它將展開為對應的 `DUT_FUNC_IMPL` 。
`DUT_FUNCS`:這個用來展開一系列 `_(x)` ,其中 x 是由 `DUT_FUNC_IMPL` 中的 `op` 參數提供的值。這將生成一系列函數的實作,其名稱格式為 `is_x_const`。
而這個 marco 的好處在於:可以自動生成一系列函數的實作,這些函數的名稱格式為 `is_x_const`,其中 x 是由 DUT_FUNCS 提供的一系列值。這樣可以節省大量的重複性工作,使代碼更加簡潔和易於維護。
:::danger
改進用語,macro 是「巨集」,implement 是「實作」
:::
:::info
ok!
:::
在讀論文的 `Implementation` 的 `a. Pre-precessing` 寫著
```
We pre-process measurements prior to
statistical processing. We discard measurements that are larger
than the p percentile, for various2 values of p. The rationale
here is to test a restricted distribution range, especially the
lower cycle count tail. The upper tail may be more influenced
by data-independent noise. This (heuristic) process gives good
empirical results (makes detection faster); nevertheless we also
process measurements without pre-processing.
```
而我在 [dudect.h](https://github.com/oreparaz/dudect/blob/master/src/dudect.h) 中發現有關 `percentile` 的程式碼理解並加入 lab0 裡面。
在這裡原始程式碼將迴圈從第十筆開始進行,我認為作者可能是為了跳過最初的幾個測量值,為了減輕實驗中可能存在的啟動效應或其他不穩定因素對結果的影響。
```diff
- for (size_t i = 0 /* discard the first few measurements */; i < (ctx->config->number_measurements-1); i++) {
int64_t difference = ctx->exec_times[i];
+ for (size_t i = 10 /* discard the first few measurements */; i < (ctx->config->number_measurements-1); i++) {
int64_t difference = ctx->exec_times[i];
```
```c
static int cmp(const int64_t *a, const int64_t *b) {
if (*a == *b)
return 0;
return (*a > *b) ? 1 : -1;
}
static int64_t percentile(int64_t *a_sorted, double which, size_t size) {
size_t array_position = (size_t)((double)size * (double)which);
assert(array_position < size);
return a_sorted[array_position];
}
/*
set different thresholds for cropping measurements.
the exponential tendency is meant to approximately match
the measurements distribution, but there's not more science
than that.
*/
static void prepare_percentiles(dudect_ctx_t *ctx) {
qsort(ctx->exec_times, ctx->config->number_measurements, sizeof(int64_t), (int (*)(const void *, const void *))cmp);
for (size_t i = 0; i < DUDECT_NUMBER_PERCENTILES; i++) {
ctx->percentiles[i] = percentile(
ctx->exec_times, 1 - (pow(0.5, 10 * (double)(i + 1) / DUDECT_NUMBER_PERCENTILES)),
ctx->config->number_measurements);
}
}
```
`cmp` 函數定義了一個比較函數,用於對整數陣列進行排序。該函數根據整數值的大小進行比較,如果第一個參數大於第二個參數,則返回 1;如果兩個參數相等,則返回 0;否則返回 -1。
`percentile` 函數計算了排序後整數陣列中特定百分位數的值。它接受三個參數:已經排序的整數陣列 a_sorted、要計算的百分位數 which、以及整數陣列的大小 size。該函數根據百分位數的大小將陣列位置計算為 `(size_t)((double)size * (double)which)`,並返回對應位置的值。
`prepare_percentiles` 函數根據給定的測量值陣列 `exec_times`,計算了一系列百分位數並存儲在 `percentiles` 陣列中。它首先將測量值陣列進行排序,然後使用 `percentile` 函數來計算一系列百分位數。該函數根據 `DUDECT_NUMBER_PERCENTILES` 定義的百分位數數量,計算不同百分位數的值。通過使用指數函數 `pow(0.5, 10 * (double)(i + 1) / DUDECT_NUMBER_PERCENTILES)`,可以在數學上更好地匹配測量值的分佈,但實際上並沒有更多的科學依據。
加入後成功使 make test 獲得 100/100
### 研讀 Linux 核心原始程式碼的 lib/list_sort.c〉
#### 將 list_sort 加入lab0-c
參考 [wanghanchi](https://hackmd.io/@wanghanchi/linux2023-lab0#%E7%A0%94%E8%AE%80-Linux-%E6%A0%B8%E5%BF%83%E5%8E%9F%E5%A7%8B%E7%A8%8B%E5%BC%8F%E7%A2%BC%E7%9A%84-liblist_sortc)
學習他的做法順利將 list_sort 加入 lab0-c
其中不明白為什麼要將 Makefile 中 OBJS,新增一個 list_sort.o
經過<s>查詢</s> 後發現:
:::danger
閱讀 GNU make 手冊,而非仰賴經由 Google 搜尋得來的隻字片語
:::
:::info
已有去查詢 GNU make 手冊,了解 OBJS 為一個變數,而將 list_sort.o 加入後在之後需要編譯時只需要加上 $ 即可不用重複輸入所要編譯的檔案。
:::
在 Makefile 中添加 OBJS 列表的目的是為了告訴 make 工具程序編譯器需要編譯哪些檔案,並將它們編譯成最終的可執行文件。每個文件對應一個目標檔(object file),而 OBJS 列表就是這些目標檔的集合。
:::danger
file 是「檔案」,而非「文件」(document)。
source file 是「原始程式碼」。
強調相互結合的意境時,譯作「連結」,例如「動態連結函式庫」(dynamic-link library),而強調資料因結合而呈現鏈狀樣貌,用「鏈結」,如鏈結串列 (linked list)。
project 是「專案」,而非「項目」(item)
參見[詞彙對照表](https://hackmd.io/@l10n-tw/glossaries)
:::
:::info
了解!
:::
如果需要在 Makefile 中添加一個名為 list_sort.o 的目標檔,就是你的專案中引入了一個名為 list_sort.c 的檔案,並且需要將其編譯成一個目標檔。這通常發生在你的項目中使用了自行實作的排序演算法,並且需要將其編譯成一個獨立的目標檔,以便在連結時使用。
 Sign in with Wallet
Sign in with Wallet







