# 2016q3 Homework1 (compute_pi)
contributed by <`jayfeng0225`>
###### tags: `jayfeng0225`
## 作業要求
* 在 GitHub 上 fork [compute-pi](https://github.com/sysprog21/compute-pi),嘗試重現實驗,包含分析輸出
* 注意: 要增加圓周率計算過程中迭代的數量,否則時間太短就看不出差異
* 詳閱廖健富提供的[詳盡分析](https://hackpad.com/Hw1-Extcompute_pi-geXUeYjdv1I),研究 error rate 的計算,以及為何思考我們該留意後者
* 用 [phonebok](/s/S1RVdgza) 提到的 gnuplot 作為 `$ make gencsv` 以外的輸出機制,預期執行 `$ make plot` 後,可透過 gnuplot 產生前述多種實做的效能分析比較圖表
* 可善用 [rayatracing](/s/B1W5AWza) 提到的 OpenMP, software pipelining, 以及 loop unrolling 一類的技巧來加速程式運作
* 詳閱前方 "Wall-clock time vs. CPU time",思考如何精準計算時間
* 除了研究程式以外,請證明 [Leibniz formula for π](https://en.wikipedia.org/wiki/Leibniz_formula_for_%CF%80),並且找出其他計算圓周率的方法
* 請詳閱[許元杰的共筆](https://embedded2015.hackpad.com/-Ext1-Week-1-5rm31U3BOmh)
* 將你的觀察、分析,以及各式效能改善過程,並善用 gnuplot 製圖,紀錄於「[作業區](https://hackmd.io/s/H1B7-hGp)」
---
## Wall-Clock Time vs. CPU Time
__1. Wall-Clock Time__ Wall-clock time 顧名思義就是掛鐘時間,也就是現實世界中實際經過的時間,是由 kernel 裡的 xtime 來紀錄,系統每次啟動時會先從設備上的 RTC 上讀入 xtime。
```clike=
struct timespec xtime __attribute__ ((aligned (16)));
struct timespec {
__kernel_time_t tv_sec; /* seconds */
long tv_nsec; /* nanoseconds */
};
```
__2. CPU Time__ 指的是程序在 CPU 上面運行消耗 (佔用) 的時間,clock() 就是很典型用來計算 CPU time 的時間函式,但要注意的是,如果有多條 threads,那 CPU time 算的是「每條 thread 的使用時間加總」,所以如果我們發現 CPU time 竟然比 Wall-clock time 還大!這可能是個很重要的原因。
另外很多時候只計算 CPU time 是不夠的,因為執行時間可能還包括 I/O time、 communication channel delay、synchronization overhead…等等。
[CPU bound](https://en.wikipedia.org/wiki/CPU-bound) 與 [I/O bound](https://en.wikipedia.org/wiki/I/O_bound)
所謂 CPU bound,指的是程序需要大量的 CPU computation (對 CPU time 需求量大),相比之下僅需少量的 I/O operation,效能取決於 CPU 速度。
所謂 I/O bound,需要大量 I/O operation (I/O request 的頻率很高或一次 I/O request 成本很高),但僅需少量的 CPU computation,效能取決於 I/O device 速度。
很多時候我們可以使用 time 判斷程式是 CPU bound 還是 I/O bound。
1. `real < user`: 表示程式是 CPU bound,使用平行處理有得到好處,效能有提昇。
2. `real ≒ user`: 表示程式是 CPU bound,即使使用平行處理,效能也沒有明顯提昇,常見的原因有可能是其實計算量沒有很大,生成、處理、結束多執行緒的 overhead 吃掉所有平行處理的好處,或是程式相依性太高,不適合拿來作平行處理。
3. `real > user`: 表示程式是 I/O bound,成本大部分為 I/O操作,使得平行處理無法帶來顯著的效能提昇 ( 或沒有提昇)。
## RDTSC instruction
RDTSC讀出的是CPU內部的計數器(counter),這個counter會隨著CPU clock遞增,而RDTSC就是會取該時刻的值。因此我們取某段程式碼前後的值,並將其相減就可以得到執行時間花了多少CPU time。
Pentium (含) 以後的 CPU 都支援 RDTSC, 而如果編譯器 (complier) 沒有支援時, 可用機械碼 0F31 代替, 再從 EAX, EDX (32 位元暫存器) 取回結果。此外, 純 DOS 底下的一般編譯器 (例如: Turbo C, Turbo Pascal ... 等) 不見得有支援 32 位元的暫存器, 可改用 Symantec C, Watcom C, Dev Pascal ... 等
原先在寫實驗室的程式時就已經用過這個功能來計算演算法的執行速度。所以在此用來計算CPU time,不過根據這篇文章 [多核時代不宜再用 x86 的 RDTSC 指令測試指令周期和時間](http://blog.csdn.net/solstice/article/details/5196544),也許RDTSC已經沒有這麼精準,不過還是可以當作我們比較使用CPU time的參考。
RDTSC的寫法如下 :
首先宣告 rdtsc()
```clike=
inline unsigned long long int rdtsc()
{
unsigned long long int x;
asm volatile ("rdtsc" : "=A" (x));
return x;
}
```
在來我們需要另外宣告
```clike=
unsigned long long int begin , end ;
```
使用的方法為
```clike=
begin = rdtsc();
// Program execution here
end = rdtsc();
unsigned long long exec_time = end - begin
```
---
## Linux指令 `time`
參考網址:[Linux 的 time 指令](http://yuanfarn.blogspot.tw/2012/08/linux-time.html)
`time` : 用來計算程式執行時間的指令
一般直接執行`time`會秀出以下結果
```
real 0m0.000s
user 0m0.000s
sys 0m0.000s
```
* `real time` 表示==後面所接的指令或程式從開始執行到結束終止所需要的時間==。簡單講,當一個程式開始執行瞬間看一下手錶記下時間,當程式結束終止瞬間再看一次手錶,兩次的時間差就是 real time。
* `user CPU time` 表示==程式在 user mode 所佔用的 CPU 時間總和==。多核心的 CPU 或多顆 CPU 計算時,則必須將每一個核心或每一顆 CPU 的時間加總起來。
* `system CPU time` 表示==程式在 kernel mode 所佔用的 CPU 時間總和==。
### OS複習
:::info
__Kernel mode__:
在kernel mode,程式可以不受限制的存取底層硬體。此外,還可以執行CPU instruction與存取內存的memory address。kernel mode通常由底層一些較受信任的作業系統函式來保存,假如crash發生再kerenl mode會影響到整個系統。
__User mode__ :
在user mode,程式無法直接存取底層硬體,需要由作業系統提供可靠的API才能存取。以這種隔離的關係對系統做保護,因此程式crash時也不會影響到作業系統,多數的程式都是屬於user mode。
:::
### make check的輸出結果
```
time ./time_test_baseline
N = 400000000 , pi = 3.141593
7.74user 0.00system 0:07.74elapsed 100%CPU (0avgtext+0avgdata 1804maxresident)k
0inputs+0outputs (0major+86minor)pagefaults 0swaps
time ./time_test_openmp_2
N = 400000000 , pi = 3.141593
7.72user 0.01system 0:03.87elapsed 199%CPU (0avgtext+0avgdata 1808maxresident)k
0inputs+0outputs (0major+87minor)pagefaults 0swaps
time ./time_test_openmp_4
N = 400000000 , pi = 3.141593
14.60user 0.01system 0:03.91elapsed 373%CPU (0avgtext+0avgdata 1600maxresident)k
0inputs+0outputs (0major+87minor)pagefaults 0swaps
time ./time_test_avx
N = 400000000 , pi = 3.141593
2.43user 0.00system 0:02.43elapsed 100%CPU (0avgtext+0avgdata 1712maxresident)k
0inputs+0outputs (0major+86minor)pagefaults 0swaps
time ./time_test_avxunroll
N = 400000000 , pi = 3.141593
2.80user 0.00system 0:02.80elapsed 99%CPU (0avgtext+0avgdata 1712maxresident)k
0inputs+0outputs (0major+86minor)pagefaults 0swaps
```
linux manpage `time`的頁面提到輸出字串格式為
```
%Uuser %Ssystem %Eelapsed %PCPU (%Xtext+%Ddata %Mmax)k
%Iinputs+%Ooutputs (%Fmajor+%Rminor)pagefaults %Wswaps
```
但是看起來相當雜亂,所以我改用-verbose參數來顯示
```
time -v ./time_test_baseline
N = 400000000 , pi = 3.141593
Command being timed: "./time_test_baseline"
User time (seconds): 7.80
System time (seconds): 0.04
Percent of CPU this job got: 99%
Elapsed (wall clock) time (h:mm:ss or m:ss): 0:07.85
time -v ./time_test_openmp_2
N = 400000000 , pi = 3.141593
Command being timed: "./time_test_openmp_2"
User time (seconds): 8.30
System time (seconds): 0.20
Percent of CPU this job got: 198%
Elapsed (wall clock) time (h:mm:ss or m:ss): 0:04.29
time -v ./time_test_openmp_4
N = 400000000 , pi = 3.141593
Command being timed: "./time_test_openmp_4"
User time (seconds): 15.02
System time (seconds): 0.02
Percent of CPU this job got: 387%
Elapsed (wall clock) time (h:mm:ss or m:ss): 0:03.88
time -v ./time_test_avx
N = 400000000 , pi = 3.141593
Command being timed: "./time_test_avx"
User time (seconds): 2.44
System time (seconds): 0.00
Percent of CPU this job got: 99%
Elapsed (wall clock) time (h:mm:ss or m:ss): 0:02.44
time -v ./time_test_avxunroll
N = 400000000 , pi = 3.141593
Command being timed: "./time_test_avxunroll"
User time (seconds): 2.72
System time (seconds): 0.00
Percent of CPU this job got: 99%
Elapsed (wall clock) time (h:mm:ss or m:ss): 0:02.73
```
time -p 的結果 :
```
time -p ./time_test_baseline
N = 400000000 , pi = 3.141593
real 7.92
user 7.84
sys 0.08
time -p ./time_test_openmp_2
N = 400000000 , pi = 3.141593
real 3.87
user 7.69
sys 0.01
time -p ./time_test_openmp_4
N = 400000000 , pi = 3.141593
real 3.90
user 14.99
sys 0.01
time -p ./time_test_avx
N = 400000000 , pi = 3.141593
real 2.44
user 2.44
sys 0.00
time -p ./time_test_avxunroll
N = 400000000 , pi = 3.141593
real 2.75
user 2.74
sys 0.01
```
---
## 先產生初步的數據結果
首先需要產生足夠的數值,才能夠畫出數據圖
因此要修改Makefile內的 gencsv
:::danger
printf的輸出要把逗點換成空白,這裡卡了很久
:::
```cmake=
gencsv: default
for i in `seq 1000 5000 1000000`; do \
printf "%d " $$i;\
./benchmark_clock_gettime $$i; \
done > result_clock_gettime.csv
```
seq的格式為`"初始值" "區間" "終止值"`
因此初始N=1000,最終值N=10^6^
runtime.gp也要修改,因為需要以指數作為x軸,因此要加上
`set logscale x`

---
## 計算圓周率
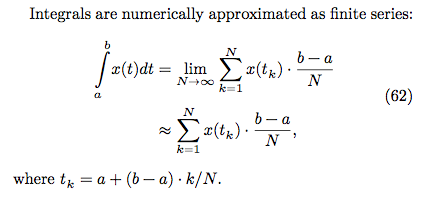
### Baseline版本
根據上述數學式轉換成 baseline.c
修改變數,將傳入的參數改為 N,比較直覺
N 越大,dt 越小,切割越細
```clike=
double computePi_v1(size_t N)
{
double pi = 0.0;
double dt = 1.0 / N; // dt = (b-a)/N, b = 1, a = 0
for (size_t i = 0; i < N; i++) {
double x = (double) i / N; // x = ti = a+(b-a)*i/N = i/N
pi += dt / (1.0 + x * x); // integrate 1/(1+x^2), i = 0....N
}
return pi * 4.0;
}
```
### AVX SIMD 版本
#### [SIMD (Single Instruction Multiple Data)](https://en.wikipedia.org/wiki/SIMD)
能夠複製多個運算元,並把它們打包在大型暫存器的一組指令集。且以同步方式,在同一時間內執行同一條指令。
#### [SSE (Streaming SIMD Extension)](https://zh.wikipedia.org/wiki/SSE)
這個網站有非常詳細的介紹 :
https://www.csie.ntu.edu.tw/~r89004/hive/sse/page_1.html
SSE 本質上是非常類似一個向量處理器的。SSE 指令包括了四個主要的部份:單精確度浮點數運算指令、整數運算指令(此為 MMX 之延伸,並和 MMX 使用同樣的暫存器)、Cache 控制指令、和狀態控制指令。這裡主要是介紹浮點數運算指令和 Cache 控制指令。
---
### [Leibniz formula for π](https://zh.wikipedia.org/wiki/%CE%A0%E7%9A%84%E8%8E%B1%E5%B8%83%E5%B0%BC%E8%8C%A8%E5%85%AC%E5%BC%8F)
Leibniz formula 為

右邊的展式是一個無窮級數,被稱為萊布尼茨級數,這個級數收斂到 π/4。

```clike=
double compute_pi_leibniz(size_t N)
{
double pi = 0.0;
double temp = 1;
for (size_t i = 0 ; i < N ; i++){
pi += temp / (2* (double)i + 1);
temp *= (-1);
}
return pi * 4.0;
}
```
### [Euler](https://zh.wikipedia.org/wiki/%E5%B7%B4%E5%A1%9E%E5%B0%94%E9%97%AE%E9%A2%98)

```clike=
double compute_pi_euler(size_t N)
{
double pi = 0.0;
for (size_t i = 1; i <= N; i++){
pi += 1/ ((double)i*(double)i);
}
pi *= 6;
return sqrt(pi);
}
```
簡單利用程式做出Leibniz以及Euler計算π的結果,並且畫在圖中

## Error Rate
參考廖健富學長的文件 error rate 算法為
```
(counted_pi - exact_pi) / exact_pi
```
利用time_test.c做修改
[程式碼](https://github.com/JayFeng0225/System_Software/blob/master/hw1/compute-pi/error_rate.c)

## CPU Time 計算
將rdtsc()實作在benchmark_rdtsc.c中
:::danger
需要將rdtsc()改為force inline的用法,否則complier可能會視為未定義。
```clike=
inline __attribute__((always_inline)) unsigned long long int rdtsc()
{
unsigned long long int x;
asm volatile ("rdtsc" : "=A" (x));
return x;
}
```
:::
接著比較看看執行時間結果是否合理:

可以看到執行時間的比例與使用clock_gettime相同。
再來需要[計算 CPU time](https://chi_gitbook.gitbooks.io/personal-note/content/cpu_time.html)
```
CPU Time = CPU clock cycle / Clock Rate
```
因此要將所有的clock cycle再除以CPU的頻率(i3-2350M **2.3GHz**)

實作出來的結果,使用rdtsc()有時候得到的值會爆表 因此曲線圖會有問題

如果將那些異常的數據移除,所產生的圖為:

這邊也可以看到,在OpenMP_4的數據使用的thread數愈多,不見得使用的CPU時間會比較短。這些問題的產生,可以根據上面提到的文章[多核時代不宜再用 x86 的 RDTSC 指令測試指令周期和時間](http://blog.csdn.net/solstice/article/details/5196544) :
:::info
在多核時代,RDTSC 指令的準確度大大削弱了,原因有三:
* 不能保證同一塊主板上每個核的TSC 是同步的;
* CPU 的時鐘頻率可能變化,例如筆記本電腦的節能功能;
* 亂序執行導致RDTSC 測得的周期數不准,這個問題從Pentium Pro 時代就存在。
這些都影響了RDTSC 的兩大用途,micro-benchmarking 和計時。
RDTSC 一般的用法是,先後執行兩次,記下兩個64-bit 整數start 和end,那麼end-start 代表了這期間CPU 的時鐘週期數。
在多核下,這兩次執行可能會在兩個CPU 上發生,而這兩個CPU 的計數器的初值不一定相同(由於完成上電複位的準確時機不同)),那麼就導致micro-benchmarking 的結果包含了這個誤差,這個誤差可正可負,取決於先執行的那塊CPU 的時鐘計數器是超前還是落後。
:::
因此要解決這部份的誤差,會需要使用信賴區間來過濾這些極端值。
---
## 信賴區間
> 之後會補完 [name=JayFeng]
## 參考資料
* [作業區](https://hackmd.io/s/H1B7-hGp)
* [RDTSC -- CPU 測速](http://eucaly61.blogspot.tw/2008/02/rdtsc-cpu.html)
* [多核時代不宜再用 x86 的 RDTSC 指令測試指令周期和時間](http://blog.csdn.net/solstice/article/details/5196544)
* [Leibniz formula for π](https://en.wikipedia.org/wiki/Leibniz_formula_for_%CF%80)
* [廖健富's 詳盡分析](https://hackpad.com/Hw1-Extcompute_pi-geXUeYjdv1I)
* [Linux 的 time 指令](http://yuanfarn.blogspot.tw/2012/08/linux-time.html)
 Sign in with Wallet
Connect another wallet
Sign in with Wallet
Connect another wallet