# 2017q3 Homework2 (作業區)
## C05 : Software-pipelining
###### tags: `jserv`, `homework`
### Reviewed by `tina0405`
* 在後半段測試實驗時,只寫出搜尋速度的變化,應該在進一步討論為什麼產生這種差異,假設可能情況,再實驗證明會比較好
### 閱讀論文後的認知和提問
- 除了 Spatial and Temporal Locality 我曾在書上看過外,有一個新的名詞 `Non-temporal`,意思是資料最近被用到後,在未來的時間內不會再被用到
- SW prefetch + HW prefetch 會有 [Traning-effect](https://en.wikipedia.org/wiki/Training_effect) :依照邏輯猜測,是需要去校正兩個方法做何用的誤差所做的調整,造成效能低落
- SW prefetcher 在於短陣列及連續記憶體配置中,減少 `L1 Cache miss`會有最佳效能
- 理解[`GHB(Global History Buffer)`](http://www.ece.cmu.edu/CALCM/seminar/110105.html) : Global History Buffer 是最新的技術去實做 Prefetch Cache data 機制在現代的 CPU 上,有兩個顯著的優點
- 第一,使用 `first in first out` history buffer 可以增進**Correlation prefetching**精確度藉由排除 Table 上的 stale data.
- 第二,包含較為完整的 cache miss history 資料,根據此資料去選擇較佳的 prefetching method.
- Context prefetching or correlation prefetching 是偵測 cache miss address 和 prefetch based on privious record address 的關聯性

- 經由一個議題 `content-based pefetch` 而去找了相關資料去了解它,於是找到 [Computer Architecture
Lecture 24: Prefetching](http://www.ece.cmu.edu/~ece740/f11/lib/exe/fetch.php%3Fmedia%3Dwiki:lectures:onur-740-fall11-lecture24-prefetching-afterlecture.pdf) 的資料去闡述 `prefetch` 也對相關機制做介紹
- Prefetching useless data 浪費資源如下幾項:
- Memory bandwidth
- Cache or prefetch buffer space
- Energy consumption
- These could all be utilized by demand requests or more accurate prefetch requests
- 以下是準確度的算式:
$Prefetch\ accuracy = \dfrac{used\ prefetches}{sent\ prefetches}$
- 有同學提問 `stride` 是什麼,針對參考連結中的 `stride` 做解釋:
- [Stride of an array](https://en.wikipedia.org/wiki/Stride_of_an_array)
- To inhence preformance and we want to reduce `compulsory cache miss`. We still have `Conflict`,`Capacity cache miss`.The prefetch technology can reduce both of **Miss rate**,**Miss latency**.
- Compulsory cache miss : 第一次對 cache 存取資料時,裡面內容不曾寫過或改過,也不存在任何資料,所發生的錯誤稱之
- Capacity cache miss : 是現在的 cache 已存滿資料,但你要的資料不存在裡面,可是因為資料是滿的要去做替代方案而發生的 miss ,稱之
- Conflict cache miss : 現在的 cache 不一定是滿的狀態,但經由 MMU 的計算或分配方式讓你目前的資料對應到不對的記憶體位置,而產生的 miss ,稱之
- 為何減少 Cache miss 如此重要?以 branch 指令做解釋,經過 `Instruction fetch, Instruction decode, Excution, Memory access, Write back ` 五個週期指令,當發現抓取資料錯誤時,需要 flush 其他已經載入的指令,這樣是非常耗成本,所以抓對資料的重要性可顯而知
>The place where will prefetch work

- Prefetch 地方性問題:
- `Prefetch data in cache`:
- advantage : 簡單實作,不需把 buffer 分割
- disadvantage: 會使有用的資料被迫遷出,造成 `cache pollution`
- `Prefetch data in separate prefetch buffer`:
- advantage : no cache pollution,機制能保護不被置換
- disadvantage : more complex to design
- 何謂 [cache pollution](https://en.wikipedia.org/wiki/Cache_pollution) :
- 當你的電腦在執行程式時,載入不必要的指令進入 `Cache` 或用不到的,造成有用的資料被置換到 Lower level cache,降低效能,e.g 在 Multi-core processor 的情況下,有可能現在在運作核心,被其他 core replace 他正要用的 block from cache.
##### `Software prefetching`:
- Instruction Set Architecture[(ISA)](https://zh.wikipedia.org/wiki/%E6%8C%87%E4%BB%A4%E9%9B%86%E6%9E%B6%E6%A7%8B) 提供 prefetch instructions
- 想法:由 Programmer or Compiler 去加入 prefetch 指令到適當的位置
- 規律性的讀取內容能表現較好 e.g array-based
- 分為 Binding & Non-binding
- Binding : Prefetching 到暫存器(using a regular load)
- advantage : 不需要分割 prefetch 指令
- disadvantage :
- 有可能佔用暫存器發生 [Exception](https://en.wikipedia.org/wiki/Exception_handling)
- 若發生其他處裡器已經變更他的值會發生 data coherence
- Non-binding : Prefetching 到 cache
- advantage : 沒有 data coherence problem 因為 cache 為連續性的
- disadvantage : 對於 regular load 的指令需要以不同的方式處理,較不容易
>可是在白算盤書中有提到 Cache coherence problem 問題,不知道是否有不同點?
>> 不要把 SMP 遇到的問題 (如 cache coherence protocol) 和這邊上述議題混而一談
>> [name="jserv"][color=red]
>> >老師,這裡對這個問題作查詢後得到資料的理解清楚自己對問題點的了解不夠深入,導致混為一談
>> >- Cache coherence problem **(快取一致性的問題)** : 是多重處理器會遇到的問題,因為多重處理器經常需要將許多份相同備份的資料存放在不同的快取記憶體中,而每一個處理器都可以對此備份做存取
>> >- Cache coherence protocol **(快取一致性協定)** : 用來維持多重處理器的資料一致性,有兩種方法
>> >- 一是 Snooping
>> >- 二是 Directory based
>> >[name="williamchangTW"][color=blue]
- x86架構下的 prefetch instruction
| Opcode | Instruction | 64-Bit Mode | Compat/Leg Mode | Description |
|:-----------:|:--------:|:-------:|:---:|:----:|
| 0F 18/1 | PREFETCHT0 m8 | Valid| Valid | Move data from m8 closer to the processor using T0 hint.|
| 0F 18/2 | PREFETCH1 m8 | Valid | Valid | Move data from m8 closer to the processor using T1 hint.|
| 0F 18/3 | PREFETCH2 m8 | Valid | Valid | Move data from m8 closer to the processor using T2 hint. |
| 0F 18/0 | PREFETCHNTA m8 | Valid | Valid | Move data from m8 closer to the processor using NTA hint. |
> 改用 HackMD 的表格重新排版
> [name="jserv"][color=red]
> > 已改進,謝謝
> > [name="williamchangTW"][color=blue]
- 依照上面的圖有些不懂,於是去找相關資料如[x86 Instruction Set Reference-PREFETCHh prefetch data into cache](http://x86.renejeschke.de/html/file_module_x86_id_252.html)
- T0(temporal data) : prefetch 資料到所有的 cache level
- T1(temporal data with respect to first level cache) : prefetch 資料到所有的 cache level,除了 0th cache level
- T2(temporal data with respect to second level cache) : prefetch 資料到所有的 cache level,除了 0th and 1st cache level
- NTA(non-temporal data with respect to all cache levels) : prefetch 資料到 Non-temporal cache 結構下(這意味著可以把 cache pollution 降到最低)
- Compiler 如何決定 prefetch 指令放在那?
- 若在每個 load 讀取
- 太過於密集的使用 bandwidth (both memory and excution bandwidth)
- 去定義或規範指令有可能會 miss 的指令
- 有可能會無法辨識輸入指令
---
---
##### `Hardware prefetching`:
- 由 HW monitor processor access
- 自動生成 prefetch address
- memorizes or finds patterns or strides
- 想法 :藉由使用特定目的的硬體去觀察 load / store 之前的習慣去 prefetch
- 優點:
- 可轉由系統實現
- 沒有 code probability issue
- 沒有浪費多餘的空間在執行的時候跟 SW prefetch compare
- 缺點:
- 硬體方面的設計較為複雜
- 方法一:Next-line Prefetcher
- 解釋:對硬體來說相當簡單,總是當需求讀取產生後,prefetch N 個 cache line給它
- 優點:
- 簡單實作,不須偵測複雜的資料
- 在 Sequential/Streaming 存取資料時,運作非常好
- 缺點:
- 若有不規則的情況發生可能會浪費空間
- 若程式發生 traversing memory from higher to lower addresses,可能無法正確的執行,因為只抓取前幾個 cache line
- 方法二:Stride Prefetcher
- 解釋:有兩種方式
- 基於 Instruction program counter
- 基於 Cache block address
- Instruction programe counter
- 想法:
- 紀錄最近被 load instruction 的記憶體位置以及上一個記憶體位置的距離
- 預想下一次會已相同距離被 fetch,prefetch last address + stride
> Load Inst PC
>
| Load Inst | Worst-case running time | Last | Confidence |
|:-----------:|:--------:|:-------:|:---:|
| PC(tag) | Referenced | Stride| |
| ... | ... | ... |
| ... | ... | ... |
- 有個問題存在於此方法中
- 要設定多遠的距離 prefetch,又能掩蓋多少 miss latency ?
- 有可能在會太晚 prefetch 因為馬上又要或是已經抓取指令了
- 解決方式:
- 使用 lookahead
-The other prefetcher performance formula:
$Coverage = \dfrac{prefetch\ misses}{all\ miss}$
$Timeliness = \dfrac{on-time\ prefetches}{used\ prefetches}$
- Coverage 若數字太大的話,是非常不好的,數字小的話效能較好
- all miss = 100 instruction percycle
- prefetch misses = 10
---
---
##### `Excution-baesd`prefetchers:
- 用 [Thread](https://en.wikipedia.org/wiki/Thread_(computing)) 去執行 prefetch
- Prefetch 時間性問題:
- 太早:造成預先取入的資料沒有用到而被置換出去
- 太晚:有可能無法隱藏 Memory latency
~~~
#Direct indexing pattern
LEA &a[i], R0
PREFETCH R0
#Indirect indexing pattern
LEA &b[i], R0
MOV R1, R0
LEA &a[0]+R1, R2
PREFETCH R@
~~~
>上述組合語言對 SW prefetcher 的影響,Direct more two instruction than Indirect
#### conclusion of reference
>依照文中所得的資料可得出
>- 處理 **常規性存取**,e.g streams,HW prefetcher 會太過於浪費,使用 SW prefetch 會比較有效率
>- Prefetch distance 只要夠大,效能就會比較好
>- SW prefetching 可以用來訓練 HW prefetcher 因此能夠獲得效能上的提升,在某些情況下會下降
>
---
### Software-pipelining 詳讀
##### Reference : [Software pipelining](https://hackmd.io/s/S1fZ1m6pe#) 中的資料
- 在開頭提到的參考資料:[CPU 結構與工作原理](https://hackmd.io/s/S1fZ1m6pe#)由這個連結下知道兩個週期是之前沒學過的:
- 當每處裡一個機械語言指令時,資料會傳送或來自記憶體或輸入/輸出單元,每一次傳送或接收的動作稱之為 **Machine cycle**,可以分為兩部份
- 指令週期(Instruction cycle, I-cycle)
- 執行週期(Execution cycle, E-cycle)
- 指令週期:
- Step 1 : Control Unit 從主記憶體中提取下一個所要執行的指令
- Step 2 : Control Unit 從指令予以解碼
- Step 3 : Control Unit 將指令中說明執行什麼動作的這一部份,存入 Instruction register
- Step 4 : Control Unit 將指令中說明相關資料所儲存之位置這一部份,存入 address register
- 執行週期:
- Step 1 : Control Unit 根據 address register 內的資訊,從 main memory 中讀取所需的資料,並將其存入 ALU 的儲存器內
- Step 2 : Control Unit 根據 Instruction register 的資訊,命令 ALU 去執行運算
- Step 3 : ALU 執行運算,將儲存暫存器以及累加器內的數值相加
- Step 4 : 運算結果再存回累加器內,這個動作會清除累加器原先所儲存的數值
>這裡對 Machine cycle & Instruction cycle 定義不是很清楚,所以去找了這篇 [What is clock cycle, machine cycle, and instruction cycle in a microprocessor?](https://www.quora.com/What-is-clock-cycle-machine-cycle-and-instruction-cycle-in-a-microprocessor) 以下做出解釋
- Clock cycle
- 是攸關**電腦的處理速度**或是說 **CPU 的處理速度**的定義,是包含振盪器的兩個震盪波之間的時間差。Clock speed 測量單位是 Hz,通常為 megahertz (MHz) 或 gigahertz (GHz)。舉例來說, 一個 4GHz processor 處理 4,000,000,000 clock cycles 每秒。電腦處裡器可以執行一或多個指令在每一個 clock cycle,要依據不同處裡器有不同的作法。較早期的電腦處裡器或較慢的處裡器只執行一個指令在每個 clock cycle,但在較快的處裡器中,更多進階的處裡器可以在每個 clock cycle 執行多個指令在處裡資料更有效率些
- Machine cycle :
- 是**一連串的執行步驟**由電腦處裡器根據擷取出來機器語言,有四個步驟如下
- Four steps of Machine cycle :
- `Step 1` 擷取(Fetch) - 從記憶體中取出指令
- `Step 2` 解碼(Decode) - 解譯指令看是那一系列的機器指令
- `Step 3` 執行(Execute) - 執行機器指令
- `Step 4` 儲存(Store) - 結果回寫回記憶體

- Instruction cycle :
- CPU 經由**循序性的運作**後輸出運算後的值
- Step 1 : 讀取指令
- Step 2 : 指令解碼
- Step 3 : 找出運算元的位址
- Step 4 : 取出運算元
- Step 5 : 做出需求要的運算
- Step 6 : 找出目的位址
- Step 7 : 把運算結果儲存到目標位址

- 文中參考資料 : [perf stat 輸出解讀](https://zhengheng.me/2015/11/12/perf-stat/) 歸納及整理
- `context-switches` 及`cpu-migrations` 之間的差異,發生 `cpu-migration` 一定會發生 `context-switches` 可是反向不一定成立,有可能還是在同一個 CPU 上執行,只是被置換出等待在執行的時間點在抓取進來執行

- 再來是與我們關注的議題有關,首先了解 CPU 的 cache structure

- 解釋如下:
- `L1 D-cache`: Level-1 資料快取記憶體
- `L1 I-cache`: Level-1 指令快取記憶體
- `MMU(Memory Management Unit)`: 記憶體管理單位元
- `TLB(Translation Lookaside Buffer)`: 轉譯後備緩衝區(個人偏好:`索引快取`較能表達其用處)
- `L2 cache`: Level-2 快取記憶體
- `L3 cache`: Level-3 快取記憶體
流程圖如下:

>數字越大代表越下層,也越大越便宜,詳情見:[Wikipedia-Memory hierarchy](https://en.wikipedia.org/wiki/Memory_hierarchy)
- 文中參考資料: [Cache 基本原理之:結構—簡書](http://www.jianshu.com/p/2b51b981fcaf) 歸納及整理
- 因為連結中有更詳細的介紹,所以我簡短的介紹 **(Associativity)關聯性** 的介紹,有有興趣想更深入了解可以參考連結:
- 資料在 Main memory 以及 cache 之間以 Block 的單位做傳遞,每塊大小可能為4 , 8 , 16 Bytes或其他值,**x86 cache line** 大部分為 64 bytes
- `Cache line` 包含**數據,TAG (地址訊息)以及狀態訊息**
- direct map:
- Main memory 每個資料只對應到一塊 `cache line`,硬體資源非常有限
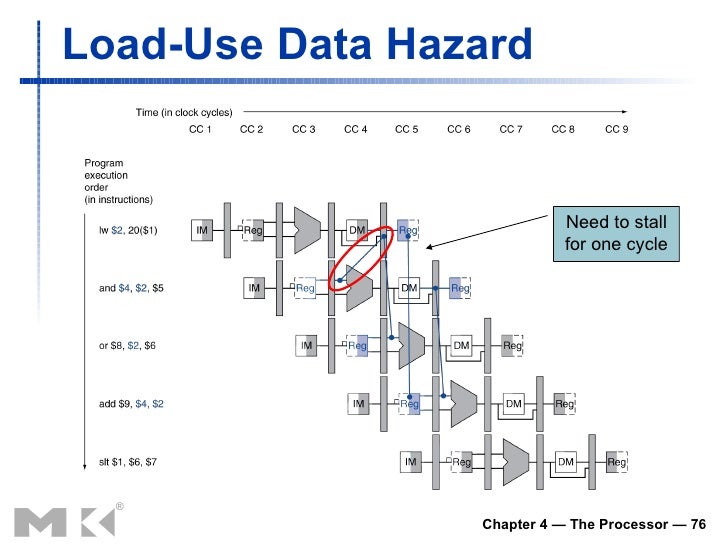
- 好處是:能在介於 200~300 MHz CPU下, load-use latancy 可以只需要一個 cycle
>1 KHz = 10^3^Hz
>1 MHz = 10^6^Hz
>so , $200\sim 300MHz = 200000000Hz\sim 3000000000Hz$
>意謂著:200,000,000 ~ 300,000,000 clock cycle per second
>這裡實證上面的理論,兩個處裡器只差在時脈下作比較:
>- [Intel® Celeron® 處理器 600 MHz,128K 快取記憶體,66 MHz 前端匯流排](https://ark.intel.com/zh-tw/products/27191/Intel-Celeron-Processor-600-MHz-128K-Cache-66-MHz-FSB)
>- [Intel® Celeron® Processor 300 MHz, 128K Cache, 66 MHz FSB](https://ark.intel.com/products/27183/Intel-Celeron-Processor-300-MHz-128K-Cache-66-MHz-FSB)
>證明:
>想先證明時脈越高,stall cycle increased
>考慮以下公式:
>$Memory\ stall\ cycle = Memory\ accesses\times\ Miss\ rate\times Miss\ penalty$
>$Execute\ time\ per\ instruction = Instruction\div clock\ rate$
>- clock rate = 300MHz:
>>-- $Execute\ time\ per\ instruction = (\frac{1} {3\times10^8}) = 3.\bar3 \times 10^{-9} = 3.\bar3 ns$
>- clock rate = 600MHz:
>>-- $Execute\ time\ per\ instruction = (\frac{1}{6\times 10^8})=1.\bar6\times10^{-9} = 1.\bar6ns$
>
>Execute time per instruction 相差兩倍,再套用第一個公式
>assume Miss rate & Miss penalty are same
>and then we already know `Execute time per instruction` two times between 300MHz and 600MHz
>so , we assume Memory accesses = N for 300MHz
>驗算如下:
>- 300MHz:
>$memory\ stall\ cycle = N$
>- 600MHz:
>$memory\ stall\ cycle = 2N$
>明顯地知道 clock rate 越大,Stall cycle increased
- N way Set-Associative:
-
- Fully-Associative:
-
---
### Compile and Excution Prefetcher
### 開發環境
~~~
Architecture: i686
CPU 作業模式: 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 4
On-line CPU(s) list: 0-3
每核心執行緒數:2
每通訊端核心數:2
Socket(s): 1
供應商識別號: GenuineIntel
CPU 家族: 6
型號: 37
Model name: Intel(R) Core(TM) i5 CPU 650 @ 3.20GHz
製程: 5
CPU MHz: 1200.000
CPU max MHz: 3201.0000
CPU min MHz: 1200.0000
BogoMIPS: 6383.71
虛擬: VT-x
L1d 快取: 32K
L1i 快取: 32K
L2 快取: 256K
L3 快取: 4096K
~~~
- 這是在終端機執行程式`naive_transpose`, `sse_transpose`, `sse_prefetch_transpose` 之間的差異
- `naive_transpose = naive`
- `sse_transpose = sse`
- `sse_prefetch_transpose = sse prefetch`
>看得出來 `sse_prefetch_transpose` 的搜尋速度較快與 `sse_transpose` 差別近兩倍`navie_transpose`差別近三倍[color=orange]
~~~
0 1 2 3
4 5 6 7
8 9 10 11
12 13 14 15
0 4 8 12
1 5 9 13
2 6 10 14
3 7 11 15
sse prefetch: 79762 us
sse: 147761 us
naive: 277587 us
~~~
- 針對程式碼做初步解釋
---
### Inhance performance by method AVX
---
## 作業要求
* 閱讀論文 "[When Prefetching Works, When It Doesn’t, and Why](http://www.cc.gatech.edu/~hyesoon/lee_taco12.pdf)" (務必事先閱讀論文,否則貿然看程式碼,只是陷入一片茫然!),紀錄你的認知和提問
* [論文重點提示和解說](https://hackmd.io/s/HJtfT3icx)
* 詳細閱讀 [software pipelining](https://hackmd.io/s/S1fZ1m6pe) 共筆以及裡頭對應的==錄影==
* 在 Linux/x86_64 (注意,要用 64-bit 系統,不能透過虛擬機器執行) 上編譯並執行 [prefetcher](https://github.com/sysprog21/prefetcher)
* 說明 `naive_transpose`, `sse_transpose`, `sse_prefetch_transpose` 之間的效能差異,以及 prefetcher 對 cache 的影響
* 在 github 上 fork [prefetcher](https://github.com/sysprog21/prefetcher),參照下方「見賢思齊:共筆選讀」的實驗,嘗試用 AVX 進一步提昇效能。分析的方法可參見 [Matrix Multiplication using SIMD](https://hackmd.io/s/Hk-llHEyx)
* 修改 `Makefile`,產生新的執行檔,分別對應於 `naive_transpose`, `sse_transpose`, `sse_prefetch_transpose` (學習 [phonebook](s/S1RVdgza) 的做法),學習 [你所不知道的 C 語言:物件導向程式設計篇](https://hackmd.io/s/HJLyQaQMl) 提到的封裝技巧,以物件導向的方式封裝轉置矩陣的不同實作,得以透過一致的介面 (interface) 存取個別方法並且評估效能
* 用 perf 分析 cache miss/hit
* 學習 `perf stat` 的 raw counter 命令
* 參考 [Performance of SSE and AVX Instruction Sets](http://arxiv.org/pdf/1211.0820.pdf),用 SSE/AVX intrinsic 來改寫程式碼
* 將原本 8x8 矩陣推廣到更大的範圍,如 16x16, 32x32, 64x64 等等,並透過實際的實驗來驗證前述推論
* 在 [Homework2 作業區](https://hackmd.io/s/HkVvxOD2-) 詳細描述實驗設計、閱讀論文的心得和疑惑,以及你的觀察
 Sign in with Wallet
Connect another wallet
Sign in with Wallet
Connect another wallet