<style>
div.ui-view-area{
background-color: black;
color: white;
}
h1.part {color: yellow;}
h2.part {color: yellow;}
h3.part {color: yellow;}
h4.part {color: yellow;}
h5.part {color: yellow;}
h6.part {color: yellow;}
.shell{
color: red;
font-size:125%
}
.dollar{
color: cyan;
font-size:125%
}
</style>
# 2016q3 Homework1 (phonebook)
contributed by <`Jim00000`>
## 作業說明
* [成大wiki](http://wiki.csie.ncku.edu.tw/sysprog/schedule)
* [A01: phonebook](https://hackmd.io/s/S1RVdgza)
## 設定目標
- [x] 學習Linux效能分析工具Perf
- [x] 學習Git與GitHub
- [x] 學習gnuplot
- [x] 研究軟體最佳化
- [ ] 挑戰題:fuzzy search
## 開發環境
ubuntu 16.04 LTS
~~<font style="color:green" >拜拜lubuntu,哈囉ubuntu</font>~~
<font class="dollar">$ </font><font class="shell" >lscpu</font>
```
Architecture: x86_64
CPU 作業模式: 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 8
On-line CPU(s) list: 0-7
每核心執行緒數:2
每通訊端核心數:4
Socket(s): 1
NUMA 節點: 1
供應商識別號: GenuineIntel
CPU 家族: 6
型號: 58
Model name: Intel(R) Core(TM) i7-3630QM CPU @ 2.40GHz
CPU MHz: 1263.750
CPU max MHz: 3400.0000
CPU min MHz: 1200.0000
BogoMIPS: 4789.11
虛擬: VT-x
L1d 快取: 32K
L1i 快取: 32K
L2 快取: 256K
L3 快取: 6144K
NUMA node0 CPU(s): 0-7
```
## Linux效能分析工具Perf
* [Linux 效能分析工具 : Perf](http://wiki.csie.ncku.edu.tw/embedded/perf-tutorial)
### 使用Perf前先打開權限
```
sudo sh -c " echo -1 > /proc/sys/kernel/perf_event_paranoid"
sudo sh -c " echo 0 > /proc/sys/kernel/kptr_restrict"
```
### Perf的用法
<font class="dollar">$</font> <font class="shell"> perf list </font>
節錄部份perf可以觸發的events
```
branch-instructions OR branches [Hardware event]
branch-misses [Hardware event]
cache-misses [Hardware event]
cache-references [Hardware event]
cpu-cycles OR cycles [Hardware event]
instructions [Hardware event]
ref-cycles [Hardware event]
context-switches OR cs [Software event]
cpu-clock [Software event]
dummy [Software event]
page-faults OR faults [Software event]
task-clock [Software event]
L1-dcache-load-misses [Hardware cache event]
L1-dcache-loads [Hardware cache event]
L1-dcache-prefetch-misses [Hardware cache event]
L1-dcache-store-misses [Hardware cache event]
L1-dcache-stores [Hardware cache event]
L1-icache-load-misses [Hardware cache event]
branch-load-misses [Hardware cache event]
branch-loads [Hardware cache event]
branch-instructions OR cpu/branch-instructions/ [Kernel PMU event]
branch-misses OR cpu/branch-misses/ [Kernel PMU event]
bus-cycles OR cpu/bus-cycles/ [Kernel PMU event]
cache-misses OR cpu/cache-misses/ [Kernel PMU event]
cache-references OR cpu/cache-references/ [Kernel PMU event]
cpu-cycles OR cpu/cpu-cycles/ [Kernel PMU event]
```
<font class="dollar">$</font><font class="shell" > perf top </font>
即時分析系統熱點
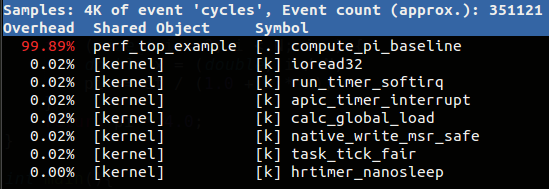
<font class="dollar">$</font><font class="shell" > perf top -p $pid </font>
根據pid 查看process的熱點
<font class="dollar">$</font><font class="shell" > perf top --event `event` --count `event period to sample` </font>
* event => 查看的事件
* count n => 取樣頻率
### perf stat
針對特定程式檢查事件
<font class="dollar">$</font><font class="shell" > perf stat --repeat 5 -e cache-misses,cache-references,instructions,cycles ./a.out</font>
* repeat n => 重複執行n次
* event => 查看的事件
### 其他補充
<font class="dollar">$</font><font class="shell" > perf stat --repeat 5 -e cache-misses:u,cache-references:u,instructions:u,cycles:u ./a.out</font>
:u 代表只統計發生在user space的事件
<font class="dollar">$ </font><font class="shell" >./a.out & sudo perf top -p $!</font>
針對a.out的程式做效能分析
## Git與GitHub
在[Learn Git Branching](http://learngitbranching.js.org/)這個網站多做幾次就大致理解如何使用git了
### 重點摘要
* <font class="dollar">$ </font><font class="shell" >git branch bugFix</font>
* 開個新分支bugFix
* <font class="dollar">$ </font><font class="shell" >git checkout bugFix</font>
* 將目前的branch轉換到bugFix
* <font class="dollar">$ </font><font class="shell" >git merge bugFix</font>
* 假設目前分支在master
* merge bugFix 到 master
* <font class="dollar">$ </font><font class="shell" >git rebase master</font>
* 
* 
* <font class="dollar">$ </font><font class="shell" >git reset --force HEAD^</font>
* 切回上一個版本
* <font class="dollar">$ </font><font class="shell" >git clean -d -fx</font>
* http://stackoverflow.com/questions/4858047/the-following-untracked-working-tree-files-would-be-overwritten-by-checkout
* <font class="dollar">$ </font><font class="shell" >git commit --amend</font>
* http://stackoverflow.com/questions/179123/how-to-modify-existing-unpushed-commits
## gnuplot
* [使用gnuplot科学作图(.pdf)](http://www.phy.fju.edu.tw/~ph116j/gnuplot_tutorial.pdf)
* [gnuplot 5.0 demo](http://gnuplot.sourceforge.net/demo_5.0/)
* [GNUPLOT使用手册](http://dsec.pku.edu.cn/dsectest/dsec_cn/gnuplot/index.html)
### 範例:台北年度雨量長條圖
[台北地區各氣象站月平均降雨量統計表](http://www.ntpc.gov.tw/ch/home.jsp?id=1358)
```
#測站 | 淡水 | 鞍部 | 臺北 | 基隆 | 竹子湖 |
#月份
1 103.9 294.3 83.2 331.6 232.6
2 174.8 329.2 170.3 397.0 273.5
3 194.5 281.8 180.4 321.0 227.1
4 179.3 247.9 177.8 242.0 207.2
5 216.1 321.2 234.5 285.1 267.4
6 243.4 345.8 325.9 301.6 314.8
7 149.2 266.1 245.1 148.4 247.7
8 202.9 422.5 322.1 210.1 439.5
9 299.1 758.5 360.5 423.5 717.4
10 173.9 703.5 148.9 400.3 683.9
11 120.7 534.7 83.1 399.6 488.8
12 97.6 357.6 73.3 311.8 289.1
```
```
set title "臺北月平均降雨量"
set xlabel "月份"
set ylabel "降雨量(毫米)"
set terminal png font " Times_New_Roman,12 "
set output "statistic.png"
set xtics 1 ,1 ,12
set key left
plot \
"data.csv" using 1:2 with linespoints linewidth 2 title "淡水", \
"data.csv" using 1:3 with linespoints linewidth 2 title "鞍部", \
"data.csv" using 1:4 with linespoints linewidth 2 title "臺北", \
"data.csv" using 1:5 with linespoints linewidth 2 title "基隆", \
"data.csv" using 1:6 with linespoints linewidth 2 title "竹子湖" \
```

## astyle
multi-language indentation and reformatting filters
http://astyle.sourceforge.net/astyle.html
## 案例分析與探討:原始程式
### githook
使用astyle檢查程式排版
```
ln -sf ../../scripts/pre-commit.hook .git/hooks/pre-commit
```
### 瀏覽原始碼學習新東西
#### Makefile
* `echo 3 | sudo tee /proc/sys/vm/drop_caches`
* <font class="dollar">$ </font><font class="shell" >`man tee`</font>
* tee - 從標準輸入寫往檔案和標準輸出
* `watch -d -t "./phonebook_orig && echo 3 | sudo tee /proc/sys/vm/drop_caches"`
* <font class="dollar">$ </font><font class="shell" >`man watch`</font>
* execute a program periodically, showing output fullscreen
* <font class="shell" >`-d`</font>
* Highlight the differences between successive updates
* <font class="shell" >`-t`</font>
* Turn off the header showing the interval, command, and current time at the top of the display, as well as the following blank line
* `.PHONY`
* https://www.gnu.org/software/make/manual/html_node/Phony-Targets.html
* A phony target is one that is not really the name of a file; rather it is just a name for a recipe to be executed when you make an explicit request.
#### main.c
* `#include <assert.h>`
* <font class="dollar">$ </font><font class="shell" >`man assert`</font>
* `void assert(scalar expression);`
* abort the program if assertion is false
* `#if defined(__GNUC__)`
* http://stackoverflow.com/questions/19908922/what-is-this-ifdef-gnuc-about
* It indicates I'm a GNU compiler and you can use GNU extensions
* https://gcc.gnu.org/onlinedocs/gcc/C-Extensions.html
* 察看所有GNU C Extension的功能與用法
* `__builtin___clear_cache((char *) pHead, (char *) pHead + sizeof(entry));`
* https://gcc.gnu.org/onlinedocs/gcc/Other-Builtins.html#Other-Builtins
* `void __builtin___clear_cache (char *begin, char *end)`
* This function is used to flush the processor's instruction cache for the region of memory between begin inclusive and end exclusive. Some targets require that the instruction cache be flushed, after modifying memory containing code, in order to obtain deterministic behavior. If the target does not require instruction cache flushes, __builtin___clear_cache has no effect. Otherwise either instructions are emitted in-line to clear the instruction cache or a call to the __clear_cache function in libgcc is made.
### 程式碼的缺失
1. linklist的memory沒有完全free掉
2. 部份程式碼缺少檢查
### 原始Phonebook版本核心程式碼
原始Phonebook版本使用Linklist串接每一筆資料
```clike=
entry *findName(char lastName[], entry *pHead)
while (pHead != NULL) {
if (strcasecmp(lastName, pHead->lastName) == 0)
return pHead;
pHead = pHead->pNext;
}
return NULL;
}
entry *append(char lastName[], entry *e)
{
/* allocate memory for the new entry and put lastName */
e->pNext = (entry *) malloc(sizeof(entry));
e = e->pNext;
strcpy(e->lastName, lastName);
e->pNext = NULL;
return e;
}
```
* findName
* 使用`strcasecmp`比較字串
* http://man7.org/linux/man-pages/man3/strcasecmp.3.html
* The strcasecmp() function performs a byte-by-byte comparison of the strings s1 and s2, ignoring the case of the characters.
### 檢查熱點與效能
<font class="dollar">$ </font><font class="shell" >`perf stat --repeat 100 -e cache-misses:u,cache-references:u,instructions:u,cycles:u ./phonebook_orig`</font>
```
Performance counter stats for './phonebook_orig' (100 runs):
1,543,383 cache-misses:u # 97.442 % of all cache refs ( +- 0.17% )
1,583,900 cache-references:u ( +- 0.18% )
290,557,320 instructions:u # 1.67 insns per cycle ( +- 0.02% )
173,701,898 cycles:u ( +- 0.40% )
0.095503279 seconds time elapsed ( +- 1.44% )
```
<font class="dollar">$ </font><font class="shell" >`./phonebook_orig & perf top -p $!`</font>
```
Overhead Shared Object Symbol
22.78% libc-2.23.so [.] __strcasecmp_l_avx
17.41% phonebook_orig [.] findName
9.29% phonebook_orig [.] main
6.70% libc-2.23.so [.] _int_malloc
4.95% libc-2.23.so [.] _IO_fgets
3.86% [kernel] [k] clear_page_c_e
3.27% libc-2.23.so [.] __memcpy_sse2
2.96% libc-2.23.so [.] malloc
2.81% libc-2.23.so [.] _IO_getline_info
2.69% phonebook_orig [.] strcasecmp@plt
2.29% [kernel] [k] free_pcppages_bulk
1.93% phonebook_orig [.] append
1.87% libc-2.23.so [.] __strcpy_sse2_unaligned
1.72% [kernel] [k] page_remove_rmap
1.64% libc-2.23.so [.] __strcasecmp_avx
1.52% libc-2.23.so [.] memchr
1.14% [kernel] [k] release_pages
1.03% [kernel] [k] native_irq_return_iret
0.98% [kernel] [k] down_read_trylock
0.91% [kernel] [k] __rmqueue.isra.79
0.57% [kernel] [k] free_hot_cold_page_list
0.57% [kernel] [k] free_hot_cold_page
0.57% [kernel] [k] free_pages_prepare
0.57% [kernel] [k] unmap_page_range
0.57% [kernel] [k] __mod_zone_page_state
0.52% [kernel] [k] __schedule
0.52% [kernel] [k] copy_user_enhanced_fast_string
0.51% [kernel] [k] apic_timer_interrupt
```
## 案例分析與探討:改善程式
### 改善目標
- [x] 縮小`struct __PHONE_BOOK_ENTRY`
- [x] 使用hash
- [x] 使用二元樹
### 縮小`struct __PHONE_BOOK_ENTRY`
* 從perf中看到cache-misses比率太高了
* http://ece-research.unm.edu/jimp/611/slides/chap5_2.html
* http://ece-research.unm.edu/jimp/611/slides/chap5_3.html
* 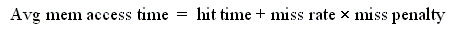
* 作業提示改寫`struct __PHONE_BOOK_ENTRY`改善cache-misses
* http://stackoverflow.com/questions/8377667/layout-in-memory-of-a-struct-struct-of-arrays-and-array-of-structs-in-c-c
* SoA (Struct of Arrays) vs AoS (Array of Structs)
* 改善cache-misses可以改善memory access time
將`struct __PHONE_BOOK_CONTENT`內不必要的資訊搬移至別處,減小空間(縮小到24bytes)
```clike=
typedef struct __PHONE_BOOK_ENTRY entry;
typedef struct __PHONE_BOOK_CONTENT Content;
struct __PHONE_BOOK_ENTRY {
char *lastName;
entry *pNext;
Content *pContent;
};
struct __PHONE_BOOK_CONTENT {
char firstName[16];
char email[16];
char phone[10];
char cell[10];
char addr1[16];
char addr2[16];
char city[16];
char state[2];
char zip[5];
};
```
cache-misses縮小了,這是合理的,因為cache可以放入更多的資料組進去
```
Performance counter stats for './phonebook_opt' (100 runs):
89,853 cache-misses:u # 33.448 % of all cache refs ( +- 4.40% )
268,634 cache-references:u ( +- 3.05% )
400,792,662 instructions:u # 2.18 insns per cycle ( +- 0.02% )
184,158,414 cycles:u ( +- 0.38% )
0.087245876 seconds time elapsed ( +- 2.01% )
```

有變動的地方為`struct __PHONE_BOOK_CONTENT`大小以及`append()`的實作
可以從效能比較圖中看到`finName()`的時間縮減了,但是在`append()`的時間增加了
`finName()`的效能增益來自於cache miss的減少,而`append()`的時間增加了可能是多了一次`malloc()`的使用
#### 另外一個版本
如果將lastname改成固定為16bytes
```clike=
struct __PHONE_BOOK_ENTRY {
char lastName[MAX_LAST_NAME_SIZE];
entry *pNext;
Content *pContent;
};
```

跟第一個版本相比,這個版本的`append()`的時間會比上一版還要短,是因為少了`malloc()`的使用
,不過在稍稍浪費了少量的記憶體(在多筆資料下浪費的量會非常可觀!!!)
結論:cache miss的減少確實影響著程式的效能
### 使用hash
從perf效能工具的圖表,overhead第1名是`__strcasecmp_l_avx`,程式花了很多cycles在`strcasecmp()`上面
使用hash來取代`strcasecmp()`或許是個很好的作法
我將比較[http://www.cse.yorku.ca/~oz/hash.html](http://www.cse.yorku.ca/~oz/hash.html)內的各種hash function,找出哪一個hash function比較有效率
* djb2
* 運算時間最長
* sdbm
* 運算時間介於`djb2`與`loselose`兩者之間
* ~~loselose~~
* 運算時間最少且簡單,但容易發生碰撞
* 例如:"12345"與"54321"會有相同的hash值
* 不適合用來作hash
```
djb2 0.000000705 seconds
sdbm 0.000000404 seconds
loselose 0.000000381 seconds
```
hash function將採用`sdbm`演算法實作
:::info
hash function的比較目前只有思考時間的部份,可能還不夠全面
:::
#### 以`hash`替換`lastName`
以hash換掉lastName
```clike=
struct __PHONE_BOOK_ENTRY {
unsigned long hash;
entry *pNext;
Content *pContent;
};
```
將`findName()`內的字串比較換成為比較`hash`,`hash`必須在使用`findName()`之前算出來,避免重複計算`hash`
```clike=
entry *findName(unsigned long hash, entry *pHead)
{
while (pHead != NULL) {
if (pHead->hash == hash )
return pHead;
pHead = pHead->pNext;
}
return NULL;
}
```
`struct __PHONE_BOOK_ENTRY`大小沒有變,cache-misses的比率沒有太大的變化
```
Performance counter stats for './phonebook_opt' (100 runs):
50,211 cache-misses:u # 35.883 % of all cache refs ( +- 3.40% )
139,928 cache-references:u ( +- 2.73% )
278,444,297 instructions:u # 1.97 insns per cycle ( +- 0.00% )
141,480,873 cycles:u ( +- 0.31% )
0.061914541 seconds time elapsed ( +- 2.13% )
```
程式的熱點依舊花在`findName`上很多時間,很多都花在遍歷linklist了
```
19.24% phonebook_opt [.] findName
12.64% phonebook_opt [.] sdbm
11.11% libc-2.23.so [.] _int_free
10.50% phonebook_opt [.] main
7.63% phonebook_opt [.] free_entry
4.81% libc-2.23.so [.] __memcpy_sse2
4.17% phonebook_opt [.] free_Content
3.80% libc-2.23.so [.] malloc
3.74% libc-2.23.so [.] _IO_fgets
3.17% libc-2.23.so [.] _IO_getline_info
2.99% phonebook_opt [.] append
2.78% libc-2.23.so [.] free
2.43% libc-2.23.so [.] _int_malloc
2.33% libc-2.23.so [.] memchr
1.25% [kernel] [k] copy_user_enhanced_fast_string
0.71% [kernel] [k] uncharge_list
0.70% [kernel] [k] release_pages
0.70% [kernel] [k] __tlb_remove_page
0.69% [kernel] [k] __khugepaged_exit
0.69% phonebook_opt [.] free@plt
0.69% ld-2.23.so [.] do_lookup_x
```
`append()`看不出來有明顯的變化,但是`findName()`的時間有稍微降低

結論:使用hash代替`strcasecmp`做比較可以減少一些時間,但是程式需要遍歷整個linklist直到找到字串為止的方法依然不變,需要想辦法減少遍歷整個linklist
#### 使用雜湊表
* https://zh.wikipedia.org/wiki/%E5%93%88%E5%B8%8C%E8%A1%A8
* 比起[線性搜尋法(Linear Search)](http://notepad.yehyeh.net/Content/Algorithm/Search/LinearSearch/LinearSearch.php)來得有效率
* 設定buckets
* 如何讓資料平均散佈整個buckets
合理使用雜湊表,減少遍歷整個linklist的可能性
:::info
因為原始版與優化版差異性變大,在這裡我將會對其做分檔處理以方便區分及理解程式碼
:::
建立一個hash table,內含固定數量的buckets,每個buckets內含一條串列(請想像成`linklist[buckets_num]`)
```clike=
struct __PHONE_BOOK_HASH_TABLE {
unsigned int buckets_num;
entry **buckets;
};
```
從結果來看cache-misses有點高
```
Performance counter stats for './phonebook_opt' (100 runs):
87,790 cache-misses:u # 66.771 % of all cache refs ( +- 1.91% )
131,478 cache-references:u ( +- 2.13% )
275,992,495 instructions:u # 2.12 insns per cycle ( +- 0.00% )
130,270,449 cycles:u ( +- 0.24% )
0.060449365 seconds time elapsed ( +- 2.17% )
```
程式熱點從`findName()`轉移至`main()`與`sdbm()`為主了
```
24.60% phonebook_opt [.] main
16.55% phonebook_opt [.] sdbm
14.34% libc-2.23.so [.] _int_malloc
8.75% phonebook_opt [.] append
8.59% libc-2.23.so [.] _IO_fgets
5.18% libc-2.23.so [.] __memcpy_sse2
3.39% libc-2.23.so [.] malloc
3.19% [kernel] [k] clear_page_c_e
2.34% [kernel] [k] free_pcppages_bulk
2.27% libc-2.23.so [.] _IO_getline_info
2.22% [kernel] [k] native_irq_return_iret
1.17% [kernel] [k] unmap_page_range
1.17% [kernel] [k] __pagevec_lru_add_fn
1.13% [kernel] [k] copy_user_enhanced_fast_string
1.11% [kernel] [k] __rmqueue.isra.79
1.11% [kernel] [k] _raw_spin_lock
0.99% [kernel] [k] release_pages
0.96% [kernel] [k] get_mem_cgroup_from_mm
0.93% [kernel] [k] handle_mm_fault
0.01% [kernel] [k] perf_pmu_enable.part.89
0.00% [kernel] [k] native_sched_clock
0.00% [kernel] [k] native_write_msr_safe
```
`append()`因為多了算hash以及一些搬移,時間會比原始來得多一點是可以預期的,`findName()`的時間降至接近於0了

結論:使用hash table讓資料分散在不同buckets,然後在`findName()`時藉由字串算出的hash找到bucket後就不用找其他bucket內的資料,在`findName()`的效能提升是明顯的
### 使用二元搜尋樹
* 在實作hash table(Key對應到Object)中每個Object都是一條Linklist,所以仍然無法避免遍歷這一條linklist如果資料比較靠近list尾端,在最差的情況下還是得從頭比對到最後
* 使用binary search tree取代linklist,增加搜尋的效率
* binary search tree的搜索複雜度為$O(log_{n})$,而在最差的情況下(例如:傾斜樹)複雜度為$O(n)$~~其實就是linklist嘛~~
* 使用紅黑樹避免二元樹傾斜
* https://www.cs.usfca.edu/~galles/visualization/RedBlack.html
* https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
* 這個網站提供資料結構視覺化,方便觀看整個流程
* http://www.cnblogs.com/skywang12345/p/3624177.html
* 例如:[80 70 60 50 40 30 20 10]
* 
* 
因為寫紅黑樹是一件大工程,為了驗證使用紅黑樹改善效能是可行的就先拿現成的程式碼來用吧
比起使用串列,紅黑樹在cache-misses上有一定程度的改善 **(But why?)**
```
Performance counter stats for './phonebook_opt' (100 runs):
1,247,330 cache-misses:u # 33.152 % of all cache refs ( +- 0.71% )
3,762,470 cache-references:u ( +- 0.22% )
401,991,447 instructions:u # 0.61 insns per cycle ( +- 0.00% )
658,891,050 cycles:u ( +- 0.41% )
0.242765557 seconds time elapsed ( +- 1.04% )
```
紅黑樹在insert和insert後的調整上花了很多cycles,銷毀紅黑樹也很花時間這倒是很意外
```
52.20% phonebook_opt [.] RBT_insert
13.19% phonebook_opt [.] RBT_destroy
7.78% phonebook_opt [.] RBT_insert_fixup
5.37% libc-2.23.so [.] _int_free
3.90% phonebook_opt [.] main
3.40% phonebook_opt [.] sdbm
3.03% libc-2.23.so [.] _int_malloc
1.75% libc-2.23.so [.] _IO_getline_info
1.37% phonebook_opt [.] append
1.08% libc-2.23.so [.] __memcpy_sse2
0.96% phonebook_opt [.] RBT_create_node
0.75% libc-2.23.so [.] _IO_fgets
0.65% libc-2.23.so [.] malloc
```
`append()`的時間突破了天際(差不多是0.2秒左右),而`findName()`一樣是趨近於0的時間花費,理論上`findName()`用紅黑樹實做要比串列好

與[f5120125](https://hackmd.io/BwMwnGIEbMC0BjAzJOAWATFApnYGBDERbKAEwQAYA2AVgwEYCEg=?both)同學實做的binary search tree相比較可以發現f5120125做得相當好(在`append()`上花比較少的時間),把串列直接轉換成binary search tree並考慮到二元樹傾斜的情況,考慮周到,但是有個缺點是來自於測資必須事先經過排序(本作業的測資本來就是排序好的不用做排序),若在動態新增資料的方面上是有問題的
結論:使用二元樹搜尋確實能大幅度改善`findName()`的時間,但是在`append()`上付出高額的時間代價,在效能trade-off上需要評估
## 挑戰題:fuzzy search
* https://zh.wikipedia.org/wiki/%E5%AD%97%E7%AC%A6%E4%B8%B2%E8%BF%91%E4%BC%BC%E5%8C%B9%E9%85%8D
* https://charles620016.hackpad.com/ep/pad/static/Japi4qFyAzt
### Levenshtein Distance (編輯距離)
* http://cpmarkchang.logdown.com/posts/222651-minimum-edit-distance
## 參考共筆
* [2016q3 Homework1 (phonebook) hold by f5120125 ](https://hackmd.io/BwMwnGIEbMC0BjAzJOAWATFApnYGBDERbKAEwQAYA2AVgwEYCEg=?both)
* [2016q3 Homework1 (phonebook) hold by ktvexe ](https://hackmd.io/EYRgJgpgbAxmBMBaeBWBiAsYU0QQ3jAA58MJh4BOGAMzAAZ6og==)
* [2016q3 Homework1 (phonebook) hold by louielu](https://hackmd.io/CYJgZgHA7AnADAFgLQGMCmaCGSEGYCsyMARjPkgIwhS4gT4VwogJA===)
 Sign in with Wallet
Connect another wallet
Sign in with Wallet
Connect another wallet