# 2016q3 Homework3 (mergesort-concurrent)
contributed by <`jkrvivian`>
## 預期目標
* 作為 [concurrency](/s/H10MXXoT) 的展示案例
* 學習 POSIX Thread Programming,特別是 [synchronization object](https://docs.oracle.com/cd/E19683-01/806-6867/6jfpgdcnd/index.html)
* 為日後效能分析和 scalability 研究建構基礎建設
* 學習程式品質分析和相關的開發工具
## 閱讀thread pool資料
由於上週作業還沒進到thread pool,因此要先讀書~~
[source](http://swind.code-life.info/posts/c-thread-pool.html)
* **condition variable**:
* type: `pthread_cond_t`
* initialize:
* `pthread_cond_t myconvar = PTHREAD_COND_INITIALIZER;`
* `pthread_cond_init()`: This method permits setting condition variable object attributes, attr.
* `pthread_cond_wait` :automatically and atomically unlock mutex while it waits.
### Thread Pool
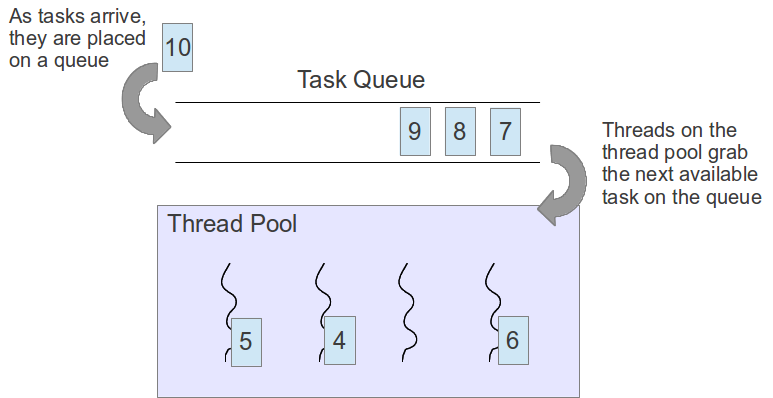
[threadpool-mbrossard](https://github.com/mbrossard/threadpool) 這份程式碼就是依循上圖實做出來,再加上作者詳盡的註解,閱讀起來並不困難
:::info
* immediate_shutdown: 馬上關掉thread pool
* graceful_shutdown: task queue裡也是空的才關thread pool
```clike==
if((pool->shutdown == immediate_shutdown) ||
((pool->shutdown == graceful_shutdown) &&
(pool->count == 0))) {
break;
}
```
:::
## Lock-free Thread Pool
* lock 的使用對於程式效能影響較大,雖然現有的 pthread_mutex 在 lock 的取得 (acquire) 與釋放,已在 Linux 核心和對應函式庫進行效能提昇,但我們仍會希望有不仰賴 lock 的 thread pool 的實做。
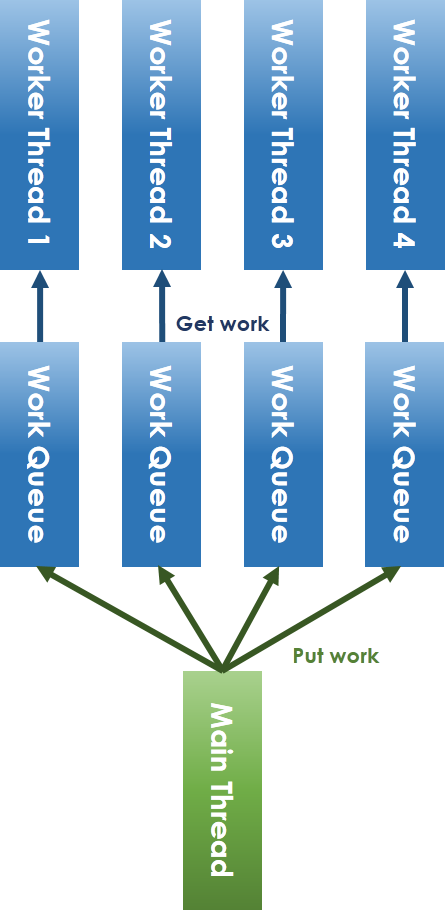
* 使用:
* **semaphore**
* 排程:
* Round-Robin: 即輪詢式地分配工作
* Least-Load演算法: 選擇目前具有最少工作的 worker thread 放入
* **ring buffer**: fixed-size buffer as if it were connected end-to-end.
* FIFO: first in, first out
* 優點: does not need to have its elements shuffled around when one is consumed
* FILO: first in, last out
* ex: stack
* **task migration**:
在執行緒的動態增加和減少的過程中,同樣基於 load-balancing 的考量,涉及到現有 task 的遷移 (migration) 問題。load-balancing 演算法主要基於平均工作量的想法,即統計目前時刻的總任務數目,均分至每一個執行緒,求出每個工作者執行緒應該增加或減少的工作數目,然後從頭至尾遍歷,需要移出工作的執行緒與需要移入工作的執行緒執行 task migration,相互抵消。最後若還有多出來的工作,再依次分配。
遷入 (migreate IN) 工作不存在競態,因為加入工作始終由 main thread 完成,而遷出 (migrate OUT) 工作則存在競態,因為在遷出工作的同時,worker thread 可能在同時執行任務。
* **atomic operation**: 同步機制,不須透過 explicit lock (如 mutex),也能確保變數之間的同步
* 在真實硬體環境中,atomics 的效能會比 pthread_mutex_t 好許多
* 在[範例程式碼](https://github.com/xhjcehust/LFTPool/blob/master/tpool.c)遇到的問題
* **load balance algorithm** may not work so balanced because worker threads are consuming work at the same time, which resulting in work count is not real-time
## 閱讀程式碼與code refactoring
* `intptr_t`
* 維持不同環境的通用性
* int相關的data type在不同位數機器的平台下長度不同,在`stdint.h`中有定義
* 參考[ C语言指针转换为intptr_t类型](http://www.cnblogs.com/Anker/p/3438480.html)及[使用變數型別的良好習慣](http://b8807053.pixnet.net/blog/post/164224857-%E4%BD%BF%E7%94%A8%E8%AE%8A%E6%95%B8%E5%9E%8B%E5%88%A5%E7%9A%84%E8%89%AF%E5%A5%BD%E7%BF%92%E6%85%A3)
* `list.h` 也使用`intptr_t`再定義`val_t`
### code refactoring
* 修改`merge_sort()`,一開始就直接找左半邊的最後一個,把next給右半邊的頭,可以少一次`list_nth()`的呼叫
* 直接使用list當左半邊,而不再另外新建一個left的list
```C==
llist_t *merge_sort(llist_t *list)
{
if (list->size < 2)
return list;
int mid = list->size / 2;
llist_t *right = list_new();
node_t *left_end = list_nth(list, mid-1);
right->head = left_end->next;
right->size = list->size - mid;
left_end->next = NULL;
list->size = mid;
return merge_list(merge_sort(list), merge_sort(right));
}
```
* 參考`TempoJiJi`同學的共筆看到他把`llist_t`這個structure拿掉,全部只使用`node_t`(更名為`list_t`)。 也就完全沒有`size`這個記錄list長度的變數。
* 重新檢視size變數的使用時機,其實主要功能就是merge sort找中間node的counter
* 但若沒了size如何找切半?
* 看了`TempoJiJi`同學的共筆才想起還有龜兔賽跑演算法可以用啊!!居然忘記這個方法了@@
* 使用兩倍速,當快的走到最後時,慢就剛好走一半
>> 有些經典的演算法就像修辭,用得好的話,則可有效又精確的表達 [name=jserv]
```C==
llist_t *list_nth(llist_t *list)
{
if(!list)
return list;
llist_t *fast = list;
llist_t *slow = list;
while(fast->next && fast->next->next) {
slow = slow->next;
fast = fast->next->next;
}
return slow;
}
```
* 由於刪除了一個資料結構,因此要修正相關function
> 要改的地方不少,過程中漏東漏西的>"<
* 改良後的merge sort
```C==
llist_t *merge_list(llist_t *a, llist_t *b)
{
llist_t *_list = list_new(0, NULL);
llist_t *current = _list;
while (a && b) {
if(a->data <= b->data){
current->next = a;
a = a->next;
} else {
current->next = b;
b = b->next;
}
current = current->next;
current->next = NULL;
}
llist_t *remaining = a ? a : b;
current->next = remaining;
return _list->next;
}
llist_t *merge_sort(llist_t *list)
{
if (!list->next)
return list;
llist_t *mid = list_nth(list);
llist_t *right = mid->next;
return merge_list(merge_sort(list), merge_sort(right));
}
```
* `task_t`裡需要兩個pointer(雙向), 我認為把指回上一個指標更名為`prev`會比`last`更清楚
* task queue pop跟push的方向錯了
* pop: 從head
* push: 從tail
## 自動化測試
* 驗證正確性
畢竟改了不少地方,還是得大量的測試才可以確保其正確性,只靠小測資目測還不夠!
* 全部使用檔案讀寫進行,去除`printf`及`scanf`
* input.txt:亂數
* merge sort生成的ouput檔與使用`sort`指令的結果比對
> 參考[compute_pi](https://github.com/jkrvivian/compute-pi/blob/master/Makefile)的Makefile編寫 [color=red][name=Vivian]
:::danger
沒辦法直接在Makefile中,使用$RANDOM輸出成檔
:::
## 參考資料
* [concurrency材料](/s/H10MXXoT)
* [TempoJiJi共筆](/s/B1-Kytv0)
###### tags: `system embedded` `Homework 3` `merge_sort_concurrent`







