# Lock-free 程式設計議題
:::danger
本頁面已不再維護,請造訪 ==[並行程式設計: Lock-Free Programming
](https://hackmd.io/@sysprog/concurrency-lockfree)== 新頁面。
:::
## 解說影片及文章
* video: [Introduction to Lock-free Programming](https://www.youtube.com/watch?v=RWCadBJ6wTk)
* 檢驗認知: 用 C11 atomics 改寫演說中示範的程式碼
* 何謂 ABA?如何避免 ABA?
* video: [Lock-Free Programming (or, Juggling Razor Blades), Part I](https://www.youtube.com/watch?v=c1gO9aB9nbs) / [Lock-Free Programming (or, Juggling Razor Blades), Part II"](https://www.youtube.com/watch?v=CmxkPChOcvw)
* Mike Acton 的 [Recent sketches on concurrency, data design and performance](https://cellperformance.beyond3d.com/articles/2009/08/roundup-recent-sketches-on-concurrency-data-design-and-performance.html)
## Fork Join Model
* 典型的平行程式,由以下 3 個區段所組成:
1. fork: 準備進入要平行化的區域時, master thread (下圖紅色) 產生出 team of threads (紅色加黃色)
> 注意: 這裡的 "fork" 並非 `fork(2)` system call

2. parallel region: 這些執行緒合力執行給定的工作

3. join: 工作完成之後, 又回到 fork 之前, 單一執行緒的狀態

* fork-join model 就是不斷重複上述過程

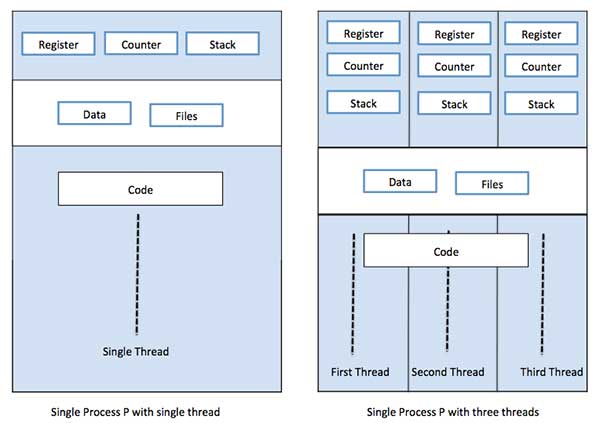
* 由記憶體的角度切入: 每個 thread 都有自己的 stack, 但 text, heap & data section 是共用的
[source](https://www.tutorialspoint.com/operating_system/os_multi_threading.htm)
## 探討 Synchronization
為了達到 concurrency,要有 Split a program 與 Synchronization 兩個步驟。
* Race Condition
* 設 count = 0 並為 Process A 和 B 的共享變數。
* 正確執行 Process A 和 B 的結果 count 應仍為 0
* 但若 Scheduler 照下列時序 (T1 -> T2 -> ...),則最後 count 為 -1
```cpp
/* Process A: count++ */
T1: lw $t1, &count
T3: addi $t1, $t1, 1
T4: sw $tw, &count
/* Process B: count-- */
T2: lw $t1, &count
T5: addi $t1, $t1, -1
T6: sw $tw, &count
```
* [Mutex vs. Semaphores – Part 1: Semaphores](https://blog.feabhas.com/2009/09/mutex-vs-semaphores-%E2%80%93-part-1-semaphores/)
* [Edsger Dijkstra](https://en.wikipedia.org/wiki/Edsger_W._Dijkstra) 在 1965 年提出 binary semaphore 的構想,嘗試去解決在 concurrent programs 中可能發生的 race conditions。想法便是透過兩個 function calls 存取系統資源 Semaphore,來標明要進入或離開 critical region。
* 使用 Semaphore 擁有的風險
* Accidental release
* This problem arises mainly due to a bug fix, product enhancement or cut-and-paste mistake.
* Recursive deadlock
* 某一個 task 重複地想要 lock 它自己已經鎖住的 Semaphore,通常發生在 libraries 或 recursive functions。
> for example, the simple locking of malloc being called twice within the framework of a library. An example of this appeared in the MySQL database bug reporting system: Bug #24745 InnoDB semaphore wait timeout/crash – deadlock waiting for itself
* Task-Death deadlock
* 某一個 task 其持有的 Semaphore 已經被終止或發生錯誤。
* Priority inversion
* Semaphore as a signal
* **Synchronization** between tasks is where, typically, one task waits to be notified by another task before it can continue execution (unilateral rendezvous). A variant of this is either task may wait, called the bidirectional rendezvous. **Quite different to mutual exclusion, which is a protection mechanism.**
* 使用 Semaphore 作為處理 Synchronization 的方法容易造成 Debug 困難及增加 "accidental release" 類型的問題。
* [Mutex vs. Semaphores – Part 2: The Mutex](https://blog.feabhas.com/2009/09/mutex-vs-semaphores-%E2%80%93-part-2-the-mutex/)
* 作業系統實作中,需要引入的機制。"The major use of the term mutex appears to have been driven through the development of the common programming specification for UNIX based systems."
* 儘管 Mutex 及 Binary Semaphore 的概念極為相似,但有一個最重要的差異:**the principle of ownership**。
* 而 Ownership 的概念可以解決前述所討論的五個風險
* Accidental release
* Mutex 若遭遇 Accidental release 將會直接發出 Error Message,因為它在當下並不是 owner。
* Recursive Deadlock
* 由於 Ownership,Mutex 可以支援 relocking 相同的 Mutex 多次,只要它被 released 相同的次數。
* Priority Inversion
* Priority Inheritance Protocol
* [Priority Ceiling Protocol](https://en.wikipedia.org/wiki/Priority_ceiling_protocol)
* [投影片](https://tams.informatik.uni-hamburg.de/lehre/2016ss/vorlesung/es/doc/cs.lth.se-RTP-F6b.pdf): 介紹 PCP,並實際推導兩個例子。
* Death Detection
* 如果某 task 因為某些原因而中止,則 RTOS 會去檢查此 task 是否擁有 Mutex ;若有, RTOS 則會負責通知所有 waiting 此 Mutex 的 tasks 們。最後再依據這些 tasks 們的情況,有不同的處理方式。
* All tasks readied with error condition
* 所有 tasks 假設 critical region 為未定義狀態,必需重新初始化。
* Only one task readied
* Ownership 交給此 readied task,並確保 the integrity of critical region,之後便正常執行。
* Semaphore as a signal
* Mutex 不會用來處理 Synchronization。
* [Mutex vs. Semaphores – Part 3: Mutual Exclusion Problems](https://blog.feabhas.com/2009/10/mutex-vs-semaphores-%E2%80%93-part-3-final-part-mutual-exclusion-problems/)
* 但還是有一些問題是無法使用 mutex 解決的。
* Circular deadlock
* One task is blocked waiting on a mutex owned by another task. That other task is also block waiting on a mutex held by the first task.
* Necessary Conditions
* Mutual Exclusion
* Hold and Wait
* Circular Waiting
* No preemption
* Solution: Priority Ceiling Protocol
* PCP 的設計可以讓低優先權的 task 提升至 ceiling value,讓其中一個必要條件 "Hold and Wait" 不會成立。
* Non-cooperation
* Most important aspect of mutual exclusion covered in these ramblings relies on one founding principle: **we have to rely on all tasks to access critical regions using mutual exclusion primitives**.
* Unfortunately this is dependent on the design of the software and cannot be detected by the run-time system.
* Solution: Monitor
* Not typically supplied by the RTOS
* A monitor simply encapsulates the shared resource and the locking mechanism into a single construct.
* Access to the shared resource is through a controlled interface which cannot be bypassed.
* [Mutexes and Semaphores Demystified](http://www.barrgroup.com/Embedded-Systems/How-To/RTOS-Mutex-Semaphore)
* Myth: Mutexes and Semaphores are Interchangeable
* Reality: 即使 Mutexes 跟 Semaphores 在實作上有極為相似的地方,但他們通常被用在不同的情境。
* The correct use of a semaphore is for **signaling** from one task to another.
* A mutex is meant to be taken and released, always in that order, by each task that uses the shared resource it protects.
* 還有一個重要的差別在於,即便是正確地使用 mutex 去存取共用資源,仍有可能造成危險的副作用。
* 任兩個擁有不同優先權的 RTOS task 存取同一個 mutex,可能會創造 **Priority Inversion**。
* Definition: The real trouble arises at run-time, when a medium-priority task preempts a lower-priority task using a shared resource on which the higher-priority task is pending. If the higher-priority task is otherwise ready to run, but a medium-priority task is currently running instead, a priority inversion is said to occur. [[Source]](https://barrgroup.com/Embedded-Systems/How-To/RTOS-Priority-Inversion)
* 但幸運的是,Priority Inversion 的風險可以透過修改作業系統裡 mutex 的實作而減少,其中會增加 acquiring and releasing mutexes 時的 overhead。
* 當 Semaphores 被用作 signaling 時,是不會造成 Priority Inversion 的,也因此是沒有必要去跟 Mutexes 一樣去更改 Semaphores 的實作。
* This is a second important reason for having distinct APIs for these two very different RTOS primitives.
## Deeper Look: Lock-Free Programming
>導讀 [An Introduction to Lock-Free Programming](http://preshing.com/20120612/an-introduction-to-lock-free-programming/) 與 [Lock-Free 编程](http://www.cnblogs.com/gaochundong/p/lock_free_programming.html)
為了解決上述 semaphore, mutex 會產生的問題 (e.g. deadlock, livelock, priority inversion, ...),可以使用 lock-free(lockless) programming 內的一些技巧以提昇效能與正確性
lock-free 不是說完全不用 mutex lock,而是指整個程式的執行不會被其單個執行緒 lock 鎖住
```cpp
while (x == 0) {
x = 1 - x;
}
```
* 由兩個執行緒同時執行這段程式碼,有可能出現兩者都無法跳出迴圈的情況嘛?
|x|thread 1|thread 2|
|-|-|-|
|0|while(x == 0)||
|0||while(x == 0)|
|1|x = 1 - x||
|0||x = 1 - x|
|0|while(x == 0)|
|0||while(x == 0)|
||...|...|
----
### A. lock-free vs wait-free
參考: [Non-blocking algorithm](https://en.wikipedia.org/wiki/Non-blocking_algorithm#Wait-freedom)
* 想像一個情況: 在使用 mutex 時,若其中一個執行緒在釋放 lock 之前被系統 preempt,則需要同一個資源的其他執行緒會無法繼續,直到原本的執行緒恢復執行完畢
* 若系統 kill 該執行緒,則整個程式就完全無法再繼續前進
* **wait-free** 是 non-blocking 之中強度最高的,它保證所有的指令可以 bound 在某個時間內完成,也就是所有的執行緒經過一段足夠的時間後,一定會有所進展
* **lock-free** 稍微弱一點,它允許部份執行緒被暫停,但仍然保證整體程式的其他部份會有進展
* 最差的情況下,就算只有一個執行緒在執行,其他所有執行緒都在等待,仍然屬於 lock-free
* obstruction-free,non-blocking 中最弱的,但不在本處的討論範圍
* 根據定義,所有 wait-free 都屬於 lock-free
故就算不使用 mutex lock (e.g. busy waiting, 上面的 spin lock),不代表就是 lock-free
----
### B. lock-free 的意義
要求整個程式都是 lock-free 是極為困難的,通常 lock-free 會應用在一些特定的資料結構上,例如為 lock-free queue 實做 lock-free 版本的 `push`, `pop`, `isEmpty` 等
----
### C. lock-free 使用的技術
#### 1. Atomic Operation: Read-Modify-Write
此類的指令雖然包含複數個動作,但由硬體的設計保證就像是 load, store, add, ... 中間無法再插入其他指令
延伸: [Read-modify-write](https://en.wikipedia.org/wiki/Read-modify-write)
常見的實作如: test-and-set, fetch-and-add, compare-and-swap
延伸: [Compare-and-swap](https://en.wikipedia.org/wiki/Compare-and-swap)
```cpp
bool test_and_set(bool *target) //atomic
{
//non-interruptable operations
bool b = *target;
*target = true;
return b;
}
```
```cpp
loop //lock init to FALSE
{
while(test_and_set(lock)) ; //block
//critical section
lock = false;
}
```
各平台提供的 API
* Win32: `_InterlockedIncrement`
* iOS: `OSAtomicAdd32`
* C++11: `std::atomic<int>::fetch_add`
值得一提的是,C++11 的 atomic operation 無法保證是 lock-free 的,必須透過 `std::atomic<>::is_lock_free` 來確認
#### 2. Compare-And-Swap Loops
在 RMW 中最常見的應用就是將 CAS 搭配 loop 使用
Win32 支援的 CAS: `_InterlockedCompareExchange`
```cpp
void LockFreeQueue::push(Node* newHead)
{
for (;;) {
// Copy a shared variable (m_Head) to a local.
Node* oldHead = m_Head;
// Do some speculative work, not yet visible to other threads.
newHead->next = oldHead;
// Next, attempt to publish our changes to the shared variable.
// If the shared variable hasn't changed, the CAS succeeds and we return.
// Otherwise, repeat.
if (_InterlockedCompareExchange(&m_Head, newHead, oldHead) == oldHead)
return;
}
}
```
* 上例為何可被稱為 lock-free? 因為如果其中一個執行緒的迴圈無法通過 `_InterlockedCompareExchange`,代表有其他的執行緒成功了,程式整體是有進展的
* 在處理 CAS Loop 時要特別小心 [ABA Problem](https://en.wikipedia.org/wiki/ABA_problem):
若兩個執行緒同時對一個記憶體內容進行操作,但優先執行完畢的執行緒把原值 A 改爲 B 又改回 A,這樣後執行的執行緒將會讀取錯誤的資料

#### 3. Sequential consistency
所有的執行緒都依循順序執行程式,簡單來說,就是前面的指令一定比後面的指令先執行
```shell
$ gcc -s main.c
$ cat main.s
...
store x, 1
load r1, y
...
```
* sequential consistency 保證不會出現
```
//in CPU
load r1, y
store x, 1
```
的情況
案例探討: [C11 Lock-free Stack](https://nullprogram.com/blog/2014/09/02/)
#### 4. Memory Ordering
參考: [浅谈Memory Reordering](http://dreamrunner.org/blog/2014/06/28/qian-tan-memory-reordering/)
* 當一個 **lock-free** 程式在**多核**系統執行,且執行環境**不保證 sequential consistency** 時,就要小心 memory reordering

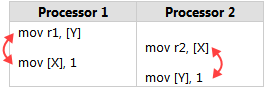
memory reordering 代表程式的執行順序不一定,可能會造成錯誤結果
實例: [Memory Reordering Caught in the Act](http://preshing.com/20120515/memory-reordering-caught-in-the-act/)
注意發生的條件
* 如果保證 sequential consistency,那就不用擔心會出錯
* 如果在**單核**系統執行,那只要關閉 compiler optimization 就可以保證 sequential consistency
* 如果程式**並非 lock-free**,那 critical section 的指令會因為有 lock 而被 block 住,也保證了執行的正確性
reordering 可以分成兩種:
* compiler reordering
實例: [Memory Ordering at Compile Time](http://preshing.com/20120625/memory-ordering-at-compile-time/)
* processor reordering
其實就是在 compile time 跟 run time 兩個時間點,因為最佳化產生指令重新排序的關係
----
### D. lock-free 衍生的問題
上文提到兩個,一個是 CAS loop 裡面的 ABA 問題,另一個是在討論 sequential consistency 時提到的 memory ordering,這裡著重於第二點
#### 1. 根據最佳化時間點不同,有不同的解法
* Compiler Barrier
[浅谈Memory Reordering](http://dreamrunner.org/blog/2014/06/28/qian-tan-memory-reordering/) 和 [Memory Ordering at Compile Time](http://preshing.com/20120625/memory-ordering-at-compile-time/) 的後半部都有實際演練,沒有乖乖讀的人現在可以點進去老實讀完
* Memory Barrier
圖解: [Memory Barriers Are Like Source Control Operations](http://preshing.com/20120710/memory-barriers-are-like-source-control-operations/)
定義: [Acquire and Release Semantics](http://preshing.com/20120913/acquire-and-release-semantics/)
總共有 4 種 barrier,而透過這 4 種 barrier 可組合成 acquire & release semantics

引述:
"**Acquire semantics** prevent memory reordering of the read-acquire with any read or write operation which follows it in program order.
...
**Release semantics** prevent memory reordering of the write-release with any read or write operation which precedes it in program order."
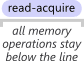

透過 Acquire and Release Semantics 來限制優化,讓記憶體相關操作必須在特定語句前後完成
#### 2. Memory Models
延伸: [Weak vs. Strong Memory Models](http://preshing.com/20120930/weak-vs-strong-memory-models/)
memory reordering 發生的機率,跟兩者有關,一個是硬體(processor),另一個是軟體(toolchain)
根據不同的執行環境可以列出下表:

所謂的 weak 就是指有很大的機率會將 load/store 指令進行重排,而 strong 則相反
1. **Weak memory model**: 可能存在所有的 memory reordering
2. **Weak with data dependency ordering**: 可能存在 storeload 和 storestore 的reordering (load 的順序必能被保證)
3. **Usually Strong**: 保證 acquire and release semantic 的執行,所以只存在 storeload reordering
4. **Sequentially consistent**: 全部被保證順序