---
tags: DYKC, C, CLANG, C LANGUAGE, pointer, memory
---
# [你所不知道的 C 語言](https://hackmd.io/@sysprog/c-prog/):記憶體管理、對齊及硬體特性
Copyright (**慣C**) 2018 [宅色夫](https://wiki.csie.ncku.edu.tw/User/jserv)
==[直播錄影](https://youtu.be/v2Lj7lI_7ig)==

> [出處](https://x.com/chessMan786/status/1876264463914999880)
## 背景知識
* [指標篇](https://hackmd.io/s/HyBPr9WGl)
* C99/C11 規格書 6.2.5 (28) 提到:
> A pointer to void shall have the same representation and alignment requirements as a pointer to a character type.
* 在 6.3.2.3 (1) 提到:
> A pointer to void may be converted to or from a pointer to any object type. A pointer to any object type may be converted to a pointer to void and back again; the result shall compare equal to the original pointer.
```C
int *intptr = NULL;
void *dvoidptr = &intptr; /* 6.3.2.3 (1) */
*(void **) dvoidptr = malloc(sizeof(*intptr));
```
* 將 `int **` 轉型為 `void *`: :+1: (fine); 將 `void *` 轉型為 `void **`: :-1: (not ok)。C 語言不保證你可以安全地轉換 `void *` 為任意型態後,再轉換回原本的型態
* `void *` 的設計,導致開發者必須透過 ==explicit (顯式)== 或強制轉型,才能存取最終的 object,否則就會丟出編譯器的錯誤訊息,從而避免危險的指標操作。也就是說,我們無法在 ISO C 中直接對 `void *` 做數值操作
```c
void *p = ...;
void *p2 = p + 1; /* what exactly is the size of void? */
```
> 在 [GNU C Extension](https://www.gnu.org/software/c-intro-and-ref/manual/html_node/Pointer-Arithmetic.html#Pointer-Arithmetic) 中,可以對 void * 做數值操作,單位為 1
- 換言之,`void *` 存在的目的就是為了強迫使用者使用 ==顯式轉型== 或是 ==強制轉型==,以避免 Undefined behavior 產生
- C/C++ [Implicit conversion](http://en.cppreference.com/w/cpp/language/implicit_conversion) vs. [Explicit type conversion](https://en.cppreference.com/w/cpp/language/explicit_cast)
* [函式呼叫篇](https://hackmd.io/@sysprog/c-function)
* `free()` 釋放的是 pointer 指向位於 heap 的連續記憶體,而非 pointer 本身佔有的記憶體 (`*ptr`)
* glibc 提供 `malloc_stats()` 和 `malloc_info()` 函式,可顯示 process 的 heap 資訊
## 你可能沒想過的 Memory

> [出處](https://twitter.com/bytebytego/status/1578259927490969600)
* Cache locality
參照 [What a C programmer should know about memory](https://marek.vavrusa.com/memory/) ([簡記](http://wen00072.github.io/blog/2015/08/08/notes-what-a-c-programmer-should-know-about-memory/))
* Understanding virtual memory - the plot thickens
> The virtual memory allocator (VMA) may give you a memory it doesn’t have, all in a vain hope that you’re not going to use it. Just like banks today
:::info
1. 現代銀行和虛擬記憶體兩者高度相似
2. malloc 給 valid pointer 不要太高興,等你要開始用的時候搞不好作業系統給個 OOM。簡單來說就是一張支票,能不能拿來開等到兌現才知道
:::
* Understanding stack allocation
> This is how variable-length arrays (VLA), and also [alloca()](https://linux.die.net/man/3/alloca) work, with one difference - VLA validity is limited by the scope, alloca’d memory persists until the current function returns (or unwinds if you’re feeling sophisticated).
:::info
C99 的 variable length array (VLA) 的運作是因為 stack frame的特性,反正你要多少,stack 在調整時順便加一加。malloc 一樣的原則
:::
* Slab allocator
:::info
有的時候程式會 allocate 並使用多個不連續的記憶體區塊,如樹狀的資料結構。這時候對於系統來說有幾個問題,一是 fragment、二是因為不連續,無法使用 cache 增快效能。
:::
* Demand paging explained
:::info
Linux系統提供一系列的記憶體管理 API
* 分配,釋放
* 記憶體管理 API
- mlock: 禁止被 swapped out (向 OS 提出需求,OS 不一定會理)
- madvise: 提供管道告訴系統 page 管理方式如 MADV_RANDOM,期待記憶體 page 讀取行為是隨機的。(不是標準,隨著 Linux 核心改版會有所不同)
- lazy loading: 配置記憶體先給位址。等到行程要存取時,作業系統就會發現存取到尚未觸及的記憶體,於是產生 page fault,這時作業系統再去處理 page 分配的問題。
:::
> Copy-on-write
:::info
有些情況是一個 process 要吃別的 process 已經 map 到記憶體的內容,而不要把自己改過的資料放回原本的記憶體。也就是說最終會有兩塊記憶體(兩份資料)。當然每次都複製有點多餘,因此系統使用了 Copy-on-write 機制。要怎麼做呢?就是在 mmap 使用 MAP_PRIVATE 參數即可。
:::
延伸閱讀:
* [現代處理器設計: Cache 原理和實際影響](https://hackmd.io/@sysprog/HkW3Dr1Rb)
* [Cache 原理和實際影響](https://hackmd.io/@SIlbVPlXR26vjqUoZDgZzA/HkyscQn2z): 進行 [CPU caches](https://lwn.net/Articles/252125/) 中文重點提示並且重現對應的實驗
* [針對多執行緒環境設計的 Memory allocator](https://hackmd.io/s/HkICAjeJg#)
* [rpmalloc 探討](https://hackmd.io/@Z892YW7ORxSwX99S5tZKxQ/H1TP6FV6z)
## 重新看 Heap
:::info
"heap" 的中文翻譯
* 台灣: 堆積
* 中國: 堆
:warning: 這裡的 Heap 跟資料結構中的 Heap 無關,而是[原本的意涵](https://dictionary.cambridge.org/dictionary/english/heap)。
:::
動態配置產生,系統會存放在另外一塊空間,稱之為 "Heap"。
依據 [Why are two different concepts both called "heap"?](http://stackoverflow.com/questions/1699057/why-are-two-different-concepts-both-called-heap)
Donald Knuth 在《The Art of Computer Programming》(Third Ed., Vol. 1, p. 435) 提到:
> ==Several authors began about 1975 to call the pool of available memory a "heap."==
He doesn't say which authors and doesn't give references to any specific papers, but does say that the use of the term "heap" in relation to priority queues is the traditional sense of the word.
## data alignment
一個 data object 具有兩個特性:
* value
* storage location (address)
data alignment 的意思就是, data 的 address 可以公平的被 1, 2, 4, 8,這些數字整除,從這些數字可以發現他們都是 2 的冪 (power of 2),亦即這些 data object 可以用 1, 2, 4, 8 byte 去 alignment。
CPU 擷取資料時不會一次只抓取 1 byte 的資料,畢竟這樣太慢。假設某個變數的型態為 `int`,若 CPU 每次都只抓取 1 byte,就必須要抓 4 次 (`int` 為 4 byte),效率低落,於是 CPU 通常一次擷取 4 或 8 byte (要看電腦的規格,32 位元的 CPU 一次可讀取 32 bit 的資料,64 位元一次可讀取 64 bit,以此類推),並依序存取。
如果你的資料分布在第 0-3 byte,那麼可以直接取:
* 直接取第 0-3 byte 的資料(下圖左側例子)

但如果你的資料是分布在第 1-4 byte(上圖右側例子),那麼事情就不太一樣了:
* 第一次取第 0-3 byte,將第 0 byte 的資料去掉,留下第 1-3 byte
* 第二次取第 4-7 byte,將第 5-7 byte 的資料去掉,留下第 4 byte
* 最後將第一次的第 1-3 byte 與第二次的第 4 byte 合起來

可見如果資料位址不在 4 的倍數,會導致存取速度降低,編譯器在分配記憶體時,會按照宣告的型態去做 alignment。
舉個例子,`int` 的大小普遍為 4 byte,因此普遍做 4 byte alignment,這代表,就算其真正使用的大小只有 1 byte,電腦也會給他 4 byte 的空間,如此一來才能將記憶體位址對齊在 4 的倍數。
* struct 會自動做 alignment,假設宣告以下這個結構體:
```c
struct s1 {
char c;
int a;
};
```
原本推論 char 為 1 byte,而 int 為 4 byte ,兩個加起來應該為 5 byte,然而實際上為 8 byte,由於 int 為 4 byte ,所以 char 為了要能 alignment 4 byte 就多加了 3 byte 進去 ,使得 cpu 存取速度不會因 address 不是在 4 的倍數上,存取變慢。
* 下一個實驗:
```c
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
typedef struct _s1 {
char a[5];
} s1;
int main() {
s1 p[10];
printf("struct s1 size: %ld byte\n", sizeof(s1));
for(int i = 0; i < 10; i++) {
printf("the struct p[%d] address =%p\n", i, p + i);
}
}
```
得到執行結果為
```
struct s1 size: 5 byte
the struct p[0] address =0x7ffc14c80170
the struct p[1] address =0x7ffc14c80175
the struct p[2] address =0x7ffc14c8017a
the struct p[3] address =0x7ffc14c8017f
the struct p[4] address =0x7ffc14c80184
the struct p[5] address =0x7ffc14c80189
the struct p[6] address =0x7ffc14c8018e
the struct p[7] address =0x7ffc14c80193
the struct p[8] address =0x7ffc14c80198
the struct p[9] address =0x7ffc14c8019d
```
由於 char type 的 data 大小只佔 1 byte 所以只要 1 byte alignment ,也就是不用使用 padding 讓其變成 4 的倍數。由於編譯器會自動幫我們以 data 的大小做 alignment ,假設有 int type(4 byte) 在配置時,已是 4 byte alignment。
* 部分微處理器可不用特別處理 data alignment 的議題,例如 intel x86/x86_64 系統允許 data unalignment。以下用 x86_64 實驗 data alignment 跟 data unalignment 的差異。
* 建立二個結構體,其中內容相同,唯一不同的是 t1 有加 pack 這屬性已告知編譯,test1 裡的 data 只要 1 byte alignment 就好,t2 則是會按照宣告的 type 作 alignment 所以 t2 裡會有 padding。
重新設計實驗
- [ ] 方式一:變更結構體佔用的空間 ([Structure-Packing Pragmas](https://gcc.gnu.org/onlinedocs/gcc-5.4.0/gcc/Structure-Packing-Pragmas.html))
```c
#pragma pack(push, 1)
typedef struct _test1 {
char c[3];
int num[256];
} test1;
#pragma pack(pop)
typedef struct _test2 {
char c[3];
int num[256];
} test2;
```
- [ ] 方式二:去掉 cache 的影響
每次執行程式前,確認以下命令已執行:
```shell
sudo sh -c 'echo 3 > /proc/sys/vm/drop_caches'
```
清除 pagecache、dentries 及 inodes
這段程式碼執行 200 次 看是否平均起來的執行時間相仿
```c
for i in `seq 0 1 200`; do \
echo 3 > /proc/sys/vm/drop_caches ;\
printf "%d," $i;\
./pointer; \
done > clock_gettime.txt
```
效能分佈:

malloc 本來配置出來的記憶體位置就有做 alignment,根據 malloc 的 man page 裡提到 :
> The malloc() and calloc() functions return a pointer to the allocated memory, which is
suitably aligned for any built-in type.
實際上到底 malloc 做了怎樣的 data alignment,繼續翻閱 [The GNU C Library - Malloc Example](https://www.gnu.org/software/libc/manual/html_node/Malloc-Examples.html),裡面特別提到:
> In the GNU system, the address is always a multiple of eight on most systems, and a multiple of 16 on 64-bit systems.
在大多數系統下,malloc 會以 8 bytes 進行對齊;而在 64-bit 的系統下,malloc 則會以 16 bytes 進行對齊。
對應的實驗,malloc 在 Linux x86_64 以 16 bytes 對齊:
```c
for (int i = 0; i < 10000; ++i) {
char *z;
z = malloc(sizeof(char));
}
```
結果用 gdb 測過之後,發現位址的結尾的確都是 0 結尾,表示真的是以 16-byte 做對齊。
Unaligned memory access
An unaligned memory access is a load/store that is trying to access an address location which is not aligned to the access size.
e.g: A load instruction trying to access 4 bytes from address 0x1 is an unaligned access. This typically gets split into two internal operations as shows in the following diagram and merges into one.
Note that in case of systems with caches, there can also be cases of addresses crossing a cache line boundary (a.k.a misaligned access) and some times accesses can also be crossing a page boundary.
Then you can also have other complexities like one half of the memory access is hit in cache while the other half is a miss in the cache. The load store execution unit along with cache controllers deals with these complexities but in summary it follows the same basic principle of merging two access
Some architectures (like Intel x86) also has alignment interrupts that help in detecting unaligned memory access.

考慮以下 `unaligned_get32` 函式的實作: (假設硬體架構為 32-bits)
```c
#include <stdint.h>
#include <stddef.h>
uint8_t unaligned_get8(void *src)
{
uintptr_t csrc = (uintptr_t) src;
uint32_t v = *(uint32_t *) (csrc & 0xfffffffc);
v = (v >> (((uint32_t) csrc & 0x3) * 8)) & 0x000000ff;
return v;
}
uint32_t unaligned_get32(void *src) {
uint32_t d = 0;
uintptr_t csrc = (uintptr_t) src;
for (int n = 0; n < 4; n++) {
uint32_t v = unaligned_get8((void *) csrc);
v = v << (n * 8);
d = d | v;
csrc++;
}
return d;
}
```
對應的 `unaligned_set32` 函式:
```c
void unaligned_set8(void *dest, uint8_t value)
{
uintptr_t cdest = (uintptr_t) dest;
uint32_t d = *(uint32_t *) (cdest & 0xfffffffc);
uint32_t v = value;
for (int n = 0; n < 4; n++) {
uint32_t v = unaligned_get8((void *) csrc);
v = v << (n * 8);
d = d | v;
csrc++;
}
return d;
}
void unaligned_set32(void *dest, uint32_t value) {
uintptr_t cdest = (uintptr_t) dest;
for (int n = 0; n < 4; n++) {
unaligned_set8((void *) cdest, value & 0x000000ff);
value = value >> 8;
cdest++;
}
}
```
參考資料:
* [Data Alignment](http://www.songho.ca/misc/alignment/dataalign.html)
* [Linux kernel: unaligned memory access](https://www.kernel.org/doc/Documentation/unaligned-memory-access.txt)
* [Data alignment: Straighten up and fly right](https://developer.ibm.com/technologies/systems/articles/pa-dalign/)
* [Interleaved Pixel Lookup for Embedded Computer Vision](https://slideplayer.com/slide/9319090/), Page 10
## 案例分析: concurrent-ll
[concurrent-ll](https://github.com/jserv/concurrent-ll/tree/master/src/lockfree)
這個實作的基礎是 [A Pragmatic Implementation of Non-Blocking Linked Lists](https://www.cl.cam.ac.uk/research/srg/netos/papers/2001-caslists.pdf) 這篇論文。
文中首先提到對「天真版」的鏈結串列進行插入與刪除,就算直接用 compare-and-swap 這個最小操作 (atomic operation) 改寫,也沒有辦法保證結果正確。在只有 insert 的狀況下可以成立,但如果加上 delete 的話,如果 insert 跟 delete 發生時機很接近,有可能會發生以下的狀況:

情境是這樣:準備插入 20, 並且刪除 10。這是做到一半的狀況。
* delete 做的事情是這樣:
`CAS(&(H->next), head_next, head->next->next)`
* insert 準備執行的動作是這樣:
`CAS(&(node_10->next), node_10->next, node_20)`
但是兩個 [CAS](https://en.wikipedia.org/wiki/Compare-and-swap) 的動作的先後是無法確定的。如果 insert 的先發生,那結果是正確的。但是如果 delete 的先發生,就會變成下面這個樣子:

結果顯然不正確,因為本來沒有要刪除 20 那個節點。那到底要怎麼辦呢?這篇文章提到一個作法:刪除時不要真的刪除,而是掛一個牌子說「此路段即將刪除」,但是還是過得去,像這樣:

然後等到真的要拆它的時候(比如說需要插入的時候),再把它拆掉。
所以需要有個方法標示「不需要的節點」,然後要有 atomic operation.
### 標示不用的節點
不過看了一陣子,發現了幾個問題:為什麼只用位元運算就可以做到「邏輯上」刪除節點?
答案是用 data alignment。首先是 C99 的規格中 6.7.2.1 提到:
* 12
> Each non-bit-field member of a structure or union object is aligned in an implementation- defined manner appropriate to its type.
* 13
> Within a structure object, the non-bit-field members and the units in which bit-fields reside have addresses that increase in the order in which they are declared. A pointer to a structure object, suitably converted, points to its initial member (or if that member is a bit-field, then to the unit in which it resides), and vice versa. There may be unnamed padding within a structure object, but not at its beginning.
所以這個東西是 implementation-defined. 查看 [gcc 的文件](https://gcc.gnu.org/onlinedocs/gcc/Structures-unions-enumerations-and-bit-fields-implementation.html) 怎麼說:
> The alignment of non-bit-field members of structures (C90 6.5.2.1, C99 and C11 6.7.2.1).
Determined by ABI.
先回去翻 C99 的規格,裡面提到關於 `intptr_t` 這個資料型態:
7.18.1.4 Integer types capable of holding object pointers
> The following type designates a signed integer type with the property that any valid pointer to void can be converted to this type, then converted back to pointer to void, and the result will compare equal to the original pointer: intptr_t
所以 `intptr_t` 是個 integral type, 要至少可以裝得下 pointer
然後對照 `/usr/include/stdint.h`, 查到以下內容:
```c
/* Types for `void *' pointers. */
#if __WORDSIZE == 64
# ifndef __intptr_t_defined
typedef long int intptr_t;
# define __intptr_t_defined
# endif
typedef unsigned long int uintptr_t;
#else
# ifndef __intptr_t_defined
typedef int intptr_t;
# define __intptr_t_defined
# endif
typedef unsigned int uintptr_t;
#endif
```
繼續找 [x86_64 ABI](https://www.uclibc.org/docs/psABI-x86_64.pdf),裡面其中一個附表:

然後又說:
* Aggregates and Unions
Structures and unions assume the alignment of their most strictly aligned compo-
nent. Each member is assigned to the lowest available offset with the appropriate
alignment. The size of any object is always a multiple of the object‘s alignment.
An array uses the same alignment as its elements, except that a local or global
array variable of length at least 16 bytes or a C99 variable-length array variable
always has alignment of at least 16 bytes. 4
Structure and union objects can require padding to meet size and alignment
constraints. The contents of any padding is undefined.
因此可推論結構:
```c
typedef intptr_t val_t;
typedef struct node {
val_t data;
struct node *next;
} node_t;
```
的定址當中,不會發生位址的最後一個 bit 被使用到的狀況(因為都是 4 的倍數 + 必須對齊)。所以就把最後一個 bit 設成 1 當作是刪掉這個節點的 mark. 而把最後一個 bit 設成 0, 就表示恢復原狀。
## glibc 的 malloc/free 實作
背景考量:[Deterministic Memory Allocation for Mission-Critical Linux](https://static.sched.com/hosted_files/ossna2017/cf/Deterministic%20Memory%20Allocation%20for%20Mission-Critical%20Linux.pdf)
**Memory request size**
* 大 request (>= 512 bytes):使用 best-fit 的策略,在一個 range(bin)的 list 中尋找
* 小 request (<= 64 bytes):caching allocation,保留一系列固定大小區塊的 list 以利迅速回收再使用
* 在兩者之間:試著結合兩種方法,有每個 size 的 list (小的特性),也有合併 (coalesce) 機制、doubly linked list (大)
* 極大的 request (>= 128KB by default):直接使用 `mmap()`,讓 memory management 解決
:::info
arena 發音為 [əˈriː.nə]
:::
**arena and thread**
arena 即為 malloc 從系統取得的連續記憶體區域,分為 main arena 與 thread arena 兩種:
* main arena:空間不足時,使用 `brk()` 延展空間,預設一次 132 KiB
* thread arena:使用 `mmap()` 取得新記憶體,預設 map 1 MiB,分配給 heap 132 KiB,尚未分配給 heap 的空間設定為不可讀寫,1 MiB 使用完後會再 map 一個 1 MiB 的新 heap
每個 thread 在呼叫 `malloc()` 時,會分配到一個 arena,在開始時 thread 與 arena 是一對一的(per-thread arena),但 arena 的總數有限制,超過時 threads 會開始共用 arena:
* 32 bit : 2 $\times$ number of cores
* 64 bit : 8 $\times$ number of cores
此設計是為了減少多 threads 記憶體浪費,但也因此 glibc malloc **不是 lockless allocator**,對於有許多 threads 的 server 端程式來說,很有可能影響效能
**Heap data structures**
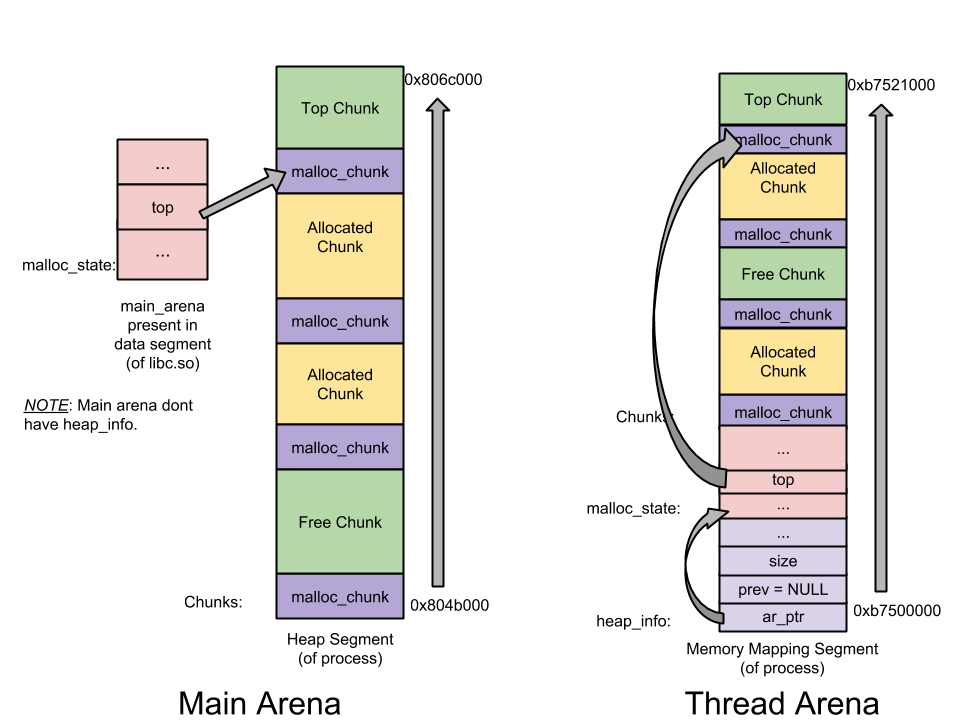
* **[malloc_state](https://github.com/sploitfun/lsploits/blob/master/glibc/malloc/malloc.c#L1671) (Arena Header)**:每個 arena 一個。紀錄 arena 的資訊,包含 bins (free list), top chunk, last remainder chunk 等等 allocation/free 需要的資訊。其中 main arena 的 header 在 data segment (static),thread 的在 heap 中
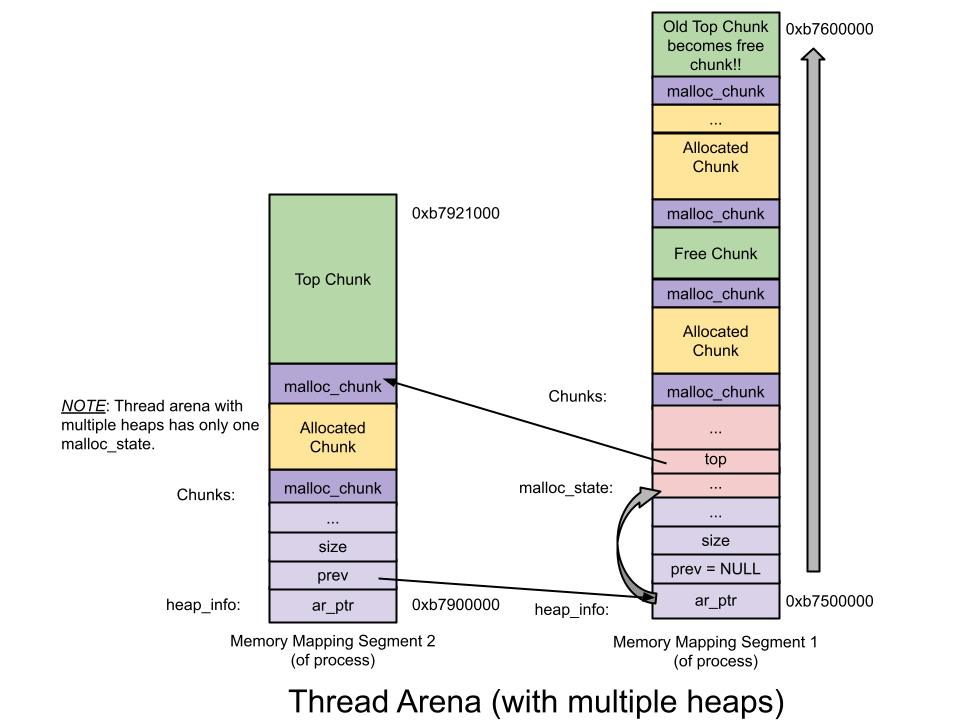
* **[heap_info](https://github.com/sploitfun/lsploits/blob/master/glibc/malloc/arena.c#L59) (Heap Header)**:在 thread arena 中,每個 arena 可能有超過一個 heap。紀錄前一個heap、所屬的 arena、已使用/未使用的 size
* **[malloc_chunk](https://github.com/sploitfun/lsploits/blob/master/glibc/malloc/malloc.c#L1108) (Chunk Header)**:一個 heap 被分為許多區段,稱為 chunk,是 user data 儲存的地方,又依使用狀態分為 free 與 allocated。紀錄 chunk 本身的 size 與型態
_Main arena vs Thread arena :_
_multiple heap Thread arena :_
**Chunks**
* 可用來分配或正在使用中的記憶體區塊,分為 allocated 與 free
* chunk 的大小在 32 bit 下最小 16 bytes,對齊 8 bytes;64 bit 下最小 32 bytes,對齊 16 bytes
* 需要至少 4 個 word 作為 free chunk 時的 field
_Allocated chunk :_

* [prev_size](https://github.com/sploitfun/lsploits/blob/master/glibc/malloc/malloc.c#L1110) : 如果前一個 chunk 是 free chunk,包含前一個 chunk 的 size,若是 allocated,則包含 user data
* [size](https://github.com/sploitfun/lsploits/blob/master/glibc/malloc/malloc.c#L1111) : 此 chunk 的大小,最後 3 bit 作為 flag 使用
* [PREV_INUSE](https://github.com/sploitfun/lsploits/blob/master/glibc/malloc/malloc.c#L1267) (P) : 前一個 chunk 是 allocated
* [IS_MMAPPED](https://github.com/sploitfun/lsploits/blob/master/glibc/malloc/malloc.c#L1274) (M) : 是 mmap 取得的獨立區塊
* [NON_MAIN_ARENA](https://github.com/sploitfun/lsploits/blob/master/glibc/malloc/malloc.c#L1283) (N) : chunk 是 thread arena 的一部分
_Free Chunk_:
.png)
* [prev_size](https://github.com/sploitfun/lsploits/blob/master/glibc/malloc/malloc.c#L1110) : 因兩個 free chunk 會合併,只會出現在 fast bin 的情況下
* fast bin 的 chunk 在 free 時不會做合併,只有在 malloc 步驟中的 consolidate fastbin (fast /small bin miss) 才會合併
* 下一個 chunk 的 PREV_INUSE flag 平時是不 set 的
* [fd](https://github.com/sploitfun/lsploits/blob/master/glibc/malloc/malloc.c#L1113) (Forward pointer):指向在同一個 bin 中的下一個 chunk
* [bk](https://github.com/sploitfun/lsploits/blob/master/glibc/malloc/malloc.c#L1114) (Backward pointer):指向在同一個 bin 中的上一個 chunk
**Bins**
bins 是紀錄 free chunks 的資料結構(freelist),依據其大小和特性分成4種:
(以下的數值為 32 bit 系統,64 bit $\times$ 2)
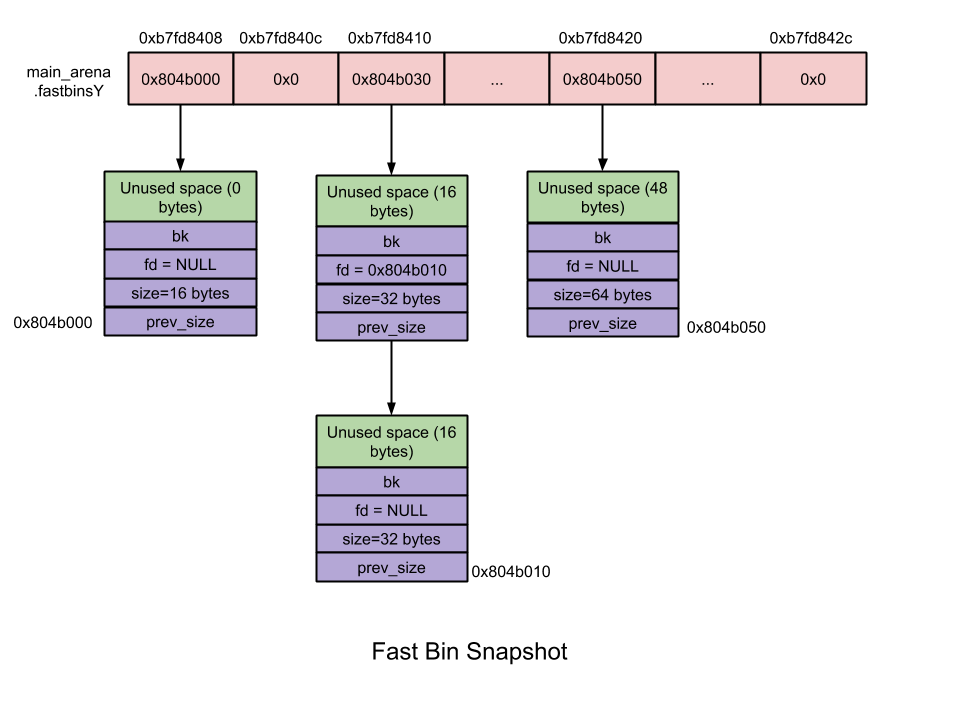
_Fast Bin_:
* 10 個 bin
* 使用 linked list,malloc 時配置最後一項 (pop from top)
* chunk 大小在 16 ~ 最大80(可設定,預設 64byte 之間
* size:每個 bin 差 8 bytes
* 不執行合併:在 free 時不會清除下一個 chunk 的 `PREV_INUSE` flag
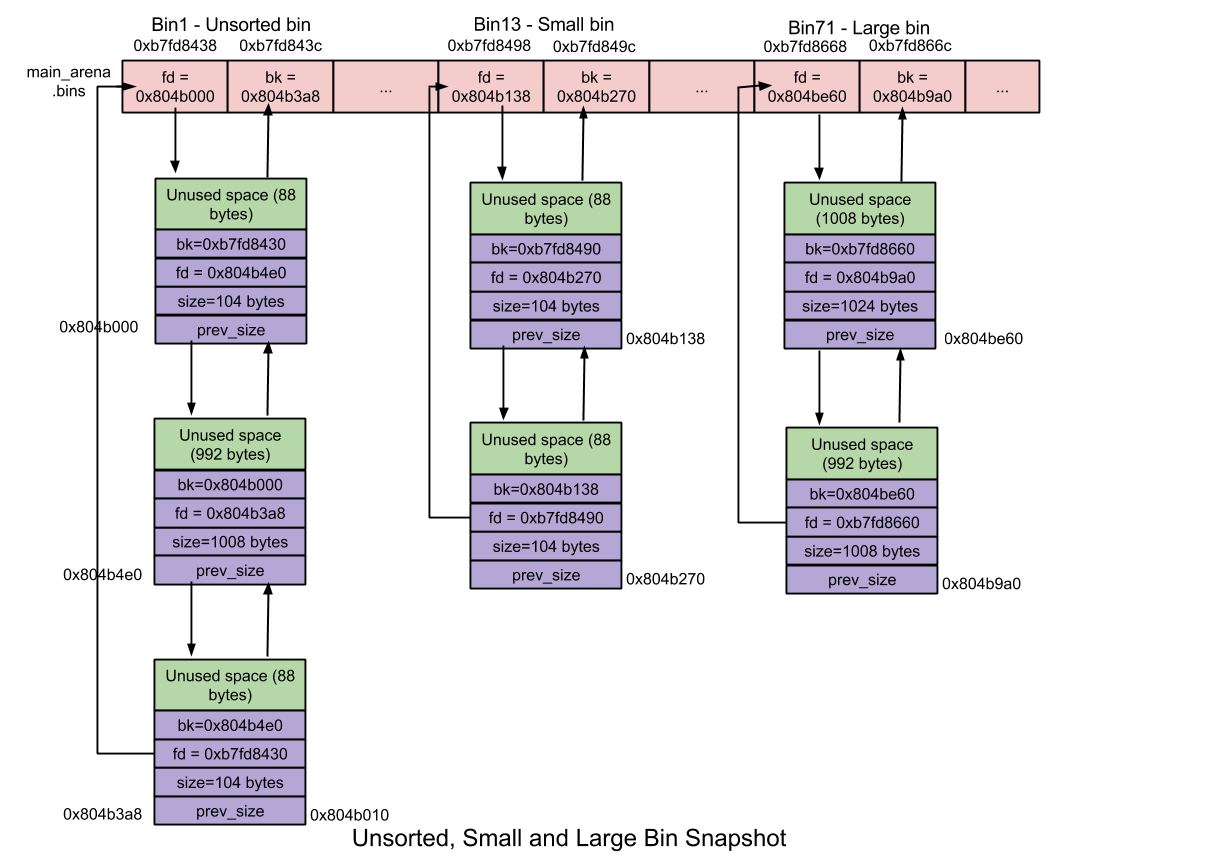
_Unsorted Bin_:
* 最近 free 的 small / large chunk,不分大小
* 重複使用 chunks 以加速 allocation
_Small Bin_:
* chunk < 512 bytes
* 62 個 bin
* size : 每個 bin 差 8 bytes
* 合併 : 兩個相鄰的 free chunk 合併,減少 fragmentation(但較耗時)
_Large Bin_:
* chunk >= 512 bytes
* 63 個 bin
* size : 每個 bin 差距不同
* 前 32 個 bin 差 64 bytes (n=1)
* 再 $2^{(6-n)}$ 個 bin 差 $8^{(n+1)}$ bytes
* n=6 : 1 個 bin 262144 bytes
* 剩最後一個 bin 存放所有更大的 chunk
* bin 裡的 chunk 依大小排序 (因 size 差距不再是最小單位),配置時需搜尋最適大小
**Top chunk**
在 arena 邊界的 chunk,若所有 bin 皆無法配置則由這裡取得,若仍不夠則用 brk / mmap 延展
**Last Remainder Chunk**
最近一次分割的 large chunk,被用來滿足 small request 所剩下的部分
**malloc 流程**
* 調整 malloc size : 加上 overhead 並對齊,若 < 32 byte (64bit 最小 size,4 pointers) 則補上
* 檢查 fastbin : 若對應 bin size 有符合 chunk 即 return chunk
* 檢查 smallbin : 若對應 bin size 有符合 chunk 即 return chunk
* 合併(consolidate)fastbin : (若 size 符合 large bin 或前項失敗) 呼叫 malloc_consolidate 進行 fastbin 的合併(取消下一 chunk 的 PREV_INUSE),並將合併的 bin 歸入 unsorted
* 處理 unsorted bin:
* 若 unsorted bin 中只有 last_remainder 且大小足夠,分割 last_remainder 並 return chunk。剩下的空間則成為新的 last_remainder
* loop 每個 unsorted bin chunk,若大小剛好則 return,否則將此 chunk 放至對應 size 的 bin 中。此過程直到 unsorted bin 為空或 loop 10000 次為止
* 在 small / large bin 找 best fit,若成功則 return 分割的 chunk,剩下的放入 unsorted bin(成為 last_remainder);若無,則繼續 loop unsorted bin,直到其為空
* 使用 top chunk : 分割 top chunk,若 size 不夠則合併 fastbin,若仍不夠則 system call
#### free 流程
* 檢查 : 檢查 pointer 位址、alignment、flag 等等,以確認是可 free 的 memory
* 合併 (consolidate)
* fastbin size : 不進行合併
* 其他 :
* 檢查前一 chunk,若未使用則合併
* 檢查後一 chunk,若是 top chunk 則整塊併入 top chunk,若否但未使用,則合併
* 將合併結果放入 unsorted bin
* ref : [allocation過程](http://brieflyx.me/2016/heap/glibc-heap/)
* **glibc malloc allocation informations**
* [mallinfo](http://man7.org/linux/man-pages/man3/mallinfo.3.html) - obtain memory allocation information
* [malloc_stats](http://man7.org/linux/man-pages/man3/malloc_stats.3.html) - print memory allocation statistics
* [malloc_info](http://man7.org/linux/man-pages/man3/malloc_info.3.html) - export malloc state to a stream
簡單測試 : `malloc(40 * sizeof(int));`
* mallinfo() [example](http://man7.org/linux/man-pages/man3/mallinfo.3.html#EXAMPLE)
```shell
Total non-mmapped bytes (arena): 135168
# of free chunks (ordblks): 1
# of free fastbin blocks (smblks): 0
# of mapped regions (hblks): 0
Bytes in mapped regions (hblkhd): 0
Max. total allocated space (usmblks): 0
Free bytes held in fastbins (fsmblks): 0
Total allocated space (uordblks): 176
Total free space (fordblks): 134992
Topmost releasable block (keepcost): 134992
```
## 待整理
* [Why does calloc exist?](https://vorpus.org/blog/why-does-calloc-exist/)
* 對應的 [Hacker News 討論](https://news.ycombinator.com/item?id=13108434)
* [Queryable pointer alignment](https://www.open-std.org/jtc1/sc22/wg14/www/docs/n2974.pdf) (C23)