---
title: hslu dda play3 2022.10.1
tags: presentations
description: View the slide with "Slide Mode".
slideOptions:
theme: white
---
<!-- .slide: data-background="#000000" -->
<img src="https://i.imgur.com/OSW972P.png" width="100">
<center><pre>
██████╗ ██████╗ █████╗ ██████╗ ██╗ █████╗ ██╗ ██╗
██╔══██╗██╔══██╗██╔══██╗ ██╔══██╗██║ ██╔══██╗╚██╗ ██╔╝
██║ ██║██║ ██║███████║ ██████╔╝██║ ███████║ ╚████╔╝
██║ ██║██║ ██║██╔══██║ ██╔═══╝ ██║ ██╔══██║ ╚██╔╝
██████╔╝██████╔╝██║ ██║ ██║ ███████╗██║ ██║ ██║
╚═════╝ ╚═════╝ ╚═╝ ╚═╝ ╚═╝ ╚══════╝╚═╝ ╚═╝ ╚═╝
</pre></center>
```python
datetime(2022, 10, 10) && what3('abbauen.beraten.offiziell')
```
PART 2 :rabbit: hackmd.io/@oleg/dda-21-play3-5
PART 1 :o: hackmd.io/@oleg/dda-21-play3
----
# Lernziele
**Selbstorganisierte Datenerhebung**
- Entwicklung von experimentellen Gestaltungs- und Visualisierungstrategien
- Kenntnisse in der Entwicklung eines eigenständigen visuellen Repertoirs
- Kenntnisse im Umgang mit kartografischem Material
- Methodisches und praktisches Vorgehen
- Kontextualisierung von Themen und Gestaltungsansätzen
- Aneignen von Kompetenzen in visueller Vermittlung von komplexen Themen und Daten
----
**Spezifische Lernziele**
- Daten mit Hilfe von Messgeräten wie GPS-Tracker, DIY und Off-The-Shelf Sensoren selbstorganisiert erheben und
extrahieren.
- Daten mit Hilfe von Crowdsourcing-Apps und offenen Datenquellen (OGD, LD, PD, …) finden und diese mit Spreadsheets und APIs aufbereiten.
- Sich auseinandersetzen mit komplexe Information durch einfache explorative Datenanalyse.
- Der unterschied zwischen kartographische, statistische und andere Daten verstehen.
----
**Weitere Lernziele**
- Einführung in Datennachhaltigkeit, Lizenzierung und der schutz von Personenbezogene Daten.
- Fähigkeiten zum selbstkritischen Recherche und Datenerhebung entwickeln.
- Ihre Feldarbeit zu starten mit eine "Spazierung in die Datendjungeln"
- Die Ergebnisse ihrer Peers sehen und kritisch hinterfragen, selbst konstruktive Kritik annehmen, diese reflektieren und sinnvoll in die Weiterentwicklung ihres Projekts einbinden.
----
### Ich heisse Oleg

Informatiker (39), verheiratet, 2 Kinder, Kanadier :maple_leaf:
Meine +/- Ziele :point_down:
I. Internetplattformen einrichten, die Menschen durch+um Informationen herum zusammenbringen; II. Projektbasiertes "hands on" Lernen fördern; III. Kritische Bewertung von Code, Algorithmen und Daten unterstützen.
---
### I. SELBSTORGANISIERTE DATENERHEBUNG
- Di. **Datenportale, Kartendienste, Personal Data**
- Mi. Brainstorming von Strategien und Richtungen
- Do. Datenerhebung und Extrahierung How-To
- Fr. Datenaufbereitung von Spreadsheets zu APIs
----
### SELBSTORGANISIERTE ...
<a href="https://commons.wikimedia.org/wiki/File:Dungeons_and_Dragons_game.jpg#/media/Datei:Dungeons_and_Dragons_game.jpg"><img src="https://upload.wikimedia.org/wikipedia/commons/thumb/8/87/Dungeons_and_Dragons_game.jpg/1200px-Dungeons_and_Dragons_game.jpg" alt="Dungeons and Dragons game.jpg"></a><br><small>Von Die Autorenschaft wurde nicht in einer maschinell lesbaren Form angegeben. Es wird <a href="//commons.wikimedia.org/wiki/User:Moroboshi" class="mw-redirect" title="User:Moroboshi">Moroboshi</a> als Autor angenommen (basierend auf den Rechteinhaber-Angaben). - Die Autorenschaft wurde nicht in einer maschinell lesbaren Form angegeben. Es wird angenommen, dass es sich um ein eigenes Werk handelt (basierend auf den Rechteinhaber-Angaben)., <a href="http://creativecommons.org/licenses/by-sa/3.0/" title="Creative Commons Attribution-Share Alike 3.0">CC BY-SA 3.0</a>, <a href="https://commons.wikimedia.org/w/index.php?curid=223468">Link</a></small>
:point_up: Metadata fail?
----
# DATENERHEBUNG

----
[](https://labs.openai.com/e/ZmXPyqlPbMdQVEyVL5cz05GY)
----

[History of Data Storage](https://www.youtube.com/watch?v=5KtMF1jLmNM) (YouTube)
----
[Kraftbalanse - Øystein Wyller Odden](https://vimeo.com/370554138) (Vimeo)
----

> „Meine Reise ins All sollte eine Feier sein, stattdessen fühlte es sich wie eine Beerdigung an“, so Shatner. „Es war eines der stärksten Trauergefühle, die ich je gefühlt habe. Der Kontrast zwischen der bösartigen Kälte des Weltraums und der warmen Erde unter mir erfüllte mich mit überwältigender Traurigkeit.“ -- [William Shatner](https://www.businessinsider.de/wissenschaft/wie-captain-kirk-start-william-shatner-seine-reise-ins-all-fand/) (BusinessInsider) beschreibt damit eine Erfahrung, die als [Overview-Effekt](https://de.wikipedia.org/wiki/Overview-Effekt) bekannt ist.
----
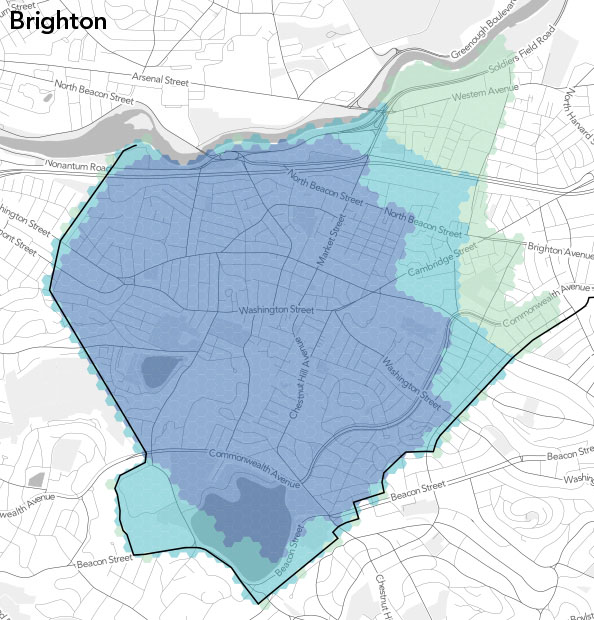
[Crowdsourced neighbourhood boundaries](https://bostonography.com/2012/crowdsourced-neighborhood-boundaries-part-one-consensus/) (Bostonography)
----
[ Field Papers](http://fieldpapers.org/)
----

[StoryMaps: Datengeschichten](https://www.geo.admin.ch/de/thematic-geoportals-federal-offices/storymaps-geo-datengeschichten.html) (Swisstopo/sCHoolmaps)
---
# Was heisst Open Data ?

Generating a word cloud for interview transcripts with R - [Struck & Simukovic](https://zenodo.org/record/12842)
----
## The Open Definition
"Wissen ist **offen**, wenn jedeR darauf frei zugreifen, es nutzen, verändern und teilen kann – eingeschränkt höchstens durch Massnahmen, die **Ursprung und Offenheit** des Wissens bewahren." ([opendefinition.org](https://opendefinition.org))
[<img src="https://opendata.utou.ch/presentations/digiges 2019.2/images/oki-small-rgb-433x344.png" width="160" style="border:none;background:none" border="0">](https://youtu.be/wS-dTTNaKE8)
----
[](https://eduwells.com/2014/10/06/safer-schools-with-creative-commons/)
----

Die „virale“ Share-Alike Klausen in CC sind ähnlich zu der [GNU General Public License](https://de.wikipedia.org/wiki/GNU_General_Public_License) von Free Software Foundation, die an die Würzeln der Open Source Bewegung in der IT stehen.
----

"Fisch" query on [Google Image Search](https://www.google.com/search?q=fisch&tbm=isch&tbs=il:cl&hl=de&sa=X&ved=0CAAQ1vwEahcKEwio4pDv8Nf6AhUAAAAAHQAAAAAQAw&biw=952&bih=532#imgrc=BF152ThVojDm4M) with Creative Commons-Filter.
----

"Fish" query on [CC BY Openverse](https://wordpress.org/openverse/search/?q=fish&license=by)
----

Creative Commons license at [YouTube Studio](https://studio.youtube.com/)
----
[](https://chooser-beta.creativecommons.org/)
[CC License Chooser Beta](https://chooser-beta.creativecommons.org/)
----

[Open Data Commons Licenses](https://opendatacommons.org/licenses/by/1-0/), von Open Knowledge empfohlen, wurden bereits in mehreren Ländern der Welt eingeführt.
----
## Warum sind Lizenzen für Daten wichtig?
- Strukturierte Daten sind nur eine andere Art von Inhalt
- Förderung der Remix-Kultur für kreative Zusammenarbeit
- Anerkennung der Urheberschaft schützt die Arbeitsbedingungen
- Die Open-Government-Strategie führt zu neuen Datenressourcen
- Eine Einladung, mit Daten "offener" (interdisziplinär..) zu arbeiten
----

Die [Bundesstrategie für OGD](https://opendata.ch/2018/11/bundesrat-beschliesst-strategie-fuer-open-government-data-2019-2023/) (2019-2023) implementiert **Nutzungsbedingungen**, die direkt von Creative Commons inspiriert sind, aber _keine_ Lizenzen per se sind. Sie sieht Mechanismen vor, mit denen Daten von schweizerische Regierungsstellen als Open Data veröffentlicht werden können.
---
<img title="MAKE badge" height="100%" src="https://opendata.utou.ch/presentations/open%20data%202013.2/images/07%20badge.png"><br>
Seit 2011 haben wir in der Schweiz eine engagierte **Community**, die den Datenzugang für die breite Öffentlichkeit vorantreibt (Bild: [MAKE badge](http://make.opendata.ch/wiki/information:badge)).
----
## Wo gibt es für mich benützbaren Daten?
:globe_with_meridians: :hospital: :moneybag: :zap: :umbrella: :building_construction:
----
<img title="Insurance map" src="https://www.seantis.ch/blog/visualiserung-der-krankenkrassenpraemien/aerzte_pro_10T.png" style="border:0;width:100%">
Oft stehen offene Daten hinter die Apps und Webseiten, die wir alltäglich brauchen (Bild: [SHIP map](https://blog.datalets.ch/029/)). Schau hinein!
----

Auf Open Data-Portalen werden immer mehr Daten zu diverse Themen publiziert. Diesen Bild von [opendata.swiss](https://opendata.swiss) stammt von 2019. Wieviel Datensätze gibt es Heute?
----

Viele Daten sind aufbereitet von Statistiker:innen, und meistens als mehrseitigen Reports publiziert, so wie die [Taschenstatistik der BFS.](https://www.bfs.admin.ch/bfs/de/home/statistiken/land-forstwirtschaft.assetdetail.22906536.html)
----

Die Open Data Community engagiert sich ab und zu um neue Datenquelle zu kreieren, oftmals in Zusammenarbeit mit Gemeinde, Kantone oder Bundesstellen (Bild: [db.schoolofdata.ch](https://db.schoolofdata.ch/event/7.html), auch im [NZZ - 4.10.2022](https://www.nzz.ch/visuals/bag-datenpanne-wie-das-amt-wieder-auf-die-richtige-spur-kam-ld.1705030)).
----

Die Monitoring der Verfügbarkeit von Datenquellen ist auch eine wichtige Aufgabe. Dieser Screenshot zeigt, wie [GeoAdmin](https://twitter.com/OD_ACal/status/1208634522721509376) seine offenen Datendienste überwacht. Siehe auch die Arbeiten von [Jonas Oesch](https://jonasoesch.ch/articles/opendata-swiss). Es ist wichtig zu erinnern, dass Daten bleiben nicht unbedingt für immer verfügbar, oder offen!
---
### Sieben beliebte Methoden der Datenerfassung
0. Ein paar Zahlen in einer Tabelle schmeissen :female-artist:
1. Mit einem Klemmbrett herumlaufen :clipboard:
2. Den Leuten eine Umfrage zum Ausfüllen schicken :iphone:
3. Einen festen Sensor irgendwo aufstellen :couch_and_lamp:
4. Einen mobilen Sensor anbringen & eine Runde fahren :bicyclist:
5. Aus (Satelliten-)Bildern interpretieren :satellite:
6. Daten von jemand anderem herunterladen :dog:
7. ~~Leise schmarotzen, wenn niemand zuschaut~~ :sleuth_or_spy:
---

[Mr. Bean Destroys Painting](https://www.youtube.com/watch?v=lmmp7fGAgRg) (YouTube) zeigt auf einer amüsanten Art, was passieren könnte, wenn wir zu nah an unsere wichtige und einzigartige Quellen können ... und versuchen sie alleine zu verbessern.
----
# Datenrecherche in der Praxis
<table>
<tr><th>Was</th><td>Sammeln von hochwertigem Material für Data Design + Art</td></tr>
<tr><th>Wie</th><td>Orientieren durch einen Datendschungel, experimentieren und "the good stuff" verpacken!</td></tr>
<tr><th>Wann</th><td>12. Oktober 2022</td></tr>
<tr><th>Wo</th><td>Luzern, Switzerland</td></tr>
<tr><th>Mitnehmen</th><td>Ein halbwegs moderner Laptop, die Fähigkeit, komfortabel im Web zu navigieren, etwas Erfahrung mit Tabellenkalkulationen und Web-Apps.</td></tr>
<tr><th></th><td> <a href="#" class="button"><i style="color:blue" class="fa fa-question-circle-o" aria-hidden="true"></i> Teams</a> <a href="#"><i style="color:#ed0" class="fa fa-lemon-o" aria-hidden="true"></i> Dribdat</a></td></tr>
</table>
---
## Anleitung
<img src="https://meta.dribdat.cc/static/img/logo11.png" width="128">
<img src="https://cdn-images-1.medium.com/max/1200/1*frC0VgM2etsVCJzJrNMZTQ.png" width="128"><br><br>
Wir verwenden Teams und [GitHub](https://github.com) mit der [Dribdat-App](https://dribdat.cc) für die Zusammenarbeit bei der Datenforschung. Siehe auch die [School of Data pipeline](http://toolbox.schoolofdata.ch/overview.html), die eine wichtige Inspiration für uns ist.
----

### dribdat :point_right: [DDA.schoolofdata.ch](https://dda.schoolofdata.ch)
1. Log dich ein, um ein Profil zu erstellen. Füge deine (Spitz-)Namen, eine kurzen Biografie (meine Skills..) und deine Ziele hinzu.
2. Schauen die vorgeschlagenen Ressourcen und Beispiele für Datenforschungsprojekte an, mit Links zu bestehenden offenen Quellen und Datenerfassungsmethoden.
3. Versuche, von jedem Datensatz, den du entdeckst und verwenden möchtest, eine Kopie zu bekommen und ihn zu untersuchen. Es könnte zunächst wie Spaghetti aussehen ... Wir werden es gemeinsam tun! Stelle deine Expeditionsleiter alle Fragen vor Ort oder über Slack.
4. Beschreibe die Hindernisse oder Erkenntnisse in einem Beitrag (Post > Log) auf deine Projektseite.
5. Am Ende der Übung sollten die Daten und eine einfache Vorschau auf deine Projektseite zu sehen sein.
----

In einer Datenexpedition lernen wir, mit offenen Daten zu arbeiten und grössere Mengen an diversen Informationen aus legalen, authentischen und aktuellen Quellen zu sammeln. Dazu dient es unsere [Ressourcenkataloge](https://dda.schoolofdata.ch/event/2/stages) (oben abgebildet).
----
## Let's go!
1. Wir **denken über Fragen** (ASK) nach, die wir gerne stellen möchten, über Themen, die uns in Bezug auf die städtische Datenlandschaft interessieren.
2. Wir **recherchieren** (FIND) gemeinsam in Datenportalen und Suchmaschinen und sammeln die Perlen, die wir finden.
3. Wir **schreiben Queries** (GET) vor, kreieren Accounts, entwerfen Briefe, laden Daten herunter.
4. Wir prüfen ob wir aus **authentischen** (VERIFY) Quellen die Daten programmatisch extrahieren und/oder rechtlich beantragen können.
5. Wir **verbessern** (CLEAN) der Datenqualität und ergänzen die Daten mittels Crowdsourcing on.
6. Wir **berechnen** (ANALYSE) die Daten, stellen Relevanz zu aktuellen Themen und Institutionen hervor.
7. Wir **berichten** (PRESENT) über unsere Entdeckungen, die wir mittels Visualisierungen und Publikationen mitteilen.
----
### Fragen für die Runde
- Wie kann eine Datenexpedition bei einem **Data Art & Design** Projekt helfen?
- Wo sucht man normalerweise nach Daten? Was müssen wir **beachten**?
- **Warum** sollten wir offene, verknüpfte oder reibungslose Daten bevorzugen?
- Wie können wir uns den Daten, und der Visualisierung auf denen basiert, **gut vertrauen**?
- Was ist genau ein **Datenkatalog**?
- Wie können Daten Ihre Privatsphäre **bedrohen**?
- Was macht eine Datenquelle **authentisch**?
----
## All the world's an [API](https://www.programmableweb.com/api-university/what-are-apis-and-how-do-they-work)
Öffentliche Einrichtungen und Unternehmen [bauen](https://twitter.com/meteoschweiz/status/1574386046774792192) jeden Tag ihre digitale Dienste auf APIs auf. Was können wir damit [anfangen](http://make.opendata.ch/wiki/project:scatterwindrose), und wie können wir [mitmachen](https://twitter.com/meteoschweiz/status/1575779211272495104)?
----
Libraries are a kind of API

----
Data..

or API?..

Ideally: the best of both worlds!
----
There are many tools to work with APIs

https://www.postman.com/
----
Look for **libraries** and open source community **examples**.

https://github.com/search?o=desc&q=srgssr&s=updated&type=Repositories
----
## From [CSV](https://csv-spec.org/) to [GeoJSON](https://geojson.org/) & beyond
Wie das [W3C](https://www.w3.org/standards/techs/csv), die [Internet Engineering Task Force](https://www.rfc-editor.org/info/rfc7946) (IETF) oder [Open Knowledge](https://frictionlessdata.io) daran arbeiten, einen Konsens für Datenformate zwischen Industrie, Regierung und Wissenschaft zu schaffen.
----

https://5stardata.info/
----

https://lod-cloud.net/
----
## Beispielhaftes Open Data API

https://opendata.swiss/de/dataset/standorte-und-verfugbarkeit-von-shared-mobility-angeboten
----
## [Siting Classification](https://community.wmo.int/activity-areas/imop/siting-classification)
Herausforderungen bei Daten-aquise? Wir können uns von der Suche nach einem "repräsentativen Standort für eine Messstation" bei der gestrigen [WMO-Konferenz in Paris](https://twitter.com/fisler/status/1580103649241763840) inspirieren. Es ist wirklich nicht einfach auf dauer gute, vergleichbare Daten zu erheben! Open standards :+1: Walled gardens :-1:
<p><a href="https://commons.wikimedia.org/wiki/File:Edzell_garden.JPG#/media/File:Edzell_garden.JPG"><img src="https://upload.wikimedia.org/wikipedia/commons/thumb/6/66/Edzell_garden.JPG/1200px-Edzell_garden.JPG" alt="Edzell garden.JPG"></a>
Jonathan Oldenbuck - <a href="https://creativecommons.org/licenses/by-sa/3.0" title="Creative Commons Attribution-Share Alike 3.0">CC BY-SA 3.0</a>, <a href="https://commons.wikimedia.org/w/index.php?curid=3899733">Link</a></p>
----
# Weiteres Vorgehen
:mag: :adult:
Wir erkunden den Raum und machen **selbstorganisierte** Datenerhebung wenn wir uns bedienen von vorhandener Systeme und Geräte (Mobile, GPS-Tracker), entwickeln unsere eigenen Sensoren und Tools, und betreiben visuelle Datenerhebung.

---
:children_crossing: :electric_plug:
Die eigene Datenerhebung stellen wir in einen grösseren Kontext zu **Open Data** und bringen sie miteinander in **Verbindung**.
[](https://opendata.swiss)
----
:coffee: :penguin:
Die Daten bearbeiten wir im Code und mit **analogen und digitalen** Gestaltungswerkzeugen. Wir forschen mittels Experimenten nach neuen **Datenformaten**, geeignet zu verschiedene Visualisierungsmöglichkeiten.

----
:sparkler:
Die gefundenen und erhobenen Daten von stellen wir kartografisch dar und ergänzen sie mit Zukunftsdaten. Für die zweite Unterrichtswoche mit Christian sollen wir wissen **wo Geodaten zu finden sind** und eigenständig diese je nachdem zu **konvertieren** (z.B. JSON - CSV - GeoJSON).

---
:world_map:
Es ist wichtig zu wissen, wie man Geodaten, welche in Schweizer Landeskoordinaten erfasst sind, nach WGS84 umformen kann. Viele offene Geodaten, gerade von Luzern, sind in Schweizer Landeskoordinaten abgelegt.
:bulb: Anleitung auf https://dda.schoolofdata.ch/project/11
[](https://geo.admin.ch)
----
 <!-- .element: style="width:33%;margin:0px;border:0px;box-shadow:none" -->
----
## Next module (18-21.10)
`<< MAXIMALE DATENFREIHEIT >>`
- Wie Daten verbessert/veredelt sind mit Machine Learning und Automation
- Selbster Daten publizieren: Quellen, Packaging, Sharing, Analytics
- Weiteren Datenerhebung und Support von Projektarbeiten
----

🔜 Wir suchen nach Datenquellen, die relativ aktuell sind, Potenzial für künstlerische Anwendungen haben und möglichst frei von Restriktionen und Zugänglichkeitsproblemen sind - im Idealfall offen gemäss der [Open Definition](https://opendefinition.org/). Aus den besten Daten, die wir gemeinsam entdecken, wollen wir qualitativ hochwertige Pakete erstellen, die in unseren Datenvisualisierungs- und 3D-Produktionswerkzeugen verwendet werden können.
----
:cloud: Wir sind Künstler und bekommen unsere Daten nicht auf dem Silbertablett serviert.
:lightning_cloud: Kombination aus offenen, angefragten, von Menschenhand gesammelten und selbst gesammelten Daten.
:sun_behind_cloud: Gemeinsame - kollaborative - Nutzung von Daten durch Studenten.
:snow_cloud: Fokus auf Datenformate, nicht auf Tools.
----
*"Where there is perfect certainty, there is no information: there is nothing to be said."*
<small>-- [J Soni & R Goodman](http://nautil.us/issue/51/limits/how-information-got-re_invented)</small>
[](https://opendatabeer.ch/impressionen/open-data-beer-nr-12-30-11-2020/)
---
# Fragen?
oleg.lavrovsky@hslu.ch :see_no_evil:
<small>This presentation is shared under [CC BY 4.0](http://creativecommons.org/licenses/by/4.0/)</small>
 Sign in with Wallet
Sign in with Wallet







