# Hand Pose Estimation: A Survey(2019)
{%hackmd theme-dark %}
###### tags: `paper`
###### description: 論文読んだまとめ記事
---
- Title
Hand Pose Estimation: A Survey
- Conference
- Authors
- URL
---
## 1. Introduction
Hand Pose EstimationのSurvey論文。
AR,VR関係でhand-estimationの研究は活発になっている。
現在大まかに2つの問題1枚の画像(RGB画像)から2Dの座標推定をするImage-based MethodとDepth-based Methodが存在する。
==近年の研究はデプスデータを使わずに、RGBだけで推定する傾向がある。==
RGBのみで推定するのは難しいタスクであり、データセットもより大きなものが必要になる。
## 2. Hand Pose Estimation Problem
hand poswe estimationは、手の関節位置推定と等しく、2Dの推定と3Dの推定がある。
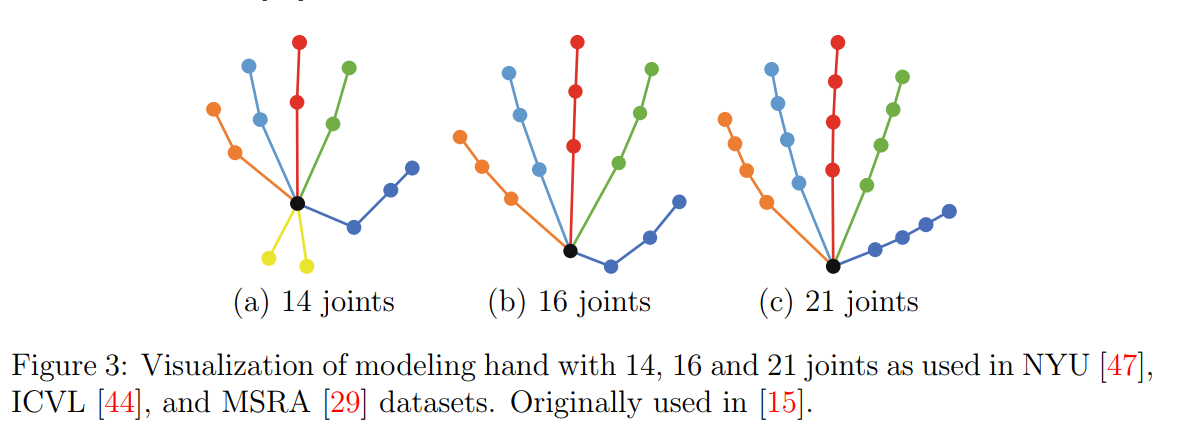
データセットの規格は存在しないが、上記の3つのモデルが主で、その中でも21関節のモデルが現在最もポピュラー。
よって多くの学習済みモデルは21関節のデータで学習されている。
## 3. Approaches
### DeepLearning以前
DeepLearning以前は伝統的な機械学習手法が使われていた。
その1つとして、下の画像に示すようなグローブに対して色ごとにnearest neighborで位置を求める手法が提案されている。
商業的には、MicrosoftがKinectのデプスカメラでRandomForestを用いて人物ポーズ推定を行ったのが一番うまく行ったと言える。
その手法はまず回転不変性のためにデプスマップを正規化する。そしてピクセルを手かどうかでラベリングした画像を学習して、ピクセルのクラス分類を行う。

### detection-based and regression-based algorithms
detection-basedの手法では関節ごとの確率密度マップを推定する。
そしてargmax関数でもっとも確率の高い位置を抽出する。
対称的にregression-basedの手法ではピンポイントに各関節位置を求める。
例えば21関節モデルでは、各関節の(x,y,z)を推定するので21*3のニューロンが出力層に用意される事になる。
高度な非線形性のためにregression-basedのネットワークはdetection-basedよりも多くのデータを必要とする。
しかし、ネットワークにとって関節ごとの3次元の確率密度関数を得るまでが大変であるため、
3Dのhand pose推定ではregression-basedネットワークが使われる。
## 3.1 Depth-based Methods
伝統的に、手や体のポーズ推定ではデプスマップイメージベースの手法が主だった。
regression-baseの手法Sinha et al.[^39]では、指ごとに独立した異なるネットワークを使って位置推定を行った。
留意するべき点としては、この手法では推定にデプスマップを使っていたが、元のデータから手を切り出すためにRGBを使っていた。
その手法の筆者は次の論文で独立したネットワークを使う手法を使っていなかったことについて、サーベイ論文の筆者は「十中八九コンピュータ性能の限界によるものだろう」と推測している。

[^2]ではGANを使って、デプス視差マップと3Dのハンドポーズモデルの関係性から1対1の対応付けしてポーズ推定を行った。
詳細には触れられていないので、リンクを要参照。
また、Conditioned GAN[^27]によりGeneratorの初期重みをランダムに決めない方法が紹介されている。
CyclicGAN [^59]を使った研究もあり、その研究ではdomainから画像を生成する。

Geet al.[9][10]の研究では、深度ベースの手法を用いた。
中心的なアイデアとしては、2.5Dイメージから3Dイメージを推定することと、別視点からの位置推定を行うことが挙げられる。しかしこの論文ではデプスマップから3Dイメージが作られる方法について明言しておらず信用できない。
デプスマップをVoxelに変換した後に推定する手法について紹介する。
- Step1
Voxel変換
- Step2
Voxelを3つの視点(front, top, side)でそれぞれレンダリングする
- Step3
Voxel座標に対してPCAを用いて、上位3つの軸に対してレンダリングする
それぞれのdepthmapに対してxy, xz, yz平面ごとに関節位置の確率を得る.
- Step4
ここまでで得られた出力を合わせて確率を出力する。
> As we know, depth maps only give us a surface of a hand, not a 3D shape. To estimate the 3D shape, they fix the camera in a 3D space and fix a surface as the farthest point in the camera’s sight. So for every pixel in the depth map, proportional to the distance number, they should put voxels from that surface to the camera. With this method, the depth map produced from these voxels and the original depth map are the same. In the next step, they have to render these 3D volume from three perpendicular views; front, top and the side. To this end, they applied a Principle Component Analysis (PCA) on voxel’s coordinates and picked the top three principal components and rendered 3D shape on those planes. They passed these depth maps to the network and got a probability for each joint in each xy, xz and yz planes. In the next step which they call fusion step, they mix the probabilities by multiplying them together.
[10]では似たようなアプローチで、3つの異なるCNNを用いた。
2Dレンダーの代わりに、Truncated Signed Distance Function (TSDF)を用いて3つの3Dレンダーを生成している。

PointNet[29]をHandPoseEstimationに適応したGeet al.[8]の研究(HandPointNet)について紹介する。
入力点群をPCAによって回転させる。その後にPointNetのネットワークで回帰を行う。
Geet al.は続けて次の論文[11]でそのネットワーク構造を変えて、エンコーダ・デコーダのような構造を取り入れた。これによってネットワークはまずglobal情報を学び、関節位置推定に必要な望ましいglobal情報を扱うようになる。
> This structure first learns a global features and then using these global features it generates the desirable number of points used for estimating the position of joints.
今までのネットワークはInputとOutputが3Dだったが、V2V-posenetは中間層でも3DのCNNを使った。様々な姿勢を学習させるために巨大なデータセットを使って学習する必要がある。

また、ResNet[14]によりresidual blocksの有効性が示された後に、Moon et al.らはResidualBlockをより深いネットワークに使った。そのアルゴリズムをデプスベースの有名なHandPoseDatasetに適応して主な手法と比較した。
## 3.2 Image-based Methods
RGB画像を入力とするモデルが普遍的で様々な分野でよい結果を得ているにも関わらず、2.5Dから2Dに次元を削減するのは極端に難しい。
同じような構造を持つネットワークを学習させるためにはデプスマップよりもRGB画像のほうが多くのデータを必要とする。
上位のImageベースの手法は、複雑なアノテーションかつ大きなデータセットを必要とするとこから、多くの研究ではデータセットを自作している。
==Image-basedでは手の領域を抽出(Crop, Resize)してから、抽出した画像を姿勢推定ネットワークに渡す必要がある.==
==多くの論文では、この前処理に**手の領域抽出にSegNet[1]を使っている**==
SegNetはセグメンテーションを行うようにデザインされており、入力画像を手かそうではないかのバイナリ画像を出力する。
これは一般的なセグメンテーションタスクよりも簡単な問題であるため、普通のSegNetを軽量化して使う。
RGB-basedの重要な手法として、Zimmermann et al.[60]について紹介する。
入力はRGBで、出力は3Dの関節位置である。
特徴的な点は4つの異なるディープラーニングモジュールを使っていることだ。
まず入力画像から手の位置を得るために、Wei et al.’s [52](human body detector trained on hand datasets)を軽量化したHandSegNetを使う。
HandSegNetの出力から手の矩形を元画像から切り出し、手が写ったRGB画像をPoseNetに与える。
出力として2Dの各関節HeatMapを得る(出力サイズは入力と同じ)。
**そしてここからが特に興味深く、2Dの予測を3Dの予測にするため、Zimmermannが提案するPosePriorを用いてregressionを行う。**
**出力は距離は最も遠い関節で1になるように正規化(normalize)された三次元座標として設計する**
最後に、回転行列を取得するネットワークから三次元座標を得る。
この手法は示唆に富んでおり、
最終的なモジュールに至るまでにRGBからHeatMap(データ的にはグレースケール)にすることで学習に必要なデータ数を減らしていることなどは興味深い点であった。
しかし、関節HeatMapから手の位置を推定するのは流石に無理があるのではないだろうか?

カーネギーメロン大学の研究では、球状の部屋で500を超えるカメラを配置して様々な角度から撮影を行った。

Mueller et al.[23]らはオクルージョンの克服や膨大なデータセットのアノテーションのために、自動的に作られたアノテーション済み合成データセットを使った。
シュミレータ上で三次元位置のアノテーションを自動生成する。
この手法は簡単にアノテーションデータを得ることができるが、汎化性が無く現実世界でうまく動作しない。
この問題を克服するため、彼らはconditioned GAN (GeoConGAN)[27]を使ってシミュレータ画像を現実の画像のように変換した。
また、シミュレータ画像と現実画像を一対一に対応付けるためにCyclicGAN [59]を適用した。
さらに、シミュレータ上でカメラと手の間に物体を置くことでオクルージョンを再現した。
また、残差モジュールを使うためにResNet[14]により特徴量抽出を行い、2Dの関節位置HeatMapと3D関節位置推定を行った。==(要1次情報の参照)==

### 3.3 RGBD
Dibra et al.[5] SynthNet シュミレータからデプス画像を得る?
Dibraの手法は手のモデルを使っていないが、手の生体構造(anatomy)を使っている。

Kazakos et al.in [18]の手法では、depth disparity mapsとRGB imageを入力としたFuseNetを使った。
FuseNetでは、入力をそれぞれを独立したCNNで処理して特徴量マップを抽出する。出力層で(x,y,z)の座標を回帰で求める。==しかし興味深いことに、2つの入力をとっているにも関わらず、それぞれのマップのみを入力とした場合よりも結果が悪くなった。==
(CNNの層が多すぎなのが原因か?)

## 4. Datasets
興味深いものに、GANerated Hand Datasetというデータセットがある。
これは、オクルージョンのあるデータセットを作るためにCycleGANで手の上にオブジェクトを配置した画像を生成したDatasetである。
## Conclusion
ここで説明した論文はこれらのデータセットで良い結果を示していますが、現実世界の問題で満足のいく結果を得ることはできません。
最も重要なことは、これらのシステムのほとんどの結果は単純な最近傍ベースラインよりも悪いということ。
## 参考文献
 Sign in with Wallet
Connect another wallet
Sign in with Wallet
Connect another wallet