# [Linux 核心 Copy On Write 實作機制](https://hackmd.io/@linD026/Linux-kernel-COW-content)
contributed by < [`linD026`](https://github.com/linD026) >
###### tags: `Linux kernel COW` , `linux2021`
> <font size = 2>此篇所引用之原始程式碼皆以用 Linux Kernel 5.10 版本,並且有關於硬體架構之程式碼以 arm 為主。</font>
---
## Copy On Write 概念
```graphviz
digraph abstract {
rankdir = LR
node [shape = record]
label = "Copy on Write"
proc1 [label = "process 1"]
proc2 [label = "process 2"]
memory [label = "main\nmemory|||<3>page 3|<4>|<5>page 5||<7>copy of\n page 5|"]
proc1 -> memory:4[style = invis]
proc1 -> memory:4[style = invis]
memory:4 -> proc2 [style = invis]
proc1 -> memory:3
proc1 -> memory:5[label = "write"]
proc2 -> memory:3
proc2 -> memory:5
proc1 -> memory:7[label = "redirect"]
}
```
一般來說,每個 process 都有屬於自己私人的記憶體空間,如 heap , stack , BSS , data 等。但是 processes 之間也可能會使用到相同的資源,例如在寫 C 語言使用的 libc 。這些不會修改到資源就可以透過 virtual address , MMU 等提供的 address 轉換機制得以使用相同資源而不作不必要的複製。
上述手法為 virtual memory 的 sharing ,而 Copy On Write ( COW ) 則為此延伸。
以下為維基百科對 COW 的說明:
**Wikipedia**
> Copy-on-write (COW), sometimes referred to as implicit sharing or shadowing, is a resource-management technique used in computer programming to efficiently implement a "duplicate" or "copy" operation on modifiable resources.
>
> **If a resource is duplicated but not modified, it is not necessary to create a new resource; the resource can be shared between the copy and the original. Modifications must still create a copy**, hence the technique: the copy operation is deferred until the first write. By sharing resources in this way, it is possible to significantly reduce the resource consumption of unmodified copies, while adding a small overhead to resource-modifying operations.
而在實作上多個 process 使用相同資料時,在一開始只會 loading 一份資料,並且被標記成 read-only 。當有 process 要寫入時則會對 kernel 觸發 page fault ,進而使得 page fault handler 處理 copy on write 的操作。
整體流程如下:
```graphviz
digraph schel {
rankdir = LR
node [shape = box]
label = "1"
read_only [label = "read-only\ndata"]
process [label = "process A"]
process -> read_only[label = "write\nsearch in PTE"]
subgraph cluster_kernel {
label = "kernel"
pf [label = "page fault handler"]
}
read_only -> pf [label = "page fault"]
}
```
```graphviz
digraph schel {
rankdir = LR
node [shape = box]
label = "2"
read_only [label = "read-only\ndata"]
subgraph cluster_kernel {
label = "kernel"
pf [label = "page fault handler"]
}
pf -> read_only [label = ""]
write [label = "copyed\ndata\n(mark writable)"]
read_only -> write [label = "copy\nupdate process A's PTE"]
{rank = same read_only write}
}
```
```graphviz
digraph schel {
rankdir = LR
node [shape = box]
label = "3"
write [label = "copyed\ndata"]
process [label = "process"]
process -> write[label = "write again\n but will find out the \ncopyed data"]
}
```
在 COW 機制當中,對此唯讀資料進行複製的操作,稱為 breaking COW 。
### process
在 Linux 裡 [**Everything is a file descriptor**](https://unix.stackexchange.com/questions/225537/everything-is-a-file) ,file 又有明確的 memory 和 address ,因此當我們在建立一個新的 process 所用到的資料也可以利用 COW 的機制作最佳化。
:::warning
> The virtual filesytem is an interface provided by the kernel. Hence the phrase was corrected to say **"Everything is a file descriptor"**. Linus Torvalds himself corrected it again a bit more precisely: **"Everything is a stream of bytes"**.
:::
根據 [Wikipedia](https://en.wikipedia.org/wiki/Copy-on-write):
> Copy-on-write finds its main use in sharing the virtual memory of operating system processes, in the implementation of the fork system call. **Typically, the process does not modify any memory and immediately executes a new process, replacing the address space entirely.** Thus, it would be wasteful to copy all of the process's memory during a fork, and instead the copy-on-write technique is used.
[`fork` system call](https://en.wikipedia.org/wiki/Fork_(system_call)) 會建立新的 process ,而在 Linux 當中它會先複製原先 process 的 mm_struct , vm_area_struct 以及 page table ,並且讓每個 page 的 flag 設為 read-only 。最後,當有作更改時則會利用 COW 機制進行處理。
---
# Virtual Memory
```graphviz
digraph linux_VM {
rankdir = LR
node [shape = record]
label = "Linux kernel - Virtual Memory"
task [label = "task_struct||<mm>mm||"]
mm [label = "mm_struct|<pgd>pgd||<m>mmap||"]
task:mm -> mm:pgd
vma1 [label = "vm_area_struct|<e>vm_end|<s>vm_start|vn_prot|vm_flags||<n>vm_next"]
vma2 [label = "vm_area_struct|<e>vm_end|<s>vm_start|vn_prot|vm_flags||<n>vm_next"]
vma3 [label = "vm_area_struct|<e>vm_end|<s>vm_start|vn_prot|vm_flags||<n>vm_next"]
mm:m -> vma1:e
vma1:n -> vma2:e
vma2:n -> vma3:e
{rank = same mm vma2}
main [label = "process virtual memory||<s>shared libraries||<d>Data|<t>Text|"]
vma1:e -> main:s
vma1:s -> main:s
vma2:e -> main:d
vma2:s -> main:d
vma3:e -> main:t
vma3:s -> main:t
}
```
在細部探討 COW 之前,需要先理解記憶體管理中虛擬記憶體的機制。現代作業系統提供了虛擬記憶體作為記憶體管理的一部份。虛擬記憶體的作法很簡單,就是把 physical address ( PA )轉換成 virtual address (VA)。而透過 address translation 使用更自由的 VA 使得資料抽離出原先硬體上的 PA 。這可以很好的處裡 process 記憶體之間的干擾、硬體之間的記憶體轉換、 RAM 等記憶體不足問題等。而在 Linux kernel 也中使用了較抽象的虛擬記憶體作為管理,而非實體記憶體,這是為了有更高效率以及較低錯誤。
1. 提升資料儲存在 cache / main memory 中的效率。因為記憶體有限,讀取不同 memory hierarchy 所造成的讀取時間成本也不同。而為了能夠有效率、花費時間少的就必須只留下需要用到的資料,也讓就的資料有更好的 locality 。
2. 提供了統一的 address space 使得在多個硬體和 process 之間能夠有更好的管理。
3. 因為並非 PA 因此可以讓每個 process 擁有自己的 VA ,讓彼此之間不互相影響。也因此使得 COW 得以更有效率的實現。
至於從 PA 轉換成 VA 則是經由 MMU ( Memory management Unit )達成,並且 CPU 對記憶體的操作都是虛擬記憶體。
:::info
關於 arm 的 MMU 可以看: [FreeRTOS (MMU)](http://wiki.csie.ncku.edu.tw/embedded/freertos-mmu) 中的 ARMv7-A MMU Architecture 。
:::
## Page Table
作為記憶體管理的最小單位 page ,一般來說大小是 4KB 至 2 MB ,在 Linux 當中是 4 KB 。
為了讓資料的 page 能夠確認是否儲存於 cache / main memory 中,以及建構上述替換不必要的 page 稱為 swapping ,作業系統會建構 page table 來進行處理。一般來說,每個 process 都有自己的 Page table 。如果只有一個 Page table ,則其 page table entry ( PTE ) 會儲存 PA 。
當 process 在 cache / memory 中的 page table 找不到想要的 page fault 就會出發 page fault exception ,而如果只是目標 page 不在此 cache 在 disk 中,則會進行 swapping 。若是其他況,則讓 fault handler 進而作對應的處置(如超出可讀取範圍的 segmentation fault 、寫入 read-only 的 object 、在 user mode 更改 kernel mode 的資料等)。
```graphviz
digraph pte {
rankdir = LR
label = "Address Translation"
node [shape = box]
m [label = "cache/\nmemory||<p>page table|<e>|<t>", shape = record]
subgraph cluster_chip {
label = "chip"
CPU, MMU
CPU -> MMU[label = "1.Virtual\nAddress"]
}
MMU -> m:p [label = "\n2.PTE Address"]
m:p -> MMU [label = "3.PTE"]
MMU -> m:e [label = "4.Phyiscal Address"]
}
```
但這種儲存結構對讀取的速度可能會太慢,並不是說結構上有缺陷而是在存取 page table 的硬體上有所限制。大體上 SRAM 、 DRAM 、 disk 的讀取速度都會有落差,而為了讓尋找 PTE 的時間能夠更加簡短,會在 MMU 之中設置 small cache 存放最近使用的 PTE 。
```graphviz
digraph pte {
rankdir = LR
label = "Address Translation with TLB ( Translation Lookaside Buffer)"
CPU [shape = box label = "CPU"]
PT [shape = box label = "Translation"]
memory [shape = record label = "main\nmemory|||"]
TLB [shape = box label ="TLB"]
CPU -> PT [label = "virtual\naddress"]
subgraph cluster_mmu {
label = "MMU"
PT -> TLB [label = "VPN "]
TLB -> PT [label = " PTE"]
{rank = same TLB PT}
}
PT -> memory [label = "physical\naddress"]
}
```
### Multi-Level Page Tables
上述所說都是針對單一 page table ,然而可能因 page 和 PTE 的關係導致 page table 記憶體過大,卻又需要常駐於 main memory 之中。
若以單個 page table 並以 64-bit address space , page size 4 KB , PTE 4 bytes 為例:
$$
\frac{2^{\mathrm{AddressSpace}}}{2^{\mathrm{PageSize}}} = \mathrm{TotalPages} = \frac{2^{64}}{2^{12}} = 2^{52}\ \mathrm{pages}
$$
$$
\mathrm{PageTableSiz}e = 2^{52}\ \mathrm{pages} \times 4\ \mathrm{bytes} = 2^{54}\ \mathrm{bytes} = 16\ \mathrm{PB}
$$
需要常駐 16 PB 大小的 page table 才可以概括整個 64-bit address space 。
若以 Intel Core i7 為例,其可支援到 52-bit physical address space ( 4 PB ),因此雖然現今確實不太會用到 PB 等級的 address space ,但仍需要一個更好的方法來減少 page table 對 main memory 的使用。
因此,有人提出了 multi-Level page table 對 page table 在進行多次的 page table 處理。以下是 3 level page tables 轉換 VA 至 PA 的圖示:
```graphviz
digraph main {
label = "3 Level of Page Tables"
rankdir = LR
node [shape = record]
VA [label = "Virtural address|{<v1>VPN 1\n(offset within\nL1 Page Table)|<v2>VPN 2\n(offset within\nL2 Page Table)|<v3>VPN 3\n(offset within\nL3 Page Table)|<o>VPO}"]
PA [label = "{<p>PPN|<0>PPO}|Physical address"]
VA:o -> PA:0
L1 [label = "<h>L1 Page Table||<t> address of\nL2 Page table|"]
L2 [label = "<h>L2 Page Table||<t> address of\nL3 Page table|"]
L3 [label = "<h>L3 Page Table||<t> address of\n Physical address|"]
VA:v1 -> L1:t [label = "VPN 1 offset"]
L1:t -> L2:h
L2:h -> L2:t
L2:t -> L3:h
L3:h -> L3:t
L3:t -> PA:p
}
```
一般來說,每個 level 的 page table 的大小是以實際 physical page frame 大小為主。
### Linux kernel - Multi-Level Page Tables
> [Chapter 3 Page Table Management - Linux kernel 2.6](https://www.kernel.org/doc/gorman/html/understand/understand006.html)
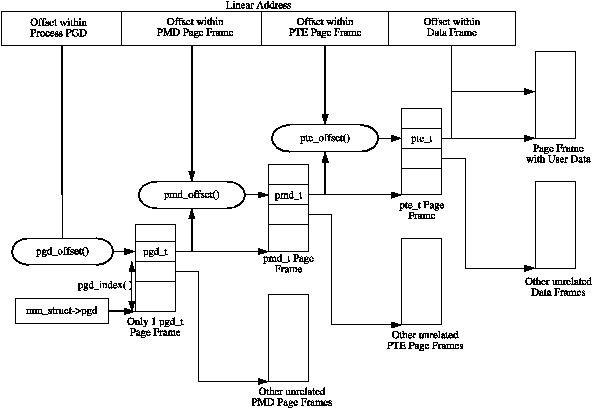
在 Linux kernel 中,每個 process 都有屬於自己的 multi-level page tables ,以每個 process 獨立擁有的 `mm_struct` 結構中的指標 `mm_struct->pgd` 指向屬於自己的 **Page Global Directory ( PGD )** 。此指標所指向的 physical page frame 含有 an array type of `pgd_t` ,其定義於 `<asm/page.h>` 標頭檔 ,而這會根據不同的硬體夠而有所不同。
> Each active entry in the **PGD** table points to a page frame containing an array of **Page Middle Directory (PMD) entries** of type **pmd_t** which in turn points to page frames containing **Page Table Entries (PTE)** of type **pte_t**, which finally points to page frames containing the actual user data. In the event the page has been swapped out to backing storage, the swap entry is stored in the PTE and used by do_swap_page() during page fault to find the swap entry containing the page data.
:::success
**延伸閱讀 - context switch**
* [/arch/arm/include/asm/mmu_context.h](https://elixir.bootlin.com/linux/v5.10.41/source/arch/arm/include/asm/mmu_context.h#L145)
```cpp
/*
* This is the actual mm switch as far as the scheduler
* is concerned. No registers are touched. We avoid
* calling the CPU specific function when the mm hasn't
* actually changed.
*/
static inline void
switch_mm(struct mm_struct *prev, struct mm_struct *next,
struct task_struct *tsk)
{
#ifdef CONFIG_MMU
unsigned int cpu = smp_processor_id();
/*
* __sync_icache_dcache doesn't broadcast the I-cache invalidation,
* so check for possible thread migration and invalidate the I-cache
* if we're new to this CPU.
*/
if (cache_ops_need_broadcast() &&
!cpumask_empty(mm_cpumask(next)) &&
!cpumask_test_cpu(cpu, mm_cpumask(next)))
__flush_icache_all();
if (!cpumask_test_and_set_cpu(cpu, mm_cpumask(next)) || prev != next) {
check_and_switch_context(next, tsk);
if (cache_is_vivt())
cpumask_clear_cpu(cpu, mm_cpumask(prev));
}
#endif
}
```
其中 `check_and_switch_context(struct mm_struct *mm, struct task_struct *tsk)` 在 arm 架構中,會根據是否有 [ASID ( Address Space Identifier )](https://community.arm.com/developer/ip-products/processors/f/cortex-a-forum/5229/address-space-identifier---asid) 而有不同的定義:
* [/arch/arm/mm/context.c](https://elixir.bootlin.com/linux/v5.10.41/source/arch/arm/mm/context.c#L237)
```cpp
/*
* On ARMv6, we have the following structure in the Context ID:
*
* 31 7 0
* +-------------------------+-----------+
* | process ID | ASID |
* +-------------------------+-----------+
* | context ID |
* +-------------------------------------+
*
* The ASID is used to tag entries in the CPU caches and TLBs.
* The context ID is used by debuggers and trace logic, and
* should be unique within all running processes.
*
* In big endian operation, the two 32 bit words are swapped if accessed
* by non-64-bit operations.
*/
```
> * [有 ASID](https://elixir.bootlin.com/linux/v5.10.41/source/arch/arm/mm/context.c#L237) / [無 ASID](https://elixir.bootlin.com/linux/v5.10.41/source/arch/arm/include/asm/mmu_context.h#L50)
在此函式當中,都有 `cpu_switch_mm(mm->pgd, mm);` 這段操作,亦即當在進行 context switch 時,關於每個 process ( task ) 的相關記憶體資訊,會需要切換 `mm_struct->pgd` 。
有關 `cpu_switch_mm` 操作,幾乎都定義於 [/arch/arm/include/asm/proc-fns.h](https://elixir.bootlin.com/linux/v5.10.41/source/arch/arm/include/asm/proc-fns.h) 之中:
```cpp
cpu_switch_mm(pgd,mm) cpu_do_switch_mm(virt_to_phys(pgd),mm)
#define cpu_do_switch_mm PROC_VTABLE(switch_mm)
#if defined(CONFIG_BIG_LITTLE) && defined(CONFIG_HARDEN_BRANCH_PREDICTOR)
#define PROC_VTABLE(f) cpu_vtable[smp_processor_id()]->f
#else
#define PROC_VTABLE(f) processor.f
struct processor {
/*
* Set the page table
*/
void (*switch_mm)(phys_addr_t pgd_phys, struct mm_struct *mm);
}
```
此外,也可看此篇:[Evolution of the x86 context switch in Linux](https://www.maizure.org/projects/evolution_x86_context_switch_linux/)
:::
:::warning
**x86 - pgd 和 TLB**
> On the x86, the process page table is loaded by copying `mm_struct->pgd` into the cr3 register which has the side effect of flushing the TLB. In fact this is how the function `__flush_tlb()` is implemented in the architecture dependent code.
> **設定分頁功能**
>在控制暫存器(control registers)中,有三個和分頁功能有關的旗標:PG(CR0 的 bit 31)、PSE(CR4 的 bit 4,在 Pentium 和以後的處理器才有)、和 PAE(CR4 的 bit 5,在 Pentium Pro 和 Pentium II 以後的處理器才有)。
>* PG(paging)旗標設為 1 時,就會開啟分頁功能。
>* PSE(page size extensions)旗標設為 1 時,才可以使用 4MB 的分頁大小(否則就只能使用 4KB 的分頁大小)。
>* 而 PAE(physical address extension)是 P6 家族新增的功能,可以支援到 64GB 的實體記憶體(本文中不說明這個功能)。
>
> **分頁目錄和分頁表**
>分頁目錄和分頁表存放分頁的資訊(參考「記憶體管理」的「緒論」)。**分頁目錄的基底位址是存放在 CR3(或稱 PDBR,page directory base register),存放的是實體位址**。在開啟分頁功能之前,一定要先設定好這個暫存器的值。在開啟分頁功能之後,可以用 MOV 命令來改變 PDBR 的值,而在工作切換(task switch)時,也可能會載入新的 PDBR 值。也就是說,每一個工作(task)可以有自己的分頁目錄。在工作切換時,前一個工作的分頁目錄可能會被 swap 到硬碟中,而不再存在實體記憶體中。不過,在工作被切換回來之前,一定要使該工作的分頁目錄存放在實體記憶體中,而且在工作切換之前,分頁目錄都必須一直在實體記憶體中。
>
> **Translation Lookaside Buffers(TLBs)**
>只有 CPL 為 0 的程序才能選擇 TLB 的 entry 或是把 TLB 設為無效。無論是在更動分頁目錄或分頁表之後,都要立刻把相對的 TLB entry 設為無效,這樣在下次取用這個分頁目錄或分頁表時,才會更新 TLB 的內容(否則就可能會從 TLB 中讀到舊的資料了)。
要把 TLB 設為無效,**只要重新載入 CR3 就可以了。要重新載入 CR3,可以用 MOV 指令(例如:MOV CR3, EAX),或是在工作切換時,處理器也會重新載入 CR3 的值**。此外,INVLPG 指令可以把某個特定的 TLB entry 設成無效。不過,在某些狀況下,它會把一些 TLB entries 甚至整個 TLB 都設為無效。INVLPG 的參數是該分頁的位址,處理器會把 TLB 中存放該分頁的 entry 設為無效。
>> 引自:[ntu - 分頁架構](https://www.csie.ntu.edu.tw/~wcchen/asm98/asm/proj/b85506061/chap2/paging.html)
:::
### Linux kernel - linear address macro
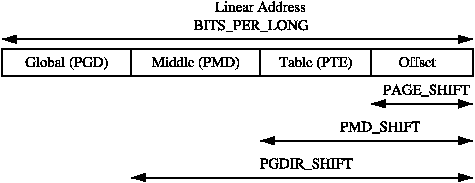
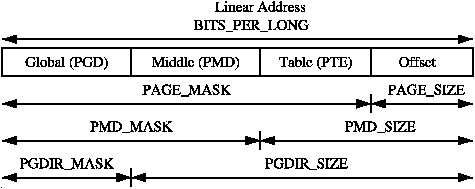
size of a page $2^{PAGE\_SHIFT}$
page align is PAGE_SIZE - 1 + (x) & PAGE_MASK
相關 [offset](https://elixir.bootlin.com/linux/v5.10.38/source/include/linux/pgtable.h#L88) 和得到 [index](https://elixir.bootlin.com/linux/v5.10.38/source/include/linux/pgtable.h#L31) 操作也是如此。
### Example of arm
:::warning
arm 架構的 page tables 有 two-level 和 three-level ,在此先以 three-level 為主。
:::
`PAGE_ALGIN()` 統一定義在 `mm.h` 裡:
* [`/arch/arm/include/asm/page.h`](https://elixir.bootlin.com/linux/v5.10.38/source/arch/arm/include/asm/page.h#L12)
```cpp
/* PAGE_SHIFT determines the page size */
#define PAGE_SHIFT 12
#define PAGE_SIZE (_AC(1,UL) << PAGE_SHIFT)
#define PAGE_MASK (~((1 << PAGE_SHIFT) - 1))
```
* [`/include/linux/mm.h`](https://elixir.bootlin.com/linux/v5.10.38/source/include/linux/mm.h#L222)
```cpp
#ifdef __KERNEL__
...
/* to align the pointer to the (next) page boundary */
#define PAGE_ALIGN(addr) ALIGN(addr, PAGE_SIZE)
...
```
* [`/include/linux/kernel.h`](https://elixir.bootlin.com/linux/v5.10.38/source/include/linux/kernel.h#L33)
```cpp
#define ALIGN(x, a) __ALIGN_KERNEL((x), (a))
```
* [`/include/linux/const.h`](https://elixir.bootlin.com/linux/v5.10.38/source/include/linux/const.h) 和 [`/include/uapi/linux/const.h`](https://elixir.bootlin.com/linux/v5.10.38/source/include/uapi/linux/const.h)
```cpp
#define __ALIGN_KERNEL(x, a) __ALIGN_KERNEL_MASK(x, (typeof(x))(a) - 1)
#define __ALIGN_KERNEL_MASK(x, mask) (((x) + (mask)) & ~(mask))
```
實際操作會像是:
```cpp
#define _AC(X,Y) X
#define _UL(x) (_AC(x, UL))
#define UL(x) (_UL(x))
#define PAGE_SHIFT 12
#define PAGE_SIZE (_AC(1,UL) << PAGE_SHIFT)
#define PAGE_MASK (~((1 << PAGE_SHIFT) - 1))
void addr_test(void) {
printf("page size is %u\n", PAGE_SIZE);
unsigned long addr;
addr = (unsigned long)&addr;
printf("address is %lx\n", addr);
printf("Page align is %lx\n", PAGE_SIZE - 1 + (addr) & PAGE_MASK);
}
page size is 4096
address is 7ffdfc0060c0
Page align is 7ffdfc007000
```
各個層級的 page table 型態有兩種定義方式,一種是沒有作 C type-checking 直接以 `pteval_t` 的形式定義 `pte_t` ,另一種是則是在 `STRICT_MM_TYPECHECKS` 下以結構方式定義:
> As mentioned, each entry is described by the structs pte_t, pmd_t and pgd_t for PTEs, PMDs and PGDs respectively. Even though these are often just unsigned integers, they are defined as structs for two reasons. **The first is for type protection so that they will not be used inappropriately. The second is for features like [PAE](https://en.wikipedia.org/wiki/Physical_Address_Extension) on the x86 where an additional 4 bits is used for addressing more than 4GiB of memory.** To store the protection bits, pgprot_t is defined which holds the relevant flags and is usually stored in the lower bits of a page table entry.
* [/arch/arm/include/asm/pgtable-3level-types.h](https://elixir.bootlin.com/linux/v5.10.38/source/arch/arm/include/asm/pgtable-3level-types.h#L13)
```cpp
typedef u64 pteval_t;
typedef u64 pmdval_t;
typedef u64 pgdval_t;
```
* [/arch/arm/include/asm/pgtable-3level-types.h](https://elixir.bootlin.com/linux/v5.10.38/source/arch/arm/include/asm/pgtable-3level-types.h#L29)
```cpp
typedef struct { pteval_t pte; } pte_t;
typedef struct { pmdval_t pmd; } pmd_t;
typedef struct { pgdval_t pgd; } pgd_t;
typedef struct { pteval_t pgprot; } pgprot_t;
#define pte_val(x) ((x).pte)
#define pmd_val(x) ((x).pmd)
#define pgd_val(x) ((x).pgd)
#define pgprot_val(x) ((x).pgprot)
#define __pte(x) ((pte_t) { (x) } )
#define __pmd(x) ((pmd_t) { (x) } )
#define __pgd(x) ((pgd_t) { (x) } )
#define __pgprot(x) ((pgprot_t) { (x) } )
```
以下為不做 C type-checking :
* [/arch/arm/include/asm/pgtable-3level-types.h](https://elixir.bootlin.com/linux/v5.10.38/source/arch/arm/include/asm/pgtable-3level-types.h#L29)
```cpp
/* !STRICT_MM_TYPECHECKS */
typedef pteval_t pte_t;
typedef pmdval_t pmd_t;
typedef pgdval_t pgd_t;
typedef pteval_t pgprot_t;
#define pte_val(x) (x)
#define pmd_val(x) (x)
#define pgd_val(x) (x)
#define pgprot_val(x) (x)
#define __pte(x) (x)
#define __pmd(x) (x)
#define __pgd(x) (x)
#define __pgprot(x) (x)
```
### Using Page Tables
在任何 level 的 page table ,其指向下一個 level 的指標可以是 null ,這意味著那段區間的 VA 是不允許操作的 ( no valid ) 。而在 The middle levels 的指標也可以直接指向較大範圍的 physical page ,而非下一個 level 。例如, PMD level 可以指向 huge page ( 2MB )。
> At any level of the page table, the pointer to the next level can be null, indicating that there are no valid virtual addresses in that range. This scheme thus allows large subtrees to be missing, corresponding to ranges of the address space that have no mapping. The middle levels can also have special entries indicating that they point directly to a (large) physical page rather than to a lower-level page table; that is how huge pages are implemented. A 2MB huge page would be found directly at the PMD level, with no intervening PTE page, for example.
> | Bit | Function |
> |:----------------:|:----------------------------------------------:|
> | `_PAGE_PRESENT` | Page is resident in memory and not swapped out |
> | `_PAGE_PROTNONE` | Page is resident but not accessable |
> | `_PAGE_RW` | Set if the page may be written to |
> | `_PAGE_USER` | Set if the page is accessible from user space |
> | `_PAGE_DIRTY` | Set if the page is written to |
> | `_PAGE_ACCESSED` | Set if the page is accessed |
> > **Table 3.1: Page Table Entry Protection and Status Bits**
#### present and used
> * `pte_none()`, `pmd_none()` and` pgd_none()` return 1 if the corresponding entry does not exist;
> * `pte_present()`,` pmd_present()` and `pgd_present()` return 1 if the corresponding page table entries have the PRESENT bit set;
> * `pte_clear()`,` pmd_clear()` and` pgd_clear()` will clear the corresponding page table entry;
> * `pmd_bad()` and `pgd_bad()` are used to check entries when passed as input parameters to functions that may change the value of the entries. Whether it returns 1 varies between the few architectures that define these macros but for those that actually define it, making sure the page entry is marked as present and accessed are the two most important checks.
### Protect
Linux 有三種 protect ,分別是 read 、 write 、 execute 。一般來說,會以 `pte_mk*` 開頭名稱作為設定 protect 的種類。譬如, write 為 `pte_mkwrite()` 、 execute 為 `pte_mkexec()` 等。而清除已設置的 protect 則以 `pte_wrprotect()` 、 `pte_exprotect()` 等函式。
根據註解說明在 arm 架構利用 write 來實作 read 。從下方程式碼中可以看出,在清除 write 的時候會被設為 read only ,而在標為 write 的時候則會清出原先的 read 設定。
* [root/arch/arm/include/asm/pgtable.h](https://git.kernel.org/pub/scm/linux/kernel/git/stable/linux.git/tree/arch/arm/include/asm/pgtable.h?h=v5.10.42#n132)
```cpp
/*
* The table below defines the page protection levels that we insert into our
* Linux page table version. These get translated into the best that the
* architecture can perform. Note that on most ARM hardware:
* 1) We cannot do execute protection
* 2) If we could do execute protection, then read is implied
* 3) write implies read permissions
*/
```
* [root/arch/arm/include/asm/pgtable.h](https://git.kernel.org/pub/scm/linux/kernel/git/stable/linux.git/tree/arch/arm/include/asm/pgtable.h?h=v5.10.42#n237)
```cpp
static inline pte_t pte_wrprotect(pte_t pte)
{
return set_pte_bit(pte, __pgprot(L_PTE_RDONLY));
}
static inline pte_t pte_mkwrite(pte_t pte)
{
return clear_pte_bit(pte, __pgprot(L_PTE_RDONLY));
}
```
至於檢測是否有設 protect 可以用 `pte_write()` 、 `pte_exec()` 等檢測。
```cpp
#define pte_write(pte) (pte_isclear((pte), L_PTE_RDONLY))
#define pte_exec(pte) (pte_isclear((pte), L_PTE_XN))
```
:::info
**flag 相關函式以及 marco**
```cpp
static inline pte_t clear_pte_bit(pte_t pte, pgprot_t prot)
{
pte_val(pte) &= ~pgprot_val(prot);
return pte;
}
static inline pte_t set_pte_bit(pte_t pte, pgprot_t prot)
{
pte_val(pte) |= pgprot_val(prot);
return pte;
}
```
* [/arch/arm/include/asm/pgtable-3level.h](https://elixir.bootlin.com/linux/v5.10.42/source/arch/arm/include/asm/pgtable-3level.h#L77)
```cpp
/*
* "Linux" PTE definitions for LPAE.
*
* These bits overlap with the hardware bits but the naming is preserved for
* consistency with the classic page table format.
*/
#define L_PTE_XN (_AT(pteval_t, 1) << 54) /* XN */
#define L_PTE_SPECIAL (_AT(pteval_t, 1) << 56)
#define L_PTE_NONE (_AT(pteval_t, 1) << 57) /* PROT_NONE */
#define L_PTE_RDONLY (_AT(pteval_t, 1) << 58) /* READ ONLY */
```
**Execution permissions - PXN / XN**
> [Learn the architecture: AArch64 memory model - Permissions attributes](https://developer.arm.com/documentation/102376/0100/Permissions-attributes)
> These attributes let you specify that instructions cannot be fetched from the address:
> PXN. Privileged Execute Never (Called XN at EL3, and EL2 when HCR_EL2.E2H==0)
> These are Execute Never bits. This means that setting the bit makes the location not executable.
:::
:::warning
**protect modify**
> The permissions can be modified to a new value with pte_modify() but its use is almost non-existent. It is only used in the function change_pte_range() in mm/mprotect.c.
:::
#### dirty bit and accessed bit
> There are only two bits that are important in Linux, the dirty bit and the accessed bit. To check these bits, the macros pte_dirty() and pte_young() macros are used. To set the bits, the macros pte_mkdirty() and pte_mkyoung() are used. To clear them, the macros pte_mkclean() and pte_old() are available.
### Five-level page tables
> [lwn.net - Five-level page tables](https://lwn.net/Articles/717293/)
在 2005 年左右, Linux 2.6.10 合併了 four-level page tables patch 。
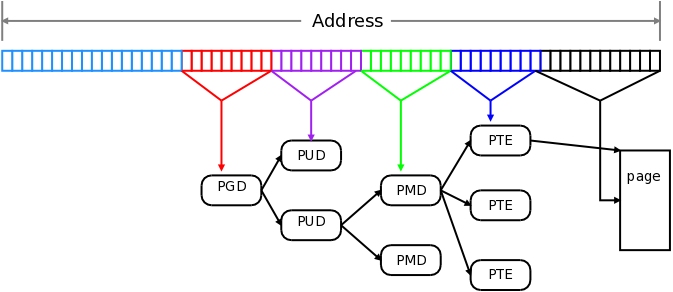
而在今日可以看到 Linux 在 4.11-rc2 開始新增了 five-level page tables 。在 PGD 和 PUD 之間有了新的 level - P4D 。
在 four-level 裡,address 的 valid bits ( VA ) 為最低位的 48-bits ,而 five-level 則是使用到 52-bits 或是 57-bits 的 VA 。
然而儘管以提供到 five-level ,在某些硬體或系統架構下,仍然是使用 three-level 更甚至 two-level ,就如前述的 arm 使用 three-level 或者是 32-bit 的系統也是使用 two-level 或是 three-level 一般。
也因為如此,記憶體管理的程式碼被撰寫成在 five-level page tables 結構下,可以容許只使用 low level 。因此,在觀看 arm 、 x86 等架構的 page table 管理時,儘管沒有用到程式碼所提供完整的 page table 功能也依然能夠運行。
關於實際例子,在 [Linux kernel - pte](https://hackmd.io/@linD026/Linux-kernel-COW-Copy-on-Write#Linux-kernel---pte) 有列出 arm 架構下在經由 `follow_pte` 函式從 page tables 中尋找目標 pte 。
### Linux kernel - pte
基本上 從 `mm_struct` 運用 `follow_pte` 函式得到 pte 的大致流程是:
```cpp=
pgd_t *pgd;
pmd_t *pmd;
pte_t *ptep, pte;
pgd = pgd_offset(mm, address);
if (pgd_none(*pgd) || pgd_bad(*pgd))
goto out;
pmd = pmd_offset(pgd, address);
if (pmd_none(*pmd) || pmd_bad(*pmd))
goto out;
ptep = pte_offset(pmd, address);
if (!ptep)
goto out;
pte = *ptep;
```
除此之外,還需要考慮到在 pmd level 時是否為 huge page ,以及取得 pte 後保護接下來操作的 lock 也要跟著回傳。
* [`/mm/memory.c - follow_pte`](https://elixir.bootlin.com/linux/v5.10.38/source/mm/memory.c#L4806)
```cpp
/**
* follow_pte - look up PTE at a user virtual address
* @mm: the mm_struct of the target address space
* @address: user virtual address
* @ptepp: location to store found PTE
* @ptlp: location to store the lock for the PTE
*
* On a successful return, the pointer to the PTE is stored in @ptepp;
* the corresponding lock is taken and its location is stored in @ptlp.
* The contents of the PTE are only stable until @ptlp is released;
* any further use, if any, must be protected against invalidation
* with MMU notifiers.
*
* Only IO mappings and raw PFN mappings are allowed. The mmap semaphore
* should be taken for read.
*
* KVM uses this function. While it is arguably less bad than ``follow_pfn``,
* it is not a good general-purpose API.
*
* Return: zero on success, -ve otherwise.
*/
int follow_pte(struct mm_struct *mm, unsigned long address,
pte_t **ptepp, spinlock_t **ptlp)
{
return follow_invalidate_pte(mm, address, NULL, ptepp, NULL, ptlp);
}
```
* [`follow_invalidate_pte`](https://elixir.bootlin.com/linux/v5.10.39/source/mm/memory.c#L4718)
```cpp
int follow_invalidate_pte(struct mm_struct *mm, unsigned long address,
struct mmu_notifier_range *range, pte_t **ptepp,
pmd_t **pmdpp, spinlock_t **ptlp)
{
pgd_t *pgd;
p4d_t *p4d;
pud_t *pud;
pmd_t *pmd;
pte_t *ptep;
pgd = pgd_offset(mm, address);
if (pgd_none(*pgd) || unlikely(pgd_bad(*pgd)))
goto out;
p4d = p4d_offset(pgd, address);
if (p4d_none(*p4d) || unlikely(p4d_bad(*p4d)))
goto out;
pud = pud_offset(p4d, address);
if (pud_none(*pud) || unlikely(pud_bad(*pud)))
goto out;
pmd = pmd_offset(pud, address);
VM_BUG_ON(pmd_trans_huge(*pmd));
if (pmd_huge(*pmd)) {
if (!pmdpp)
goto out;
if (range) {
mmu_notifier_range_init(range, MMU_NOTIFY_CLEAR, 0,
NULL, mm, address & PMD_MASK,
(address & PMD_MASK) + PMD_SIZE);
mmu_notifier_invalidate_range_start(range);
}
*ptlp = pmd_lock(mm, pmd);
if (pmd_huge(*pmd)) {
*pmdpp = pmd;
return 0;
}
spin_unlock(*ptlp);
if (range)
mmu_notifier_invalidate_range_end(range);
}
if (pmd_none(*pmd) || unlikely(pmd_bad(*pmd)))
goto out;
if (range) {
mmu_notifier_range_init(range, MMU_NOTIFY_CLEAR, 0, NULL, mm,
address & PAGE_MASK,
(address & PAGE_MASK) + PAGE_SIZE);
mmu_notifier_invalidate_range_start(range);
}
ptep = pte_offset_map_lock(mm, pmd, address, ptlp);
if (!pte_present(*ptep))
goto unlock;
*ptepp = ptep;
return 0;
unlock:
pte_unmap_unlock(ptep, *ptlp);
if (range)
mmu_notifier_invalidate_range_end(range);
out:
return -EINVAL;
}
```
:::success
**MMU notifier 機制**
> [lwn.net - Memory management notifiers](https://lwn.net/Articles/266320/)
> [lwn.net - A last-minute MMU notifier change](https://lwn.net/Articles/732952/)
當變更 page table 時,要確保 TLB 的相對地變成 invalidated 。
在方面的處理會需要 **[MMU notifier 機制](https://lwn.net/Articles/266320/)**,這在 2.6.27 被整合進來。最一開始的原因在於虛擬化, guest 端對記憶體操作時,為了資安考量並不准許實際操作 host 端的記憶體,而是利用在 guest 端管理一個 shadow page table。
guest 端當有需要操作時會在 shadow page table 進行,而 host 端會查看 guest 端的 shadow page table 來進行相對應的操作。這會產生幾個問題,比如當 host 端 swap 某個 guest 端所要用的 page 時,guest 端要如何得知此記憶體在 host 端被移出?原先 KVM 的解決方法是把被 guest mapped 的 page 固定在記憶體當中,然而這對 host 端記憶體使用效率很有問題。因此 MMU notifier 機制才被提出。
在這之後,又有許多裝置開始使用 memory bus ,如顯示卡有了自己的 MMU 等,而 MM 在對記憶體進行操作後,那些 non-CPU MMU 也需要更新,但 MM 卻不能直接干涉等相關議題也會用到此機制。
> More recently, other devices have appeared on the memory bus with their own views of memory; graphics processing units (GPUs) have led this trend with technologies like GPGPU, but others exist as well. To function properly, these non-CPU MMUs must be updated when the memory-management subsystem makes changes, but the memory-management code is not able (and should not be able) to make changes directly within the subsystems that maintain those other MMUs.
此機制的主要目的是准許子系統掛載 mm operations 與當變更 page table 時得到 callback。
```cpp
struct mmu_notifier_ops {
void (*release)(struct mmu_notifier *mn,
struct mm_struct *mm);
int (*age_page)(struct mmu_notifier *mn,
struct mm_struct *mm,
unsigned long address);
void (*invalidate_page)(struct mmu_notifier *mn,
struct mm_struct *mm,
unsigned long address);
void (*invalidate_range)(struct mmu_notifier *mn,
struct mm_struct *mm,
unsigned long start, unsigned long end);
};
```
> To address this problem, Andrea Arcangeli added the MMU notifier mechanism during the 2.6.27 merge window in 2008. **This mechanism allows any subsystem to hook into memory-management operations and receive a callback when changes are made to a process's page tables.** One could envision a wide range of callbacks for swapping, protection changes, etc., but the actual approach was simpler. **The main purpose of an MMU notifier callback is to tell the interested subsystem that something has changed with one or more pages; that subsystem should respond by simply invalidating its own mapping for those pages. The next time a fault occurs on one of the affected pages, the mapping will be re-established, reflecting the new state of affairs.**
而 `mmu_notifier_invalidate_range_start/end` 為此機制中的一種掛載方式之一。
> `mmu_notifier_invalidate_range_start/end` are just calling MMU notifier hooks; these hooks only exist so that other kernel code can be told when TLB invalidation is happening. The only places that set up MMU notifiers are
>
> * KVM (hardware assisted virtualization) uses them to handle swapping out pages; it needs to know about host TLB invalidations to keep the virtualized guest MMU in sync with the host.
> * GRU (driver for specialized hardware in huge SGI systems) uses MMU notifiers to keep the mapping tables in the GRU hardware in sync with the CPU MMU.
>
> [stackoverflow - Linux Kernel Invalidating TLB Entries](https://stackoverflow.com/questions/8381531/linux-kernel-invalidating-tlb-entries)
> In this case, `invalidate_range_start()` is called while all pages in the affected range are still mapped; no more mappings for pages in the region should be added in the secondary MMU after the call. When the unmapping is complete and the pages have been freed, `invalidate_range_end()` is called to allow any necessary cleanup to be done.
:::
### struct page to pte
* [/arch/arm/include/asm/pgtable.h](https://elixir.bootlin.com/linux/v5.10.38/source/arch/arm/include/asm/pgtable.h)
```cpp
#define pfn_pte(pfn,prot) __pte(__pfn_to_phys(pfn) | pgprot_val(prot))
#define mk_pte(page,prot) pfn_pte(page_to_pfn(page), prot)
```
* [Linux kernel source tree - /mm/memory.c](https://git.kernel.org/pub/scm/linux/kernel/git/stable/linux.git/tree/mm/memory.c?h=v5.10.35#n594)
```cpp
/*
* vm_normal_page -- This function gets the "struct page" associated with a pte.
*
* "Special" mappings do not wish to be associated with a "struct page" (either
* it doesn't exist, or it exists but they don't want to touch it). In this
* case, NULL is returned here. "Normal" mappings do have a struct page.
*
* There are 2 broad cases. Firstly, an architecture may define a pte_special()
* pte bit, in which case this function is trivial. Secondly, an architecture
* may not have a spare pte bit, which requires a more complicated scheme,
* described below.
*
* A raw VM_PFNMAP mapping (ie. one that is not COWed) is always considered a
* special mapping (even if there are underlying and valid "struct pages").
* COWed pages of a VM_PFNMAP are always normal.
*
* The way we recognize COWed pages within VM_PFNMAP mappings is through the
* rules set up by "remap_pfn_range()": the vma will have the VM_PFNMAP bit
* set, and the vm_pgoff will point to the first PFN mapped: thus every special
* mapping will always honor the rule
*
* pfn_of_page == vma->vm_pgoff + ((addr - vma->vm_start) >> PAGE_SHIFT)
*
* And for normal mappings this is false.
*
* This restricts such mappings to be a linear translation from virtual address
* to pfn. To get around this restriction, we allow arbitrary mappings so long
* as the vma is not a COW mapping; in that case, we know that all ptes are
* special (because none can have been COWed).
*
*
* In order to support COW of arbitrary special mappings, we have VM_MIXEDMAP.
*
* VM_MIXEDMAP mappings can likewise contain memory with or without "struct
* page" backing, however the difference is that _all_ pages with a struct
* page (that is, those where pfn_valid is true) are refcounted and considered
* normal pages by the VM. The disadvantage is that pages are refcounted
* (which can be slower and simply not an option for some PFNMAP users). The
* advantage is that we don't have to follow the strict linearity rule of
* PFNMAP mappings in order to support COWable mappings.
*
*/
```
:::success
**[[RFC PATCH 0/6] Add support for shared PTEs across processes](https://lore.kernel.org/linux-mm/eb696699-0138-33c5-ad47-bfca7f6e9079@intel.com/T/)**
此 patch 是為了解決當多個行程共享 `struct page` 時,每個行程的 page table 都會產生 PTE 以儲存此 page 。這在行程多到一定程度後,其記憶體開銷會變得不可忽略。因此,在 2022 一月中, Khalid Aziz 提出了在行程之間共用 PTE 這個概念。
> Some of the field deployments commonly see memory pages shared
across 1000s of processes. **On x86_64, each page requires a PTE that
is only 8 bytes long which is very small compared to the 4K page
size. When 2000 processes map the same page in their address space,
each one of them requires 8 bytes for its PTE and together that adds
up to 8K of memory just to hold the PTEs for one 4K page.**
以 syscall 的形式,提供 userspace 的操作界面。
> This is a proposal to implement a mechanism in kernel to allow
userspace processes to opt into sharing PTEs. The proposal is to add
a new system call - **mshare()**, which can be used by a process to
create a region (we will call it mshare'd region) which can be used
by other processes to map same pages using shared PTEs. Other
process(es), assuming they have the right permissions, can then make
the mashare() system call to map the shared pages into their address
space using the shared PTEs. When a process is done using this
mshare'd region, it makes a **mshare_unlink()** system call to end its
access. When the last process accessing mshare'd region calls
mshare_unlink(), the mshare'd region is torn down and memory used by
it is freed.
:::
### valid bits of address
> Another interesting problem is described at the end of the patch series. It would appear that there are programs out there that "know" that only the bottom 48 bits of a virtual address are valid. They take advantage of that knowledge by encoding other information in the uppermost bits. Those programs will clearly break if those bits suddenly become part of the address itself. To avoid such problems, the x86 patches in their current form will not allocate memory in the new address space by default. An application that needs that much memory, and which does not play games with virtual addresses, can provide an address hint above the boundary in a call to mmap(), at which point the kernel will understand that mappings in the upper range are accessible.
:::info
**allocate and free page table**
```cpp
pgd_alloc()
pgd_free()
pgd_quicklist()
get_pgd_fast()
pmd_alloc_one_fast()
get_pgd_slow()
pmd_alloc_one()
```
:::
### Implement three level page table
> [**GitHub - linD026 / Three-level-page-table**](https://github.com/linD026/Three-level-page-table)
> 因篇幅在此不把程式碼完整列出來,請去上方連結觀看或是實際測試及修改。
此為 three level page table 的部份實作,僅實現建立 page tables 以及插入 page 操作。並且有關 pa 、 va 和 pfn 轉換涉及到 MMU 等硬體支援的操作,並未完整模擬出來,而是以現有 va 以及自行設定各 level 中的偏移量建構另一個 va 。
在實作的過程中發現,對於 page table 的 lock 不管在哪個 level 都會以 `mm_struct->page_table_lock` 操作,這在 concurrent 下有明顯的效能不足。至此,lwn.net 也有一篇有關 range lock 的相關討論: [Range reader/writer locks for the kernel](https://lwn.net/Articles/724502/) 。其中說明到,一般資源控管的 lock 會如此設定,是因為要求對於 lock 的操作會以最簡單不複雜的方式進行全域的保護。
> The kernel uses a variety of lock types internally, but they all share one feature in common: they are a simple either/or proposition. When a lock is obtained for a resource, the entire resource is locked, even if exclusive access is only needed to a part of that resource. Many resources managed by the kernel are complex entities for which it may make sense to only lock a smaller part; files (consisting of a range of bytes) or a process's address space are examples of this type of resource.
至於為何一般 lock 會是如此簡潔的方式來運行的原因,是為了要減少操作 lock 的成本。
> **As a general rule, keeping the locks simple minimizes the time it takes to claim and release them.** Splitting locks (such as replacing a per-hash-table lock with lots of per-hash-chain locks) tends to be the better approach to scalability, rather than anything more complex that mutual-exclusion.
而 range lock 的提出不外乎就是可以提高 scalability ,但可以注意到的是這兩種型態的 lock 也都有優缺點,因此並不會完全傾向任一種 lock ,而是會在適當的地方使用:
> Range locks are handling a fairly unique case. Files are used in an enormous variety of ways - sometimes as a whole, sometimes as lots of individual records. In some case the whole-file `mmap_sem` really is simplest and best. Other times per-page locks are best. But sometimes, taking `mmap_sem` will cause too much contention, while taking the page lock on every single page would take even longer... and some of the pages might not be allocated yet.
> So range locks are being added, not because it is a generally good idea, but because there is a specific use case (managing the internals of files) that seems to justify them.
在 2013 以及 2017 年左右,開發者們也開始提出了一些 range lock 的策略,如 [`range_lock tree`](https://www.slideshare.net/davidlohr/range-readerwriter-locking-for-the-linux-kernel) 等。
:::success
**`insert_page`**
插入 page 至 page table 的函式 `insert_page` 有作 lock 的效能提昇的修改。目前版本中有提到,關於在 `arch` 硬體相關程式碼當中要提供 `pmd_index` 等功能,才可以運用此版本。至於舊版的 `insert_page` 也有保留下來,在註解中有說明僅限使用於舊的 driver 。
> 相關紀錄:[mm/memory.c: add vm_insert_pages()](https://github.com/torvalds/linux/commit/8cd3984d81d5fd5e18bccb12d7d228a114ec2508)
* [/mm/memory.c](https://elixir.bootlin.com/linux/v5.10.48/source/mm/memory.c#L1703)
```cpp
/* insert_pages() amortizes the cost of spinlock operations
* when inserting pages in a loop. Arch *must* define pte_index.
*/
static int insert_pages(struct vm_area_struct *vma, unsigned long addr,
struct page **pages, unsigned long *num, pgprot_t prot)
{
pmd_t *pmd = NULL;
pte_t *start_pte, *pte;
spinlock_t *pte_lock;
struct mm_struct *const mm = vma->vm_mm;
unsigned long curr_page_idx = 0;
unsigned long remaining_pages_total = *num;
unsigned long pages_to_write_in_pmd;
int ret;
more:
ret = -EFAULT;
pmd = walk_to_pmd(mm, addr);
if (!pmd)
goto out;
pages_to_write_in_pmd = min_t(unsigned long,
remaining_pages_total, PTRS_PER_PTE - pte_index(addr));
/* Allocate the PTE if necessary; takes PMD lock once only. */
ret = -ENOMEM;
if (pte_alloc(mm, pmd))
goto out;
while (pages_to_write_in_pmd) {
int pte_idx = 0;
const int batch_size = min_t(int, pages_to_write_in_pmd, 8);
start_pte = pte_offset_map_lock(mm, pmd, addr, &pte_lock);
for (pte = start_pte; pte_idx < batch_size; ++pte, ++pte_idx) {
int err = insert_page_in_batch_locked(mm, pte,
addr, pages[curr_page_idx], prot);
if (unlikely(err)) {
pte_unmap_unlock(start_pte, pte_lock);
ret = err;
remaining_pages_total -= pte_idx;
goto out;
}
addr += PAGE_SIZE;
++curr_page_idx;
}
pte_unmap_unlock(start_pte, pte_lock);
pages_to_write_in_pmd -= batch_size;
remaining_pages_total -= batch_size;
}
if (remaining_pages_total)
goto more;
ret = 0;
out:
*num = remaining_pages_total;
return ret;
}
#endif /* ifdef pte_index */
```
**延伸閱讀**
[HackMD - Linux 核心原始程式碼巨集: `max`, `min`](https://hackmd.io/@sysprog/linux-macro-minmax)
:::
---
## Physical Memory Abstract
```graphviz
digraph bank_memory {
label = "node abstract"
rankdir = LR
cpu [label = "CPU"]
dma [label = "DMA"]
mm1 [label = "memory 1" shape = box]
mm2 [label = "memory 2" shape = box]
mm3 [label = "memory 3" shape = box]
mm1 -> mm2 -> mm3
subgraph cluster_node1 {
label = "Node 1"
cpu -> mm1
{rank = same mm1, cpu}
}
subgraph cluster_node2 {
label = "Node 2"
dma -> mm3
{rank = same mm3, dma}
}
}
```
在 [NUMA](https://en.wikipedia.org/wiki/Non-uniform_memory_access) 架構中,不同記憶取區段對於不同處理器的讀取,根據記憶體與處理器的距離會有不同的讀取成本。
根據 [wikipedia](https://en.wikipedia.org/wiki/Non-uniform_memory_access) 對於 NUMA 架構的說明:
> **Non-uniform memory access (NUMA) is a computer memory design used in multiprocessing, where the memory access time depends on the memory location relative to the processor.** Under NUMA, a processor can access its own local memory faster than non-local memory (memory local to another processor or memory shared between processors). The benefits of NUMA are limited to particular workloads, notably on servers where the data is often associated strongly with certain tasks or users.
對於每個處理器都會有自己的記憶體區段,而每個區段的 phyiscal memory 在 Linux 當中以 node 稱之,並以 `struct pglist_data` ( `pg_data_t` )進行操作。而在每個 node 之中,記憶體又會被區分成數個區段以 zone ( `struct zone` )來進行。
:::success
**UMA** 架構則是會以一個 `pglist_data` 來描述整個記憶體。
:::
```graphviz
digraph main {
label = "abstract"
rankdir = TB
node1 [label = "node ( pg_data_t )"]
zone_normal [label = "zone ( struct zone )"]
page_normal [label = "struct page"]
node1 -> zone_normal -> page_normal
}
```
```cpp
/*
* On NUMA machines, each NUMA node would have a pg_data_t to describe
* it's memory layout. On UMA machines there is a single pglist_data which
* describes the whole memory.
*
* Memory statistics and page replacement data structures are maintained on a
* per-zone basis.
*/
typedef struct pglist_data {
...
/*
* node_zones contains just the zones for THIS node. Not all of the
* zones may be populated, but it is the full list. It is referenced by
* this node's node_zonelists as well as other node's node_zonelists.
*/
struct zone node_zones[MAX_NR_ZONES];
/*
* node_zonelists contains references to all zones in all nodes.
* Generally the first zones will be references to this node's
* node_zones.
*/
struct zonelist node_zonelists[MAX_ZONELISTS];
int node_id;
unsigned long node_start_pfn;
...
} pg_data_t;
```
從 `struct page` 至 zone 的轉換一般來說會是以 `page_zone` 函式進行:
* [/include/linux/mm.h](https://elixir.bootlin.com/linux/v5.10.38/source/include/linux/mm.h#L1455)
```cpp
static inline struct zone *page_zone(const struct page *page)
{
return &NODE_DATA(page_to_nid(page))->node_zones[page_zonenum(page)];
}
```
Zone 有三種型態分別是 `ZONE_DMA` 、`ZONE_NORMAL`、`ZONE_HIGHMEM`。這三種型態的對於記憶體的區分會因硬體架構而有不同。而在早期, `ZONE_DMA` 因 [ISA](https://en.wikipedia.org/wiki/Industry_Standard_Architecture) 的硬體限制被劃分在低段記憶體位置上。
> The DMA zone (ZONE_DMA) is a memory-management holdover from the distant past. Once upon a time, many devices (those on the ISA bus in particular) could only use 24 bits for DMA addresses, and were thus limited to the bottom 16MB of memory.
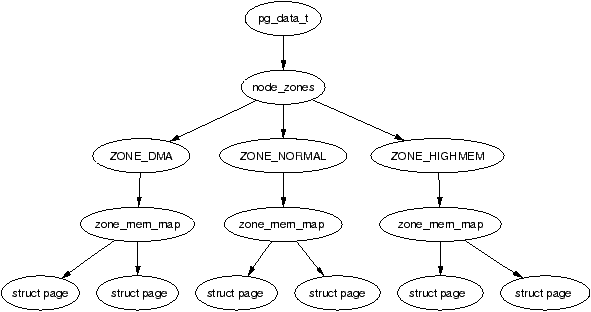
:::success
[stackoerflow - Increasing Linux DMA_ZONE memory on ARM i.MX287](https://stackoverflow.com/questions/44391968/increasing-linux-dma-zone-memory-on-arm-i-mx287)
> The ZONE_DMA 16MB limit is imposed by a hardware limitation of certain devices. **Specifically, on the PC architecture in the olden days, ISA cards performing DMA needed buffers allocated in the first 16MB of the physical address space because the ISA interface had 24 physical address lines which were only capable of addressing the first 2^24=16MB of physical memory.** Therefore, device drivers for these cards would allocate DMA buffers in the ZONE_DMA area to accommodate this hardware limitation.
**延伸閱讀**
在 2018 年時,開發者們有討論過是否要移除 `ZONE_DMA` 這古老的東西。而[另一篇列出對此會受影響的 driver 清單](https://lwn.net/Articles/753274/)則建議不要。詳細請見: [lwn.net - Is it time to remove ZONE_DMA?](https://lwn.net/Articles/753273/)
:::
可以利用 struct page 中描述 page 狀態的 flag 以及 `page_zonenum` 函式來得到此 struct page 是屬於哪種 zone 。
* [/include/linux/mm.h](https://elixir.bootlin.com/linux/v5.10.38/source/include/linux/mm.h#L1083)
```cpp
static inline enum zone_type page_zonenum(const struct page *page)
{
ASSERT_EXCLUSIVE_BITS(page->flags, ZONES_MASK << ZONES_PGSHIFT);
return (page->flags >> ZONES_PGSHIFT) & ZONES_MASK;
}
```
### Zone initialization in arm
區分上述三種 zone type 的方式以 `min_low_pfn` 、 `max_pfn` 、 `max_low_pfn` 變數設定。 kernel 可使用的第一個 pfn 位於 `min_low_pfn` ,而最後一個則是在 `max_pfn` 。
:::warning
> **The value of max low pfn is calculated on the x86 with `find_max_low_pfn()`, and it marks the end of ZONE_NORMAL.** This is the physical memory directly accessible by the kernel and is related to the kernel/userspace split in the linear address space marked by PAGE OFFSET. The value, with the others, is stored in mm/bootmem.c. In low memory machines, the max pfn will be the same as the max low pfn.
x86 的三種 zone 型態為:
> * ZONE_DMA : First 16MiB of memory
> * ZONE_NORMAL : 16MiB - 896MiB
> * ZONE_HIGHMEM : 896 MiB - End
**延伸閱讀**
[patchwork.kernel.org - \[v6,3/4\] arm64: use both ZONE_DMA and ZONE_DMA32](https://patchwork.kernel.org/project/linux-arm-kernel/patch/20190911182546.17094-4-nsaenzjulienne@suse.de/)
[lwn.net - ARM, DMA, and memory management](https://lwn.net/Articles/440221/)
:::
* [arch/arm/include/asm/dma.h](https://elixir.bootlin.com/linux/v5.10.47/source/arch/arm/include/asm/dma.h#L11)
```cpp
#define MAX_DMA_ADDRESS ({ \
extern phys_addr_t arm_dma_zone_size; \
arm_dma_zone_size && arm_dma_zone_size < (0x10000000 - PAGE_OFFSET) ? \
(PAGE_OFFSET + arm_dma_zone_size) : 0xffffffffUL; })
```
* [arch/arm/mm/init.c](https://elixir.bootlin.com/linux/v5.10.38/source/arch/arm/mm/init.c#L74)
```cpp
static void __init find_limits(unsigned long *min, unsigned long *max_low,
unsigned long *max_high)
{
*max_low = PFN_DOWN(memblock_get_current_limit());
*min = PFN_UP(memblock_start_of_DRAM());
*max_high = PFN_DOWN(memblock_end_of_DRAM());
}
```
* [/arch/arm/mm/init.c](https://elixir.bootlin.com/linux/v5.10.47/source/arch/arm/mm/init.c#L235)
```cpp
void __init bootmem_init(void)
{
memblock_allow_resize();
find_limits(&min_low_pfn, &max_low_pfn, &max_pfn);
early_memtest((phys_addr_t)min_low_pfn << PAGE_SHIFT,
(phys_addr_t)max_low_pfn << PAGE_SHIFT);
/*
* sparse_init() tries to allocate memory from memblock, so must be
* done after the fixed reservations
*/
sparse_init();
/*
* Now free the memory - free_area_init needs
* the sparse mem_map arrays initialized by sparse_init()
* for memmap_init_zone(), otherwise all PFNs are invalid.
*/
zone_sizes_init(min_low_pfn, max_low_pfn, max_pfn);
}
```
* [/arch/arm/mm/init.c](https://elixir.bootlin.com/linux/v5.10.47/source/arch/arm/mm/init.c#L109)
```cpp
static void __init zone_sizes_init(unsigned long min, unsigned long max_low,
unsigned long max_high)
{
unsigned long max_zone_pfn[MAX_NR_ZONES] = { 0 };
#ifdef CONFIG_ZONE_DMA
max_zone_pfn[ZONE_DMA] = min(arm_dma_pfn_limit, max_low);
#endif
max_zone_pfn[ZONE_NORMAL] = max_low;
#ifdef CONFIG_HIGHMEM
max_zone_pfn[ZONE_HIGHMEM] = max_high;
#endif
free_area_init(max_zone_pfn);
}
```
設定好三種型態以後,會進行 `free_area_init_node` 函式:
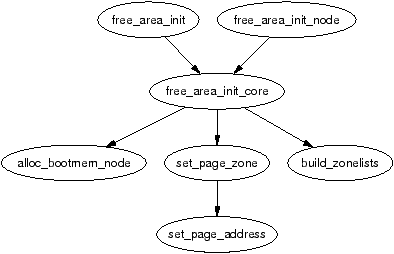
而在 NUMA 架構下,每個 node 會以 `node_start_pfn` 以及 `node_mem_map` 紀錄自己的 struct page 。 `pfn` ( physical page frame number ) 是描述 page 在 phyiscal memory 之中的位置,因此每個 node 都會有相同的 `pfn` 數值,此時就是利用 `nid` (node ID) 以及 `node_start_pfn` 來得到在全域當中可分辨的 `pfn` 。
> On **NUMA** systems, the global `mem_map` is treated as a virtual array starting at `PAGE_OFFSET`. `free_area_init_node()` is called for each active node in the system, which allocates the portion of this array for the node being initialized.
從 struct page 轉換至 `pfn` 的詳細程式碼在之後會列出,請見 [Mapping address to page - page to pfn and back](https://hackmd.io/@linD026/Linux-kernel-COW-Copy-on-Write#page-to-pfn-and-back) 。
:::warning
**`node_start_pfn`**
此紀錄了 node 的第一個能自己使用的 `pfn` ( physical page frame number ) 。在 2.6 版本以前是以 physical address 紀錄,但這會因 [PAE](https://en.wikipedia.org/wiki/Physical_Address_Extension) 而產生一些問題。
> A PFN is simply an index within physical memory that is counted in page-sized units.
:::
而實際分配記憶體會是以下列形式:
1. 從 [`free_area_init_node(nid)`](https://elixir.bootlin.com/linux/v5.10.47/source/mm/page_alloc.c#L7047) 建立 node 的 `pg_data_t` 的資料結構,並設定偏移量如 `node_start_pfn` 等。
3. 再以 [`alloc_node_mem_map`](https://elixir.bootlin.com/linux/v5.10.47/source/mm/page_alloc.c#L6989) 與先前函式建立的資訊,得到實際分配的大小(會處理因 buddy allocator 等 aligned 的問題),並傳給下個函式。
4. [`memblock_alloc_node`](https://elixir.bootlin.com/linux/v5.10.47/source/include/linux/memblock.h#L436) 和 [`memblock_alloc_try_nid`](https://elixir.bootlin.com/linux/v5.10.47/source/mm/memblock.c#L1552) 會提供相關分配記憶體資訊,並由下個函式實際執行。
5. 最後,[`memblock_alloc_internal`](https://elixir.bootlin.com/linux/v5.10.47/source/mm/memblock.c#L1428)才會依照 `slab allocator` 實際以分配記憶體。如果不能完整分配所要求的記憶體,則會試著分配現有剩餘的記憶體。
### `mem_map` in Physical memory models
儲存整個 physical page 的結構會以 `struct page *` 型態包含 `mem_map` 名稱的陣列維持,相關函式操作則會以 `mem_map` 或是 `memmap` 、 `memblock` 等命名。
> Each physical page frame is represented by a struct page and all the structs are kept in a global `mem_map` array which is usually stored at the beginning of ZONE_NORMAL or just after the area reserved for the loaded kernel image in low memory machines.
```cpp
#ifndef CONFIG_NEED_MULTIPLE_NODES
/* use the per-pgdat data instead for discontigmem - mbligh */
unsigned long max_mapnr;
EXPORT_SYMBOL(max_mapnr);
struct page *mem_map;
EXPORT_SYMBOL(mem_map);
#endif
```
在不同 physical memory model 下,會有不同的 `mem_map` 形式儲存,因為要在下個段落才會介紹 physical memory model 因此在此只簡短列出不同 model 所使用的 `mem_map` :
* **Flat** : global `mem_map`
* **discontiguous** : `node_data[nid]->node_mem_map` (in arm64)
```cpp
typedef struct pglist_data {
...
#ifdef CONFIG_FLAT_NODE_MEM_MAP /* means !SPARSEMEM */
struct page *node_mem_map;
#ifdef CONFIG_PAGE_EXTENSION
...
} pg_data_t;
```
* [/arch/arm64/mm/numa.c](https://elixir.bootlin.com/linux/v5.10.38/source/arch/arm64/mm/numa.c#L19)
```cpp
struct pglist_data *node_data[MAX_NUMNODES] __read_mostly;
```
* [/arch/arm64/include/asm/mmzone.h](https://elixir.bootlin.com/linux/v5.10.38/source/arch/arm64/include/asm/mmzone.h#L10)
```cpp
#define NODE_DATA(nid) (node_data[(nid)])
```
* **sparse** : `section[i].section_mem_map`
* **sparse vmemmap** : `vmemmap`
:::success
**延伸閱讀 - page_wait_table**
當 page 進行 I/O 處理時,會希望在同一時間下只有一個 process 進行運作。因此,衍生出管理 waiting queue 的 `wait_table` 。以下是 2.6 版本左右的圖示(現今已更改):
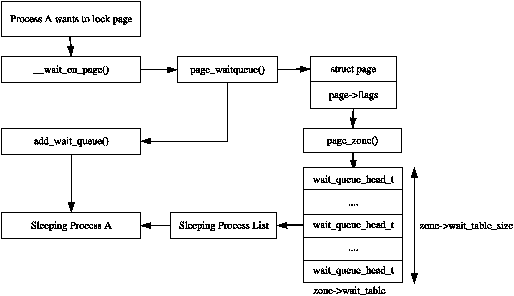
然而如果實際查看原始碼會發現 [/mm/filemap.c](https://elixir.bootlin.com/linux/v5.10.38/source/mm/filemap.c#L998) 以及 [/kernel/sched/wait_bit.c](https://elixir.bootlin.com/linux/v5.10.38/source/kernel/sched/wait_bit.c#L10) 都有 `bit_wait_table` 相關程式碼。而根據 [Re: CONFIG_VMAP_STACK, on-stack struct, and wake_up_bit](https://lwn.net/Articles/704725/) 此系列的電子郵件紀錄可得知 `wait_page_table` 等操作有做更改。
然而,在之後又做了多次修改,可見:
[Re: [PATCH 2/2 v2] sched/wait: Introduce lock breaker in wake_up_page_bit](https://lkml.org/lkml/2017/8/25/789)
> We encountered workloads that have very long wake up list on large
> systems. A waker takes a long time to traverse the entire wake list and
> execute all the wake functions.
>
> We saw page wait list that are up to 3700+ entries long in tests of large
> 4 and 8 socket systems. It took 0.8 sec to traverse such list during
> wake up. Any other CPU that contends for the list spin lock will spin
> for a long time. It is a result of the numa balancing migration of hot
> pages that are shared by many threads.
>
> Multiple CPUs waking are queued up behind the lock, and the last one queued
> has to wait until all CPUs did all the wakeups.
根據此系列電子郵件紀錄來看, struct page 所使用的 waitqueue 只會有 per-page ,不會同時有 per-page 和 per-bit 。
[Re: [PATCH 2/2 v2] sched/wait: Introduce lock breaker in wake_up_page_bit](https://lkml.org/lkml/2017/8/25/832)
> But even without sharing the same queue, we could just do a per-page
allocation for the three queues - and probably that stupiud
add_page_wait_queue() waitqueue too. So no "per-page and per-bit"
thing, just a per-page thing.
在現今 5.10 版本當中是以維持 element 為 `struct wait_queue_head` 的 hash table 。 Process 利用 `page_waitqueue` 得到 index ,並且進行 [wait_on_page_bit](https://elixir.bootlin.com/linux/v5.10.38/source/include/linux/pagemap.h#L673) 函式等待。
* [/include/linux/wait.h](https://elixir.bootlin.com/linux/v5.10.38/source/include/linux/wait.h#L40)
```cpp
struct wait_queue_head {
spinlock_t lock;
struct list_head head;
};
typedef struct wait_queue_head wait_queue_head_t;
```
* [/mm/filemap.c](https://elixir.bootlin.com/linux/v5.10.38/source/mm/filemap.c#L998)
```cpp
/*
* In order to wait for pages to become available there must be
* waitqueues associated with pages. By using a hash table of
* waitqueues where the bucket discipline is to maintain all
* waiters on the same queue and wake all when any of the pages
* become available, and for the woken contexts to check to be
* sure the appropriate page became available, this saves space
* at a cost of "thundering herd" phenomena during rare hash
* collisions.
*/
#define PAGE_WAIT_TABLE_BITS 8
#define PAGE_WAIT_TABLE_SIZE (1 << PAGE_WAIT_TABLE_BITS)
static wait_queue_head_t page_wait_table[PAGE_WAIT_TABLE_SIZE] __cacheline_aligned;
```
* [/mm/filemap.c](https://elixir.bootlin.com/linux/v5.10.38/source/mm/filemap.c#L998)
```cpp
static wait_queue_head_t *page_waitqueue(struct page *page)
{
return &page_wait_table[hash_ptr(page, PAGE_WAIT_TABLE_BITS)];
}
```
在函式一開始時會被加入至 linked list tail 位置( [`__add_wait_queue_entry_tail`](https://elixir.bootlin.com/linux/v5.10.38/source/include/linux/wait.h#L184) ),之後進入迴圈確保自身狀態。
```cpp
/*
* Note that until the "finish_wait()", or until
* we see the WQ_FLAG_WOKEN flag, we need to
* be very careful with the 'wait->flags', because
* we may race with a waker that sets them.
*/
for (;;) {
unsigned int flags;
set_current_state(state);
/* Loop until we've been woken or interrupted */
flags = smp_load_acquire(&wait->flags);
if (!(flags & WQ_FLAG_WOKEN)) {
if (signal_pending_state(state, current))
break;
io_schedule();
continue;
}
/* If we were non-exclusive, we're done */
if (behavior != EXCLUSIVE)
break;
/* If the waker got the lock for us, we're done */
if (flags & WQ_FLAG_DONE)
break;
/*
* Otherwise, if we're getting the lock, we need to
* try to get it ourselves.
*
* And if that fails, we'll have to retry this all.
*/
if (unlikely(test_and_set_bit(bit_nr, &page->flags)))
goto repeat;
wait->flags |= WQ_FLAG_DONE;
break;
}
```
當出來迴圈會呼叫 `finish_wait` 函式,對 waitqueue 進行處理:
```cpp
/*
* If a signal happened, this 'finish_wait()' may remove the last
* waiter from the wait-queues, but the PageWaiters bit will remain
* set. That's ok. The next wakeup will take care of it, and trying
* to do it here would be difficult and prone to races.
*/
finish_wait(q, wait);
/*
* NOTE! The wait->flags weren't stable until we've done the
* 'finish_wait()', and we could have exited the loop above due
* to a signal, and had a wakeup event happen after the signal
* test but before the 'finish_wait()'.
*
* So only after the finish_wait() can we reliably determine
* if we got woken up or not, so we can now figure out the final
* return value based on that state without races.
*
* Also note that WQ_FLAG_WOKEN is sufficient for a non-exclusive
* waiter, but an exclusive one requires WQ_FLAG_DONE.
*/
if (behavior == EXCLUSIVE)
return wait->flags & WQ_FLAG_DONE ? 0 : -EINTR;
return wait->flags & WQ_FLAG_WOKEN ? 0 : -EINTR;
```
以下為 ftrace 的部分紀錄:
```shell
bash-7535 [004] .... 8473.950735: wait_on_page_writeback <-truncate_inode_pages_range
bash-7535 [004] .... 8473.950735: page_mapping <-wait_on_page_writeback
bash-7535 [004] .... 8473.950735: wait_on_page_bit <-wait_on_page_writeback
bash-7535 [004] .... 8473.950735: _raw_spin_lock_irq <-wait_on_page_bit
bash-7535 [004] .... 8473.950736: io_schedule <-wait_on_page_bit
bash-7535 [004] .... 8473.950736: io_schedule_prepare <-io_schedule
bash-7535 [004] .... 8473.950736: schedule <-io_schedule
bash-7535 [004] d... 8473.950737: rcu_note_context_switch <-__schedule
// task switching...
// doing another work
<idle>-0 [004] d... 8473.955194: psi_group_change <-psi_task_switch
<idle>-0 [004] d... 8473.955194: record_times <-psi_group_change
<idle>-0 [004] d... 8473.955195: psi_group_change <-psi_task_switch
<idle>-0 [004] d... 8473.955195: record_times <-psi_group_change
<idle>-0 [004] d... 8473.955196: switch_mm_irqs_off <-__schedule
bash-7535 [004] d... 8473.955197: finish_task_switch <-__schedule
bash-7535 [004] .... 8473.955197: finish_wait <-wait_on_page_bit
bash-7535 [004] .... 8473.955198: truncate_inode_page <-truncate_inode_pages_range
bash-7535 [004] .... 8473.955198: truncate_cleanup_page <-truncate_inode_page
bash-7535 [004] .... 8473.955198: page_mapped <-truncate_cleanup_page
bash-7535 [004] .... 8473.955199: ext4_invalidatepage <-truncate_cleanup_page
bash-7535 [004] .... 8473.955199: block_invalidatepage <-ext4_invalidatepage
bash-7535 [004] .... 8473.955199: _cond_resched <-block_invalidatepage
bash-7535 [004] .... 8473.955200: rcu_all_qs <-_cond_resched
bash-7535 [004] .... 8473.955200: unlock_buffer <-block_invalidatepage
bash-7535 [004] .... 8473.955200: wake_up_bit <-unlock_buffer
bash-7535 [004] .... 8473.955200: __wake_up_bit <-wake_up_bit
bash-7535 [004] .... 8473.955201: try_to_release_page <-block_invalidatepage
```
而 page 的使用權被釋放後,會走訪此 linked list 直到其中一個 item 可使用此 page 。
[wikipedia - thundering herd problem](https://en.wikipedia.org/wiki/Thundering_herd_problem)
> In computer science, the thundering herd problem occurs when a large number of processes or threads waiting for an event are awoken when that event occurs, but only one process is able to handle the event. When the processes wake up, they will each try to handle the event, but only one will win. All processes will compete for resources, possibly freezing the computer, until the herd is calmed down again
:::
---
## Physical Memory Model
> [root/Documentation/vm/memory-model.rst](https://git.kernel.org/pub/scm/linux/kernel/git/stable/linux.git/tree/Documentation/vm/memory-model.rst?h=v5.10.38)
> [Memory: the flat, the discontiguous, and the sparse](https://lwn.net/Articles/789304/)
關於 physical memory 有多種方式可以呈現,例如最簡單的直接從 0 開始一直算到最大可表示範圍 ( 64-bits 的 0 到 $2^{64}-1$ ) 。然而實際上還須考慮 CPU 讀取範圍的漏洞以及多個 CPU 之間不同的範圍、 NUMA 架構、 SMP 等多個外部因素。在 Linux kernel 中總共提供了 3 memory model : FLATMEM 、 DISCONTIGMEM 和 SPARSEMEM ,分別運用在 flat 、 discontiguous 以及 sparse 的記憶體空間。
:::warning
At time of this writing, **DISCONTIGMEM is considered deprecated**, although it is still in use by several architectures.
All the memory models track the status of physical page frames using struct page arranged in one or more arrays.
Regardless of the selected memory model, **there exists one-to-one mapping between the physical page frame number (PFN) and the corresponding `struct page`.**
Each memory model defines :c:func:`pfn_to_page` and :c:func:`page_to_pfn` helpers that allow the conversion from PFN to `struct page` and vice versa.
:::
### FLATMEM
FLATMEM 適用於連續或多為連續的 physical memory 的 non-NUMA 系統。此 memory model 會有個以 `struct page` 為 element 的 global `mem_map` array 對應到所有 physical memory 並包含記憶體漏洞,記憶體漏洞會對應上無法初始化的 `struct page` object 。 此中方式提供了有效率的 pfn 轉 `struct page` ,這在 cache 上對讀取 `struct page` 有很好的最佳化,因為僅做出 index 之間的 offset 即可。
:::success
在 1.3.50 版本 `mem_map` 的 element 才被命名為 `struct page`。
:::
在分配 `mem_map` array 之前,需要先下 `free_area_init` 函式並且以 `memblock_free_all` 函式初始化給 page allocator 才可使用。
* [`/include/linux/mm.h - free_area_init()`](https://elixir.bootlin.com/linux/v5.10.39/source/include/linux/mm.h#L2433)
```cpp
/*
* Using memblock node mappings, an architecture may initialise its
* zones, allocate the backing mem_map and account for memory holes in an
* architecture independent manner.
*
* An architecture is expected to register range of page frames backed by
* physical memory with memblock_add[_node]() before calling
* free_area_init() passing in the PFN each zone ends at. At a basic
* usage, an architecture is expected to do something like
*
* unsigned long max_zone_pfns[MAX_NR_ZONES] = {max_dma, max_normal_pfn,
* max_highmem_pfn};
* for_each_valid_physical_page_range()
* memblock_add_node(base, size, nid)
* free_area_init(max_zone_pfns);
*/
void free_area_init(unsigned long *max_zone_pfn);
```
* [`/mm/page_alloc.c - free_area_init()`](https://elixir.bootlin.com/linux/v5.10.39/source/mm/page_alloc.c#L7425)
```cpp
/**
* free_area_init - Initialise all pg_data_t and zone data
* @max_zone_pfn: an array of max PFNs for each zone
*
* This will call free_area_init_node() for each active node in the system.
* Using the page ranges provided by memblock_set_node(), the size of each
* zone in each node and their holes is calculated. If the maximum PFN
* between two adjacent zones match, it is assumed that the zone is empty.
* For example, if arch_max_dma_pfn == arch_max_dma32_pfn, it is assumed
* that arch_max_dma32_pfn has no pages. It is also assumed that a zone
* starts where the previous one ended. For example, ZONE_DMA32 starts
* at arch_max_dma_pfn.
*/
void __init free_area_init(unsigned long *max_zone_pfn)
```
* 此函式最一開始會先設置可操作的 boundary :
```cpp
/* Record where the zone boundaries are */
memset(arch_zone_lowest_possible_pfn, 0,
sizeof(arch_zone_lowest_possible_pfn));
memset(arch_zone_highest_possible_pfn, 0,
sizeof(arch_zone_highest_possible_pfn));
```
* 之後設置操作之初始位置以及判斷記憶體空間是否為 descending ,以便之後的迴圈設置 pfn,示意圖:
```graphviz
digraph main {
rankdir = TP
node [shape = record]
label = "simple memory with none descending"
cmm [label = "{{{<0>0|0}|{<1>0|1}|{<2>0|...}|{<3>0|i}|{<4>0|...}|{<n>0|n}}|from left to right}"]
s1 [label = "start 1"]
e1 [label = "end 1"]
s1 -> cmm:1
e1 -> cmm:3
s2 [label = "start 2"]
s2 -> cmm:3
}
```
每個 `start_pfn` 和 `end_pfn` 的會別儲存於 `arch_zone_lowest_possible_pfn[zone]` 和 `arch_zone_highest_possible_pfn[zone]` 之中,而當 `zone` 為 `ZONE_MOVABLE` 時,會區分下一個區塊,並且下一個區塊始於上一個 end 。
關於 `ZONE_MOVABLE` ,此為 `enum` 並且被定義於 [`/include/linux/mmzone.h`](https://elixir.bootlin.com/linux/v5.10.38/source/include/linux/mmzone.h#L347) 當中:
```cpp
/*
* ZONE_MOVABLE is similar to ZONE_NORMAL, except that it contains
* movable pages with few exceptional cases described below. Main use
* cases for ZONE_MOVABLE are to make memory offlining/unplug more
* likely to succeed, and to locally limit unmovable allocations - e.g.,
* to increase the number of THP/huge pages. Notable special cases are:
*
* 1. Pinned pages: (long-term) pinning of movable pages might
* essentially turn such pages unmovable. Memory offlining might
* retry a long time.
* 2. memblock allocations: kernelcore/movablecore setups might create
* situations where ZONE_MOVABLE contains unmovable allocations
* after boot. Memory offlining and allocations fail early.
* 3. Memory holes: kernelcore/movablecore setups might create very rare
* situations where ZONE_MOVABLE contains memory holes after boot,
* for example, if we have sections that are only partially
* populated. Memory offlining and allocations fail early.
* 4. PG_hwpoison pages: while poisoned pages can be skipped during
* memory offlining, such pages cannot be allocated.
* 5. Unmovable PG_offline pages: in paravirtualized environments,
* hotplugged memory blocks might only partially be managed by the
* buddy (e.g., via XEN-balloon, Hyper-V balloon, virtio-mem). The
* parts not manged by the buddy are unmovable PG_offline pages. In
* some cases (virtio-mem), such pages can be skipped during
* memory offlining, however, cannot be moved/allocated. These
* techniques might use alloc_contig_range() to hide previously
* exposed pages from the buddy again (e.g., to implement some sort
* of memory unplug in virtio-mem).
*
* In general, no unmovable allocations that degrade memory offlining
* should end up in ZONE_MOVABLE. Allocators (like alloc_contig_range())
* have to expect that migrating pages in ZONE_MOVABLE can fail (even
* if has_unmovable_pages() states that there are no unmovable pages,
* there can be false negatives).
*/
ZONE_MOVABLE,
```
而最一開始的 `start_pfn` 則由 `find_min_pfn_with_active_regions` 找出( 最小 `PFN` 數值 ):
```cpp
/**
* find_min_pfn_with_active_regions - Find the minimum PFN registered
*
* Return: the minimum PFN based on information provided via
* memblock_set_node().
*/
unsigned long __init find_min_pfn_with_active_regions(void)
{
return PHYS_PFN(memblock_start_of_DRAM());
}
```
以下為實際程式碼以及之後印出出定義區塊的迴圈程式碼:
```cpp
start_pfn = find_min_pfn_with_active_regions();
descending = arch_has_descending_max_zone_pfns();
for (i = 0; i < MAX_NR_ZONES; i++) {
if (descending)
zone = MAX_NR_ZONES - i - 1;
else
zone = i;
if (zone == ZONE_MOVABLE)
continue;
end_pfn = max(max_zone_pfn[zone], start_pfn);
arch_zone_lowest_possible_pfn[zone] = start_pfn;
arch_zone_highest_possible_pfn[zone] = end_pfn;
start_pfn = end_pfn;
}
/* Find the PFNs that ZONE_MOVABLE begins at in each node */
memset(zone_movable_pfn, 0, sizeof(zone_movable_pfn));
find_zone_movable_pfns_for_nodes();
/* Print out the zone ranges */
pr_info("Zone ranges:\n");
for (i = 0; i < MAX_NR_ZONES; i++) {
if (i == ZONE_MOVABLE)
continue;
pr_info(" %-8s ", zone_names[i]);
if (arch_zone_lowest_possible_pfn[i] ==
arch_zone_highest_possible_pfn[i])
pr_cont("empty\n");
else
pr_cont("[mem %#018Lx-%#018Lx]\n",
(u64)arch_zone_lowest_possible_pfn[i]
<< PAGE_SHIFT,
((u64)arch_zone_highest_possible_pfn[i]
<< PAGE_SHIFT) - 1);
}
/* Print out the PFNs ZONE_MOVABLE begins at in each node */
pr_info("Movable zone start for each node\n");
for (i = 0; i < MAX_NUMNODES; i++) {
if (zone_movable_pfn[i])
pr_info(" Node %d: %#018Lx\n", i,
}
```
之後,印出之前的記憶體空間 ( node ),並 enable `sub-section` 至新的分配空間的最後一個區塊 ( 因前面的迴圈使得 `start_pfn` 指向最後一個 )。
```cpp
/*
* Print out the early node map, and initialize the
* subsection-map relative to active online memory ranges to
* enable future "sub-section" extensions of the memory map.
*/
pr_info("Early memory node ranges\n");
for_each_mem_pfn_range(i, MAX_NUMNODES, &start_pfn, &end_pfn, &nid) {
pr_info(" node %3d: [mem %#018Lx-%#018Lx]\n", nid,
(u64)start_pfn << PAGE_SHIFT,
((u64)end_pfn << PAGE_SHIFT) - 1);
subsection_map_init(start_pfn, end_pfn - start_pfn);
}
/* Initialise every node */
mminit_verify_pageflags_layout();
setup_nr_node_ids();
for_each_online_node(nid) {
pg_data_t *pgdat = NODE_DATA(nid);
free_area_init_node(nid);
/* Any memory on that node */
if (pgdat->node_present_pages)
node_set_state(nid, N_MEMORY);
check_for_memory(pgdat, nid);
}
```
* [`/mm/memblock.c - memblock_free_all`](https://elixir.bootlin.com/linux/v5.10.39/source/mm/memblock.c#L1974)
```cpp
/**
* memblock_free_all - release free pages to the buddy allocator
*
* Return: the number of pages actually released.
*/
unsigned long __init memblock_free_all(void)
{
unsigned long pages;
reset_all_zones_managed_pages();
pages = free_low_memory_core_early();
totalram_pages_add(pages);
return pages;
}
```
轉換 `PFN` 與 `struct page` 在 FLATMEM 是非常直觀的,以 `PFN - ARCH_PFN_OFFSET` 即可得到在 `mem_map` array 的位置。
`ARCH_PFN_OFFSET` 則為系統中第一個 page frame number 的 physical address 。
* [/arch/arm/include/asm/memory.h](https://elixir.bootlin.com/linux/v5.10.39/source/arch/arm/include/asm/memory.h#L189)
```cpp
#define ARCH_PFN_OFFSET PHYS_PFN_OFFSET
/*
* Physical vs virtual RAM address space conversion. These are
* private definitions which should NOT be used outside memory.h
* files. Use virt_to_phys/phys_to_virt/__pa/__va instead.
*
* PFNs are used to describe any physical page; this means
* PFN 0 == physical address 0.
*/
#if defined(CONFIG_ARM_PATCH_PHYS_VIRT)
#define PHYS_PFN_OFFSET (__pv_phys_pfn_offset)
#else
#define PHYS_OFFSET PLAT_PHYS_OFFSET
#define PHYS_PFN_OFFSET ((unsigned long)(PHYS_OFFSET >> PAGE_SHIFT))
```
> [/arch/arm/kernel/head.S - __pv_phys_pfn_offset](https://elixir.bootlin.com/linux/v5.10.39/source/arch/arm/kernel/head.S#L715)
* [/arch/arm/include/asm/memory.h](https://elixir.bootlin.com/linux/v5.10.39/source/arch/arm/include/asm/memory.h#L146)
```cpp
/*
* PLAT_PHYS_OFFSET is the offset (from zero) of the start of physical
* memory. This is used for XIP and NoMMU kernels, and on platforms that don't
* have CONFIG_ARM_PATCH_PHYS_VIRT. Assembly code must always use
* PLAT_PHYS_OFFSET and not PHYS_OFFSET.
*/
#define PLAT_PHYS_OFFSET UL(CONFIG_PHYS_OFFSET)
```
* [/arch/arm/Kconfig](https://elixir.bootlin.com/linux/v5.10.39/source/arch/arm/Kconfig#L267)
```
config PHYS_OFFSET
hex "Physical address of main memory" if MMU
depends on !ARM_PATCH_PHYS_VIRT
default DRAM_BASE if !MMU
default 0x00000000 if ARCH_EBSA110 || \
ARCH_FOOTBRIDGE
default 0x10000000 if ARCH_OMAP1 || ARCH_RPC
default 0x20000000 if ARCH_S5PV210
default 0xc0000000 if ARCH_SA1100
help
Please provide the physical address corresponding to the
location of main memory in your system.
```
:::warning
If an architecture **enables `CONFIG_ARCH_HAS_HOLES_MEMORYMODEL` option**, it may free parts of the `mem_map` array that do not cover the actual physical pages. **In such case, the architecture specific :c:func:`pfn_valid` implementation should take the holes in the `mem_map` into account.**
:::
### DISCONTIGMEM
DISCONTIGMEM 如字面意思般適用於不連續記憶體上,是以 `nodes` 來操作 physical memory ,而對於每個 node 是以 `struct pglist_data` ( `pg_data_t` ) 獨立儲存自己的記憶體空間,如 free-page list 、in-use-page list 、 LRU 等相關資訊。每個 `pg_data_t` 則以 `node_mem_map` array 儲存 phsical pages ,`node_mem_map` 同如 FLATMEM 的 `mem_map` 。每個 node 的第一個 page frame 則以 `node_start_pfn` 標示,而這也造成了每當對應 pfn 轉 `struct page` 時,對要先了解是哪個 node 所有。
每個 node 的以 `free_area_init_node` 函式初始化它的 `pg_data_t` object 。
:::warning
可以從 FLATMEM 的 `free_area_init` 註解得知,`free_area_init` 會初始化所有 `pg_data_t` ,而 `free_area_init_node` 則是初始化單一 `pg_data_t` 。
:::
* [`/mm/page_alloc.c - free_area_init_node`](https://elixir.bootlin.com/linux/v5.10.38/source/mm/page_alloc.c#L7047)
```cpp
static void __init free_area_init_node(int nid)
{
pg_data_t *pgdat = NODE_DATA(nid);
unsigned long start_pfn = 0;
unsigned long end_pfn = 0;
/* pg_data_t should be reset to zero when it's allocated */
WARN_ON(pgdat->nr_zones || pgdat->kswapd_highest_zoneidx);
get_pfn_range_for_nid(nid, &start_pfn, &end_pfn);
pgdat->node_id = nid;
pgdat->node_start_pfn = start_pfn;
pgdat->per_cpu_nodestats = NULL;
pr_info("Initmem setup node %d [mem %#018Lx-%#018Lx]\n", nid,
(u64)start_pfn << PAGE_SHIFT,
end_pfn ? ((u64)end_pfn << PAGE_SHIFT) - 1 : 0);
calculate_node_totalpages(pgdat, start_pfn, end_pfn);
alloc_node_mem_map(pgdat);
pgdat_set_deferred_range(pgdat);
free_area_init_core(pgdat);
}
```
關於 `PFN` 以及 `struct page` 轉換較為複雜一些,是以 node number - `nid` ( node ID ) 為中介,利用 `pfn_to_nid` 和 `page_to_nid` 處理。因為在得知 `nid` 時,可以利用 `node_mem_map` array 的 index 得 struct page 並且以其 offset 加上 `node_start_pfn` 可得它的 PFN 。
> **nid** is the Node ID which is the logical identifier of the node whose zones are being initialised;
:::warning
Architectures that support DISCONTIGMEM provide **:c:func:`pfn_to_nid` to convert PFN to the node number**. The opposite conversion helper :c:func:`page_to_nid` is generic as it uses the node number encoded in page->flags
:::
### SPARSEMEM
> SPARSEMEM is the most versatile memory model available in Linux and it is the only memory model that supports several advanced features such as hot-plug and hot-remove of the physical memory, alternative memory maps for non-volatile memory devices and deferred initialization of the memory map for larger systems.
相對於 nodes 之間各自以 `pg_data_t` 維護記憶體空間的 DISCONTIGMEM , SPARSEMEM 抽象化了各個硬體架構之間的 memory map , 以 [`struct mem_section`](https://elixir.bootlin.com/linux/v5.10.38/source/include/linux/mmzone.h#L1193) 操作 physical memory ,並以 `section_mem_map` 指標指向 array of `struct page` 。 section 的大小以 `SECTION_SIZE_BITS` 常數表示,而最大數量則以前者和 `MAX_PHYSMEM_BITS`決定,而兩者皆依據架構而有所不同。`MAX_PHYSMEM_BITS` 是以用架構所提供的 physical address 大小定義; `SECTION_SIZE_BITS` 則為任意數。例如在 arm 架構,這兩個值分別為:
* [/arch/arm/include/asm/sparsemem.h](https://elixir.bootlin.com/linux/v5.10.38/source/arch/arm/include/asm/sparsemem.h#L23)
```cpp
/*
* Two definitions are required for sparsemem:
*
* MAX_PHYSMEM_BITS: The number of physical address bits required
* to address the last byte of memory.
*
* SECTION_SIZE_BITS: The number of physical address bits to cover
* the maximum amount of memory in a section.
*
* Eg, if you have 2 banks of up to 64MB at 0x80000000, 0x84000000,
* then MAX_PHYSMEM_BITS is 32, SECTION_SIZE_BITS is 26.
*
* These can be overridden in your mach/memory.h.
*/
#define MAX_PHYSMEM_BITS 36
#define SECTION_SIZE_BITS 28
```
而 section 的最大數量 `NR_MEM_SECTIONS` 定義為
$NR\_MEM\_SECTIONS = 2^{( MAX\_PHYSMEM\_BITS - SECTION\_SIZE\_BITS )}$
對於 pfn 轉 `struct page` ,在 PFN 的高位元之中儲存了在 array 之中的 index ,而在哪個 `mem_section` 則是在儲存於 page flag 。
在 SPARSEMEM 提出數個月之後 SPARSEMEM_EXTREME 被提出,以多個 `struct mem_section` object 組成名為 `mem_section` 的二維 array 。 array 大小受 `CONFIG_SPARSEMEM_EXTREME` 以及 section 的最大數量影響:
如果 `CONFIG_SPARSEMEM_EXTREME` disabled , 此為靜態 array , row 有 `NR_MEM_SECTIONS` 大小,而每個 row 只有一個 object 。若為 enable , 則為動態記憶體分配的 array , row 的總數為 計算過後要符合所有 memory sections 的數量,而每個 row 含有 `mem_section` 記憶體大小分之 `PAGE_SIZE` 個 object 。
* [/mm/sparse.c](https://elixir.bootlin.com/linux/v5.10.38/source/mm/sparse.c#L26)
```cpp
#ifdef CONFIG_SPARSEMEM_EXTREME
struct mem_section **mem_section;
#else
struct mem_section mem_section[NR_SECTION_ROOTS][SECTIONS_PER_ROOT]
____cacheline_internodealigned_in_smp;
#endif
```
* [/include/linux/mmzone.h](https://elixir.bootlin.com/linux/v5.10.38/source/include/linux/mmzone.h#L1223)
```cpp
#ifdef CONFIG_SPARSEMEM_EXTREME
#define SECTIONS_PER_ROOT (PAGE_SIZE / sizeof (struct mem_section))
#else
#define SECTIONS_PER_ROOT 1
#endif
#ifdef CONFIG_SPARSEMEM_EXTREME
extern struct mem_section **mem_section;
#else
extern struct mem_section mem_section[NR_SECTION_ROOTS][SECTIONS_PER_ROOT];
#endif
```
memory sections 與 memory maps 的初始化為呼叫 `sparse_init()` 函式。
在 `PFN` 與 `page` 間的轉換( `pfn_to_page` 和 `page_to_pfn` ),SPARSEMEM 有兩種選擇 - "classic sparse" 和 "sparse vmemmap",並在 build time 以 `CONFIG_SPARSEMEM_VMEMMAP` 作選擇。 SPARSEMEM_VMEMMAP 是在 2007 年的時候新增的,其理念是把整個 memory map 對應到虛擬化的記憶體區塊。
:::warning
Another enhancement to SPARSEMEM was added in 2007; it was called generic virtual memmap support for SPARSEMEM, or SPARSEMEM_VMEMMAP. **The idea behind SPARSEMEM_VMEMMAP is that the entire memory map is mapped into a virtually contiguous area, but only the active sections are backed with physical pages.** This model wouldn't work well with 32-bit systems, where the physical memory size might approach or even exceed the virtual address space. However, for 64-bit systems SPARSEMEM_VMEMMAP is a clear win. At the cost of additional page table entries, page_to_pfn(), and pfn_to_page() became as simple as with the flat model.
:::
sparse vmemmap 利用虛擬化 mapping 的手段最佳化了 pfn 以及 `struct page` 之間的轉換。`vmemmap` 為 `struct page` 結構的指標,指向 `struct page` object 組成的虛擬化的連續 array ,而 PFN 便是其 offset 。
:::warning
There is a **global `struct page *vmemmap` pointer** that points to a **virtually contiguous array of `struct page` objects**. A **PFN** is an index to that array and the offset of the `struct page` from `vmemmap` is the PFN of that page.
:::
根據 kernel doc 文件:
> **To use vmemmap, an architecture has to reserve a range of virtual addresses that will map the physical pages containing the memory map and make sure that `vmemmap` points to that range.** In addition, the architecture should implement :c:func:`vmemmap_populate` method that will allocate the physical memory and create page tables for the virtual memory map. If an architecture does not have any special requirements for the vmemmap mappings, it can use default :c:func:`vmemmap_populate_basepages` provided by the generic memory management.
`vmemmap` 是以連續的 virtual address 來儲存 memory map ,以 `vmemmap_populate` 分配 physical memory 並且也要建立相關的 page table 。
:::warning
**The virtually mapped memory map allows storing `struct page` objects for persistent memory devices in pre-allocated storage on those devices.** This storage is represented with `struct vmem_altmap` that is eventually passed to `vmemmap_populate()` through a long chain of function calls. The `vmemmap_populate()` implementation may use the `vmem_altmap` along with :c:func:`vmemmap_alloc_block_buf` helper to allocate memory map on the persistent memory device.
:::
:::success
**延伸閱讀 - ZONE_DEVICE**
> :::spoiler 原文
> The `ZONE_DEVICE` facility builds upon `SPARSEMEM_VMEMMAP` to offer `struct page` `mem_map` services for device driver identified physical address ranges. The "device" aspect of `ZONE_DEVICE` relates to the fact that the page objects for these address ranges are never marked online, and that a reference must be taken against the device, not just the page to keep the memory pinned for active use. `ZONE_DEVICE`, via :c:func:`devm_memremap_pages`, performs just enough memory hotplug to turn on :c:func:`pfn_to_page`, :c:func:`page_to_pfn`, and :c:func:`get_user_pages` service for the given range of pfns. Since the page reference count never drops below 1 the page is never tracked as free memory and the page's `struct list_head lru` space is repurposed for back referencing to the host device / driver that mapped the memory.
>
> While `SPARSEMEM` presents memory as a collection of sections, optionally collected into memory blocks, `ZONE_DEVICE` users have a need for smaller granularity of populating the `mem_map`. Given that `ZONE_DEVICE` memory is never marked online it is subsequently never subject to its memory ranges being exposed through the sysfs memory hotplug api on memory block boundaries. The implementation relies on this lack of user-api constraint to allow sub-section sized memory ranges to be specified to :c:func:`arch_add_memory`, the top-half of memory hotplug. Sub-section support allows for 2MB as the cross-arch common alignment granularity for :c:func:`devm_memremap_pages`.
>
> The users of `ZONE_DEVICE` are:
>
> * pmem: Map platform persistent memory to be used as a direct-I/O target via DAX mappings.
> * hmm: Extend `ZONE_DEVICE` with `->page_fault()` and `->page_free()` event callbacks to allow a device-driver to coordinate memory management events related to device-memory, typically GPU memory. See Documentation/vm/hmm.rst.
> * p2pdma: Create `struct page` objects to allow peer devices in a PCI/-E topology to coordinate direct-DMA operations between themselves, i.e. bypass host memory.
> :::
`ZONE_DEVICE` 與 `ZONE_MOVABLE` 一樣定義在 [/include/linux/mmzone.h](https://elixir.bootlin.com/linux/v5.10.38/source/include/linux/mmzone.h#L418)中,此 `enum` 讓 `SPARSEMEM_VMEMMAP` 提供了 `struct page` 和 `mem_map` 識別 device driver 的 physical address 範圍,而這些 address 永遠不會被標為 online ,亦即 [sysfs](https://en.wikipedia.org/wiki/Sysfs) 不會對它作與其他一般記憶體一樣的處置。
> Given that `ZONE_DEVICE` memory is never marked online it is subsequently never subject to its memory ranges being exposed through the sysfs memory hotplug api on memory block boundaries.
>
`ZONE_DEVICE` 利用 `devm_memremap_pages` 表示足夠的記憶體去能夠隨時開起 `pfn_to_page` 、`page_to_pfn` 、 `get_user_pages` 功能。
也因為 page reference 永遠不會低於 1 ,因此不會被劃分到如 free memory 、`struct list_head lru` 等空間,而是會重新導向至 mapping 到次記憶體空間的 the host device / driver 。
也因他不會在 memory block boundaries 被揭露於 sysfs memory hotplug API 上 ,因此他的相關記憶體操作是以 `arch_add_memory` 、`devm_memremap_pages` 等 API 操作。
> The implementation relies on this lack of user-api constraint to allow sub-section sized memory ranges to be specified to :c:func:`arch_add_memory`, the top-half of memory hotplug. Sub-section support allows for 2MB as the cross-arch common alignment granularity for :c:func:`devm_memremap_pages`.
註:`arch_add_memory` 是根據硬體架構而有所不同。
* [`/mm/memremap.c - devm_memremap_pages`](https://elixir.bootlin.com/linux/v5.10.38/source/mm/memremap.c#L425)
```cpp
/**
* devm_memremap_pages - remap and provide memmap backing for the given resource
* @dev: hosting device for @res
* @pgmap: pointer to a struct dev_pagemap
*
* Notes:
* 1/ At a minimum the res and type members of @pgmap must be initialized
* by the caller before passing it to this function
*
* 2/ The altmap field may optionally be initialized, in which case
* PGMAP_ALTMAP_VALID must be set in pgmap->flags.
*
* 3/ The ref field may optionally be provided, in which pgmap->ref must be
* 'live' on entry and will be killed and reaped at
* devm_memremap_pages_release() time, or if this routine fails.
*
* 4/ range is expected to be a host memory range that could feasibly be
* treated as a "System RAM" range, i.e. not a device mmio range, but
* this is not enforced.
*/
void *devm_memremap_pages(struct device *dev, struct dev_pagemap *pgmap)
{
int error;
void *ret;
ret = memremap_pages(pgmap, dev_to_node(dev));
if (IS_ERR(ret))
return ret;
error = devm_add_action_or_reset(dev, devm_memremap_pages_release,
pgmap);
if (error)
return ERR_PTR(error);
return ret;
}
EXPORT_SYMBOL_GPL(devm_memremap_pages);
```
:::
---
## Mapping address to page
### page to pfn and back
大略說明完三種 memory model 後,再來看 page 與 address 是如何轉換。在先前有說明到,不同的 memory model 有不同 physical memory 的管理機制,因此在轉換的過程也可能會不同。
`struct page` 在轉換成 address 時,會先轉換成 **page frame number** ( `pfn` ) ,之後在根據不同 memory model 的管理結構作偏移。
* [GitHub - linux/include/linux/pfn.h](https://github.com/torvalds/linux/blob/master/include/linux/pfn.h)
```cpp
/*
* pfn_t: encapsulates a page-frame number that is optionally backed
* by memmap (struct page). Whether a pfn_t has a 'struct page'
* backing is indicated by flags in the high bits of the value.
*/
typedef struct {
u64 val;
} pfn_t;
```
* [Linux kernel source tree - arch/arm/include/asm/memory.h](https://git.kernel.org/pub/scm/linux/kernel/git/stable/linux.git/tree/arch/arm/include/asm/memory.h?h=v5.10.35#n353)
```cpp
/*
* Conversion between a struct page and a physical address.
*
* page_to_pfn(page) convert a struct page * to a PFN number
* pfn_to_page(pfn) convert a _valid_ PFN number to struct page *
*
* virt_to_page(k) convert a _valid_ virtual address to struct page *
* virt_addr_valid(k) indicates whether a virtual address is valid
*/
```
* [/include/asm-generic/memory_model.h](https://elixir.bootlin.com/linux/v5.10.39/source/include/asm-generic/memory_model.h#L82)
```cpp
#ifndef __ASSEMBLY__
...
/*
* supports 3 memory models.
*/
#if defined(CONFIG_FLATMEM)
#define __pfn_to_page(pfn) (mem_map + ((pfn)-ARCH_PFN_OFFSET))
#define __page_to_pfn(page) ((unsigned long)((page)-mem_map) + ARCH_PFN_OFFSET)
#elif defined(CONFIG_DISCONTIGMEM)
#define __pfn_to_page(pfn) \
({ \
unsigned long __pfn = (pfn); \
unsigned long __nid = arch_pfn_to_nid(__pfn); \
NODE_DATA(__nid)->node_mem_map + arch_local_page_offset(__pfn, __nid); \
})
#define __page_to_pfn(pg) \
({ \
const struct page *__pg = (pg); \
struct pglist_data *__pgdat = NODE_DATA(page_to_nid(__pg)); \
(unsigned long)(__pg - __pgdat->node_mem_map) + __pgdat->node_start_pfn; \
})
#elif defined(CONFIG_SPARSEMEM_VMEMMAP)
/* memmap is virtually contiguous. */
#define __pfn_to_page(pfn) (vmemmap + (pfn))
#define __page_to_pfn(page) (unsigned long)((page)-vmemmap)
#elif defined(CONFIG_SPARSEMEM)
/*
* Note: section's mem_map is encoded to reflect its start_pfn.
* section[i].section_mem_map == mem_map's address - start_pfn;
*/
#define __page_to_pfn(pg) \
({ \
const struct page *__pg = (pg); \
int __sec = page_to_section(__pg); \
(unsigned long)(__pg - __section_mem_map_addr(__nr_to_section(__sec))); \
})
#define __pfn_to_page(pfn) \
({ \
unsigned long __pfn = (pfn); \
struct mem_section *__sec = __pfn_to_section(__pfn); \
__section_mem_map_addr(__sec) + __pfn; \
})
#endif /* CONFIG_FLATMEM/DISCONTIGMEM/SPARSEMEM */
/*
* Convert a physical address to a Page Frame Number and back
*/
#define __phys_to_pfn(paddr) PHYS_PFN(paddr)
#define __pfn_to_phys(pfn) PFN_PHYS(pfn)
#define page_to_pfn __page_to_pfn
#define pfn_to_page __pfn_to_page
#endif /* __ASSEMBLY__ */
#endif
```
:::warning
此為沒有 `__ASSEMBLY__` 定義的轉換。
此外 [/include/asm-generic/memory_model.h](https://elixir.bootlin.com/linux/v5.10.39/source/include/asm-generic/memory_model.h),更精確的說是 `asm-generic` 也有補足未定義到相關操作的架構。
就如, arm 架構沒有對 `pfn_to_virt` 有自己的定義,因此會因用此標頭檔。
:::
### pfn to physical address and back
* [/include/linux/pfn.h](https://elixir.bootlin.com/linux/v5.10.39/source/include/linux/pfn.h#L21)
```cpp
#define PFN_PHYS(x) ((phys_addr_t)(x) << PAGE_SHIFT)
#define PHYS_PFN(x) ((unsigned long)((x) >> PAGE_SHIFT))
```
:::info
利用上述 marco 可組成 pfn 與 pte 之間得關係:
* [/arch/arm/include/asm/pgtable.h](https://elixir.bootlin.com/linux/latest/source/arch/arm/include/asm/pgtable.h#L176)
```cpp
#define pmd_page(pmd) pfn_to_page(__phys_to_pfn(pmd_val(pmd) & PHYS_MASK))
#define pte_pfn(pte) ((pte_val(pte) & PHYS_MASK) >> PAGE_SHIFT)
#define pfn_pte(pfn,prot) __pte(__pfn_to_phys(pfn) | pgprot_val(prot))
#define pte_page(pte) pfn_to_page(pte_pfn(pte))
#define mk_pte(page,prot) pfn_pte(page_to_pfn(page), prot)
```
:::
### pfn to virtual address and back
* [/arch/arm/include/asm/memory.h](https://elixir.bootlin.com/linux/v5.10.39/source/arch/arm/include/asm/memory.h#L284)
```cpp
#define virt_to_pfn(kaddr) \
((((unsigned long)(kaddr) - PAGE_OFFSET) >> PAGE_SHIFT) + \
PHYS_PFN_OFFSET)
```
* [/include/asm-generic/page.h](https://elixir.bootlin.com/linux/v5.10.39/source/include/asm-generic/page.h#L82)
```cpp
#define pfn_to_virt(pfn) __va((pfn) << PAGE_SHIFT)
```
:::info
關於 VA 與 pfn ,也可以利用這些 marco 與相關 page table 操作在目標 page table 中新增 entry :
* [/arch/arm64/mm/trans_pgd.c](https://elixir.bootlin.com/linux/latest/source/arch/arm64/mm/trans_pgd.c#L272)
```cpp
/*
* Add map entry to trans_pgd for a base-size page at PTE level.
* info: contains allocator and its argument
* trans_pgd: page table in which new map is added.
* page: page to be mapped.
* dst_addr: new VA address for the page
* pgprot: protection for the page.
*
* Returns 0 on success, and -ENOMEM on failure.
*/
int trans_pgd_map_page(struct trans_pgd_info *info, pgd_t *trans_pgd,
void *page, unsigned long dst_addr, pgprot_t pgprot)
{
pgd_t *pgdp;
p4d_t *p4dp;
pud_t *pudp;
pmd_t *pmdp;
pte_t *ptep;
pgdp = pgd_offset_pgd(trans_pgd, dst_addr);
if (pgd_none(READ_ONCE(*pgdp))) {
p4dp = trans_alloc(info);
if (!pgdp)
return -ENOMEM;
pgd_populate(NULL, pgdp, p4dp);
}
p4dp = p4d_offset(pgdp, dst_addr);
if (p4d_none(READ_ONCE(*p4dp))) {
pudp = trans_alloc(info);
if (!pudp)
return -ENOMEM;
p4d_populate(NULL, p4dp, pudp);
}
pudp = pud_offset(p4dp, dst_addr);
if (pud_none(READ_ONCE(*pudp))) {
pmdp = trans_alloc(info);
if (!pmdp)
return -ENOMEM;
pud_populate(NULL, pudp, pmdp);
}
pmdp = pmd_offset(pudp, dst_addr);
if (pmd_none(READ_ONCE(*pmdp))) {
ptep = trans_alloc(info);
if (!ptep)
return -ENOMEM;
pmd_populate_kernel(NULL, pmdp, ptep);
}
ptep = pte_offset_kernel(pmdp, dst_addr);
set_pte(ptep, pfn_pte(virt_to_pfn(page), pgprot));
return 0;
}
```
:::
### Page to physical address and back
利用 pfn 和 phsical address 的關係。
* [Linux kernel source tree - arch/arm/include/asm/memory.h](https://git.kernel.org/pub/scm/linux/kernel/git/stable/linux.git/tree/arch/arm/include/asm/memory.h?h=v5.10.35#n129)
```cpp
/*
* Convert a page to/from a physical address
*/
#define page_to_phys(page) (__pfn_to_phys(page_to_pfn(page)))
#define phys_to_page(phys) (pfn_to_page(__phys_to_pfn(phys)))
```
:::info
在分配 page table 記憶體的相關函式,則會用到 [`page_to_phys`](https://elixir.bootlin.com/linux/latest/source/arch/arm/include/asm/pgalloc.h) 。
:::
### page to virtual address and back
* [/arch/arm64/include/asm/memory.h](https://elixir.bootlin.com/linux/latest/source/arch/arm64/include/asm/memory.h#L331)
```cpp
#if !defined(CONFIG_SPARSEMEM_VMEMMAP) || defined(CONFIG_DEBUG_VIRTUAL)
#define page_to_virt(x) \
({ \
__typeof__(x) __page = x; \
void *__addr = __va(page_to_phys(__page)); \
(void *)__tag_set((const void *)__addr, page_kasan_tag(__page)); \
})
#define virt_to_page(x) pfn_to_page(virt_to_pfn(x))
#else
#define page_to_virt(x) \
({ \
__typeof__(x) __page = x; \
u64 __idx = ((u64)__page - VMEMMAP_START) / sizeof(struct page); \
u64 __addr = PAGE_OFFSET + (__idx * PAGE_SIZE); \
(void *)__tag_set((const void *)__addr, page_kasan_tag(__page)); \
})
#define virt_to_page(x) \
({ \
u64 __idx = (__tag_reset((u64)x) - PAGE_OFFSET) / PAGE_SIZE; \
u64 __addr = VMEMMAP_START + (__idx * sizeof(struct page)); \
(struct page *)__addr; \
})
#endif /* !CONFIG_SPARSEMEM_VMEMMAP || CONFIG_DEBUG_VIRTUAL */
```
:::danger
arm 沒有 `page_to_virt` , 但 arm64 有。
:::
### Virtual Address to Phyiscal Address and back
[tldp.org - Translating Addresses in Kernel Space](https://tldp.org/LDP/khg/HyperNews/get/devices/addrxlate.html)
* [arch/arm/include/asm/memory.h](https://git.kernel.org/pub/scm/linux/kernel/git/stable/linux.git/tree/arch/arm/include/asm/memory.h?h=v5.10.35#n274)
```cpp
/*
* These are *only* valid on the kernel direct mapped RAM memory.
* Note: Drivers should NOT use these. They are the wrong
* translation for translating DMA addresses. Use the driver
* DMA support - see dma-mapping.h.
*/
#define virt_to_phys virt_to_phys
static inline phys_addr_t virt_to_phys(const volatile void *x)
{
return __virt_to_phys((unsigned long)(x));
}
#define phys_to_virt phys_to_virt
static inline void *phys_to_virt(phys_addr_t x)
{
return (void *)__phys_to_virt(x);
}
/*
* Drivers should NOT use these either.
*/
#define __pa(x) __virt_to_phys((unsigned long)(x))
#define __pa_symbol(x) __phys_addr_symbol(RELOC_HIDE((unsigned long)(x), 0))
#define __va(x) ((void *)__phys_to_virt((phys_addr_t)(x)))
#define pfn_to_kaddr(pfn) __va((phys_addr_t)(pfn) << PAGE_SHIFT)
```
:::warning
[stackoverflow - Is there any API for determining the physical address from virtual address in Linux?](https://stackoverflow.com/questions/5748492/is-there-any-api-for-determining-the-physical-address-from-virtual-address-in-li)
`asm/io.h`
```cpp
virt_to_phys(virt_addr);
phys_to_virt(phys_addr);
virt_to_bus(virt_addr);
bus_to_virt(bus_addr);
```
:::
---
> [下篇:Linux 核心 Copy On Write - Memory Region](https://hackmd.io/@linD026/Linux-kernel-COW-memory-region)