# MPI
## Message Passing Interface (MPI)
- 跨語言的 **平行程式 API** 標準,常用在 HPC 領域的程式開發
- 通常支援直接 C/C++ 及 Fortran
- 透過擴充的 library 也可以在 Java、Python 等語言執行
- 定義 **processes** 之間的的 **通訊介面/協定**
- 高階的訊息傳遞 API,比 POSIX 原生的 IPC 更容易使用
- 同時有極高的效率以及移植性
- MPI 可以透過各類型的網路(TCP、IB)做 **跨 nodes 的溝通**
- MPI 程式可以 **直接運行在 cluster 上**,**不需要修改原始碼**
- 執行時在指令中加入相關參數,就能指定要執行在哪些 nodes 上
- MPI 本身就支援多 nodes 執行的功能
- 不需要 Slurm 等管理軟體也能直接在多節點上執行,但通常還是會搭配 Slurm 使用
- 只需要基本的網路設定並啟用 SSH、NFS 服務
- 除了提供溝通的介面,MPI 本身就會讓 **程式平行化**
- 用 **Multi-Process** 的方式平行化
- MPI 會依照硬體環境或指令參數,**自動啟動多個 process**
- 不需要用 `fork()` 之類的 API 手動建 process
- 在 cluster 中,會自動讓 process 在不同 nodes 上啟動
### 名詞定義
MPI 環境中,有下列幾個主要的物件
- 呼叫 MPI 的 API 進行溝通前,需先透過 API 初始化這些物件
:::success
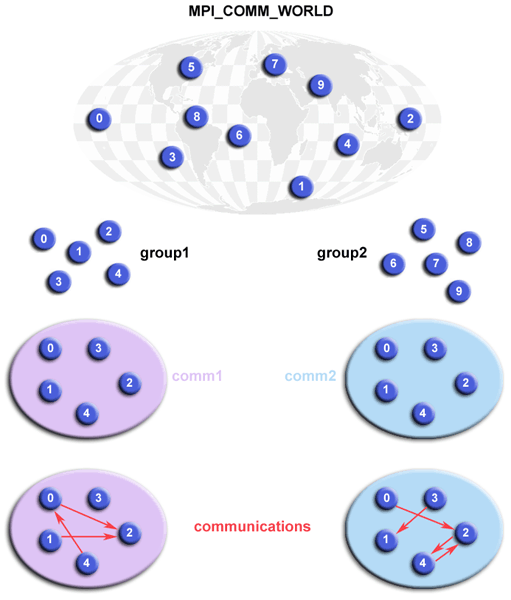
**Communicator** (`MPI_Comm`)
- MPI 中的一種物件,用來進行 **processes 間的溝通**
- 一個 communicator 可以連結多個 processes
- processes 必須在 ***同一個 communicator 中才能互相溝通***
- 用網路中的術語來比喻:
- 把每個 process 當作一台電腦
- 那 communicator 就是連接所有電腦的 link (或是 switch)
- 大部分 API 需要 communicator 作為參數,指定要進行傳輸工作的是哪一組 processes
- **`MPI_COMM_WORLD`** 是一個 communicator 常數,會在程式開始執行時 **被系統初始化**
- 連結 **本次執行時**,啟動的 **所有 processes**
:::
:::info
**Group**
- 一個 **communicator 中的所有 processes**,所成的一個集合
- 一個 group 對應到一個 communicator
- 和 communicator 不同的是
- **Group** 指的是 **processes 的集合** (Collection of processes)
- **Communicator** 是 **用來進行訊息傳輸的物件**,它連結了某個 group 中的 processes
:::
:::warning
**Rank**
- 一個整數,用來 **辨識不同 process**,由 MPI 環境自動指派
- **同一個 communicator** 中,**rank 不會重複**
- Rank 會 **從 0 開始**
- 若一 communicator 中共有 **n 個 processes**,那 rank 的範圍就是 **0~n-1**
- **rank 加上 communicator**,即可對應 **某一個特定的 process**
:::
- 除了系統自動初始化的 `MPI_COMM_WORLD`,也可以自行透過相關的 API 另外建立其他的 communicator 和 group
### MPI Implementations
MPI 只是一個 **介面**,只定義了標準和規格,而 **沒有特定的實作**
- 只是一套標準,而不是一套特定的軟體、套件或 library
- 但 MPI 實作至少要滿足 MPI 定義的所有標準
所以目前有許多不同組織開發、發行的版本 (通常是套件及 library 的形式)
:::success
**OpenMPI**
- **開源** 的 MPI Library
- 支援 Unix 和 Unix-Like 作業系統
- 可以跨 (硬體) 平台執行
:::
:::info
**Intel MPI**
- Intel 開發、發行的 MPI
- 針對 **Intel CPU 優化**
:::
以上兩種是常見的 MPI 版本,兩者沒有絕對的優劣
- 實際的效能差異,受硬體硬體平台和執行的軟體影響
## MPI Commands
### Compile
MPI 編譯器是 **gcc/g++ 的 wrapper**
- MPI 原始碼和 library 被 MPI 編譯器處理好後,**最終的編譯仍是 gcc/g++ 執行**
- 參數和 **使用方式** 都和 **gcc/g++ 相同**
完全用 C 開發的原始碼
- 使用 **mpicc** 編譯
- 對應 **gcc**
:::info
**Example**
編譯原始碼 `hello.c`,並將執行檔存檔為 `hello`
```bash
mpicc hello.c -o hello
```
:::
有用到 C++ 語法的原始碼
- 使用 **mpic++** 或是 **mpicxx** 編譯
- 對應 **g++**
:::info
**Example**
編譯原始碼 `hello.cc`,並將執行檔存檔為 `hello`
```bash
mpic++ hello.cc -o hello
# or
mpicxx hello.cc -o hello
```
:::
### Execute
MPI 程式編譯後的二進位檔案(執行檔)需要用 `mpirun` 或 `mpiexec` 指令執行
:::info
**Example**
啟動執行檔 `hello`
```bash
mpirun hello
# or
mpiexec hello
```
- 以上指令沒有額外參數和選項,MPI 會開啟和 **CPU 總核心數數量** 相同的 processes
- 如果是 *4 核心的 CPU*,就會啟動 *4 個 processes*
- 如果 **用 Slurm 先分配好** CPU,那 **只使用分配到的 CPU**
- E.g., `salloc -n 4 mpirun hello`
- 分配 4 個 CPU core
- 對 `mpirun` 來說,系統就只會有 4 個 CPU core,所以會啟動 4 個 processes
:::
- `mpirun` 和 `mpiexec` 後面接的參數是 **執行檔的 path**,可以是絕對或相對路徑
- 所以 **`mpirun hello`** 和 **`mpirun ./hello`** 是相同的意義
- 這邊的 `./hello` 不是 "_啟動 hello 檔案_",而是檔案的相對路徑
- 代表目前目錄下的 `hello` 檔案
<!-- - 預設情況下,MPI 會自動把 **一個 process,bind 到一個 CPU core 上**
- **一個 process** 只會跑在 **一個固定的 core 上**
- Bind 的方式可以透過其他 MPI 指令設定 -->
<!-- 實驗後發現 MPI 本身好像不會綁定 Slurm 才會 -->
### Command-line Arguments
如果要執行的程式有 command-line arguments,arguments 要放在 **執行檔名稱之後**
:::info
**Example**
```bash
mpirun hello PJ
```
- `PJ` 為 `hello` 的 argument
:::
### 指定 Process 數量
- `-np <num>`: 啟動 `<num>` 個 processes
- `-c`, `-n`, `--n` 或 `-np` 都是相同的功能
:::info
**Example**
用 4 個 process 執行 `hello`
```bash
mpirun -c 4 hello
# or
mpirun -n 4 hello
# or
mpirun --n 4 hello
# or
mpirun -np 4 hello
```
:::
## MPI 執行原理
- 使用 `mpirun` 指令時,會自動建立多個 process,並透過這些 process 執行指定的 binary
### 實驗
- 引入 `unist.h` 以使用 `getpid()` 和 `getppid()`
- 這兩個 API 可以拿到目前 process 的 PID 和 praent process 的 PID
```c
// demo.c
#include <mpi.h>
#include <stdio.h>
#include <unistd.h>
int main(int argc, char** argv) {
MPI_Init(&argc, &argv);
int pid = getpid();
int ppid = getppid();
printf("PID: %d, PPID: %d\n", pid, ppid);
MPI_Finalize();
}
```
- **Compile & Run**
```
mpicc demo.c -o demo
mpirun -np 4 demo
```
- **Output**
```
PID: 3235, PPID: 3231
PID: 3236, PPID: 3231
PID: 3237, PPID: 3231
PID: 3238, PPID: 3231
```
> 數值僅供參考,實際 PID 在執行時才會確定
- 所有 process 的 parent 都是同一個,且不是這幾個 process 的任何一個
- 可以確定額外的 process 不是由 `demo` 的 process 產生的
- 也就是說,我們寫的程式本身不會建立任何額外的 process
- 和 `fork()` 的行為不同
### 使用 `ps` 指令觀察
- 在程式中加上 `sleep()`,拉長整體的執行時間
- 在執行結束前,打開另一個 terminal,並且用 `ps` 指令觀察系統中的所有 process
```c
// demo.c
#include <mpi.h>
#include <stdio.h>
#include <unistd.h>
int main(int argc, char** argv) {
MPI_Init(&argc, &argv);
int pid = getpid();
int ppid = getppid();
printf("PID: %d, PPID: %d\n", pid, ppid);
sleep(5); // 暫停程式 5 秒
MPI_Finalize();
}
```
執行結果如下:

- 執行檔 `demo` 的 4 個 processes 的 parent 都是 3231
- 從 `ps` 的結果可以看到 3231 確實就是 `mpirun`
- 可以確定 `demo` 的所有 process 都是由 `mpirun` 啟動的
## MPI Hello World!
- 以下範例程式會使用到一些常用或必要的 API
- 詳細的 API 說明,會在其他幾篇筆記中
### MPI 程式基本架構
- MPI 的所有 API 和常數都定義在 header 檔案: `mpi.h`
- MPI 程式中一定要呼叫 `MPI_Init()` 和 `MPI_Finalize()`
- 所有 MPI API 的呼叫一定要在 `MPI_Init()` 之前,`MPI_Finalize()` 之後
:::info
```c
#include <mpi.h>
int main(int argc, char** argv) {
// non-MPI function calls
// ...
MPI_Init(&argc, &argv);
// MPI and non-MPI function calls
// ...
MPI_Finalize();
// non-MPI function calls
// ...
}
```
:::
**`MPI_Init(int*, char***)`**
- **初始化** 執行環境
- 呼叫此 function **前**,***不能*** 呼叫其他 MPI function,且此 function 在一個 process 中 **只能呼叫一次**
- 通常以 `argc` 和 `argv` 的指標當引數呼叫
```c
int main(int argc, char** argv) {
MPI_Init(&argc, &argv);
// ...
}
```
- 如果程式不需要 command line argument,可以用 `NULL` 當引數呼叫
```c
int main(int argc, char** argv) {
MPI_Init(NULL, NULL);
// ...
}
```
**`MPI_Finalize()`**
- **終止** 執行環境
- 呼叫此 function **後**,***不能*** 呼叫其他 MPI function,且此 function 在一個 process 中 **只能呼叫一次**
- 如果沒有呼叫 `MPI_Finalize()`,只要有其中 **一個 process 結束** 執行,**所有 processes 都會被強制終止**
- 可能導致程式有非預期的執行結果
- 部分 process 可能執行到一半就被中斷
:::success
**Example: Hello, World!**
```c
// hello.c
#include <stdio.h>
#include <mpi.h>
int main(int argc, char** argv) {
// init MPI environment
MPI_Init(&argc, &argv);
printf("Hello, World!\n");
// finalize MPI environment
MPI_Finalize();
}
```
- **Compile & Run**
```bash
mpicc hello.c -o hello
mpirun -np 2 hello
```
- **Output**
```
Hello, World!
Hello, World!
```
:::
:::warning
- **不像** Linux 原生的 `fork()` 或是 OpenMP
- 呼叫 `fork()` 後才會平行執行
- 使用 OpenMP,被標記為要 multi-threading 的地方才會平行執行
- MPI 程式從 **啟動到結束**,**全程都是平行執行**
- 在 `MPI_Init()` 前、和 `MPI_MPI_Finalize()` 後的程式碼,也會被所有 processes 執行
- 代表 **額外的 process *不是* 在程式執行期間建立的**
- 所以下面程式碼有一樣的執行結果
```c
#include <stdio.h>
#include <mpi.h>
int main(int argc, char** argv) {
printf("Hello, World!\n");
// init MPI environment
MPI_Init(&argc, &argv);
// finalize MPI environment
MPI_Finalize();
}
```
- 建議還是把 `MPI_Init()` 寫在最前面、`MPI_Finalize()` 寫在最後面,可讀性會更好
:::
### 取得環境資訊
**`MPI_Comm_rank(MPI_Comm comm, int* rank)`**
- 取得目前 process,在某個 communicator 中的 rank
- 第一個參數是要查詢的 communicator
- 第二個參數是 int pointer,指向用來存 rank 的記憶體空間
**`MPI_Comm_size(MPI_Comm comm, int* size)`**
- 取得某個 communicator 的 size (有幾個 process)
- 第一個參數是要查詢的 communicator
- 第二個參數是 int pointer,指向用來存 size 的記憶體空間
:::success
**Example: Get Rank and Communicator Size**
```c
// hello.c
#include <mpi.h>
#include <stdio.h>
int main(int argc, char** argv) {
// init MPI environment
MPI_Init(&argc, &argv);
// 宣告儲存 rank 和 size 的變數
int rank, comm_size;
// 把 rank、size 的指標傳給 MPI_Comm_rank()、MPI_Comm_size()
// 讓 funciton 可以修改 rank、size 的值 (pass by pointer)
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &comm_size);
printf("Process %d-%d: Hello, World!\n", rank, comm_size);
// finalize MPI environment
MPI_Finalize();
}
```
- **Compile & Run**
```bash
mpicc hello.c -o hello
mpirun -np 2 hello
```
- **Output**
```
Process 0-2: Hello, World!
Process 1-2: Hello, World!
```
> 實際輸出的順序可能不同,因為沒辦法確定哪個 process 會先執行
:::