
<p style="text-align: center"><b><font size=5 color=blueyellow>Practical Deep Learning - Day 1</font></b></p>
:::success
**Practical Deep Learning — Schedule**: https://hackmd.io/@yonglei/practical-deep-learning-schedule-2025
:::
## Schedule
| Time | Contents | Instructor(s) |
| :---------: | :------: | :-----------: |
| 09:00-09:10 | Welcome | YW |
| 09:10-09:50 | Introduction to Deep Learning | YW |
| 09:50-10:00 | Coffee Break | |
| 10:00-10:50 | Classification by a neural network using Keras (I) | AM |
| 10:50-11:00 | Coffee Break | |
| 11:00-11:50 | Classification by a neural network using Keras (II) | AM |
| 11:50-12:00 | Wrap-up | |
---
## Setup your environment
### LUMI
Go to Open On-demand interface: <https://www.lumi.csc.fi/pun/sys/dashboard/>
==Choose Jupyter==
:::info
* **Project:** project_465001310
* **Partition:** dev-g
#### Resources
* **Number of CPU cores:** 8
* **Memory (GiB):** 8
* **Number of GPUs:** 1
* **Time:** 3:00:00
#### Settings
* **Working directory:** /scratch/project_465001310
* **Show advanced settings:** :heavy_check_mark:
* **Custom Python type:** container
* **Modules to load:**
```
LUMI/22.08 partition/G rocm/6.0.3
```
* **Path to container with Python:**
```
/scratch/project_465001310/env-deep-learning-intro/container.sif
```
* **Container arguments:** `--rocm`
* **Init script for container:**
```
/scratch/project_465001310/env-deep-learning-intro/init_script.sh
```
* **Enable virtual environment:** :no_entry_sign:
* **Save settings**: Give it a name, like `deep-learning-intro`, so that you can use it later!
:::
==Launch Jupyter, and change to your directory==
The init script should have created one for you under the _scratch directory_ at `env-deep-learning-intro/workspace/$USER/deep-learning-intro/notebooks/lumi`
:::danger
You can ask questions about the workshop content at the bottom of this page. We use the Zoom chat only for reporting Zoom problems and such.
:::
---
## Questions, answers and information
- Is this how to ask a question?
- Yes, and an answer will appear like so!
### ==1. Introduction==
**human neuron vs deep learning neuron**

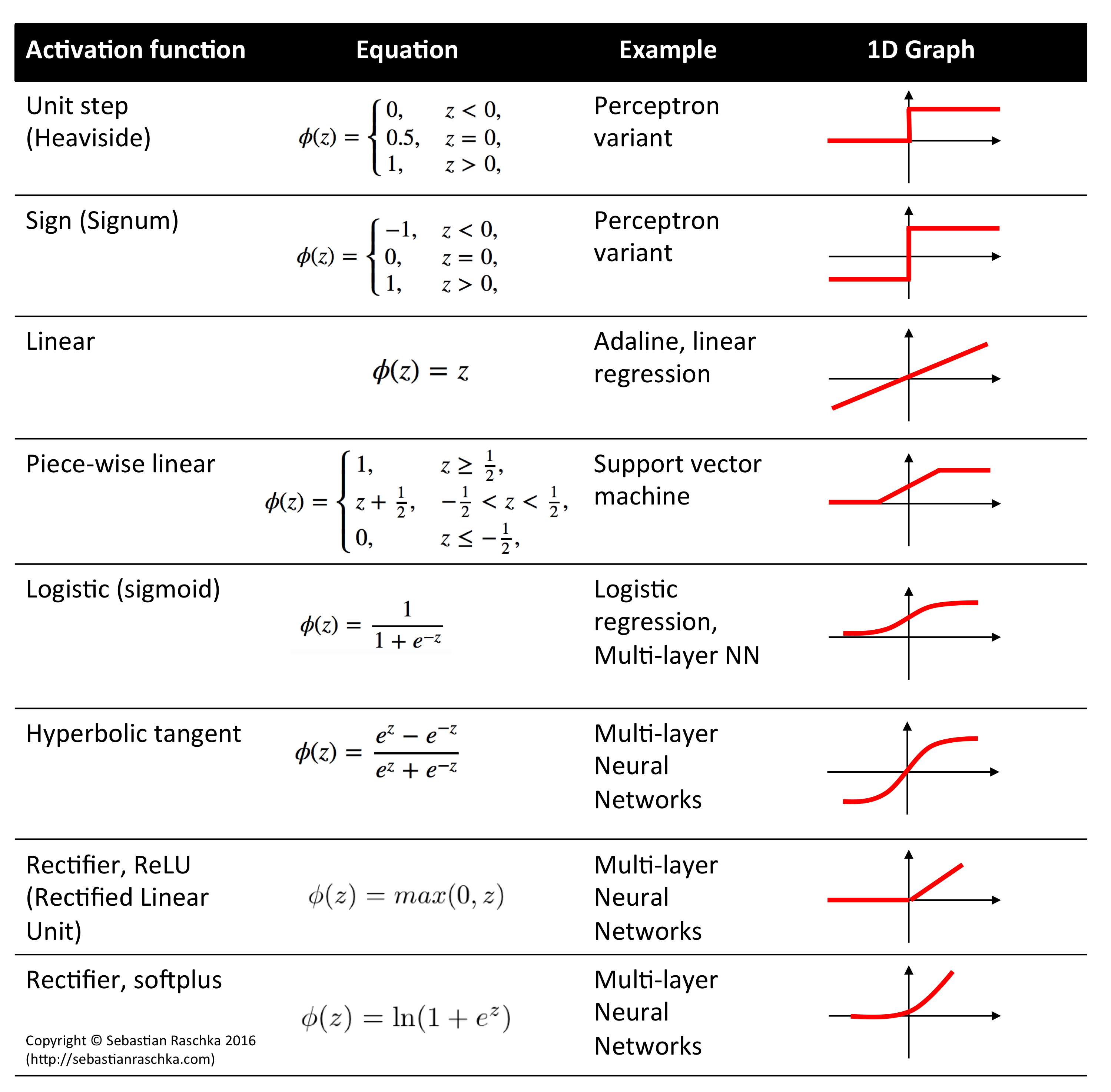
**activation functions**
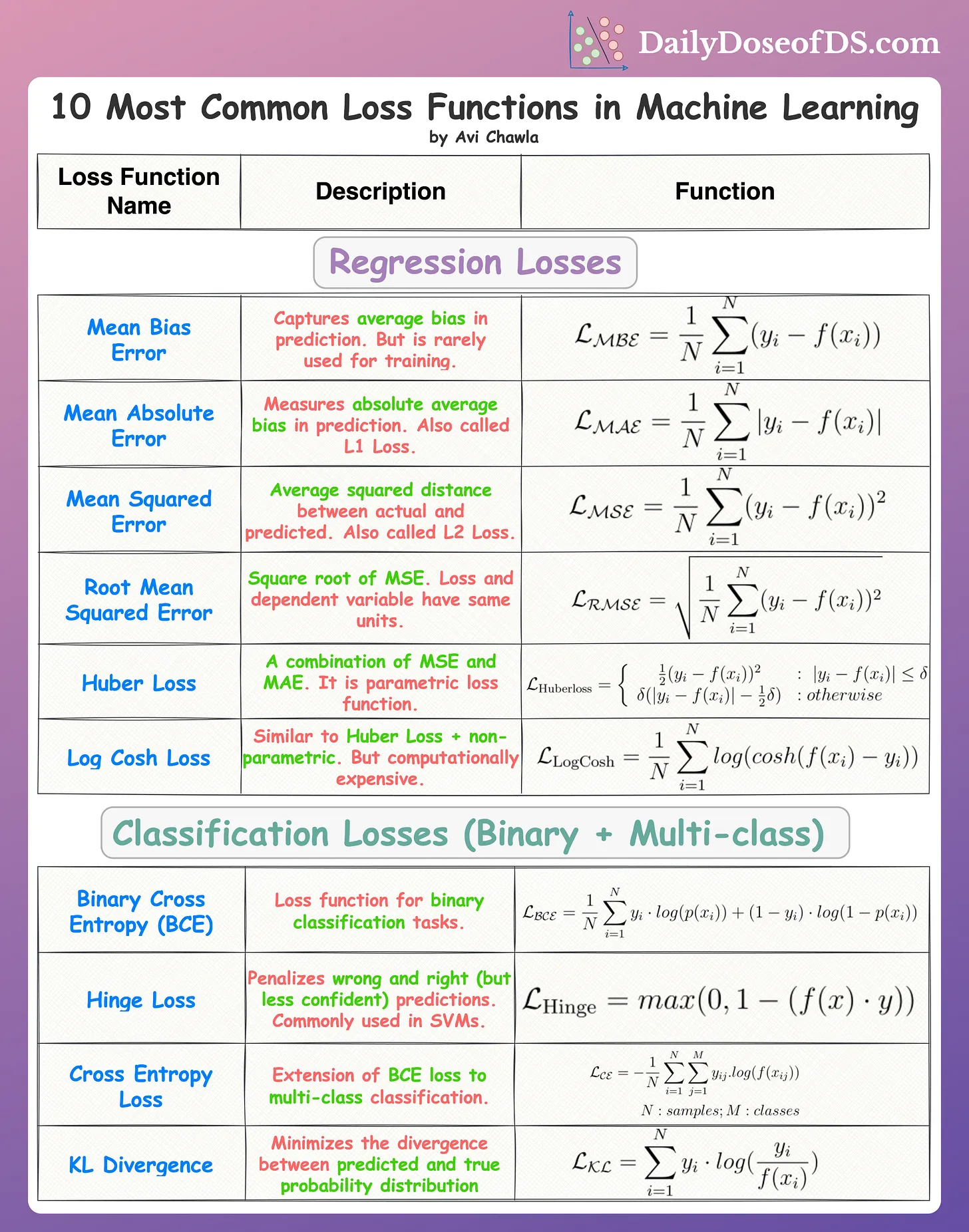
**LOSS functions**
- Question from S.H: If we have more features than number of data samples is that an issue?
- We will take a look at this in episode 2. The short answer is that it is important to explore the data and visualize it. Based on that, throwing out some features could be useful.
## ==2. Classification by a neural network using Keras==
Do you have Jupyter Lab up and running?
*Add a `+` to cast your vote*
- Yes:+ + + + + + + +
- No:
- Maybe: I got a Jupyter Notebook, but the names of the directories are not as expected. I started in /users/<my_username>
```shell=
git clone https://github.com/ENCCS/deep-learning-intro
```
### ==Pairplot==
- Is there any class that is easily distinguishable from the others?
*Add a `+` to cast your vote*
- Adelie:
- Chinstrap:
- Gentoo:+ ++ ++ + +
- Which combination of attributes shows the best separation for all 3 class
labels at once?
- bill_depth vs bill_length
- bill_length/flipper_length (+2 +1 +1 +)
- bill_length, bill depth, flipper_length
### ==One-hot encoding==
How many output neurons will our network have now that we one-hot encoded the
target class?
*Add a `+` to cast your vote*
A: 1
B: 2
C: 3 ++++++++
- Would it be a good idea to use normalization of the used features e.g. to their mean value (and standard deviation)? Otherwise they might be weighed differently in the process just by having different numerical ranges.
- yes, normalization is one import step to get well-organized data
- Can there be backedges or loops in neural networks with multiple hidden layers?
- Yes, in recurrent neural networks there are loops. For example, RNNs are applied in tasks which has a time component and the "loops" are used to connect back to time history of the data.
- Can you recommend some easy example projects where we can set up a DL neural network from scratch to get some practice?
- The "titanic survival prediction" problem is a very good task to start with.
- the [**iris flower**](https://www.kaggle.com/code/kamrankausar/iris-dataset-ml-and-deep-learning-from-scratch) is also a good case to start with
- How is uncertainty handled in the data? Meaning if I would have objects where overlay is possible, but they still not the same? Example would be I have a distinct pattern of peaks, but the peaks position can vary due to instrumental problems. Is there a chance to seperate multiple patterns with deep learning? A pattern (combination of peaks) identifies one object.
- i would say that the amount of data is a significant way to reduce the uncertainty, like the penguins classification problem, we got three values (high and low probabilities for one penguine to be Adelie, gentoo, and chinstrap)
- *i.e.*, if we have a small amount of data, we might get three values like 0.1 (for adelie), 0.44 (for gentoo), and 0.46 (for chinstrap).
- from the output, it seems that we should consider this penguine to be a chinstrap, but the probability for this penguine to be a gentoo is almost similar to that to be a chinstrap.
- a better way is to collect more data, as much as possbile, as this will decrease the uncertainty
- Thank you. Even a penguin could be identified with 10 different parameters? It would not matter if features overlay? I would be still able to identify the right penguin? In the penguin example, we know already that there are 3 penguin. But what if I would not know the number of penguin beforehand?
- not applicable, for the classification problem, we can only classify the "unknown" feature to the "known" ones in the dataset
- When you say this is not applicable, could I provide a database where each entry shows the 10 features and then I check against the database? There is no chance I can solve this problem with deep learning? In this database would be for example 500000 different objects.
- reinforcement learning will be a good option for your case, you train the model with data, and check the result, give it a reward it the prediction is true, and a penalty if the prediction is not true, then iterative train the model until you get a good score for the training :+1:
- and I could add artificially uncertainty on my objects in the database to have little shifts in the features?
- yes, you can do some "manual" work to the dataset
- another option is to increase the sensitivity of the algorithm
- You show commands one after the other. Could you maybe comment on how relevant software design principles are relevant to make this reusable?
- Is `epoch` a unit of time?
- you can consider this is a `step` for the training, say we run 100 `steps` to train the model
- One `epoch` is then a number of steps?
- one epoch is a complete pass through the entire training dataset
- we say `training for 5 epochs`, it means that the model can see the every training examples 5 times
- it gives a kind of high-level view of training process
- How difficult is it to code a simple DL neural network from scratch (for understanding not as production code) without using any specific packages like tensorflow or keras?
- This approach is often called scientific ML or Sci-ML where you create novel neural networks and architectures from the scratch. For this, some packages in Python are Jax and in Julia: Flux.
- If you want to understand how neural networks are implemented internally, take a look at <https://github.com/joelgrus/joelnet> where the author creates a dummy application by using only Numpy. The downside of using Numpy is it runs only CPUs and is not heavily optimized as the big libraries.
### ==The Training Curve==
- How does the training progress?
- based on loss function, it seems to be that the training is doing good.
- training seems quick
- Rapidly. Why? Is it because we have a small amount of parameters?
- Do you think the resulting trained network will work well on the test set?
- Yes: ++++
- No:
- Can't say:
- When will the recording of this session be available to listen to it again, please
:::warning
**Reflections and quick feedback:**
One thing that you liked or found useful for your projects?
- I liked the speed. As a beginner, I appreciated that you explained even apaprently simple concepts, names. I appreciate your patience.
- It was clear and easy to follow.
- It was good and I think the level/explanations were appropriate for beginners
- As a beginner I'd like to confirm the previous statement :)
One thing that was confusing/suboptimal, or something we should do to improve the learning experience?
- Beeing a bit hesitant when using HPC systems (not being used to it) setting up the jupyter on LUMI has been a bit fast for me. In the end it worked out just fine!
- A bit more explanation of structure of folders and files and which of them could or should be used on the LUMI machine would be helpful.
:::
:::danger
*Always ask questions at the very bottom of this document, right **above** this.*
:::
---
 Sign in with Wallet
Connect another wallet
Sign in with Wallet
Connect another wallet