分布式图数据库 NebulaGraph 的存储底层采用了 RocksDB,正好在美国 SaaS 公司 Datadog 工作的 [Artem Krylysov](https://artem.krylysov.com/) 近期发表了他多年研究 RocksDB 的经验总结。经他授权,本文对他的文章 [《How RocksDB works》](https://artem.krylysov.com/blog/2023/04/19/how-rocksdb-works/) 进行翻译,希望大家了解 RocksDB 的运行原理之余,能更加了解 NebulaGraph 的底层存储逻辑。
> 原文出处:[https://artem.krylysov.com/blog/2023/04/19/how-rocksdb-works/](https://artem.krylysov.com/blog/2023/04/19/how-rocksdb-works/)
## 概述
近几年,RocksDB 的采用率急剧增加,俨然成为可嵌入 key-value(下文简写 kv)存储的标准。
目前,RocksDB 在 Meta、[Microsoft](https://blogs.bing.com/Engineering-Blog/october-2021/RocksDB-in-Microsoft-Bing)、[Netflix](https://netflixtechblog.com/application-data-caching-using-ssds-5bf25df851ef) 和 [Uber](https://www.uber.com/en-JP/blog/cherami-message-queue-system/) 等公司的生产环境中运行。**在 [Meta](https://engineering.fb.com/2021/07/22/data-infrastructure/mysql/),RocksDB 作为 MySQL 部署的存储引擎,为分布式图数据库提供支持存储服务**。其实,大型科技公司不是 RocksDB 的唯一用户,像是 CockroachDB、Yugabyte、PingCAP 和 Rockset 等多个初创企业都建立在 RocksDB 基础之上。
我在 Datadog 工作了 4 年时间,在生产环境中构建和运行了一系列基于 RocksDB 的服务。本文将对 RocksDB 的工作原理进行深度讲解。
## 什么是 RocksDB
RocksDB is an embeddable persistent key-value store. It's a type of database designed to store large amounts of unique keys associated with values. The simple key-value data model can be used to build search indexes, document-oriented databases, SQL databases, caching systems and message brokers.
RocksDB 是一种可嵌入的持久化 kv 存储。它是一种设计用于存储大量与值 value 相关联的唯一键 key 的数据库类型。RocksDB 这个 kv 数据模型可用于构建搜索索引、文档数据库、SQL 数据库、缓存系统和消息代理。
RocksDB was forked off Google's LevelDB in 2012 and optimized to run on servers with SSD drives. Currently, RocksDB is developed and maintained by Meta.
RocksDB is written in C++, so additionally to C and C++, the С bindings allow embedding the library into applications written in other languages such as Rust, Go or Java.
RocksDB 是 2012 年从 Google 的 [LevelDB](https://github.com/google/leveldb) fork 出来的分支,并针对 SSD 运行环境进行了优化。目前,RocksDB 由 Meta 开发和维护。
RocksDB 采用 C++ 编写而成,因此除了支持 C 和 C++ 之外,通过 С binding 还能将 RocksDB 嵌入到其他的编程语言应用程序中,例如 [Rust](https://github.com/rust-rocksdb/rust-rocksdb)、[Go](https://github.com/linxGnu/grocksdb) 或 [Java](https://github.com/facebook/rocksdb/tree/main/java)。
If you ever used SQLite, then you already know what an embeddable database is! In the context of databases, and particularly in the context of RocksDB, "embeddable" means:
* The database doesn't have a standalone process, it's instead linked with your application.
* It doesn't come with a built-in server that can be accessed over the network.
* It is not distributed, meaning it does not provide fault tolerance, replication, or sharding mechanisms.
如果你之前用过 SQLite,那么你应该知道什么是可嵌入式数据库。在数据库领域,特别是 RocksDB 这里,“可嵌入”意味着:
* 该数据库没有独立进程,而是同应用相链接。
* 它没有内置服务器,无法通过网络访问。
* 它不具备分布式功能,这意味着它不提供容错性、复制或分片 sharding 机制。
It is up to the application to implement these features if necessary.
RocksDB stores data as a collection of key-value pairs. Both keys and values are not typed, they are just arbitrary byte arrays. The database provides a low-level interface with a few functions for modifying the state of the collection:
* put(key, value): stores a new key-value pair or updates an existing one
* merge(key, value): combines the new value with the existing value for a given key
* delete(key): removes a key-value pair from the collection
而如果你需要上面的这些特性,就需要依赖于应用程序来实现。
RocksDB 将数据存储为 kv 对集合,并未进行 key 和 value 的类型化,因此 key 和 value 都只是任意字节的数组。RocksDB 提供了一个低级接口用来支持修改集合状态的函数:
* `put(key, value)`:存储新的 kv 对或更新现有键值对
* `merge(key, value)`:将新值与给定键的现有值组合
* `delete(key)`:从集合中删除一对 kv
Values can be retrieved with point lookups:
* get(key)
An iterator enables "range scans" - seeking to a specific key and accessing subsequent key-value pairs in order:
* iterator.seek(key_prefix); iterator.value(); iterator.next()
可以根据点来检索对应值:
* `get(key)`
此时,如果你有个迭代器的话,就能进行范围扫描 range scans——找到特定的 key 并依序访问后续的键值对:
* `iterator.seek(key_prefix); iterator.value(); iterator.next()`
## LSM-Tree
The core data structure behind RocksDB is called the Log-structured merge-tree (LSM-Tree). It's a tree-like structure organized into multiple levels, with data on each level ordered by key. The LSM-tree was primarily designed for write-heavy workloads and was introduced in 1996 in a paper under the same name.
RocksDB 的核心数据结构被称为 _日志结构合并树_ LSM-Tree。它是一种类似树结构的数据结构,由多个层级组成,每个层级上的数据按 key 排序。LSM-Tree 主要设计用于写入密集型工作负载,并于 1996 年在同名论文 [The Log-Structured Merge-Tree (LSM-Tree)](http://paperhub.s3.amazonaws.com/18e91eb4db2114a06ea614f0384f2784.pdf) 被大家所知。
The top level of the LSM-Tree is kept in memory and contains the most recently inserted data. The lower levels are stored on disk and are numbered from 0 to N. Level 0 (L0) stores data moved from memory to disk, Level 1 and below store older data. When a level becomes too large, it's merged with the next level, which is typically an order of magnitude larger than the previous one.
LSM-Tree 的顶层保存在内存中,并包含最近插入的数据。层级低的数据存储在磁盘上,从 0 到 N 编号。第 0 层 L0 存储从内存移动到磁盘上的数据,第 1 层及以下层级存储更老的数据。当某个层级变得太大时,它会与下一个层级合并,通常这是在比前一个层级大一个数量级的情况下进行的。
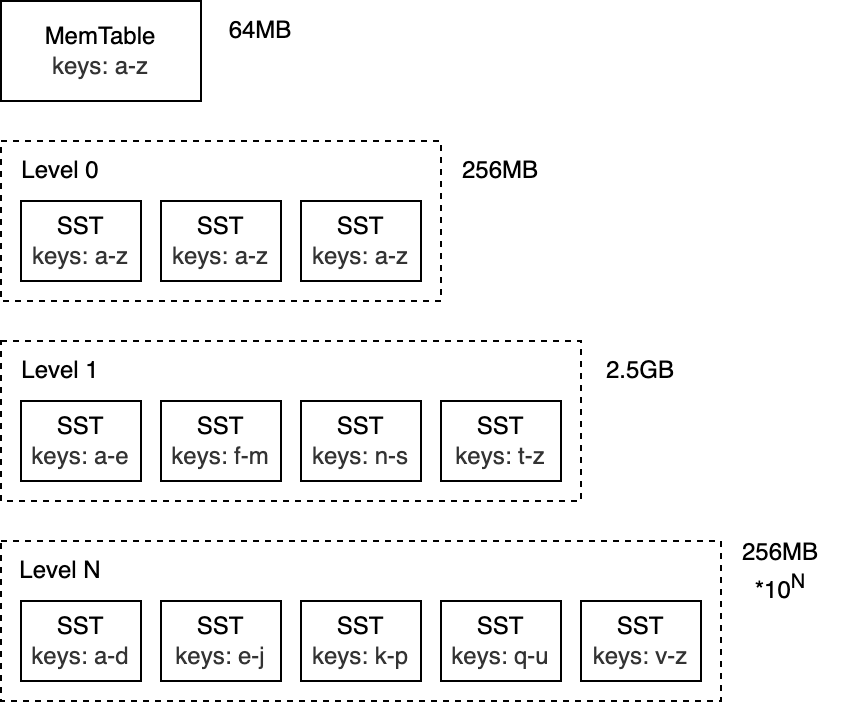
NoteI'll be talking specifically about RocksDB, but most of the concepts covered apply to many databases that uses LSM-trees under the hood (e.g. Bigtable, HBase, Cassandra, ScyllaDB, LevelDB, MongoDB WiredTiger).
To better understand how LSM-trees work, let's take a closer look at the write and read paths.
_题外话:虽然本文专门讨论 RocksDB,但涉及到 LSM-Tree 的概念适用于大多数采用此技术实现底层数据库(例如 Bigtable、HBase、Cassandra、ScyllaDB、LevelDB 和 MongoDB WiredTiger)_。
为了更好地理解 LSM-Tree 是如何工作,下面我们将着重了解下它的写 / 读路径。
## 写路径
### MemTable
The top level of the LSM-tree is known as the MemTable. It's an in-memory buffer that holds keys and values before they are written to disk. All inserts and updates always go through the memtable. This is also true for deletes - rather than modifying key-value pairs in-place, RocksDB marks deleted keys by inserting a tombstone record.
LSM-Tree 的顶层被称作是 MemTable。它是一个内存缓冲区,用来保护写入磁盘之前的键值对。所有插入和更新操作都经过 MemTable。当然 MemTable 也会处理删除操作:在 RocksDB 中,删除操作是通过插入墓碑 tombstone 记录来标记已删除的 key,而非直接原地修改键值对。
The memtable is configured to have a specific size in bytes. When the memtable becomes full, it is swapped with a new memtable, the old memtable becomes immutable.
Note: The default size of the memtable is 64MB.
Let's start by adding a few keys to the database:
MemTable 有特定大小,以字节为单位进行配置。当 MemTable 变满时,它会被新的 MemTable 替换,旧的 MemTable 状态变更为不可变。一般,MemTable 的默认大小为 64 MB。
现在,我们往数据库加点 key 看看:
```c++
db.put("chipmunk", "1")
db.put("cat", "2")
db.put("raccoon", "3")
db.put("dog", "4")
```
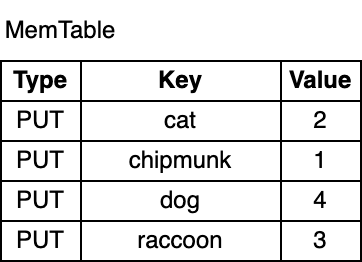
As you can see, the key-value pairs in the memtable are ordered by their key. Although chipmunk was inserted first, it comes after cat in the memtable due to the sorted order. The ordering is a requirement for supporting range scans and it makes some operations, which I will cover later more efficient.
如上所示,MemTable 中的键值对是根据它们的 key 有序排列的。尽管 chipmunk 是最先插入的,但由于 MemTable 是根据 key 排序的(LSM-Tree 章节的配图显示了 key 为字典序),所以 chipmunk 在 cat 之后。为了支持范围扫描,这种排序是必需的,且它让某些操作更高效(稍后我会详细介绍)。
### 预写日志
In the event of a process crash or a planned application restart, data stored in the process memory is lost. To prevent data loss and ensure that database updates are durable, RocksDB writes all updates to the Write-ahead log (WAL) on disk, in addition to the memtable. This way the database can replay the log and restore the original state of the memtable on startup.
在进程崩溃或程序有计划的重启时,存储在进程内存中的数据会丢失。为了防止数据丢失,保证数据库更新能够持久化,在 MemTable 之外,RocksDB 也会将所有更新追加到磁盘上的预写日志(WAL,Write-ahead log)中。这样,在重启后,数据库可以回放日志,进而恢复 MemTable 的原始状态。
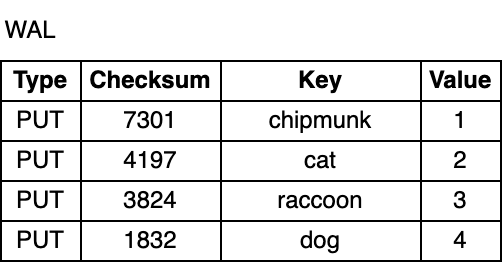
The WAL is an append-only file, consisting of a sequence of records. Each record contains a checksum, a key-value pair, and a record type (Put/Merge/Delete). Unlike in the memtable, records in the WAL are not ordered by key. Instead, they are appended in the order in which they arrive.
WAL 是一个只追加文件,由一系列记录组成。每个记录包含校验和 checksum、键值对和记录类型(Put / Merge / Delete)。与 MemTable 不同,**在 WAL 中,记录不按 key 排序。相反,它们按到达顺序排序**。
## Flush
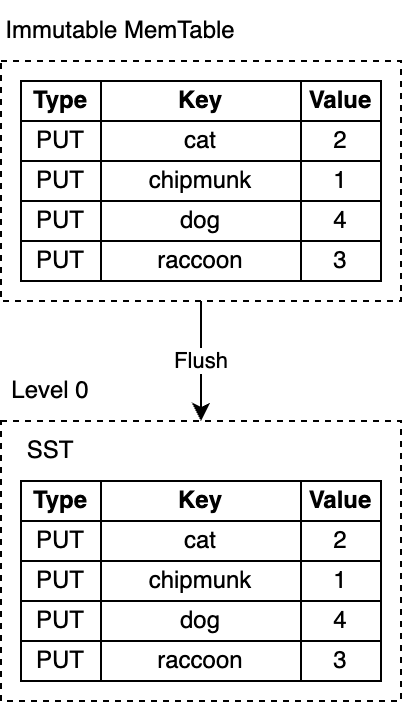
RocksDB runs a dedicated background thread that persists immutable memtables to disk. As soon as the flush is complete, the immutable memtable and the corresponding WAL are discarded. RocksDB starts writing to a new WAL and a new memtable. Each flush produces a single SST file on L0. The produced files are immutable - they are never modified once written to disk.
RocksDB 运行一个专用的后台线程来把不可变的 MemTable 持久化到磁盘。一旦 flush 完成,不可变的 MemTable 和相应的 WAL 就会被丢弃。RocksDB 开始写入新的 WAL、MemTable。每次 flush 都在 L0 层上产生一个单独的 SST 文件。这个文件一旦写入磁盘之后,就不再修改。
The default memtable implementation in RocksDB is based on a skip list. The data structure is a linked list with additional layers of links that allow fast search and insertion in sorted order. The ordering makes the flush efficient, allowing the memtable content to be written to disk sequentially by iterating the key-value pairs. Turning random inserts into sequential writes is one of the key ideas behind the LSM-tree design.
RocksDB 默认用跳跃表 skip list 来实现 MemTable。这种数据结构为链式表,它带有额外链接层次结构,允许按排序快速搜索和插入数据。排序让 flush 更高效,可以通过迭代键值对将 MemTable 内容按序写入磁盘上。而 LSM-Tree 的随机插入变顺序写是它的核心设计之一。
Note:RocksDB is highly configurable. Like many other components, the memtable implementation can be swapped with an alternative. It's not uncommon to see self-balancing binary search trees used to implement memtables in other LSM-based databases.
_题外话:RocksDB 高度可配,同大多数的其他组件一样,你可以用其他方案来代替 MemTable 实现。在其他基于 LSM 实现的数据库中,采用自平衡二叉搜索树来实现 MemTable 并不罕见_。
### SST
SST stands for Static Sorted Table (or Sorted String Table in some other databases). This is a block-based file format that organizes data into fixed-size blocks (4KB by default). Individual blocks can be compressed with various compression algorithms supported by RocksDB, such as Zlib, BZ2, Snappy, LZ4, or ZSTD. Similar to records in the WAL, blocks contain checksums to detect data corruptions. RocksDB verifies these checksums every time it reads from the disk.
SST 表示静态排序表 Static Sorted Table,或是数据库那些已排序的字符串表 Sorted String Table。它是一种块文件格式,把数据变成固定大小的块(默认为 4KB)。RocksDB 支持各种压缩算法压缩单个块文件,例如 Zlib、BZ2、Snappy、LZ4 或 ZSTD 算法。与 WAL 的记录类似,块包含 checksum 来检测数据是否损坏。每次磁盘读取这些 checksum 时,RocksDB 都会进行校验。
Blocks in an SST file are divided into sections. The first section, the data section, contains an ordered sequence of key-value pairs. This ordering allows delta-encoding of keys, meaning that instead of storing full keys, we can store only the difference between adjacent keys.
SST 文件中的块由几个部分组成:第一个部分是数据部分,它含有一组有序的键值对。这个排序允许我们对 key 进行增量编码,这就是说我们可以仅存储相邻 key 之间的差异而不是存储完整 key。
To find a specific key, we could linearly scan the entire file. That would be very inefficient, and we can do better than that. RocksDB optimizes lookups by adding an index, which is stored in a separate section right after the data section. The index maps the last key in each data block to its corresponding offset on disk. Again, the keys in the index are ordered, allowing us to find a key quickly by performing a binary search. For example, if we are searching for lynx, the index tells us the key might be in the block 2 because lynx comes after chipmunk, but before raccoon.
如果我们要查找指定 key,可以线性扫描整个文件。但这样非常低效,我们有更好的方法。RocksDB 在数据部分右侧存储了索引 index,以此来优化查找。Index 会把每个数据块中最后一个 key 映射到它在磁盘上的对应偏移量。同样地,index 中的 key 也是有序的,因此我们可以通过二进制搜索快速找到某个 key。
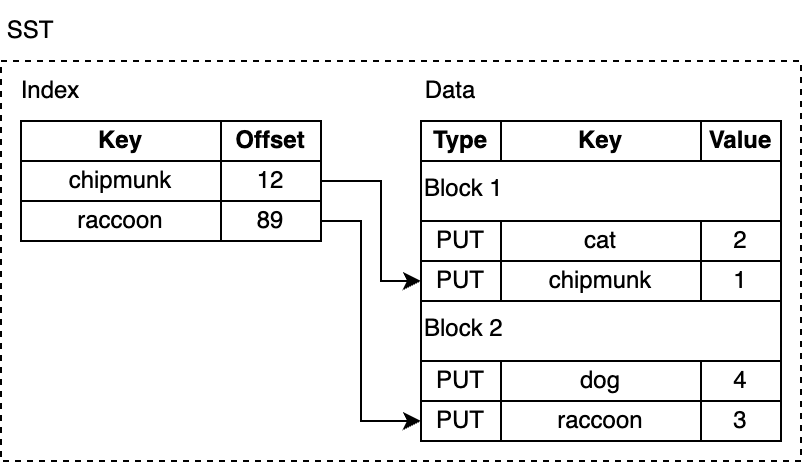
例如,我们在找 lynx,索引告诉我们它可能在块 2,因为 lynx 在 chipmunk 之后但在 raccoon 之前插入。
In reality, there is no lynx in the SST file above, but we had to read the block from disk and search it. RocksDB supports enabling a bloom filter - a space-efficient probabilistic data structure used to test whether an element is in a set. It's stored in an optional bloom filter section and makes searching for keys that don't exist faster.
Additionally, there are several other less interesting sections, like the metadata section.
但,事实上 SST 文件中并没有 lynx,我们不得不读取磁盘的块文件来检索它。RocksDB 支持启用[布隆过滤器](https://en.wikipedia.org/wiki/Bloom_filter),这是一种空间高效的概率结构,用来检测某个元素是否在集合中。而存有 key 的 index 存储在可选的布隆过滤器中,以便更快地找到不存在的 key。
此外,SST 还有其他几个不太有趣的部分,像是元数据部分。
## Compaction
What I described so far is already a functional key-value store. But there are a few challenges that would prevent using it in a production system: space and read amplification. Space amplification measures the ratio of storage space to the size of the logical data stored. Let's say, if a database needs 2MB of disk space to store key-value pairs that take 1MB, the space amplification is 2. Similarly, read amplification measures the number of IO operations to perform a logical read operation. I'll let you figure out what write amplification is as a little exercise.
Now, let's add more keys to the database and remove a few:
好的,一个功能完备的键值存储引擎讲完了。但就这样上生产环境的话,会有些问题:空间和读取放大。空间放大率是用来衡量存储空间与存储的逻辑数据大小比。假设一个数据库需要 2 MB 磁盘空间来存储占用 1 MB 的键值对,那么它的空间放大率是 2。类似地,读取放大率是来衡量执行逻辑读操作所需进行的 IO 操作数量。作为一个小练习,你可以想象下什么是写放大。
现在,让我们向数据库添加更多 key 并删除当中的一些 key:
```c++
db.delete("chipmunk")
db.put("cat", "5")
db.put("raccoon", "6")
db.put("zebra", "7")
// Flush triggers
db.delete("raccoon")
db.put("cat", "8")
db.put("zebra", "9")
db.put("duck", "10")
```
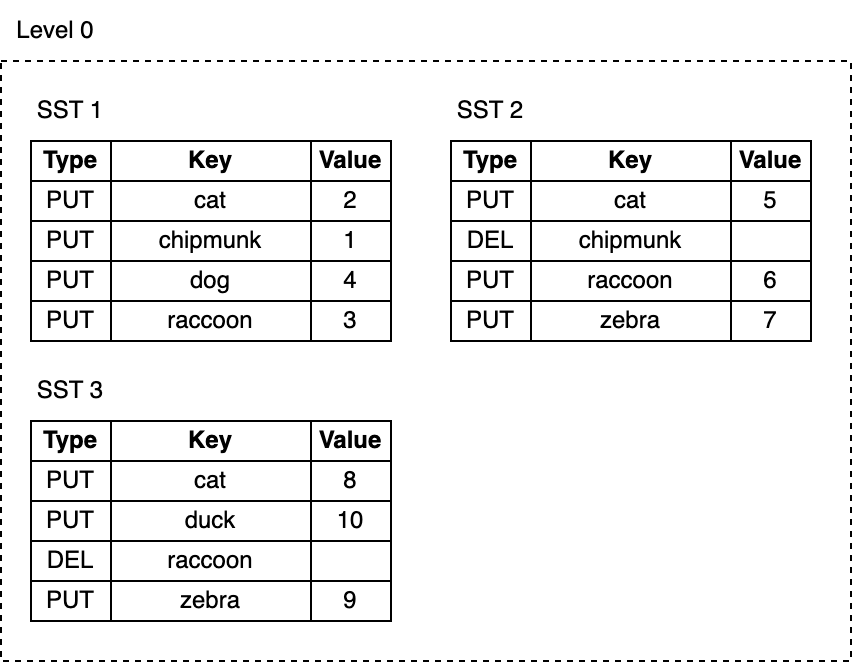
As we keep writing, the memtables get flushed and the number of SST files on L0 keeps growing:
* The space taken by deleted or updated keys is never reclaimed. For example, the cat key has three copies, chipmunk and raccoon still take up space on the disk even though they're no longer needed.
* Reads get slower as their cost grows with the number of SST files on L0. Each key lookup requires inspecting every SST file to find the needed key.
随着我们的不断写入,MemTable 持续刷新,L0 上的 SST 文件数量也在增长:
* 删除或更新 key 所占用的空间永远不会被回收。例如,“cat” 键有三个副本,“chipmunk” 和 “raccoon” 即使不再需要,仍然占用磁盘空间。
* 随着 L0 上 SST 文件数量的增加,读取变得越来越慢。每次找 key 都要检查每个 SST 文件。
A mechanism called compaction helps to reduce space and read amplification in exchange for increased write amplification. Compaction selects SST files on one level and merges them with SST files on a level below, discarding deleted and overwritten keys. Compactions run in the background on a dedicated thread pool, which allows RocksDB to continue processing read and write requests while compactions are taking place.
Compaction 机制可以减少空间和读放大,来换取更高的写放大。Compaction 会将某层的 SST 文件同下一层的 SST 文件合并,在这个过程中丢弃已删除和被覆盖的 key。Compaction 在专用线程池的后台运行,这也就保证了 RocksDB 可以在做 Compaction 时处理读写请求。
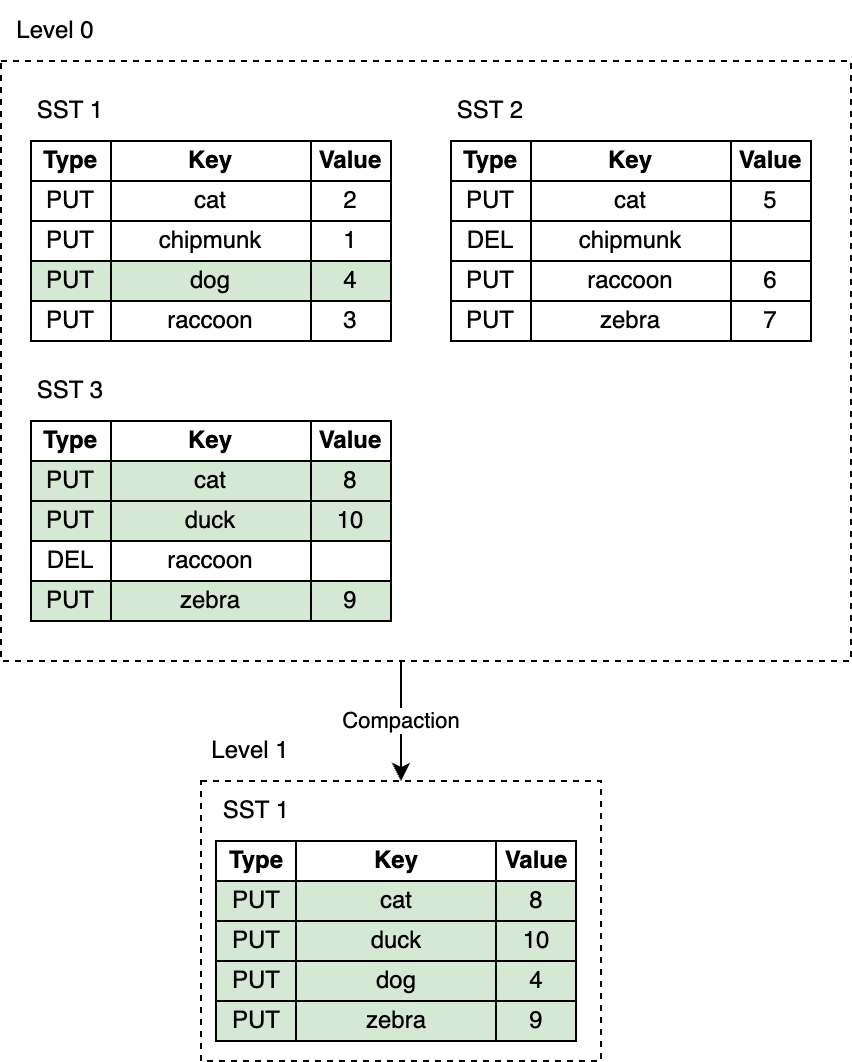
Leveled Compaction is the default compaction strategy in RocksDB. With Leveled Compaction, key ranges of SST files on L0 overlap. Levels 1 and below are organized to contain a single sorted key range partitioned into multiple SST files, ensuring that there is no overlap in key ranges within a level. Compaction picks files on a level and merges them with the overlapping range of files on the level below. For example, during an L0 to L1 compaction, if the input files on L0 span the entire key range, the compaction has to pick all files from L0 and all files from L1.
层级 Compaction 是 RocksDB 中的默认 Compaction 策略。使用层级 Compaction,L0 上的 SST 文件键范围会重叠。L1 层及其以下层级会变成一个键范围排序的分区,包含多个 SST 文件,确保在一个层级内没有键范围重叠。Compaction 会选择性地将某层的 SST 文件同下一层的重叠 SST 文件进行合并。
例如,像下图展示的那样,在 L0 到 L1 层进行 Compaction 时,如果 L0 上的输入文件跨越整个键范围,此时就需要对所有 L0 和 L1 层的文件进行 Compaction。
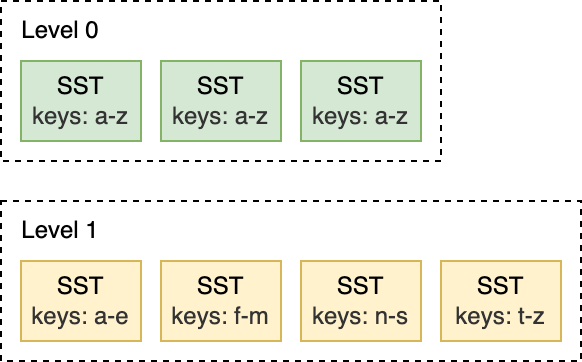
For this L1 to L2 compaction below, the input file on L1 overlaps with two files on L2, so the compaction is limited only to a subset of files.
而像是下面的这种 L1 和 L2 层的 Compaction,L1 上的输入文件与 L2 上的两个 SST 文件重叠,因此,只需要对部分文件进行 Compaction 就行。
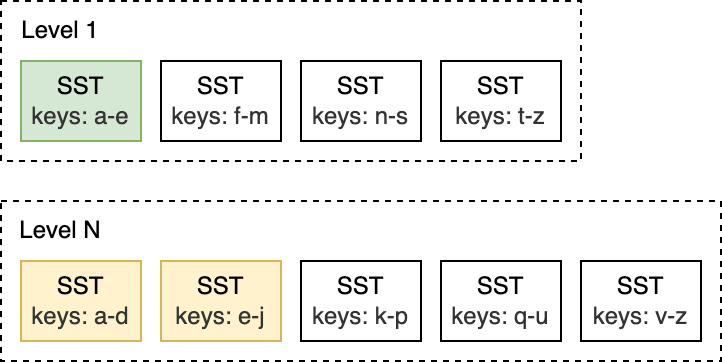
Compaction is triggered when the number of SST files on L0 reaches a certain threshold (4 by default). For L1 and below, compaction is triggered when the size of the entire level exceeds the configured target size. When this happens, it may trigger an L1 to L2 compaction. This way, an L0 to L1 compaction may cascade all the way to the bottommost level. After the compaction ends, RocksDB updates its metadata and removes compacted files from disk.
Note:RocksDB provides other compaction strategies offering different tradeoffs between space, read and write amplification.
Remember that keys in SST files are ordered? The ordering guarantee allows merging multiple SST files incrementally with the help of the k-way merge algorithm. K-way merge is a generalized version of the two-way merge that works similarly to the merge phase of the merge sort.
Compaction 是在 L0 层上的 SST 文件数量达到一定阈值(默认为 4)时触发的。对于 L1 层及以下层级,当整个层级的大小超过配置的目标大小时,Compaction 会被触发。当这种情况发生时,可能会触发L1 到 L2 层的 Compaction。这样,从 L0 到 L1 层的 Compaction 可能会级联到最底层。在 Compaction 完成之后,RocksDB 会更新元数据并从磁盘中删除已压缩文件。
_题外话:RocksDB 提供其他不同权衡空间、读写放大之间的折中 Compaction 策略_。
看到这里,你还记得上文提过 SST 文件中的 key 是有序排列的吗?排序保证允许 K 路归并算法逐步合并多个 SST 文件。K 路归并算法是二路归并排序的归并排序操作的通用版。
## 读路径
With immutable SST files persisted on disk, the read path is less sophisticated than the write path. A key lookup traverses the LSM-tree from the top to the bottom. It starts with the active memtable, descends to L0, and continues to lower levels until it finds the key or runs out of SST files to check.
在磁盘上持久化不可变的 SST 文件后,读路径比写路径可简单多了。要找寻某个 key,直接遍历 LSM—Tree 的顶部到底部。从活动 MemTable 开始,逐步下沉到 L0,并继续向更低层级移动,直到找到该 key 或者检查完所有 SST 文件为止。
Here are the lookup steps:
1. Search the active memtable.
2. Search immutable memtables.
3. Search all SST files on L0 starting from the most recently flushed.
4. For L1 and below, find a single SST file that may contain the key and search the file.
以下是查找步骤:
1. 检索活动 MemTable。
2. 检索不可变 MemTables。
3. 搜索最近 flush 过的 L0 层中的所有 SST 文件。
4. 对于 L1 层及以下层级,找到可能包含该 key 的单个 SST 文件并进行搜索。
Searching an SST file involves:
1. (optional) Probe the bloom filter.
2. Search the index to find the block the key may belong to.
3. Read the block and try to find the key there.
搜索 SST 文件涉及:
1. (可选)探测布隆过滤器。
2. 搜索索引来查找可能属于该 block 文件的 key 所在位置。
3. 读取 block 文件并尝试在其中找到 key。
That's it!
Consider this LSM-tree:
就是如此的简单。看看这个 LSM-Tree:
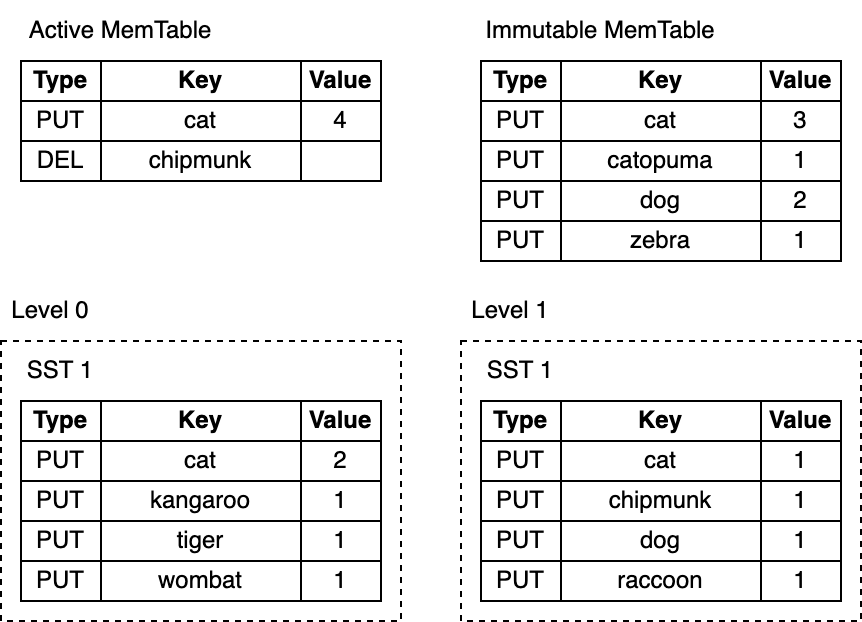
Depending on the key, a lookup may end early at any step. For example, looking up cat or chipmunk ends after searching the active memtable. Searching for raccoon, which exists only on Level 1 or manul, which doesn't exist in the LSM-tree at all requires searching the entire tree.
看 key 情况,查找工作可能在上面任意步骤完成。例如,在搜索活动的 MemTable 后,key “cat” 或 “chipmunk” 的查找工作会立即结束。搜索仅存在于 L1 层的 “raccoon” 或是根本 LSM-tree 上不存在的 “manul” 需要搜索整个树。
## Merge
RocksDB provides another feature that touches both read and write paths: the Merge operation. Imagine you store a list of integers in a database. Occasionally you need to extend the list. To modify the list, you read the existing value from the database, update it in memory and then write back the updated value. This is called "Read-Modify-Write" loop:
RocksDB 提供了另一个涉及读写路径的功能:合并 merge 操作。想象一下,你在数据库中存了一个整数列表,偶尔需要扩展该列表。要修改列表,你需要从数据库中读取现有值,在内存中更新它,再把更新后的值写回数据库。
上面整个操作被称为“读-修改-写”循环:
```c++
db = open_db(path)
// Read
old_val = db.get(key) // RocksDB stores keys and values as byte arrays. We need to deserialize the value to turn it into a list.
old_list = deserialize_list(old_val) // old_list: [1, 2, 3]
// Modify
new_list = old_list.extend([4, 5, 6]) // new_list: [1, 2, 3, 4, 5, 6]
new_val = serialize_list(new_list)
// Write
db.put(key, new_val)
db.get(key) // deserialized value: [1, 2, 3, 4, 5, 6]
```
The approach works, but has some flaws:
* It's not thread-safe - two different threads may try to update the same key overwriting each other's updates.
* Write amplification - the cost of the update increases as the value gets larger. E.g., appending a single integer to a list of 100 requires reading 100 and writing back 101 integers.
上面这种方法一定程度上是可行的,但存在几点缺陷:
* 它不是线程安全的——两个不同的线程可能尝试更新相同的 key,覆盖彼此的更新。
* 写放大——随着值变得越来越大,更新成本也会增加。例如,在 100 个数据列表中追加一个整数需要读取 100 次并将 101 个整数写回。
In addition to the Put and Delete write operations, RocksDB supports a third write operation, Merge, which aims to solve these problems. The Merge operation requires providing a Merge Operator - a user-defined function responsible for combining incremental updates into a single value:
除了 `Put` 和 `Delete` 写操作之外,RocksDB 还支持第三种写操作 `Merge`。`Merge` 操作需要提供 `Merge Operator`——一个用户定义的函数,负责将增量更新组合成单个值:
```c++
func merge_operator(existing_val, updates) {
combined_list = deserialize_list(existing_val)
for op in updates {
combined_list.extend(op)
}
return serialize_list(combined_list)
}
db = open_db(path, {merge_operator: merge_operator})
// key's value is [1, 2, 3]
list_update = serialize_list([4, 5, 6])
db.merge(key, list_update)
db.get(key) // deserialized value: [1, 2, 3, 4, 5, 6]
```
The merge operator above combines incremental updates passed to the Merge calls into a single value. When Merge is called, RocksDB inserts only incremental updates into the memtable and the WAL. Later, during flush and compaction, RocksDB calls the merge operator function to combine the updates into a single large update or a single value whenever it's possible. On a Get call or an iteration, if there are any pending not-compacted updates, the same function is called to return a single combined value to the caller.
上面的 `merge_operator` 将传递给 Merge 调用的增量更新组合成一个单一值。当调用 Merge 时,RocksDB 仅将增量更新插入到 MemTable 和 WAL 中。过段时间,在 flush 和 compaction 期间,RocksDB 调用 `merge_operator()` 函数将更新组合成一个单个大型更新,如果有可能的话会是单个值。在 `Get` 调用或迭代时,如果有任何未 compact 的待处理更新,则会调用相同的函数向 caller 返回一个单独的组合值。
Merge is a good fit for write-heavy streaming applications that constantly need to make small updates to the existing values. So, where is the catch? Reads become more expensive - the work done on reads is not saved. Repetitive queries fetching the same keys have to do the same work over and over again until a flush and compaction are triggered. Like almost everything else in RocksDB, the behavior can be tuned by limiting the number of merge operands in the memtable or by reducing the number of SST files in L0.
Merge 非常适合于写入密集型流应用,这些应用程序需要不断对现有值进行少量更新。那么,问题来了?读将变得更加昂贵——读所做的工作没有保存。重复查询获取相同 key 必须一遍又一遍地执行相同的工作,直到触发 flush 和 compaction 为止。与 RocksDB 其他模块一样,我们可以通过限制 MemTable 中 merge 运算数目或减少 L0 中 SST 文件数量来优化读行为。
## 挑战
If the performance is critical for your application, the most challenging aspect of using RocksDB is configuring it appropriately for a specific workload. RocksDB offers numerous configuration options, and tuning them often requires understanding the database internals and diving deep into the RocksDB source code:
"Unfortunately, configuring RocksDB optimally is not trivial. Even we as RocksDB developers don't fully understand the effect of each configuration change. If you want to fully optimize RocksDB for your workload, we recommend experiments and benchmarking, while keeping an eye on the three amplification factors."
—Official RocksDB Tuning Guide
如果性能对你的应用程序至关重要,那么 RocksDB 面临的最大挑战是为特定工作负载适对它进行合理配置。RocksDB 提供了众多的可配置项,但调整它们通常需要理解数据库内部运行原理并深入研究 RocksDB 源代码:
> “不幸的是,优化 RocksDB 的配置并不容易。即使我们作为 RocksDB 开发人员也不能完全理解每个配置更改的影响。如果你想充分优化 RocksDB 以适应你的工作负载,我们建议进行实验和基准测试,并注意三个放大因素。”
> -- 官方 RocksDB 调整指南
## 总结
Writing a production-grade key-value store from scratch is hard:
* Hardware and OS can betray you at any moment dropping or corrupting data.
* Performance optimizations require a large time investment.
RocksDB solves this allowing you to focus on the business logic instead. This makes RocksDB an excellent building block for databases.
从零开始写一个生产级别的 kv 存储是很困难的:
* 硬件和操作系统可能在任何时候丢失或损坏数据。
* 性能优化需要大量时间投入。
RocksDB 解决了上面两个问题,你可以专注于业务逻辑。这也使得 RocksDB 成为优秀的数据库构建模块。







