# 2019q3 Homework5 (quiz7)
contributed by < `kksweet8845` >, < `Davinais` >, < `Benny1117Yen` >
## quiz 1
:::warning
TODO: 補上原始題目的連結和分析
:::
### The principle of bitwise.c
```cpp
#define MSG_LEN 8
static inline bool is_divisible(uint32_t n, uint64_t M) {
return n * M <= M - 1;
}
static uint64_t M3 = UINT64_C(0xFFFFFFFFFFFFFFFF) / 3 + 1;
static uint64_t M5 = UINT64_C(0xFFFFFFFFFFFFFFFF) / 5 + 1;
int main(int argc, char **argv) {
for (size_t i = 1; i <= 100; i++) {
uint8_t div3 = is_divisible(i, M3);
uint8_t div5 = is_divisible(i, M5);
unsigned int length = (2 << div3) << div5;
char fmt[MSG_LEN + 1];
strncpy(fmt, &"FizzBuzz%u"[(MSG_LEN >> KK1) >> (KK2 << KK3)], length);
fmt[length] = '\0';
printf(fmt, i);
printf("\n");
}
return 0;
}
```
The main concept in here is that not using any branches on it.
Because of the `Fizz Buzz`, which are length of four, if the number is divisible by 3, output Fizz. If the number is divisible by 5, output Buzz. If both, output FizzBuzz.
Means that we can simple output the front four, front eight or middle four length of byte of string of `"FizzBuzz"`. That is,
```cpp
unsigned int length = (2 << div3) << div5
```
However, we need to care about the start place when we need to output from the beginning of string or the middle of the string. That is,
```cpp
&"FizzBuzz%u"[(MSG_LEN >> div5) >> (div3 << 2)]
```
- Only can be divided by 3
- div3 <= 1
- div5 <= 0
- the length <= 4
- then, the start address of pointer is 0
- finally, we get `"Fizz"`
- Only can be diviede by 5
- div3 <= 0
- div5 <= 1
- the length <= 4
- then, the start address of pointer is 4,
- finally, we get `"Buzz"`
- Both can be divided by 3 and 5
- div3 <= 1
- div5 <= 1
- the length <= 8
- then, the start address of pointer is 0,
- finally, we get `"FizzBuzz"`
### Analysis of performance (Ext 1)
At first, I thought the branchless version of FizzBuzz is better than the naive one.
```shell
perf stat --repeat 100 \
-e cache-misses,cache-references,instructions,cycles \
./naive
Performance counter stats for './naive' (100 runs):
46,679 cache-misses # 43.589 % of all cache refs ( +- 0.91% )
107,088 cache-references ( +- 0.84% )
429,029,517 instructions # 3.02 insn per cycle ( +- 0.00% )
142,295,173 cycles ( +- 0.74% )
0.042437 +- 0.000351 seconds time elapsed ( +- 0.83% )
perf stat --repeat 100 \
-e cache-misses,cache-references,instructions,cycles \
./bitwise
Performance counter stats for './bitwise' (100 runs):
31,267 cache-misses # 36.621 % of all cache refs ( +- 1.62% )
85,380 cache-references ( +- 2.35% )
621,245,521 instructions # 2.88 insn per cycle ( +- 0.05% )
215,632,285 cycles ( +- 0.52% )
0.063427 +- 0.000412 seconds time elapsed ( +- 0.65% )
```
However,After I use the perf-stat, the result is not what I thought.
### (Ext 2)
### (Ext 3)
在程式中,所有的變數以及函數都在記憶體中佔有空間,也因此都擁有記憶體位址;並且由於在 C 語言中有指標的存在,因此我們得以在虛擬記憶體空間中存取特定的位址。但是,這也造成了有心人士得以利用的漏洞,如透過 buffer overflow 的手段穿越到非法空間,更改掉函數的 return address 等方式執行惡意植入的程式。如果程式能夠接受使用者輸入更是要小心萬分,否則如果有心人士植入了直譯器並且透過使用者輸入輸入程式碼,我們的程式變會淪為惡意程式碼的溫床。
可能有人會覺得單純只是輸入輸出能夠有什麼攻擊,HexHive 團隊便為我們展示了 [printbf](https://github.com/HexHive/printbf),以 `printf()` 系列來進行直譯 [Brainfuck](https://en.wikipedia.org/wiki/Brainfuck) 程式碼。為何 `printf()` 得以直譯 [Turing Complete](https://en.wikipedia.org/wiki/Turing_completeness) 的程式語言?這都歸功於 `printf()` 能進行以下操作:
- 記憶體讀取: `printf()` 既然可以格式化變數輸出,必然可以讀取記憶體,而其中 `%s` 更可以讀取一整個字串,若使用不當可是相當有風險。
- 記憶體寫入: `%n` 可以將目前成功輸出的字元數寫入到對應的變數中,因此只要能夠控制輸出內容大小,我們便能利用 `%n` 來寫入特定的數字。
- 條件控制: 可以利用 `*` ,使用對應變數來控制輸出的寬度或精確度,如 `printf("%.*d", a, 10)` ,我們就能利用 `a` 來控制輸出的精確度,即是能控制輸出內容大小。
- 指定變數操作: `n$` 可以讓 `printf()` 使用第 n 個參數作為對應的變數,如 `printf("%1$.*2$d", 10, a)` ,我們就能指定第 1 個參數 `10` 為欲輸出的整數,而第 2 個參數 `a` 為精確度,也能夠用來重複使用參數。
可見 `printf()` 功能其實相當強大,只要加以配合便能夠組合出 [Turing Machine](https://en.wikipedia.org/wiki/Turing_machine) 了。
要做出 Brainfuck 的直譯器,首先我們先將所有 8 個指令全部列出:
| Char | Behavior |
| ---- | -------- |
| `>` | 指標加一 |
| `<` | 指標減一 |
| `+` | 指標指向的位元組的值加一 |
| `-` | 指標指向的位元組的值減一 |
| `.` | 輸出指標指向的單元內容(ASCII碼) |
| `,` | 輸入內容到指標指向的單元(ASCII碼) |
| `[` | 如果指標指向的單元值為零,向後跳轉到對應的`]`指令的次一指令處 |
| `]` | 如果指標指向的單元值不為零,向前跳轉到對應的`[`指令的次一指令處 |
`printf()` 無法直接做加減,那麼我們要怎麼改變指標指向的位址或者是指標指向的內容呢?
方才提到 `%n` 可以用來寫入輸出字元數到對應的變數中,如:
```c
int a = 0xffffffff;
printf("12345678%n", &a);
```
以 gdb 監看,最後會得到 `a = 8`,而如果再利用 `*` 以及 `n$` 來指定輸出的長度,如:
```c
int a = 2;
printf("12345678%1$.*1$d%2$n", a, &a);
```
用 `"%1$.*1$d"` 配合參數 `a` 讓他固定輸出 `a` 個字元(前提是 `a` 直接印出來不會超過 `a` 個字元,這裡不會有這個問題),再加上原本的 `8` 個字元,最後再利用 `"%2$n"` 將總輸出字元數放入 `a` 中,便等同於執行了 `a = a + 8` ,最後 `a = 10`。
::: success
減法與加法類似,藉由 overflow 實現補數的概念來執行,比如說在要減去 `char` 的值時,我們直接在直譯時將欲減去之值轉換成 `CHAR_MAX + 1 - (欲減去之值)` ,即可透過類似二補數的方式執行減法。
:::
雖然以上述的方式就能夠執行加減法,對於指標指向的內容還可以以上述方式簡單實現,但是指標指向的位址在 64 位元電腦而言就是一個 64 位元的數字,光是以 `printf()` 印出來就要花上許久,而如果以 `sprintf()` 的話,更是要先要求一塊 $2^{64}$ 的 `buf` 存放輸出才行,實在是太過不切實際,因此不會用上述的方式實現。
其實,[格式化字串](https://zh.wikipedia.org/zh-tw/%E6%A0%BC%E5%BC%8F%E5%8C%96%E5%AD%97%E7%AC%A6%E4%B8%B2) 有一個 length 欄位可以指定預期參數的長度,將他與 `%n` 結合使用看看:
```c
int a = 0xffffffff;
printf("12345678%hn", &a);
printf("\na = %#x\n", a);
```
`h` 表示 `printf()` 期待所對應的參數是 `short` 尺寸,而同時我們也發現最後印出的 `a = 0xffff0008`(64 位元環境下)。
那麼如果我們能讓我們記憶體的 base 部分為 0 ,我們就能使用這個技巧來控制指標指向的內容了:
```c=
#include <stdio.h>
#include <stdlib.h>
char buf[250000]; // buf for not spill to stdout
int main() {
/* Preprocess for array base */
char *array_ = calloc(1, 1 << 17);
char *array = (void*)((char*)array_ + 0x10000-(((long)array_)&0xFFFF));
/* Insert data */
int shift1 = 16, shift2 = 304;
array[shift1] = 'R';
array[shift2] = 'H';
/* Use printf to fetch */
sprintf(buf, "%1$.*1$d%2$hn", shift1, &array);
printf("array[shift1] = %c\n", *array);
sprintf(buf, "%1$.*1$d%2$hn", shift2, &array);
printf("array[shift2] = %c\n", *array);
return 0;
}
```
我們申請一塊足夠大的空間,讓我們能夠將後面 16 位的位址進位清為 0 作為 base,再來運用上述的技巧來控制指標的位址,最後發現輸出:
```
array[shift1] = R
array[shift2] = H
```
觀察 gdb ,當 `array_` 以 `0x7ffff7c4010` 為 base 時,藉由上述的進位技巧將 `array` 的 base 變為 `0x7ffff7d0000`,也能發現後續操作中 `array` 也成功對應到 `0x7ffff7d0010` 以及 `0x7ffff7d0130`。
結合上述的加減法,我們也能完全藉由 `printf()` 來執行資料以及指標的變動:
```cpp
#include <stdio.h>
#include <stdlib.h>
char buf[250000]; // buf for not spill to stdout
int main() {
/* Preprocess for array base */
char *array_ = calloc(1, 1 << 17);
char *array = (void*)((char*)array_ + 0x10000-(((long)array_)&0xFFFF));
/* Use printf to insert data */
int shift1 = 16, shift2 = 304;
sprintf(buf, "%1$.*1$d%2$hn", shift1, &array);
sprintf(buf, "%1$.*1$d%2$hhn", 'R', array);
sprintf(buf, "%1$.*1$d%2$hn", shift2, &array);
sprintf(buf, "%1$.*1$d%2$hhn", 'H', array);
/* Use printf to fetch */
sprintf(buf, "%1$.*1$d%2$hn", shift1, &array);
printf("array[shift1] = %c\n", *array);
sprintf(buf, "%1$.*1$d%2$hn", shift2, &array);
printf("array[shift2] = %c\n", *array);
return 0;
}
```
最後可以成功輸出
```
array[shift1] = R
array[shift2] = H
```
#### 流程跳轉
`[` 與 `]` 需要在檢查指標後確定是否跳轉,要同時比較以及動到 pc ,看起來不是一個指令能解決的。
首先我們發現到 `[` 與 `]` 是相對的,一個是在為零時跳轉,另一個是在非零時跳轉,因此我們只要強迫某一邊強制跳轉,另一邊做檢查就可以了。
在 printbf 中,便讓 `]` 強制跳轉回前面:
```c
strcpy(bf_GOTO_fmt, "%10$.*10$d%11$hn");
```
以上是 printbf 中 `]` 對應的指令字串,依照前一部分的說明以及對照下面實際使用的參數
```c=189
/* execute instruction */
sprintf(buf, *real_syms,
/* slight cheating for bitwise and */
((long)array)&0xFFFF, &array, /* 1, 2 */
*array, array, /* 3, 4 */
output, /* 5 */
/* slight cheating for bitwise and */
((long)output)&0xFFFF, &output, /* 6, 7 */
&cond, &bf_CGOTO_fmt3[0], /* 8, 9 */
rpc[1], &rpc, /* 10, 11 */
0, /* 12 */
*input, /* 13 */
/* slight cheating for bitwise and */
((long)input)&0xFFFF, &input /* 14, 15 */
);
```
也就是我們將 `rpc[1]` 放入 `rpc` 中,而 `rpc[1]` 在此放置的是跳轉位址,因此可以實現強制跳轉。
`]` 因為要比較條件,因此分為三個指令:
```c
strcpy(bf_CGOTO_fmt1, "%8$n%4$s%8$hhn");
strcpy(bf_CGOTO_fmt2, "%8$s%12$255d%9$hhn");
strcpy(bf_CGOTO_fmt3, " %10$.*10$d%11$hn");
```
#### 第一個指令
我們先來看看第一個指令 `"%8$n%4$s%8$hhn"`,對照上方實際使用的參數,`8$` 為 `cond`,而 `4$` 為 `array` ,因此這個指令的意思是首先先將 `cond` 清為 0 之後,以 `%s` 直接印出 `array` ,最後將印出字元數以 `char` 寬度放回 `cond` 中。
由於 `%s` 會一直印出到 `\000` 字串結尾為止,該值剛好就是 `0` ,**因此只要指標指向的資料恰好為 `0` 就不會印出任何字元**,因此最後寫入 `0` 到 `cond` 中,否則寫入非 `0` 。
#### 第二個指令
第二個指令是 `"%8$s%12$255d%9$hhn"` ,我們將 `&cond` 以 `%s` 方式印出,接著印出 `%12$255d`,也就是讓印出字元數增加 255,最後將印出字元數以 `char` 寬度寫入參數 `&bf_CGOTO_fmt3[0]` 中。
由於 `cond` 本身是 `int` ,而 `%s` 會讓 `&cond` 以 `char*` 解讀,因此我們會讓 `cond` 以字串方式被印出; `int` 在 64 位元機器上為 4 個 `char` ,而 `cond` 我們在先前的操作中,已經能確保高位部分必定為 `0`,因此**如果機器是 Little Endian,就純粹是比較 `cond` 最低的 8 位中的值是否為 `0` ,若非零則會印出一個字元,否則不印出字元。**
```c
(char*)+3 (char*)+2 (char*)+1 (char*)
(int*)&cond = [00000000] [00000000] [00000000] [xxxxxxxx]
```
:::success
因此 Big Endian 的機器,要稍微做一些修改才能執行。
比如說直接將 `int cond` 改成 `char cond[2]` ,就能避開這個問題。
:::
由於接下來我們讓印出字元數直接增加了 `255` ,因此最後總印出字元數只有可能是 `255` (`cond` 為 `0`) 或 256 (`cond` 非 `0`)。以 `char` 寬度輸出的話, `256` 就會因為 overflow 而變成 `0`。因此我們可以發現:
- 若 `cond` 為 `0` ,最後輸出非 `0`
- 若 `cond` 為非 `0` ,最後輸出 `0`
實際上就像是一個 not 的行為,我們最後將他寫入 `bf_CGOTO_fmt3[0]` ,可以注意到這其實就是接下來第三個指令的第一個欄位。
#### 第三個指令
第三個指令是 `" %10$.*10$d%11$hn"` ,極度單純,除了前面多了四個空白之外,後續都跟強制跳轉的部份一樣,除了這讓印出字元數 +4 之外,由於我們第二個指令將值寫入了這個指令的第一個欄位,這便是條件判斷的關鍵所在。
比較一下狀況,如果 `cond` 為 `0` 時,`bf_CGOTO_fmt3[0]` 為 非`0` (`255`):
```
000 001 002 003 .....
[255][ ][ ][ ]%10$.*10$d%11$hn[\00]
```
字串沒什麼太大的改變,一樣會執行強制跳轉 `rpc[1] + 4`。
但如果 `cond` 為 非 `0` 時,`bf_CGOTO_fmt3[0]` 為 `0`:
```
000 001 002 003 .....
[\00][ ][ ][ ]%10$.*10$d%11$hn[\00]
```
字串提早在第一個欄位就結束,因此後面都不會印出,進而不會跳轉。
#### 其他的 return address 攻擊
先前在 PTT 的 C 語言版中有一篇關於不用迴圈印出九九乘法表的文章,以下是[其中一篇](https://www.ptt.cc/bbs/C_and_CPP/M.1531855007.A.FCC.html)的回答:
```c=
#include <stdio.h>
long long salon(long long hair, int i){
if( i < 1 ) hair = 2[&hair];
if( i < 81 ) 2[&hair] = hair;
return hair;
}
int main(){
int i = -1;
long long hair = salon(hair, ++i);
printf("%d x %d = %2d %c", i/9+1, i%9+1, (i/9+1) * (i%9+1), 32-22*!(i%9-8));
hair = salon(hair, ++i);
return 0;
}
```
在 x86_64 機器上執行,輸出結果:
```shell
$ gcc -O0 -o 99 99.c
$ ./99
1 x 1 = 1 1 x 2 = 2 1 x 3 = 3 1 x 4 = 4 1 x 5 = 5 1 x 6 = 6 1 x 7 = 7 1 x 8 = 8 1 x 9 = 9
2 x 1 = 2 2 x 2 = 4 2 x 3 = 6 2 x 4 = 8 2 x 5 = 10 2 x 6 = 12 2 x 7 = 14 2 x 8 = 16 2 x 9 = 18
3 x 1 = 3 3 x 2 = 6 3 x 3 = 9 3 x 4 = 12 3 x 5 = 15 3 x 6 = 18 3 x 7 = 21 3 x 8 = 24 3 x 9 = 27
4 x 1 = 4 4 x 2 = 8 4 x 3 = 12 4 x 4 = 16 4 x 5 = 20 4 x 6 = 24 4 x 7 = 28 4 x 8 = 32 4 x 9 = 36
5 x 1 = 5 5 x 2 = 10 5 x 3 = 15 5 x 4 = 20 5 x 5 = 25 5 x 6 = 30 5 x 7 = 35 5 x 8 = 40 5 x 9 = 45
6 x 1 = 6 6 x 2 = 12 6 x 3 = 18 6 x 4 = 24 6 x 5 = 30 6 x 6 = 36 6 x 7 = 42 6 x 8 = 48 6 x 9 = 54
7 x 1 = 7 7 x 2 = 14 7 x 3 = 21 7 x 4 = 28 7 x 5 = 35 7 x 6 = 42 7 x 7 = 49 7 x 8 = 56 7 x 9 = 63
8 x 1 = 8 8 x 2 = 16 8 x 3 = 24 8 x 4 = 32 8 x 5 = 40 8 x 6 = 48 8 x 7 = 56 8 x 8 = 64 8 x 9 = 72
9 x 1 = 9 9 x 2 = 18 9 x 3 = 27 9 x 4 = 36 9 x 5 = 45 9 x 6 = 54 9 x 7 = 63 9 x 8 = 72 9 x 9 = 81
```
明明沒有迴圈卻能夠執行像是迴圈的結果,這是如何做到的呢?其實這也是透過修改 return address 的方式來執行的。
我們其以 `gcc -O0 -S` 分析:
```s
salon(long long, int):
pushq %rbp
movq %rsp, %rbp
movq %rdi, -8(%rbp)
movl %esi, -12(%rbp)
cmpl $0, -12(%rbp)
jg .L2
movq 8(%rbp), %rax
movq %rax, -8(%rbp)
.L2:
cmpl $80, -12(%rbp)
jg .L3
leaq -8(%rbp), %rax
addq $16, %rax
movq -8(%rbp), %rdx
movq %rdx, (%rax)
.L3:
movq -8(%rbp), %rax
popq %rbp
ret
```
對照
```c
long long salon(long long hair, int i){
if( i < 1 ) hair = 2[&hair];
if( i < 81 ) 2[&hair] = hair;
return hair;
}
```
可以發現參數傳遞中的 `long long hair` 就是 `%rdi`,而因為 `hair` 也成為了 local variable,因此我們最後壓入了 `-8(%rbp)` 中。
而接下來的這個部分:
```
cmpl $0, -12(%rbp)
jg .L2
```
應該就是對應到 `if( i < 1 )` 的部分,因此接下來的
```
movq 8(%rbp), %rax
movq %rax, -8(%rbp)
```
應該就是 `hair = 2[&hair]` 的部分了,那麼 `8(%rbp)` 又是什麼值呢?
#### Calling Stack Frame
由[此篇文章](https://eli.thegreenplace.net/2011/09/06/stack-frame-layout-on-x86-64),我們可以得知 x86-64 的 stack frame:
以以下程式碼為例:
```c
long utilfunc(long a, long b, long c) {
long xx = a + 2;
long yy = b + 3;
long zz = c + 4;
long sum = xx + yy + zz;
return xx * yy * zz + sum;
}
```
在沒有任何最佳化選項開啟的情況下,最後在 x86-64 的 stack frame 中,會如下擺放:
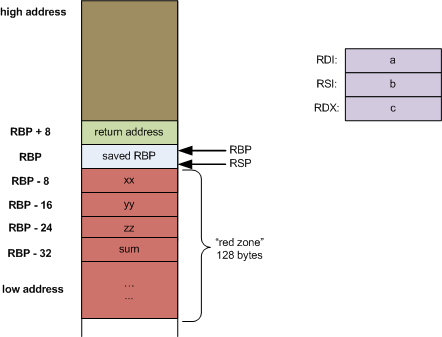
參照 [64-bit_data_models](https://en.wikipedia.org/wiki/64-bit_computing#64-bit_data_models) ,我們可以發現在 Unix-like x86-64 中,`long long` 與 `long` 的大小都是一樣的,因此可以直接對照。
`xx` 對應到 `hair` 對應到 `-8(%rbp)`,**那麼 `8(%rbp)` 就是對應到 return address 了。**
因此這個動作我們就是將目前的 return address 存起來。
對應到 `main` :
```c=
int main(){
int i = -1;
long long hair = salon(hair, ++i);
printf("%d x %d = %2d %c", i/9+1, i%9+1, (i/9+1) * (i%9+1), 32-22*!(i%9-8));
hair = salon(hair, ++i);
return 0;
}
```
第一次呼叫 `salon()` 時 `i = 0` ,因此我們將 return address,也就是下一行程式 `printf()` 的位址存回 hair;
而第二次呼叫之後,我們將 `2[&hair] = hair`,對應到組語:
```
leaq -8(%rbp), %rax
addq $16, %rax
movq -8(%rbp), %rdx
movq %rdx, (%rax)
```
我們在 `%rax` 中存放地址 `-8(%rbp) + $16`,其實也就是 `8(%rbp)` ,最後再將 `-8(%rbp)` 放入 `8(%rbp)` 中,因此**就是將目前的 return address 以我們自己儲存的 return address 覆蓋掉**。因此,才能夠達成上述類似迴圈的效果。
不過在 `gcc -O1` 之後 `salon()` 直接被最佳化成以下:
```
salon(long long, int):
movq %rdi, -8(%rsp)
testl %esi, %esi
jle .L3
.L2:
movq -8(%rsp), %rax
ret
.L3:
movq 8(%rsp), %rax
movq %rax, -8(%rsp)
jmp .L2
```
便無法以更改 return address 的方式執行了。
### quiz 2
[CS:APP 第 3 版](https://hackmd.io/@sysprog/S1vGugaDQ) 一書的第 2 章家庭作業 `2.97` (Page 97) 題目:
> 依據浮點數位元編碼規則,實作出符合以下原型定義和作用的函式: (`float-i2f.c`)
```cpp
/* compute (float) i */
float_bits float_i2f(int i);
```
> 給定整數 `i`, 此函式計算 (float) i 逐位元的表示法。
> 其中
```cpp
typedef unsigned float_bits;
```
> 並假設 `int` 長度為 32-bit 且在 little endian 機器上執行。
可用的工具函式:
```cpp
/* Assuming i > 0, calculate an integer's bit length */
/* * e.g. 0x3 => 2, 0xFF => 8 */
static inline int bits_length(int i) { return 32 - __builtin_clz(i); }
/* generating bitmask. e.g. 3 => 0x00000007, 16 => 0x0000FFFF */
static inline unsigned bits_mask(int l) { return (unsigned) -1 >> (32 - l); }
```
==本題採問答形式進行==
```cpp=
#include <stdio.h>
#include <limits.h>
typedef unsigned float_bits;
float_bits float_i2f(int i);
static inline int bits_length(int i) { return 32 - __builtin_clz(i); }
static inline unsigned bits_mask(int l) { return (unsigned) -1 >> (32 - l); }
// Compute (float) i
float_bits float_i2f(int i) {
unsigned sig, exp, frac, rest;
// exp w/ sig
unsigned exp_sig, round_part;
unsigned bits, fbits;
// 01111111 = 127
unsigned bias = 0x7F;
if (i == 0) {
sig = 0;
exp = 0;
frac = 0;
return sig << 31 | exp << 23 | frac;
}
if (i == INT_MIN) {
sig = 1;
exp = bias + 31;
frac = 0;
return sig << 31 | exp << 23 | frac;
}
sig = 0;
/* 2's complatation */
if (i < 0) {
sig = 1;
i = -i;
}
// ex: ex. 14; 25; 26
bits = bits_length(i);
// 13; 24; 25
fbits = bits - 1;
// 127 + 13; 127 + 24; 127 + 25
exp = bias + fbits;
/* 11101101101101 & (u)-1 >> 19 = 00000000000000000001101101101101; 25 bits & (u)-1 >> 8 剩下 24 bits; 26 bits & -1 >> 7 剩下25 bits */
rest = i & bits_mask(fbits);
if (fbits <= 23) {
frac = rest << (23 - fbits);
exp_sig = exp << 23 | frac;
} else {
// if fbits > 23
int offset = fbits - 23;
/* ex. 0000 ~ 1111, mid = 1000 */
int round_mid = 1 << (offset - 1);
// 等於拿多出來的一段 & 整段, 得到多出來的 part
round_part = rest & bits_mask(offset);
// 因為多於 23
frac = rest >> offset;
exp_sig = exp << 23 | frac;
/* round to even */
if (round_part < round_mid) { // 代表不會進位
/* nothing */
} else if (round_part > round_mid) { // 進位 +1
exp_sig += 1;
} else { /* 當兩個相同時, 拿 frac 來 & 1, 等於 1 就是看 frac 最小位為 1 時就把 sig + 1 */
/* round_part == round_mid */
if ((frac & 0x1) == 1) {
/* round to even */
exp_sig += 1;
}
}
}
return sig << 31 | exp_sig;
}
#define T1 (192786519)
#define T2 (192786520)
#define T3 (258744328)
#define T4 (258744329)
int tests[] = { T1, T2, T3, T4 };
int main (int argc, char* argv[]) {
union {
int i;
float f;
} i2f;
for(int i = 0; i < sizeof(tests)/sizeof(int); i++) {
i2f.i = tests[i];
printf("[%d] 0x%.8X\t%d\n", i, i2f.i, i2f.i);
i2f.i = float_i2f(i2f.i);
float t = tests[i];
printf("[%d] 0x%.8X\t%.50f\n", i, i2f.i, i2f.f);
printf("[%d] Direct cast:%.50f\n", i, t);
puts("========");
}
}
```
#### Results
```
[0] 0x0B7DB057 192786519
[0] 0x4D37DB05 192786512.00000000000000000000000000000000000000000000000000
[0] Direct cast:192786512.00000000000000000000000000000000000000000000000000
========
[1] 0x0B7DB058 192786520
[1] 0x4D37DB06 192786528.00000000000000000000000000000000000000000000000000
[1] Direct cast:192786528.00000000000000000000000000000000000000000000000000
========
[2] 0x0F6C2008 258744328
[2] 0x4D76C200 258744320.00000000000000000000000000000000000000000000000000
[2] Direct cast:258744320.00000000000000000000000000000000000000000000000000
========
[3] 0x0F6C2009 258744329
[3] 0x4D76C201 258744336.00000000000000000000000000000000000000000000000000
[3] Direct cast:258744336.00000000000000000000000000000000000000000000000000
========
```
### quiz 3
According to the `union ele`, we can define the following grapch to describe the `union ele`
```shell
union ele
------------
+ + # Eight bytes offset
+ Part 1 +
+ +
------------
+ + # Eight bytes offset
+ Part 2 +
+ +
------------
```
Because the size of pointer need 8 bytes in 64-bit systems and long will also take 8 bytes.
```cpp
void proc(union ele *ptr) {
ptr->AAA.x = *(ptr->BBB.CCC->DDD.p) - (ptr->EEE.FFF->GGG.HHH);
}
```
Let take a look to the assembly code
```shell
proc:
movq 8(%rdi), %rdx
movq (%rdx), %rax
movq (%rax), %rax
subq 8(%rdx), %rax
movq %rax, (%rdi)
ret
```
- `%rdi` : 1st argument
- `%rdx` : In here, it just uses it as a temporary register.
- `%rax` : return value
It directly add the 8 byte offset to the address of 1st argument, ptr, to the `%rdx`, then we can simpley infer that it is accessing the address at the `Part 2` of the `union ele`.
In here, the corresponding c code is as following
```cpp
ptr->BBB.CCC
```
However, we don't know which struct the BBB is ?
After I see there is a pointer to struct statement, `CCC->DDD`, there is only `struct e2` has the pointer to `union ele`. I can absolutely say that
- `CCC` is `next`
- `BBB` is `e2`
- `DDD` is `e1` because of `DDD.p`.
And, how the code access `ptr->e2.next` ? The answer shown as following. It typically move the address to which `ptr->e2.next` points to another register, `%rax`.
```shell
proc:
movq 8(%rdi), %rdx
movq (%rdx), %rax # ptr->e2.next
movq (%rax), %rax
subq 8(%rdx), %rax
movq %rax, (%rdi)
ret
```
In the next line, `movq (%rax), %rax`, it typically move the value, `Mem[%rdx]` to itself and the offset is zero, that coincides to the following statement, `ptr->e2.next->e1.p`.
```shell
ptr another
------------- ------------- offset 0
+ e2 + + e1 +
+ long x + + long *p +
+ + + +
------------- ------------- offset 8
+ e2 + + e1 +
+ union ele +----- + long y +
+ next + | + +
------------- | -------------
& --------> &
```
Next assembly code, we can see that it is performing the subtraction to some register.
```shell
proc:
movq 8(%rdi), %rdx
movq (%rdx), %rax
movq (%rax), %rax
subq 8(%rdx), %rax <-- %rax = %rax - Mem[%rdx + 8]
movq %rax, (%rdi)
ret
```
The interesting part is `Mem[%rdx + 8]`. I have said that the value which `%rdx` holding is the address of pointer `*ptr` point to.
Then it adds 8 offset to the `%rdx`, it is accessing `ptr->e2.next`, and the subsequent assembly code has no other offset to add, that is , it is accessing the zero offset of either `struct e1` or `struct e2`.
And there is a tiny thing that the whole satement is not deferenced.
```cpp
(ptr->EEE.FFF->GGG.HHH)
```
It is absolutely acccessing the member `x` of `struct e2`.
- `EEE` is `e2`
- `FFF` is `next`
- `GGG` is `e2`
- `HHH` is `x`
### `.cfi_startproc` & `.cfi_endproc`
Thanks for the < `colinyoyo26` >
The following content is quoted from [here](https://hackmd.io/@colinyoyo26/2019q3quiz7)
Stack unwinding
- The process of removing function entries from function call stack at run time is called Stack Unwinding. Stack Unwinding is generally related to Exception Handling.
查閱 [the x86-64 Linux “ABI” - Intel® Developer Zone](https://software.intel.com/sites/default/files/article/402129/mpx-linux64-abi.pdf) 得到以下資訊
> 6.3 Unwinding Through Assembler Code For successful unwinding on AMD64 every function must provide a valid debug information in the DWARF Debugging Information Format. In high level languages (e.g. C/C++, Fortran, Ada, ...) this information is generated by the compiler itself. However for hand-written assembly routines the debug info must be provided by the author of the code. To ease this task some new assembler directives are added:
cfi (call frame information) compiler 會自動加入,用於程式遇錯誤時紀錄 Stack Trace
另外 .debug_frame 要加入 -g 編譯才會有,除錯資訊量更大
`.cfi_startproc`
- is used at the beginning of each function that should have an entry in .eh_frame. It initializes some internal data structures and emits architecture dependent initial CFI instructions. Each .cfi_startproc directive has to be closed by.cfi_endproc
> 在有 .eh_frame 內有 entry 的 function 需要加入這個,用於初始化內部資料結構
`.cfi_endproc`
- is used at the end of a function where it closes its unwind entry previously opened by.cfi_startprocand emits it to.eh_frame
> 和 .cfi_startproc 搭配使用
4.2.3 Special SectionsTable
- .got This section holds the global offset table.
- .plt This section holds the procedure linkage table.
- .eh_frame section holds the unwind function table.
4.2.4 EH_FRAME sections The call frame information needed for unwinding the stack is output into one or more ELF sections of type SHT_X86_64_UNWIND.
> eh_frame 用於支援 stack unwinding
### Implementation of linked list
[GitHub](https://github.com/kksweet8845/LinkedList_x86_64/blob/master/linkedlist.asm)
// ToDo
Add the explaination
```cpp
%macro init 1
mov qword [%1], 0
%endmacro
%macro append 1-*
%rep %0
push qword %1
push linkedList
call ll_append
%rotate 1
%endrep
%endmacro
%macro print 1
push qword [%1]
call ll_print
%endmacro
global main
section .data
size_i:
struc node
info: resd 1
next: resq 1
endstruc
len: equ $ - size_i
numOfNode: dd 0
MAXNODE: dd 20
section .bss
linkedList: resq 1
buffer: resb 320
section .text
main:
; save stack
push rbp
mov rbp, rsp
init linkedList
; Append the hex codes of the message 'LinkedList NYC' to
; the linked list via the append macro
append 0x4c, 0x69
; Print out the contents of the linked list
print linkedList
; Restore stack
mov rsp, rbp
pop rbp
ret
malloc:
; Store stack
push rbp
mov rbp, rsp
; Save register
push rax
push rbx
cmp numOfNode, MAXNODE
je malloc_failed
; access the number
mov [byte buffer + numOfNode*16], 0 ;save the info to it
mov qword [buffer + numOfNode*16 + info], 0 ;Set the next to null
mov byte [buffer + numOfNode*16 + info + next ], 0 ;Set the unavailable
mov rax, numOfNode
mov [rsp + 16], rax
jmp malloc_exit
malloc_failed:
; Failed to malloc address
malloc_exit:
pop rbx
pop rax
; Restore stack
mov rsp, rbp
pop rbp
ret
ll_append:
; store stack
push rbp
mov rbp, rsp
; save register
push rax
push rbx
call malloc
; which will return pointer at eax
mov rbx, [qword rbp + 4]
mov dword [buffer + rax*16], rbx
mov qword [buffer + rax*16 + info], 0
mov byte [buffer + rax*16 + info + next], 0 ; indicate the current node is unavailable
; Check if the linked list is currently null
mov rbx, [qword rbx + 3]
cmp qword [rbx], 0 ; Set the ZF if equal
je ll_append_null
mov rbx, [rbx]
ll_append_next:
; Find the address of the last element in the linked list
cmp qword [rbx + info ], 0
je ll_append_last
mov rbx, [rbx + info ]
jmp ll_append_next ; Unconditional jump
ll_append_last:
mov qword [rbx + info], buffer+rax*16
jmp ll_append_exit
ll_append_null:
; set pointer to first element
mov [rbx], rax
ll_append_exit:
; Resotre registers
pop rbx
pop rax
; Restore stack
mov rsp, rbp
pop rbp
ret 8
; Linked list print
; Print all elements out from a linked list
ll_print:
; Save the stack
push rbp,
mov rbp, rsp
; Save register
push rbx
; Get the address of the first element in the list
mov rbx, [qword rbp + 2]
; If ebx is 0, then the list is empty - nothing to print
cmp rbx, 0
je ll_print_exit
ll_print_next:
; Loop through the linked list and print each character
mov rax, 1
mov rdi, 1
mov rsi, [rbx]
mov rdx, 4
syscall
mov rbx, [rbx + info]
; As long as ebx doesn't equal 0 (end of list) then loop
cmp rbx, 0
jne ll_print_next
; Print a new line character at the end
push dword 10
mov rax, 1
mov rdi, 1
mov rsi, dword 10
mov rdx, 1
syscall
ll_print_exit:
; Restore stack
pop rbx
mov rsp, rbp
pop rbp
ret 4
```
 Sign in with Wallet
Sign in with Wallet







