---
title: Webinaire 5 GT Notebook
date: 2024-04-02
---
# Webinaire 5 GT Notebook - 2 avril 2024 13h30-14h30
###### tags: `gt notebook`,`webinaire`

:::info
- Présent.e.s :
- Konrad Hinsen
- Alexandre Wauthier
- Alia Benharrat
- Anne Vial-Logeay
- Briand
- Carmen Brando
- Charles Bourdot
- E Braux
- Elisaneth Guerard
- Frédéric Clavert
- Frédéric Vergnaud
- Hakima Manseri
- Victor Hoffner
- Julien Rabaud (UPPA)
- Marnon Marchand
- Martin Amouzou
- Mattia Bunel
- Max Beligné
- Muriel Val Ruymbeke
- Nicolas Rougier
- Nicolas Sauret
- Nicolas Thiéry
- Quentin Guilloteau
- Raphaël Tournoy
- T Dupriez
- Sébastien Rey-Coyrehourcq
- Raphaëlle Krummeich
- Pierre C
- Laurent Mouchard
- Nicolas Roelandt
- Alex
- Anna
- Sébastien Morin
- Cathy Tuchming
- Antoine Fortuné
- Rastetter
- Nicolas Roelandt
- Guillaume
- ff
- Excusé.e.s :
- Hugues Pécout
- Lien site web : https://gt-notebook.gitpages.huma-num.fr/site_quarto/
- Issue & ODJ : https://gitlab.huma-num.fr/gt-notebook/webinaires/-/issues/6
- Lien visio BBB : https://webconf.univ-rouen.fr/greenlight/rey-px2-ewg-7av
- Lien chat public : https://rocket.esup-portail.org/channel/GT-Notebook
- Lien mailling-list : https://groupes.renater.fr/sympa/info/notebooks-inter-reseaux
- Lien support présentation et notebooks de démonstration:
:::
## Ordre du Jour
- Accueil (5 minutes)
- Intervention de **Elisabeth Guérard et Frédéric Clavert, Journal of Digital History**
- Discussions
- Compte-rendu des journées du réseau Recherche Reproductible
- Infos / événements
- JE de l'automne
### Accueil
### Journal of Digital History
https://journalofdigitalhistory.org/en
Elisabeth Guerard : depuis 3 ans au DH Lab, premier projet sur le journal DH : développement + participe au board du journal et en charge de la revue technique

Journal Diamond (seul journal gratuit de Greyter)
Les auteurs ne payent pas
Passage du double aveugle à simple aveugle
Ecriture d'article à couches multiples : valoriser des recherches data driven
Multi layered article, pas facile à traduire en français
La revue est exclusivement en ligne
Trois couches :
- narrative: exposition des résultats d'une recherche
- herméneutique : méthodologie, outils numériques utilisés, code, possibilité de reexecution
- critique : discussion sur résultats et méthodo/outils

Darnton (new age of the book 1999) : Ce que peut être le livre à l'ère du web : en 6 couches
1. vue d'ensemble du sujet
2. plus d'explications, couche narrative
3. documentation
4. historiographique / discussion
5. pédagogique
6. commentaires autour du livre : rapport, évaluation, annotation, etc.
Inspiration : The valley of the shadow

accès aux sources primaires

montrer ce qu'est l'histoire, le travail de l'historien, ce qu'est l'interprétation de l'histoire
Pourquoi des notebooks : revue de diff. éditions scientifiques sur le web :
- Wordpress (commonpress) → commentaires sur diff. chapitres au niveau du paragraphes
- Blogs scientifiques : interactions avec les lecteurs
- annotations ouvertes
- Collection [Parcours Numériques](https://www.parcoursnumeriques-pum.ca/) (Michael Sinatra, Marcello Vitali-Rosati) au PUM : version étendue sur le web, notes additionnelles, contenus zotero, mais pas d'execution de code

- Signature graphique (visualisation) de chaque article
- Couche narrative en premier lieu lorsqu'on clique sur un article.
- Couche herméneutique, accès au code du notebook ? on clique sur le bouton, on peut basculer d'une couche à l'autre :
> Méthodologie, code, outils numériques utilisés + perspective critique sur ces méthodes, code et outils.
- Bibliographie géréé par Zotero
- couches données : github + serveur dédié
- on peut ouvrir dans mybinder pour visualiser le notebook, ce qui permet de visualiser et rejouer le code (limité toutefois en capacité - d'où l'intérêt de dépôt github)
-
#### Environnement d'écriture composite

- quel éditeur ? Jupyter notebook ? réaliser "nos propres boutons", environnement NB a beacuoup changé (Quarto, Lisp markdown)
- écosystème de plus en plus mûr
Choix de Juptyer:
- idée d'utiliser un logiciel existant pour d'autres utilisations (pédagogique, pérenne)
- pérennité et écosystème
- question du langage (julia, python, R) - non limité pour les humanistes
- combiner écriture, média et code (vidéo, iframe, audio, html - nos développements) - flexible et ouvert grace à ipython display

Impose une connaissance de github, markdown, un langage de programmation, binder, zotero (citation manager) → vers une _digital literacy_ ?
- premiers auteurs familiers de github et python... mais travail à réaliser pour les nouveaux auteurs - un stack docker (pour python, pour R) pour les utilisateurs
- configruations préexistantes des auteurs avec leurs propres environnements (conda, etc.)
- plusieurs co-auteurs / partie narrative & partie technique
comment amener des auteurs à produire des articles multi-layers ?
- stratégie : proposer des template_repo_JDH sur github contenant déjà tous les éléments demandés
- systèmes de tags (ex: herméneutique) pour les différentes couches
question: même stratégie pour RZine ? https://rzine.fr/
Contrainte de certaines versions de python ou R ? certains auteurs développent leurs propres librairies.
Environnement très ouvert avec cet investissement de départ qui peut paraitre très important.
#### Du notebook à l'article

Les articles de la revue ne sont pas un simple affichage des notebooks.

Le notebook est parsé et le résultat du parsing est affiché ç l'écran
On utilise la fonctionnatlité du tagging de chaque cellule (code ou texte):
- chaque cellule de texte va aller dans la couche narrative
- cellule de code → couche herméneutique
mais l'un ou l'autre peut aller dans l'une ou l'autre des couches (une cellule de code affichant un tableau)
inconvénient : linéarité du notebook --> contourné via les tags
Commet les auteurs jouent avec les différentes strates ? Avec ces fameuses fingerprint/empreinte => cercle avec des lignes.

Représentation des articles:
- Violet = code
- Noir = texte
- Plus la ligne est longue plus la cellule est longue
- Cercle pour le titre, rond pour les citations biblio
Au début, des articles assez linéaires : narration puis code puis discussions
Evolution des pratiques, désormais les auteurs passent d'une couche à l'autre, au sein même du texte : allez-retour entre narratif et herméneutique
Questionnement des auteurs => Savoir ce qui peut être mis dans la couche narrative ou hermeneutique ? → Diff. types d'article
#### Évaluer un article à strates multiples

On distingue
- l'évaluation technique
- l'évaluation classique
Evaluation technique, beaucoup de travail à faire, notamment sur la partie reproductible. Passage en simple aveugle aussi pour cette raison car github il faut l'anonymiser.
Mise en place d'une Charte éthique à respecter, évaluateur connaitrons les personnes à évaluer.
Evaluation classique par les pairs
La partie évaluation classique, pas évident d'avoir des thématiciens, donc on passe par du pdf ou de la visualisation en ligne.
Problème de l'évaluation du code, toujours pas complétement résolu, et on essaye d'avoir quelqu'un de capable d'évaluer ce code.
Beaucoup de choses faites manuellement au départ, avec des écueils récurrents qui ont permis d'aller vers l'automaisation
Pousser à ce que les auteurs soient aussi les.. de l'évaluation technique
Action github "prefly action" pour faire un premier check pour détecter les problèmes (urls root, js, citation formaté, nbconvert fonctionne, lib installées, etc.)
Production en markdown a titre indicatif pour l'auteur. L'usage du template fait que de pus en plus de gens sont conscients du contexte d'écriture. Evaluation technique se limite au formatage du code et l'execution.
Fonctionnalité demandée par les auteur·e·s : version PDF en ajoutant `.pdf` à l'url. ~~Web2print : production d'un pdf depuis la version Web~~ pas de CTRL+P, voir la question dans la discussion
https://github.com/c2dh/journal-of-digital-history-ipynb-preflight-action
Complexité d'installation pour les auteur·e·s, mais ensuite, ca marche plutôt bien.
Défis :
- archivage des articles (script spécifique par la bibliothèque nationale)
- mise à jour de la plateforme (version notebook de JLab) : estce que les anciens articles sont compatibles avec les dernières maj ?
### Discussions
#### action de prévol inclue t'elle des vérifications de bonnes pratiques d'accessibilité du texte, comme par exemple la présence d'alt dans les images? ou la bonne séparation fond/forme?
le prefly est au niveau du notebook, contrôle l'affichage (preview) du notebook.
Ce serait plutôt au parser multicouche de tester l'accessibilité (ALT par exemple).
#### Quel pourcentage d'historiens sont capables d'utiliser cette stack techniques
Ce serait plutôt le pourcentage d'historiens capables de travailler en collaboration : digital humanist + historien
certains historiens y voient très vite l'intérêt (par exemple en histoire orale)
#### question de delegation de calcul qui pose probleme pour de la reproductibilité ?
certains articles font déjà du machine learning. la limite, c'est la mémoire des notebooks. Dans ce cas, certains scripts sont simplement mentionnés dans le notebook, mais ne sont pas présents : trop complexe.
article avec IA générative : besoin de codes d'acces pour rejouer le notebook.
histoire contemporaine : on doit accepter parfois que certaines données ne soient pas ouvertes
#### question évaluation et maintenance du code : avez-vous une action d’optimisation, de nettoyage, de réorganisation du code ? Le code est-il évalué comme le texte par des pairs et de manière classique avec des allers-retours entre auteur et évaluateur ?
Au début, les éditeurs n'osaient pas retoucher le code des auteurs, mais expérimentation en cours / exécution séquentielle des cellules, télécharger les imports etc. mais pas l'idée d'évaluer le code autre que sur le fait d'être exécuté ou non.
#### sur la maintenance : les langages évoluant rapidement, certains objets/fonctions/bibliothèques doivent être mises à jour voire deviennent obsolètes. Qu’avez-vous prévu pour cela ?
Développement de sa propre librairie (detection d'image dans les vidéos) : pas de review possible (trop couteux en temps)
Pour les librairies obsolètes : on collecte les versions utilisées
#### question d'accessibilité sur l'activation JS et motivation à ne pas mettre à disposition les pdf
le pdf donne accès à la seule couche narrative. Pas d'intérêt de mettre un code non interactif, donc la couche herméneutique est hors scope
#### infrastructure
hébergement C2DH - université de Luxembourg (docker stack - difficultés firefox)
on prefere utiliser mybinder plutôt qu'un environnement dédié dans un docker pour chaque article.
Pas de possibilité d'utiliser un binderhub à la place de mybinder
Evoque l'utilisation de Codespace de Github avec l'interface jupyterlab (le template utilisé pour codespaces https://github.com/github/codespaces-jupyter template)
#### Quelle réception chez les historiens ou chez les collègues ?
très bonne réception dans les DH, milieux numériques
pas de pb à recruter des auteurs pour le moment (discplines "du passé", pas simplement "histoire")
le notebook devient une infrastructure au sein du C2DH
Le refus d'un évaluateur est souvent une question de temps. Les évaluateurs n'ont pas à évaluer le code ou la partie herméneutique : distribution des rôles
Retour de certains auteurs ? pas encore pour le moment. mais certains sont devenus évaluateur, voire membre du comité
#### Perennisation : Gestion d'éléments "vivants" → software heritage
pas encore d'initative de ce côté là.
- PDF pour la couche narrative
- Github
- serveur dataverse
Nicolas Thiéry :
> il y a un projet d'infrastructure Jupyter nationale (candyce.org), pensé en premier pour l'enseignement, mais aussi pour des usages «légers» en recherche. Avec notamment cette fonctionnalité de souplesse des environnements comme dans mybinder. La première tentative de demande de financement traîne depuis 2021 (soupir); nous sommes en train de repenser le projet sur d'autres sources potentielles d'enseignement. Don't hold your breath though, comme ils disent.
>
> Je note le cas d'usage pour alimenter la réflexion. N'hésitez pas à contribuer des témoignages sur l'intérêt que pourrait avoir ce type d'infrastructure sur https://codimd.math.cnrs.fr/kWae25O-Tqyg5_PdeH_VWw# .
### Compte-rendu des journées du réseau Recherche Reproductible
Accès au programme :
https://jrfrr-2024.sciencesconf.org/resource/page/id/1
3 jours à Grenoble, environ 50 personnes en présentiel et plus d'une centaine de personnes en visioconférence. Tout a été capté, donc les vidéos devraient être disponibles sous peu. En attendant, ci-dessous, l'ébauche du report de quelques notes. Le GT Notebook, qui a bénéficié de la communication sur le site web du réseau RR tout au long de l'année, était invité pour faire un retour d'expérience le jeudi 28/03 (Raphaelle Krummeich, Sébastien Rey-Coyrehourcq). Plusieurs membres du GT était aussi présent (Konrad Hinsen, Nicolas Rougier) dans la salle.
#### Mardi 26 Mars après-midi : "Introduction générale, contexte français et européen"
---
**Historique du réseau RR | Microbiome & Cancer**
- empirical, statistical, computationnal reproductibility
- 2023 network days : state of the art
- 110 inscrit-es
- reproductibilité observationnelle, computationnelle, statistique, expérimentale,
- pédagogie & initiatives européennes & internationales
- définition des limites de la reproductibilité,
- sujets & GT, communauté
- objectifs : fédérer, actions de support, matériel pédagogique, promotion...
- équipe : 5 membres du comité
- réseau : 160 inscrit-es & forum
- structure : 3 collèges transverses, gt thématiques, partage de pratiques etc.
- soutien MESR : poste de chargé de projet en cours de recrutement (31st march)
=> support (temporaire) partagé : https://semestriel.framapad.org/p/jrfrr2024-a6iy
**(Isabelle Blanc, MESRI) de la transparence à la reproductibilité**
La transparence de la recherche est un élément clef, mais elle ne garantit pas la reproducbilité.
La science ouverte (*open science*) et la reproductibilité sont toutes deux essentielles pour améliorer la qualité des résultats de recherche et la fiabilité des pratiques de la recherche scientifique. Elles sont deux composantes majeures de l'intégrité scientifique.
**(Ulf Toelch) From local to national initiatives: How to make reproducible research the norm**
[QUEST Center for Responsible Research](https://www.bihealth.org/en/translation/innovation-enabler/quest-center) develops and implements new approaches to ensure biomdecical research is conducted in trustworhty, useful and ethical manner.
- observationnal innovation curve (gaussian) 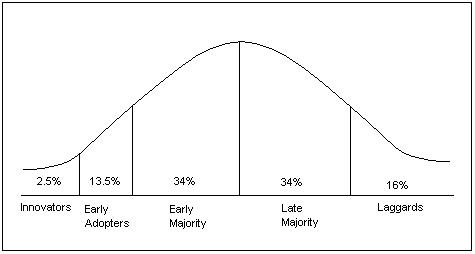
*innovators & early adopters (at the first / left part of the curve, where reproducibility "is") then early majority, late majority & Laggards (see Nosek et al 2022, Annual Review Psychology 73:19-48)*
- interventions
- infrastructure : make it possible
- user experience : make it easy
...
- communities : make it normative
- incentives : make it rewarding
- policy : make it required
- behavioural change wheel
Advancement of knowledge : trustworthy (robust & rigorous), useful (for scientists transparent, for society relevant), ethical (for humans, for animals)
- more thant 10 national networks in Europe, see [National Reproducibility Networks: A strategy for a loose federation](https://osf.io/aq5je)
- there is an African reproducibility network (https://africanrn.org/) and a Brazilian reproducibility network (https://www.reprodutibilidade.bio.br/home)
- european funded projects :
- [Improving Reproducibility In SciencE](https://www.irise-project.eu/)
- [Open Science to Increase Reproducibility In Science](https://osiris4r.eu/)
- [Enhancing Trust, Integrity and Efficiency in Research through next-level Reproducibility](https://www.tier2-project.eu/), and report [The Future(s) of Reproducibility in Research](https://osf.io/k2nzv)
To make reproducible research the norm
- Diverse set of low entry interventions needed (board vs deep)
- Barriers (e.g., work environment need to identified and mitigation stategies are needed)
- Reproducibility networks need to be strentghtened on national and international levels
- Outcome and impact need to be measurable
**(Eva Furrer) Training at the Center for Reproducible Science (CRS)**
Supports : https://osf.io/drthk
- Nombreuses ressources pédagogiques & matériel / retour d'expériences
- quelques liens utiles :
[Teaching tools](https://teachingtools.uzh.ch/)
[5 steps to good data science pratice in R](www.sts.uzh.ch)
[UZH Reproducibility Day 9 février 2023 organized by CRS](www.reprozurich.org)
[Publication "Ten simple rules for good research"](https://journals.plos.org/ploscompbiol/article?id=10.1371/journal.pcbi.1010139)
Swiss Reproducibility Conference : june 2024, https://www.reproducibility.ch/
Depuis 2018, 2 journées de formations, participants assez interdisciplinaires entre 2019 et 2022.
- Program day 1 :
- open science principle
- best pratcice
- effective statistical practice : Kass et al. 2016
- study protocols and registration
- statistical analysis plans and data management plans
- how good medata improves your research outputs
- => feedback "reproducibility clinic Q&A"
- Program day 2 :
- reproducibility and replicability
- discussion : data definition and metadata
- git
- etc.
- ...
- feedback
Il existe aussi une autre formation, _from design to paper : make your research fully reproducible_, trois jours pour les _arts and social sciences_ :
- open science in qualitative research
- intensive workshops on version and RMarkdown
- Containerization
- Publications bias
Ils prennent tous les étudiants et étudiantes qui remplissent un certain nombre de critères, et ils ont fixé des objectifs à atteindre en terme d'apprentissage qui sont intéressants.
Autre formes de discussions et accès aux ressources :
- Lunch and Learn
- [Reproducibility Lab Pitch](https://www.crs.uzh.ch/en/training/ReproLabPitch.html)
- CRS Primers = > [CRS Zenodo communities](https://zenodo.org/communities/crs-uzh/records)
Pas encore de feedback récolté de façon systématique auprès des participant.e.s pour savoir ce que font ensuite les gens suite aux acquis de ces journées.
#### Mercredi 27/03 matin : "Reproductibilité expérimentale"
---
Quatre thématiques très différentes sont représentées, la psychologie expérimentale (Dominique Muller), la métalobolomique (Estelle PUJOS-GUILLOT), la sismologie (Jonathan Schaeffer), et la physique avec les synchrotron (Andrew Goetz).
**(Dominique Muller) Réplicabilité et reproductibilité en psychologie expérimentale**
Dominique Muller a beaucoup évoqué les dégats faits par la crise de la reproductibilité dans sa discipline, et sa présentation était l'occasion d'évoquer à la fois les mesures et les réflexions prises pour y remédier collectivement.
Deux exemples de publications sont cités comme catastrophiques, et entraine une perte de temps collective sur le plan de la replicabilité : les "capacité extra sensorielle" (Daryl J Bem en 2011) et "l'effet d'épuisement de soi". D'autres sont plus volontaire, comme des "pavé jeté dans la mare" pour évoquer les failles d'analyses statistiques et le p-hacking : "False Positive Psychology" (Simmons2011)
Dominique Muller à évoquer plusieurs techniques pour tenter d'y remédier :
- des méta-analyses et des études multi-centriques,
- l'emploi de techniques statistiques particulière (Bayes Factor),
- l'augmentation des taills d'échantillon à plus de 50 personnes,
- l'acceptation des études peu importe leur résultat (Registered Report),
- l'émergence de plateforme de données ouvertes comme OSF,
- des indicateurs/indices de réplicabilité.
- charte sur les pratiques dans les laboratoires pour les nouveaux recrutements
Il en résulte une nouvelle forme de champs d'étude dans la psychologie expérimentale, "une méta-science" propre à l'étude ce ces biais et des outils pour leur résolution.
**(Estelle Pujos-Guillot) Reproductibilité expérimentale en métabolomique**
- vision intégrée du métabolisme
- data complexity : facteurs intrinsèques & extrinsèques + bruit des mesures, manque d'interopérabilité & de reproductibilité
- domaine à la frontière de plusieurs disciplines (biologie, chimie analytique, statistique bioinformatique)
- sources de variation / bias : effet saisonnier, temporalité de la nutrition, collecte manuelle ou robotisée, conditions de conservation des échantillons, spectrométrie de masse - destructive - biais d'*encrassement* de la machine
- question de la reproductibilité en terme de résultats
- consortium sur la qualité des processus & résultats / certification
- résultats : pas de standardisation mais publication d'indicateurs variés mais pas de consensus, sur les approches analytiques (ciblées & non ciblées) - décrites mais pas homogènes, il existe des normes ISO (champ d'application de l'industrie pharmaceutique) mais non applicables pour les métabolites
- plusieurs solutions : méthodologie de quantification absolue (métabohub2.0), stratégies post-analytiques avec des analyses multi-variées et correction des données
**(Jonathan Schaeffer) Ré-utilisabilité des données : l'exemple de la sismologie dans Epos-France**
Les données sismologiques sont fédérées au niveau national via un réseau hierarchique, par le centre de données sismologiques Epos France certifié _Certification Core Trust Seal_ cette année, qui sanctionne les bonnes pratiques au niveau scientifique. Les données sont consultées depuis le monde entier avec des protocoles standards, il s'agit de données de séries temporelles sans métadonnée, celle-ci étant distribuée par ailleurs.
Les attributs pour les métadonnées sont : position géographiques, orientation des capteurs, réponse instrumentale, condition au sol. Les métadonnées de citation utilisent le vocabulaire datacite où un DOI est attribué par réseau sismologique. Le format de données n'a pas changé depuis 40 ans, mais maintenant il y a des nouvelles technologies (fibre optique, haute fréquence) pour lesquelles le format n'est plus adapté. Pour le moment on ne sait pas faire, donc on fait des transformations de format, des réductions pour rentrer dans le standard... mais on commence à avoir un virage et des nouveaux formats spécifiques avec de nouveaux protocoles d'échanges.
En terme de stockage, les données ne sont pas trop volumineuses et restent très importantes sur le plan scientifique. Cela représente 40 ans de données d'observation, on les garde en ligne, et c'est plutôt préférable (~100To). Sur les données de très gros volume, il n'y a pas encore la maturité de la réflexion. Actuellement les nouveaux instruments c'est plutôt 100To par mois pour un instrument, donc il va falloir gérer cette rupture instrumentale en terme de volumétrie ! Il y a des technologies qui permettraient de faire du "tiring" pour les garder un peu en retrait.
|Critère FAIR|sismologie|
|--|--|
|Findable | Doi, Métadonnées métier et métadonnées datacite complètes, Lien métadonnée - données |
| Accessible | Métadonnées métier avec standard, Métadonnée survivent à la donnée|
| Interoperable | Vocabulaire contrôlé|
| Réusable | ce qui est détaillé dans cette présentation|
Ce que l'on vise :
- Faciliter l'accès à la donnée
- Réaliser des corrections sur la métadonnée
- Garantir que son interprétation sera toujours possible
Identification claire :
- Orcid pour les personnes
- RE3DATA pour les centres de données
- RoR pour les organismes impliqués
Plutôt de la réutilisabilité que de la reproductibilité ici.
Les systèmes ne permettent pas de faire de la reproductibilité car :
- la donnée peut être modifiée par le producteur
- il n'y a pas de versioning
- ni de standard du domaine pour figer les données et l'identifier de façon pérenne.
Mais il y a des propositions en cours.
**(Andy Gotz) Reproducibility in photon science**
Andy Gotz est _Data Manager ESRF_, _Responsable Software + Data manager_ et _PaNOSC coordinateur_
Pour lui la reproductibilité = DATA + CODE devrait être :
- accessible
- available
- cited
- verifiable
- reusable
Les synchrotrons sont amenés à analyser des échantillons qui vont du nano au mètre, ce qui induit énormément de variété en terme de données et de disciplines. La [LEAPS initiative](https://leaps-initiative.eu/) est un consortium pour travailler tous ensemble : partage standard et trouver des solutions. Au niveau mondial, cela représente une 20aine de synchrotrons et lasers électron libre.
A terme, tous les synchrotrons doivent être upgradés, avec un facteur 100 en terme de faisceau en puissance, flux, qualité. ESRF Upgrade a été le premier en 2020 (https://www.esrf.fr/fr/home/about/upgrade.html)
En terme de production, cela représente habituellement 10Po par an par instrument, et avec les nouvelles machines on sera à 100Po par an. C'est un défi de gérer 100To, donc la plupart de ces données restent dans ces instituts. Pour gérer l'accès à la donnée, un important travail est réalisé avec le programme européen [EOSC](https://eosc-portal.eu/), et récemment, le lancement du programme OSCARS autour des données (https://oscars-project.eu/). Le problème n'est pas le stockage, mais la qualité des métadonnées et la curation donc. Le défi est donc de tout garder dès le départ.
A ce jour, les métriques FAIR dans le domaine du photon, c'est : F 25%, A 25%, restent le I et le R qui sont à 0%. L'emprunte carbone d'une expérimentation avec un synchrotron (7-8 mégawatts en fonctionnement) est élevée, par exemple 3 tonnes équivalent CO2 pour générer un jeu de données de 200Go. Le système d'archivage l'est beaucoup moins; sur 10 ans, c'est 130 grammes de CO2 pour 200Go. La stratégie est donc de garder les données, car ce n'est pas plus facile de refaire l'expérience ! Avec LTO 9 à 1 hexabyte, il sera possible de faire du stockage ADN (*cold storage* pour 500 ans).
La typologie des pratiques associées aux différentes données est la suivante :
|type|mesure/règle adoptée|
|--|--|
| raw |=> archivé au moins 10 ans|
| processed| => workflow stocké expliquant le traitement|
| auxiliaires |=> images, échantillons, etc. souvent préparatoires & nécessaires pour comprendre les données : elles ne sont pas systématiquement syockées avec les données brutes|
| résultats | => stockés plutôt proche des données brutes, mais on est pas encore là |
|dérivées |=> réutilisation "dans la nature", c'est à dire pas de contrôle|
| *Data Policies* | adoptées par tous les synchrotron en Europe (90%): [PaNData](http://pan-data.eu/) in 2010, [PaNosc](https://www.panosc.eu/) in 2019|
|portail thématique (par domaine) | Human Organ Atlas, par exemple (https://human-organ-atlas.esrf.eu/search)|
|doi | < 10%|
| modèle de données | HDF5/Nexus (http://pan-data.eu/NeXus) avec d'autres, par exemple, pour la paléontologie, la médecine, etc.|
| plateforme de visualisation | MyHDF5 (https://myhdf5.hdfgroup.org/), portail pour voir ce qu'il y a dans un dataset sans bouger les données !|
| revue Data paper | Raw Data Letters (https://iucrdata.iucr.org/x/|index.html)
#### Mercredi 27/03 après-midi : "Reproductibilité computationelle"
**(Ludovic Courtès / Pierre-Antoine Bouttier) Introduction à la reproductibilité des environnements de calcul : construction de paquets et liens avec Software Heritage**
Une session des [café guix](https://hpc.guix.info/events/2024/caf%C3%A9-guix/), un événément qui se tient environ une fois par mois, à eu lieu en début d'après midi. Cette session était volontairement orienté grand débutant, avec pour objectif d'introduire l'intérêt de Guix au plus grand nombre.
Résumer la session en détail ici serait trop complexe, vous pouvez trouver les supports sur le site des café guix, et bientôt sur le site de la conférence RRR.
Les principales avantages de Guix sont présentés au travers de :
- la gestion d'environnement séparé (similaire à Virtual Env par exemple) qui peuvent être décris et figés dans leur versions via deux fichiers `manifest.scm` et `channels.scm`
- la possibilité de mixer les versions de paquets au sein de ces environnements séparé grâce à `guix time-machine`
- guix étant un gestionnaire d'environnement logiciel complet, une fois l'environnement décrit il est très facile de générer des containers docker, des tar.gz, etc. à partir de celui-ci.
Ainsi, GUIX répond à diverses questions :
- quid *faits pour la reproductibilité" ?*
- indépendance du système hôte à la construction des binaires
- construction reproductible des binaires
- définitions
- un paquet guix = code source des instructions & dépendances pour installer un logiciel
- un channel guix = dépôt git contenant un ensemble de définitions de paquets
- comment ça marche
- guix construit des binaires à partir des instructions, dans un répertoire /gnu/store
- ensuite, via liens symboliques & positionnements de variables, il permet l'accès utilisateurs et utilisatrices
#### (Miguel Colom-Barco) Software Heritage and IPOL, a fruitful collaboration toward reproducible research
[Ipol](http://www.ipol.im/) est un journal de l'ENS Cachan, Centre Borelli, sur la thématique du traitement d'image. Ouvert depuis 2009, ce journal propose une revue de code source FOSS (CC-BY-NC-CA, GPL/BSD, CC-BY) en plus d'une revue thématique depuis 2010. Il y a également une démo en ligne disponible.
On retiendra une remarque classique pour les journaux qui font de la revue de code à l'heure actuelle, il n'est pas facile de trouver systématiquement deux reviewers pour le code et la thématique. On pourrait penser qu'il suffit de séparer en deux personnes, mais parfois, ce n'est pas possible de séparer l'expertise thématique de l'expertise du code source.
Pour le moment l'archivage du code source sur SWH se fait manuellement, par période, mais il y a la volonté de l'automatiser.
Perspective :
- déploiement automatique
- utilisation de SWHID
- téléchargement automatique des sources
- pour la revue, préférer la copie sur SWHID plutot que la copie locale
- vérification de l'intégrité
Des nouveaux outils restent en développement, ceux-ci seront reversé à la communauté en open-source.s
#### Jeudi 28/03 matin : "Présentation des GT" et de la future "Gouvernance"
- Présentation du "GT sur les formations", avec la volonté de dresser un paysage de l'ensemble des formations qui proposent d'aborder la reproductibilité.
- Pour la présentation du "GT Notebook", vous pouvez retrouver [les slides ici](https://hackmd.io/MeTLHXNFR0S0cjEte_zSVw#/1), nous avons essayé de mettre quelques notes aussi dans le corps du texte.
- Konrad Hinsen a fait un rapide retour (statistique) sur la première version du MOOC reproductible de l'INRIA, dans ses différentes versions (https://www.fun-mooc.fr/fr/cours/recherche-reproductible-principes-methodologiques-pour-une-science-transparente/) avant de nous parler de la suite, cette fois-ci destinée à un public plus avancé : https://www.fun-mooc.fr/fr/cours/reproducible-research-ii-practices-and-tools-for-managing-comput/
- Présentation de la structure temporaire adoptée pour la suite [WIP]:
- Comité pilotage
- Collèges transverses
- Animation scientifique => Présence de Nicolas Rodlandt
- GTs : formation, Notebook, ...
- National / International => impliquer/intégrer des acteurs directement ?
- Veille & bibliographie (AAP / Publications / Politiques) => Présence de Nicolas Rougier
=> il faut un animateur par collège
- **Un appel a été lancé, si vous êtes au courant d'un événement lié à la recherche reproductible dans votre entourage, n'hésitez pas à le relayer au COPIL !**
- Les prochaines journées seront à Lyon en 2025
### Infos / événements
### JE de l'automne
- 2 journées
- un *sprint* PKM
- des conférences invitées (paradigme LP, écosophie, reproductibilité)
 Sign in with Wallet
Sign in with Wallet







