# 回顧 ARM 架構
## 經典回顧
* [1992 年 ARM 在 Apple 內部簡報](https://youtu.be/ZV1NdS_w4As)
> A historic internal presentation made by ARM to Apple Computer staff regarding the ARM 610 processor.
* [Mike Muller Interview - 2018 - Life, Acorn and ARM](https://youtu.be/ljbdhICqETE)
## State-of-the-art Technology
* [ [source](http://www.eetimes.com/document.asp?doc_id=1329941) ] 全球 500 強超級電腦 (Top500) 在 6 月 20 日公佈排名,中國研發製造的「神威太湖之光」(SunwayTaihuLight) 的效能表現為:
* "93 petaflops/second on the Linpack benchmark (浮點運算)
* a theoretical peak performance of 125.4 Pflop/s"
* 系統架構看來是特別為 Linpack 跑分所設計的,所以在跑Linpack時的單位計算功耗(Watts/FLOPS)只有天河系列的三分之一
* 在跑 CG 的時候,反過來這套系統的效率只有天河的四分之一,所以架構上相當的不平衡,推估不少應用在上面跑不好,或是必須花很大代價去優化
* 運算速度排名第一,並終止「天河 2 號」的六連霸,成為當今世界威力最強的超級電腦。這是中國首度沒有使用美國技術 (而是使用過期專利技術),而登上龍頭寶座
* 美國禁止 Intel 出口 KNL 到中國
* Top500 每年發布兩次,此次中國有 167 款電腦上榜,美國上榜數量則為 165 台,是電腦500強問世以來中國上榜數首次超越美國。相較於 10 年前,中國只有 28 款電腦進入世界 500 強,沒有一款進入前 30 名,顯示中國超級電腦領域正在蓬勃發展。
* 「神威太湖之光」安裝在無錫國家超級電腦中心,全機由中國研發製造,主要用於高端製造業、天氣預報和大數據分析,運算速度是之前的超級電腦「天河 2 號」的 2 倍,中國製造的「天河2號」使用的芯片來自 Intel
* 進入前 10 名的超級電腦除了第 1 和第 2 名來自中國,美國占了 4 名,其餘 4 名分別來自日本、瑞士、德國和沙烏地阿拉伯。
* 神威太湖之光使用高達 40,960 個自主研發處理晶片 SW26010 ,每個處理器晶片中有高達 260 個核心,以專利已經過期的DEC ALPHA 21164A EV-56 架構為基礎,開發 64 位元 RISC 處理器,對外聲稱為神威-64 架構,可支援 SIMD 亂序執行,每個晶片記憶體頻寬達到 136.5GB/s ,時脈設定在 1.45GHz
* 訪談: [Jack Dongarra Shares his Assessment of World’s Newest No. 1 Supercomputer](http://sc16.supercomputing.org/2016/06/20/sc16s-jack-dongarra-shares-assessment-worlds-newest-no-1-supercomputer/)
* 背景知識: [superscalar](http://faculty.washington.edu/lcrum/TCSS372AF09/13_Superscalar.ppt)
* 背景知識: [DEC Alpha](https://en.wikipedia.org/wiki/DEC_Alpha)
* 1997 年,《鐵達尼號》(Titanic) 製作電腦特技效果的 [Digital Domain](http://digitaldomain.com/) 公司在製作過程中用了 105 台跑 Red Hat Linux 的 Alpha 電腦 (另有二百多台 SGI 及 55 台 NT) [ [source](http://www.linuxjournal.com/article/2494) ]
* Linux 在 1995 年,即可在 i386 以外的平台運作,包含 Alpha
* [Porting Linux to the DEC Alpha: Infrastructure](http://www.linuxjournal.com/article/1044)
* Digital Domain 製作了不少賣座電影,像是《阿波羅 13 號》、《天崩地裂》、《第五元素》等等。當導演 James Cameron 把《鐵達尼號》的視覺特效交給 Digital Domain 公司時,工程團隊面臨了前所未有的挑戰:鐵達尼號的動畫特效伴隨著一個體型相當龐大、且複雜的物件模型,也就是說,需要非常快速且穩定的電腦系統來作為開發平臺,才能夠負荷如此複雜且大量的視覺特效運算
* 為了以最少的成本換取最高的計算能力,Digital Domain 公司向當時執工作站牛耳的 DEC 公司買下了 160 部 Alpha 工作站電腦。儘管多數的 DEC Alpha 使用者偏好採用 Digital UNIX 或 Microsoft Windows NT 作業系統,但 Digital Domain公司卻選擇在其中的 105 部新機器上安裝 Red Hat Linux 作業系統,事後證實是相當划算的投資,許多動畫特效公司紛紛採用 Linux 搭配價格低廉且高效能的硬體
* [ [source](http://www.saydigi.com/2016/06/you-know-the-cpu-gpu-but-do-you-know-what-vpu-what-is-it.html) ] [Movidius](http://www.stoneip.info/tag/movidius) 對自家處理器的稱為,全稱為 Vision Processing Unit (VPU)
* [Fujitsu picks 64-bit ARM for Japan’s monster 1,000-PFLOPS super](http://www.theregister.co.uk/2016/06/20/fujitsu_arm_supercomputer/)
* [自動駕駛車輛需要什麼樣的處理器?](http://www.eettaiwan.com/news/article/20160608NT02-autonomous-car-processor)
* [World’s First 1,000-Processor Chip](https://www.ucdavis.edu/news/worlds-first-1000-processor-chip)
* [中文報導](https://e.rocket.cafe/%E4%B8%8D%E8%A6%81%E5%86%8D%E8%AA%AA%E4%BD%A0%E7%9A%84%E6%89%8B%E6%A9%9F%E6%9C%898%E6%A0%B8%E5%BF%83%E5%BE%88%E4%BA%86%E4%B8%8D%E8%B5%B7%E4%BA%86-a05c28778b38#.ejmmi0ncp)
* 時脈速度為1.78GHz的處理器,每個核心都可以視需要獨立開啟或關閉,而且核心之間可以獨立互傳資料,不需要經過共用的快取記憶體
* 1,000個核心每秒能處理多達1,150億的指令、而且只耗電0.7瓦,比目前常見的筆電處理器省電100倍
* 處理器具有智慧型自我管理的演算法(例如用其中的4個核心動態管理其餘核心的工作,或是類似的內建機制)、再加上軟體的適當搭配,才能讓它有效分配工作。
* 中國網購公司京東商城在上海的倉庫[接近全機器操作階段](https://www.facebook.com/bbctrad/videos/1357220324294634/) (video)
## 理解計算需求:金融操作
* [Artificial Neural Networks for Beginners](http://blogs.mathworks.com/loren/2015/08/04/artificial-neural-networks-for-beginners/)
* [In Pursuit of Ultra-Low Latency: FPGA in High-Frequency Trading](https://www.velvetech.com/blog/fpga-in-high-frequency-trading/) 闡述 FPGA 在資料搜尋、影像處理,以及金融模型等方面的效能提昇,最顯著的就是金融。全球前 500 大超級電腦,約 10% 由金融機構使用,主要用於避險基金(Hedge Fund) 高頻交易,或投資銀行進行衍生商品模擬運算。
* 銀行的電腦系統配置從多核心 CPU,移動到上千核心 GPU 的環境,後者有高效能、大量模擬運算優勢,而 FPGA 則在Performance/ Power 得以高度客製化,達到最好的表現
* 千萬不要以為 Real-Time System (RTS) 只是跟嵌入式系統相關,事實上 RTS 無所不在,除了在自動控制領域,在股市金融也隨處可見,當然,Linux 也扮演重要的角色,甚至 Real-Time Linux 還跟 KVM (Kernel-based Virtual Machine) 有關!
* 好比有人學中文,畢業後找不到工作,就抱怨中文系沒用,但大陸作家于丹出版《論語》心得,一躍成為中國版稅第二高的作家,中文有沒有用呢?
* 在金融界,有個術語叫做「高頻交易」,一般來說,符合以下三個要件:
* 交易指令: 全由資訊系統發送交易指令,對市場數據的回應時間在 us 等級 ($10^{-6}$ sec)
* 資訊系統: 特製的軟硬體架構,大多使用 FPGA / ASIC,近年也搭配 GPU
* 位置: 需要快速存取交易所主機的資料,自然物理位置也不能太遠,並獲得特別許可,讓交易指令可直接發送到交易所,而非證券商
* 包含 IBM, Oracle, Red Hat 等主要 Linux 開發商都投入資源在 Real-Time Linux,除了作傳統 RTS 應用外,就是鎖定金融市場。
* 延伸閱讀:
* [《我是高頻交易工程師》](https://zhuanlan.zhihu.com/p/25372263)
* [快閃大對決:一場華爾街起義](http://www.anobii.com/books/%E5%BF%AB%E9%96%83%E5%A4%A7%E5%B0%8D%E6%B1%BA/9789866613678/0197b548ea6d2f7659)
==[投影片](https://drive.google.com/file/d/0B5GW0aIORHIBUjVvUXJ2NVhPckU/view?ths=true): ARM processor==
**Evolution of ARM**
介紹 ARM 的起源、發展以及獲利模式 (賣 IP,矽智財),以及 Linaro 公司,後者致力加速 ARM 平台相關的開放原始碼專案,由 ARM、Freescale 也就是現在的 NXP、TI 等公司出錢出力發起 。
A history of ARM
* [part 1: Building the first chip](https://arstechnica.com/gadgets/2022/09/a-history-of-arm-part-1-building-the-first-chip/)
* [part 2: Everything starts to come together](https://arstechnica.com/gadgets/2022/11/a-history-of-arm-part-2-everything-starts-to-come-together/)
* [part 3: Coming full circle](https://arstechnica.com/gadgets/2023/01/a-history-of-arm-part-3-coming-full-circle/)
**Evolution of the ARM ISA**
到目前為止,ARM 共 8 種 ISA 版本,也就是 ARMv1 ~ ARMv8。其中 ARMv1 和 ARMv2 位址範圍只到 26 bits,自 ARMv3 開始則採用了 32 bits 位址範圍,也因此在這份投影片中,將以 ARMv3 作為 ARM 基本 ISA (ARM’s basic ISA) 來進行演化的討論。
基本上 ARM 處理器具有 16 個 32 bit 長度的暫存器,其中有 13 個為 _通用暫存器 (General Purpose Registers, GPRs)_ , R13-R15 則有其他用途。

R13 通常會被用來當作堆疊指標 (Stack Pointer, SP),在實際使用中,一般會在記憶體分配一些空間作為堆疊,系統初始化時將這一塊堆疊的底部位址儲存到 R13 。
R14 為 連結暫存器 (Link register, LR) ,用來存放副程式的返回地址,比如我們在組語中呼叫到了 BL、BLX 等指令時,會將 PC 的數值複製到 R14 中,作為反還 (return) 的位址,具體範例如下。
R15 則是程式計數器(Program Counter, PC),用來存放下一道指令的位址,根據 [ARM7TDMI Technical Reference Manual](http://infocenter.arm.com/help/index.jsp?topic=/com.arm.doc.ddi0210c/ch02s06s01.html)
, R15 在 ARM 或是 Thumb 模式下狀況不同
* ARM 模式 (ARM state)
* bits [1:0] 未定義且會被忽略, bits [31:2] 保留了 PC 數值
* Thumb 模式 (Thumb state)
* bit [0] 未定義且被忽略, bits [31:1] 保留了 PC 數值
除了上面的基礎 ISA 外,ARM 根據不同的狀況增加了許多種 ISA 的擴充,比如在 Java 很火紅的年代,為了提昇 JVM 執行的效率,而引入了 [Jazelle 指令集](https://en.wikipedia.org/wiki/Jazelle) ,用來加速 Sun Microsystems 定義的 Java bytecode 執行。不過 Android 的 Dalvik/ART 不採用 Java bytecode (stack-based),而是使用自行定義的 register-based 指令,這使得 Jazelle 指令集對 Dalvik/ART 的加速沒有任何效果,自然形同雞肋。
各個不同的 ARM 版本對應的擴充指令集架構資訊如下:

而這些 ISA 擴充架構則又可以分為兩組:
* 通用暫存器 (General Purpose Registers, GPRs)
* FP (Floating Point) 和 Advanced SIMD (NEON)

* SIMD extension
我們先來看 SIMD (Single Instruction Multiple Data) extension, 他其實是透過通用暫存器 (General Purpose Registers, GPRs) ,也就是 R0 ~ R12 這 13 個 32-bit 暫存器所組成,這項擴展自 [ARMv6](http://lars.nocrew.org/computers/processors/ARM/ARMv6.pdf) 引入 ,但是由於效能提昇有限,自 ARMv7 後被 Advanced SIMD, 也就是我們說的 NEON 所替代掉。
此外,早期的 ARM 處理器並沒有負責處理浮點數運算的功能,因此浮點數的運算就必須透過 CPU 來進行處理,對於越來越多的浮點數要求 (影像處理、音訊、遊戲等等) 若沒有額外的計算輔助,則 CPU 會耗費非常多的時間進行浮點數的運算,為了解決這個問題,ARM 加入了 VFP (Vector Floating Point) 這種透過協同處理器來輔助計算浮點數的應用。
VFP (Vector Floating Point) 指令集擴充可以分兩個部份來討論,一個是自 ARMv5 引入的 VFPv1/VFPv2 ,另外一個則是自 ARMv6 引入的 VFPv3/VFPv4。

VFPv1/v2 自 ARMv5 引入,具有 32 個 VFP 暫存器,並可分成四個暫存器庫區(Register Banks),每一區具有 8 個 VFP 暫存器,如下圖

從上圖我們可以看到,在 VFPv1/v2 中,第一個暫存器庫區 (Register Banks) 存放了純量 (Scalar) 運算元,剩下的三區則是存放向量 (Vector) 運算元。和 SIMD (Single Instruction Multiple Data) 不同的是,向量是依序 (sequential) 處理,而不是像 SIMD 那樣同步進行。
如同名稱一樣,VFPv3/v4 是 VFPv1/v2 的延伸,自 ARMv6 開始引入。和 VFPv1/v2 不同的是,VFPv3/v4 的 VFP 暫存器變成 64 bit 暫存器,並增加了一些指令協助 FX (Fixed Point) 與 FP (Floating Point) 之間的轉換。
NEON 指令集自 ARMv7 引入,為 64/128-bit SIMD (Single Instruction Multiple Data) extension。NEON 指令集被設計用來補足日益興盛的影像編碼/解碼、2D/3D 圖像處理、遊戲、影像處理等功能。
為何這類用途需要額外的指令集去處理?以影像處理為例,影像的處理其實就是透過遮罩(mask)去對2維影像陣列進行捲積(convolution)的運算,就像這樣 ([圖片來源](https://developer.apple.com/library/prerelease/content/documentation/Performance/Conceptual/vImage/ConvolutionOperations/ConvolutionOperations.html))

對於這種運算,我們是可以同時對陣列(vector)的各個元素進行處理的,也就是這些運算可以平行處理(parallel),可以加快運算速度。
順道一題,[SIMD](https://en.wikipedia.org/wiki/SIMD) (Single Instruction Multiple Data) 這種運算模式也是費林分類法([Flynn’s Taxonomy](https://en.wikipedia.org/wiki/Flynn%27s_taxonomy)) 中的一種運算結構。

若以 NEON 指令集的命令來看,`VADD.I16 Q0, Q1, Q2` 這樣的指令,會執行一個平行的陣列加法,將 Q1 以及 Q2 各元素的運算結果存放到 Q0 中。 ([圖片來源](http://infocenter.arm.com/help/index.jsp?topic=/com.arm.doc.dht0002a/BABIIFHA.html))

## ARM NEON 案例分析
給定每個像素 (pixel) 為 32-bit 的 RGBA 的位元圖 (bitmap),RGBA 代表紅綠藍三原色的首字母,Alpha 值則表示顏色的透明度/不透明度,其轉換為灰階影像 (gray scale) 的函式為:
```cpp
void rgba_to_bw(uint32_t *bitmap, int width, int height, long stride) {
int row, col;
uint32_t pixel, r, g, b, a, bw;
for (row = 0; row < height; row++) {
for (col = 0; col < width; col++) {
pixel = bitmap[col + row * stride / 4];
a = (pixel >> 24) & 0xff;
r = (pixel >> 16) & 0xff;
g = (pixel >> 8) & 0xff;
b = pixel & 0xff;
bw = (uint32_t) (r * 0.299 + g * 0.587 + b * 0.114);
bitmap[col + row * stride / 4] = (a << 24) + (bw << 16) + (bw << 8) + (bw);
}
}
}
```
人類視網膜包含三類錐形對光敏感的細胞,分別對不同波長範圍的光有反應:

> 上圖中的縱軸代表人眼對某對應波長的光的敏感度。其中 1 Å (埃) = $10^{–10}$ 米 = **0.1 nm** [[出處](http://www.phy.ntnu.edu.tw/demolab/html.php?html=everydayPhysics/color)]
人眼吸收綠色比其他顏色敏感,也可說人眼最容易捕捉到綠色,所以當影像變成灰階時,僅僅將紅色、綠色、藍色加總取平均,不足以反映出人眼所見。常見的方法是將 $Red \times 77, Green \times 151, Blue \times 28$,這三個除數的總和為 `256` (即 $2^8$),可使除法變簡單 (等同於右移 8 位元)。
請提出效能改善的方案:
* 建立表格加速浮點數操作 (L1 cache?)
* 減少位移數量
Hint: 考慮以下寫法
```cpp
bwPixel = table[rgbPixel & 0x00ffffff] + rgbPixel & 0xff000000;
```
$\to$ 16 MB; 表格太大
Hint: 如果先計算針對「乘上 0.299」一類的運算,先行計算後建立表格呢?
```cpp
bw = (uint32_t) mul_299[r] + (uint32_t) mul_587[g] + (uint32_t) mul_144[b];
bitmap[col + row * strike / 4] = (a << 24) + (bw << 16) + (bw << 8) + bw;
```
$\to$ 降到 32 KB 以內; cache friendly
**目前實作的程式碼**:[embedded-summer2015 / RGBAtoBW](https://github.com/charles620016/embedded-summer2015/tree/master/RGBAtoBW)
> 個別函式在 [bmp.c](https://github.com/charles620016/embedded-summer2015/blob/master/RGBAtoBW/bmp.c)
BMP (BitMaP) 檔是是很早以前微軟所開發並使用在 Windows 系統上的圖型格式,通常不壓縮,不像 JPG、GIF、PNG 會有破壞性或非破壞性的壓縮。雖然 BMP 缺點是檔案非常大,不過因為沒有壓縮,即使不借助 OpenCV, ImageMagick 或 .NET Framework 等等,也可以很容易地直接用 Standard C Library 作影像處理。
BMP 主要有四個部份組成
1. Bitmap File Header:Magic Number ('BM')、file size、Offset to image data
2. Bitmap Info Header:image width and height、the number of bits per pixel、Compression type
3. Color Table (Palette)
4. Image data

* 未優化版本:
以下是我使用一張 1920x1080 的 BMP 圖片所印出來的資訊
```
==== Header ====
Signature = 4D42
FileSize = 8294456
DataOffset = 54
==== Info ======
Info size = 40
Width = 1920
Height = 1080
BitsPerPixel = 32
Compression = 0
================
RGBA to BW is in progress....
Save the picture successfully!
Execution time of rgbaToBw() : 0.034494
```

$\to$ 執行時間:0.034494 sec
* 優化版本:* Version 1
RGB 分別都是 8 bit,可以建立三個大小為 256 bytes 的 table,這樣就不用在每次轉 bw 過程中進行浮點數運算。
* 原本 : bw = (uint32_t) (r * 0.299 + g * 0.587 + b * 0.114);
* 查表 : bw = (uint32_t) (table_R[r] + table_G[g] + table_B[b]);
$\to$ 執行時間:0.028148 sec
* Version 2
使用 pointer 的 offset 取代原本的繁雜的 bitwise operation。
```cpp
uint32_t *pixel = bmp->data;
r = (BYTE *) pixel + 2;
g = (BYTE *) pixel + 1;
b = (BYTE *) pixel;
```
$\to$ 執行時間:0.020379 sec
* Version 3
將上述兩種優化方法合併在一起
$\to$ 執行時間:0.018061 sec
* Version 4 and Version 5
使用 NEON instruction set 來加速,執行環境是 Raspberry Pi 2 (Cortex-A7 x4)。
`CC = gcc-4.8`
`CFLAGS = -O0 -Wall -ftree-vectorize -mcpu=cortex-a7 -mfpu=neon-vfpv4 -mfloat-abi=hard`
* Execution time of rgbaToBw() : 0.353600
* [Version 1 : using RGB table]
* Execution time of rgbaToBw() : 0.319600
* [Version 2 : using pointer]
* Execution time of rgbaToBw() : 0.251800
* [Version 3] : versoin1 + versoin2
* Execution time of rgbaToBw() : 0.226800
* [Version 4] : NEON
* Execution time of rgbaToBw() : 0.016000
* [Version 5] : NEON (unroll loop + PLD)
* Execution time of rgbaToBw() : 0.013200
什麼是 NEON ?
> NEON technology is an advanced **SIMD** (Single Instruction, Multiple Data) architecture for the ARM Cortex-A series processors.
* Registers are considered as **vectors** of **elements** of the same **data type**
* Data types can be: signed/unsigned 8-bit, 16-bit, 32-bit, 64-bit, single precision [floating point](http://www.arm.com/products/processors/technologies/vector-floating-point.php)
* Instructions perform the same **operation** in all **lanes**
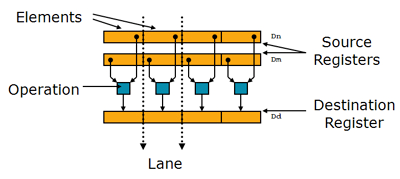
Register :
* 16 x 32-bit general purpose ARM registers (R0-R15).
* 32 x 64-bit NEON registers (D0-D31) OR viewed as 16x128-bit registers (Q0-Q15).
簡言之,有了 NEON instruction set,就可以「同時」操作許多個 8, 16 或 32-bit 的資料,在訊號處理、影像處理、視訊解碼等領域應用廣泛。
首先先看 Version 4 :
將 RGB 三色的 weight 存入 r3 - r5。
`vdup.8` (Vector Duplicate),分別複製到大小為 8 bit 的 NEON register d0 - d2
```cpp
mov r3, #77
mov r4, #151
mov r5, #28
vdup.8 d0, r3
vdup.8 d1, r4
vdup.8 d2, r5
```
`vld4.8` (Vector Load),載入 pixel 的資料到 4 個 8-bit 的 NEON register d4-d7,其中那個 `4` 為 interleave,因為我們有 ARGB,所以 gap = 4。
再來就是計算 weighted average。Vector Multiply 和 Vector Multiply Accumulate
```cpp
@ (alpha,R,G,B) = (d7,d6,d5,d4)
vld4.8 {d4-d7}, [r0]!
vmull.u8 q10, d6, d0
vmlal.u8 q10, d5, d1
vmlal.u8 q10, d4, d2
```
將值除以 256 就是我們要的灰階值。
`vrshrn` (Vector Shift Right by immediate value)
> vrshrn.u16 d4, q10, #8
最後儲存結果。
`vst` (Vector Store)
> vst4.8 {d4-d7}, [r3]!
$\to$ 執行時間:0.016000 sec
從上面瀏覽過一遍用到的 NEON instruction set,就可以發現我們都是一次對多個 NEON register 作操作,下面討論分析有比較圖就可以看出效能差距。
再來看 Version 5
> [Cycle Counter for Cortex A8](http://pulsar.webshaker.net/ccc/index.php) (:warning: 網址掛了)
$\to$ 執行時間:0.013200 sec
* 討論與分析:
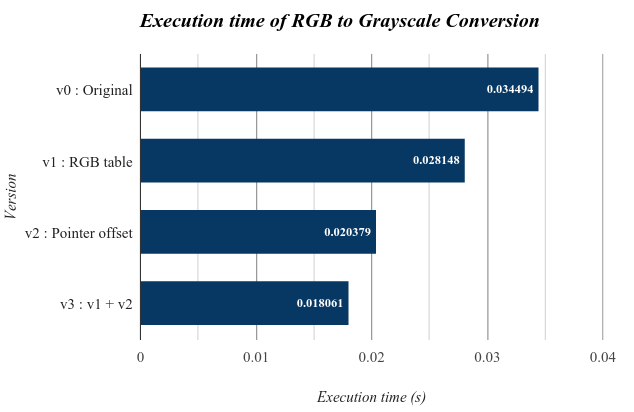
以上各版本執行時間都是 50 次迴圈平均下來的結果,測試檔為 1920x1080 32bit bmp 圖片。可以明顯看到 v2 效能表現比起 v1 來說 還好上許多,可見原始程式中「多次」的 bitwise operation 結果所帶來損耗比起浮點數運算還更多一些。若我們再將浮點數運算改成查表的話,最後時間能進步到 0.018061 secs ,幾乎是原來的一半。
另外使用 perf 效能分析工具來觀察原始版本和 version 3 中 instruction 和 cycle 數量。
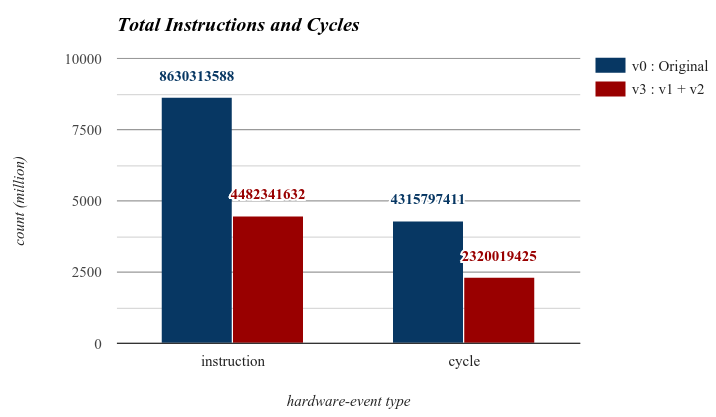
可以看到 version 3 的 instruction 和 cycle 大約都只有原來的一半,這結果也正好反應在上面的執行時間上。
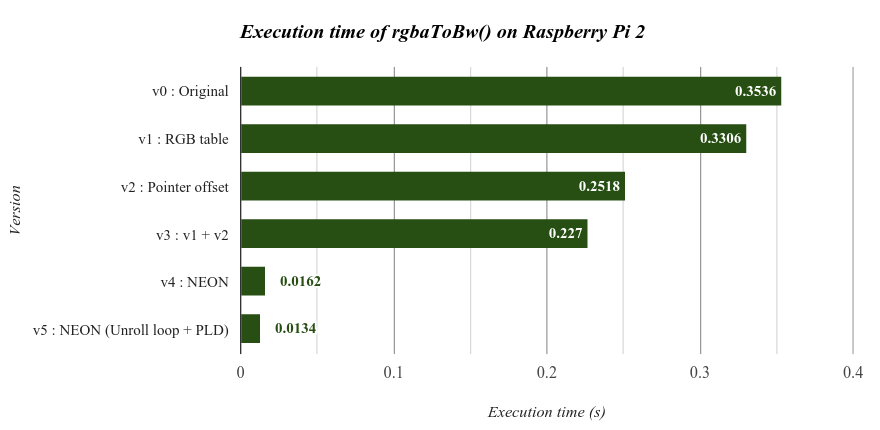
從這張表即可理解,使用 NEON 指令集加速後所得到的效能增長, Version 4 只用原本 4.6% 的時間就完成彩色轉灰階處理。
**Overview of ARM’s processor series**
到目前為止(投影片寫的年代),ARM 系列大致上可以分為以下幾類,這將會在投影片的不同章節來提及

* Processors implementing the ARM v1 - ARM v3 ISA
如同 [Overview](https://embedded2015.hackpad.com/2016-coldnew-L71IxfOsBV7#:h=Overview) 裡面提及的那樣,ARM v1 以及 ARM v2 只有實作 26-bit 位址匯流排(address bus)以及 32-bit的資料匯流排(data bus),也因此,ARM v1 以及 ARM v2 皆屬於 26-bit 的 CPU 結構。
到了 ARMv3 時候狀況就些許不同了,ARM v3 採用了 32-bit 位址匯流排(address bus)以及 32-bit的資料匯流排(data bus),這種 32-bit CPU 架構一直延續到 ARMv7。
ARMv8 開始,CPU 架構則更改為 64-bit。

* Processors implementing the ARM v4 - ARM v6 ISA

自 ARMv4 開始,開始有針對特定需求而增加的延伸指令集。以 ARMv4 增加的 Thumb 指令為例,當時 Nokia 決定採用 ARM 的 IP 後 ,Nokia 為了降低程式碼密度(code density),便派遣不少工程師協助 ARM 建立了 Thumb 指令集 ([出處](https://indianengineeringdesignforum.wordpress.com/2013/12/06/what-made-arm-a-successful-company/))
> Initially Nokia worried about ARM’s code density, which was quite poor. This translated to more memory and hence higher cost. ARM engineers listened to Nokia and got thinking. This was how the more memory efficient THUMB architecture was born. Likewise, TI wanted the ARM core on a smaller die size. ARM engineers initially believed this to be impossible. TI engineers knew that the goal was realistic. When ARM engineers achieved what they had thought was impossible, they got a fat bonus.
而其他的 ISA 也是有相應的理由才逐步發展,比如前文提到的 [Jazelle 指令集](https://en.wikipedia.org/wiki/Jazelle) 就是用來協助增強 Java bytecode 運算的速度/佔用空間,畢竟在當時的手機,也就是我們稱為傻瓜手機(傳統手機)的時代,Java ME (J2ME) 的遊戲一度非常盛行。
* [Introduction to ARM Architecture](https://docs.google.com/presentation/d/1cFBRICktpVQAOLzE5eDKD-OM4ckJuncFsn39Wg8aLZI/edit#slide=id.p14)
* [ARM Architecture](http://www.csie.ntu.edu.tw/~cyy/courses/assembly/12fall/lectures/handouts/lec08_ARMarch.pdf)
 Sign in with Wallet
Sign in with Wallet







