# FIPA Over Linda
[Emiliano Ciavatta](mailto:emiliano.ciavatta@studio.unibo.it), [Stefano Righini](mailto:stefano.righini@studio.unibo.it), [Luca Tremamunno](mailto:luca.tremamunno@studio.unibo.it)
### Sommario
Lo scopo del progetto è quello di estendere una minimale implementazione di un framework ad agenti fornendo supporto per i [protocolli di interazione](http://www.fipa.org/repository/ips.php3) proposti da [FIPA](http://www.fipa.org/).
FIPA è una fondazione che ha l’obiettivo di proporre standard per permettere a sistemi multiagente di interagire attraverso lo scambio di messaggi. Le regole che stabiliscono come deve essere effettuata una comunicazione sono definite attraverso i protocolli di interazione. Il modello di coordinazione utilizzato per la memorizzazione dei messaggi è Linda, che permette agli agenti di comunicare tramite uno spazio di tuple condiviso. Per la realizzazione del progetto si utilizzeranno spazi di tuple logiche, utilizzando il linguaggio logico Prolog per rappresentare le tuple e i template. Per sfruttare il modello di coordinazione Linda in un sistema multiagente si sceglierà di utilizzare il servizio di coordinazione TuSoW (Tuple Spaces over the Web). Tramite questo servizio di coordinazione sarà possibile far interagire agenti presenti sullo stesso ambiente o su ambienti diversi tramite API ReST attraverso il protocollo HTTP.
## Obiettivi
L'obiettivo del progetto è quello di estendere il framework per programmazione ad agenti realizzato in laboratorio aggiungendo una forma di supporto per i messaggi ACL e protocolli di interazione specificati da FIPA. I messaggi specificati da FIPA nella Communicative Act Library forniscono agli agenti un modo standardizzato per interagire, permettendo ad esempio di effettuare richieste o interrogare altri agenti. Questi messaggi possono essere utilizzati in maniera indipendente, oppure nel contesto di un protocollo di interazione che definisce le regole per lo scambio di una serie di messaggi tra due o più agenti.
Lo scambio dei messaggi deve avvenire per mezzo di spazi di tuple utilizzando il modello di coordinazione Linda. Nello specifico si utilizzeranno gli spazi di tuple logici e l'implementazione TuSoW.
Sarà quindi necessario implementare Behaviours per permettere agli utenti di inviare e ricevere messaggi ACL verso/da spazi di tuple. Sarà necessario realizzare delle classi rappresentanti i messaggi in modo da consentirne la costruzione e l'utilizzo nascondendo i dettagli relativi alla loro rappresentazione come termini Prolog; in maniera analoga sarà necessario costruire astrazioni dei template che consentano il recupero di messaggi con determinate caratteristiche da uno spazio di tuple.
Infine sarà necessario realizzare i *behaviour* per permettere agli agenti di iniziare o partecipare a protocolli di interazione. Questi *behaviour* dovranno gestire gli aspetti di basso livello per quanto riguarda il protocollo, lasciando all'utente il solo compito di specificare i comportamenti strettamente correlati al sistema che esso deve realizzare. Questo significa che i *behaviour* realizzati nel framework gestiranno ad esempio gli aspetti relativi alla creazione, invio e ricezione dei messaggi, mentre l'utente dovrà specificare il loro contenuto e le istruzioni da eseguire a seguito della ricezione di determinati messaggi.
### Scenari d'uso
Il progetto che si intende realizzare è un framework per programmazione ad agenti che fornisce supporto per la comunicazione tra due o più agenti tramite i protocolli di interazione definiti da FIPA. Le specifiche di ciascun protocollo sono standard descritte dettagliatamente in [FIPA Interaction Protocol Specifications](http://www.fipa.org/repository/ips.php3).
Questo framework può quindi essere utilizzato nelle situazioni in cui si vogliono realizzare sistemi ad agenti che comunicano in maniera standardizzata.
Di seguito sarà riportata brevemente la descrizione di ciascun protocollo di interazione che si è deciso di implementare, in modo da dare panoramica sui possibili usi delle interazioni.
- **Request Interaction Protocol**: consente ad un agente di chiedere ad un altro agente di eseguire un'azione
- **Query Interaction Protocol**: permette ad un agente di chiedere informazioni ad un altro agente
- **Request When Interaction Protocol**: consente ad un agente di chiedere ad un altro agente di eseguire un'azione nel momento in cui una data precondizione diventa vera
- **Contract Net Interaction Protocol**: un agente (iniziatore) vuole assegnare dei compiti ad altri agenti (partecipanti) ottimizzando il costo da sostenere per raggiungere lo scopo. Non tutti gli agenti contattati possono accettare la proposta
- **Iterated Contract Net Interaction Protocol**: come il protocollo descritto sopra con l'aggiunta di una fase iterativa di contrattazione
- **Brokering Interaction Protocol**: un agente (broker) offre servizi di facilitazione della comunicazione con altri agenti utilizzando alcune conoscenze sui requisiti e sulle capacità di tali agenti. Lo scambio di messaggi tra il broker e gli agenti avviene in maniera trasparente dal punto di vista dell'iniziatore
- **Recluiting Interaction Protocol**: analogo al caso di brokering con la differenza che i messaggi inviati dagli agenti contattati dal broker vengono recapitati direttamente all'iniziatore
- **Subscribe Interaction Protocol**: permette ad un agente di richiedere ad un altro agente di essere informato ogniqualvolta che lo stato di un oggetto referenziato cambia
- **Propose Interaction Protocol**: consente ad un agente di proporre un'azione ad un altro agente che può scegliere se rifiutare o accettare
### Politica di autovalutazione
Gli scenari d'uso sopra descritti serviranno, oltre ad indicare all'utente come utilizzare ed interagire con il sistema, a realizzare un framework robusto durante il suo sviluppo. I requisiti funzionali e non funzionali che il software dovrà soddisfare per essere considerato robusto verranno discussi nella sezione seguente, nell'analisi dei requisiti.
Per implementare il progetto verrà utilizzato il linguaggio di programmazione Java. Il linguaggio Java non offre supporto per la creazione di propri DSL, che sarebbero stati utili in questo contesto. Utilizzando però funzionalità avanzate del linguaggio come generici e stream sarà possibile realizzare API di qualità. Dove possibile dovranno essere progettate API fluenti che permetteranno di utilizzare il framework con un approccio più rivolto al funzionale che all'imperativo. Non verranno utilizzati strumenti automatici per il controllo della qualità del software.
Per raggiungere i requisiti preposti si sceglie di adottare uno sviluppo agile del software. In particolare si è deciso di seguire un approccio di tipo *Test Driven Development*. Il principale motivo per cui si è scelta questa metodologia di lavoro è quello di implementare i protocolli di interazione a partire da ciascun caso d'uso. Grazie all'analisi approfondita delle specifiche si è riusciti a stabilire sin da subito che cosa ciascun protocollo di interazione dovrà fare piuttosto che come dovrà essere realizzato.
## Analisi dei requisiti
Il software che si intende realizzare è un framework ad agenti che deve essere di supporto all'utente per implementare i protocolli di interazione standardizzati da FIPA. Per la realizzazione del progetto si utilizza il paradigma di programmazione orientato ad agenti (_Agent-oriented programming_). Gli agenti saranno il cuore del framework e saranno utilizzati come componente attiva per la realizzazione dei protocolli di interazione tramite comportamenti, i cosiddetti _behaviours_. Nel caso specifico tramite il framework dovrà essere possibile realizzare un sistema distribuito. Ciascun agente dovrà poter essere eseguito su una qualsiasi macchina e potrà far parte di un ambiente personale o condiviso. Il sistema che si dovrà mettere in atto sarà quindi un sistema multiagente.
Per la realizzarazione dei protocolli di interazione si utilizza il modello di coordinazione Linda, che permette agli agenti di comunicare tramite uno spazio di tuple condiviso. Lo spazio di tuple è un sistema di memorizzazione costituito da un insieme di tuple che costituiscono i dati. In particolare per la realizzazione di questo progetto si utilizzano spazi di tuple logici, utilizzando Prolog come linguaggio di comunicazione che specifica il formato di rappresentazione delle tuple. Anche i _template_, che sono strutture dati che permettono di effettuare query sullo spazio di tuple, sono definiti utilizzando il linguaggio di programmazione logico Prolog.
Per sfruttare il modello di coordinazione Linda in un sistema multiagente si sceglie di utilizzare il servizio di coordinazione TuSoW (Tuple Spaces over the Web). Tramite questo servizio di coordinazione sarà possibile far interagire agenti presenti sullo stesso ambiente o su ambienti diversi tramite API ReST attraverso il protocollo HTTP. Questo livello di astrazione permette di realizzare il sistema multiagente senza che sia necessario dover gestire il canale di trasporto.
### Requisiti impliciti
- Sarà necessario riadattare il modello ad agenti precedentemente implementato per soddisfare i nuovi requisiti di progetto
- Occorrerà inserire template logici a cui possono essere aggiunti vincoli. In questo modo sarà poi possibile effettuare query più complesse con più vincoli di selezione al motore Prolog, utilizzato dal modello di coordinazione
- Sarà necessario implementare una struttura statica per poter successivamente implementare i protocolli di interazione proposti da FIPA. In particolare occorrerà:
- Definire la struttura dei messaggi ACL, ovvero i messaggi elementari e primitivi presentati da FIPA
- Definire la struttura dei template che dovranno servire per filtrare i messaggi ACL nello spazio di tuple logico
- Realizzare le operazioni di marshalling e unmarshalling per poter trasportare sia i messaggi ACL sia i template in un canale di trasporto. In particolare dovranno poter essere serializzati in termini logici per permettere agli agenti di interfacciarsi con _TuSoW_
### Osservazioni
- Per supportare i protocolli di interazione definiti da FIPA è sufficiente definire soltanto due operazioni primitive: l'operazione di invio dei messaggi ACL e l'operazione di ricezione di messaggi ACL definita tramite selezione di parametri attraverso i template
- Sarà necessario quindi cercare il corretto compromesso per:
- Lasciare all'utente più libertà possibili per implementare i protocolli di interazione senza inserire vincoli imponenti che potrebbero minare sull'usabilità del framework
- Inserire implementazioni astratte dei protocolli di interazione per facilitare l'utente fornendogli linee guida. In questo modo l'utente potrà utilizzare direttamente il framework per i casi d'uso più comuni senza che sia necessario implementare manualmente i protocolli di interazione seguendo le specifiche FIPA
- L'introduzione di vincoli nei template potrebbero causare problemi nello spazio di tuple quando deve essere effettuata un'operazione di _retract_ tramite il motore Prolog, necessaria ad esempio per realizzare la funzione di Linda _take_
- Sarà necessario quindi revisionare l'attuale implementazione dello spazio di tuple logico per permettere di realizzare template più complessi
### Requisiti non funzionali
- Siccome il software da realizzare sarà un framework estendibile dall'utente, sarà necessario realizzare API minimali, concise e autoesplicative. Deve essere lasciato all'utente la possibilità di implementare soltanto le parti minimali per realizzare qualsiasi protocollo di interazione, fornendo implementazioni predefinite dove possibile
- Dovrà essere sfruttata al massimo la proprietà di modularità e riutilizzo del codice. Molti protocolli di interazione hanno parti in comune che dovranno essere generalizzate per una maggiore velocità di implementazione e di testing
- Il problema dell'efficienza non sarà criterio principale di questo progetto. Occorrerà però gestire in maniera efficiente le risorse dato che lo scambio di messaggi avviene via rete
- Il numero degli agenti che possono partecipare in un ambiente non deve considerarsi un vincolo. Il sistema distribuito quindi dovrà avere le caratteristiche di un sistema scalabile
## Design
Lo scopo del progetto è quello di estendere il framework per programmazione ad agenti sviluppato durante le lezioni, quindi la struttura degli agenti è rimasta la stessa. Di seguito si indicano alcune caratteristiche e la struttura generale del sistema.
Un agente è un'unità di computazione autonoma che esegue delle attività specificate tramite dei `Behaviour`. Ciascun agente appartiene ad un `Environment` che fornisce l'`ExecutorService` su cui i suoi agenti vengono eseguiti.
Un agente si può trovare in vari stati, raffigurati nel seguente diagramma:
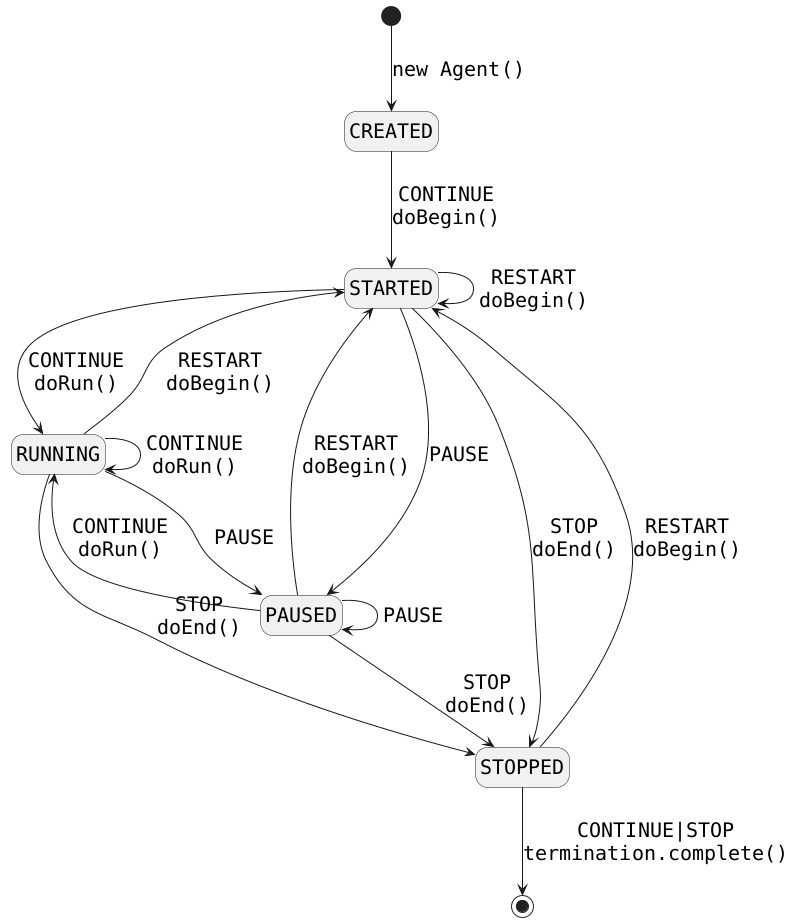
Un agente nello stato `RUNNING` eseguirà ciclicamente i suoi `Behaviour`, e se nessun behaviour è disponibile per l'esecuzione l'agente cambierà il proprio stato in `PAUSED`. Lo stato di un agente può essere modificato anche tramite il proprio `AgentController` che permette ad esempio di avviare o fermare l'agente.
I `Behaviour` specificano le attività che deve svolgere l'agente tramite il metodo `execute`. Questo può essere eseguito solo se il metodo `isPaused` restituisce `false`, e potrebbe essere necessario che venga chiamato più volte prima che il `Behaviour` sia considerato terminato (`isOver` restituisce `true`). È opportuno che il metodo `execute` dei `Behaviour` non effettui computazioni bloccanti o estremamente lunghe, in quanto queste non solo bloccherebbero il flusso di controllo dell'agente che lo esegue, ma anche quello degli altri agenti che condividono lo stesso `Environment` e quindi lo stesso `ExecutorService`.
Infine ad ogni `Environment` sono associati degli spazi di tuple; nel caso specifico del `DistributedEnvironment` questi utilizzano TuSoW: ad ognuno di questi environment è associata un'istanza di TuSoW che fornisce una API REST per l'utilizzo degli spazi di tuple, permettendone quindi l'utilizzo anche da remoto.
### Agent Communication Language
Per gli Agent Communication Language è stato creato un package dedicato per meglio suddividere ed organizzare il software. Questi rappresentano il formalismo utilizzato per i messaggi scambiati tra i vari agenti, definito dal protocollo FIPA. Per la realizzazione si sono utilizzate le specifiche del protocollo sia per la [struttura dei messaggi](http://www.fipa.org/specs/fipa00061/SC00061G.html) che per i tipi dei parametri. Per quest'ultimi si sono rispettati i tipi definiti dallo standard FIPA per la [rappresentazione dei messaggi](http://www.fipa.org/specs/fipa00070/SC00070I.html).

#### ACL Message
I messaggi ACL sono scambiati dai vari agenti nel protocollo FIPA.
Questi messaggi sono composti da molteplici parametri, tra questi i più importanti e obbligatori sono:
- performative: il tipo di messaggio
- sender: il mittente
- receiver: i destinatari che lo riceveranno
Nel seguente diagramma delle classi i messaggi sono identificati dall'interfaccia `LogicAclMessage` che permette di accedere ad ogni parametro del messaggio. Il sender ed ogni receiver vengono identificati come `AgentIdentifier`. Ogni messaggio deve contenere un solo sender ed uno o più receiver. I messaggi ACL sono serializzabili in termini Prolog, infatti l'interfaccia `LogicAclMessage` estende `PrologSerializable`. I messaggi contengono tutti i parametri specificati dal protocollo FIPA. Inoltre l'utente può aggiungere ulteriori parametri in modo da specificare altre informazioni non previste dal protocollo, ma che si ritiene siano importanti e utili al ricevente. Questi saranno inseriti nel parametro "user-defined-parameters" previsto dal protocollo FIPA. Si è scelto di utilizzare i termini Prolog come tipo di dato per i parametri di tipo espressione in modo da mantenere il più possibile un parallelismo con le specifiche FIPA.

##### Creazione
Per la creazione di messaggi ACL si è deciso di utilizzare il pattern builder semplificandone il processo in quanto questi messaggi presentano molti parametri. L'interfaccia `LogicAclMessageBuilder` contiene tutti i metodi necessari per poter impostare i parametri desiderati per un determinato messaggio; inoltre estende l'interfaccia `Builder` che mette a disposizione un metodo `build` che effettuerà la creazione vera e propria. Si è deciso di aggiungere tramite la classe `AclMessages` una factory che permetta di creare un builder vuoto e degli ACL message a partire da un termine Prolog. Inoltre partendo da un messaggio può essere creato un messagio di risposta con alcuni parametri già impostati recuperabili dal messaggio ricevuto. La classe `LogicAclMessageBuilderImpl` che realizza l'implementazione del builder è quindi interna al package grazie a questa factory. In questo modo si è incapsulata la creazione dei messaggi. La generalità con cui sono stati sviluppati i messaggi permette all'utente di specificare i parametri in modo completamente libero nel rispetto dei vincoli di FIPA. Pertanto è stato reso possibile specificare tutti i parametri di tipo espressione sia come stringhe che come termini Prolog. Sarà poi il builder, nell'esecuzione del metodo `build`, ad occuparsi di verificare se il messaggio ha i parametri necessari e rispetta le specifiche FIPA.

##### Serializzazione in Prolog
I messaggi ACL possono essere serializzati in termini Prolog e, viceversa, è possibile creare un messaggio a partire da un termine Prolog eseguendo quindi una deserializzazione. Per la serializzazione viene creata una struttura di nome `aclMessage` i cui argomenti saranno i parametri del messaggio. Per ogni parametro del messaggio si crea un ulteriore struttura il cui nome sarà il nome del parametro stesso, e contentente un singolo argomento che sarà il suo valore. Un problema è stato serializzare i parametri del messaggio non valorizzati, si è deciso di creare termini Prolog che rappresentassero dei termini opzionali. Questo è stato applicato a tutti i parametri che possono essere omessi o non avere un valore. Per ogni parametro opzionale il valore sarà contenuto in una struttura di nome "some" se presente oppure sarà rappresentato da una struttura di nome "none" senza argomenti. Le collezioni non sono considerate opzionali e, nel caso siano vuote, vengono codificate come lista vuota.
Per meglio chiarire il modo in cui verranno formattati i termini Prolog vengono fornite le rappresentazioni sottoforma di stringa dei termini Prolog:
- parametro obbligatorio: `nome(valore)`;
- parametro opzionale: `nome(some(valore))` oppure `nome(none)`;
- parametro con lista: `nome([elem_1 .. elem_n])` oppure `nome([])`.

##### Contenuto
Un parametro dei messaggi è `content` che contiene il contenuto del messaggio. Quest'ultimo può essere espresso nel linguaggio che si preferisce, il quale va specificato nel parametro `language`. Inoltre è possibile codificare il contenuto per mezzo di un codificatore il quale dovra essere specificato nel parametro `encoding`. Questi tre parametri vanno inseriti nel messaggio dal `sender`. Con questa organizzazione è quindi possibile specificare un linguaggio a scelta e allo stesso modo una codifica. Utilizzando la codifica *base64* il contenuto *"contenuto di prova"* sarà trasformato in *"Y29udGVudXRvIGRpIHByb3Zh"*.
#### Agent identifier
Gli agent identifier sono utilizzati per identificare un agente durante l'esecuzione di un protocollo di interazione di FIPA. Sono identificati da un nome univoco nel sistema che si sta considerando. Nel diagramma sottostante vengono realizzati per mezzo dell'interfaccia `AgentIdentifier` che viene realizzata, internamente al package, dalla classe `AgentIdentifierImpl`.

##### Creazione
Per creare un agent identifier è stato adottato il pattern factory, che viene realiizato dalla classe `AgentIdentifiers`. Quest'ultima mette a disposizione diversi metodi i quali permettono una creazione veloce e con i parametri necessari. L'unico parametro obbligatorio è il nome che verrà utilizzato come identificativo. In questo modo la creazione è ben incapsulata e, all'esterno del package viene fornita solo l'interfaccia mantenendo l'implementazione restituita interna.

##### Serializzazione in Prolog
Gli agent identifier possono essere serializzati in termini Prolog. Questo si è reso necessario perchè alcuni parametri degli ACL message sono degli agent identifier e quindi era necessario che anche quest'ultimi potessero essere serializzati. Il tutto è stato incaspulato all'interno del package in quanto l'unico caso di utilizzo è appunto per la serializzazione e deserializzazione dei messaggi. Per i parametri si è seguita la stessa logica di serializzazione applicata ai messaggi ACL. In questo caso non essendoci parametri opzionali (eccetto possibili collezioni vuote) non vengono utilizzate le strutture opzionali. Nel caso in cui in futuro si presenti la necessità sarà possibile definire quali parametri sono opzionali e questi verranno automaticamente codificati come tali, utilizzando il sistema precedentemente spiegato.

#### ACL Message Template
I messaggi memorizzati nello spazio di tuple logico devono poter essere letti o estratti tramite le operazioni di Linda _read_ e _take_. Queste operazioni necessitano un template che deve servire per selezionare uno o più messaggi disponibili nell'insieme delle tuple in base a criteri di selezione. Tramite gli ACL Message Template dovrà essere quindi possibile selezionare uno specifico messaggio presente nello spazio di tuple che abbia delle caratteristiche prefissate.
Utilizzando uno spazio di tuple logico come modello di coordinazione e memorizzazione delle informazioni occorre che anche i template siano realizzati rispettando il paradigma di programmazione logico. I template dovranno quindi essere poter costruti come termini Prolog.
Per effettuare operazioni di selezione complesse sulle tuple occorre utilizzare espressioni estese al momento della costruzione dei termini Prolog. Il progetto da cui si è partiti non prevede l'utilizzo di vincoli aggiuntivi alla creazione di template logici, è necessario quindi estendere il framework per permettere di realizzare query complesse. Il modo in cui il framework verrà esteso per permettere questa funzionalità verrà descritto successivamente nella sezione dei _Template logici_.
Gli ACL Message Template saranno realizzati tramite API fluenti per assicurare una maggiore usabilità durante la costruzione di template logici. L'interfaccia che permetterà la creazione dei template per i messaggi ACL sarà `LogicAclMessageTemplate`, il cui diagramma UML è riportato in figura sotto. Tramite questa API sarà possibile filtrare i messaggi dallo spazio di tuple per selezionare il messaggio desiderato. I criteri di selezione saranno relativi soltanto ad un sottoinsieme di campi dei messaggi ACL perché per alcuni campi la selezione perdeva significato. I campi in cui si possono aggiungere vincoli di selezione sono:
- **performative**: utile per selezionare soltanto i messaggi con una data intenzione
- **sender**: fondamentale per filtrare per mittente per assicurare corrispondenza
- **receivers**: serve per selezionare i messaggi che contengono come destinatario gli agenti interessati
- **inReplyTo**: utile per filtrare messaggi in risposta ad un messaggio precedente
- **protocol**: serve per selezionare i messaggi che utilizzano un determinato protocollo
- **conversationId**: fondamentale per cercare messaggi in una conversazione già avviata
- **userDefinedParameters**: utile per filtrare in base ad altri criteri definiti dall'utente
I criteri di selezione con cui è possibile filtrare uno dei campi elencati sopra sono molteplici:
- cercare l'esatta corrispondenza (es. `performative(single_value)`)
- trovare un messaggio che abbia la proprietà specificata in un insieme di valori (es. `performativeAny(Set.of(value1, value2, ...))`)
- cercare un messaggio che abbia una proprietà diversa da quella indicata (es. `performativeNot(single_value)`)
- stabilire che una proprietà contenga un insieme di valori (es. `receiverContains(Set.of(value1, value2))`)
- cercare un messaggio che abbia una proprietà *non* definita, se opzionale (es. `protocolEmpty()`)
- cercare un messaggio che abbia una proprietà definita, se opzionale (es. `protocolDefined()`)
Gli argomenti nei metodi di selezione possono essere specificati attraverso `Term` (termini Prolog) o stringhe.

#### Agent Identifier Template
Nei vincoli di selezione che riguandano il mittente (`sender`) e i destinatari (`receivers`) è necessario specificare come argomento di selezione un template per gli identificatori d'agente. I template per gli Agent Identifier sono anch'essi logici e sono analoghi ai messaggi ACL.
L'interfaccia che fornisce le API fluenti per la creazione degli Agent Identifier Template e per il loro utilizzo è definita come `LogicAgentIdentifierTemplate`. I criteri di selezione sono gli stessi dei template per i messaggi ACL descritti in precedenza. I campi in cui si possono specificare vincoli di selezione sono:
- **name**: il nome dell'agente da selezionare
- **addresses**: gli indirizzi che indicano l'URI dal quale l'agente può essere raggiunto
- **userDefinedParameters**: utile per filtrare in base ad altri criteri definiti dall'utente
Di seguito è mostrato il diagramma delle classi di `LogicAgentIdentifierTemplate`.

### Template logici
Per poter fornire maggior controllo sulle operazioni di *read* e *take* è stato necessario realizzare un nuovo tipo di template logico che permettesse di utilizzare espressioni Prolog più complicate rispetto a quelle consentite dal template originale.
Il logic template di TuSoW permette solo di specificare vincoli relativamente alla struttura della tupla: si possono ad esempio realizzare i template `a(b)` o `a(X)`, dove `X` può essere un qualunque termine, ma non è possibile realizzare un singolo template che permetta di recuperare le tuple della forma `a(X)` dove `X` è `b` o `c`.
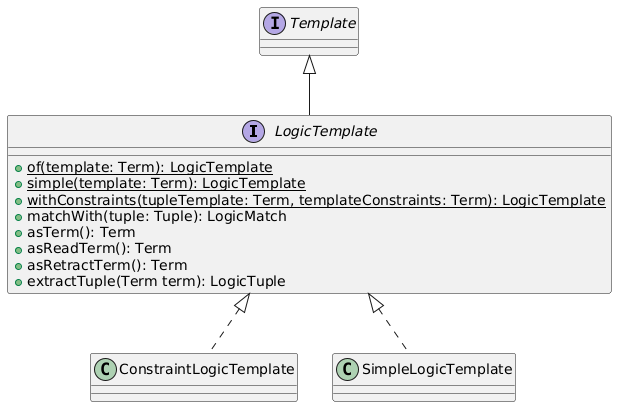
Si è quindi deciso di realizzare una versione di `LogicTemplate` composta da due parti: una prima parte specifica i vincoli relativi alla struttura della tupla da recuperare, mentre la seconda parte può essere una qualsiasi espressione Prolog, permettendo ad esempio all'utente di introdurre vincoli sulle variabili utilizzate nella prima parte come un range o set di valori accettabili. L'implementazione di questo nuovo tipo di template è `ConstraintLogicTemplate`, mentre quella originale è stata rinonimata in `SimpleLogicTemplate`.
Per poter realizzare i `ConstraintLogicTemplate` è stato necessario modificare l'implementazione del `LogicSpace` in quanto alcune assunzioni che erano state fatte in questa non sono più valide con l'introduzione della nuova tipologia di template. Per evitare che in futuro sia necessario modificare nuovamente il `LogicSpace` qualora si vogliano aggiungere nuovi tipi di `LogicTemplate`, si è deciso di spostare la logica di alcune operazioni effettuate dal `LogicSpace` nell'interfaccia `LogicTemplate`.
In particolare le implementazioni di quest'ultimi dovranno definire i seguenti metodi, che saranno utilizzati per effettuare le operazioni di *read* e *take* nel `LogicSpace`:
- `asReadTerm`: restituisce un termine Prolog le cui soluzioni permettono di ottenere le tuple corrispondenti al template
- `asRetractTerm`: analogo a `asReadTerm`, ma effettua anche l'operazione di retract sulle tuple della soluzione
- `extractTuple`: si aspetta in input una soluzione ottenuta tramite questo template, e restituisce la tupla contenuta in questa
Infine ciascun template dovrà definire il metodo `asTerm` che lo converte in un termine che rappresenta il template, permettendo di trasferirlo sulla rete. Per ricostruire poi il template da questo termine si può usare il metodo `of`, che costruisce l'oggetto template più appropriato sulla base della struttura del termine.
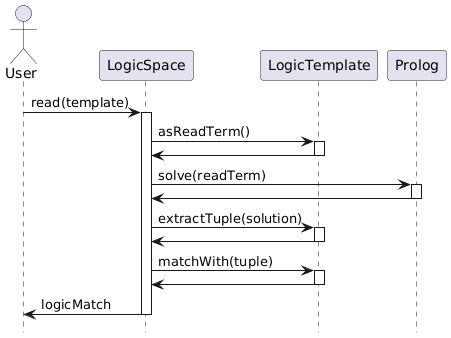
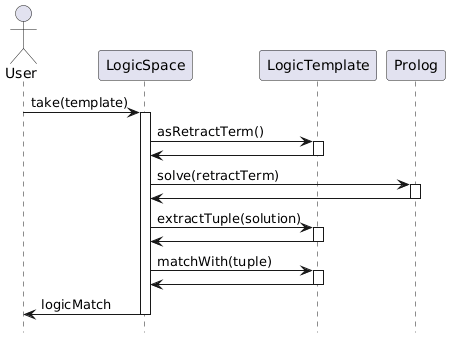
Di seguito sono rappresentati dei diagrammi di sequenza che mostrano l'uso dei template da parte dello spazio di tuple nel caso di *read* e *take*.
### Comportamento protocolli di interazione
#### Behaviours per invio e ricezione messaggi
I protocolli di interazione sono realizzati tramite lo scambio di più messaggi ACL, quindi il primo passo nella realizzazione di questi è stata l'implementazione di behaviour per invio e ricezione di messaggi.
Per lo scambio dei messaggi si è deciso di utilizzare degli spazi di tuple; ad ogni agente è associato uno spazio di tuple logico TuSoW dedicato ai messaggi ACL ricevuti, e i behaviour per l'invio e ricezione dei messaggi sono quindi operazioni di *write* e *take*.
Questi behaviour possono essere instanziati tramite la *static factory* `FipaBehaviours`. Nel caso del behaviour send è necessario specificare il messaggio da mandare e opzionalmente una callback che verrà eseguita quando l'invio del messaggio è completato con successo. Per il behaviour receiver si deve invece specificare il template del messaggio da ricevere e opzionalmente una callback che sarà eseguita quando il messaggio è ricevuto.
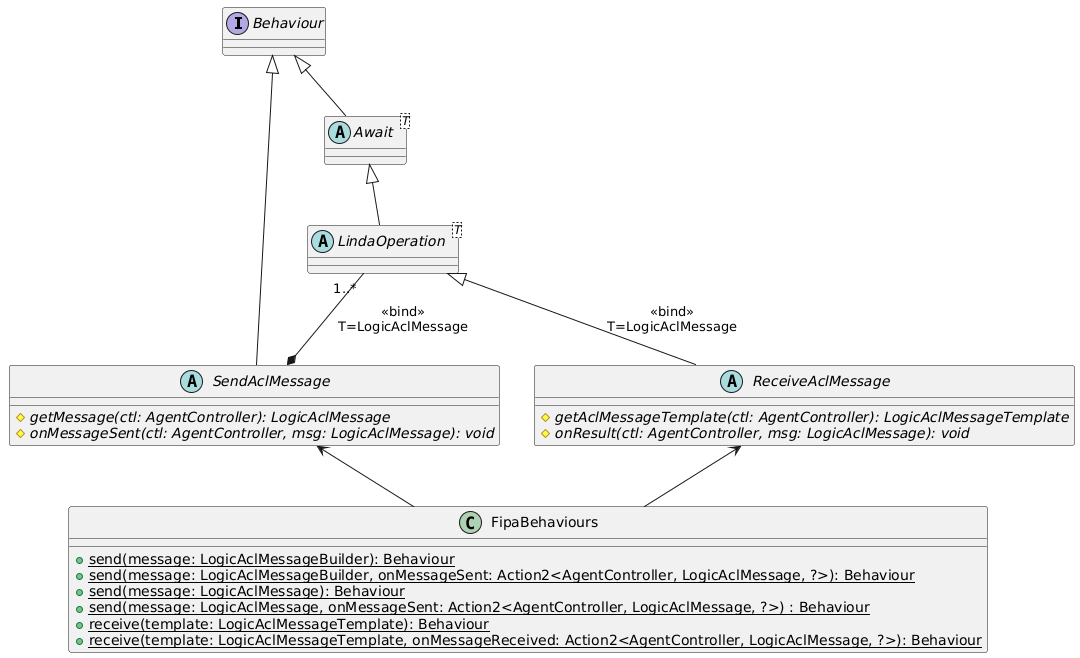
I behaviours `SendAclMessage` e `ReceiveAclMessage` internamente fanno uso del behaviour `LindaOperation` già implementato nel progetto base (uno singolo nel caso della receive, molteplici eseguiti in parallelo nel caso della send). Le prima volte che questi vengono eseguiti inizializzano i behaviour Linda relativi e saranno poi in stato *paused* fino al termine di questi. Una volta che le operazioni sono terminate il behaviour viene eseguito un'ultima volta, prima di terminare anch'esso, durante la quale richiama eventuali callback impostate.
Per quanto riguarda gli spazi di tuple su cui effettuare queste operazioni nel caso dell'operazione send viene determinato automaticamente sulla base dei receiver del messaggio da inviare, mentre nel caso receive sarà quello dell'agente che effettua l'operazione.
#### Fipa responder
Per ogni protocollo di interazione si sono realizzati due behaviour, uno per l'agente che assume il ruolo di initiator e l'altro per il participant.
Il modo in cui un agente inizia un protocollo di interazione è abbastanza diretto, in quanto basta che questo esegua un behaviour initiator relativo al protocollo desiderato.
Per quanto riguarda invece l'agente participant la situazione è più complicata, e in seguito ad un'analisi del problema si sono individuate due possibili strade:
1. La prima possibilità sarebbe quella di avere semplicemente un behaviour responder per ogni protocollo, che inizialmente attendono un messaggio per l'inizializzazione della relativa interazione e in seguito la eseguono in maniera totalmente autonoma
2. La seconda possibilità invece è quella di avere anche un behaviour responder principale che attende i messaggi per l'inizializzazione di una qualsiasi interazione ed effettui poi il dispatch di questi verso behaviour responder più specifici
Dopo aver analizzato pro e contro di entrambe si è deciso di implementare la seconda soluzione, per due motivi principali:
1. Un agente dovrebbe rispondere a tutte le richieste che gli arrivano, anche se si tratta soltanto di rifiutarle. Utilizzando un behaviour dispatcher che ascolta tutte le richieste si può imporre questo vincolo
2. Si possono implementare varie versioni del behaviour dispatcher, ciascuna delle quali può utilizzare una strategia diversa per la gestione di richieste multiple in contemporanea
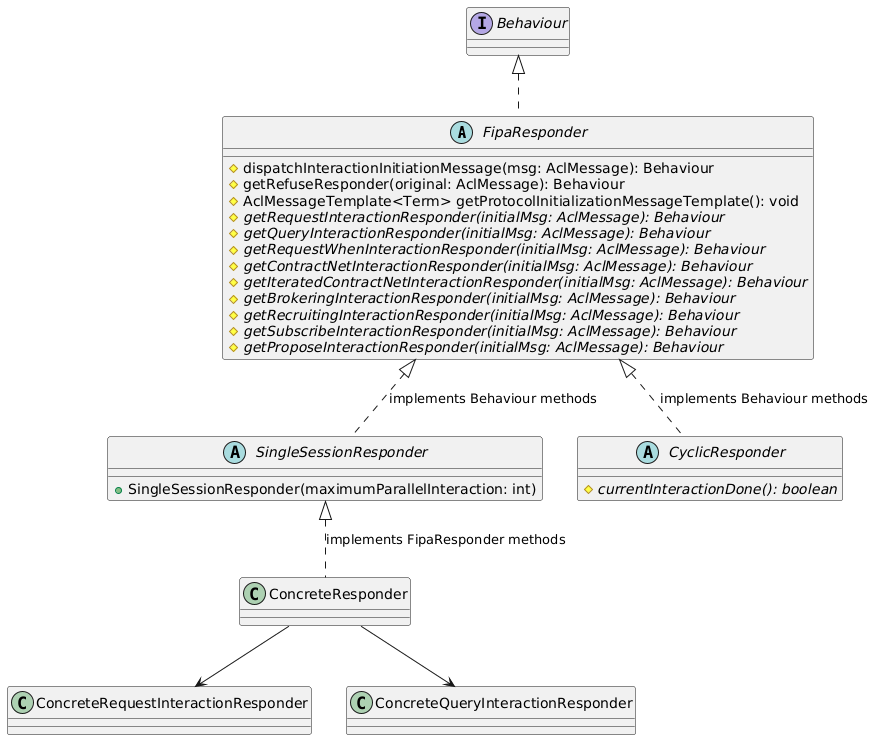
La classe astratta `FipaResponder` è la base per la creazione dei behaviour dispatcher; di questa sono fornite due implementazioni parziali `CyclicResponder` e `SingleSessionResponder`, che implementano i metodi di `Behaviour`. La prima gestisce solo una interazione alla volta e quando questa termina invoca il metodo `currentInteractionDone`, decidendo se eseguire un'altra iterazione sulla base del valore restituito da quest'ultimo. La seconda, invece, può gestire fino ad *n* iterazioni in contemporanea; se quando questo behaviour viene eseguito il numero di interazioni correnti è minore di *n* e sono tutte *paused* allora controllerà se è presente un'altra richiesta di interazione a cui rispondere e la aggiungerà a quelle correnti.
I responder concreti estenderanno da una delle implementazioni parziali di `FipaResponder`, implementando i metodi `getXInteractionResponder` dove restituiranno le versioni di interaction responder specifiche per il protocollo.
#### Interaction behaviours
I behaviour per gli interaction protocol sono stati realizzati come classi astratte, in cui sono già implementati gli aspetti di basso livello del protocollo, come ad esempio l'invio e ricezione dei messaggi, mentre all'utente è lasciato il compito di specificare il comportamento specifico per l'applicazione realizzata, come ad esempio le operazioni da effettuare alla ricezione di uno specifico messaggio tramite l'implementazione di apposite funzioni astratte.
Questi behaviour sono stati progettati con l'obiettivo di rendere il loro utilizzo il più semplice possibile in quelli che si sono ritenuti i casi d'uso più probabili.
Ad esempio nel caso del protocollo *query ref* per il behaviour initiator l'utente deve specificare contenuto e receiver del messaggio di query e implementare i metodi richiamati quando riceve in risposta un messaggio *agree*, *refuse* o *inform*; per quanto riguarda invece il behaviour responder l'utente deve implementare un metodo che effettui la computazione richiesta e restituisca il contenuto per il messaggio di risposta.
Si è deciso di realizzare il behaviour responder in questo modo nell'ipotesi che, nella maggior parte dei casi, il tipo di computazione richiesto sarà breve e che si può quindi fornire una risposta immediatamente; grazie a questo l'utilizzo dei behaviours risulta semplice, ma, qualora fosse necessario eseguire computazioni bloccanti, l'utente sarà costretto a realizzare un nuovo behaviour ad-hoc. Considerazioni analoghe valgono anche per i behaviour relativi agli altri protocolli.
Come risultato delle decisioni discusse in precedenza la maggior parte dei behaviour per i protocolli di interazione sono semplici macchine a stati finiti che effettuano una serie di send e receive di messaggi ACL. Di seguito è rappresentato il diagramma degli stati per un behaviour `QueryInteractionProtocolInitiator`.
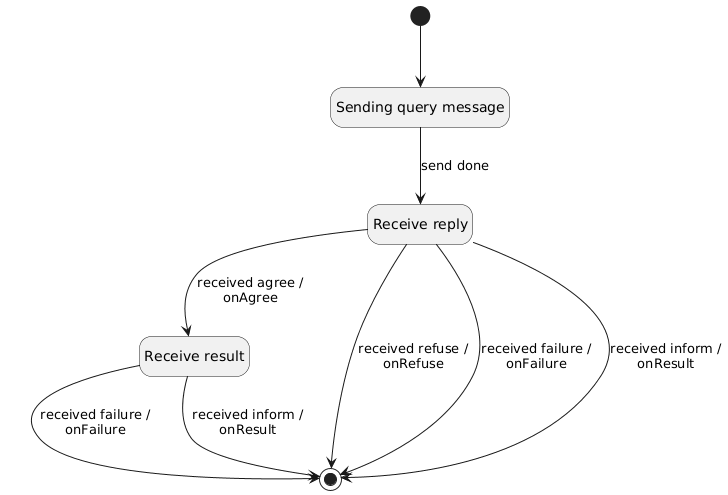
Si fa notare che data la natura dei `Behaviour` le transizioni di stato e specialmente l'esecuzione delle azioni associate avvengono solamente durante l'esecuzione del metodo `execute` del behaviour stesso.
Un'ulteriore conseguenza della decisione di creare behaviour di semplice utilizzo e l'assunzione che le computazioni effettuate saranno brevi è l'assenza di supporto per la cancellazione dell'interazione. Ogni protocollo di interazione prevede che il behaviour initiator possa richiedere di cancellare l'esecuzione dell'interazione inviando un apposito messaggio; questa operazione però perde di significato nel caso in cui il participant debba svolgere operazioni brevi, in quanto esso terminerebbe di eseguire l'interazione prima di poter ricevere il messaggio di cancellazione. Un'eccezione a questo sono i protocolli *subscribe* e *request-when*; a differenza degli altri protocolli questi potrebbero durare a lungo, in quanto dipendono anche da eventi esterni al protocollo di interazione. In particolare nel caso dell'interazione *subscribe* il participant deve inviare un messaggio ogni volta che un oggetto indicato nel messaggio iniziale cambia valore, mentre nel caso del *request-when* il participant deve eseguire una determinata azione quando una precondizione si avvera. Per questo motivo quindi i behaviour responder di queste interazioni devono essere in grado di rispondere alle richieste di cancellazione.
Nel caso dei behaviour initiator però non si ha una situazione completamente simmetrica; per poter mantenere la semplicità nell'uso di questi il supporto per l'invio del messaggio di cancellazione è fornito solo nel caso dell'interazione *subscribe*. Questo perché la cancellazione può essere effettuata solo a seguito di una richiesta da parte dell'utilizzatore del framework, ma nel caso del behaviour per *request-when* non sono presenti situazioni significative in cui la si può richiedere, in quanto le istruzioni specificate dall'utilizzatore sono eseguite soltanto alla ricezione dei messaggi che sottintendono la terminazione del protocollo (*refuse*, *failure* o *inform*), oppure alla ricezione di *agree* (che per le ipotesi effettuate sarà immediatamente successivo alla richiesta). Nel caso invece dell'interazione *subscribe* l'initiator riceverà un messaggio *inform* ogni volta che il valore specificato cambia, e quindi la callback definita dall'utente sarà chiamata più volte; in questo caso l'utente potrebbe essere interessato a cancellare l'interazione, basandosi per esempio sul nuovo valore ricevuto.
Di seguito è rappresentato il diagramma degli stati per il behaviour `RequestWhenInteractionResponder` in cui si possono notare la presenza di supporto alla cancellazione e la transizione *precondition holds* che, come detto in precedenza, sarà attivata da eventi esterni.
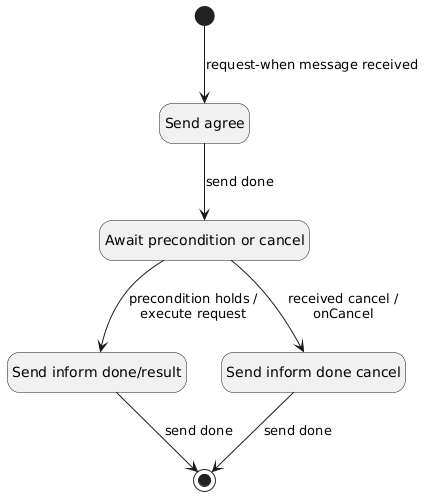
Anche in questo caso però le transizioni di stato, così come le azioni ad esse associate, sono di fatto effettuate solo durante l'esecuzione del metodo `execute`, grazie anche all'utilizzo del behaviour *await* per attendere che le precondizioni si avverino.
#### Esempio di interazione
Di seguito è raffigurato un esempio di un'interazione *request-when* completa, utilizzando i behaviour forniti dal framework.
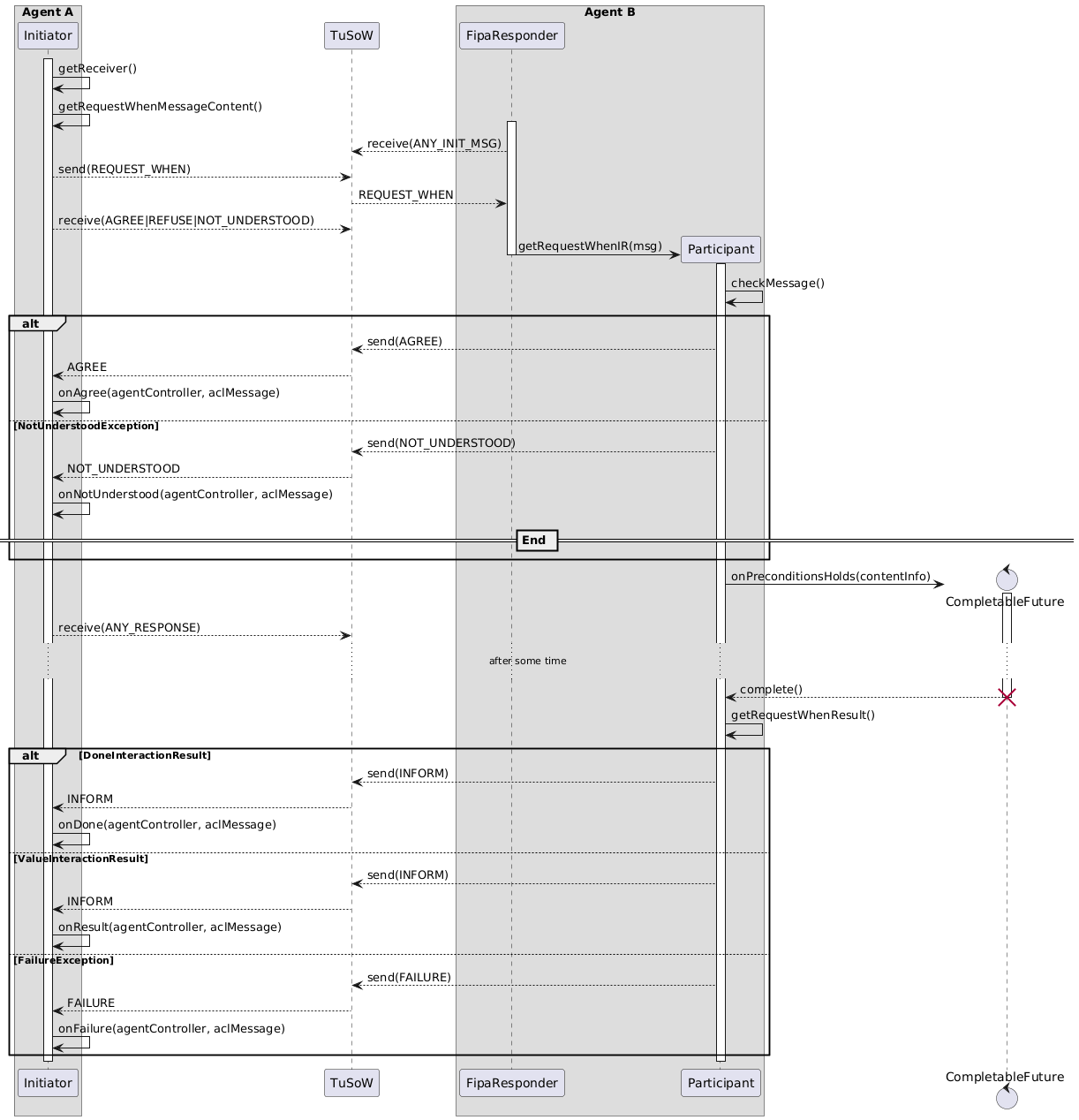
L'agente B esegue un behaviour `FipaResponder` che una volta ricevuto il messaggio request-when costruirà un behaviour più specifico (*participant*) per rispondere all'interazione.
Per controllare le precondizioni si fa uso di una completable future che sarà completata quando le precondizioni si verificano. Il completamento di questa avverrà per eventi esterni al behaviour responder, per esempio, tramite un behaviour differente o un thread separato rispetto a quelli dell'executor degli agenti.
Nel diagramma precedente si sono omessi i dettagli relativi allo scambio dei messaggi, indicando semplicemente TuSoW come partecipante all'interazione. In realtà gli agenti utilizzeranno, attraverso i behaviour di send e receive, dei `LogicTupleSpace` forniti dal loro environment. In questa interazione ne saranno usati due, uno per i messaggi ricevuti dall'agente A, e uno per quelli dell'agente B; quando un agente effettua la send scriverà sullo spazio di tuple dell'altro, mentre quando effettua una receive richiederà il messaggio al proprio spazio di tuple.
## Dettagli implementativi
L'implementazione in generale non presenta punti particolarmente complicati e si è proceduti seguendo le decisioni prese in fase di progettazione.
Si è però portata particolare attenzione nel decidere quali elementi esporre all'esterno tra quelli non previsti in fase di progettazione, come ad esempio classi di utility. Esponendo troppi elementi si rischia di rendere l'utilizzo del framework complicato, al contrario però se si nascondono componenti che potrebbero essere utili anche all'utente quest'ultimo sarà costretto a reimplementarli.
Inoltre ognuno dei componenti esposti è accompagnato da appropriata documentazione Javadoc. Questa sarà di supporto agli utilizzatori del framework, aiutando a comprendere meglio come utilizzare il sistema e il suo comportamento. La Javadoc, che viene aggiornata ad ogni modifica minore del framework, è disponibile sulle [Gitlab Pages](https://pika-lab.gitlab.io/courses/ds/projects/ds-project-aa1819-ciavatta-righini-tremamunno/).
## Autovalutazione
Durante lo sviluppo ci si è assicurati che il codice prodotto rispettasse i vincoli e i requisiti preposti principalmente tramite la realizzazione di unit test. Per ogni elemento principale del progetto è stata eseguita una verifica diretta del suo corretto funzionamento realizzando test appositi; invece nel caso di elementi secondari, come ad esempio metodi di utility, non si sono realizzati test specifici per gli stessi, ma la loro correttezza viene comunque verificata attraverso i test per le componenti che li usano. Ogni volta che si è terminata l'implementazione di uno degli elementi principali si sono realizzati i relativi test prima di procedere all'implementazione di elementi successivi; in questo modo si sono potuti intercettare subito errori di programmazione che si sarebbero altrimenti propagati, rendendo le operazioni di debug più semplici e limitate.
I test realizzati coprono il 94% delle classi implementate e l'83% delle righe di codice. Seppure questo indicatore non è da solo necessario per stabilire se i test coprano la totalità dei casi d'uso del progetto, i risultati ottenuti sono da considerarsi ottimi. I test più complessi che sono stati realizzati sono relativi ai protocolli di interazione, dove si è cercato di coprire più scenari di esecuzione possibili.
Si è inoltre usufruito di Gradle per automatizzare il processo di build e test del progetto. Oltre ad effettuare queste operazioni in locale, si sono utilizzati gli strumenti di continuous integration forniti da GitLab che utilizzano anch'essi Gradle per eseguirle in maniera completamente automatica ad ogni push.
Oltre all'utilizzo dei test per verificare il rispetto dei requisiti ci si è assicurati che il software prodotto fosse di buona qualità tramite dei criteri interni decisi all'inizio del progetto. Questi criteri sono stati scelti sulla base delle nostre esperienze passate e convenzioni.
Uno dei criteri scelti è stato quello di fornire la Javadoc per ogni componente esposto all'esterno, in modo da fornire supporto nell'utilizzo del framework ad un eventuale utente.
## Istruzioni di deployment
Il progetto realizzato è un framework che può essere utilizzato per implementare un sistema multiagente che utilizzi i protocolli di interazione standardizzati da FIPA per comunicare. Non è distribuito come un'applicazione standalone perché non è presente la logica applicativa che dovrà implementare l'utente.
Il framework viene distribuito con un wrapper di Gradle che dovrà essere utilizzato per compilare i sorgenti, lanciare i test, generare la javadoc ed eventualmente ulteriori artefatti. Lo stesso wrapper è utilizzato per effettuare continuous integration dai runner di GitLab. Per lanciare i test in un ambiente vergine viene lanciato un container Docker sul quale è già preinstallata la versione di Java desiderata. In particolare è stata utilizzata l'immagine distribuita da OpenJDK che include Java 12 (`openjdk:12-oracle`).
Il servizio di continuous integration oltre ad eseguire i test ad ogni modifica per assicurare che non ci siano rotture genera anche la documentazione e la pubblica sulle pagine di Gitlab. Si avrà così ad ogni cambiamento la Javadoc che è possibile trovare al seguente [link](https://pika-lab.gitlab.io/courses/ds/projects/ds-project-aa1819-ciavatta-righini-tremamunno/) aggiornata.
## Esempi di utilizzo
Il framework realizzato può essere usato nelle situazioni in cui si vuole realizzare un sistema distribuito che sia in grado di comunicare con altri sistemi. I protocolli di interazione implementati dal framework permettono di implementare rapidamente sistemi di questo tipo, siccome l'utilizzatore del framework non dovrà preoccuparsi di gestire direttamente lo scambio di messaggi. Trattandosi di protocolli standard si possono trovare online vari esempi di possibili utilizzi per ciascuna interazione, inoltre gli unit test realizzati forniscono anch'essi dei semplici esempi di utilizzo.
Un esempio concreto di sistema che potrebbe far uso dei protocolli di interazione è un servizio meteorologico. Si potrebbe avere per esempio un agente che fornisce informazioni meteo quando richiestogli tramite il protocollo *query-ref*, inoltre lo stesso agente potrebbe essere in ascolto anche per richieste *subscribe* tramite le quali un altro agente può richiedere di essere informato automaticamente quando ci sono aggiornamenti importanti, come ad esempio allerte meteo.
## Conclusioni
Il framework realizzato fornisce, tramite appositi behaviour, supporto per l'invio e ricezione di messaggi ACL utilizzando spazi di tuple logici. Grazie alle caratteristiche degli spazi di tuple i messaggi possono essere ricevuti in maniera asincrona, ed è anche possibile specificare dei filtri (template) in modo da ricevere solo messaggi con le caratteristiche indicate.
Per permettere lo scambio di messaggi tra sistemi potenzialmente distribuiti si è utilizzato il servizio TuSoW, che fornisce delle web API rest per l'utilizzo di spazi di tuple.
Visto il bisogno di usare filtri avanzati nella ricezione dei messaggi è stato necessario aggiungere una nuova versione di template logico, oltre a quello già supportato da TuSoW, in modo da fornire più libertà nel loro utilizzo. Questo, a differenza del template originale, permette di specificare ulteriori espressioni Prolog nel template, oltre ad un'espressione principale che indica la struttura della tupla, in modo da poter vincolare ulteriormente le soluzioni ottenute.
Infine utilizzando i behaviour send e receive già realizzati si sono implementati anche behaviour per l'esecuzione completa dei protocolli di interazione. Quest'ultimi gestiscono in autonomia l'invio e ricezione dei messaggi per il funzionamento del protocollo, lasciando all'utilizzatore del framework il solo compito di specificare il comportamento specifico del sistema che si vuole realizzare.
### Sviluppi futuri
#### Rappresentazione dei messaggi ACL
Gli agenti del framework realizzato si scambiano messaggi ACL serializzati come termini Prolog, ma questa rappresentazione non è standard FIPA. Per poter aderire agli standard in modo più completo sarebbe necessario fornire supporto alla serializzazione e deserializzazione di messaggi verso una delle [rappresentazioni standard](http://www.fipa.org/repository/aclreps.php3).
Questa funzionalità sarà sicuramente necessaria se si vuole permettere l'interazione con agenti realizzati con framework diversi.
#### Sanitizzazione template logici
I `ConstraintLogicTemplate` introdotti forniscono all'utente la possibilità di specificare oltre ad un'espressione principale che rappresenta la struttura del template ulteriori espressioni Prolog che possono essere utilizzate per esprimere ulteriori vincoli sulla tupla da recuperare. Attualmente però non viene effettuato alcun controllo sul contenuto di quest'ultima espressione e l'utente potrebbe inserire termini che hanno effetti indesiderati, come ad esempio `assert`, che permetterebbe all'utente di scrivere nuove tuple durante un'operazione di lettura.
Sarebbe opportuno implementare dei controlli che verificano le espressioni inserite dall'utente in modo da evitare questi effetti indesiderati.
#### Behaviour più generali per protocolli di interazione
Come detto in precedenza i behaviour per i protocolli di interazione realizzati sono di semplice utilizzo, ma per questo motivo hanno anche delle limitazioni. In futuro sarebbe possibile realizzare anche delle versioni meno limitate dei behaviour già implementati, fornendo per esempio supporto all'esecuzione di computazioni lunghe e di conseguenza anche cancellazione.
In questo modo l'utente potrà continuare ad utilizzare i behaviour semplificati, ma qualora i limiti di queste non siano appropriati per le interazioni che vuole realizzare potrà utilizzare come base i nuovi behaviour anziché doverne costruire uno da zero.
#### Timeout per ricezione messaggi ACL
Sebbene le specifiche FIPA prevedono il supporto per dei limiti temporali entro i quali rispondere ad un messaggio ACL il framework realizzato non permette di specificare un timeout oltre il quale la ricezione del messaggio è da considerarsi fallita.
Si sarebbe potuta realizzare un'implementazione semplice di questa utilizzando un behaviour parallelo tra la ricezione del messaggio e un `Await`, considerando la ricezione fallita se il timer termina prima di aver ricevuto il messaggio. Questa soluzione però ha un problema: l'operazione effettuata sullo spazio di tuple non viene cancellata, quindi se in futuro viene ricevuto un messaggio che fa match con il template della receive fallita allora questo viene rimosso dallo spazio di tuple senza però essere utilizzato.
Per implementare in maniera corretta questa funzionalità sarebbe quindi necessario fornire supporto per il timeout già nello spazio di tuple.
### Conoscenze acquisite
Questo progetto è stato formante sotto diversi aspetti. Oltre le conoscenze acquisite durante la progettazione e lo sviluppo del software questo progetto ha accresciuto le nostre competenze per lavorare in team e per approcciarci allo sviluppo agile, acquistando padronanza delle tecniche della continuous integration. Ci ha permesso di conoscere il paradigma di programmazione ad agenti che non avevamo visto in altri corsi e da cui abbiamo appreso le basi per lo sviluppo di sistemi distribuiti. Abbiamo capito come utilizzare il modello di coordinazione basato sullo spazio di tuple per realizzare un progetto concreto e abbiamo aumentato le nostre conoscenze dei linguaggi logici, in particolare Prolog. Inoltre abbiamo capito che effettuare debug di un'applicazione distribuita può essere complesso e abbiamo acquisito tecniche per poterlo fare in maniera più efficiente.







