# Computer Architecture Notes
###### tags: `sysprog`
[黃婷婷教授的計算機組織課程錄影](https://www.youtube.com/playlist?list=PL67lj4m-vhchqUiwXXoz0PH5j18gvupW_)
## Outline
- Computer Architecture = Instruction Set Architecture + Machine Organization
( 比喻 : 建築設計師 and 營造商 ) , 有個 trade-off
- Instruction Set Architecture
- 可看成是 Software 和 hardware 的 interface
- MIPS
- instruction 只有三種 format
- 都是32 bits
- 評估效能
- response time
- CPU time
low level => number of clock cycle * clock period(clock frequency 倒數)
instruction level => CPI (clock per instruction) 一個 instruction 需要多少 cycle
CPU time = instruction/Program * CPI * Seconds/Clock cycle(clock period)
- throughput : 單位時間內可以做多少事情
- Instruction Set Architecture(A)
- CPU time
- CPU time = instruction/Program * CPI * Seconds/Clock cycle(clock period)
- multi-core 如果一行程式都沒變的話就是增加 throughput, 沒增加 response time .
- 如果想增加 response time, 則 multi programming
- Benchmarks
- speed of processor depends on code used to test it. Need industry standards so that different processors can be fairly compared -> benchmark programs
- 不同的 work load 所需要的 benchmark不同
- power consumption
- static power consumption : 漏電 (目前漏電比例仍大)
- dynamic power consumption
## Instruction Set Architecture(B)
- Computer Architecture = Instruction Set Architecture + Machine Organization
- Operands
- Register operands
- Memory operands
- Immediate operands
- arithmetic/logic instructions :
- add $0, $1, $2 -> operation destination , source1 , source2
- assembly don't use variables => registers
- 使用 register 的好處 :
- faster than memory
- easier for a compiler to use
- Registers can hold variables to reduce memory traffic and improve code density
- ( register named with fewer bits than memory location, 用多少bit來描述哪個register or memory )
- 32 registers , each is 32 bits wide
## Pipeline

- pipeline 的五個stage :
- instruction fetch -> register access (instruction decode) -> ALU -> memory access -> write back
( IF -> ID -> EX -> MEM -> WB )
- throughput 增加 , response time 不會
- 和 single cycle 比較 , 同樣是五個stage , 有加了 pipeline register
- datapath :
- 切的時候盡量 balance. clock cycle 會設為消耗時間最長的那個 stage, 才能讓全部的 state 往下一個前進
- control :
- "control signal" decode 之後就繼續往下傳 , 存在 pipeline register
- Data hazards
- 假設 z instruction 在 stage 2 的時候要 R5 這個 register 資料, 但 y instruction 還在 stage 3, 要寫資料進 R5 需要在 stage 5, 所以這時候就產生 data hazards.
- Control hazards
- z instruction 在 stage 3 or 4 要 branch , stage 1 2 已經有 instruction 進來了 , 這時候就要把之前的 flush 掉.
- Forwarding (R-type and R-type)
- Stalls (Load and R-type)
### Pipeline Hazards / Forwarding
- **Structure hazards** : 不同的 instruction 要競爭同一個 resources
- 解決 : resource 都在同一個 stage 使用.
不論是哪種 instruction type , 都要分五種 stage.
- **Data hazards** : attempt to use item before ready. (data dependency)
- 如果是 internal forwarding 就可解決
- Type :
- RAW (read after write) : I2 tries to read operand before I1 write it.
- WAR (write after read) : I2 tries to write operand before I1 read it. (pipeline 不會發生)
- WAW (write after write) : I2 tries to write operand before I1 write it. (pipeline 不會發生)
- **Control hazards** : attempt to make decision before condition is evaluated.
- **waiting** 永遠可以解決 hazards
- 每一個 stage 要用的 resources 要不一樣 !!!
- 解決 Data hazard :
- internal forwarding : clock trigger 的時候就寫入 register(first half of clock) , read in second half

- Compiler inserts NOP (software solution)
- Forwarding (hardware solution)
- Stall (hardware solution)
- another way to fix Forwarding (Datapath with forwarding) :

- DataPath : MUX 是一個 three to one, 一個是從正常的 register file, 另外兩個是 forwarding 回來的 data.
- "Forwarding unit" 要發出 signal 來控制 MUX 的 input.
- normal input -> Forwarding = 00
- EX hazard -> Forwarding = 01
- MEM hazard -> Forwarding = 10
- Don't forward if instruction does not write register => check if RegWrite is asserted.
- Don't forward if destination register is $0
### Stalling
- Can't Always Forward !!!!
- Load(`lw`) and R-type (Stalling) : 還沒從 memory 拿到資料 , 要如何 forward?
- **Stall** pipeline by keeping instructions in same stage and inserting an NOP instead. (停一個 clock cycle)
- hazard detection controls , PC , IF/ID , control signals
### 小結 :
Data Hazard 分兩種 :
1. 第一個 instruction 和 第二個 instruction 的關係是 R-type and R-type :
-> 永遠可以 forwarding
2. 第一個 instruction 和 第二個 instruction 的關係是 load and R-type :
-> stall a clock cycle , can not forward.
### Handling Branch Hazard (Control hazard)
- **Predict branch** always not taken
- need to add hardware for flushing instruction , if wrong.
- **flush** 掉前面的 data 就是把 control signal 都設為0
- Dynamic Branch Prediction
- e.g. loop
- 如果切越深的 pipeline, branch 越早決定越好, flush 掉的 instruction 越少
- Branch prediction buffer (i.e., branch history table) 紀錄上次跳躍的狀況, associate memory to implements.
- 在第二個 stage 做
- Indexed by recent branch instruction addresses.
- Store outcome. -> taken(branch) or not taken.
- 1-Bit Predictor : Shortcoming
- 2-Bit Predictor (Finite State Machine)
- Branch target buffer
- Cache of target addresses
- **Delayed Branch**
- instruction 再 decode 的時候就要決定/猜是要跳 (taken) 或不跳 (not taken -> pc=pc+4 or target address), 但其實只要差一個 cycle 就可以知道是哪一個了. 找到一個 instruction 是兩個都執行, 等到下一個 cycle 就知道是哪個了
- the following instruction is always executed.
### Exception & Interrupt
- exception : Arises within the CPU
- e.g., undefined opcode, overflow, syscall...
- interrupt : from an external I/O controller
- Handling Exceptions
- Save PC of offending(or interrupted) instruction
- In MIPS : 存在 Exception Program Counter (EPC)
- Single address
- Vectored Interrupts
- 看發生的原因, 然後查表後 直接跳去相對應的 handler 處理
- Another form of control hazard (flush instruction)
- Simple approach : 從最早的 instruction 開始處理
- 發生 exception 的指令 之前的指令還是要處理完, 後面的則 flush 掉
- In complex pipelines :
- Out of order completion (data has no dependency)
- imprecise Exceptions
- 不知道誰先誰後, 則丟給 OS 來處理
### Superscalar and dynamic pipelining
- pipeline 就是一種 instruction level parallelism (ILP)
- 基本是同時執行五個 instruction
- To increase ILP
- Deeper pipeline( 深度 ) => shorter clock cycle. 因為每個 stage 要做的事情變少了
- Multiple issue( 廣度 ) => Duplicate pipeline stages -> multiple pipelines
- CPI < 1 , so use instruction per cycle (IPC)
- Static multiple issue :
- Compiler groups instruction to be issued together.
- Packages them to "issue slot"
- Compiler detects and avoids hazard
- Speculation (Guess) : 因為要平行化, 所以要猜. (like branch)
- speculate on branch outcome :
- Roll back if path taken different
- Speculate on load :
- 正常的情況下, store 接 load 的 instruction, 通常 load 的 address 會和 store 的 address 不同. 所以 load 可以先作. load 的資料要準備作計算, 較急需. store 只要存資料 write back, 所以可以慢慢 store.
- Roll back if instruction updated.
- 小結 :
- Static multiple issue : compiler approach
- software 在 run time 之前就把可以平行處理的 instruction 給 pack在一起, 且當成是一個single instruction. => VLIW (Very long instruction word)
- 兩個 instruction packets (一次抓 64 bits) :
- one ALU / branch instruction
- one load / store instruction
- Scheduling
- Loop Unrolling :
- Replicate loop body to expose more parallelism
- Use different registers per replication
- Called "register renaming" -> anti-dependency
- Dynamic multiple issue : hardware approach
- Scheduling (superscalar):
- Allow the CPU to execute instructions out of order to avoid stalls.
- Speculation
- Predict branch
- Load speculation
- Why Do Dynamic Scheduling ? 為何不要 software approach 就好?
- Not all stalls are predictable
- e.g., cache misses
- Can not always schedule around branches
- Different implementations of an ISA have different latencies and hazards.
## Memory
- Random access :
- Access time same for all locations, 和 magnetic disk不一樣
- SRAM :
- use for caches
- 如果電量一直維持的話, 內容會持續
- DRAM :
- use for main memory
- 需要 refreshed regularly
- memory as a 2D matrix ( read row to activate and read column to select )
- access SRAM 比 DRAM 快幾乎100倍
- 想要快, 又想要容量大 -> solution : Memory Hierarchy
### Memory Hierarchy
- Block : basic unit of information transfer. (再 virtual memory 叫 page)
- Why memory hierarchy works ?
- Principle of Locality :
- **90/10 rule** : 10% of code executed 90% of time. ( like loop )
- Temporary Locality : item is referenced, 它還有可能會在被 referenced again (loop)
- Spatial Locality : array , program(pc=pc+4) , sequential 的
- (upper level) registers -> caches -> memory -> disk (lower level)
- Memory Hierarchy : Terminology (術語 專有名詞)
- Hit : data appears in upper level.
- Hit rate, Hit time
- Miss : data need to be retrieved from a block in the lower level.
- Miss rate, Miss Penalty
- Questions for Hierarchy Design :
- block placement, block finding, block replacement, write strategy
### Cache Memory
- basics of cache : direct-mapped cache
- Address mapping : modulo (取餘數) number of blocks
- 以 binary 來看. ex: 10100 如果 cache 只有八個 blocks 的話, 那就看後面三個 bits 就知道了! (10100 -> 100)

### Tags and Valid Bits : Block Finding
- 下面四個 block 都 map 到上面的 upper level, 那我們從 cache 中要怎麼知道是哪個 block map 過來的?
- 除了存 data 外, 還要存部分地址 (high-order bits -> called tag)
- What if there is no data in a location ?
- valid bit 1 = present.
- cache 架構會不一樣, block size 也會不一樣 , 所以 tag 是多少個 bits 也不一樣 -> 要計算
- Ex : 64 blocks, 16 bytes/block (offset)
- What block number does address 1200 map?
- block address => 1200/16 = 75
- block number => 75 modulo 64 = 11
- 1200 = 10010110000(2 進位) / 10000 => 1001011
- 1001011 取後面 6 bits 的 index => 001011 (block number, 表示在 cache 中的位置)
| Tag | Index | Offset |
| ------- | ------ | ------ |
|31 ~ 10|9 ~ 4|3 ~ 0|
| 22 bits | 6 bits | 4 bits |
### Block Size Considerations
- Larger blocks should reduce miss rate
- due to spatial locality
- 但是因為 cache size 是固定的, 所以 block number 就會減少, 這樣表示更多人要來搶這個 block. -> tradeoff
### Cache Read/Write Miss/Hit :
- Read cache hit : CPU 正常執行
- Read cache miss :
- Stall the CPU pipeline -> penalty !!
- 從下一個 level 去抓資料 (block)
- Write cache hit :
- 因為 data 在 cache 和 memory 都有, 有一致性的問題
- Write through : also update memory
- slow -> solution : write buffer. CPU continuous immediately.
- 優點 : data 在 cache 和在 memory 永遠維持一致性
- 缺點 : 浪費 memory 的 bandwidth (traffic)
- Write back : 當 block 要被 replace 掉的時候, 再write back 回 memory
- use dirty bit. 有被改寫過的 dirty bit 就設 1
- Write cache miss :
- 是否要 allocate to cache 呢?
- 第一個方法 : write back - fetch the block. 把cache 內的 replace掉
- 第二個方法 : write through - 直接寫到 memory 內 , 不用搬進 cache 內
### Memory Design to support cache :
- how to increase memory bandwidth to reduce miss penalty?
- 3 structure ( 不同的 memory organization )9
- 1. 一次一個 word
- Access memory 的時間可分為 : access time and cycle time.
- Access of DRAM :
- address 拆成兩個部分: 一部份為 row index, 一部份為 column index
### Measuring and improving cache performance
- 要計算 program 的 execution cycles ( 不管 miss or hits )
- 如果是 Miss 的話, 還要計算 stall cycles
- 算法是 (memory access/Program) * Miss rate * Miss penalty
- Average memory access time (AMAT)
- Hit time + Miss rate * Miss penalty
- Improve cache performance :
- improve hits time
- decrease miss ratio
- decrease miss penalty
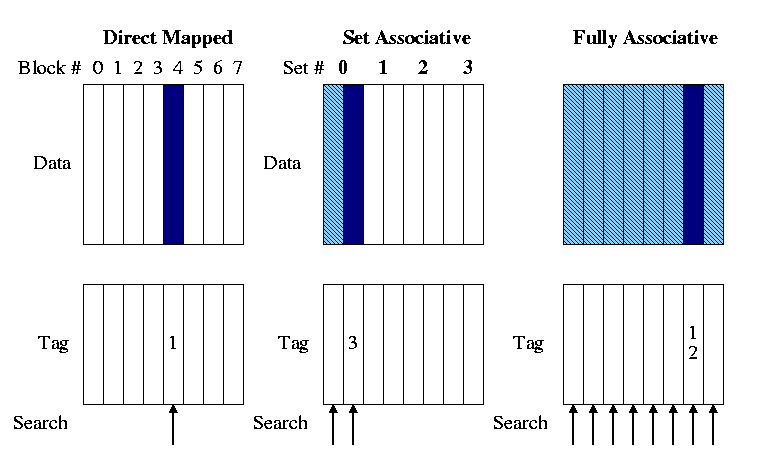
- Direct mapped
- 缺點 : 一個號碼只有一張椅子
- 改進 : Associative Caches
- Direct mapped 和 fully associate 是兩個極端值, fully associate 是表示 lower level 的 address 可以任意 map 到 upper level內的 cache.
- 所以折衷辦法是 set associate. ( 1 set associate == fully associate )
- Fully associative :
- Comparator per entry (貴) : entry 有幾個 block 就要比較幾次
- 就不需要 index 了, 那表示 tag 長度變大
- n-way set associative :
- Each set contains entries(blocks). ( 一個號碼內有多個椅子可以坐 )
- 
- 增加 associativity 會減少 miss rates
- **Data Placement Policy** :
- Direct mapped cache :
- Each memory block mapped to one location
- N-way set associative cache :
- Each memory block has choice of N locations
- fully associative cache :
- Each memory block can be placed in ANY cache
- Cache Block Replacement 有一些機制 :
- Direct mapped : 沒選擇
- Set associative or fully associative :
- Random
- Least Recently Used (LRU) 最近最少用到的 :
- use a pointer pointing at each block in turn
- 我們拿到的是 byte address, 要取得他的 block address 就要先把後面的 byte offset 先不看才可以得到 block address. 假設現在一個 block 有兩個 word, 也就等於 8 bytes , 表示byte address 後面三個 bits 是不用看的. 有 block address 後再去用 index and tag 去找他在哪個 block.
- Multiple Caches.
### Virtual Memory
- Memory <--> Disk (之前談的是 Cache <--> Memory), 概念其實和之前的一樣
- 很多 program 之間 只要搬部份的 program 進 memory 內, 由 OS 控制
- Program share main memory :
- 每一個人有自己的 private virtual address holding its frequently used code and data.
- Upper level (physical memory) <--> Lower level (virtual memory)
1. address 的 high order 表示 frame number , low order 表示 offset
- 要 access data 會先拿到 virtual address, 透過 page table 做了 address translation 後, 即可找到 physical address, 即可 access 到 data.
- "block" -> "page" , "miss" -> "page fault"
- Basic Issues :
- Size of data blocks ?
- 如何放置 (placement) policy to the page ?
- 如何替換 (replacement) policy to the page ?
### Block Size & Memory Placement
- miss penalty 太大了 : a page fault 會造成 millions of cycles to process
- 所以 page size 一定要大
- 用 fully associative placement !!!
- 每個 page 可能會對應到任何的 frame, 所以需要 page table(in memory) 來做對應
- ( 在memory 叫 frame, 在 disk 叫page )
- Address Translation :
- 也是要先找 page number : address / page size(e.g., 4K => 2的12次方的 bytes), => 12 bits 不看, 剩下的 bits 才是他的 page number.
- Page Table :
- 存放 placement 的資訊. 放在 main memory 內
- Problem :
- page table 太大
- How many memory references for each address translation?
- 2 次. 一次查 page table , 一次 access memory
- Page fault :
- 表示 page 不在 main memory內.
- Hardware must detect situation but it cannot remedy the situation.
- software 解決.
- The faulting process can be context switch
### Page Replacement and Writes:
- fully associative -> 如果都滿了的話, 誰要出去?誰要被替換? -> 需要policy
- To reduce page fault rate -> prefer least-recently used (LRU) replacement
- Reference bit (use bit), 過了一段時間會刷新, 把全部的 bit 都設為零
- 一定是 Write back.
- 需要 dirty bits ( 有被寫過的設為1 , 之後要 write back 回 disk )
### Handling Huge page table : page table is too big
- 有多大的 page 就要有多大的 page table 來做對應
Ex: Page table occupies storage :
32-bit VA, 4KB page, 4bytes/entry
=> 2的20次方 PTE(page table entry), 4MB table
Solutions :
- 用 bound registers 來限制 table size; add more if exceed.
- 讓 pages grow in both directions
- 2 tables -> 2 registers, one for hash , one for stack
- hashing (modular)
- multiple levels of page tables
### Translation Lookaside Buffer :
- 某個 entry 一直用到 (locality), 就要一直做 address translation(查 page table), 那不如不要放在 main memory, 就放在 CPU 旁邊 -> TLB
- Fast Translation Using a TLB(Translation Look-aside Buffer)
- Hardware 做的事
- Fast cache of PTEs within the CPU
- TLB : 其實就是常常用的 page table entry , 然後放在 CPU 旁邊. 就不用去 main memory 去 translate 它
- TLB hits
- TLB miss
- translation miss (在 page table 內的 entry 沒擺上來)
- page fault (這個 page 根本不在我的 main memory 內)
### TLB and Cache
- Translation 在 TLB, 得到一個 physical address 後 那個東西已經在 cache內了 , 就不用去 main memory 拿. -> 不用任何的 memory access
- 另一個方法: 如果 cache 內是 virtual address 的話, 那 TLB 就不需要去做 translation, 直接去 cache 內找有沒有 hit. 省去做 translation 的時間. (Cache is virtually indexed and virtually tagged)
- Problem :
- 相同的 virtual address 會對應到不同的 physical addresses(consistency 問題) -> tag + process id
- Synonym/alias problem : two different virtual addresses map to same physical address (需要 hardware 支援)
- 所以基本上 cache 還是用 physical address -> Virtually Indexed but Physically Tagged (Overlapped Access).

### Memory Protection
- 不同的 task 會 share 他們部份的 virtual address. 但不是任何的 user 都可以去 access 別人的東西. -> Supervisor mode 才可以去 access, 需要 system call (CPU from user to kernel) .
### A common framework for memory hierarchy
- 每一個 level 都是用 physical locality. (常常可以用的就放在附近)
會有四個問題 :
Block placement, Finding a block , Replacement on a miss, Write policy
- Block Placement :
1. Direct mapped, n-way set associative, fully associative
2. 越高的 associativity 會減少miss rate , 但會增加複雜度, cost , access time.
- Finding a Block :
1. Tag 的比對 : 1, n, Search all entries(# of entries), fully lookup table(0 -> for virtual memory)
- Replacement :
1. Least recently used (LRU) , Random
- Write Policy :
1. Write through , write back
Sources of Misses :
1. Compulsory misses (一定會 miss 的, 像是 cold start misses )
2. Capacity misses : size 有限, 容量不夠 (Due to finite cache size)
3. Conflict misses : 在 non-fully associative cache 會發生
### Using a Finite State Machine to Control a Simple Cache
- Coherence Defined
Reads return most recently written value
- 可以 centralize 的管也可以分開管
- snooping protocols : Each cache monitors bus reads/writes (一直去窺探 一直去竊聽)
- Broadcasts an invalidate message on the bus.
### Pitfall
- Byte address vs. word address
- 看一個 word 是幾個 byte , 還要看 block size/page size, 才能決定 block number/page number.
- In multiprocessor with shared L2 or L3 cache
- More cores -> need to increase associativity