# 2017q1 team4 MathEX
constributed by <`henry0929016816`, `vtim9907`, `twzjwang`, `rayleigh0407`>
Task: 擴充 [MathEX](https://github.com/jserv/MathEX),設計高效能的數學表示式運算器,參考 [muparserSSE - A Math Expression Compiler](http://beltoforion.de/article.php?a=muparsersse&p=implementation)
# [muparserSSE - A Math Expression Compiler](http://beltoforion.de/article.php?a=muparsersse&p=implementation)
- Implementation Notes
- 寫 assembly code 效能很難超越使用所有優化的(現代的)compiler。(原因:由於使用者可能不太了解 intel 內部構造,無法依照硬體性能寫出好的 assembly code)
- 當你寫一個任何類型的 interpreter ,如果想用 just in time compiler 來提高性能,那麼最有可能需要 assembly language。
- compiled code 仍然比高度優化的interpreted code 快上許多。
- Streaming SIMD Extension 提供 8 個可以進行快速浮點數運算的暫存器,讓 CPU 實現 SSE。目的是同時運算 4 個數。
- SSE 指令集中包含 ss 的指令只運算一個值,這些是 muparserSSE 主要使用的指令子集 (i.e. movss, divss, mulss, addss, subss, ...)。
- The reverse polish notation
- 了解 muParserSSE 前必須先知道甚麼是 [reverse polish notation](https://en.wikipedia.org/wiki/Reverse_Polish_notation) 。
- Reverse Polish notation (RPN) 中 operator 會放在所有 operand 後面。
- 平常所使用的是 infix notation ,可以加上括號 `( )` 表示順序
- A simple Expression
- Infix notation

- 運算子標為藍色,數值標為黑色
- human friendly
- Reverse Polish notation (RPN)

- computer friendly
- infix notation 轉 postfix notation
- [Shunting-yard algorithm](https://en.wikipedia.org/wiki/Shunting-yard_algorithm)
- RPN evaluated from left to right
- 遇到數值 push 進 stack
- 遇到運算子取出 stack 前兩個運算,再把結果 push 進 stack
- 最後 stack 中剩下的那個數 (在 s[0]) 為答案
```
a : s[0] = a
1 : s[1] = 1
2 : s[2] = 2
+ : s[1] = s[1] + s[2]
b : s[2] = b
* : s[1] = s[1] * s[2]
+ : s[0] = s[0] + s[1]
3 : s[1] = 3
- : s[0] = s[0] - s[1]
```
- 使用 SSE 指令集
```
a : movss xmm0, a
1 : movss xmm1, 1
2 : movss xmm2, 2
+ : addss xmm1, xmm2
b : movss xmm2, b
* : mulss xmm1, xmm2
+ : addss xmm0, xmm1
3 : movss xmm1, 3
- : subss xmm0, xmm1
```
- movss : 將浮點數移到暫存器
- addss subss mulss : 將兩個暫存器的值做加法、減法、乘法運算,存回第一個暫存器
- 算完後結果在 xmm0
- 動畫 (assume a=1 and b=2)
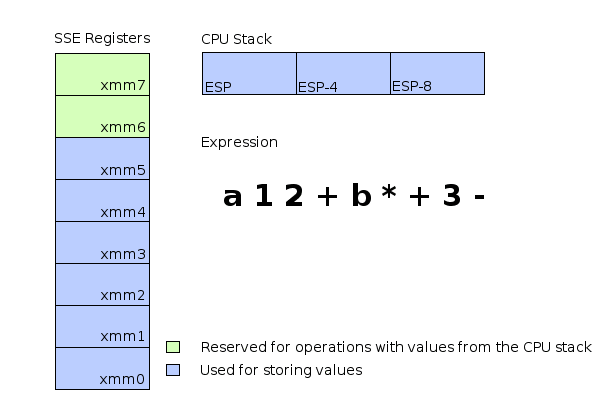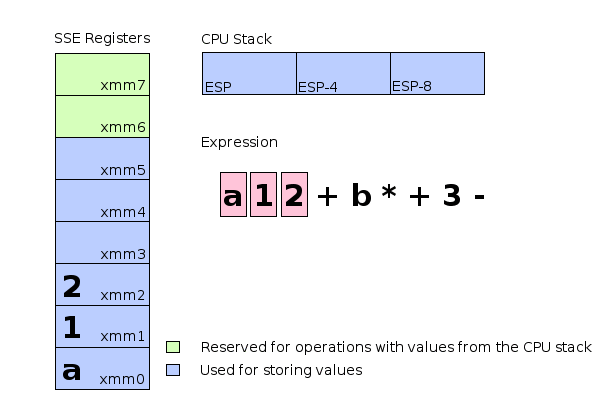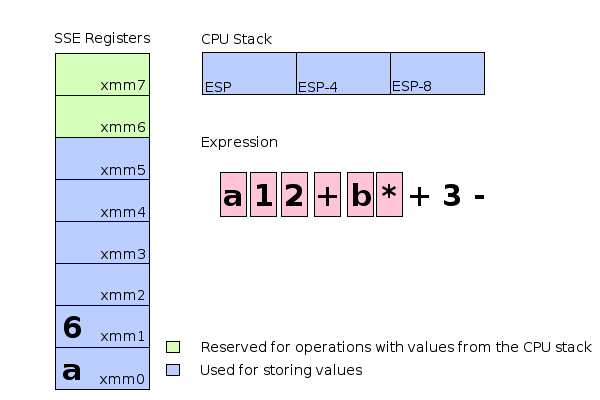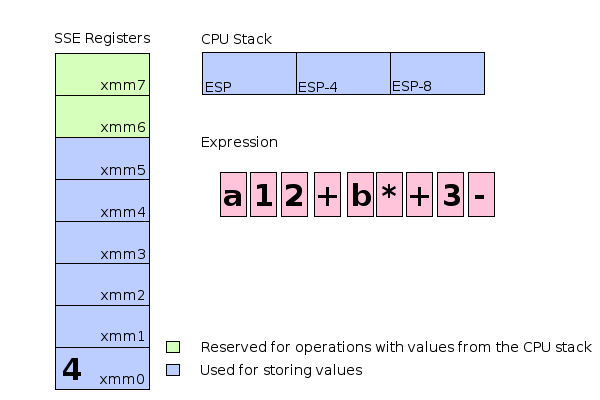
- 但並沒有想像中簡單
- A slightly more complex Expression
- 以下是個比較複雜的例子


- 轉成 pseudo assembly
```
1 : movss xmm0, 1
2 : movss xmm1, 2
3 : movss xmm2, 3
4 : movss xmm3, 4
5 : movss xmm4, 5
6 : movss xmm5, 6
7 : movss xmm6, 7
8 : movss xmm7, 8
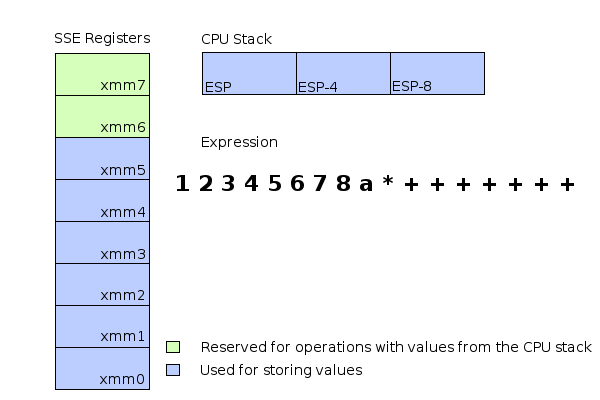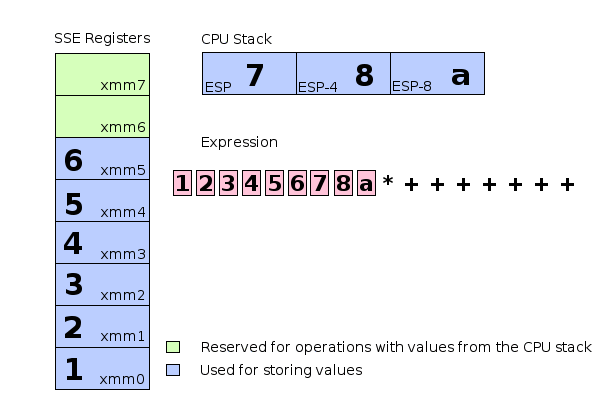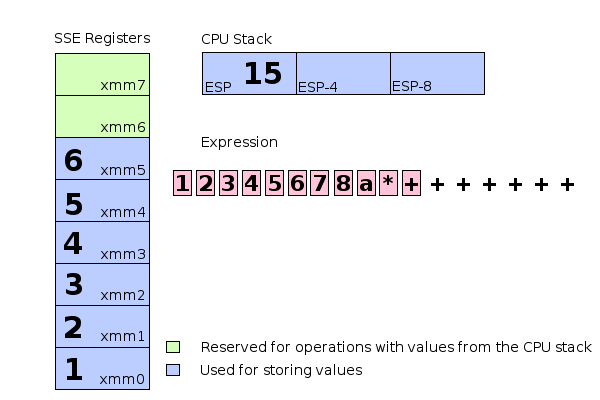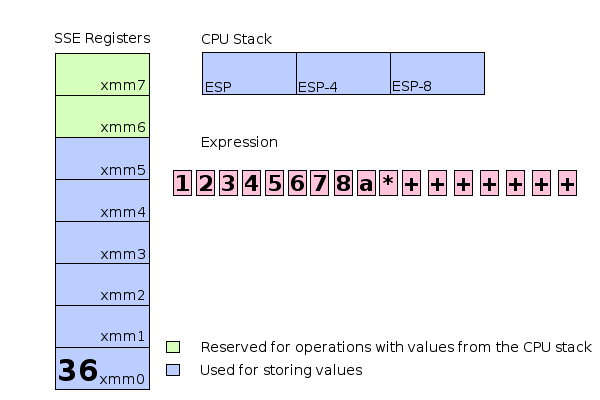
a : movss xmm8, a ; we don't have a register xmm8!
* : mulss xmm7, xmm8 ; we don't have a register xmm8!
+ : addss xmm6, xmm7
+ : addss xmm5, xmm6
+ : addss xmm4, xmm5
+ : addss xmm3, xmm4
+ : addss xmm2, xmm3
+ : addss xmm1, xmm2
+ : addss xmm0, xmm1
```
- 只有 8 個 SSE 暫存器,但上面卻使用了第 9 個 (xmm8)
- 沒有辦法將所有內容存在 SSE 暫存器中,必須找到另一個解決方案
- 最低的 6 個暫存器(xmm0,xmm1,...,xmm5)用於直接存儲值,如果一個值需要存儲在較高的位置,它將直接存儲在CPU stack 上,剩餘的兩個 SSE 暫存器(xmm6和xmm7)用於運算 cpu stack 上的值。
- 動畫
- This library supports only callbacks with the cdecl calling convention.
- Arguments are pushed to the stack from right to left and the calling function has to clean up the stack afterwards
- Benchmarks
- muparserSSE 主要的功能是提昇運算的效能,但要兼顧運算的效能和準確性並不容易。
- 對 muparserSSE 來說,若算式裡不包含函式 (e.g. tan(), sin()),效能明顯好很多;如果算式裡有函式,效能可能會變原來的 1/2 ~ 1/5 倍。
- 有用進 Benchmark 裡的 parsers:
- Interpreter
- [fparser](http://warp.povusers.org/FunctionParser/) - Function Parser for C++ v4.2
- [MTParser](http://www.codeproject.com/KB/recipes/MathieuMathParser.aspx) - An extensible math expression parser with plug-ins
- [muParser](http://beltoforion.de/article.php?a=muparser) - a fast math parser library
- Compiler
- [MathPresso](https://code.google.com/archive/p/mathpresso/) - A Math expression parser from the author of asmjit
- muparserSSE - A math expression compiler
- 算式裡不包含函式的效能比較 ([測資](http://beltoforion.de/en/muparserx/bench_expr_without_functions.txt))

- 算式裡包含函式的效能比較 ([測資](http://beltoforion.de/en/muparserx/bench_expr_with_fun.txt))

# 原始版本
- `"x=5, y = 3, x+y"`

> 一開始 expr_eval 的參數 struct expr e 的 type 是 OP_COMMA
> 分別以 e 的兩個 args.buf(type 為 `=`), args.buf(type 為 `,`)為參數
> 遞迴呼叫 expr_eval
# 實驗一 - 參考 muparserSSE 使用 SSE 指令運算
- 將 expr_create 建好的結果改用 SSE 運算
```C=
void expr_eval_sse_create(struct expr *e)
{
if (e->param.op.args.buf[0].type == OP_CONST)
top = eval_sse_stack_push(top, e->param.op.args.buf[0].param.num.value);
else
expr_eval_sse(&e->param.op.args.buf[0]);
if (e->param.op.args.buf[1].type == OP_CONST)
top = eval_sse_stack_push(top, e->param.op.args.buf[1].param.num.value);
else
expr_eval_sse(&e->param.op.args.buf[1]);
__m128 m1, m2, m3;
float f2 = eval_sse_stack_pop(top);
float f1 = eval_sse_stack_pop(top);
float f3;
m2 = _mm_load_ss(&f2);
m1 = _mm_load_ss(&f1);
switch (e->type) {
case OP_MULTIPLY:
m3 = _mm_mul_ss(m1, m2);
break;
case OP_DIVIDE:
m3 = _mm_div_ss(m1, m2);
break;
case OP_PLUS:
m3 = _mm_add_ss(m1, m2);
break;
case OP_MINUS:
m3 = _mm_sub_ss(m1, m2);
break;
}
_mm_store_ss(&f3, m3);
top = eval_sse_stack_push(top, f3);
}
float expr_eval_sse(struct expr *e)
{
top = NULL;
expr_eval_sse_create(e);
return eval_sse_stack_pop(top);
}
```
> 以上程式碼只能處理 + - * /
> 不能處理變數
- 結果
- 修改前
```=
BENCH 5+5+5+5+5+5+5+5+5+5: 43.447018 ns/op (23M op/sec)
BENCH 5*5*5*5*5*5*5*5*5*5: 38.432121 ns/op (26M op/sec)
BENCH ((5+5)+(5+5))+((5+5)+(5+5))+(5+5): 38.277864 ns/op (26M op/sec)
```
- 修改後
```=
BENCH 5+5+5+5+5+5+5+5+5+5: 442.471027 ns/op (2M op/sec)
BENCH 5*5*5*5*5*5*5*5*5*5: 433.096886 ns/op (2M op/sec)
BENCH ((5+5)+(5+5))+((5+5)+(5+5))+(5+5): 438.788891 ns/op (2M op/sec)
```
- 比較OP_CONST
- 慢了10倍以上...
BENCH|BENCH1|BENCH2|BENCH3
-|-|-|-
修改前(ns/op)|43.447018|38.432121|38.277864
修改後(ns/op)|442.471027|433.096886|438.788891
修改前/修改後|0.098|0.089|0.087
- 問題
- 過程中仍有遞迴呼叫
- stack 並非 [muparserSSE - A Math Expression Compiler](http://beltoforion.de/article.php?a=muparsersse&p=implementation) 中使用的 CPU stack
- 不能處理變數
> 原來的實做是把字串分析完之後 (infix notation -> postfix notation),用 tail recursion 快速算完。
> 如果要更快的話,可能要一邊分析字串的時候就要即時一邊算結果,比如針對分析的輸出,如果是數字就存進 stack,如果是符號,就直接 pop stack 做運算,應該比較符合 mupaserSSE 原來的設計。
> 我還在找怎麼改原來的 code 比較好 @@@ [name=偉庭]
>
# 使用 sse 的 register
* 由於 sse 的 register 有固定的名稱(xmm0,xmm1) ,所以為了動態的將資料傳入這些 register 我們可以使用 define ## 這個用法
`#define sse_register(x) xmm##x`
* 修改 vec_push
概念:
```c=
int register_ct=0
switch(e->type)
{
case OP_CONST:
movss sse_register(register_ct++) , val
break;
case OP_PLUS:
register_ct-=2;
addss sse_register(register_ct) , sse_register(register_ct++);
break;
}
```
# inline assembly code in C
為了做到讀取到的值,直接放入指定的 register 我們需要使用 inline assembly code 。
* ### GCC inline assembly code 語法
assembly 語言有兩種呈現的方式,一種是 intel Style ,另一種是 AT&T style 而 GCC 使用的是 AT&T 語法,所以接下來介紹的都是 AT&T 語法
* #### register 的命名方式:
register 的名稱都是由 ==%== 這個字符當作開頭,例如:`%eax ,%cl`
* #### 運算元的排序方式 :
不像 intel Style (第一個運算元是 destination), AT&T 則是將第一個運算元當作是 source , 第二個運算元當作是 destination ,所以照 intel Style syntax 寫這段 code `mov eax, edx` 在 AT&T syntax 就會變成 `mov eax, edx`
* #### 運算元的大小:
運算元的大小取決於 op-code 的結尾字符, b (byte) 為 8 bit , w(word) 為 16 bit , l(long) 為 32 bit , 對於以上的 code 正確的寫法應該是 ` movl %eax, %edx`
* #### 立即的運算元:
立即的運算元會使用 ==$== 當作開頭,例如:`movl $5, $eax`,就是將 long value 5 立即的傳到 register(%eax) 裡
* #### memory operand:
如果運算元沒有前綴字符,代表這個運算元為記憶體位址,因此 ` movl $bar, %eax` 這段 code 是要將 bar 這個變數的 address 傳到 %eax ,但是 `movl bar, %eax` 則是要將 bar 這個變數的內容傳到 %eax 這個 register
* #### indexing:
`movl, 8(%ebx),%eax` 這段 code 是將 %ebx 的位址往後移 8 位,將這個位址的內容傳到 %eax 這個 register
* ### Basic inline Code
我們可以使用以下兩種方式來撰寫我們的 assembly code:
* `asm("assembly code");`
* `__asm__ ("assembly code");`
# 改善
## Evaluate vs Execute
- Evaluate
- expression
- 求值
- Execute
- instructions
- 執行
## 為啥會變快,關鍵
- Cache friendly
- 以 cache locality 分析
## Psuedo assembly 跟可執行的 assembly 差在哪
## 不同表示式差異
## 為啥要定義先乘除後加減
## 可不可以有括號,演算法
## 正確性分析
## 缺 evaluator
## 一開始會變慢的問題在 parser
# Reference
[Unary Operation](https://en.wikipedia.org/wiki/Unary_operation)
[Using Inline Assembly in C/C++](https://www.codeproject.com/Articles/15971/Using-Inline-Assembly-in-C-C)
###### tags: `twzjwang`