# How C programs work
(返回[2016年暑期系統軟體課程:台南場次](https://hackmd.io/EwZg7AbALAjArADgLSShJUBGECcSEAME6uYmB2OAplAGa1A))
## 有所變,有所不變
* 1980 年代的電腦廣告: [IMSAI 8080](https://en.wikipedia.org/wiki/IMSAI_8080)

* source: [twitter](https://twitter.com/HistoryInPics/status/552536619849613312)
* USD $5995 (而且是 35 年前的物價!) 只能買到 8-bit 微處理器,搭配 64 KB 主記憶體和 10 MB 硬碟。有趣的是,當時軟體開發的模式部分還延續至今
* 硬體突飛猛進,軟體的問題依舊還在
## Maslow’s pyramid of code review

* 21 世紀的軟體開發均已規模化,絕非「有就好」,而是持續演化和重構,code review 是免不了的訓練
* uber 工程師 Charles-Axel Dein 認為好的程式碼應該要:
* [ Correct ] : 做到預期的行為了嗎?能夠處理各式邊際狀況嗎?即便其他人修改程式碼後,主體的行為仍符合預期嗎?
* [ Secure ] : 面對各式輸入條件或攻擊,程式仍可正確運作嗎?
* [ Readable ] : 程式碼易於理解和維護嗎?
* [ Elegant ] : 程式碼夠「美」嗎?可以簡潔又清晰地解決問題嗎?
* [ Altruist ] : 除了滿足現有的狀況,軟體在日後能夠重用嗎?甚至能夠抽離一部分元件,給其他專案使用嗎?
* 「需求」層次: 正確 → 安全 → 可讀 → 優雅 → 利他
* @**[徐元豪](https://www.facebook.com/profile.php?id=100000019155769&fref=ufi)** : 「工程師都會寫程式,但是 (往往) 欠了 code review 的能力。code review 不是用來戰別人,而是訓練自己如何看得懂別人程式、了解別人的想法,常看人家的程式,無形中是在訓練自己。」
* [@](https://twitter.com/Chaoint)Chaoint : 「沒關係。」總是講給自己聽的。
* 「人們不敘述自己的過往,而是為自己的過往作證。」—— Frantz Fanon
* 「如果你把游泳池當作浴缸泡著,再泡幾年還是不會游泳」 -- jserv
延伸閱讀: [Code Reading](https://en.wikipedia.org/wiki/Code_Reading)
* 大量篇幅回顧 C 語言概念,以及在真實世界中的程式如何展現,細節!
## 什麼叫做簡潔?

尤拉猜想是 Euler 在 1769 年對費馬定理的延伸: n 個正整數的 k 次方的總和,若是另一個正整數的 k 次方,則 n 不可能小於 k。n = 2 就是費馬最後定理,不過這個猜想在 1966 年被號稱「最短論文」給否定。
延伸閱讀:
* [美麗的錯誤--猜想的真與假](http://www.mathland.idv.tw/fun/erroneous.htm)
* [邏輯思維:費馬大定理](https://www.youtube.com/watch?v=7nORW4edSaI) (YouTube)
## 「事實」很容易被遮蔽,所以我們要 Benchmark / Profiling

source: [twitter](https://twitter.com/Harvey1966/status/624099087466500096)
## 《進擊的鼓手》之後

"No pain, no gain"
source: [CSAIL at MIT twitter](https://twitter.com/MIT_CSAIL/status/614140774620332032/photo/1)
* 延伸閱讀: [Operational Amplifier](http://memo.cgu.edu.tw/shin-yan/0909_Electronics(I)/2_OP.pdf)
## 理解系統程式
* 從實際案例著手: [從無到有打造類似 Facebook 社群網站](https://embedded2016.hackpad.com/MT7688-cgi-server-facebooc-EqEoM4o7nVv)
**計算機結構的改變**
[ [source](https://www.facebook.com/shihhaohung/posts/995419510500537) ]
* 早年計算能力相對低的年代,常常有用查表法代替計算,有空間換取時間的做法,來增進效能。... 那個時候 個人電腦的 CPU 可以在一個時脈週期中讀取一筆資料,但是要做乘法計算則需要幾十個時脈週期,所以用查表的比較快。除法和超越函數更是如此,而現在還有一些低階的處理器,還在用這些技巧。
* 後來當 CPU 時脈提高,但記憶體存取相對變慢的時候,我們必須反過來減少記憶體存取的次數,所以高階處理器 cache 越來越大,做 data prefetch 來提早取得資料、使用 multi-threaded architecture 來容忍資料遲到的狀況、使用壓縮的方式傳送資料,甚至還會用 speculation 的方式來猜測資料是在哪裡和是什麼。
* 在多處理機和多核心電腦上,存取資料的問題更嚴重,除了時間延遲和頻寬之外,還要考慮到尖峰時刻塞車的問題,所以有時候簡單的工作,就可能就不分工了,要不就由一個 CPU 代表去做,做完把結果給大家,要不就大家都做同樣的事情。前者多半在有共享記憶體的多核心處理器上看到,後者多半在分散式的系統看到。
* 到了異質計算的年代,CPU 和 GPU 的分工,更需要好好地做效能分析。因為傳統 GPU 和 CPU 不共享記憶體,透過較慢的 PCIe Bus 交換資料,所以有些工作 CPU 自己做比較快。另一方面,當 GPU 有超過 2000 個核心的時候,用重複的計算 (redundant computation)取代資料交換,也是常見的事。
* [](http://www.hsafoundation.com/)[http://www.hsafoundation.com/](http://www.hsafoundation.com/)
* 更進一步談巨量資料,為了節省資料的取得時間,我們往往費盡心思。我們花時間將資料和計算擺在同一個地方,做所謂的 data computation co-location,將重複出現的資料利用 data deduplication 技術節省儲存空間和取得時間,用一堆目錄 (indexing) 讓資料可以快速被找到。
* 當計算機結構有所不同時,優化的策略可能會隨之而變,不能食古不化。但原理雖然簡單,系統和實作技巧卻越來越複雜,軟硬體優化的機會越來越多,可惜能夠真正連通理論和實務的人則越來越少。
* 以上這些技術,講起來很容易,但在實作上,必須先搞清楚運算和資料的相對位置、距離、時間先後、相依性、數量等等,才知道該如何取捨。但很多人根本不會用效能分析工具,就在那邊瞎子摸象,隨便亂講,這時候要解決問題,就需要瞎貓遇到死耗子的運氣。
* i586 和 i686 看起來指令相似,但本質不同!
* 從 i686 (Pentium Pro) 開始,底層已經是** RISC 架構**
* 因為現在計算機結構改變很大
* 即便把程式用組合語言重寫,效能也不見得比 Compiler 產生的還好
* 效能的問題在存取資料本身
* 組合語言會快,是因為你分析過程式要怎樣寫才可以比較快
* 直接照著程式碼的邏輯改寫組合語言不見得比較好
* [hyperloglog](https://en.wikipedia.org/wiki/HyperLogLog)
* 使用 1.5k 表達 10 億筆資料
* <u>正規表示法? </u>
* [Python implementation of Hyperloglog, redis, fuzzy hashing for malware detection](https://bigsnarf.wordpress.com/2013/03/16/python-implementation-of-hyperloglog-redis-fuzzy-hashing-for-malware-detection/)
( 從測驗來刺激思考: Quiz-0 )
「[你所不知道的 C 語言](http://hackfoldr.org/dykc/)」系列講座
[A circuit-like notation for lambda calculus](http://csvoss.github.io/projects/2015/11/08/lambda-circuitry.html)
* 1928年,[Alonzo Church](https://en.wikipedia.org/wiki/Alonzo_Church) 發明了lambda演算(當時他 25 歲)。Lambda 演算被設計為一個通用的計算模型,並不是為了解決某個特定的問題而誕生的。1929 年,Church 成為普林斯頓大學教授。1932 年,Church 在 Annals of Mathematics 發表了一篇論文,糾正邏輯領域裡幾個常見的問題,他的論述中用了lambda演算。1935年,Church 發表論文,使用 lambda 演算證明基本數論中存在不可解決的問題。1936 年 4 月,Church發 表了一篇兩頁紙的 “note”,指出自己 1935 年那篇論文可以推論得出,著名的Hilbert“可判定性問題”是不可解決的
## Programming Small
* 在小處下功夫,不放棄整體改善的機會
* [快速計算和表達圓周率](http://chamberplus.myweb.hinet.net/ems_2.htm)
* [解說](http://godspeedlee.myweb.hinet.net/trick.html)
* [字串反轉](http://godspeedlee.myweb.hinet.net/c_str/c_str.htm)
* C 語言講究效率
* 為什麼 C 語言沒有內建 swap 機制?
* 很難作出通用且有效率的 swap 方式
* [Swapping in C, C++, and Java](http://www.cs.utsa.edu/~wagner/CS2213/swap/swap.html)
* 最佳化來自對系統的認知
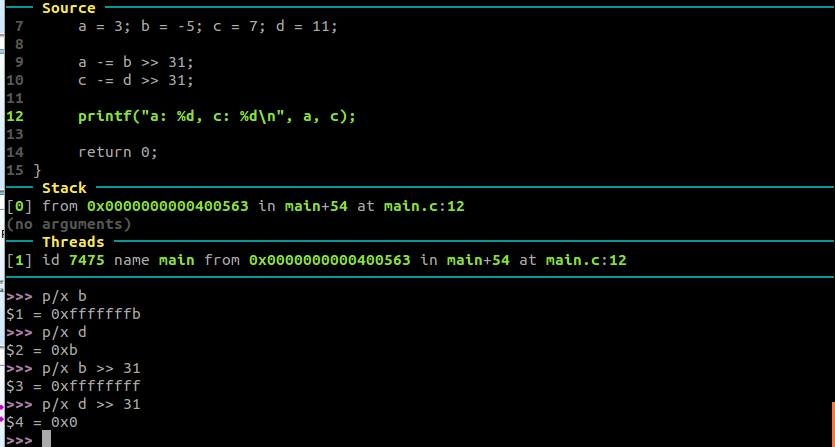
* 假設我們有兩個****有號整數***:
```C=
#include<stdint.h>
int32_t a, b;
```
* 然後原本涉及到分支的陳述:
**if (b < 0) a++;**
* 可更換為沒有分支的版本: # superscalar [](https://en.wikipedia.org/wiki/Superscalar_processor)https://en.wikipedia.org/wiki/Superscalar_processor
**a -= b >> 31;**
* 為什麼呢?一旦 b 右移 31 個 bit,在右移 `>>` 時在前面補上 sign bit ,所以移完會是 0xffff 也就是-1,故結果會是 `a -= -1`,即 `a++`,於是,原本為負數的值就變成 1 ,而原本正數的值就變成 0,又因為原本的行為是有條件的 a++,如此就是數值操作,沒有任何分支指令。
## GNU Toolchain
* gcc : GNU compiler collection
* as : GNU assembler
* ld : GNU linker
* gdb : GNU debugger
介紹完編譯工具後,來講點大概編譯的流程還有格式
**Compile flow **
先來看這張圖:

.c 和 .s 我想大家比較常見,所以就解釋一下 .coff 和 .elf 是什麼:
* [COFF (common object file format)](https://en.wikipedia.org/wiki/COFF) : 是種用於執行檔、目的碼、共享函式庫 (shared library) 的檔案格式
* [ELF (extended linker format)](https://en.wikipedia.org/wiki/Executable_and_Linkable_Format) : 現在最常用的文件格式,是一種用於執行檔、目的碼、共享函式庫和核心的標準檔案格式,用來取代COFF
**GAS program format (AT&T)**
```asm=
* .file “test.s”
* .text
* .global main
* .type main, %function
* main:
* MOV R0, #100
* ADD R0, R0, R0
* SWI #11
* .end
```
由一個簡短的 code 來介紹,在程式的section 會看到 `.` ,是定義一些 control information,如 _.file_ , _.global_ 等
* %function : 是一種 type 的表示方式 .type 後面可以放 function 或者是 object 來定義之
* SWI #11 : 透過 software interrupt 去中斷現有程式的執行,通常會存取作業系統核心的服務 (system call)
* .end : 表示是 the end of the program
注意,在後來的 ARM 中,一律以 "SVC" (Supervisor Call) 取代 "SWI",但指令編碼完全一致
==> [ARM Instruction Set Quick Reference Card](http://infocenter.arm.com/help/topic/com.arm.doc.qrc0001l/QRC0001_UAL.pdf)
以下簡介 ELF 中個別 section 的意義: (注意: ELF section 的命名都由 `.` 開頭)
* .bss : 表示未初始化的 data,依照定義,系統會賦予這些未初始化的值 0
* .data : 表示有初始過的 data
* .dynamic : 表示 dynamic linking information
* .text : 表示 "text" 或者是 executable instructions
**寫程式的要點**
* 程式是拿來實現一些演算法 (想法) 進而去解決問題的
* 可以透過 Flow of control 去實現我們的程式
* Sequence
* Decision: if-t
* hen-else, switch
* Iteration: repeat-until, do-while, for
* 將問題拆成多個更小而且方便管理的單元 (每一個單元或稱 function ,盡量要互相獨立)
* Think: In C, for / while ?
**Procedures**
來複習一下名詞
* Arguments: expressions passed into a function
* Parameters: values received by the function
* Caller & callee [呼叫者(通常就是在其他函式呼叫的function) 與 被呼叫者(被呼叫的 function)]
==> "argument" 和 "parameter" 在中文翻譯一般寫「參數」或「引數」,常常混淆
==> "argument" 的重點是「傳遞給函式的形式」,所以在 C 語言程式寫 `int main(int argc, char *argv[])` 時,我們稱 argc 是 argument count,而 argv 是 argument vector
==> "parameter" 的重點是「接受到的數值」,比方說 C++ 有 [parameterized type](https://isocpp.org/wiki/faq/templates#param-types),就是說某個型態可以當作另外一個型態的「參數」,換個角度說,「型態」變成像是數值一樣的參數了。
==> [](https://en.wikipedia.org/wiki/Parameter_(computer_programming))[https://en.wikipedia.org/wiki/Parameter_(computer_programming](https://en.wikipedia.org/wiki/Parameter_(computer_programming))

在撰寫程式常常會使用呼叫( call ),在上圖中高階語言直接將參數傳入即可,那麼在組語的時候是如何實作的呢?是透過暫存器? Stack ? memory ? In what order ?我們必須要有個 protocol 來規範
* ABI [](https://en.wikipedia.org/wiki/Application_binary_interface)https://en.wikipedia.org/wiki/Application_binary_interface
**ARM Procedure Call Standard (AAPCS)**
* ARM Ltd. 定義一套規則給 procedure entry 和 exit
* Object codes generated by different compilers can be linked together
* Procedures can be called between high-level languages and assembly
* AAPCS 是 [Procedure Call Standard for the ARM® Architecture](http://infocenter.arm.com/help/topic/com.arm.doc.ihi0042e/IHI0042E_aapcs.pdf) 的簡稱,從 10 年前開始,全面切換到 EABI (embedded ABI)
* 過去的 ARM ABI 稱為 oabi (old ABI),閱讀簡體中文書籍時,要格外小心,因為資訊過時
* APCS 定義了
* Use of registers
* Use of stack
* stack-based 資料結構型式
* argument passing 的機制
* first four word arguments 傳到 R0 到 R3
* 剩餘的 parameters 會被 push 到 stack (參數依照反過來的排序丟入堆疊中)
* 少於 4 個 parameters 的 procedure 會比較有效率

* Return value
* one word value 存在 R0
* 2 ~ 4 words 的 value 存在 ( R0-R1, R0-R2, R0-R3)
以下測試一個參數數量為 4 和 5的程式:
```C=
* int add4(int a, int b, int c , int d){
* return a + b + c + d;
* }
* int add5(int a, int b, int c , int d, int e){
* return a + b + c + d + e;
* }
```
程式編譯後,用 objdump 組譯會得到類似以下:

紅框標注的是比左邊多出的程式碼,從這裡可以看到參數 1-4 是存在 R0-R3,而第 5個參數存在原本 sp + 4 的位置,隨著程式碼進行 R0-R3 存在 stack 中,圖下為 stack 恢復前的樣子:

因此若寫到需要輸入5個或以上的參數時,就必須存取外部記憶體,這也導致效能的損失。
==> xorg xserver 的最佳化案例
**Standard ARM C program address space**
下圖為 ARM C program 標準配置記憶體空間的概念圖:

**Accessing operands**
通常 procedure 存取 operands 透過以下幾種方式:
* An argument passed on a register : 直接使用暫存器
* An argument passed on the stack : 使用 stack pointer (R13) 的相對定址 (immediate offset)
* A constant : PC-relative addressing
* A local variable : 分配在 stack 上,透過 stack pointer 相對定址方式存取
* A global variable : 分配在 static area (就是樓上圖片的 static data),透過 static base (R9) 相對定址存取
用幾張圖來表現出存取 operands 時,stack 的變化:
圖下為 passed on a register:

圖下為存取 local variables:

## Target Triple
在使用 Cross Compiler 時,gcc 前面總有一串術語,例如:
* arm-none-linux-gnueabi-gcc
這樣 `arm-none-linux-gnueabi-`稱為 target triple,通常規則如下:
<target>[<endian>][-<vender>]-<os>[-<extra-info>]
* vendor 部份只是常見是可以塞 vendor 而已, 但沒有一定塞 vendor 的資訊
* extra-info 部份大部份是在拿來描述用的 ABI 或著是 library 相關資訊
先以常見 x86 的平台為例子:
gcc 下 -v 可以看到以下:
```Target: x86_64-redhat-linux```
<target>-<vendor>-<os> 的形式
Android Toolchain:
```Target: arm-linux-androideabi```
<target>-<os>-<extra-info>
androideabi : 雖然 Android 本身是 Linux 但其 ABI 細節跟一般 linux 不太一樣
Linaro ELF toolchain:
```Target: arm-none-eabi```
<target>-<vender>-<extra-info>
vender = none
extra-info = eabi
Linaro Linux toolchain:
```Target: arm-linux-gnueabihf```
<target><endian>-<os>-<extra-info>
extra-info:
eabi: EABI
hf : Hard float, 預設有 FPU
* soft (GPR), softfp (GPR -> float register), hardfp
Linaro big-endian Linux toolchain:
```Target: armeb-linux-gnueabihf```
<target><endian>-<vender>-<extra-info>
endian = be = big-endian
Buildroot 2015-02
```Target: arm-buildroot-linux-uclibcgnueabi```
<target>-<vender>-<os>-<extra-info>
extra-info:
uclibc 用 uclibc (通常預設是 glibc, uclibc 有些細節與 glibc 不同)
gnu : 無意義
eabi : 採用 EABI
NDS32 Toolchain:
```Target: nds32le-elf```
<target><endian>-<os>
Andes 家的,應該淺顯易懂不用解釋
由以上眾多 pattern 大概可以歸納出一些事情:
vender 欄位變化很大,os 欄位可不填。若不填的話,通常代表 Non-OS (Bare-metal)
source: [](http://kitoslab.blogspot.tw/2015/08/target-triple.html)[http://kitoslab.blogspot.tw/2015/08/target-triple.html](http://kitoslab.blogspot.tw/2015/08/target-triple.html)
## 編譯器原理
為何我們要理解編譯器?這是電腦科學最早的思想體系
* [Compiler的多元應用](https://embedded2015.hackpad.com/Compiler-rtfoECtyuOd)
* 從理解動態編譯器 (如 Just-in-Time) 的運作,可一路探索作業系統核心, ABI,效能分析的原理
* [編譯器和最佳化原理篇](https://embedded2015.hackpad.com/C-DWAUb7NnQF0)
* 以 GNU Toolchain 為探討對象,簡述[編譯器如何運作,以及如何實現最佳化](http://www.slideshare.net/jserv/how-a-compiler-works-gnu-toolchain)
* C 語言程式如何轉換為機械碼,以及最佳化的空間和限制
* [Compiler Development](http://slide.logan.tw/compiler-intro/)
GCC 會透過 builtins 來達到最佳化,在 GCC flag -funit-at-a-time 指定時 (-O3 implies),原本的:
* **sprintf(buf,"%s",str);**
在 front-end 會被改寫為:
* **strcpy(buf,str);**
printf 本身就是一個小型的 interpreter,所以 GCC 的作法就是簡化複雜度,這對一般情況下是 正面的,不過涉及 function rewriting 的議題,對系統程式或設計一個作業系統核心來說,就是一個潛在的問題。
[ [Interpreter, Compiler, JIT from scratch](http://www.slideshare.net/jserv/jit-compiler) ]
* [碎形程式 in C](http://blog.linux.org.tw/~jserv/archives/2011/09/_mandelbrot_set.html) (Brainf*ck 的版本作為 benchmark)
[ [Virtual Machine Constructions for Dummies](http://www.slideshare.net/jserv/vm-construct) ]
[ [A brief history of just-in-time](http://dl.acm.org/citation.cfm?id=857077) ]
[ [Making an Embedded DBMS JIT-friendly](http://arxiv.org/abs/1512.03207) ]
值得注意的是,program loader 也很關鍵
* [PokémonGo Hacking without Jailbreak](https://docs.google.com/presentation/d/1XqU2GPG6l5nF8rsGTGbddQXk8k--5ZCDP7HlPC2D2eQ/edit#slide=id.g35f391192_00)
## 作業系統的核心裡面也有編譯器
* [A JIT for packet filters](https://lwn.net/Articles/437981/): Linux 核心已收錄 [Berkeley Packet Filter](https://secure.wikimedia.org/wikipedia/en/wiki/Berkeley_Packet_Filter) (BPF) JITC
* 形式來說來,bpf 就是 in-kernel virtual machine
* [BPF - the forgotten bytecode](https://blog.cloudflare.com/bpf-the-forgotten-bytecode/)
* tcpdump 不但可分析封包的流向,連封包的內容也可以進行「監聽」
* 鳥哥 Linux 私房菜: [第五章、 Linux 常用網路指令](http://linux.vbird.org/linux_server/0140networkcommand.php)
* [Berkeley Packet Filter (BPF)](https://en.wikipedia.org/wiki/Berkeley_Packet_Filter) 會透過 bytecode 和 JIT compiler 來執行
```C=
* $ sudo tcpdump -p -ni eth0 -d "ip and udp"
* (000) ldh [12]
* (001) jeq #0x800 jt 2 jf 5
* (002) ldb [23]
* (003) jeq #0x11 jt 4 jf 5
* (004) ret #65535
* (005) ret #0
```
* [Introduction to Linux kernel tracing and eBPF integration](http://www.slideshare.net/vh21/meet-cutebetweenebpfandtracing)
* [BPF Compiler Collection (BCC)](https://github.com/iovisor/bcc)
* BCC is a toolkit for creating efficient kernel tracing and manipulation programs, and includes several useful tools and examples. It makes use of eBPF (Extended Berkeley Packet Filters), a new feature that was first added to Linux 3.15.

## 實做案例
* [jit-construct](https://github.com/embedded2015/jit-construct) : Brainf*ck
* [rubi](https://github.com/embedded2015/rubi) : Ruby-like JIT compiler
* 將 [Rubi](https://github.com/embedded2015/rubi) 實做切換到 DynASM,並且設計效能評估機制,從而改善
* 原本 x86 code generator 換成 [DynASM 語法](http://luajit.org/dynasm.html)
* [The Unofficial DynASM Documentation](https://corsix.github.io/dynasm-doc/)
* 「[作業區](https://embedded2015.hackpad.com/2015q3-Homework-4-8AvSmXDYC38)」(C)
* [amacc](https://github.com/jserv/amacc): Small C Compiler generating ELF executable for ARM architecture
## Can we make Apache Spark 10x faster?
好比在金庸《射雕英雄傳》,馬鈺教郭靖修煉內功的方式,無外乎就是一些呼吸、走路、睡覺的法子。

(圖片來源:獵人 Hunter x Hunter)
* [Apache Spark as a Compiler: Joining a Billion Rows per Second on a Laptop](https://databricks.com/blog/2016/05/23/apache-spark-as-a-compiler-joining-a-billion-rows-per-second-on-a-laptop.html)
[ 舊有的資料處理模式 ]

```java=
* class Filter(child: Operator, predicate: (Row => Boolean))
* extends Operator {
* def next(): Row = {
* var current = child.next()
* while (current == null || predicate(current)) {
* current = child.next()
* }
* return current
* }
* }
```
[ 以簡馭繁 ]

```java=
* var count = 0
* for (ss_item_sk in store_sales) {
* if (ss_item_sk == 1000) {
* count += 1
* }
* }
```
[ 進一步改善 ]
* No virtual function dispatches
* Intermediate data in memory vs CPU registers
* Loop unrolling and SIMD
* [生日悖論](https://zh.wikipedia.org/zh-hant/%E7%94%9F%E6%97%A5%E5%95%8F%E9%A1%8C)

## 編譯器技術對於現行運算需求的重要性
* [AutoFDO](https://gcc.gnu.org/wiki/cauldron2013?action=AttachFile&do=get&target=AutoFDO.pdf), Google
* [GCC Function Instrumentation](https://gcc.gnu.org/onlinedocs/gcc/Instrumentation-Options.html)
* 該機制出現於 GCC 2.x,由 Cygnus (現為 RedHat) 所提出,在 GCC 中對應的選項為:"finstrument-functions"
* 測試 GCC Function Instrumentation 的小程式: (hello.c)
```C=
* #include <stdio.h>
* #define DUMP(func, call) \
* printf("%s: func = %p, called by = %p\n", __FUNCTION__, func, call)
* void __attribute__((__no_instrument_function__))
* __cyg_profile_func_enter(void *this_func, void *call_site)
* { DUMP(this_func, call_site); }
* void __attribute__((__no_instrument_function__))
* __cyg_profile_func_exit(void *this_func, void *call_site)
* { DUMP(this_func, call_site); }
* main() { puts("Hello World!"); return 0; }
```
* 編譯與執行:
```
* $ **gcc -finstrument-functions hello.c -o hello**
* $ **./hello**
* __cyg_profile_func_enter: func = 0x8048468, called by = 0xb7e36ebc
* Hello World!
* __cyg_profile_func_exit: func = 0x8048468, called by = 0xb7e36ebc
```
* 看到 "__attribute__" 就知道一定是 GNU extension,而前述的 man page 也提到 -finstrument-functions 會在每次進入與退出函式前呼叫 "__cyg_profile_func_enter" 與 "__cyg_profile_func_exit" 這兩個 hook function。等等,「進入」與「退出」是又何解?
* C Programming Language 最經典之處在於,雖然沒有定義語言實做的方式,但實際上 function call 皆以 stack frame 的形式存在。
* 如果我們不透過 GCC 內建函式 "__builtin_return_address" 取得 caller 與 callee 相關的動態位址,那麼仍可透過 -finstrument-functions,讓 GCC 合成相關的處理指令,讓我們得以追蹤。而看到 __cyg 開頭的函式,就知道是來自 Cygnus 的貢獻,在 gcc 2.x 內部設計可瞥見不少。
* 當我們試著移除 "__attribute__((__no_instrument_function__))" 那兩行來看看: (wrong.c)
* 編譯與執行:
```
* $ **gcc -g -finstrument-functions wrong.c -o wrong**
* $ **./wrong**
* Segmentation Fault
```
* 發生什麼事情呢?請出 gdb 協助:
```
* $ **gdb -q ./wrong**
* (gdb) **run**
* Starting program: /home/jserv/HelloWorld/helloworld/instrument/wrong
* Program received signal SIGSEGV, Segmentation fault.
* 0x0804841d in __cyg_profile_func_enter (this_func=0x8048414, call_site=0x804842d) at wrong.c:7
* 7 {
* (gdb) **bt**
* #0 0x0804841d in __cyg_profile_func_enter (this_func=0x8048414, call_site=0x804842d) at wrong.c:7
* #1 0x0804842d in __cyg_profile_func_enter (this_func=0x8048414, call_site=0x804842d) at wrong.c:7
* #2 0x0804842d in __cyg_profile_func_enter (this_func=0x8048414, call_site=0x804842d) at wrong.c:7
* ...
* #30 0x0804842d in __cyg_profile_func_enter (this_func=0x8048414, call_site=0x804842d) at wrong.c:7
* #31 0x0804842d in __cyg_profile_func_enter (this_func=0x8048414, call_site=0x804842d) at wrong.c:7
* #32 0x0804842d in __cyg_profile_func_enter (this_func=0x8048414, call_site=0x804842d) at wrong.c:7
```
* 既然 "__cyg_profile_func_enter" 是 function hook,則本身不得也被施以 "function instrument",否則就無止盡遞迴了,不過我們也可以發現一件有趣的事情:
```
* $ **nm wrong | grep 8048414**
* 08048414 T __cyg_profile_func_enter
```
* 如我們所見,"__cyg_profile_func_enter" 的位址被不斷代入 __cyg_profile_func_enter function arg 中。GNU binutils 裡面有個小工具 addr2line,我們可以該工具取得虛擬位址對應的行號或符號:
```
* $ **addr2line -e wrong 0x8048414**
* /home/jserv/HelloWorld/helloworld/instrument/wrong.c:7
```
* 就 Linux 應用程式開發來說,我們可透過這個機制作以下應用:
* 撰寫特製的 profiler
* 取得執行時期的 Call Graph
* 置入自製的 signal handler,實做 backtrace 功能
* 模擬 Reflection 機制
* [Java reflection 參考](http://jjhou.boolan.com/javatwo-2004-reflection.pdf)

但 profiling 的成本在許多環境,像是雲端運算來說,實在太沈重,所以 Google 提出透過 perf 工具來取得 profiling 資料的 AutoFDO:

* [Accelerating the Core of the Cloud](http://events.linuxfoundation.org/sites/events/files/slides/Accelerating%20the%20Core%20of%20the%20Cloud%20LCNA%20davest.pdf), Intel
* Core software optimization: a strategy
* Case Study: OpenStack


* PLT vs. GOT
* [](http://refspecs.linuxfoundation.org/ELF/zSeries/lzsabi0_zSeries/x2251.html)[http://refspecs.linuxfoundation.org/ELF/zSeries/lzsabi0_zSeries/x2251.html](http://refspecs.linuxfoundation.org/ELF/zSeries/lzsabi0_zSeries/x2251.html)
[Skymizer](https://www.facebook.com/skymizer/) 針對日前釋出的 GCC 6.1,翻譯部份 [GCC Release note](https://gcc.gnu.org/gcc-6/changes.html):
* 上半段: [](http://blog.skymizer.com/gcc_6_1/)[http://blog.skymizer.com/gcc_6_1/](http://blog.skymizer.com/gcc_6_1/)
* 下半段: [](http://blog.skymizer.com/gcc_6_1_2/)[http://blog.skymizer.com/gcc_6_1_2/](http://blog.skymizer.com/gcc_6_1_2/)
"so you all hate on C++. all right. all right. tell me. does your favorite language have a concept of friendship, then? eh?
thought so." from [twitter](https://twitter.com/whitequark/status/756614865364525056)
"C++ Is my favorite garbage collected language because it generates so little garbage."
- Bjarne Stroustrup ([origin](http://www.stroustrup.com/bs_faq.html#really-say-that))
## 隨堂測驗
- [ ]Quiz-0 : Give you the prototype of the function:
int p(int i, int N);
use it to print the numbers from i up to N and then down to i again, one number per line
Don’t use those keywords: do, while, for, switch, case, break, continue, goto, if.
Don’t use ’:?’
You can only use ONE statement!
==>
```C=
int p(int i, int N)
{
return (i < N && printf("%d\n", i) && !p(i + 1, N))
|| printf("%d\n", i);
}
```
- [ ]Quiz-1 : 只能使用位元運算子和遞迴,在C程式中實做兩個整數的加法
void add(int a, int b) { ... }
=>
```C=
int add(int a, int b) {
if (b == 0) return a;
int sum = a ^ b; // 相加但不進位
int carry = (a & b) << 1; // 進位但不相加
return add(sum, carry);
}
```
Reference: [](http://stackoverflow.com/questions/14695051/how-to-simulate-a-4-bit-binary-adder-in-c)http://stackoverflow.com/questions/14695051/how-to-simulate-a-4-bit-binary-adder-in-c
- [ ]Quiz-2 : 給定一個 singly-linked list 結構:
```C=
* typedef struct _List {
* struct _List *next;
* int val;
* } List;
```
實做得以交換存在 list 中兩個節點的函式: (考慮 HEAD 與 TAIL)
int swap_list(List **head, List *a, List *b) {
...
}
==>
[](https://github.com/shengwen1997/sys2016_homework/blob/master/linked_list_swap/main.c)https://github.com/shengwen1997/sys2016_homework/blob/master/linked_list_swap/main.c