# 2017q3 Homework1 (phonebook)
contributed by <`ChiuYiTang`>
[github](https://github.com/ChiuYiTang/phonebook.git)
### Reviewed by `st9007a`
- 在**原始程式分析**中 `defined(__GNUC__)` 跟 `diff_in_second` 的敘述寫反了
- 在**優化過程**中的**方法一**,計算 L1 cache 可容納多少原始資料的算法為 $32k\ bytes \div 136\ bytes = 32 \times 1024 \div 136 = 240.941176471$,原始算法中乘上 8 的用意是 ?
- 在**優化過程**中的**方法二**,雖然執行速度變快了,但是 cache miss 上升了,應該要解釋其原因
- 在**優化過程**中的**方法三**,優化過程是針對 cache line 大小調整資料結構,如果補上 cache miss 的比較會更有說服力
- 在 [phonebook_opt.h](https://github.com/ChiuYiTang/phonebook/blob/master/phonebook_opt.h) 中,`MAX_TABLE_SIZE` 設定為 1024,可以說明一下選擇這個數字的理由
- 在 [main.c](https://github.com/ChiuYiTang/phonebook/blob/master/main.c) 中第 85 - 90 行,每次加入一筆資料就做一次 malloc 的效率不佳
- 在 [main.c](https://github.com/ChiuYiTang/phonebook/blob/master/main.c) 中,一個 hash table 就夠了,`tableHead` 這個變數的用意是 ?
- 在 [main.c](https://github.com/ChiuYiTang/phonebook/blob/master/main.c) 中,利用 `OPT` 來區分使用的優化方法可讀性不高,可以嘗試使用 gcc 的 -D 來處理
- 在 [Makefile](https://github.com/ChiuYiTang/phonebook/blob/master/Makefile) 中,用了 4 個 `CFLAGS` 來定義 gcc 編譯的優化程度,考慮這個 repo 的使用情境,可以整合成一個 `CFLAGS` ( 或者作者想比較 hash table方法 + -O0 跟 binary search tree + -O1 之間的效能,如果是的話,這點請無視 )
- 承上,在 `CFLAGS` 統一使用的狀況下,`Makefile` 在產生執行檔的部分可以寫得更精簡
- 在 [Makefile](https://github.com/ChiuYiTang/phonebook/blob/master/Makefile) 中,cache-test 可以用 for loop 讓它更精簡
- 在 [phonebook_bstbig.c](https://github.com/ChiuYiTang/phonebook/blob/master/phonebook_bstbig.c) 中,在 `findName` 的實作中,`root == NULL` 的判斷提前做可讀性比較高,也可以省掉 `current != NULL` 跟 `if(root)` 這兩個判斷
- 在 commit [1d2aeef38](https://github.com/ChiuYiTang/phonebook/commit/1d2aeef38f36e02004214c990d97b6e327e0600a) 中的 `main.c` 第 20 行再次 define MAX_TABLE_SIZE 的用意是 ? 在 [phonebook_opt.h](https://github.com/ChiuYiTang/phonebook/blob/master/phonebook_opt.h) 中已經 define 過了
- 執行檔不應該進 github:[phonebook_bstbig](https://github.com/ChiuYiTang/phonebook/blob/master/phonebook_bstbig),保持 repo 簡潔
## 開發環境
```
Ubuntu 16.04.5
Linux 4.4.0-96-generic
gcc version 5.4.0 20160609
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 8192K
```
`$ lscpu`
* Architecture: x86_64
* CPU op-mode(s): 32-bit, 64-bit
* Byte Order: Little Endian
* CPU(s): 8
* On-line CPU(s) list: 0-7
* Thread(s) per core: 2
* Core(s) per socket: 4
* Socket(s): 1
* NUMA node(s): 1
* Vendor ID: GenuineIntel
* CPU family: 6
* Model: 94
* Model name: Intel(R) Core(TM) i7-6700 CPU @ 3.40GHz
* Stepping: 3
* CPU MHz: 1261.187
* CPU max MHz: 4000.0000
* CPU min MHz: 800.0000
* BogoMIPS: 6816.00
* Virtualization: VT-x
* L1d cache: 32K
* L1i cache: 32K
* L2 cache: 256K
* L3 cache: 8192K
* NUMA node0 CPU(s): 0-7
## Astyle
#### 程式撰寫風格一致的重要
To format your file you can execute below command:
```
$ astyle --style=kr --indent=spaces=4 --indent-switches --suffix=none *.[ch]
style決定程式中,大括弧{ }的擺放方式。
indent=space決定程式中,每個縮排為設定數值的倍數。
indent-switches讓程式中 switch-case 的 case statements 對齊
suffix=none不保留格式化前的文件
```
利用此行指令設定程式風格,就可以自動格式化。
## 原始程式分析
* 主要分為一計算時間差的function `diff_in_second()`,以及main函數。
#### `main()`函數分為五大部份
1. 開啟/關閉phonebook檔案
2. 建立linked-list作為儲存區域
3. 計算時間差
4. 將phonebook資料append進linked-list裡
5. 找尋input character
#### 7:`#include IMPL`
參考gcc --help得知此為gcc -DIMLP=""的macro。觀察make file發現, gcc -Dname=definition 的東西會被翻譯成 #define name definition。
其中$@為Makefule裡的target,這邊可以替換phonebook_orig 或 phonebook_opt。
#### 17:`defined(__GNUC__)`
計算時間差的subfunction。
#### 52:`diff_in_second`
判斷編譯器是不是GCC。
#### 127:Memory leak 參考[你所不知道的C語言:函式呼叫篇](https://hackmd.io/s/SJ6hRj-zg)
觀察free(pHead),發現似乎只有free掉部份memory。
利用valgrind檢查 phonebook_orig:
`$ valgrind --leak-check=full ./phonebook_orig`
結果:
```
==3708== HEAP SUMMARY:
==3708== in use at exit: 47,586,264 bytes in 349,899 blocks
==3708== total heap usage: 349,906 allocs, 7 frees, 47,596,856 bytes allocated
```
可以發現malloc 349,906次卻只free掉7次,嘗試修改 main.c 中釋放記憶體的部份:
```clike=
entry *tmp;
while ((tmp = pHead) != NULL) {
pHead = pHead->pNext;
free(tmp);
}
```
重新檢查:
```
==3961== HEAP SUMMARY:
==3961== in use at exit: 0 bytes in 0 blocks
==3961== total heap usage: 349,906 allocs, 349,906 frees, 47,596,856 bytes allocated
==3961==
==3961== All heap blocks were freed -- no leaks are possible
```
## 未優化效能分析
`$ perf stat --repeat 100 -e cache-misses,cache-references,instructions,cycles ./phonebook_orig`
```
size of entry : 136 bytes
execution time of append() : 0.047000 sec
execution time of findName() : 0.005270 sec
Performance counter stats for './phonebook_orig' (100 runs):
4,774,624 cache-misses # 93.941 % of all cache refs ( +- 0.13% )
5,082,555 cache-references ( +- 0.20% )
261,003,454 instructions # 1.21 insns per cycle ( +- 0.02% )
215,517,588 cycles ( +- 0.28% )
0.059957913 seconds time elapsed ( +- 0.33% )
```
## 優化過程
### 方法一:透過有效資料縮減 struct 大小
* 優化前的Size of entry= 136 bytes,然而L1 Cache僅32K bytes,最多放置32 * 1024) / (136 * 8) = 30.12 筆資料。於幾十萬筆資料查找情況下,將造成嚴重的Cache miss。
* 根據程式碼可發現,無論findName()或是Append()只和『last name』有關,因此透過刪減原先struct大小,只需儲存『last name』,並透過pointer to entry *detail指向儲存詳細資訊之struct。
* 透過此修正,使得原先Size of entry變為32bytes。L1 Cache即可放入(32 * 1024) / (32 * 8) = 128 筆資料,增加Cache hit之機率。
```clike=
typedef struct __PHONE_BOOK_ENTRY {
char firstName[16];
char email[16];
char phone[10];
char cell[10];
char addr1[16];
char addr2[16];
char city[16];
char state[2];
char zip[5];
struct __PHONE_BOOK_ENTRY *pNext;
} DetailEntry;
typedef struct __LAST_NAME_ENTRY{
char lastName[MAX_LAST_NAME_SIZE];
DetailEntry *detail;
struct __LAST_NAME_ENTRY *pNext;
} entry;
```
#### 優化結果
```
size of entry : 32 bytes
execution time of append() : 0.041626 sec
execution time of findName() : 0.001664 sec
Performance counter stats for './phonebook_opt' (100 runs):
1,632,174 cache-misses # 70.076 % of all cache refs ( +- 0.31% )
2,329,162 cache-references ( +- 0.47% )
244,053,016 instructions # 1.79 insns per cycle ( +- 0.02% )
136,425,581 cycles ( +- 0.75% )
0.038485186 seconds time elapsed ( +- 0.79% )
```

### 方法二:Hash function
* 原先使用之linked-list是循序搜尋,若可以透過Hash function將資料有效地分類至不同的address上,即可提升效率。
* 如何選擇Hush function,以降低發生碰撞之頻率過高,失去雜湊函數的意義。
* 參考[不同Hash function比較](https://https://www.byvoid.com/zhs/blog/string-hash-compare)。
* 採用其所推薦之`BKDR hash function`:
```clike=
unsigned int BKDRHash(char *str)
{
unsigned int seed = 131;
unsigned int hash = 0;
while(*str)
hash = hash * seed + (*str++);
return (hash % MAX_TABLE_SIZE);
}
```
而當碰撞發生時,即透過鏈結(Chaining)碰撞解決方法。
(可直接套用原先append()以及findName()的 linked-list 操作)
[ [source](http://libeibei.cn/2016/10/13/algorithms-data-structures-1/) ]
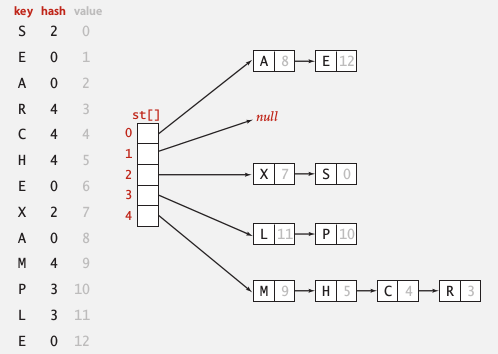
#### 優化結果
```
size of entry : 32 bytes
execution time of append() : 0.052022 sec
execution time of findName() : 0.000002 sec
Performance counter stats for './phonebook_opt' (100 runs):
586,290 cache-misses # 39.869 % of all cache refs ( +- 0.42% )
1,470,529 cache-references ( +- 1.20% )
233,415,491 instructions # 1.69 insns per cycle ( +- 0.02% )
137,911,226 cycles ( +- 0.73% )
0.038492741 seconds time elapsed ( +- 0.92% )
```

### 方法三:Binary search tree
* 翻閱資料結構書籍搜尋的章節,除了Hash table之外的方法,就屬Binary search tree為主要了,並參考了[ryanwang522](https://hackmd.io/s/Sk-qaWiYl)實作後,也讓我來試試看。
* 字串放進BST裡所依靠的規則為`strcasecmp()`的回傳值為依據。
* 查詢`strcasecmp()`的結果:
```
The strcasecmp() function performs a byte-by-byte comparison of the
strings s1 and s2, ignoring the case of the characters. It returns
an integer less than, equal to, or greater than zero if s1 is found,
respectively, to be less than, to match, or be greater than s2.
```
* 實作
* 參考[Sorted Linked List to Balanced BST](https://http://www.geeksforgeeks.org/sorted-linked-list-to-balanced-bst/)發現,只要linked-list sorted,即可以直接利用recursion建立BST。
```clike=
int Length(entry *head)
{
int count = 0;
entry *current = head;
while (current != NULL) {
count++;
current = current -> pNext;
}
return count;
}
treeNode *BuildBST(entry **headRef, int length)
{
if(length <= 0)
return NULL;
treeNode *left = BuildBST(headRef, length/2);
treeNode *root = (treeNode *) malloc(sizeof(treeNode));
root->entry = *headRef;
root->left = left;
*headRef = (*headRef)->pNext;
root->right = BuildBST(headRef, length - (length / 2 + 1));
return root;
}
```
* 構建之BST節點
```clike=
typedef struct __TREE_NODE {
entry *entry;
struct __TREE_NODE *right;
struct __TREE_NODE *left;
} treeNode;
```
#### 優化結果
```
size of entry : 32 bytes
execution time of append() : 0.058509 sec
execution time of findName() : 0.000000 sec
Performance counter stats for './phonebook_bst' (100 runs):
1,603,989 cache-misses # 73.761 % of all cache refs ( +- 0.15% )
2,174,566 cache-references ( +- 0.33% )
283,643,852 instructions # 1.85 insns per cycle ( +- 0.02% )
153,239,845 cycles ( +- 0.31% )
0.042808917 seconds time elapsed ( +- 0.62% )
```

* 整體效能比hash table更好
* 然而在[ryanwang522](https://hackmd.io/s/Sk-qaWiYl)實作之基礎下希望能進一步優化
### 方法三進階:針對 Cache line 調整 BST 結構
#### Cashe line
* CPU Cashe中最小的儲存單位
* 主流CPU Cache Line大小為 64 bytes
* 若能將每個 BST node 的大小剛好等於 cache line 大小或其一半,或許能降低一個 node 需要填充兩個 cache line 造成的呼叫 cache 的時間。
* 修改之BST節點為 64 bytes (1 cache line)
```clike=
typedef struct __TREE_NODE {
entry *entry[6];
struct __TREE_NODE *right;
struct __TREE_NODE *left;
} treeNode;
```
#### 優化結果

* 對齊 cache line 後的結果又比原先的 BST, 於 `append()` 的部份更加有效率。
> 對於此微小的差異感到存疑...........[name=ChiuYiTang]
## 問題探討
### 本例選用的 dataset (也就是輸入電話簿的姓名) 是否存在問題?
* 有代表性嗎?跟真實英文姓氏差異大嗎?
* 本實驗之 dataset 大多為無意義之英文字母組合,與真實姓名具備隨人文與時代變化等變因,有極大之差距。
* 真實姓名的分佈,以獨立隨機變數之角度來看,較趨近於常態分佈,相較於本實驗之 dataset 為均勻分佈,彼此差異甚大。
* 資料難道「數大就是美」嗎?
* 需要有意義的資料,避免許多無效資料來填充『數大』。
* 如果我們要建立符合真實電話簿情境的輸入,該怎麼作?
* 透過網站產生大量名字。
* 透過政府機構蒐集普查資料。
* 透過公司團體(eg.[whoscall](https://whoscall.com/zh-TW/))蒐集數據資料庫。
## 參考資料
[strcasecmp() — Compare Strings without Case Sensitivity](https://www.ibm.com/support/knowledgecenter/en/ssw_ibm_i_72/rtref/strcasecmp.htm)
[常见数据结构(一)-栈,队列,堆,哈希表](http://libeibei.cn/2016/10/13/algorithms-data-structures-1/)
[什么是Cache Line](http://cenalulu.github.io/linux/all-about-cpu-cache/)
 Sign in with Wallet
Connect another wallet
Sign in with Wallet
Connect another wallet