2016q3 Homework5 (jit-compiler)
===
contributed by <`kobe0308`>, <`youchihwang`>, <`vjux`>, <`mingnus`>
## 作業說明
[A09: jit-compiler](https://hackmd.io/s/SJ7AZJv1e) ([source](https://mimihalo.hackpad.com/ep/pad/static/fF2g9dyypfz))
## 環境設定
* fork [jit-construct](https://github.com/sysprog21/jit-construct)
* install below packages (see `README.md`)
```shell
$ sudo apt-get update
$ sudo apt-get install build-essential
$ sudo apt-get install gcc-5-multilib
$ sudo apt-get install lua5.2 lua-bitop
$ sudo apt-get install gcc-arm-linux-gnueabihf
$ sudo apt-get install qemu-user
```
因為 github 上的 source code 是在 Ubuntu 16.04 LTS 上開發的,某些安裝套件不適用在 Ubuntu 14.04 LTS ,以下是針對Ubuntu 14.04 LTS 所做的修改如下:
* Modify 1: Ubuntu 14.04 沒有 gcc-5-multilib 套件
```shell
$ sudo apt-get install gcc-5-multilib
Reading package lists... Done
Building dependency tree
Reading state information... Done
E: Unable to locate package gcc-5-multilib
```
改為
```shell
$ sudo apt-get install gcc-multilib
```
* Modify 2: gcc-arm-linux-gnueabihf 安裝問題
```
$ make run-compiler
./compiler-x86 progs/hello.b > hello.s
cc -m32 -o hello-x86 hello.s
x86: Hello World!
./compiler-x64 progs/hello.b > hello.s
cc -o hello-x64 hello.s
x64: Hello World!
./compiler-arm progs/hello.b > hello.s
arm-linux-gnueabihf-gcc -o hello-arm hello.s
make: arm-linux-gnueabihf-gcc: Command not found
make: *** [run-compiler] Error 127
$ arm-linux-gnueabihf-gcc
The program 'arm-linux-gnueabihf-gcc' is currently not installed. You can install it by typing:
sudo apt-get install gcc-arm-linux-gnueabihf
```
但若再安裝一次
```
sudo apt-get install gcc-multilib
```
則會自動地,
```
Removing gcc-arm-linux-gnueabihf (4:4.8.2-1) ...
```
屆時./make run-compiler,會使用到arm-linux-gnueabihf-gcc而發生錯誤。
在 [How to install the latest g++(currently 5.1) in Ubuntu(currently 14.04)](http://askubuntu.com/questions/618474/how-to-install-the-latest-gcurrently-5-1-in-ubuntucurrently-14-04) 找到了解決方式,
>> Ubuntu Linux 的版本很關鍵,儘量安裝最新的穩定版本,然後用 `sudo apt-get update ; sudo apt-get dist-upgrade` 升級 [name=jserv]
```
sudo add-apt-repository ppa:ubuntu-toolchain-r/test
sudo apt-get update
sudo apt-get install gcc-5-multilib
```
即可安裝gcc-5-multilib,又不會Removing gcc-arm-linux-gnueabihf。
* Modify 3: 修正 `README.md` 筆誤
```shell
$ ./interpreter progs/hello.bf
```
改為
```shell
$ ./interpreter progs/hello.b
```
>>中英文關鍵字中間請記得以空白間隔喔!
>>[color=red][name=課程助教]
>> 任何名詞嗎? e.g., 中文 english 中文 [name=mingnus]
>>> 沒錯,這樣比較清楚=w=
>>> 下面有部份已經幫忙填空囉~[color=red][name=課程助教]
## Brainfuck & JIT Tryout
### Programs
* interpreter
* compile-{x86|x64|arm}
brainfuck compiler, 輸出x86/x64/arm ASM
* jit-{x86|x64|arm}
* jit0-{x64|arm}
測試用 jit, 相當於執行下列 machine code。N為使用者輸入的數值
```asm
mov eax, N
ret
```
reference: [Basic JIT]( https://nickdesaulniers.github.io/blog/2013/04/03/basic-jit/)
* test_stack
### Makefile targets
* test
測試 test_stack 及 jit0-{x64|arm}
* run-compiler
測試所有版本的 compiler (x86, x64, and arm)
測試方式: 編譯 hello.b, 再以 gcc 組譯並連結為 binary
* run-jit-{x86|x64|arm}
測試特定版本的 jit compiler (使用hello.b)
* bench-jit-{x86|x64}
執行 tests/bench.py, 測試 jit compiler 編譯效能 (預設使用 hanoi.b, awib.b, and mandelbrot.b), 並用程式輸出驗證編譯的正確性
### Sample Brainfuck Programs
#### [awib: a brainfuck compiler written in brainfuck](http://awibiswritteninbrainfuck.blogspot.com/) ([github](https://github.com/matslina/awib)) ([Technical Report](https://www.nada.kth.se/kurser/kth/2D1464/awib.pdf))
可輸出 C, Ruby, Go, 及 tcl 等語言, 或輸出 i386 binary
範例用法:
```shell
## Compile hello.b
$ ./jit-x64 progs/awib.b < progs/hello.b
## Compile nothing. The output is a blank program
$ echo -n -e '\x00' | ./jit-x64 progs/awib.b
```
作業裡附的awib.b版本是2010-10-03的0.3版 (git commit 90520312e), 有點舊
awib.b 檔案末端含有一個用 C 寫成 bf 直譯器。我們可用 gcc 編譯 awib.b, 以直譯方式執行 awib。編譯方法見README
## Brainfuck 程式語言
### Instructions
* Pointer operation: `>` `<`
* Math operation: `+` `-`
* IO operations: `.` `,`
* Loop operations: `[` `]`
### 範例: hello.b (The program to print "Hello World!")
```brainfuck
++++++++++[>+++++++>++++++++++>+++>+<<<<-]
>++.>+.+++++++..+++.>++.<<+++++++++++++++.
>.+++.------.--------.>+.>.
```
我們用 awib 0.3 將其編譯為 C code, 觀察其執行方式
```shell
$ ./jit-x64 progs/awib.b < progs/hello.b > hello.c
$ gcc -E hello.c -o /tmp/hello.c
$ astyle --style=kr --indent=spaces=4 --indent-switches --suffix=none /tmp/hello.c
```
:::info
註: awib 使用以下九個 C macros 表示 brainfuck operations, 其中`[-]`已被最佳化為macro `e9`
```clike
#define e9(x) *p=0;
#define e8(x) }
#define e7(x) while(*p){
#define e6(x) p+=x;
#define e5(x) p-=x;
#define e4(x) putchar(*p);
#define e3(x) *p-=x;
#define e2(x) c=getchar();if(c>=0)*p=c;
#define e1(x) *p+=x;
```
:::
awib 輸出的 hello.c:
```clike
char buf[0xffff];
int main()
{
char *p=buf;
int c;
*p+=10;
while(*p) {
p+=1;
*p+=7;
p+=1;
*p+=10;
p+=1;
*p+=3;
p+=1;
*p+=1;
p-=4;
*p-=1;
}
p+=1;
*p+=2;
putchar(*p);
p+=1;
*p+=1;
putchar(*p);
*p+=7;
putchar(*p);
putchar(*p);
*p+=3;
putchar(*p);
p+=1;
*p+=2;
putchar(*p);
p-=2;
*p+=15;
putchar(*p);
p+=1;
putchar(*p);
*p+=3;
putchar(*p);
*p-=6;
putchar(*p);
*p-=8;
putchar(*p);
p+=1;
*p+=1;
putchar(*p);
p+=1;
putchar(*p);
return 0;
}
```
Execution steps:
column 1 ~ 10 表示迴圈迭代時 array `buf` 的狀態, 剩下的columns 表示輸出過程中 array 的狀態

>>請避免用圖片表示文字訊息
>>[color=red][name=課程助教]
本程式示範如何使用 5 bytes buffer 輸出含九種字元的字串 (helowrd!及換行字元)。實際上用於字元輸出的只有 `buf[1:4]`,`buf[0]` 是迴圈 counter
---
## 文件心得
### [Compiling brainfuck to java in brainfuck](http://calmerthanyouare.org/2014/09/30/brainfuck-java.html)
* But brainfuck is also turing-complete and as such capable of solving any and all computational problems.
>brainfuck 是一個圖靈機,可以解決全部的計算機問題。[name=王佑誌]
* Awib is a brainfuck compiler written entirely in brainfuck. It has multiple compiler backends making it capable of compiling brainfuck to well-performing executables (Linux IA32 ELF) as well as to several programming languages (C, Tcl, Ruby and Go)
>這文章是說 Awib 有多個 compiler 後端處理,所以可以將 brainfuck 的 code,compile 成C語言嗎?[name=王佑誌]
>> awib 可以將 Brainfuck 程式轉為 C 語言程式碼 (translator),也可以輸出對應的 ELF 執行檔 (自己處理 relocation!)。輸入是 Brainfuck,輸出則是資料,只是比較特別罷了 [name=jserv]
* Brainfuck’s computational model is simple. There is a contiguous memory area of cells and a pointer into said memory. Although the exact size can differ between implementations, it is generally safe to assume that each memory cell has 8 bits or more. All cells are initially set to 0.
>Brainfuck 的計算機模型是簡易的,有一個連續記憶體且每一個 cell 是8位元或更多並初始化為0。[name=王佑誌]
* A great way of grokking the brainfuck language is to implement it. The process of writing a compiler or an interpreter makes both syntax and semantics a lot clearer. When you think about it, should it not be even more educational to write the compiler itself in brainfuck? Perhaps not a bullet proof argument, but that’s what led to the creation of awib. It’s a brainfuck compiler written in brainfuck.
>了解 brainfuck language 的最好方法就是去寫 brainfuck 的 compiler 及直譯器。[name=王佑誌]
* Compilers are commonly composed of one or more frontends and one or more backends. The frontends accept source code as input and produce an intermediary representation (IR) as output. The backends in turn accept IR as input and produce executable programs as output. Commonly there will also be an optimization step between frontend and backend. GCC is a great example of a compiler structured like this; it has frontends for e.g. C, C++ and Fortran; it has backends for e.g. arm, sparc and i386.<br>The awib compiler is structured in the same way. The frontend reads brainfuck source code from stdin, translates it into IR and performs a couple of optimizations. Control is then handed over to the appropriate backend which translates the IR into executable binaries or into another programming language.
```
+------- awib ---------------------------------------+
| +----------+ +-----------+ +---------+ |
brainfuck | | | IR | | IR | | | executable
----------+--->| Frontend |---->| Optimizer |---->| Backend |--+------------>
| | | | | | | |
| +----------+ +-----------+ +---------+ |
+----------------------------------------------------+
```
>compiler 一般是由一個或多個 frontend 及一個或多個 backend 及 Optimizer 所組成, frontend 接受 source code 並產出 IR, Optimizer 接受IR做優化並產出優化後的 IR , backend 接受優化過後的 IR,並產出可執行檔,GCC 就是這樣的 compiler structure ,接受 C, C++, ...., 輸出 ARM、 386, ......<br>
awib compiler 也是這樣的structure, frontend 從 stdin 讀取 brainfuck code,轉成 IR,做兩次優化,再由 backend 接手 IR 輸出執行檔或是轉成另一個程式語言。[name=王佑誌]
>> awib 的設計很先進,具備現代編譯器的特徵。 [name=jserv]
* Awib’s IR itself is like brainfuck on steroids; it operates on the same memory model but is much more expressive. A good example is the IR instruction ADD(). When presented with a sequence of lets say 5 adjacent “+” instructions, awib’s frontend will pass on the IR instruction ADD(5). Similar instructions of course exists for subtraction (“-“) and for moving the pointer (“>” and “<”).
>Awib’s IR itself is like brainfuck 這句話再加上 on steroids 要怎麼理解呢?[name=王佑誌]
>> 我們說某件事物或某個活動 "on steroids",意思是這件事情或活動到了一個極致 from [source](http://thomastagebuch.pixnet.net/blog/post/18526990) [name=jserv]
>這裡有一個 IR 的 ADD() 做為一個好例子,當 awib frontend 接收到有5個緊連"+"的指令,將會輸出IR指令 ADD(5),類似的做法也可使用在 "-",">","<"
* Although compiling brainfuck to i386 Linux executables is a pretty hairy process - and the 386_linux backend certainly is a tad complex - many of the backends are conceptually simple. The Ruby, Go, Tcl and C backends operate by iterating over the IR in a single pass. For each instruction the compiler will output a single piece of code and in some cases also the decimal representation of the instruction’s argument. E.g., the C backend translates the instruction ADD(47) into *p+=47;.
>The Ruby, Go, Tcl and C backends operate by iterating over the IR in a single pass. 這要怎麼理解? The Ruby, Go, Tcl and C 的後端,只會重覆地執行?[name=王佑誌]
* Naively failing
At first glance it would seem as if Java could be treated in the same way as any other programming language. After all, we previously were able to define brainfuck in terms of Java, so why wouldn’t it work? This was the initial approach adopted by the awib development team (read: me) and it certainly looked promising.
```
$ ./awib < hello.b > Bf.java
$ javac Bf.java
$ java Bf
Hello World!
```
Excellent. After implementing, polishing, and testing, it was finally time to release. But before we do, let’s make sure that this new version of awib can compile itself. It would be embarrassing if the compiler wasn’t self-hosting.
```
$ ./awib < awib-0.4.b > Bf.java
$ javac Bf.java
Bf.java:39: error: code too large
private void _0() {
^
```
1 error
Facepalm…
As it turns out, Java has a strict 64k limit on the size of compiled methods. For a sufficiently large input, the naive mapping will result in a method much larger than that. As demonstrated by a 1999 bug report, several other Java code generators have been affected by this limit over the years and it’s unlikely to disappear anytime soon. We need a different approach.
The path forward is clear: we must break up our program into multiple methods and somehow have them be invoked in the correct order. We have immediately been moved from the happy land of trivial IR to Java mappings to someplace worse.
>開發團隊原先認為可以將 brainfuck code 轉成java直接執行,但沒想到遇到一個問題, java 的 method 的大小限制為 64KB,於是將 code 拆成若干個 method,使用某些方法正確地執行程式,[name=王佑誌]
>We have immediately been moved from the happy land of trivial IR to Java mappings to someplace worse.這要怎麼翻呀![name=王佑誌]
>> 可翻譯為:我們原本設想可輕易將 IR 轉成 Java bytecode,但如今這件事變難了 [name=jserv]
* A method for splitting methods
One option for circumventing the 64k limit is to simply create a new method for each loop body encountered. Implementing this would be a piece of cake in most programming languages: compile non-loop instructions as usual, recursively compile loop bodies, attach the compiled loops to a list of methods and finally append these method declarations at the end of the output before returning.
>為了避開 java 64kb method 大小的限制,其中一個方法是為每一個 loop body(迴圈主體)建立一個 method,大部分的程式語言都容易達成,且一如往常地編譯 non-loop 指令,遞迴地編譯 loop body,並將編譯好的 loop 加到 method list 中,
> finally append these method declarations at the end of the output before returning. 這段話要如何理解呢?output 指得是什麼呢?[name=YouChih Wang]
Alas, brainfuck does not support recursion and maintaining the method list will require a lot of scanning back and forth over the memory area (no random memory access in brainfuck, remember?) Turning the recursive implementation into an iterative one would require introducing a stack, adding further complexity.
>很遺憾地, brainfuck 不支援遞迴也不支援維護 method list,因為需要在 memory 中來回地存取(brainfuck 沒有支援隨機存取 memory)使用迴圈來實作遞迴需要引入堆疊,這會顯得更複雜。[name=YouChih Wang]
What we want is a way of compiling the IR into Java in a single pass, without copying code around and only using very simple data structures. Here’s one way to do it:
>in a single pass ? 這是指什麼?這是指說只掃描 source code 一次,不做優化嗎?[name=YouChih Wang]
```
count = 1
for op in input
...
if op = [
print " while (mem[p] != 0) {
print " method_" + count + "();"
print " }"
print " method_" + (count + 1) + "();"
print "}"
print "private void method_" + count + "() {"
stack.push(count + 1)
count += 2
if op = ]
print "}"
print "private void method_" + stack.pop() + "() {"
...
```
>以上這段 code 是將 brainfuck 的 source code 切成一段一段,讓每一段 code 不要超過 64kB
>遇到'['就以目前的 method number 來編號,並使用 '}{' 分開 code,
>並且 method number + 1再 push 到 stack,
並將目前的 method 號碼加2指定為新的 method 號碼,
遇到 ']' 就使用 pop stack 做為新的 method 號碼,並使用 '}{' 分開 code。
>舉例:
>m1 : method1
> [] -> }{m1}{m2
> [[]] -> }{m1}{m3}{m4}{m2
> [[][]] -> }{m1}{m3}{m4}{m6}{m5}{m2
> [][] -> }{m1}{m2}{m4}{m3
> 每個 {} 都是等待要被轉成一個method。[name=YouChih Wang]
This executes in a single pass over the IR and only requires us to maintain a counter and a stack of integers (previous counter values). Much more brainfuck-friendly.
>以上是以 single pass 掃描 IR,而切割 code 的方法僅要 counter 及 stack 即可完成,讓 brainfuck 看起來更友善。
>single pass 相對於 multi pass,具有速度快的優點,請參考 [One-pass compiler](https://en.wikipedia.org/wiki/One-pass_compiler#Advantages)
>[name=YouChih Wang]
Representing large integers
As mentioned, cells in the memory area can’t be assumed to be larger than 8 bits, so a single cell counter can not be expected to count beyond 255 (28-1). The chosen algorithm will increment the counter twice for each loop encountered so single cell counters won’t allow more than 127 loops being compiled. Not nearly enough for anything but the smallest of programs.
>brainfuck 的 memory cell 不能大於 8 bits,所以只可以計算到 255 ( 2 的 8 次方 -1 ),而且切割 source code 的方法中,每個 loop 中,counter 一次加 2,最多只可以 compile 127 個 loop,實在太小了。[name=YouChih Wang]
Our counters must span multiple cells and it seems as if two cells, giving us 16 bits, should do the trick. 32767 ((216-1) / 2) loops ought to be enough for anybody, no?
>為了解決 count 的範圍太小,採用了兩個memory cell 合併計算,16 bit 可以算到 32767 (( 2 的 16 次方 -1 ) / 2 ) loops[name=YouChih Wang]
The most straightforward way to implement this is to start both cells at 0 and on each increment check if the least significant cell holds 255. If it does then we reset it to 0 and increment the most significant cell. If it does not then incrementing the least significant cell is enough.
```
function increment(hi, lo):
if lo < 255:
return (hi, lo + 1)
return (hi + 1, 0)
```
>最直覺的方法是將兩個 memory cell 初始化為0,每次增加 count 時,都去檢查 least significant cell 是否為255,若是 255 則將 reset 為0,並遞增 the most significant cell。[name=YouChih Wang]
In practice, always having to do a comparison against 255 becomes annoyingly expensive. Brainfuck only allows us to check if cells are zero or non-zero, so checking for an non-zero value X requires first subtracting X from the cell, then checking for zero, then restoring the cell’s original value. An easier approach is to initialize the counters to 255 and decrement instead of incrementing:
```
function decrement(hi, lo):
if lo != 0:
return (hi, lo - 1)
return (hi - 1, 255)
```
>因為 brainfuck 只能檢查 memory cell 是否為 0 ,來判斷是否執行 loop ,所以檢查某個變數是否到達某個數值,可以將變數減去數值,若為非 0,代表未到達,則需回存原有數值,若為 0,代表到達。
>一個最簡單的方法是將 count 初始為 255,使用遞減代替遞增,並檢查是否為 0。[name=YouChih Wang]
The difference may appear subtle in our high-level pseudo code, but it makes a real difference when implementing in brainfuck:
```
+<-[>-]>[>]<[+++++++++++++++[-<++++++++++++++++>]<-<->>]
```
Beautiful. This is actually a little bit different from the pseudo code decrement. Deciphering precisely how is left as an exercise to the reader.
>上面這段程式,看不懂,再看。[name=YouChih Wang]
Storing the stack
Implementing a stack in a random access memory model is straightforward: maintain an array of stack frames and use an integer variable to keep track of where the top frame resides. A stack push means incrementing the integer and writing a frame; a stack pop means reading a frame and decrementing the integer.
>使用一個隨機存取記憶體實作一個 stack 最直覺的方法是需要一個 array 及一個指向 top cell 的變數, push 動作是遞增 top variable 並寫進 data 至 stack , pop 動作提取 stack 的 data , 並遞減 top variable。 [name=YouChih Wang]
Brainfuck’s memory model changes some things. The lack of random access makes the stack top variable redundant and the lack of dynamic memory allocation requires us to dedicate a stack segment of the memory area ourselves. We also need to make sure that the stack can grow a fair bit to allow for the compilation of programs with many levels of nested loops.
>Brainfuck's 特殊 memory model 導致它需要 不同的 stack 實作方法,因為沒有隨機存取使得 stack top variable 是無用處,因為沒有動態記憶體配置,使得我們需要製做一個 stack segment ,然後得確認 stack 可以不斷地成長為了編譯巢狀 loop 的程式。[name=YouChih Wang]
+---------------+---+---+---+- -+---+---+------------+
| stack segment | 0 | 1 | 1 | ... | 1 | 0 | IR segment |
+---------------+---+---+---+- -+---+---+------------+
The diagram above illustrates awib’s memory layout in this phase of the compilation. Each IR instruction is two cells or larger so processing an instruction effectively frees up two cells for the stack segment. Since each stack frame spans two cells, this guarantees that the stack won’t expand into and ruin the IR segment.
>以上這張圖是在說明 awib's 在編譯時期的 memory 陳列。每一個 IR 指令佔了兩個或甚至更多的 memory cells 所以當在處理一個 IR 指令時可以釋放兩個 memory cells 的空間給 stack segment. 也因為每一個 stack frame 佔了兩個 memory cells, 而保證 stack 將不會擴張、破壞 IR segment。[name=YouChih Wang]
Most instructions processed will not be loops, so we can expect the area between the IR and the stack to grow larger and larger. We won’t be able to move the pointer to the stack using a constant number of ‘<’ instructions. One option would be to maintain a counter of the number of cells between the two segment and use that to maneuver between the segments. An easier solution is to fill the gap with non-zero cells, in our case 1’s, so that we can traverse the gap using a simple brainfuck idiom:
```
[<]
```
>大部分的指令都不是迴圈,所以可以預期 IR 和 stack 之間的區域會愈來愈大,範圍是會變動,因此不能使用固定數量 '<' 指令來移動 pointer 到 stack segment。有一個方式是維護一個 counter,其值是兩個 segment 之間 memory cell 的數量,並使用 counter 來回移動 IR 和 stack segment。一個較簡易的解決方式是在 IR 和 segment 之間的 gap 都填入非 0 值,在我們的範例是填 1,所以我們可以使用指令 [<] 來穿過 gap。[name=YouChih Wang]
This snippet opens a loop, moves the pointer a single step left and then closes the loop. Since brainfuck loops only terminate when the cell currently pointed at is zero, the loop will move the pointer leftwards over the gap until the cell holding 0 is reached. Replacing the ‘<’ with a ‘>’ can obviously be used to move back to the IR segment.
>這段 code 執行一個迴圈,將 pointer 一步一步往左移,然後跨過 gap 直到所指的 memory cell 為0然後結束迴圈[name=YouChih Wang]
Where did this get us?
>這怎麼翻呢?[name=YouChih Wang]
Putting all this together resulted in an awib backend that appears to function as it should. It passes all of awib’s unit and system tests and successfully compiles awib itself. The commented source code of the backend is available here.
>整合上述的程式碼後, awib backend 似乎就可以達到應該所要的功能,也通過全部的 awib's unit 和 system 測試,並成功地 compile awib 自己本身。注釋過的 backend source code [在這](https://code.google.com/p/awib/source/browse/trunk/lang_java/backend.b?spec=svn117&r=116)。[name=YouChih Wang]
To try it out, just download awib-0.4.b and follow the instructions in the file. Awib is, as of version 0.2, polyglot in C, Tcl and bash so you can easily bootstrap it locally without installing any other brainfuck interpreter or compiler. Remember to prepend the string “@lang_java” to your brainfuck code to instruct awib to use the Java backend.
>試驗它,只要下載 awib-0.4 和照著檔案中的指令。 Awib 自從 0.2 版後就是使用多種程式語言,如C, Tcl, bash 所以你可以不需要安裝任何其它 brainfuck interpreter 或是 compiler 就可以輕易地 bootstrap Awib。記得要使用 "@lang_java" 字串在您的 brainfuck source code 中去命令 awib 使用 Java backend .[name=YouChih Wang]
That was all. Thanks for reading.
---
### [Interpreter, Compiler, JIT](https://nickdesaulniers.github.io/blog/2015/05/25/interpreter-compiler-jit/)
* Interpreter
* 根據 compiler 課本《Compilers, 2/e》及 Wikipedia, interpreter 包含以下幾種型式:
* 將 source code 轉譯為中間碼
* 執行 source code 所描述的動作
* 本文的 BF interpreter 是第二種interpreter
* 由於 interpreter 的即時性要求, 使其不像 compiler 有充裕時間可做 code 最佳化,
>> 不過像投影片提到的 [brainfuck直譯器](https://github.com/xatier/brainfuck-tools) 一次僅能處理一段輸入, 是否算是傳統直譯器? [name=mingnus]
* Compiler
* Compiler 會產生獨立的 machine code 程式
* 因為要生成 machine code, 所以必須考慮 host machine 的 instruction set 及 ABI, 以BF compiler為例:
* x86-64 ABI 要求 stack pointer 必須對齊 16 bytes
* 巢狀迴圈的 jump label 處理
* JIT compiler
* 相較於 interpreter 逐一轉譯指令, JIT compiler 是將一個片段的程式碼即時轉譯為 machine code 並執行
>> 感覺 JIT compiler 和 interpreter 的界線有點模糊, 是否只差在執行 source code 的方式 [name=mingnus]
---
### [Brainfuck optimization strategies](http://calmerthanyouare.org/2015/01/07/optimizing-brainfuck.html)
* Contraction: Run-length coding
* Clear loops: Set *p to zero
* Multiplication loops: Add the value of *q by (*p * N), then zero *p
* "Copy loops" is a special case of "multiplication loops", with N=1
* Scan loops: Linearly search for the first zero value from p
* Operation offsets: Moving to the offset
awib尚有以下最佳化項目:
* Constant folding: 合併連續的`+-`或`><`
* 刪除無法執行的loops, 以減少code size
* Assignment: `[-]+`最佳化為`*p = 1;`
#### 文件心得
In almost every computation a great variety of arrangements for the succession of the processes is possible, and various considerations must influence the selection amongst them for the purposes of a Calculating Engine. One essential object is to choose that arrangement which shall tend to reduce to a minimum the time necessary for completing the calculation.”
>整篇看完再回來看這。[name=YouChih Wang]
Lovelace’s words still ring true, almost two centuries later. One way to choose that arrangement is to use an optimizing compiler. In this post, we’ll have a look some important compiler optimization strategies for the brainfuck programming language and we’ll examine how they affect the run time of a handful of non-trivial brainfuck programs. The chart below illustrates the impact of the techniques covered.
>Lovelace's 建言在兩個世紀後聽起來仍真實可靠。其中一個方法選擇程式碼的安排是使用優化的 compiler。在這篇文章,將專注在 brainfuck 程式語言上一些重要的 compiler 優化策略和觀察這些優化策略是如何影響那一小段複雜的 brainfuck 程式碼的執行時間。以下的圖表說明了這些技巧對執行時間的影響。[name=YouChih Wang]
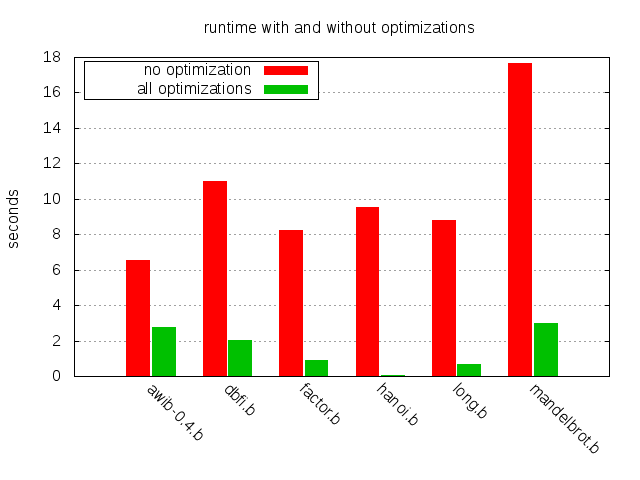
Prerequisites
If you’re new to the brainfuck programming language, then head on over to [the previous post](http://calmerthanyouare.org/2014/09/30/brainfuck-java.html) where we cover both the basics of the language as well as some of the issues encountered when writing a brainfuck-to-java compiler in brainfuck. With that said, most of this post should be grokkable even without prior experience of the language.
>前提,假如您第一次接觸 brainfuck 程式語言,請先閱讀 [compiling brainfuck to java in brainfuck](http://calmerthanyouare.org/2014/09/30/brainfuck-java.html) , 在那篇文章討論了 brainfuck 程式語言基本的東西以及使用 brainfuck 撰寫 brainfuck-to-java compiler 會遇到的某些問題。根據以上的說法(讀了[compiling brainfuck to java in brainfuck](http://calmerthanyouare.org/2014/09/30/brainfuck-java.html)文章),即使您沒有 brainfuck langue 的經驗,對這篇文章都應該有一點體會。[name=YouChih Wang]
Programs worth optimizing
In order to meaningfully evaluate the impact different optimization techniques can have, we need a set of brainfuck programs that are sufficiently non-trivial for optimization to make sense. Unsurprisingly, most brainfuck programs out there are pretty darn trivial, but there are some exceptions. In this post we’ll be looking at six such programs.
The interested reader is encouraged to head over to this repository for a more detailed description of these programs.
>值得優化的程式
>為了更有意義地評估不同優化技巧帶來的影響,我們需要一組足夠複雜的 brainfuck 程式使用來優化,讓我們可以更有感覺。不出所料地,大部分的 brainfuck programs 都相當的簡單,但其中有一些是例外。在這篇文章將觀察 6 個複雜的程式。[name=YouChih Wang]
>有興趣的讀者建議可以到這[link](https://github.com/matslina/bfoptimization)看這 6 個複雜程式更多的描述。
An intermediary representation
Our first step is to define an intermediary representation (IR) on which an optimizer can operate. Working with an IR enables optimizations that are platform independent and brings more expressiveness than brainfuck itself. To further illustrate how the IR functions, we’ll also give C implementations for each operation.
>第一步是定義 optimizer 可以操作在上面的 IR 中間層, 讓 compiler 和 IR 一起運作讓優化獨立於平台,也就是優化這動作不會因為平台不同而受影響,
> brings more expressiveness than brainfuck itself.這怎麼翻呢?[name=YouChih Wang]
> 為了進一步說明 IR 是如何運作的,我們將給出每一個操作所對應的 C 語言實作。
In the table below we find all 8 brainfuck instructions, their IR counterparts and an implementation of the IR in C. This basic mapping provides a very simple and somewhat naive way of compiling brainfuck.
>以下的表格,列出了 8 個 brainfuck 指令、及其對應的 IR 指令和以 C 語言實作 IR。 這個基本的對應提供非常簡單和有一點天真的方法來編譯 brainfuck。[name=YouChih Wang]

The C code depends on the memory area and pointer having been set up properly, e.g. like this:
```
char mem[65536] = {0};
int p = 0;
```
At this point the IR is no more expressive than brainfuck itself but we will extend it later on.
>這裡的 C code 依賴著記憶體範圍和被設定的指標。
>At this point the IR is no more expressive than brainfuck itself。這要怎麼翻呢?[name=YouChih Wang]
Making things faster
Throughout the remainder of this post we’ll look at how different optimizations affect the execution time of our 6 sample programs. The brainfuck code is compiled to C code which in turn is compiled with gcc 4.8.2. We use optimization level 0 (-O0) to make sure we benefit as little as possible from gcc’s optimization engine. Run time is then measured as average real time over 10 runs on a Lenovo x240 running Ubuntu Trusty.
>讓事情更快。
>這篇文章的其它部分將全部專注在不同的優化如何影響 6 個範例程式的 run time。 Brainfuck code 被編譯成 C code
>The brainfuck code is compiled to C code which in turn is compiled with gcc 4.8.2.這要如何理解呢? [name=YouChih Wang]
>使用 gcc 的 -O0 參數,儘可能不要使用 gcc 的優化引擎優化。 Run time 則是執行超過 10 次以上取平均。
>[name=YouChih Wang]
Contraction
Brainfuck code is often riddled with long sequences of +, -, < and >. In our naive mapping, every single one of these instructions will result in a line of C code. Consider for instance the following (somewhat contrived) brainfuck snippet:
```
+++++[->>>++<<<]>>>.
```
> 縮短
> Brainfuck code 經常會被一長串的 + - < > 困惑。在上面的 mapping table 中,每一個 brainfuck 指令都會產生一行 c code。思考以上的範例(有一些人為)
This program will output an ascii newline character (ascii 10, ‘\n’). The first sequence of + stores the number 5 in the current cell. After that we have a loop which in each iteration subtracts 1 from the current cell and adds the number 2 to another cell 3 steps to the right. The loop will run 5 times, so the cell at offset 3 will be set to 10 (2 times 5). Finally, this cell is printed as output.
>這個程式將會輸出一個 ascii 換行的字元 (ascii 10 = '\n')。 第一個長串的 '+' 儲存數字 5 到目前的 memory cell。之後我們有一個迴圈,每一回會從目前的 memory cell 減 1 ,加 2 到右邊的第 3 個 memory cell。這個迴圈會執行 5 次,所以右邊第 3 個 cell 會被設為 10 (2 x 5),最後,右邊第 3 個 cell 會被印出。[name=YouChih Wang]
Using our naive mapping to C produces the following code:
```
mem[p]++;
mem[p]++;
mem[p]++;
mem[p]++;
mem[p]++;
while (mem[p]) {
mem[p]--;
p++;
p++;
p++;
mem[p]++;
mem[p]++;
p--;
p--;
p--;
}
p++;
p++;
p++;
putchar(mem[p]);
```
We can clearly do better. Let’s extend these four IR operations so that they accept a single argument x indicating that the operation should be applied x times:

>以上的 c code 是由 brainfuck code 對應 table 所轉換出來。
>很明確的,可以做得更好。修改 4 個 IR 操作,讓其可以接受一個參數 x ,而這 x 代表這個操作要被執行幾次。
Applying this to our snippet produces a much more compact piece of C:
```
mem[p] += 5;
while (mem[p]) {
mem[p] -= 1;
p += 3;
mem[p] += 2;
p -= 3;
}
p += 3;
putchar(mem[p]);
```
>應用修改過的 IR 到剛才的 brainfuck code 會產生較少的 c code。
Analyzing the code of our six sample programs is encouraging. For instance, about 75% of the instructions in factor.b, hanoi.b and mandelbrot.b are contractable, i.e. part of a sequence of at least 2 immediately adjacent >, +, < or -. Lingering around 40% we have dbfi.b and long.b, while awib-0.4.b is at 60%. Still, we shouldn’t stare ourselves blind at these figures; it could be that these sequences are only executed rarely. Let’s look at an actual measurement of the speedup.
>分析這 6 個程式碼,舉個例子,將近有 75% 的指令在各別的 factor.b, hanoi.b and mandelbrot.b 是可以縮短的。在 dbfi.b long.b 有將近 40%,而 awib-0.4.b 可以有 60%。我們不應該盲目地盯著這些數字,這重覆的 sequence code 也許很少執行,讓我們看看實際的量測。
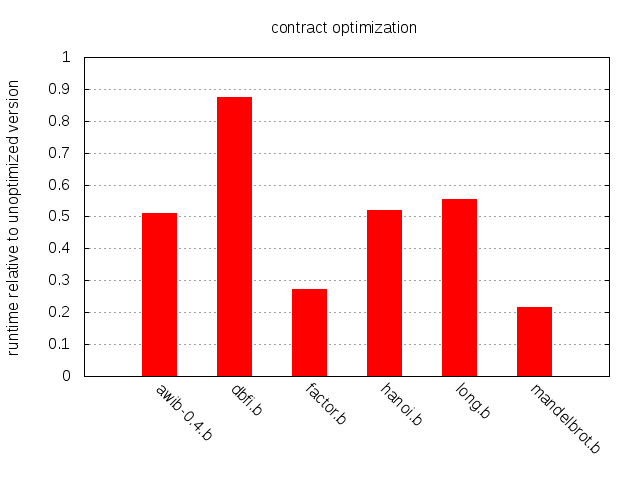
The impact is impressive overall and especially so for mandelbrot.b and factor.b. On the other end of the spectrum we have dbfi.b. All in all, contraction appears to be a straightforward and effective optimization that all brainfuck compilers should consider implementing.
>這個影響在 mandelbrot.b 和 factor.b 是令人印象深刻的。反之dbfi.b的結果就沒有這麼好。從各方面考量,縮短指令似乎是所有brainfuck compiler 都應該是一個值得思考實作的簡單而有效的優化。
Clear loops
A common idiom in brainfuck is the clear loop: [-]. This loop subtracts 1 from the current cell and keeps iterating until the cell reaches zero. Executed naively, the clear loop’s run time is potentially proportional to the maximum value that a cell can hold (commonly 255).
We can do better. Let’s introduce a Clear operation to the IR.
>在 brainfuck 中有一個常見的程式碼 [-] clear loop,這個 loop 每一個輪回會遞減 memory cell 直到 memory cell 為 0
>Executed naively 這要怎麼翻呢?[name=YouChih Wang]
>clear loop's 執行時間和 memory cell(一般是 255 ) 能夠保存的最大值可能呈現比例關係,這個地方可以做的更好,可以引用 Clear 操作到 IR 。

In addition to compiling all occurrences of [-] to Clear, we can also do the same for [+]. This works since (all sane implementations of) brainfuck’s memory model provides cells that wrap around to 0 when the max value is exceeded.
>除了將 [-] compile 成為 Clear,也可以將 [+] compile 成為 Clear,因為完整的 brainfuck's memory model 實作中,當 memory cell 的值超過 max value 時,會歸零。
Inspecting our sample programs reveals that roughly 8% of the instructions in hanoi.b and long.b are part of a clear loop, while the corresponding figure for the other programs is around 2%.
>觀察 sample programs 會得出在 hanoi.b long.b 約 8% 的 Clear loop 指令,而其它的程式約有 2%。
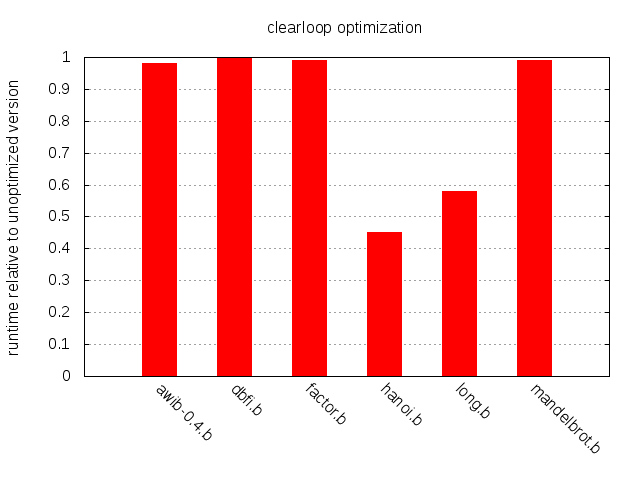
As expected, the impact of the clear loop optimization is modest for all but long.b and hanoi.b, but the speedup for these two is impressive. Conclusion: the clear loop optimization is simple to implement and will in some cases have significant impact. Thumbs up.
>如同預期, clear loop 優化對所有程式的影響都很小除了 long.b 和 hanoi.b,但是這兩個程式執行時間的加速是令人印象深刻。結論: clear loop 優化是容易實作的,且在某些 case 有著若大的影響。 讚!
Copy loops
Another common construct is the copy loop. Consider for instance this little snippet: [->+>+<<]. Just like the clear loop, the body subtracts 1 from the current cell and iterates until it reaches 0. But there’s a side effect. For each iteration the body will add 1 to the two cells above the current one, effectively clearing the current cell while adding its original value to the other two cells.
>複製 loop
>另一個常見的架構是 copy loop。思考這段程式 [->+>+<<] 。正如 Clear loop , loop body 每一個輪回遞減目前的 memory cell 直到 0 為止。但是有一個 side effect. 每一次輪回 loop body 都會加 1 到目前 memory cell 右邊的兩個 memory cell,也就是說將 current cell 的值加到 另外兩個 memory cell。
Let’s introduce another IR operation called Copy(x) that adds a copy of the current cell to the cell at offset x.

> 引進另一個名為 Copy(x) 的 IR 操作,它會將目前的 memory cell 的值加到偏移 x 的 memory cell。
Applying this to our copy loop example ([->+>+<<]) results in three IR operations, Copy(1), Copy(2), Clear, which in turn compiles into the following C code:
```
mem[p+1] += mem[p];
mem[p+2] += mem[p];
mem[p] = 0;
```
> 將 Copy(x) 應用到 ([->+>+<<]),產生 3 個 IR 操作,Copy(1), Copy(2), Clear,並且依序 compile 成以上的 C code :
This will execute in constant time while the naive implementation of the loop would iterate as many times as the value held in mem[p].
>改善過後的 IR 將會以固定時間來執行,然而未改善前的 IR 則以 mem[p] 的值當作執行次數。
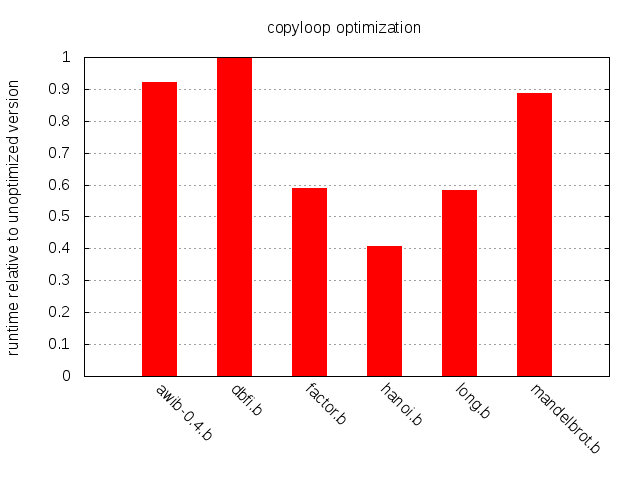
Improvement across the board, except for dbfi.b.
>全部都有改善,除了 dbfi.b
Multiplication loops
Continuing in the same vein, copy loops can be generalized into multiplication loops. A piece of brainfuck like ```[->+++>+++++++<<]``` behaves a bit like an ordinary copy loop, but introduces a multiplicative factor to the copies of the current cell. It could be compiled into this:
```
mem[p+1] += mem[p] * 3;
mem[p+2] += mem[p] * 7;
mem[p] = 0
```
Let’s replace the Copy operation with a more general Mul operation and have a look at what it does to our sample programs.
>乘法迴圈
>和 copy loops 類似的作法, copy loop 可以被推導為 multiplication loops。```[->+++>+++++++<<]```行為有點像是 copy loop,但引入了乘數的因子。 brainfuck code 可以被 compile 成以下的 c code
mem[p+1] += mem[p] * 3;
mem[p+2] += mem[p] * 7;
mem[p] = 0
使用更普遍的 Mul 操作和觀察 sample program 會有什麼變化。

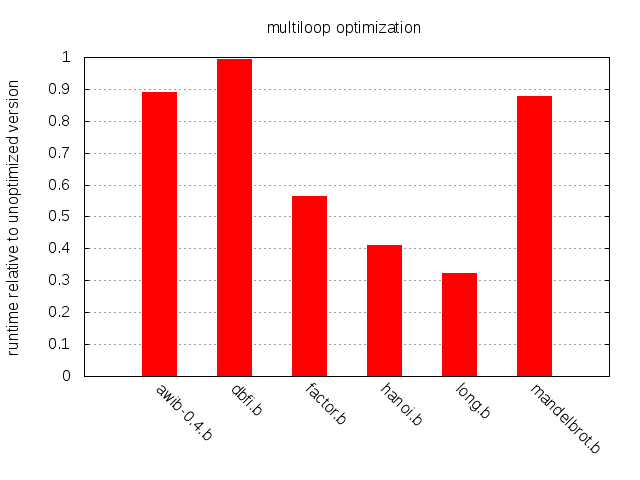
While most programs benefit slightly from the shift from Copy to Mul, long.b improves significantly and hanoi.b not at all. The explanation is simple: long.b contains no copy loops but one deeply nested multiplication loop; hanoi.b has no multiplication loops but many copy loops.
>大部分的程式都可藉著 Copy 轉換到 Mul 後得到些微的 run time 加速。 long.b 大幅度加速, hanoi.b 卻沒有加速,因為 long.b 有很多的 multiplication loop; hanoi.b 有很多的 Copy loops,卻沒有 Multiplication loops。
Scan loops
We have so far been able to improve the performance of most of our sample programs, but dbfi.b remains elusive. Examining the source code reveals something interesting: out of dbfi.b’s 429 instructions, a whopping 8% can be found in loops like [<] and [>]. Contrast that with awib-0.4 being at 0.8% and the other programs having no occurrences of this construct at all. These pieces of code operate by repeatedly moving the pointer (left or right, respectively) until a zero cell is reached. We saw a nice example in the previous post of how they can be utilized.
>掃描迴圈
>到目前為止已改善大部分的範例程式,但 dbfi.b 仍未有改善。觀察 source code 可以看出有趣的事情:dbfi.b 有超過 429 個指令, 也就是 8% ,看起來像是 loops 指令 ```[<]``` 和 ```[>]```。對比 awib-0.4 只有 0.8%,其它程式則沒有這樣的指令。這些小段的程式會重覆地移動指標 (向左或向右或各自移動) 直到 memory cell 為 0 為止。這有一個[範例](http://calmerthanyouare.org/2014/09/30/brainfuck-java.html#storing-the-stack)解說用途。[name=YouChih Wang]
It should be mentioned that while scanning past runs of non-zero cells is a common and important use case for these loops, it is not the only one. For instance, the same construct can appear in snippets like +<[>-]>[>]<, the exact meaning of which is left as an exercise for the reader to figure out. With that said, the scanning case can be very time consuming when traversing large memory areas and is arguably what we should optimize for.
>應該提及的是
Ada Lovelace, 1843
---
## Optimization
因為brainfuck不易閱讀, 故以awib編譯後的結果來觀察有無其他最佳化的手法 (基於IR的二次最佳化)
這裡採用github上最新版的awib, 作業裡附的版本(2010-10-03)似乎沒有multiplication loops的功能
```shell
$ git clone https://github.com/matslina/awib.git
$ make binary
$ ./awib <source_file.b> > output.c
$ gcc -E output.c -o output.p
$ astyle --style=kr --indent=spaces=4 --indent-switches --suffix=none output.p
```
### Adjacent loops
上述最佳化手法僅處理一個迴圈, 對於相鄰的迴圈則無特別處理
以awib.b開頭這段code為例, 這段code的兩個迴圈都在處理相同位址的數值
```brainfuck
[->+>+<<]>>[-<<+>>]+
```
經awib.b編譯, 套用multilication loops的結果為:
```clike
*(p+1)+=*p*1;
*(p+2)+=*p*1;
*p=0;
p+=2;
*(p-2)+=*p*1;
*p=1;
```
可改寫為
```clike
*(p + 1) += *p * 1;
*p += *(p + 2);
*(p + 2) = 1;
```
由上述例子我們可以看到brainfuck語法上的限制:
* 只能進行加減法運算
* Copy assigment 必須以迴圈實作, 而且 copy assignment expression 裡的 rvalue (即 copy source) 是迴圈 counter, 所以會被設為零。迴圈結束後這個位址的數值就無法再被利用, 除非我們事先把該數值暫存到其他地方, 例如上式把`*p`累加到`*(p + 2)`, 迴圈結束後再把`*(p + 2)`搬回`*p`
以下C code可用一個brainfuck loop完成:
```clike
*p += *(p + 2);
*(p + 2) = 0;
```
brainfuck:
```brainfuck
>>[<<+>>-]+
```
以下C code無法用一個brainfuck loop完成
```clike
*(p + 1) += *p * 1;
*p += *(p + 2);
```
>> TODO: 檢查 bf 如何實作其他 statement/expression [name=mingnus]
### Loop initial value
本手法來自Tritium interpreter ("Change more complex loops if the initial states are known")。以上述程式片段為例:
```brainfuck
[->+>+<<]>>[-<<+>>]+
```
對應的 C code 為
```clike
*(p + 1) += *p * 1;
*p += *(p + 2);
*(p + 2) = 1;
```
如果確定 `*(p + 1)` 和 `*(p + 2)` 都是零, 可再進一步簡化為
```clike
*(p + 1) = *p;
*(p + 2) = 1;
```
---
## Concurrent
文件閱讀:
#### [Brainfuck Process Extensions](http://www.kjkoster.org/BFPX/Manual.html)
I have written this compiler and added parallel processing to brainfuck as an exercise to experiment with [continuations](https://en.wikipedia.org/wiki/Continuation)
>continuations 是一種資料結構,對於process狀態的描述,不懂的地方是具體的形式為何?
The BFPX runtime builds on this concept by allowing the programmer to create brainfuck processes explicitly. Each process acts as a complete, self-contained, traditional brainfuck program.
It has its own, private memory space and memory pointer. Pointer positions, memory contents and programs are not shared across processes once they are created.
>self-contained 在這地方是否表示每個process都有獨立的程式碼與記憶體空間?還是包含了其他意思?
There are two cases where processes are created; program start-up and through forking.
* program start-up
新的prcoess有全新的記憶體空間,初始值都是0,指標指向第一個位置.

* through forking
使用系統呼叫fork來實現,有同樣的狀態與共享記憶體空間,

They are only different in how the process memory is initialised and what code they execute.
使用'{'與'}'符號來代表一個process要執行的區域,而父行程跟子行程分別執行的程式碼區段如下圖所示:

BFPX uses a rendez-vous communication mechanism for both IPC and process synchronisation.
Channel Communication
在concurrent要注意的議題有:
1.記憶體共享的問題(most import)
2.同步問題(barrier/join)
3.IPC
### 實作Concurrent:
[github](https://github.com/kobe0308/bf-concurrent.git)
version: pre-alpha
擴充語法:
* '{' 相當於c語言的pthread_create,children thread要執行的指令介於{}之間.
* '}' child thread執行{}內的指令,parent thread從'}'後的第一個指令開始執行.
* '|' 相當於c語言中的pthread_join,僅用於parent thread
todo:
* 建立一個資料結構,儲存要執行的指令({}內的指令),tape的副本與tape指針的偏移量
* 記憶體操作改為atomic => 思考有其必要性嗎? 因為記憶體空間都是各自獨立的,目前的版本應該不會有data race的問題.
* 如果功能確認可行,整合回jit-construct.
不支援功能:
* IPC
* data sync
* child thread內在開啟一個thread.
## 參考資料
* Brainfuck
* [Brainfuck on Wikipedia](https://en.wikipedia.org/wiki/Brainfuck)
* [Brainfuck Implementations](https://esolangs.org/wiki/Brainfuck_implementations)
* Esoteric Programming Language
* [Esoteric Programming Language on Wikipedia](https://en.wikipedia.org/wiki/Esoteric_programming_language)
* [Esoteric Programming Language on esolang.org](https://esolangs.org/wiki/Esoteric_programming_language)
* Compilers
* [One-pass compiler](https://en.wikipedia.org/wiki/One-pass_compiler#Advantages)
* [Compiler optimization techniques](https://en.wikipedia.org/wiki/Optimizing_compiler)
* [How to install the latest g++(currently 5.1) in Ubuntu(currently 14.04)](http://askubuntu.com/questions/618474/how-to-install-the-latest-gcurrently-5-1-in-ubuntucurrently-14-04), AskUbuntu
* [DynASM References](http://corsix.github.io/dynasm-doc/reference.html), The Unofficial DynASM Documentation
 Sign in with Wallet
Connect another wallet
Sign in with Wallet
Connect another wallet