---
tags: keda
---
# KEDA Community Standups
## ⚠️ Communit Standup agenda has moved to Google Docs ⚠️
As of March 15th, meeting notes are taken on https://aka.ms/keda/standup/agenda and HackMD is no longer used.
Meeting notes here are kept as archive.
## March 1st Meeting
### Proposed Agenda
- Improving our roadmap (Tom - [issue](https://github.com/kedacore/governance/issues/48))
- Migrate community standups to Google Doc & CNCF-based Zoom account (Tom - [issue](https://github.com/kedacore/governance/issues/50))
### Attendees (add yourself)
- Jorge Turrado (Docplanner Tech)
- Ramya Oruganti (Microsoft)
- Tom Kerkhove (Microsoft)
- Zbynek Roubalik (Red Hat)
### Notes
- ARM deployment is WIP but close to merge for 2.7
- We need e2e tests for external scalers
- How fast will we fix the external scaler metric name bug? 2.7 should be included
## Feb 15th Meeting
### Proposed Agenda
### Attendees (add yourself)
- Ashish Kanojia (Quantiphi Inc)
- Aaron Schlesinger (Microsoft)
- Daisy Guo (Intel)
- Jorge Turrado (Docplanner Tech)
- Joel Smith (Red Hat)
- Ramya (Microsoft)
- Jaiprakash Sharma (Microsoft)
### Notes
- V2.6.1 has been released :tada::tada:
## Feb 1st Meeting
### Proposed Agenda
- CNCF Website (https://github.com/kedacore/governance/issues/40)
- ARM Release (https://github.com/kedacore/keda/pull/2457)
- HTTP-Addon: New release during this month: [v0.3.0](https://github.com/kedacore/http-add-on/releases/tag/v0.3.0)
### Attendees (add yourself)
- Jorge Turrado (Docplanner Tech)
- Manu Cañete (Docplanner Tech)
- Aaron (Microsoft)
- Alessandro Corsi (Dnata)
- Tom Kerkhove (Microsoft)
- Zbynek Roubalik (Red Hat)
- Ajanth Kumarak
### Notes
- CNCF Website:
- They will note do all the stuffs but they will help us
- https://github.com/kedacore/keda-docs/issues/548 is block till this is done
- ARM Release:
- It's ready to review
- HTTP-Addon: New release during this month
## Jan 18th Meeting
### Proposed Agenda
- Predictive Autoscaling (Tom - [External service](https://predictkube.com/) - [#197](https://github.com/kedacore/keda/issues/197) & [#2401](https://github.com/kedacore/keda/issues/2401))
- Zapier end-user case (Tom)
- v2.6 Status (Tom)
- Can someone give it a help for selenium grid 4 with video?(https://github.com/SeleniumHQ/selenium/issues/9845)
- Pausing Autoscaling (Tom - [#944](https://github.com/kedacore/keda/issues/944))
- Automatically release container image for ARM (Jorge - [#2457](https://github.com/kedacore/keda/pull/2457))
- Website Refresh (Tom - [Milestone](https://github.com/kedacore/keda-docs/milestone/1))
### Attendees (add yourself)
- Aaron Schlesinger (Microsoft)
- Aleksander Slominski (IBM)
- Daniel Yavorovych (Dysnix, PredictKube)
- Jorge Turrado (Docplanner Tech)
- Manuel Cañete (Docplanner Tech)
- Ramya Oruganti (Microsoft)
- Sergei Kolobov (Dysnix, PredictKube)
- Tom Kerkhove (Microsoft)
### Notes
- **Predictive scaling with PredictKube scaler**
- Thank you for adding a privacy policy to our docs
- No rate limiting is applied at the moment so there should not be an issue for KEDA
- Support for more Prometheus authentication flavors? PR is already updated
- Dysnix presentation of how it works:

- **Zapier end-user case**
- Coming to CNCF blog
- **v2.6 Status**
- We still need to close one blocking bug ([PR](https://github.com/kedacore/keda/pull/2394))
- Will follow-up with Zbynek offline once he's back
- Ready to ship once that PR is merged
- **Selenium grid 4 with video**
- Need more information on the ask as it's not clear
- Tom will post an update on the issue
- **Pausing Autoscaling**
- Scenarios:
- Pause autoscaling and keep on current amount of instances
- Pause autoscaling and provide x amount of instances, based on user configuration
- Would be ideal if we could stick with one annotation, but how do you cover the scenario where pausing is required without specifying an amount?
- Specify something that is not valid to indicate to keep it as is?
- **Automatically release container image for ARM**
- Will hold off to do it correctly instead of rushing it
- PR is ready but would be ideal if we can do more testing
- **Website Refresh**
- CNCF will provide estimate later this week
- Jorge will see if his PR is still relevant
- **Upgrading SO to v2.5**
- External metrics cannot be pulled for existing SO's due to metric rename ([#2381](https://github.com/kedacore/keda/issues/2381))
- Probably related as well [#2480](https://github.com/kedacore/keda/issues/2480)
- Should be fixed in v2.6
## Jan 4th Meeting
### Proposed Agenda
- Predictive Autoscaling (Tom - [External service](https://predictkube.com/) - [#197](https://github.com/kedacore/keda/issues/197) & [#2401](https://github.com/kedacore/keda/issues/2401))
- CloudEvents Proposal (Tom - [#479](https://github.com/kedacore/keda/issues/479#issuecomment-988605627))
- Composite Scaler (Tom - [#2431](https://github.com/kedacore/keda/discussions/2431))
- Azure Function & ScaledObject generation
### Attendees (add yourself)
- Jorge Turrado (Docplanner Tech)
- Ramya Oruganti (Microsoft)
- Tom Kerkhove (Microsoft)
- Zbynek Roubalik (Red Hat)
### Notes
- Azure Function & ScaledObject generation for CPU/Memory
- Tom will check with Ramya offline
- Predictive autoscaling is postponed until next standup when the Dysnix team can join.
- CloudEvents proposal
- Overall good but waiting for others to review
- Tom will create a proposal list for events with payload
- Composite scaler
- Tricky point will be the formula composition, maybe we can re-use something from promql.
- Preferrably we use a library for this instead of rolling our own.
- This highly depends on [#2282](https://github.com/kedacore/keda/issues/2282)
- We will POC the formula first in [`ScaledJob`](https://keda.sh/docs/2.5/concepts/scaling-jobs/#scaledjob-spec) to extend `multipleScalersCalculation`, before we think about the next steps for `ScaledObject`
- Tom will ask Or to create a feature request
- Bugs in v2.5:
- Issues:
- Helm chart was fixed with missing RBAC change
- KEDA doesn't reconnect to external dependencies when it failed to talk to it earlier (to be fixed, [#2415](https://github.com/kedacore/keda/issues/2415))
- When there are secrets with secrets, KEDA will move on with invalid data and create HPA with CPU instead of correct info (review required on [PR](https://github.com/kedacore/keda/pull/2394))
- Cache issues
- We should aim to ship v2.6 earlier to mitigate these issues
- We should review PRs
- https://github.com/kedacore/keda/pull/2309
- https://github.com/kedacore/keda/pull/2409
- https://github.com/kedacore/keda/pull/2364 (Consider for v2.7+)
- Multiple KEDA installations
- Can we allow this scenario? Yes, but not 100% given there can only be 1 metrics adapter
- Related https://github.com/kedacore/keda/issues/470 & https://github.com/kubernetes-sigs/custom-metrics-apiserver/issues/70#issuecomment-869393203
- Validating CRDs in PRs
- Idea of Jorge to deploy most recently shipped version and upgrade to current main version, this would allow us to:
- Check if we can upgrade to the CRD in the PR
- Check if we are still alive after the upgrade
- Add this to main repo, inspiration can be taken from https://github.com/kedacore/charts/blob/main/.github/workflows/ci-core.yml
- Deploying to one Kubernetes version in the PR is ok, but [#2392](https://github.com/kedacore/keda/issues/2392) should be done for full testing
## December 7th Meeting
### Proposed Agenda
- [v2.5](https://github.com/kedacore/keda/releases/tag/v2.5.0) is available :tada:
- Standup on Dec 21st is cancelled due to holidays (Tom)
- Request CNCF Cloud Credits for open source projects (Tom)
- CloudEvent support proposal (Tom - [#479](https://github.com/kedacore/keda/issues/479))
- Kubernetes HPA might be a bottleneck for larger deployments [2382](https://github.com/kedacore/keda/issues/2382) (Zbynek)
- We should work with SIG Autoscaling on a fix.
### Attendees (add yourself)
- Ahmed ElSayed (Microsoft)
- Joel Smith (Red Hat)
- Jorge Turrado (Docplanner Tech)
- Ramya Oruganti (Microsoft)
- Tom Kerkhove (Microsoft)
- Tony Chege
- Zbynek Roubalik (Red Hat)
### Notes
- Kubernetes HPA might be a bottleneck for larger deployments
- Large deployments are scaling slowly because the HPA is single-threaded (ie. 1000+ HPAs)
- Upstream issue is already open on [kubernetes/kubernetes #96242](https://github.com/kubernetes/kubernetes/issues/96242)
- Joel will bring it up at SIG Autoscaling standup to see if we can improve it
- Tom & Zbynek will try to join as well
- There is no way to detect/visualize, only by suffering from it
- Request CNCF Cloud Credits for open source projects has been approved and we will get $500/mo on AWS/GCP
- CloudEvent support proposal is not open yet, Tom will do that ASAP
## November 23rd Meeting
### Proposed Agenda
- We are happy to welcome @Jorge Turrado as a new maintainer :tada:
- External Scaler for Azure Cosmos DB v0.1 is out :tada:
- v2.5 release
- Switching all default branches from master to main ([issue](https://github.com/kedacore/governance/issues/39) - Tom)
- Documentation improvements for growing pains ([issue](https://github.com/kedacore/governance/issues/40) - Tom)
- CNCF is going to help us, first a [doc review](https://github.com/cncf/techdocs/issues/87) will be done
- We want to: ([details](https://github.com/kedacore/keda-docs/milestone/1))
- Structure our current scalers
- Incorporate external scalers from community and standardize on Artifact Hub
- Improve our current website structure
- Fix bugs
- Add e2e tests for scalers that are not covered currently (AWS,GCP,...)
- Request AWS credit for open source projects
- Deprecating Azure Durable Functions Scaler
- https://github.com/kedacore/keda-external-scaler-azure-durable-functions/pull/20
### Attendees (add yourself)
- Ahmed ElSayed
- Jorge Turrado
- Tom Kerkhove
- Zbynek Roubalik
### Notes
- **Jorge should become a code owner, added to issue**
- **add on vs external scaler** - External scaler is more clear and the HTTP one is more than just an external scaler (CRD)
- [x] Tom to update Jatin to proceed
- **v2.5 release**
- Blob listing scaler change is moved to v2.6
- Let's aim for Thursday so we have a nice gift for Thanksgiving
- Jorge will be the release captain 👨✈️ to verify his permissions and our documented process
- https://github.com/kedacore/keda/blob/main/RELEASE-PROCESS.MD
- [ ] Tom needs to add a new step for Snyk to scan stored images
- **AWS / GKE and end-to-end tests**
- We need to identify and track gaps in our e2e tests
- We need somebody to write end-to-end tests for these scalers
- We are onboarding to the CNCF CLoud Credits program to get access to these
- **Deprecating Azure Durable Functions Scaler**
- https://github.com/kedacore/keda-external-scaler-azure-durable-functions/pull/20 is pending review
- **Cache metrics (values) in Metric Server and honor pollingInterval**
- https://github.com/kedacore/keda/issues/2282
- Proposal to cache metrics from Prometheus in metric server within the timespan of the polling interval to reduce load
- We need to ensure we are backwards compatible
- Makes sense, let's do it 🚀
## November 9th Meeting
### Proposed Agenda
- v2.5 release
- https://github.com/kedacore/keda/pull/2187 - Ahmed's PR - review please
### Attendees (add yourself)
- Zbynek Roubalik (Red Hat)
- Jorge Turrado (Docplanner Tech)
- Jeff Hollan (Microsoft)
- Aaron (Microsoft)
- Jatin (Microsoft)
- Joel Smith (Red Hat)
- Ramya (Microsoft)
### Notes
## October 26th Meeting
### Proposed Agenda
- ARM support
- build/unit tests done - https://github.com/kedacore/keda/pull/2213
- v2.5 release
- CPU scaler issue
- GH Container Registry UI Pages 404ing - https://github.com/kedacore/keda/issues/2215
### Attendees (add yourself)
- Zbynek Roubalik (Red Hat)
- Jorge Turrado (Docplanner Tech)
- Aaron Schlesinger (Microsoft)
- Ramya Oruganti (Microsoft)
### Notes
- ARM based e2e tests and images TBD - help welcome
- Try to find a possibility to trigger GH action manually
- if all set do the 2.5 release after the next call (Nov 9)
- CPU scaler issue with Value type - check whether it is a problem in k8s or keda.sh docs [Jorge]
- rech out to GH team on #2215 [Tom], Zbynek will try to change the settings first
## October 12th Meeting
### Proposed Agenda
- ARM support (Tom)
- v2.5 Release (Zbynek)
- Introduction of better community recognition (Tom - [governance #30](https://github.com/kedacore/governance/issues/30))
- Bot for managing Issues/GH (Jorge Turrado)
- Update on HTTP Addon (Aaron)
### Attendees (add yourself)
- Aaron Schlesinger (Microsoft)
- Zbynek Roubalik (Red Hat)
- Jorge Turrado (Docplanner Tech)
- Ajanth Kumarakuruparan (WSO2)
- Lakshmi (Microsoft)
- Tom Kerkhove (Codit)
### Notes
- ARM support is in progress but requires more time, aiming for v2.5 but no commitment
- v2.4 was Aug 6th so aiming for first half of November for v2.5
- https://github.com/kedacore/keda/milestone/15
- The more reviews we get, the better!
- Our release cadance is not updated yet, pending Ahmed & Jeff's sign-off
- Time will ping them
- We'll introduce a definition of what it takes to become a KEDA member and introduce a group for active contributors
- It's difficult to filter all the issues as a new community member and to figure out where to help
- It would be ideal to use [Stale](https://github.com/marketplace/stale) bot or [GitHub Action](https://github.com/marketplace/actions/close-stale-issues) and introduce a `do-not-close`/`cant-touch-this` label
- Tom will do the monkey work on this
- HTTP Add-on
- v0.2 release is coming closer but requires a little bit more infrastructure changes
- Would be nice to have more reviews on PRs
- Should we align releases with KEDA core? No but we should go to a frequent cadance once we have more contributors
- Investigating how to integrate the add-on on keda.sh
- We should make it more clear how people can integrate their external scaler with Artifact Hub
## September 28th Meeting
### Proposed Agenda
- Azure Blob Storage - Recursive / Blob listing (Tom)
- https://github.com/kedacore/keda/issues/1789
- Keeping scalers running (Ahmed)
- https://github.com/kedacore/keda/issues/1121
- Hacktoberfest (Tom)
### Attendees (add yourself)
- Tom Kerkhove (Codit)
- Ahmed ElSayed (Microsoft)
- Jorge Turrado (SRE at Docplanner Tech)
### Notes
- Ahmed is working on [#2036](https://github.com/kedacore/keda/pull/2036) and will come later on
- Ahmed is working on a fix for [#1121](https://github.com/kedacore/keda/pull/1121)
- We have opted-in for hacktoberfest with [a ton of issues to pick up](https://github.com/kedacore/keda/issues?q=is%3Aissue+is%3Aopen+sort%3Aupdated-desc+label%3AHacktoberfest)
## September 14th Meeting
### Proposed Agenda
- Bot for managing Issues/GH (Jorge Turrado)
- RabbitMQ pagination issue: (Jorge Turrado)
- https://github.com/kedacore/keda/pull/2087
### Attendees (add yourself)
- Zbynek Roubalik (Red Hat)
- Aaron Schlesinger (Microsoft)
- Jorge Turrado (SRE at Docplanner Tech)
### Notes
- RabbitMQ issue - handle error in a separate PR and wait for the feedback on pagination
- Bot could mark stale issues, so we are not overhelmed with issues. Let's discuss this when we have a bigger quorum.
## August 31st Meeting
### Proposed Agenda
- Migration to Kubebuilder v3 (Z)
- Issue [2030](https://github.com/kedacore/keda/issues/2030)
### Attendees (add yourself)
- Zbynek Roubalik (Red Hat)
- Amir Schwartz (Microsoft)
- Aaron Schlesinger (Microsoft)
- Jorge Turrado (SRE at Docplanner Tech)
- Filippo
### Notes
- Start working on [issue 2030](https://github.com/kedacore/keda/issues/2030)
## August 17th Meeting
### Proposed Agenda
- CNCF Incubation (Tom)
- It will be announced tomorrow 🎉
- Cast.AI Reference Case (Tom)
- Published 🎉
- KEDA 2.4 release (Tom)
- Shipped 🎉
- Azure Blob Storage Scaler & list blobs recursively (Tom)
- https://github.com/kedacore/keda/issues/1789
- Reuse connection for some scalers, potential perf improvement (Z)
- https://github.com/kedacore/keda/issues/1121
- would be nice to target this feature for the next release
- HTTP Add-On
- Update
- Questions from Hieu
### Attendees (add yourself)
- Aaron Schlesinger (Microsoft)
- Ahmed ElSayed (Microsoft)
- Ajanth Kumarakuruparan (WSO2)
- Jorge Turrado (Docplanner)
- Hieu (Microsoft)
- Jatin Sanghvi (Microsoft)
- Shivam Rohilla (Microsoft)
- Terry Humphries (HTTP Services)
- Tom Kerkhove (Codit)
### Notes
- Azure Blob Storage Scaler & list blobs recursively
- Discussed and issue updated
- Reuse connection for some scalers, potential perf improvement
- v2.5 is being targetted by Ahmed, issue updated
- HTTP Add-on
- Multi-tenant scaler allowing end-users to have less infrastructure containers running in the cluster and will be faster for scaling / CRUD HTTP ScaledObject
- Almost finished and being reviewed by Yaron
- Targetting v0.2
- Dedicated scaler based on HTTP ScaledObject will be part of v0.3
- https://github.com/kedacore/http-add-on/issues/183
- Is there a reason why we are not using in-memory scraping (kube-metrics-adapter) over interceptor?
- We use the interceptor to be able to stream from interceptor to workload
- Are there plans to automatically add labels/annotations to pods that we spin up?
- For example, add identity label so that Azure Pipelines can use it to authenticate
- We rely on the HPA but we could scan pods to see if we need to apply the labels, but we need to see if we want to do that
- Scale down order support would be nice (Kubernetes v1.21+)
- Hieu will open an issue
## August 3rd Meeting
### Proposed Agenda
- CNCF Incubation (Tom)
- We are graduating 🎉 Finished the PR content and blog post will go out in a couple of weeks
- Cast.AI Reference Case (Tom)
- PR is open for review on https://github.com/kedacore/keda-docs/pull/497
- Planned to publish on Thursday
- Releases (Tom)
- We have published our approach to planning & shipping releases
- 👉 https://github.com/kedacore/governance/blob/main/RELEASES.md
- KEDA 2.4 release (Tom)
- Would be nice if Ahmed could review https://github.com/kedacore/keda/pull/1907 so it can be merged for v2.4
- Tom is happy to be the release captain on Thursday, if agreed
### Attendees (add yourself)
- Zbynek (Red Hat)
- Aaron (MSFT)
- Ahmed (MSFT)
- Dennis (Solace)
### Notes
- We are ready to release 2.4 this Thursday
- A new Solace Push Scaler - probably start with external one, if there's demand
- HTTP Add On - architecture change coming, Aaron will present the change in some of the upcoming calls
## July 20th Meeting
### Proposed Agenda
- CNCF Incubation (Tom)
- Public comment period has started ([link](https://lists.cncf.io/g/cncf-toc/topic/83831841)), after that TOC vote
- Releases (Tom)
- We have published our approach to planning & shipping releases
- 👉 https://github.com/kedacore/governance/blob/main/RELEASES.md
- KEDA 2.4 release (Zbynek)
- HTTP Addon update (Aaron)
### Attendees (add yourself)
- Zbynek (Red Hat)
- Ahmed (Microsoft)
- Dennis Brinley (Solace)
- Aaron (Microsoft)
### Notes
- Will discuss a release KEDA 2.4 on the next call (Aug 3rd), if there are no issues the release will happen that week
- HTTP Addon - Aaron working on multi tenant architecture
- Ahmed to work on:
- e2e tests stability
- https://github.com/kedacore/keda/issues/1121
- Push scaler docs
## June 22nd Meeting
### Proposed Agenda
- CNCF Incubation (Tom)
- Due dilligence is being wrapped up
- Migrating our container images to GitHub Container Registry (Tom)
- Notice opened on March 26th (https://github.com/kedacore/keda/discussions/1700)
- Effective since v2.2
- GitHub Container Registry is GA (https://github.blog/2021-06-21-github-packages-container-registry-generally-available/), we should remove Docker Hub
- Activation and Scaling request - FYI (Jeff)
- End to end tests (Jeff)
- Solace scaler (Dennis)
### Attendees (add yourself)
- Jeff
- Zbynek
- Ahmed
- Shubham
- Dennis
### Notes
- Thinking being we can continue to parallelize Docker Hub for the next 2 or 3 releases and then omit Docker Hub for latest releases. Potentially updating the announcement to say we will do until something like Aug 31
- Had some discussion about the threshold issue https://github.com/kedacore/keda/issues/692
-
## June 8th Meeting
### Proposed Agenda
- KEDA 2.3 release is out!
- https://github.com/kedacore/keda/releases/tag/v2.3.0
- New reference case with Cast.AI (Tom)
- Blog post in the works
- HTTP v0.1 release
- Renovate (Tom)
- Only need to configure it to use 1 PR for all our dependencies
- CNCF Incubation (Tom)
- Still ongoing, I'll get back to it this week
- We are actively seeking end-users who want to be listed on keda.sh or want to be interviewed by CNCF
- Reach out to kerkhove.tom@gmail.com if you are interested
### Attendees (add yourself)
- TODO
### Notes
- TODO
## May 25th Meeting
### Proposed Agenda
- KEDA 2.3 release
- HTTP v0.2 release
- Dependabot vs Renovate
- CNCF Incubation
### Attendees (add yourself)
- Zbynek (Red Hat)
- Tom (Codit)
- Aaron (Microsoft)
- Shubham (NEC)
- Terry Humphries ()
- Ryan Karg (Activition / Blizzard)
### Notes
- KEDA 2.3 release
- Zbynek wants to pick it up on Thursday (estimate)
- Blog post is ready to be merged when released
- HTTP v0.1.0 release
- Blocking PR in charts: https://github.com/kedacore/charts/pull/151
- Nice to have: https://github.com/kedacore/http-add-on/pull/168
- Blog post is open: https://github.com/kedacore/keda-docs/pull/428
- Dependabot vs Renovate
- Dependabot has too many PRs (one per dependency)
- Tom has used it before and likes it
- https://github.com/kedacore/keda/issues/1823
- CNCF Incubation
- Tom is working on the due dilligence with Zbynek
## May 11th Meeting
### Proposed Agenda
- None
### Attendees (add yourself)
- Zbynek
- Tom
- Jeff
### Notes
- CNCF Incubation
- We have just wrapped up our presentation for TAG Runtime who supports our proposal
- Due dilligence is starting where Tom will work with Liz to get everything written down
- Maintainership
- We have not found a replacement for Aniruth yet
- Microsoft has 50% of the maintainers and we want to have vendor neutral governance, so decided to change our voting process (PR open on https://github.com/kedacore/governance/pull/21)
- Just to be clear, Microsoft is not abusing their position at them moment but we just want to have this improved to align with other project's their governance
## April 27th Meeting
### Proposed Agenda
- CNCF Incubation (Tom)
- Our proposal is open on https://github.com/cncf/toc/issues/621
- Liz Rice is happy to sponsor us and starting due dilligence
- A presentation will be done for SIG-Runtime, checking who needs to be involved
- CNCF will do end-user reviews.
- Are you and end-user? Reach out to Tom if you want to help (kerkhove.tom@gmail.com)
- Alibaba reference case is published (Tom)
- https://www.cncf.io/blog/2021/03/30/why-alibaba-cloud-uses-keda-for-application-autoscaling/
### Attendees (add yourself)
- Zbynek
- Tom
### Notes
- Discussed KubeCon
- Tom has a session on KEDA
- There will be two office hours sessions on KEDA (Tom & Zbynek), Tuesday and Thursday
## March 16th Meeting
### Proposed Agenda
- CNCF (Tom)
- Annual review is approved
- Still checking with Liz Rice if she wants to sponsor our incubation proposal, otherwise will go to Lei Zhang
- Our Alibaba Cloud reference case will be published on March 30th on CNCF blog
- Proposal to move our Docker images to GitHub Container Registry (Tom)
- Done, only need a blog post + discussion coming later this/next week
- KubeCon EU (Tom)
- Project Pavillion frequest for 2x office hours (Tom + Zybnek)
- HTTP Autoscaling (Tom)
- Blog post is almost finished
- 2.2 release (Z)
- https://github.com/kedacore/keda/milestone/13
### Attendees (add yourself)
- Tom Kerkhove (Codit)
- Sonia (Microsoft)
- Ahmed ElSayed (Microsoft)
- Jonathan Beri (Golioth)
- Pedro Dominguite (SIDI)
- Zbynek Roubalik (Red Hat)
### Notes
- Zbynek can do the 2.2 release on Thursday
- We would like to have integration tests for OpenStack scaler which requires a hosted option
- Open CNCF ticket to see if they can sponsor the hosted offering
- It should be a couple of $/mo for end-to-end tests
- Once we have an instance, Zbynek will contact Pedro
## March 2nd Meeting
### Proposed Agenda
- Congrats Zbynek 🎉👶
- CNCF (Tom)
- Annual review is open on https://github.com/cncf/toc/pull/607
- Checking with Liz Rice if she wants to sponsor our incubation proposal
- Would it be useful if we would document all our integrations? (Tom)
- Was there an outcome last standup?
- Relates to https://github.com/kedacore/governance/issues/14
- Proposal to move our Docker images to GitHub Container Registry (Tom)
- https://github.com/kedacore/governance/issues/16
- Just need Jeff, Anirudh and/or Ahmed's blessing
- KubeCon EU (Tom)
- HTTP Autoscaling (Tom)
- Status
- Integrating with existing resources / automatically creating new resources
- Blog post
### Attendees (add yourself)
- Tom Kerkhove (Codit)
- Zbynek Roubalik (Red Hat)
- Jeff Hollan (Microsoft)
- Tsuyoshi (Microsoft)
- Ritika (NEC)
- Shubham Kuchhal (NEC)
- Aaron Schlesinger (Microsoft)
- Ahmed ElSayed (Microsoft)
- Sonia (Microsoft)
- Ryan Karg (Activision Blizzard)
### Notes
- CNCF
- Graduation process to incubation is documented on https://github.com/cncf/toc/blob/main/process/README.md#project-graduation-process-sandbox-to-incubating
- Would it be useful if we would document all our integrations?
- Everyone thinks it's a good idea to do it
- A dedicated page on keda.sh, ie keda.sh/integrations, would be ideal with a description on how it uses KEDA and why
- Proposal to move our Docker images to GitHub Container Registry (Tom)
- Jeff & Ahmed agree, let's do it
- Tom will open an issue to publish new images to GHCR, in parallel to Docker Hub
- Tom will open an issue to retag and push our existing images to GHCR
- Tom will open an issue with a notice on our Discussions with some context
- HTTP Autoscaling
- First alpha is out with basic functionality
- Alpha 2
- Aiming for next week
- https://github.com/kedacore/http-add-on/milestone/2
- Blog post
- Tom is slacking big time on this
- Link: https://docs.google.com/document/d/1jlLqw7AZEt0B1VdLum4Hq_e5OLjeb2wc1DjuTHHp7-k/edit?usp=sharing
- How far do we go?
- Integrating with existing resources and/or automatically creating new resources?
- Aaron his plan is to build a layer on top of it, that could include the pieces that we move out
- Ryan mentions that options would be nice so that the full experience makes it easier for you to learn, but majority of it will go through self-managed services, etc
- Operator can also create deployments for you, but maybe we should leave that out?
- We will move this out for now and is maybe more part of a CLI on top of this
- Aaron will write a more thorough scope which focusses on where the traffic starts and where it ends
- Aaron will add some use-cases explaining the scenario and how you can apply HTTP autoscaling on those, how it works and what the impact is.
- Ahmed was curious about our next release since he wanted to get a few things in
- He need a week, which is fine, so we'll discuss the release next time
- Jeff had a few customers with asks for Cosmos DB
- The PG will check if they can build a Cosmos DB scaler
## Feb 16th Meeting
### Proposed Agenda
- Alibaba Reference Case (Tom)
- Finalizing the blog post and checking with CNCF to publish it is up next
- CNCF (Tom)
- Started working on annual review
- Incubation proposal is coming after that
- Would it be useful if we would document all our integrations? (Tom)
- Relates to https://github.com/kedacore/governance/issues/14
- Early exploration of KEDA for IoT ([thread](https://kubernetes.slack.com/archives/CKZJ36A5D/p1607004394421300))
### Attendees (add yourself)
- Jeff
- Jonathan (golioth.io)
- Shubham
- Ritika
- Sonia
## Feb 2nd Meeting
### Proposed Agenda
- KEDA 2.1 is out! (Tom - https://github.com/kedacore/keda/releases/tag/v2.1.0)
- Here are some highlights:
- Introduction of ClusterTriggerAuthentication for cluster-wide trigger authentication
- Introducing new InfluxDB, MongoDB & OpenStack Swift scaler
- Improvements to AWS Cloudwatch, Azure Event Hub, Kafka & Redis scalers
- Automatically determine the RabbitMQ protocol (when possible)
- Support for Redis clusters
- Performance improvements
- Azure Functions users can use it soon (https://github.com/Azure/azure-functions-core-tools/pull/2406)
- ARM support (Tom)
- We can request an ARM machine on which we can run a self-hosted GH Actions runner
- Request to be created
- Tracking in https://github.com/kedacore/governance/issues/12
- Issue reports will be easier, we are in the GitHub Issue forms preview (Tom)
- Example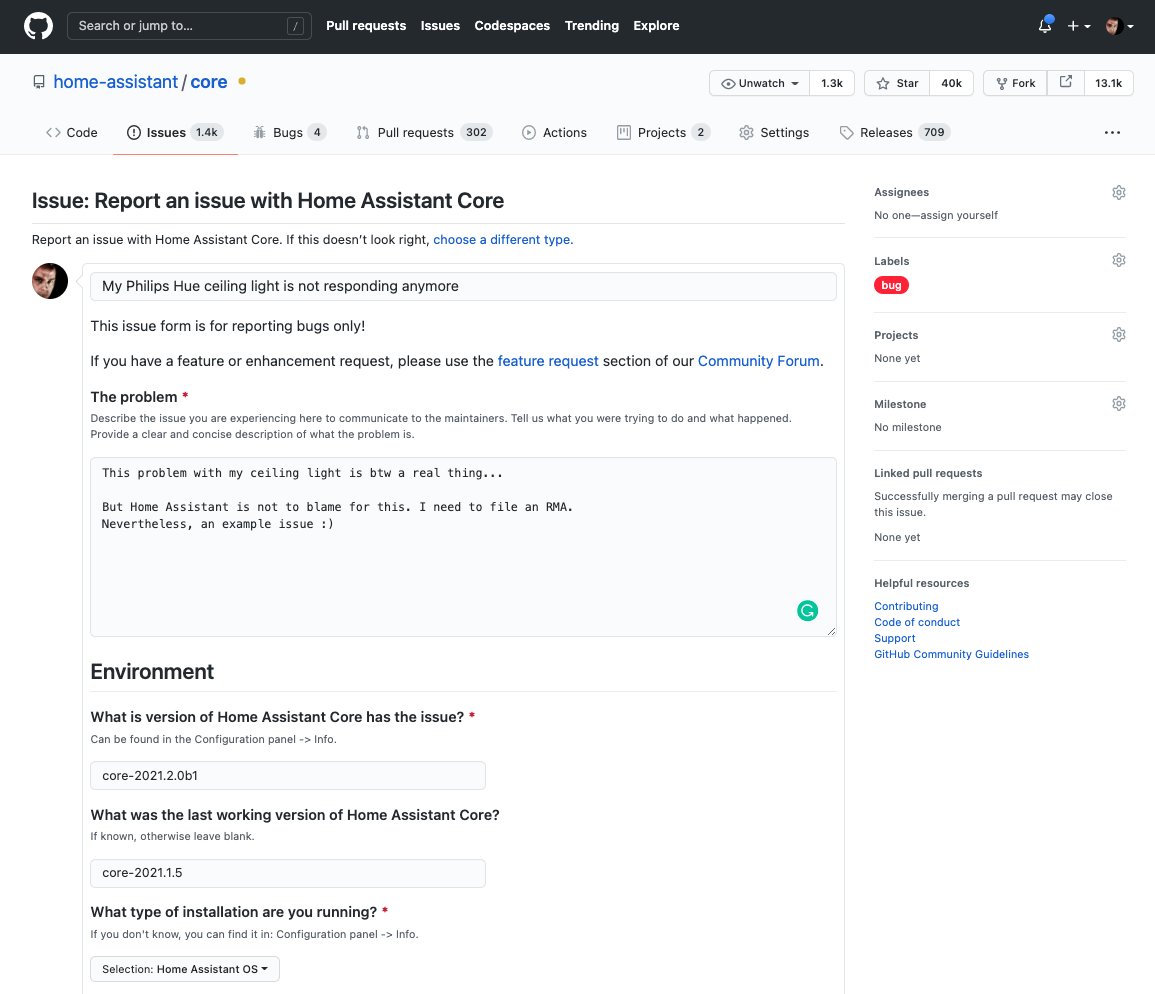
- We'd 💘 some community help on our end-to-end tests ([open issues](https://github.com/kedacore/keda/issues?q=is%3Aissue+is%3Aopen+label%3Atesting))
### Attendees (add yourself)
- Tom Kerkhove (Codit)
- Shubhuam Kuchhal (NEC)
- Aaron Schlesinger (MSFT)
- Jonathan Beri (Golioth)
- Ahmed ElSayed (MSFT)
- Jeff Hollan (MSFT)
- Sonia Kulkarni (MSFT)
## Jan 19th Meeting
### Proposed Agenda
- Support for ARM (https://github.com/kedacore/keda/issues/779)
- we can produce images, but need an environment, that can be used to check the images (Z)
- KEDA 2.1 (https://github.com/kedacore/keda/blob/main/CHANGELOG.md#unreleased)
- we have a lot of improvements, fixes and new scalers, I think that we are good to go with a new release, once KEDA docs are up to date and the e2e tests are stabilized (Z)
- KEDA 2.0 support in Azure Function CLI ([get started](https://docs.microsoft.com/en-us/azure/azure-functions/functions-run-local?tabs=windows%2Ccsharp%2Cbash))
- Available in [version >= 3.0.3216](https://github.com/Azure/azure-functions-core-tools/releases/tag/3.0.3216)
- EKS, Calico, and CNI - and how we can support that
- HTTP Add-on
- CNCF Incubation
### Things to note
- For ARM support we'd need an ARM machine to build, wondering if Google Cloud could provide with CNCF credits? Tom may check into this
- Astronomer has a customer running in EKS, but they have replaced the EKS CNI and added Calico. Calico is handling all the traffic, but the control plane using CNI.
- Pods that need to talk to control plane need to run on host network
- Scaling events (calling Postgres for events), which needs access to the database via the network policies.
- HTTP Add on https://github.com/kedacore/http-add-on/pull/2
- Hoping early / mid February for beta, Alpha sooner
- Aaron open to writing a blog, ideally x-posting to https://keda.sh/blog/
### Attendees
- Jeff Hollan (MSFT)
- Daniel Imberman (Astronomer.io)
- Terry Humphries (GTP services)
- Tom Kerkhove (Codit)
- Aaron Schlesinger (MSFT)
- Ritika (NEC)
- Shubhuam Kuchhal (NEC)
- Kris Dockery (Astronomer.io)
- Jonathan Beri (Golioth)
### Notes
- TODO
## Jan 5th Meeting
### Proposed Agenda
- Support for cluster-scoped trigger authentication ([issue](https://github.com/kedacore/keda/issues/1469))
- E2E tests are unstable :/
- A lot of reported issues with EKS and Calico (networking related)
### Things to note
- TODO
### Attendees
- Jeff Hollan (MSFT)
- Daniel Imberman (Astronomer)
- Tom Kerkhove (Codit)
- Tsuyoshi (MSFT)
- Jonathan Beri (Golioth - Serverless IoT startup)
- Zbynek Roubalik (Red Hat)
### Notes
- TODO
## Dec 8th Meeting
### Proposed Agenda
- HTTP-based autoscaling & SMI (Tom)
- Experimental add-on is available in [our org](https://github.com/kedacore/http-add-on)
- This is a starting point and we'll compare it with other tech such as KNative & OpenFaaS but you should not need to run Prometheus
- Aaron created first PR, to be reviewed by Zbynek
- Tom is working with [SMI](https://smi-spec.io/) people to have the metrics in other places such as Ingress, Service, etc.
- [Ingress v2](https://kubernetes-sigs.github.io/service-apis/) is also very interested
### Things to note
- This is our last standup of 2020
- Targetting January the soonest for KEDA 2.1
- [Governance](https://github.com/kedacore/governance) repo is now available
### Attendees
- Jonathan Beri (Golioth - Serverless IoT startup)
- Callum Pilton (IBM)
- Jess McCreery (IBM)
- Richard Coppen (IBM)
- Ritika (NEC)
- Shubham Kuchhal (NEC)
- Tom Kerkhove (Codit)
### Notes
- None
## Nov 24th Meeting
### Proposed Agenda
- HTTP-based autoscaling (Tom)
- Pause scaling option (Zbynek)
- https://github.com/kedacore/keda/issues/944
### Things to note
- Merch is now available on https://merch.keda.sh
### Attendees
- Zbynek
- Tom
- Shubham
- Rory
- Aron
- Richard
- Nisheeka
### Notes
- HTTP based autoscaling
- Should support multiple ingresses, Prometheus metrics can give us universality in some cases.
- Design document is updated in the issue.
- SMI: we could support if needed, it is been taken in the account in the proposal. So far nothing is tightly coupled with KEDA, scaler could be swapped by SMI, the same applies to Interceptor.
- Tom will prepare a repo for HTTP add on
- The scaler will be external one first
- IBM e2e tests are in the progress, no issues
- Pause scaling option
- will use annotation/label to on ScaledObject/ScaledJob. KEDA will skip scaling for the target Deployment when the label is present (HPA will be probably removed), there will be option to specify the number of replicas on the target Deployment during this phase.
## Nov 10th Meeting
### Proposed Agenda
- KEDA 2.0
- Roadmap Review
### Attendees
- Ahmed
- Jeff
- Liam
- Richard
- Bimsara
- Shubham
- Zbynek
### Notes
- Congrats on the KEDA 2.0 Release 🎉
- Reviewed roadmap, bubbled a few items up to the top of the list we'd consider for 2.1
- https://github.com/kedacore/keda/projects/3
## Oct 29th Meeting
### Proposed Agenda
- KEDA 2.0 Go live
- Update on Helm issus
- Standup Move (Tom)
- Can we move it to 16:00 UTC?
- Otherwise it will be hard for me to join in the future, which is ok
(now is the time if you want to get rid of me 🙊)
- HTTP and KEDA (Aaron MSFT)
- Enable KEDA as a single source of truth on scaler metrics ([#1281](https://github.com/kedacore/keda/issues/1281) - Tom)
- Mir and Shashik PR review
### Attendees
- Jeff (MSFT)
- Tom (Codit)
- Aaron (MSFT)
- Anirudh (MSFT)
- Ikaika (Carvana)
- James (Carvana)
- Mir (Linqia)
- Shashik (Linqia)
- Ritika (NEC)
- Shubham (NEC)
- Zbynek (Red Hat)
### Notes
- Making good progress on 2.0. Fixed memory leak in scaler. No blocking issues known. Could release on Nov 4
- https://github.com/kedacore/charts/issues/88
- https://docs.google.com/document/d/1vhT-wwEPPNImFmLZHGJxdKjUvKWk6ckeE7QCLSOJzLY/edit# for blog post that goes live on Nov 4
- @Jeff to work on Azure update to help amplify
- @Tom to work on document and help to share plan with Slack / maintainers
- Rename master to main, and merge v2 to main (and make a v1 branch). @Zbynek can help do this
- Rename keda-docs to main
- Moving standup on Nov 10 (tuesdays) at 16:00 UTC which is an hour earlier for folks who have daylight savings.
- Aaron spent some time using KEDA, and wanting to enable HTTP scaling workloads
- Discussed a design to set a minimum threshold, specifically for Kafka, but felt it was a useful pattern to build in a way other scalers could mirror this functionality
- https://github.com/kedacore/keda/issues/692
## Oct 15th Meeting
### Proposed Agenda
- KEDA 2.0 Go live
- Roadmap review
- Daylight savings
- IBM MQ
- Merch (Tom)
- What do you think of the current designs? They are pending approval.
- Things I've asked:
- Can we have a mix of 1 & 2, ie. have blue & gray in option 1 but mint in option 2?
- Can we fill the lightningbolt with white to make it more clear
- Azure Service Bus Sample Update (Tom)
- Migrated to KEDA 2.0
- Pod identity tutorial on the way
- Helm 2 support (Tom)
- I still causes issues and there is a big push to migrate to 3.x (https://twitter.com/HelmPack/status/1314294233994493953)
- I think we should remove it as part of KEDA 2.0
### Attendees
- Richard Coppen
- Jess McCreery
- Callum Pilton
- Shubhuam Kuchhal
- Jeff Hollan
- Tsuyoshi
- Anirudh Garg
- Ahmed ElSayed
- Zbynek Roubalik
- Tom Kerkhove
### Notes
- Have a few new PRs, also a report of ScaledJobs memory leak, looking to resolve and then do RC 2
- Tom created a roadmap https://github.com/kedacore/keda/projects/3
- Daylight savings, currently we meet at 1600 UTC, thinking is that starting Nov 1 we move standup to 1700 UTC
- Also move to Tuesdays?
- Start with the week of Nov 9 and meet on Nov 10
- IBM MQ scaler
- https://developer.ibm.com/components/ibm-mq/series/badge-ibm-mq-developer-essentials
- https://github.com/kedacore/keda/pull/1259
- Samples to v2 - Jeff to ping the samples to move to v2
- We are ok to remove helm 2 for the KEDA 2.0 charts given it's going EOL in November
### Merch Mockups
**Option 1**

**Option 2**

## Oct 1st Meeting
### Proposed Agenda
- KEDA 2.0 Beta
- Meeting notes (Tom)
- Thoughts on this proposal? https://docs.google.com/document/d/1zdwD6j86GxcCe5S5ay9suCO77WPrEDnKSfuaI24EwM4/edit?usp=sharing
- High availability (Jeff)
- Roadmap (Tom)
- Might be good if we define a longer-term roadmap for KEDA
- It should be flexible so that we can easily pivot
- Requested by community
### Attendees
- Jeff Hollan (Microsoft)
- Tsuyoshi (Microsoft)
- Anirudh Garg (Microsoft)
- Zbynek Roubalik (Red Hat)
- Travis Bickford (Shutterstock)
- Ritika Sharma (NEC)
- Shubham Kuchhal (NEC)
### Notes
- KEDA 2.0 beta going well, a few minor things to do before KEDA beta 2, Tsuyoshi working on some push stuff with scaled jobs (working to repro and fix) and some minor stuff in helm chart
- Tom was able to do the Azure podcast about KEDA
- Alibaba cloud was looking to do a blog post around how they are integrating with KEDA, and hopefully get logo on website
- Travis has a PR for the helm chart that has the API CRD changes - though a bug in helm 3.3 with linting, and blocked on that for now.
- Wanting to revert to older version of helm (< 3.3) for now so we can get it out there
- Preference is whatever is easiest / most convenient
- High availability
- Current state is that we DO have readiness and liveness probes, so Kubernetes should detect that it is down if it locked up
- The bottleneck currently is the metrics server. We can deploy multiple operators per namespace to partition in that regard, but are restricted to only have a single metrics server per cluster.
- Relying on a library for K8s that doesn't allow us to deploy multiple metrics servers
- If we did this it would require significant changes in the library
- Other potential ineffeciency is that we open and close connection each polling interval. Could do some better pooling / connection re-use to reduce the amount of outbound connections we are making
- https://github.com/kedacore/keda/issues/1121
- Best practice may be to do the multiple namespaces to partition it a bit
- Should create roadmap
- EVERYONE should take a bit of time to review some slack / issue stuff that's popped up around v2
- [ ] Jeff to add travis to have permission for GH actions on repos
- [ ] Jeff and Tom to start building out a roadmap
- [ ] Tom to help push out the KEDA 2.0 RC
## Sep 17th Meeting
### Proposed Agenda
- KEDA 2.0 release - no major issues
- Support for Helm 2.x - Travis has a solution for this, will follow up with him.
- New Logo is in mockup stage (Tom)
- Created an issue for CNCF incubation stage but a bit of work required for that (Tom)
- Have to do some process level stuff
- Pod Identity support in Azure Event Hubs - (Anirudh) to see if he can help get that implemented
- Ask for Pod Identity support for Log Analytics - the person who implemented the Scaler for this will do it.
- Since the v2 Beta is out - we need to decide how long should be wait before moving out of Beta - Tentatively **early October** if we dont hear any significant issues
- Usage
- Issues - If we dont hear anything significant her
- Open Items
- Question on how we construct the Scalers from the Golang code (Zbynek)
- Better connection management for the event sources
- (Ahmed) will have a look at it
- https://github.com/kedacore/keda/issues/1121
- (Tom) is doing a podcast for KEDA next week
- (Tom) We might be using some vulnerable packages in our testing
- https://github.com/kedacore/keda/network/alerts
- (Zbynek) can look at this
### Attendees
- Zbynek
- Ahmed
- Tom
- Anirudh
## Sept 3rd Meeting
### Proposed Agenda
- Standup Notes (Tom)
- Anyone having laggy experience lately as well? It's pretty unusable to me lately
- Should we move to Google docs? Happy to setup if we need to.
- Renaming metadata propertied to indicate source of the value (Tom - #1044)
- Change looks good to me but I would not only rename it to awsAccessKeyIDFromEnv but also support:
- Using literal values (awsAccessKeyID)
- Using trigger authentication (awsAccessKeyID)
- This gives people to use the right approach for their
- Now is the time with v2 imo
- Support for Helm 2.x (Tom)
- Helm 2.0 is [officially end of support](https://helm.sh/blog/helm-v2-deprecation-timeline/) and [v2.16.10](https://github.com/helm/helm/releases/tag/v2.16.10) is the last release
- I think we should stop supporting it so we can fix https://github.com/kedacore/charts/issues/18
- Docker Hub's new policy limiting image retention & Announcement for GitHub Container Registry (Tom - #995)
- Docker Hub is applying throttling on pulls (user-level) and automatically removing image tags that are no longer used (6m)
- GitHub Container Registry is announced which stores all images in our org
- Do we move or not? What is the benefit?
- I believe this will give us more metrics and centralizes everything in one place, but not a must
- Personally, I would move the CIs to GH CR and explore what it looks like. After that, evaluate if we should move our official images with a migration period
- Hacktoberfest is coming (Tom)
- Any chores we can list for people to pick up?
- KEDA artwork (missing lightning bolt)
- https://github.com/kedacore/keda/issues/650
- Any update on the logo?
- Standup Security
- Do we need to any more action or did we set the password already @jeff?
- Pod Identity support for Azure Event Hubs (Tom)
- Any chance we can add this for 2.0? Ahmed?
- https://github.com/kedacore/keda/issues/994
### Attendees
- Jeff
- Zbynek
- Travis
- Tomasz
- Anirudh
### Notes
- Hackmd- Zbynek mentioned that sometimes it lags for him as well (it's doing it for me right now). We're cool with google docs
- Just need to clean up formatting on the FromEnv and LGTM
- I think the best course of action is take the Travis fix. Pending closure on when /if 2.x charts get published and how the repo is structured but that approach for Helm 2 support seems good.
- On the docker registry one Jeff will email CNCF to see what other projects are doing.
- Group action item to mark items with Hacktoberfest / Good first issu / help wanted.
- Anirudh mentioned maybe we could put a banner on the keda.sh site that points to a simple docs page or even https://github.com/kedacore/keda/contribute
- Provide some useful description in the issues with hacktoberfest so people know where to start. So we need to revie w all issues and add clear action items / what's expected.
- Jeff will poke in jest the person who needed a few weeks before tweaking the SVG. In the meantime Tomasz mentioned he can give a shot
- Jeff will ad a password this week
- Event Hubs
- v2, just need to merge PRs and the Helm chart and migration guide for scaled jobs. Also update the migration guide with the table of metadata name changes from Ahmed
- Goal to release 2.x beta on TUESDAY
### Action Items
- [ ] TODO
## Aug rd Meeting
### Proposed Agenda
- 2.0 Release
- Blog post for alpha is available for preview
- https://github.com/kedacore/keda-docs/pull/226)
- What are the dates for alpha/stable?
- 2.0 Outstanding issues (Zbynek):
- Rename ScaledObject.spec.scaleTargetRef.containerName
- https://github.com/kedacore/keda/issues/1017
- Thoughts?
- Remove confusing fields in Scalers metadata
- https://github.com/kedacore/keda/issues/753#issuecomment-656224125
- Volunteer to implement this?
- Script to convert existing ScaledObjects from v1 to v2
- https://github.com/kedacore/keda/issues/946
- In progress by Travis
- IMHO doesn't have to be done for alpha
- ScaledJob Migration guide
- https://github.com/kedacore/keda-docs/issues/225
- Kafka Scaler fix
- PR opened: https://github.com/kedacore/keda/pull/996
- Pod Identity support for Azure Event Hubs (Tom)
- Any chance we can add this for 2.0? Ahmed?
- https://github.com/kedacore/keda/issues/994
- KEDA Dashboard (Tom - Post 2.0)
- Would love to bring [KEDA Dashboard](https://github.com/kedacore/dashboard) back to life and make it a scaling dashboard which could optionally even show cluster autoscaler and other non-KEDA things
- A bit similar to https://github.com/dapr/dashboard
- KEDA Extensibility (Tom - Post 2.0)
- Would love to have this in 2.1:
- [Emit Kuberentes Events on major KEDA events](https://github.com/kedacore/keda/issues/530)
- [Provide CloudEvent to extend KEDA](https://github.com/kedacore/keda/issues/479)
- KEDA artwork (missing lightning bolt)
- https://github.com/kedacore/keda/issues/650
- issue opened for almost 6m
- essential for merch/swag designs and production
### Attendees
- TODO
### Notes
- TODO
### Action Items
- [ ] TODO
## Aug 20th Meeting
### Proposed Agenda
- 2.0 Release
- Blog post for alpha is available for preview
- https://github.com/kedacore/keda-docs/pull/226)
- What are the dates for alpha/stable?
- 2.0 Outstanding issues (Zbynek):
- Rename ScaledObject.spec.scaleTargetRef.containerName
- https://github.com/kedacore/keda/issues/1017
- Thoughts?
- Remove confusing fields in Scalers metadata
- https://github.com/kedacore/keda/issues/753#issuecomment-656224125
- Volunteer to implement this?
- Script to convert existing ScaledObjects from v1 to v2
- https://github.com/kedacore/keda/issues/946
- In progress by Travis
- IMHO doesn't have to be done for alpha
- ScaledJob Migration guide
- https://github.com/kedacore/keda-docs/issues/225
- Kafka Scaler fix
- PR opened: https://github.com/kedacore/keda/pull/996
- Pod Identity support for Azure Event Hubs (Tom)
- Any chance we can add this for 2.0? Ahmed?
- https://github.com/kedacore/keda/issues/994
- KEDA Dashboard (Tom - Post 2.0)
- Would love to bring [KEDA Dashboard](https://github.com/kedacore/dashboard) back to life and make it a scaling dashboard which could optionally even show cluster autoscaler and other non-KEDA things
- A bit similar to https://github.com/dapr/dashboard
- KEDA Extensibility (Tom - Post 2.0)
- Would love to have this in 2.1:
- [Emit Kuberentes Events on major KEDA events](https://github.com/kedacore/keda/issues/530)
- [Provide CloudEvent to extend KEDA](https://github.com/kedacore/keda/issues/479)
- KEDA artwork (missing lightning bolt)
- https://github.com/kedacore/keda/issues/650
- issue opened for almost 6m
- essential for merch/swag designs and production
### Attendees
- TODO
### Notes
- TODO
### Action Items
- [ ] TODO
## Aug 6th Meeting
### Proposed Agenda
- 2.0 Release (T)
- Let's not forget the config alignment
- Alpha & full release planning?
- Proposal - Alpha next week, full end of Aug if possible
- Number of replicas remains the same after deleting ScaledObject (T - [#947](https://github.com/kedacore/keda/issues/947))
- Maintain last known state if prometheus is unavailable (Z - [#965](https://github.com/kedacore/keda/issues/965))
- Migrate to the new Kubebuilder based Operator SDK framework (Z - [#969](https://github.com/kedacore/keda/issues/969))
- Any volunteer to implement Script to do the migration from v1 to v2? (Z - [#946](https://github.com/kedacore/keda/issues/946))
- Standup authentication changes with Zoom (T - [#963](https://github.com/kedacore/keda/issues/963))
- Cluster Autoscale
### Attendees
- Jeff Hollan
- Zbynek Roubalik
- Travis Bickford
- Tsuyoshi
- Patrick McQuighan
- Tom Kerkhove (Codit)
### Notes
- 2.0 release is almost done
- Migration guide is on its way [link](https://keda.sh/docs/2.0/migration/)
- Fix job related problems and ship alpha next week
- Full release at end of the month, maybe sooner
- Tom will start working on the blog post next week ([WIP](https://docs.google.com/document/d/1vhT-wwEPPNImFmLZHGJxdKjUvKWk6ckeE7QCLSOJzLY/edit?usp=sharing))
- We should try to get the samples up-to-date based on the alpha version and assign an owner or archive them
- Number of replicas remains the same after deleting ScaledObject
- People agree that it should scale back to the original number
- However, Kubernetes & HPA without KEDA use the same approach
- [ ] Tom will update the issue to keep current approach and give option to scale back to the original instance count
- Maintain last known state if prometheus is unavailable
- Prometheus metric adapter will maintain the same instance count, while KEDA will scale back to 0 if it doesnt' have the count
- HPAs receiving errors from metric servers stop taking any action; this seems liek a safe aproach for us. Otherwise we can create autoscaling loops flooding whole cluster.
- This is how it works today so we are good to go
- We shouldn't do 1 -> 0 nor 0 -> 1 scaling if we cannot fetch metrics
- Would be nice for 2.0, otherwise afterwards
- Migrate to the new Kubebuilder based Operator SDK framework
- We are using Operator SDK which is being merged with Kubebuilder, we should check if we can migrate
- Has no functionality changes but just reshuffling of the code
- Will be done for 2.0 stable release
- Any volunteer to implement Script to do the migration from v1 to v2?
- Travis will look at this
- Aiming for full release
- Standup authentication changes with Zoom
- We need to migrate before Sept 21st
- We'll use password for meetings
- Cluster Autoscale
- A few folks at Amazon are managing EKS and looking at KEDA for event-driven autoscaling
- It won't be easy for cluster autoscaler as they don't provide APIs
- Long-requested feature for Kubernetes upstream
- Still in exploration phase
- Related - https://github.com/kubernetes/autoscaler/issues/3182
- e2e tests
- They seem flaky, what cluster are we running on?
- Jeff will check with Ahmed
- That's why we need cluster autoscaler integration ;)
## Archived Notes:
- [May 9 2019 - Jul 23 2020](https://hackmd.io/@jeffhollan/SkqW9_FVP)