# 2017q3 Homework2 (prefix-search)
contributed by < `maskashura` >
----
### Reviewed by `yusihlin`
* [Fix bugs](https://github.com/maskashura/prefix-search/commit/0689950435e30e56da19773587676f38b4042cd1) 有點模糊,雖然 commit 中的內文有針對修改的部分做描述,但在標題應該盡可能指出修改的焦點,相同的兩個 commit messages 卻做內容中不同部分的修改,可以使用 git commit --amend 和 git push -f 修正原有的 commit, 參考 [Git commit message 撰寫和改進實例](https://hackmd.io/s/HJQk5dt2x)
## Ternary search tree 原理
### Trie
在討論 ternary search tree 前我們先討論一個支援自動查詢,但較佔空間的結構 "trie"
Trie 為一種樹狀資料結構, 其中每個 node 都包含一組指標陣列, 一個指向字元 character 中各個字母的指標。 我們可以從根節點開始,透過目標字中的字母對應的指標來追蹤一個單字詞。
:::danger
1. 你不覺得「一個指於各個 character 中字母的指標」這樣的翻譯很難懂嗎?
2. 你不需要從 Wikipedia 翻譯,相反的,應該理解後,嘗試用自己的認知紀錄和描述下來。這是很重要的訓練,而且是本課程在意的
:notes: jserv
:::
> [name=Bruce Ke]謝謝老師指教,今後的作業我會加強並改進!
這裡討論以 trie 型式儲存的字串 AB, ABBA, ABCD, 及 BCD. 字串的終止節點標記為黃色:

([圖片來源](http://igoro.com/archive/efficient-auto-complete-with-a-ternary-search-tree/))
使用 Trie 實現自動完成 (auto-completion) 很容易。我們只需追踪指標來獲得一個表示使用者輸入的字串的節點。透過從該節點搜尋 trie ,我們可以列舉所有完成使用者輸入的字串。
但是,我們可以由上圖中看到一個 trie 的主要問題。上圖 trie 僅支援4個字母 {A,B,C,D}。如果我們需要支援到所有26個英文字母,意味著每個節點將存儲 26 個指標。而且,==如果我們需要支持萬國碼(international characters),標點符號或區分小寫字母,則所需的記憶體空間將變得非常巨大。==
:::danger
character 在台灣和繁體中文的翻譯慣例為「字元」,共筆有一堆這樣的誤寫,請及早修正
:notes: jserv
:::
> [name=Bruce Ke]己修正共筆中不正確的誤寫
我們可以考慮在每個節點中使用不同的數據結構,例如 HASH mapping 。然而,管理成千上萬的 HASH maps 通常不是一個好主意,所以讓我們來看看一個更好的解決方案。
### Ternary search tree (TST)
三元搜尋樹 (ternary search tree) 是一種 trie 的型式 (有時稱為 prefix tree), 有點類似 Binary search tree ,但 ternary search tree 是由三個子樹 (children) 所組成的, ternary search tree 每個節點由一個字元 character 構成,m一個 value ,及三個指向子樹的指標(分別為 equal kid, lower kid and higher kid), 下面引用作業中 TST node 結構做參考。
```clike=
/** ternary search tree node. */
typedef struct tst_node {
char key; /* char key for node (null for node with string) */
unsigned refcnt; /* refcnt tracks occurrence of word (for delete) */
struct tst_node *lokid; /* ternary low child pointer */
struct tst_node *eqkid; /* ternary equal child pointer */
struct tst_node *hikid; /* ternary high child pointer */
} tst_node;
```
:::danger
1. search 在台灣和繁體中文翻譯的慣例為「搜尋」,請尊重自己的文化
2. 「以及一個實現物件 object」這句話是不是很奇怪?而且和程式碼匹配嗎?
:notes: jserv
:::
> [name=Bruce Ke]己修正共筆中不正確的誤寫, 並修正內文與作業程式碼匹配
而和標準的 prefix tree 相比 ==ternary search tree 的空間效率更高, 以速度為代價== (雖然較其他 prefix tree 慢,但是由於其空間效率,三元搜尋樹適合應用在較大的資料集( data set )。
:::danger
1. data set 在繁體中文翻譯為「資料集」
2. 「三元搜索樹可以更適合於...」這段中文描述不順口,請修改
:notes: jserv
:::
> [name=Bruce Ke]修正 data set 的誤寫, 並修正為"三元搜尋樹適合應用在較大的資料集"
我們將以上述的字串 AB, ABBA, ABCD, 及 BCD 做三元搜尋樹的討論
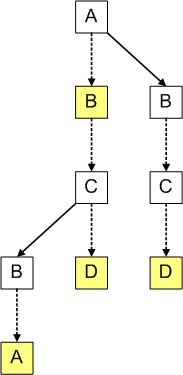
([圖片來源](http://igoro.com/archive/efficient-auto-complete-with-a-ternary-search-tree/))
* 三元搜尋樹包含三種類型的箭頭。首先,有對應於相應 trie 的箭頭(如虛線箭頭所示)。
* 實線向下箭頭對應於“ matching ”箭頭開始的字串。目前字串與目前位置的所需字元不匹配時,箭頭將被左右移動。
* ==我們和正在尋找的字串和目前節點的字元相比(以字母排序),若字元排序小於則向左找, 若大於則向右找==
:::danger
"current" 的繁體中文翻譯為「目前」,而非「當前」,兩者的應用情境不同
:notes: jserv
:::
例如,綠色箭頭顯示如何確認三元樹包含字串 ABBA:
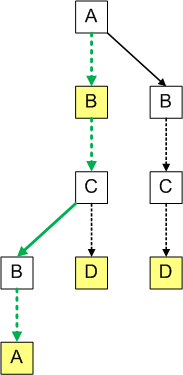
([圖片來源](http://igoro.com/archive/efficient-auto-complete-with-a-ternary-search-tree/))
而我們可以在下圖發現 ternary string 中不含字串 ABD:
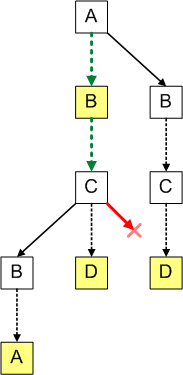
([圖片來源](http://igoro.com/archive/efficient-auto-complete-with-a-ternary-search-tree/))
可以使用三元搜尋樹來解決許多問題,其中大量的字串必須以==任意順序儲存和檢索==。一些最常見的應用的如下:
:::danger
"store" 的繁體中文翻譯為「儲存」,而非「存儲」。你可以適度摘錄和引用簡體中文內容,但應該用繁體中文慣用語改寫。愛護自己的文化,你我有責。
:notes: jserv
:::
> 謝謝老師提醒,己修正繁體中文慣用詞為"儲存"
> [name=Bruce Ke]
* 任何時候都可以使用 trie ,但優先選用的是 memory-consuming 較少的結構
* 一種快速,節省空間的數據結構,用於將 string 映射到其他數據
* 自動完成 (auto-completion)
* 拼寫檢查 (spell-checking)
* 鄰近搜尋(其中拼寫檢查是特殊情況)。
* 代替 HASH table
Ternary Search Tree (TST)時間複雜度表示如下:
|Algorithm | Average| Worst Case|
|-----------|----------|--------------|
|Search |O(log n) | O(n) |
|Insert |O(log n) | O(n) |
|Delete |O(log n) | O(n) |
----
## 開發系統環境:
```shell
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 2
On-line CPU(s) list: 0,1
Thread(s) per core: 1
Core(s) per socket: 2
Socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 23
Model name: Pentium(R) Dual-Core CPU T4300 @ 2.10GHz
Stepping: 10
CPU MHz: 1600.000
CPU max MHz: 2100.0000
CPU min MHz: 1200.0000
BogoMIPS: 4190.13
L1d cache: 32K
L1i cache: 32K
L2 cache: 1024K
NUMA node0 CPU(s): 0,1
```
----
~~### Segmentation fault 錯誤修正~~
### 修正超出邊界的記憶體操作
:::danger
1. [segmentation fault](https://en.wikipedia.org/wiki/Segmentation_fault) 是「結果」,而你在分段標題應該明確提及「分析後的現象」,像是「超出邊界的記憶體操作」
2. 除了用 GDB 追蹤外,應當思考如何有效分析原始程式碼同類型的錯誤。提示: [Clang Static Analyzer](https://clang-analyzer.llvm.org/)
:notes: jserv
:::
在原始程式執行時,會發現在做 search words matching prefix 輸入"A"發現會有出現 Segmentation fault ,使用 GDB 去追蹤,可發現錯誤出現在 a[(*n)++] = (char *) p->eqkid; (at tst.c:330)
```shell
Program received signal SIGSEGV, Segmentation fault.
0x0000555555555eea in tst_suggest (p=0x555556b1cb90, c=65 'A', nchr=1, a=0x7fffffffbdd0, n=0x7fffffffbd90, max=1024) at tst.c:330
330 a[(*n)++] = (char *) p->eqkid;
```
但"Ab"可搜尋到190筆資料, 而輸入其他單字如B,C,D..皆能正常執行沒發生錯誤, 故我開始檢查 tst_suggest 中的程式碼
```clike=317
void tst_suggest(const tst_node *p,
const char c,
const size_t nchr,
char **a,
int *n,
const int max)
{
if (!p || *n == max)
return;
tst_suggest(p->lokid, c, nchr, a, n, max);
if (p->key)
tst_suggest(p->eqkid, c, nchr, a, n, max);
else if (*(((char *) p->eqkid) + nchr - 1) == c)
a[(*n)++] = (char *) p->eqkid;
tst_suggest(p->hikid, c, nchr, a, n, max);
}
```
從tst_suggest的程式碼中, 我們會發現tst_suggest()會遞迴呼叫自己,而在 a[(*n)++] = (char *) p->eqkid; 這段程式 *n 會持續往上加並執行遞迴,而當 *n 值 >=1024(a[1024])時,程式就會發生 Segmentation fault
開始對 *n 進行檢查, 避免*n存取到錯誤區段
```clike
else if (*(((char *) p->eqkid) + nchr - 1) == c ){
if (*n < max)
a[(*n)++] = (char *) p->eqkid;
}
```
:::danger
上述程式碼可改寫為:
```clike
else if ((c == (*(((char *) p->eqkid) + nchr - 1)) &&
(*n < max)) {
a[(*n)++] = (char *) p->eqkid;
}
```
:notes: jserv
:::
修改後結果如下, A字元~~看起來~~可以正常執行搜尋:
> 不要說「看起來」,只要你能確保都可重現 (reproduce),就是「可以」。用語要精確
> [name="jserv"][color=red]
```shell
...
suggest[1016] : Akwanga,
suggest[1017] : Akwatia,
suggest[1018] : Akyab,
suggest[1019] : Akyazı,
suggest[1020] : Akyurt,
suggest[1021] : Akzhal,
suggest[1022] : Alà
suggest[1023] : Alàs
```
----
### FIXME程式修改
根據tst.h文件內的註解, 並依據 Fixme 的指示將 CPY 都改成 REF, 但在觀察 CPY 及 REF 二個變數後可以發現CPY一開始被定義為1,而DEL被定義為0
```clike=8
/** constants insert, delete, max word(s) & stack nodes */
enum { INS, DEL , WRDMAX = 256, STKMAX = 512, LMAX = 1024 };
#define REF INS
#define CPY DEL
```
我試著將tst.h內的 CPY 都改成 REF, 重新make後執行可以發現程式在 search words matching prefix 出現錯誤(搜尋結果僅列出開頭第一個字母)
```shell
suggest[1017] : A
suggest[1018] : A
suggest[1019] : A
suggest[1020] : A
suggest[1021] : A
suggest[1022] : A
suggest[1023] : A
```
用gdb檢查單步執行 並顯示變數值 可以發現在sgl[i]並沒有放入完整字串
```shell
126 for (int i = 0; i < sidx; i++)
(gdb) n
127 printf("suggest[%d] : %s\n", i, sgl[i]);
(gdb) p i
$1 = 0
(gdb) p sgl[0]
$2 = 0x7fffffffddd0 "A"
(gdb) n
suggest[0] : A
126 for (int i = 0; i < sidx; i++)
(gdb) n
127 printf("suggest[%d] : %s\n", i, sgl[i]);
(gdb) p sgl[1]
$3 = 0x7fffffffddd0 "A"
```
故我們開始回推程式尋找程式中和 CPY 及 REF 有關的地方, 最後在tst.c中的 tst_ins_del 發現有 CPY 關連的地方
1).
```clike
void *tst_ins_del(tst_node **root, char *const *s, const int del, const int cpy)
```
2).
> 程式碼應該用指定的 coding style 編排 (4 個空白,而非 tab),開發的紀律和對細節的重視,不能少!
> [name="jserv"][color=red]
>
[PSR-1](https://github.com/php-fig/fig-standards/blob/master/accepted/PSR-1-basic-coding-standard.md)
>謝謝老師提醒,查了網路一下,才知道原來不只為了防止不同編輯器作業下格式混亂,許多大公司也開始規定程式需以空白代替tab
> [name=Bruce Ke]
```clike=274
if (*p++ == 0) {
if (cpy) { /* allocate storage for 's' */
const char *eqdata = strdup(*s);
if (!eqdata)
return NULL;
curr->eqkid = (tst_node *) eqdata;
return (void *) eqdata;
} else { /* save pointer to 's' (allocated elsewhere) */
curr->eqkid = (tst_node *) *s;
return (void *) *s;
}
}
```
可以發現 CPY 及 REF 的差異在於 , CPY 會分配一塊儲存空間 ==const char *eqdata = strdup(*s)==, 但此方式系統會不斷要求分配記憶體空間,而造成資料空間片段而不連續, 而不斷 malloc 和 free 記憶體區塊。會導致記憶體的碎片問題,碎片一多可使用的記憶體就變少最後產生 memory leak
>to do: 能否用GDB去觀察記憶體空間
而 REF 並沒有分配空間,會將指標指向資料位置 ==curr->eqkid = (tst_node *) *s==
我們試著在 REF 分配記憶體空間,同時避免如 CPY 不連續的記憶體配置方式, 我們一次分配較大的記憶體空間( memory pool )
----
## 作業要求
* 在 GitHub 上 fork [prefix-search](https://github.com/sysprog21/prefix-search),並修改 `Makefile` 以允許 `$ make bench` 時,可對 ternary search tree 的實作做出效能評比,涵蓋建立 tst 和 prefix search 的時間,應比照 [clz](https://hackmd.io/s/Hyl9-PrjW) 透過統計模型,取出 95% 信賴區間
* 測試程式碼應該接受 `--bench` 的執行參數,得以在沒有使用者輸入的前題下,對 tst 程式碼進行效能分析,應涵蓋 `cpy` 和 `ref` 兩種途徑 (詳情參閱 `tst.h` 的程式碼註解)
* 解釋 tst 的優點和引入 tst 到電話簿或戶政管理系統的適用性
* 修改 [test_ref.c](https://github.com/sysprog21/prefix-search/blob/master/test_ref.c),參照裡頭標註 `TODO` 的部分,替換成真正有效的 API 和對應的程式碼,這裡要求你學習分析現有的程式碼並得以擴充
* 分析 `test_cpy` 和 `test_ref` 兩種方式 (copy/reference) 的效能,並且針對現代處理器架構,提出效能改善機制
* 指出目前實作中,針對各國城市的 prefix search 有無缺陷呢?比方說無法區分城市和國家,並提出具體程式碼的修正
* 引入 [phonebook](https://hackmd.io/s/HJJUmdXsZ) 的基礎工作,透過 [ternary search tree](https://en.wikipedia.org/wiki/Ternary_search_tree) 讓電話簿程式得以更符合人性,當使用者新增資料時,可以在居住地透過 prefix search 找出最接近的城市並避免輸入錯誤
* 詳細觀察 `tst.h` 和 `tst.c` 為何要 forward declaration 呢?分離介面和實作有何好處呢?這樣的思維又該如何運用於 [phonebook](https://hackmd.io/s/HJJUmdXsZ) 呢?提出想法並且實作
* 研究程式碼的 `tst_traverse_fn` 函式,並思考如何運用這個實作,注意到 [callback function](https://en.wikipedia.org/wiki/Callback_(computer_programming)) 的程式開發技巧/模式
* 將你的觀察、上述要求的解說、應用場合探討,以及各式效能改善過程,善用 gnuplot 製圖,紀錄於「[作業區](https://hackmd.io/s/HkVvxOD2-)」
Reference:
1. [Efficient auto-complete with a ternary search tree](http://igoro.com/archive/efficient-auto-complete-with-a-ternary-search-tree/)
2. [Ternary Search Tries](https://www.youtube.com/watch?v=LelV-kkYMIg)
3. [Ternary search tree From Wikipedia](https://en.wikipedia.org/wiki/Ternary_search_tree)
4. [GDB document](https://www.gnu.org/software/gdb/documentation/)
5. [zhanyangch同學共筆](https://hackmd.io/s/Syc8yOhhW#)
6. [ChiuYiTang同學共筆](https://hackmd.io/s/ByeocUhnZ)
 Sign in with Wallet
Connect another wallet
Sign in with Wallet
Connect another wallet