# 2017q3 Homework1 (phonebook)
contributed by < `BreezeDa` >
###### tags: `sysprog2017`
## Linux 效能分析工具: Perf
Perf 全名是 Performance Event,他可以測量 CPU performance counters, tracepoints, kprobes, and uprobes (dynamic tracing)。他可取樣分析的東西很多,不過可以分成三類:
- Hardware event
- Software event
- Tracepoint event
### 跑個範例程式
跟著 [perf 原理和實務](https://hackmd.io/s/B11109rdg) 實作一次範例,利用 perf 取樣以下程式
```clike=
#include <stdio.h>
#include <unistd.h>
double compute_pi_baseline(size_t N) {
double pi = 0.0;
double dt = 1.0 / N;
for (size_t i = 0; i < N; i++) {
double x = (double) i / N;
pi += dt / (1.0 + x * x);
}
return pi * 4.0;
}
int main() {
printf("pid: %d\n", getpid());
sleep(10);
compute_pi_baseline(50000000);
return 0;
}
```
程式碼中的 compute_pi_baseline() 代入了相當大的整數,由此我們可以猜側程式大部分的時間將會花在該函式中的 for loop。
在程式執行後,會先印出 pid,我們趁他執行結束前輸入以下指令,便可對該程式做取樣
```
$ sudo perf top -p $pid
```
當程式跑完, perf 便會秀出取樣結果
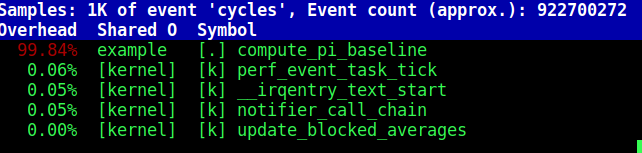
由上圖 "cycles",知道數據表示 cycle 百分比,而結果如我們所預期的 compute_pi_baseline() 佔了很高的比例
### 基本指令
- `$ perf list` : 可列出 perf 目前可以觸發的 event , 將會看到 Hardware event、 software Event 、 HardWare cache event,另外據 [perf 原理和實務](https://hackmd.io/s/B11109rdg) 描述,需要 root 權限才可以看到 trace point event。
- `$ perf top` : 該指令類似 linux 內建的 top 它能夠「即時」的分析各個函式在某個 event 上的熱點 (或者說 bottleneck),找出拖慢系統的兇手,就如同上面那個範例一樣。預設的 event 是 cycle , 預設的取樣頻率是 4000 次/s,若 event 想改為 cache miss ,頻率想改為 5000 `$ perf top -e cache-misses -c 5000`
-
參考資料
- [perf 原理和實務](https://hackmd.io/s/B11109rdg)