CPU Cache 原理探討
===
由此圖可見,從主記憶讀取資料是最慢的,而從第一級快取讀取資料是最快的。另外,根據 [Wikipedia: 記憶體階層](https://zh.wikipedia.org/wiki/%E8%A8%98%E6%86%B6%E9%AB%94%E9%9A%8E%E5%B1%A4),我們也可以知道,不同階級快取之間的關係為:
* 第一級快取(L1)–通常存取只需要幾個週期,通常是幾十個KB。
* 第二級快取(L2)–比L1約有2到10倍較高延遲性,通常是幾百個KB或更多。
* 第三級快取(L3)(不一定有)–比L2更高的延遲性,通常有數MB之大。
## Lecture 1/9 - Caches-Intro
>參考網站:[Caches-Intro](https://www.youtube.com/watch?v=chnhnxWIjgw)
基本上就是在講,為什麼要有 Cache , 以及 Cache 扮演的角色。以下以我自己整理的內容取代。
### 1.1 什麼是 CPU Cache
> A CPU cache[1] is a hardware cache used by the central processing unit (CPU) of a computer to reduce the average cost (time or energy) to access data from the main memory.
根據 [Wikipedia: CPU Cache](https://en.wikipedia.org/wiki/CPU_cache),可以知道 CPU cache
是一種被電腦的 CPU 用來降低從主記憶體 (Main Memory) 存取資料時所耗費的時間的快取(Cache)。
上面的定義看不懂? 簡單來說,CPU Cache 就是介於 CPU 和 主記憶體之間的中繼站。如下圖所示:

>圖片來源:[Lecture 1/9:Caches-Intro](https://www.youtube.com/watch?v=chnhnxWIjgw)
CPU Cache 跟 主記憶體的差別在於:
* CPU Cache 的儲存空間不大,但是能夠快速的被 CPU 存取資料。
* 主記憶體儲存空間大,但是存取資料的時間相對慢很多。
而 CPU Cache 通常都會被安裝在 CPU 上。
### 1.2 為什麼要有 CPU Cache
那為什麼要有 CPU Cache 呢?我們可以從下面這張圖得到一點提示:
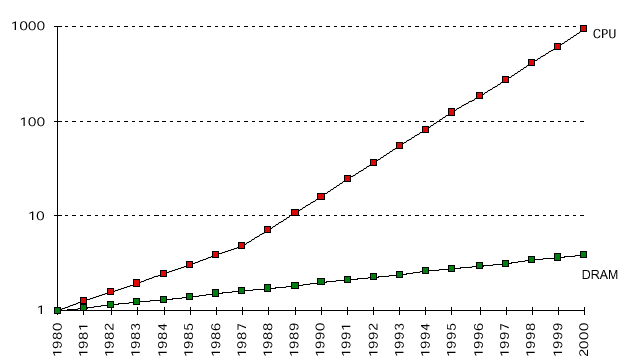
>圖片來源:[Data Commentary](http://hzch.blogspot.tw/2012/04/data-commentary.html)
根據 [Data Commentary]((http://hzch.blogspot.tw/2012/04/data-commentary.html))
>From the picture, we can see that the clock rate of CPU is increasing about 30% per year and the overall performance has increased 1000 times; while the memory speed only increase in a speed about 10% per year, and increased less than 10 times totally.
從這張圖中,我們可以知道 CPU 的時脈(clock rate) 每年提昇約 30% 。到 2010 年為止,與 1980 年相比,效能也提昇了約 1000 倍。然而,主記憶體(DRAM) 的速度每年只提昇了約 10%。到 2010 年為止,與 1980 年相比,效能提昇的幅度還不到 10 倍。因此,
因此,即使 CPU 能夠以非常快的速度進行運算,由於存取主記憶體裡的資料時所耗費的時間跟 CPU 的運算速度相差太大,所以電腦的運算效能還是被限制住了。
為了解決 CPU 的運算速度和主記憶體的讀取速度之間的差異造成的效能限制,人們開始是將主記憶體裡的資料先複製在一種能夠被快速存取的記憶體裡([SRAM](https://zh.wikipedia.org/wiki/%E9%9D%99%E6%80%81%E9%9A%8F%E6%9C%BA%E5%AD%98%E5%8F%96%E5%AD%98%E5%82%A8%E5%99%A8)),也就是我們現稱的 CPU Cache。因此當 CPU 要進行運算時,CPU 就會先到 CPU Cache 裡找找看有沒有他需要的資料,以減少 CPU 在主記憶體存取資料時所需要耗費的時間。(或是換句話說,我們只需要將 CPU 在運算時常用的資料儲存在 CPU Cache 裡,就能夠大幅提昇電腦的運算速度!)
### 1.3 不同階級的 CPU Cache
```
$ lscpu
CPU(s): 4
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 3072K
```
由於我的電腦的 CPU 為 4 核心,且共有三種不同的 CPU Cache,依序為:
1. L1 Cache (L1d, L1i)
* L1**d** 代表 L1 Cache for **Data**
* L1**i** 代表 L1 Cache for **Instruction**
2. L2 Cache
3. L3 Cache
若以圖形的方式來表達我的 CPU 的結構的話,會如下圖所示:

>圖片來源:[Lecture 1/9:Caches-Intro](https://www.youtube.com/watch?v=chnhnxWIjgw)
從這張圖我們可以發現,每個 CPU Core 都有屬於自己的 L1 和 L2 Cache,並且這些不同的 Core 會共用 L3 Cache。因此當 CPU 運算時,CPU 會先到 L1i Cache 去看他接下來要做哪些運算,再到 L1d Cache 去找運算時所需存取的資料。而 L1i Cache 和 L1d Cache 的資料來自 L2 Cache, L2 Cache 的資料來自 L3 Cache, L3 Cache 的資料來自主記憶體。
>需要注意的是,CPU 對於 L1d Cache 的處理會比 L1i Cache 還複雜,因為在 CPU 運算時,L1i Cache 裡的資料是不會被變更的,而 L1d Cache 仍可能會被寫入新的數值。
**那為什麼要有不同階級的快取呢?**
由於 CPU 在運算時需要存取的資料的大小越來越大,原本的第一級存取 (L1 Cache) 沒辦法提供足夠儲存空間,而增加第一級存取的數目又將導致成本大幅提昇。為了解決這個問題,人們採納了讀取速度沒有第一級快取快,但儲存空間較第一級快取大的第二級快取 (L2 Cache) 來當作主記憶體和第一級快取之間的暫存空間。因此,若第一級快取的儲存空間不夠大時,仍然可以將主記憶體裡的資料複製到第二級快取中,而從第二級快取中存取資料的速度仍然比從主記憶體中存取資料還要快。
下圖顯示了不同階級的快取與主記憶的讀取速度之間的比較:
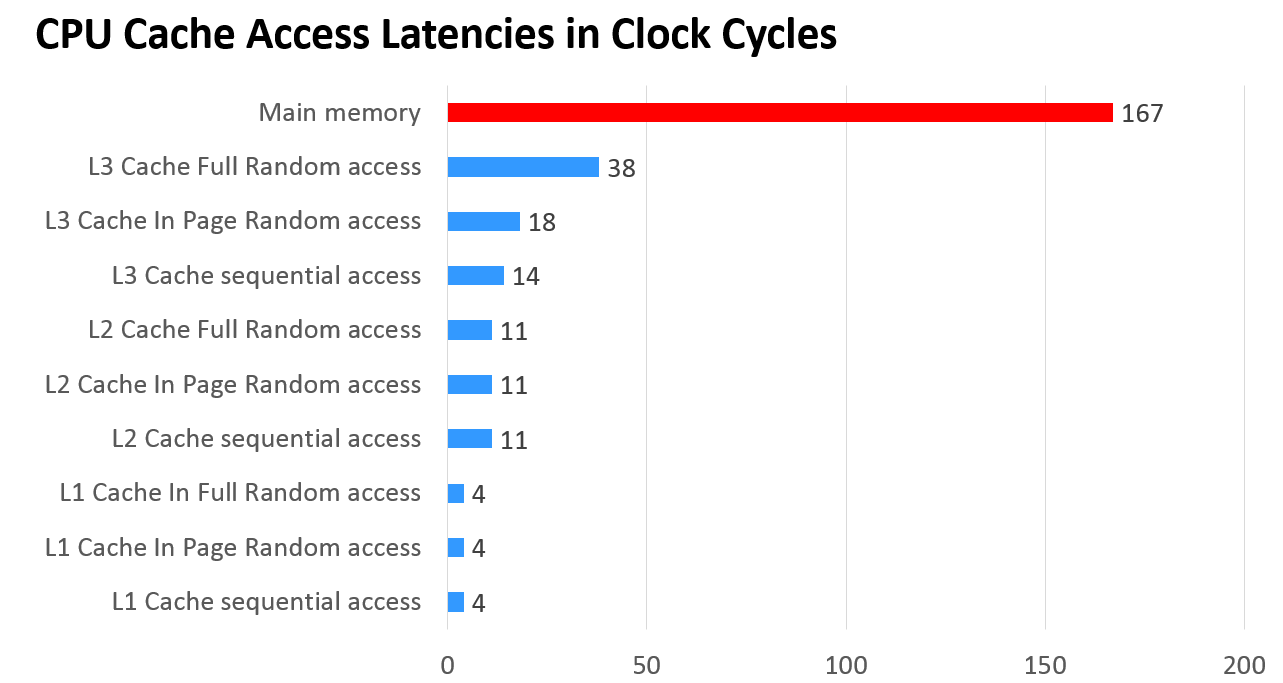
## Lecture 2/9 - Caches-Basic Concepts
>參考網站:[Caches-Basic Concepts](https://www.youtube.com/watch?v=rvTkRef4K48)
### 2.1 Block
* 從下級記憶體(例如:主記憶體) 複製資料到 上級記憶體(例如: Cache) 時的最小單位
* 通常是 64 Bytes (512 Bits)
* 
### 2.2 Cache Hit
* 當 CPU 可以從 Cache 中的 Block 裡找到他想要找的資料時,稱為 **Cache Hit**
### 2.3 Cache Miss
* 當 CPU 沒有辦法從 Cache 中的 Block 裡找到他想要找的資料時,稱為 **Cache Miss**
* 會導致讀取速度下降
* Cache 必須去 主記憶體或其他下層記憶體中找到含有 CPU 想要找的資料的 Block,並複製到 Cache 後,才能將資料 傳給 CPU。
### 2.4 Eviction / Replacement
* 當新的 Block 被複製到 Cache 時,必須將其他 L.R.U (Least Recently Used) 的 Block 移除,而此動作稱為 **Eviction**。
### 2.5 The Address / Data Bus

* 當 CPU 想要讀取特定記憶體位置上的資料時:
* CPU 會將他想要讀取的資料的記憶體位置透過 ADDR 的訊號線傳遞
* CPU 會發佈 Read 的訊號,並透過 READ 的訊號線傳遞
* 主記憶體 會接收到該 READ 的訊號,並根據 ADDR 的訊號線上的 記憶體位置,將該記憶體位置上的資料透過 DATA 訊號線傳遞出去
* CPU 可以透過 DATA 訊號線接收到 他想要讀取的資料。
* 當 CPU 想要修改特定的記憶體位上的資料時:
* CPU 會將他想要修改的資料的記憶體位置透過 ADDR 的訊號線傳遞
* CPU 會將他想要修改的資料透過 DATA 訊號線傳遞出去
* CPU 會發佈 WRITE 的訊號,並透過 WRITE 的訊號線傳遞
* 主記憶體 會接受到 WRITE 的訊號,並根據 ADDR 的訊號線上的 記憶體位置 和 DATA 的訊號線上的 資料修改 該記憶體位置上的資料。

* 若 CPU 與 主記憶體 之間 存在 Cache
* 則他們之間的 溝通方式(READ/WRITE) 也如剛剛的例子一樣
* 對 CPU 而言,他不知道 Cache 的存在,以為 Cache 是 主記憶體。
* 對 主記憶體 而言,他也不知道 Cache 的存在,以為 Cache 是 CPU。
* 當 Cache 和 CPU 在溝通時,Cache 辦演的角色是 主記憶體。
* 當 Cache 和 主記憶體 在溝通時,Cache 辦演的角色是 CPU。
## Lecture 3/9 - Caches-Locality
>參考網站:[Caches-Locality](https://www.youtube.com/watch?v=LzsiFYVMqi8)
### 3.1 Typical Programs
* 程式中的有些 **指令(Instructions)** 常常會被重複執行
* ``` C Program
for (i=0, i<N, i++){
for (j=0, j<M, j++){
... Loop Body ...
}
}
```
* 此時的 Loop Body 中指令 被稱為 熱點(Hot Spot)
* 若在一段時間內,只有一部分的指令會被不斷執行,則稱 這些指令 在 Working Set 中。
* Working Set 中的 指令(Instructions) 會隨時間改變。
### 3.2 Typical Data Usage
* 有些 **變數(Variables)** 或 **資料(Data)** 常常會被使用
* ``` C Program
for (...){
for (...){
sum += ...
}
}
```
* 此時的變數 **sum** 被稱為 熱點(Hot Spot)
* 在 Working Set 中的 變數 會被常常使用。
* 因此,若上述的範例程式執行到 此雙 for 迴圈的部分時,變數 sum 會在 Working Set 中。
* Working Set 中的 資料(Data) 跟 指令(Instruction) 一樣會隨時間改變。
### 3.3 The Principle of Locality
* **Temporal Locality**
* 如果記憶體中的一個 Byte 最近被使用過,則該 Byte 在未來很有可能會再被使用。
* **Spatial Locality**
* 如果記憶體中的一個 Byte 最近被使用過,則該 Byte 附近的 Bytes 在未來也很有可能會被使用。
* 以上兩種 Locality 皆適用於 **資料(Data)** 和 **指令(Instruction)**
### 3.4 The Working Sets
* 定義:
* The set of bytes that were used recently.
* 翻譯:最近使用過的 一組字節(bytes)。
* The set of bytes that will be needed soon.
* 翻譯:很快就會被需要用到的 一組字節(bytes)。
* 如果能將 Working Set 儲存在 CPU Cache 中,則程式的運算速度將會大幅提升。
* 方法:
* 當將 一組字節 儲存在 CPU Cache 後,將 該組字節 保留在 CPU Cache 中。 (Temporal Locality)
* 盡量保留最常被使用的 一組字節。
* 當將 一組字節 被儲存到 CPU Cache 後,連帶將該組字節附近的字節一起儲存至 CPU Cache 中。 (Spatial Locality)
### 3.5 The Working Set Changes

* 當一個程式執行到紅色虛線框框內的部分時,在該框框內被使用到的字節被稱為 Working Set。
* 如果 Working Set 中的字節都能被儲存到 CPU Cache 的話,程式執行的速度就會很快。
* 也就是沒有所謂的 Cache Miss 的情況發生時,程式執行的速度就會很快。
* 然而很明顯的,若是我們關住的紅色框框變大的話,Working Set 的大小也會變大。
* 若想要應付更大的 Working Set,就需要擁有更大的儲存空間的 CPU Cache。
### 3.6 Data Locality

* 這裡有兩個 for 迴圈所構成的程式,且右旁有將 A 陣列的記憶體位置畫出來。
* 第一個程式的 stride 為 `1` ,因此這個程式有比較好的 Data Locality。
* 也就是說,一筆資料 附近的資料被使用的機率比較高。
* 第二個程式的 stride 為 `4` ,因此這個程式的 Data Locality 比較差。
* 也就是說,一筆資料 附近的資料被使用的機率比較低。
* 因此第二個程式比較容易發生 Cache Miss。
### 3.7 2-D Arrays: Row - Major Storage

* 在大部分的程式語言中(例如 C 語言),二維陣列的儲存方式是以 Row 為主。
* 例如:Row 0 (A(0,0),A(0,1),A(0,2)) -> Row 1 (A(1,0),A(1,1),A(1,2))
* 因此
* ``` C Program
//Program 1
for(i=0; i<4; i++){
for(j=0; j<3; j++){
....A[i,j].....
}
}
//Program 2
for(j=0; j<3; j++){
for(i=0; i<4; i++){
....A[i,j].....
}
}
```
* 程式 1 的 Data Locality 會比 程式 2 還要來的高。
* 也就是說 程式 1 發生 Cache Miss 的機會比 程式 2 低。

* 若假設
1. Cache 的 Block 的大小為 64 bytes (也就是 8 個 double 變數)
2. 程式的 Stride 為 1
* 則當程式要讀取 Row 294 的第一個字節時,7個後續的字節(因為在同一個 Block 中)也將會被一起存入 CPU Cache 中。
* 代表
* 每一次 Cache Miss 之後就會有 七次 Cache Hits
* Cache Hit Rate 為 ${{7}\over{8}} = 87\%$
* Cache Miss Rate 為 ${{1}\over{8}} = 12\%$
## Lecture 4/9 - Caches-Writes and Coherency
>參考網站:[Caches-Writes and Coherency](https://www.youtube.com/watch?v=P565tSWTSwY)
### 4.1 Main Memory
* 不知道自己的記憶體位置,但是知道自己的數值。
### 4.2 Cache
* Cache 裡的 Block 是來自於主記憶體中的 Block。
* 因此 Cache 裡的 Block 需要額外記錄相對應的記憶體中的 Block 的記憶體位置。
### 4.3 When CPU Wants to Read
* 如果在 Cache 裡可以找到想要讀取的資料 -> **Cache Hit**
* 相反的,如果找不到 -> **Cache Miss**
* 此時 Cache 會將 含有想要讀取的資料的 Block 從主記憶體中複製到 Cache 裡,並將最久沒有被使用的 Block 清除 -> **Eviction**
### 4.4 When CPU Wants to Write
* 如果在 Cache 裡可以找到想要寫入的資料位置 -> **Write Hit**
* **Write Through**
* 修改 Cache 中的 Block 的數值後,一併修改主記憶中相對應的 Block 的數值。
* **Write Back**
* 修改 Cache 中的 Block 的數值後將此 Block 標記為 **Dirty Block**,但並不會立即修改主記憶體中相對應的 Block 的數值,而是等到 Cache 中的此 Block 被取代時 (Eviction),才會修改主記憶體中相對應的 Block 的數值。
* 此方式有資料遺失的危險,但是速度較快。
* 相反的,如果找不到 -> **Write Miss**
* **Write Allocate**
* 將主記憶體中含有想要寫入的記憶體位置的 Block 複製到 CPU Cache 中,並在修改 Cache 中該 Block 的數值後將該 Block 標記為 **Dirty Block**。
* **Write No Allocate**
* 直接將寫入的訊號從 CPU Cache 繼續傳遞到主記憶體,並直接修改主記憶體中含有想要寫入的記憶體位置的 Block 的數值,但卻不會將此 Block 複製到 CPU Cache 中。
### 4.5 Typical Approach
* Write Hit 時使用 Write Back
* Write Miss 時使用 Write Allocate
### 4.6 Cache Line Explained
>由於我覺得影片中的這個部分沒有解釋得很清楚,所以這裡我參考的是 [這個網站](https://www.zhihu.com/question/24612442) 和 [這份講義](https://cseweb.ucsd.edu/classes/su07/cse141/cache-handout.pdf)
>

>圖片來源:[Carnegie Mellon](https://link.zhihu.com/?target=http%3A//cs.slu.edu/~fritts/csci224/schedule/chap6-cache-memory.pptx)
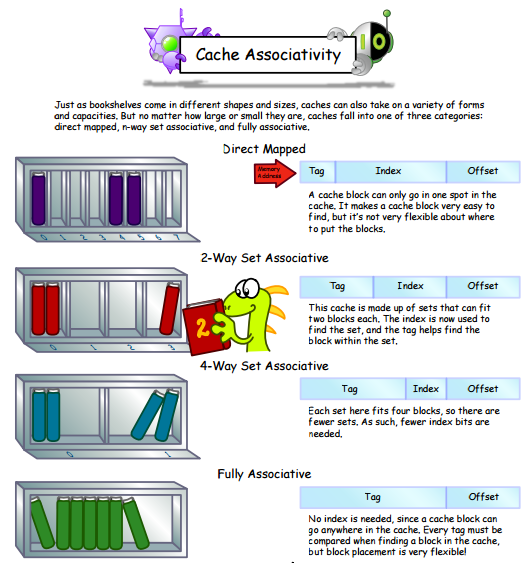
* Cache 是由 **Set** 組成,**Set** 是由 **Line** 組成, **Line** 則是由 **Valid Bit** 、 **Tag** 、 和 **Data** 組成。
* 一個 Set 裡有幾個 Line/Block 是由 Cache 的邊排(layout) 決定的
* 常見的 layout 有三種:
* **Directed Mapped**
* **Set Associative**
* **Fully Associative**
* 
* Tag 是用來區分不同的 Block 的標記。
* Valid Bit 是用來區分 一個 Block 裡的資料是否為有效的。
* Valid -> 1
* Invalid -> 0
* Cache 的大小的計算公式為:C = S x E x B data bytes
* **S** = 2^s^ sets
* **E** = 2^e^ lines per set
* **B** = s^b^ bytes per cache block (data)
## Lecture 5/9 - Caches-Associative
>參考網站:[Caches-Associative](https://www.youtube.com/watch?v=7IVE6vXqEoc)
### 5.1 Traditional Memory (Byte Addressable)

* 將想知道的資料的記憶體位置告訴 記憶體,記憶體就會回傳 資料
* 記憶體位置的大小若為 N bits
* 可以儲存 2^N^ 個數值。
### 5.2 Associative Memory

* 將想知道資料的 Key 告訴記憶體
* 可能可以找到相對應的 Key,並回傳 資料
* 也可能找不到相對應的 Key。
* 此時的 Value 可以想像成 CPU Cache 的 Block 所儲存的資料。
* 例子:
* 假設:
* Size of Cache (C = B * E * S): 32 Kbytes
* Block Size (B): 64 Bytes
* Number of Lines (E): 512 lines
* Number of Sets (S): 1 set
* 計算 Cache 的大小時,不會考慮到 Key 和 Valid Bit 或 Dirty Bit 的大小,只會考慮到 Block 的大小 和 Line 跟 Set 的數目。
* Address Size: 32 bits
* 
* 由於 Cache Block Size 是 64 bytes,因此 32 bits 的空間有 6 個 bits (2^6^) 要用來表示這個 Block 中 64 個不同 Byte。而此 6 bits 被稱為 **Block Offset**。
* 而剩下來的 26 bits (32 bits - 6 bits) 則被稱為 **Key** 或是 **Tag**。
* Cache Operation - Fully Associative Cache
* 若想要讀取一個記憶體位置(32 bits) 上所儲存的數值:
* 先將該記憶體位置的前 26 bits 記為 Tag,後 6 Bits 記為 Block Offset
* 接著把 Tag 傳給 Cache
* 若在 Cache 中找得到對應的 Tag 的 Block(**Cache Hit**)
* 則再透過 Block Offset 將 此Block 中的 特定一個 Byte 的內容傳給 CPU。
* 若在 Cache 中找不到擁有相對應的 Tag 的 Block (**Cache Miss**)
* 將 L.R.U (Least Recently Used) 的 Block 刪除 (Evict)
* 若此 Block 為 Dirty Block,將此 Block 在 主記憶體中對應到的 Block 改寫。
* 接著將 Tag 繼續傳遞至 主記憶體上,並將主記體中的記憶體位置的前 26 bits 與 Tag 相符合的 Block 複製起來。
* 接著將 Cache 中含有剛被刪除的 Block 的 Line 上的 Key、Data、Dirty Bit、Valid Bit 更新。
* Data 更新成 剛剛從主記憶體上複製起來的 Block 中的數值。
* 接著透過 Block Offset 將 Block 中的 特定一個 Byte 的內容傳給 CPU。
## Lecture 6/9 - Caches-Direct Mapped
>參考網站:[Caches-Direct Mapped](https://www.youtube.com/watch?v=Ref231Eg9QE)
### 6.1 Direct Mapped Cache
* 簡單來說,就是給每個 Block 一個自己專屬的 line 。
* 假設現在有一個 Cache 的大小為 32 Kbytes
* Block size: 64 bytes
* Number of Lines: 1 lines
* Address size: 32 bits
* 
* 前 17 個 bits 用來當作 **Tag**, 中間 9 個 bits (2^9^ = 512) 用來當作 **Index**,以知道這個 Block 應屬於哪個 Line, 後面 6 個 bits 一樣用來當作 **Block Offset**
* 對於 Direct Mapped Cache, 每個 Block 都有自己所屬的特定的 line
* 比如說:Block 0 對應到 line 0 、 Block 4 對應到 line 4
* 但是若 Block 的數量 大於 511
* 比如說 Block 512,則 Block 512 也會屬於 line 0。
* Block 515 屬於 line 4
* 因此可以很快的知道 特定的 Block 是否存在其所屬的 line 中。
* Directed Mapped Cache 的設計,正是為了解決當 Fully Associative Cache 的大小變大了,在搜尋對應的 Tag 時所耗費的 **時間** 和 **能量** 都會增加的問題。
### 6.2 Direct Mapped Cache Operation
* 若想要讀取一個記憶體位置(32 bits) 上所儲存的數值:
* 先將該記憶體位置的前 17 bits 記為 Tag,中間 9 bits 記為 Index,後 6 Bits 記為 Block Offset
* 接著透過 Index 的資訊去找到 Cache 裡相對應的 Line
* 若此 Line 裡的 Block 所含的 Tag 和我們想讀取的記憶體位置上的 Tag 相同 (**Cache Hit**)
* 透過 Block Offset 將 此Block 中的 特定一個 Byte 的內容傳給 CPU。
* 相反的,若不相同 (**Cache Miss**)
### 6.3 Cache Thrash
* 
* 由於 Block 2 和 Block 514 都會被歸類在 Line 2 中,因此若程式
* 需要 Block 2 的資料 -> 將 Block 2 放到 line 2 中
* 然後又需要 Block 514 的資料 -> Evict Block 2
* 然後又需要 Block 2 的資料 -> Evict Block 514
* 雖然以上情況不太可能會發生,但是若是發生的話,卻會大大影響效能,而此情況稱為 **Cache Thrash**
* 因此可以知道,Direct Mapped Cache 雖然方便,但是仍然會有問題。
## Lecture 7/9 - Caches-General Approach
>參考網站:[Caches-General Approach](https://www.youtube.com/watch?v=Agsi5W-Ewiw)
### 7.1 The General Form
* 將 Direct Mapped Cache 和 Fully Associated Cache 結合
* 假設現在有一個 Cache 的大小為 32 Kbytes
* Block size: 64 bytes
* Number of Lines: 8 lines
* Number of Sets: 64 sets
* Address size: 32 bits
* 則此 Cache 被稱為 32 Kbytes 8-way set Associative Cache
* 
* 
### 7.2 General Form Operation
* 延續上面的例子,若想要讀取一個記憶體位置(32 bits) 上所儲存的數值:
* 先將該記憶體位置的前 20 bits 記為 **Tag**,中間的 6 bits (2^6^ = 64) 記為 **Index**,後 6 Bits 記為 **Block Offset**
* 接著透過 Index 的資訊去找到 Cache 裡相對應的 Set
* 若此 Set 裡的 Block 所含的 Tag 和我們想讀取的記憶體位置上的 Tag 相同 (**Cache Hit**)
* 透過 Block Offset 將 此Block 中的 特定一個 Byte 的內容傳給 CPU。
* 相反的,若不相同 (**Cache Miss**)
* 由於同一個 Set 能夠儲存 8 個不同的 Block,所以發生 Cache Thrash 的機率比 Direct Mapped Cache 低且 讀取的速度也比 Fully Associative Cache 快。
## Lecture 8/9 - Cache-Misses
>參考網站:[Cache-Misses](https://www.youtube.com/watch?v=OBp7rpdg_IQ)
### 8.1 三種不同的 Cache Miss
* **Compulsory Miss** (**Cold Cache**)
* 當程式剛開始執行時,Cache 中沒有任何的 Block。因此會發生 Cache Miss。
* **Capacity Miss**
* Cache 的大小太小了,沒有辦法涵蓋到整個 Working Set。
* **Conflict Miss**
* 雖然 Cache 還有很多空間,但在 Working Set 中的 任意兩個 Block 可能無法同時存在 Cache 中。發生的原因可能是因為,此 2 個 Block 的 Index 相同。(也就是所謂的 **Cache Thrash**)
## Lecture 9/9 - Caches-Summary
>參考網站:[Caches-Summary](https://www.youtube.com/watch?v=otrEgQ2bNCc)
 Sign in with Wallet
Connect another wallet
Sign in with Wallet
Connect another wallet