# 2016q3 Homework2 (phonebook-concurrent)
contributed by <`kevinbird61`>
## 名詞定義
- hyperthreading
- 在同一個cpu上平行執行多個thread
- Multicore
- 在同一個chip上執行多個實體CPU
- on-die cache
- 加大空間對於整體運行效率的提升為最大
- A synchronizes-with B
- 表示兩者關係:A對於記憶體的操作於B是完全可見的,而A、B是兩個完全不同的thread
- Thread: Create&Join

- 跟fork(),exec()相似的過成(fork前的memory於全體thread是可見的)
- 文中提到java對於這塊thread間的問題處理掉了,而C++則是選擇讓使用者自己來;所以就想到,假如要處理的資料屬於獨立性較強,則不需要實作等待的mutex,只要再程式末加上判斷thread count是否全部到達,再把資料依據thread的順序排列即可,可以省去mutex的時間。
- 詳細的分析:

- Memory Consistency Model
- 為硬體與軟體設計上,為了再所有可能發生的執行結果中能夠達到預期結果,彼此做的約定稱之。
- Sequential Consistency
- 對於每個獨立的處理單元,執行時都維持程式的順序(Program Order)
- 整個程式以某種順序在所有處理器上執行
其中提到,現代的的處理器上會限制許多最佳化的手段,讓程式執行的沒那麼快;但假設我們能夠放棄一些約定(應該要注意是否會造成影響的情況下),我們不保證每個處理單元維持程式執行的順序下,能夠榨出更多效能出來。
舉個例子,再處理critical section時,程式必須設計的讓所有thread再接觸到這塊時,勢必只有一個thread能對他做write(暫時不去討論read),而這樣就能保證該區域是一個sequential consistency的情況;但考慮到假設此critical section內的write各自為independent的情況時,我們大可不必限制一次只能一個thread進來
- setjmp & longjmp
- 看不太懂原本的聯結的內容,直接查閱[man page](http://man7.org/linux/man-pages/man3/setjmp.3.html),看到對setjmp的解釋:used for performing "non-local gotos": transferring execution from one function to a predetermined location in another function.其中`setjmp()` function dynamically establishes the target to which control will later be transferred ; `longjmp()` performs the transfer of execution.(TODO實作後補上自己的說明)
- `setjmp()` function saves various information about the calling environment(typically,the stack pointer,the instruction pointer,possibly the values of other registers and the signal mask) in the buffer `env` for later use by longjmp(). In this case, setjmp() returns 0.)
- `longjmp()` function uses the information saved in `env` to transfer control back to the point where setjmp() was called and to restore ("rewind") the stack to its state at the time of the setjmp() call.
In addition, and depending on the implementation (see NOTES), the values of some other registers and the process signal mask may be restored to their state at the time of the setjmp() call.
- Following a successful longjmp(), execution continues as if setjmp()
had returned for a second time. This "fake" return can be
distinguished from a true setjmp() call because the "fake" return
returns the value provided in val. If the programmer mistakenly
passes the value 0 in val, the "fake" return will instead return 1.
- [setjmp/longjmp測試實作](https://github.com/kevinbird61/Fun-part-of-C/blob/master/setjmp/setjmp_test.c)
- 執行結果
```shell
$ ./a.out
A(1)
B(1)
A(2) r = 10001
B(2) r=20001
A(3) r = 10002
B(3) r=20002
A(4) r = 10003
```
- 可以看到,setjmp把資訊儲存於bufferA後執行B routine後,再藉由longjmp回到當初於A routine中呼叫B的位置;藉此可以達到再兩個函式中切換;把routine A,B換成兩條thread,便是thread間維持Sequential Consistency的實作
## Concurrency Kit
- Attribute
- A concurrent memory model for C.
- A unified interface for hardware intrinsics.
- Safe memory reclamation mechanisms.
- Specialized concurrent data structures.
### Concurrency Primitive
- 提供完整的(partial ordering interface)於store、loads、atomic operations的操作上,Memory ordering exceptions expressed with strict fence interface. [partial order set](https://en.wikipedia.org/wiki/Partially_ordered_set)
- 
- 而memory model和instruction set是分開的,為了使用上方便,porters transcribe a handful of operations from architecture manuals and rarely have to concern themselves with memory model minutiae(細節) and additional boilerplate(樣板).
- 
- 
- 所有的concurrent accesses到actively mutable state(應該譯做易變動的記憶體區塊)都被紀錄再可用於必要hardware instructions的`ck_pr` operations,也可被視為compiler barrier
- 投影片中提到,volatile不提供任何的atomicity上的保證,且disable掉許多的最佳化,ordering也只能和部份volatile accesses做defined
### SpinLocks
- 實作了許多不同特性跟擴展性的保證

- 實作兩種不同的spinlock做比較

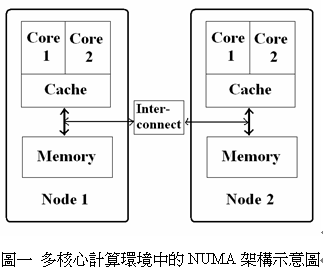
- 文中提到,starvation-freedom跟fairness對於NUMA(Non-Uniform Memory Access)架構來說是非常重要的
- 簡單來說,同一台電腦上,各核心間訊息傳遞速率上也會有所不同,且不同核心存取不同記憶體的速率也會不同;原因是當系統核心量增加時,原本的對稱式多處理器(SMP)設計,在處理器和記憶體之間的匯流排造成資料存取的瓶頸,嚴重的影響效能;而NUMA則是簡化了`匯流排`的複雜程度,把系統切成數個node,每個node上都有處理器及記憶體,當處理器存取同一個節點的記憶體時,會有較高的存取速度;而當需要存取到其他node時,才需要花費較多的時間。
- 而這些演算法實作成的spinlock,優化了busy-wait stage並提供了較強並fairness(公正?)的保證
- Ex: Elision(Intel x86 & Power 8 processors support restricted transactional memory - RTM) => Typical use-case with those processors is Elision.
from =>
to =>
@ Unscalable lock => degrade performance under contention
### Execution Barriers
- 再所有thread到達前,阻擋先來的thread繼續執行的工作。(Scalability is usually not a concern)
- `Blocking Asymmetric Synchronization`
- 最常見的便是read-write lock
- 
- 藉由block來分配read跟write的時機
### Read-Write Synchronization
- 任何不可忽略的write工作量,相對會對reader的效能造成影響
- If `liveness` and `reachability` of object is decoupled with blocking synchronization, techniques like reference counting must be used(reference counting => expensive!) => 提到使用blocking synchronization時同時會需要的成本
### Safe Memory Reclamation
- protects against read-reclaim races with minimal to no interference to readers.

- 可以看到使用一般read-write lock以及reference counting的執行時間都是較高的
### Data Structure
- Ring Buffer
- `ck_ring_t`: is a lock-free ring buffer in C.K. .It is wait-free for single-producer/ single-consumer and lock-free for single-producer/ multi-consumer.
- Hash Table
- 為普遍達成lock-free/wait-free
## Conclusion
- Concurrency kit是一個可以讓我們在concurrency程式中使用的一項工具(測試看看如何使用,以及效能比較)
-
# Reference
- [NUMA](http://www.cc.ntu.edu.tw/chinese/epaper/0015/20101220_1508.htm)
 Sign in with Wallet
Connect another wallet
Sign in with Wallet
Connect another wallet