# 2017q1 Homework1 (compute-pi)
contributed by <yih6208>
### Reviewed by `zhanyangch`
* 沒有嘗試比較在不同的 N 值下,所算出的圓周率的誤差
* 可以使用不同公式計算圓周率,並比較差異
我更換了我的作業環境
底下是我新的開發環境
## Develop Environment
```shell=
Architecture: x86_64
CPU 作業模式: 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 8
On-line CPU(s) list: 0-7
每核心執行緒數:2
每通訊端核心數:4
Socket(s): 1
NUMA 節點: 1
供應商識別號: GenuineIntel
CPU 家族: 6
型號: 60
Model name: Intel(R) Core(TM) i7-4770 CPU @ 3.40GHz
製程: 3
CPU MHz: 3424.171
CPU max MHz: 3900.0000
CPU min MHz: 800.0000
BogoMIPS: 6784.25
虛擬: VT-x
L1d 快取: 32K
L1i 快取: 32K
L2 快取: 256K
L3 快取: 8192K
NUMA node0 CPU(s): 0-7
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc aperfmperf eagerfpu pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm epb tpr_shadow vnmi flexpriority ept vpid fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm xsaveopt dtherm ida arat pln pts
```
## First Step - Make it run
`$ make check`
```shell=
benchmark_clock_gettime.c -o benchmark_clock_gettime
time ./time_test_baseline
N = 400000000 , pi = 3.141593
2.92user 0.00system 0:02.92elapsed 99%CPU (0avgtext+0avgdata 1856maxresident)k
0inputs+0outputs (0major+85minor)pagefaults 0swaps
time ./time_test_openmp_2
N = 400000000 , pi = 3.141593
2.92user 0.00system 0:01.46elapsed 199%CPU (0avgtext+0avgdata 1820maxresident)k
0inputs+0outputs (0major+85minor)pagefaults 0swaps
time ./time_test_openmp_4
N = 400000000 , pi = 3.141593
3.03user 0.00system 0:00.76elapsed 397%CPU (0avgtext+0avgdata 1788maxresident)k
0inputs+0outputs (0major+91minor)pagefaults 0swaps
time ./time_test_avx
N = 400000000 , pi = 3.141593
0.83user 0.00system 0:00.83elapsed 100%CPU (0avgtext+0avgdata 1812maxresident)k
0inputs+0outputs (0major+84minor)pagefaults 0swaps
time ./time_test_avxunroll
N = 400000000 , pi = 3.141593
0.80user 0.00system 0:00.80elapsed 100%CPU (0avgtext+0avgdata 1784maxresident)k
0inputs+0outputs (0major+84minor)pagefaults 0swaps
```
摁~程式跑得很正常
## Second Step - Gencsv
在我執行`$ make gencsv`之前,我先看了[0xff07的筆記](https://hackmd.io/s/H1MV8APKg#)。他說當他在產生結果的時候,他在用youtube聽音樂。導致跑出來的數據相當浮動,因此我登出了GUI界面。按下`Crtl+Alt+F1`進入CLI,確保系統的負載達到最小化。
`$ make plot`


我不知道為什麼我的4 threads的情況下跑得比avx還快,接下來要想辦法找出原因。
## Third Step - Find thread and AVX's problem
我找到了[Introduction to Intel® Advanced Vector Extensions](https://software.intel.com/en-us/articles/introduction-to-intel-advanced-vector-extensions)及[Vectorization - Find out what it is, Find out More!
](https://software.intel.com/en-us/blogs/2012/01/31/vectorization-find-out-what-it-is-find-out-more)這兩個網站分別講述了SIMD 以及AVX指令集的功能。我發現到AVX的暫存器(register)可能只有一組,而這一組同一時間僅可被執行一次。相較於4core的核心來說,雖然以CPU的執行速度較低,但由於同一時間內可執行次數較多次,因而導致了這個結果。

## 4th Step - What if I use more threads?
如果我加上更多的thread 會產生什麼樣的結果呢?
因此我想試看看由4 threads 增加到 8 threads 後有什麼樣的差異

除了一開始8 threads的飆升外可以發現幾乎整條都是重合的。
來查看看 intel 的hyper threading 是怎麼實做的。
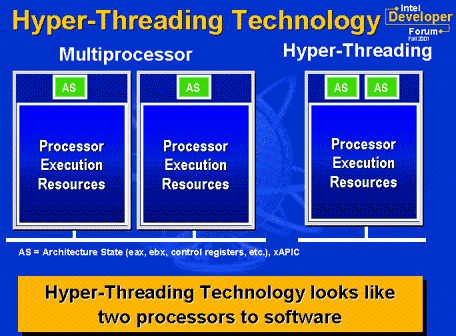
其實可以發現到兩個執行緒還是在一個core上執行, 因compute pi其實已經可以佔用了整個core的運算能力,因此當兩個執行程序分配到同一個core時並不會有加速的效果,甚至還有可因為分配時的時間損失而變慢。
## 5th Step - Optimize more
我後來找到這個網站,[Intel Intrinsics Guide](https://software.intel.com/sites/landingpage/IntrinsicsGuide/) 裡面詳列了所有的SIMD指令。
我找到multiple and add 的指令,屬於FMA指令集須在compile 指令加上 -mfma。我將原本
```c
/* AVX */
ymm3 = _mm256_set1_pd(i * dt); // i*dt, i*dt, i*dt, i*dt
ymm3 = _mm256_add_pd(ymm3, ymm2); // x = i*dt+3*dt, i*dt+2*dt, i*dt+dt, i*dt+0.0
ymm3 = _mm256_mul_pd(ymm3, ymm3); // x^2 = (i*dt+3*dt)^2, (i*dt+2*dt)^2, ...
ymm3 = _mm256_add_pd(ymm0, ymm3); // 1+x^2 = 1+(i*dt+3*dt)^2, 1+(i*dt+2*dt)^2, ...
ymm3 = _mm256_div_pd(ymm1, ymm3); // dt/(1+x^2)
ymm4 = _mm256_add_pd(ymm4, ymm3); // pi += dt/(1+x^2)
```
改為
```c
/* AVX OPT */
ymm5 = _mm256_set1_pd(i);
ymm3 = _mm256_fmadd_pd( ymm5 , ymm1 , ymm2);
ymm3 = _mm256_fmadd_pd( ymm3 , ymm3 , ymm0);
ymm3 = _mm256_div_pd(ymm1, ymm3);
ymm4 = _mm256_add_pd(ymm4, ymm3);
```

可以觀察到效能稍微的增進了一點點,但是幅度不大。
我後來也將unroll的版本改成multiple and add
```c
ymm14 = _mm256_set1_pd(i * dt);
ymm10 = _mm256_add_pd(ymm14, ymm2);
ymm11 = _mm256_add_pd(ymm14, ymm3);
ymm12 = _mm256_add_pd(ymm14, ymm4);
ymm13 = _mm256_add_pd(ymm14, ymm5);
ymm10 = _mm256_mul_pd(ymm10, ymm10);
ymm11 = _mm256_mul_pd(ymm11, ymm11);
ymm12 = _mm256_mul_pd(ymm12, ymm12);
ymm13 = _mm256_mul_pd(ymm13, ymm13);
ymm10 = _mm256_add_pd(ymm0, ymm10);
ymm11 = _mm256_add_pd(ymm0, ymm11);
ymm12 = _mm256_add_pd(ymm0, ymm12);
ymm13 = _mm256_add_pd(ymm0, ymm13);
ymm10 = _mm256_div_pd(ymm1, ymm10);
ymm11 = _mm256_div_pd(ymm1, ymm11);
ymm12 = _mm256_div_pd(ymm1, ymm12);
ymm13 = _mm256_div_pd(ymm1, ymm13);
ymm6 = _mm256_add_pd(ymm6, ymm10);
ymm7 = _mm256_add_pd(ymm7, ymm11);
ymm8 = _mm256_add_pd(ymm8, ymm12);
ymm9 = _mm256_add_pd(ymm9, ymm13);
```
改成
```c
ymm15=_mm256_set1_pd(i);
ymm10=_mm256_fmadd_pd( ymm15 , ymm1 , ymm2);
ymm11=_mm256_fmadd_pd( ymm15 , ymm1 , ymm3);
ymm12=_mm256_fmadd_pd( ymm15 , ymm1 , ymm4);
ymm13=_mm256_fmadd_pd( ymm15 , ymm1 , ymm5);
ymm10=_mm256_fmadd_pd( ymm10 , ymm10 , ymm0);
ymm11=_mm256_fmadd_pd( ymm11 , ymm11 , ymm0);
ymm12=_mm256_fmadd_pd( ymm12 , ymm12 , ymm0);
ymm13=_mm256_fmadd_pd( ymm13 , ymm13 , ymm0);
ymm10 = _mm256_div_pd(ymm1, ymm10);
ymm11 = _mm256_div_pd(ymm1, ymm11);
ymm12 = _mm256_div_pd(ymm1, ymm12);
ymm13 = _mm256_div_pd(ymm1, ymm13);
ymm6 = _mm256_add_pd(ymm6, ymm10);
ymm7 = _mm256_add_pd(ymm7, ymm11);
ymm8 = _mm256_add_pd(ymm8, ymm12);
ymm9 = _mm256_add_pd(ymm9, ymm13);
```

但在這個版本中卻幾乎沒有增進,原因還有待探討。
 Sign in with Wallet
Connect another wallet
Sign in with Wallet
Connect another wallet