# Everything you need to know about Nebula Graph Index
[TOC]
> Nebula Graph Native Index explained, why did I see `index not found`? When should I use Nebula Index and full-text index?
The term Index in Nebula Graph is quite similar to the same term in relational databases, but they are not exactly the same. I noticed that some Nebula Graph users are often confused when getting started with Nebula Graph. Typically, people want to know what exactly Nebula Graph Index is, when should they use it, and how it impacts the performance of Nebula Graph.
Today I'm going to walk you through the Index concept in Nebula Graph and hopefully, this article will answer these questions.
Let's get started!
## What exactly Nebula Graph Index is
To put it short, Nebula Graph Index is only used when the vertextID is not specified, or only when **properties** of vertices or edges are defined in the query conditions.
Index is only used in a starting entry of a graph query. If a query is in the pattern: (a->b->c, where c is with the condition "foobar"), since the only filter `condition-foobar` is on `c`, this query under the hood will start to look for `c`, and then it walks reversely through the `->` to `b`, and finally to `a`. Thus, the Nebula Graph Index will be used and only be possibly used when locating c.
### Index is used only to seek starting points
We know that in RDBMS, indexing is to create a duplicate of sorted data to enable QUERY with conditional filtering on the sorted data, in order to **accelerate the query in reads** and it also brings additional data writes.
> Note: in RDBMS/Tabular DB, indexing some columns means to create extra data that are sorted on those columns to make a query with those columns' conditions to be scanned faster, rather than scanning from the original table data sorted based on the key only.
In Nebula Graph, the index is to create a duplicate of sorted **Vertex/Edge PROP DATA** to **locate the starting point of a QUERY**.
Not all of queries relied on the index, here are some example queries, where the starting points are only defined using conditions, rather than VertextIDs. Let's call them `pure property condition starting queries`:
```cypher
#### Queries relying on Nebula Graph Index
# query 0 pure-property-condition-start query
LOOKUP ON tag1 WHERE col1 > 1 AND col2 == "foo" \
YIELD tag1.col1 as col1, tag1.col3 as col3;
# query 1 pure-property-condition-start query
MATCH (v:player { name: 'Tim Duncan' })-->(v2:player) \
RETURN v2.player.name AS Name;
```
In both `query 0` and `query 1`, the pattern is to "Find VID/EDGE only based on given property conditions".
On the contrary, the starting point is VertexID based instead in `query 2` and `query 3`:
```cypher
#### Queries not based on Nebula Graph Index
# query 2, walk query starting from given vertex VID: "player100"
GO FROM "player100" OVER follow REVERSELY \
YIELD src(edge) AS id | \
GO FROM $-.id OVER serve \
WHERE properties($^).age > 20 \
YIELD properties($^).name AS FriendOf, properties($$).name AS Team;
# query 3, walk query starting from given vertex VID: "player101" or "player102"
MATCH (v:player { name: 'Tim Duncan' })--(v2) \
WHERE id(v2) IN ["player101", "player102"] \
RETURN v2.player.name AS Name;
```
If we look into `query 1` and `query 3`, which shared the same condition on vertices on `tag:player`, which are both `{ name: 'Tim Duncan' }`, they are differentiated in starting points:
For `query 3`, the index is not required as the query will start from the known vertex ID in `["player101", "player102"]` and thus:
- It'll directly fetch vertex data from `v2`'s vertex IDs
- then to GetNeighbors(): walk through edges of `v2`, GetVertices() for the next hop: `v` and filter based on the property: `name`
For `query 1`, the query has to start from `v` due to no known vertex IDs were provided:
- It'll do IndexScan() first to find all vertices only with the property condition of `{ name: 'Tim Duncan' }`
- Then, GetNeighbors(): walk through edges of `v`, GetVertices() for the next hop: `v2`
Now, we know the whole point that matters here is on **whether we know the vertexID**. And the above differences could be shown in their execution plans with PROFILE or EXPLAIN like the following:
| `query 1`, requires index(on tag: player), pure property condition query as starting point | `query 3`, no index required, query starting from known vertex IDs |
| ------------------------------------------------------------ | ------------------------------------------------------------ |
| 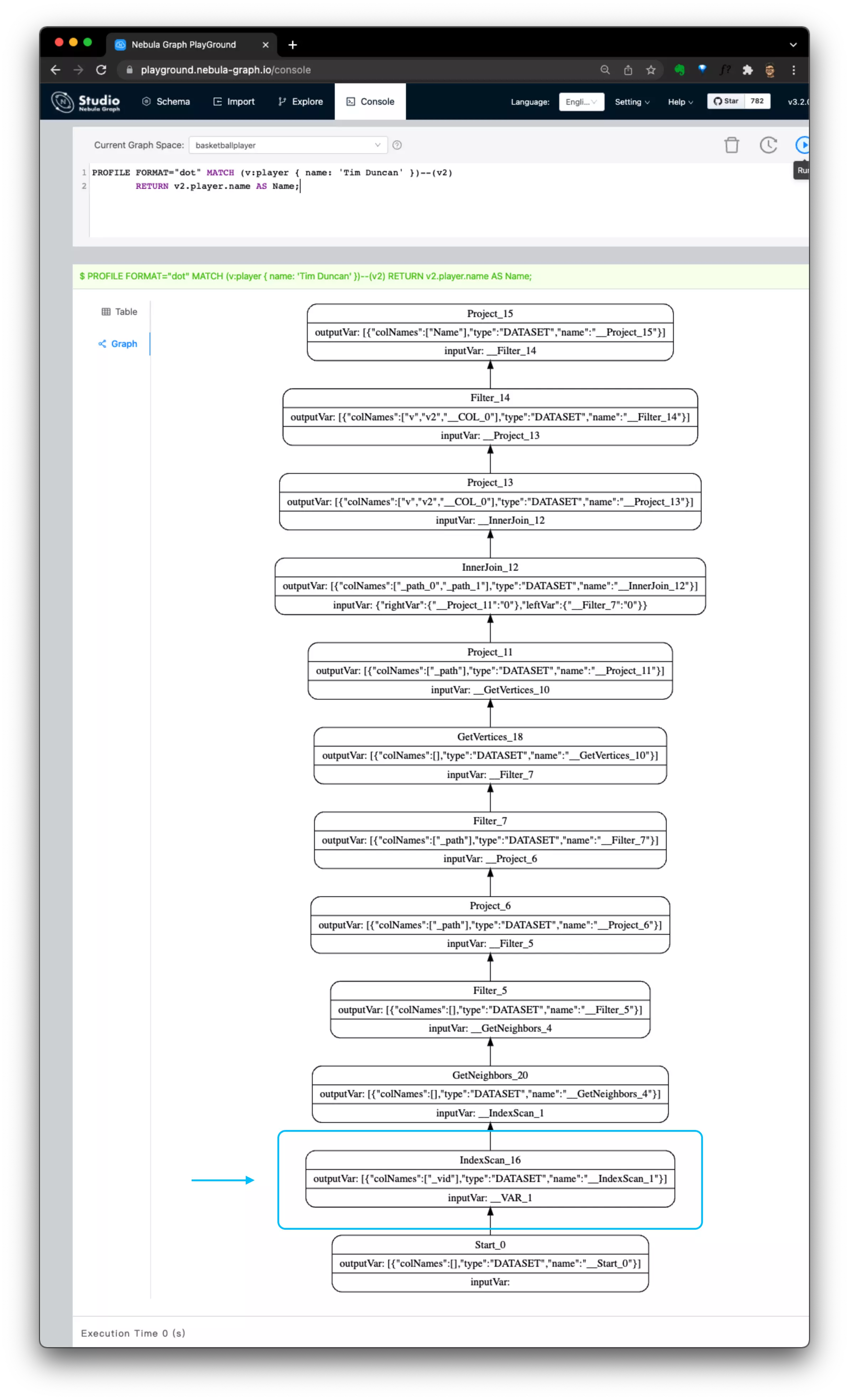 | 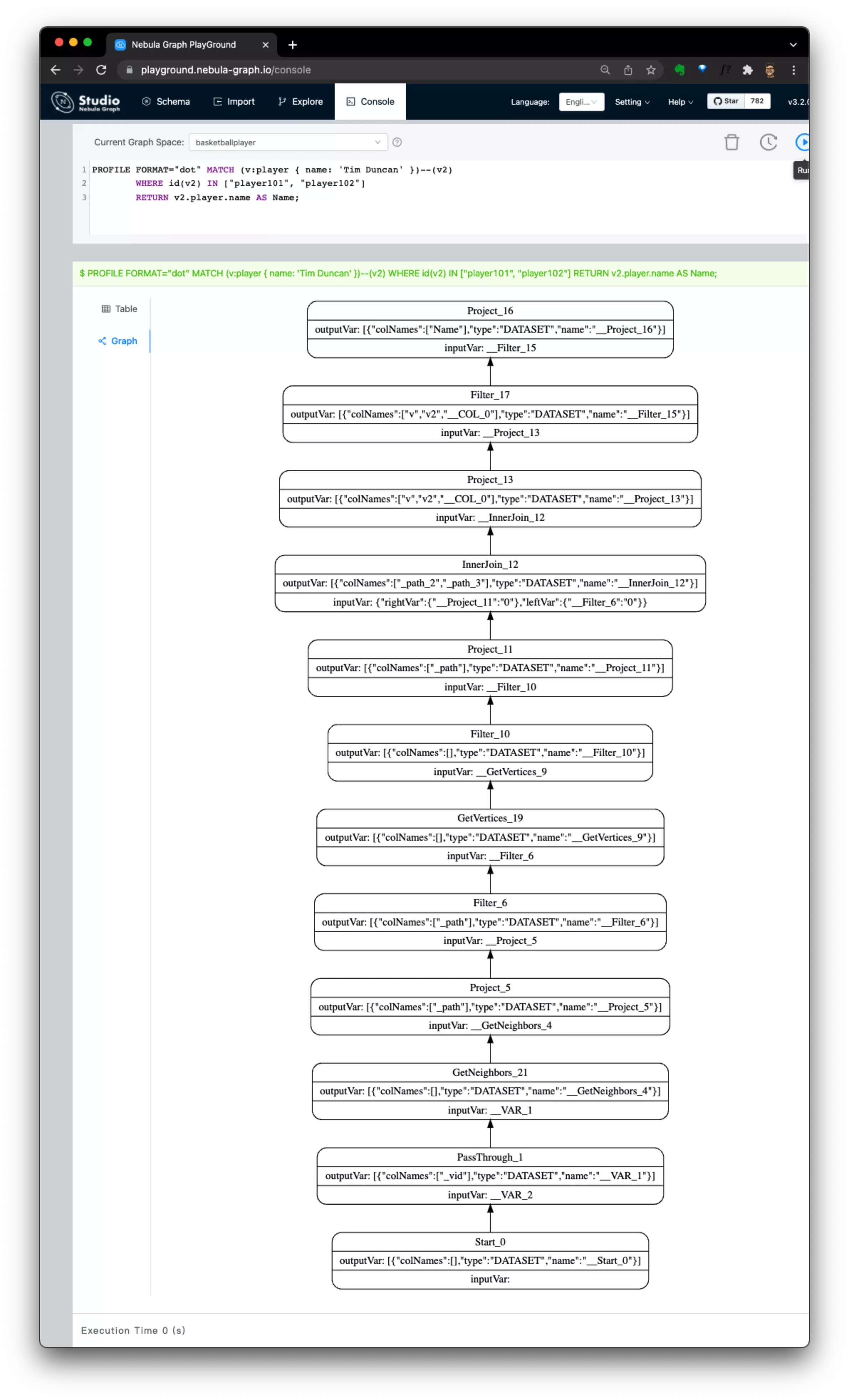 |
### Why Nebula Graph index is an enabler rather than an accelerator
Can't those queries be done without indexes?
It's possible in theory with a full scan, but disabled without an index.
The reason is that Nebula Graph stores data in a distributed and graph-oriented way, the full scan of data was considered too expensive to be allowed.
> Note: from v3.0, it's possible to do TopN Scan without index, where the `LIMIT <n>` is used, this is different from the fullscan case(index is a must), which will be explained later.
>
> ```cypher
> MATCH (v:player { name: 'Tim Duncan' })-->(v2:player) \
> RETURN v2.player.name AS Name LIMIT 3;
> ```
### Why starting point only
Index data is not used in the traversal. It could confuse us to think of index as sorting data based on properties, does it accelerate the traversal with property condition filtering? The answer is no.
In Nebula Graph, the data is structured in a way to enable fast graph-traversal, which is already indexed/sorted on vertex ID(for both vertex and edge) in the raw data, where traversal(underlying in storage, it's calling GetNeighbors interface) of the given vertex is cheap and fast due to the persistent storage.
So in summary:
> Nebula Graph Index is sorted property data to find the starting vertex or edge on given pure property conditions.
## Facts on Nebula Graph Index
To understand more details/limitations/cost of Nebula, let's reveal more about its design. Here are some facts in short:
- Index Data is stored and shared together with Vertex Data
- It's **Left Match** based only: It's RocksDB Prefix Scan under the hood
- Effect on write and read path(to see its cost):
- Write Path: Extra Data written + Extra Read request introduced
- Read Path: RBO(Rule-based optimization), Fan Out(to all shards)
- Data Full Scan LIMIT Sample(not full scan) is supported without index
- `LOOKUP ON t YIELD t.name | LIMIT 1`
- ```cypher
MATCH (v:player { name: 'Tim Duncan' })-->(v2:player) \
RETURN v2.player.name AS Name LIMIT 3;
```
The key info can be seen in one of my [sketch notes](https://www.siwei.io/en/sketch-notes/):
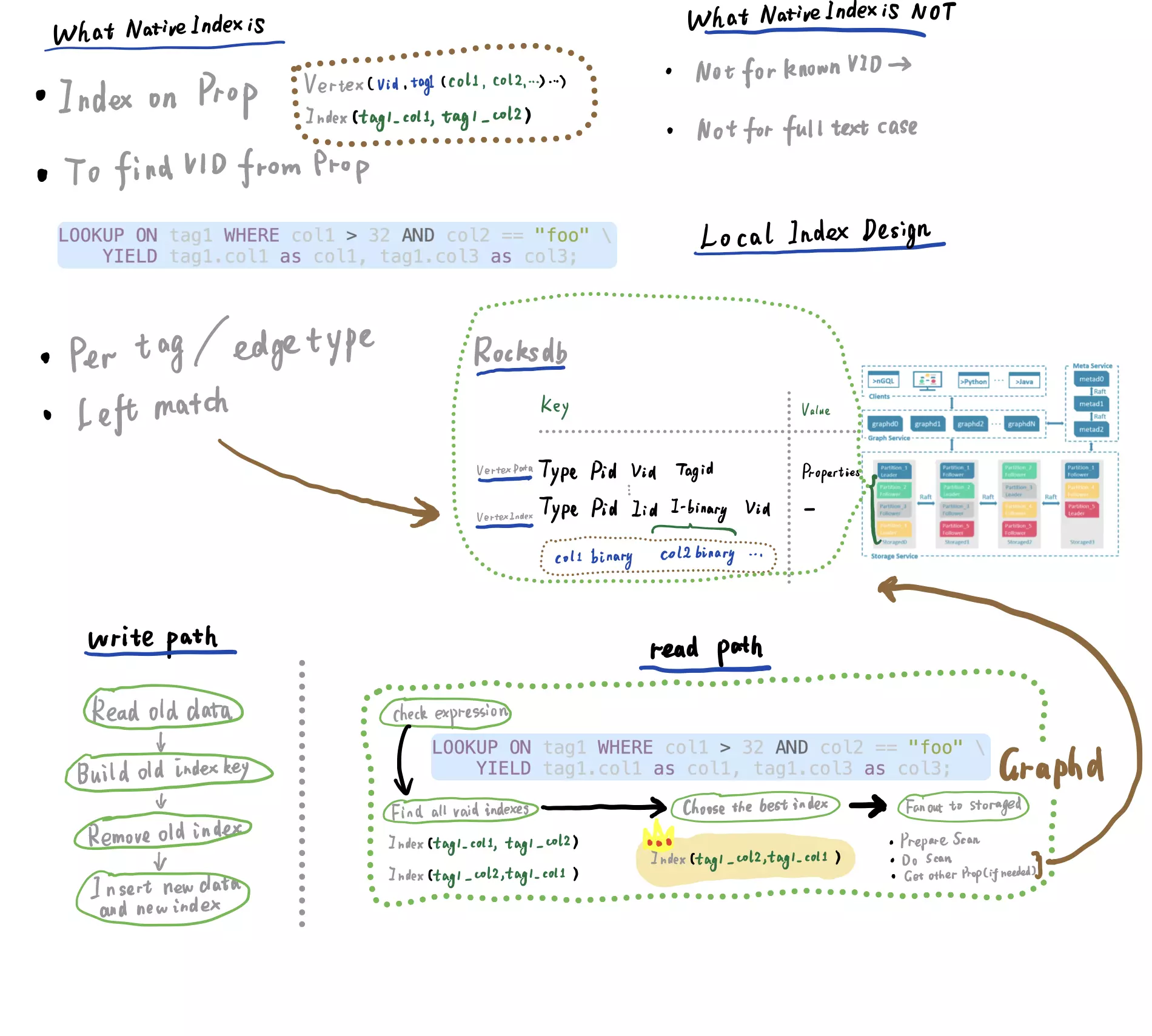
> We should notice that only the left match is supported in pure-property-condition-start queries. For queries like wildcard or regular expression, Full-text Index/Search is to be used, where an external elastic search is integrated with Nebula: please check [Nebula Graph Full text index](https://docs.nebula-graph.io/3.1.0/4.deployment-and-installation/6.deploy-text-based-index/2.deploy-es/) for more.
Within this sketch note, more highlights are:
- It's a Local Index Design
- The index is stored and shared locally together with the graph data.
- It's sorting based on property value, and the index search is underlying a RocksDB prefix scan, that's why only left match is supported.
- There are costs in the writing path
- The index enables the RDBMS-like property Condition Based Query with cost in the write path including not only the extra write but also, random read, to ensure the data consistency.
- Index Data writing is done in a synchronous way
- For the reading path:
- In pure-property-condition-start queries, in GraphD, the index will be selected with Rule-based-optimization like this example, where, in a rule, the col2 to be sorted first is considered optimal with the condition: col2 equals 'foo'.
- After the index was chosen, the index-scan request will be fanout to storageD instances, and in the case of filters like LIMIT N, it will be pushed down to the storage side to reduce data payload.
- Note: it was not shown in the sketch but actually from v3.0, the nebula graph allows LIMIT N Sample Property condition query like this w/o index, which is underlying pushing down the LIMIT filter to storage side.
Takeaways:
- Use index only when we have to, as it's costly in write cases and if the limit N sample is the only needed case and it's fast enough, we can use that instead.
- Index is left to match
- composite index order matters, and should be created carefully.
- for full-text search use case, use [full-text index](https://docs.nebula-graph.io/3.1.0/4.deployment-and-installation/6.deploy-text-based-index/2.deploy-es/) instead.
## How to use the index
We should always refer to the [documentation](https://docs.nebula-graph.io/3.1.0/3.ngql-guide/14.native-index-statements/), and I just put some highlights on this here:
- To create an index on a tag or edge type to specify a list of props in the order that we need.
- `CREATE INDEX`
- If an index was created after existing data was inserted, we need to trigger an index asynchronously to rebuild the job, as the index data will be written in a synchronous way only when the index is created.
- `REBUILD INDEX`
- We can see the index status after `REBUILD INDEX` is issued.
- `SHOW INDEX STATUS`
- Queries levering index could be LOOKUP, and with the pipeline, in most cases, we will do follow-up graph-walk queries like:
```sql
LOOKUP ON player \
WHERE player.name == "Kobe Bryant"\
YIELD id(vertex) AS VertexID, properties(vertex).name AS name |\
GO FROM $-.VertexID OVER serve \
YIELD $-.name, properties(edge).start_year, properties(edge).end_year, properties($$).name;
```
- Or in MATCH query like this, under the hood, v will be searched on index and v2 will be walked by default graph data structure without involving index.
```cypher
MATCH (v:player{name:"Tim Duncan"})-->(v2:player) \
RETURN v2.player.name AS Name;
```
## Recap
Finally, Let's Recap
- Index is to sort Property DATA to enable finding starting point on a given Pure Property Condition(no VertexID provided)
- Index is **not** for traversal
- Index is left match, **not** for full-text search
- Index has cost on WRITE
- Remember to REBUILD after `CREATE INDEX` on existing data
Happy Graphing!
Feture image credit to [Alina](https://unsplash.com/photos/ZiQkhI7417A)
 Sign in with Wallet
Sign in with Wallet







