---
title: OCR-D Produktiv
tags: OCR-D, OCR
description: Einführungsvortrag Leipzig 12.05.2021
slideOptions:
theme: white
slideNumber: true
---
<style>
/* reduce from default 48px: */
.reveal {
font-size: 24px;
text-align: left;
}
.reveal .slides {
text-align: left;
}
/* change from default gray-on-black: */
.hljs {
color: #005;
background: #fff;
}
/* prevent invisible fragments from occupying space: */
.fragment.visible:not(.current-fragment) {
display: none;
height:0px;
line-height: 0px;
font-size: 0px;
}
/* increase font size in diagrams: */
.label {
font-size: 24px;
font-weight: bold;
}
/* increase maximum width of code blocks: */
.reveal pre code {
max-width: 1000px;
max-height: 1000px;
}
/* remove black border from images: */
.reveal section img {
border: 0;
}
.reveal pre.mermaid {
width: 100% !important;
}
.reveal svg {
max-height: 600px;
}
.reveal .scaled-flowchart-td pre.mermaid {
width: 100% !important;
/* why? float: left; */
}
.reveal .scaled-flowchart-td svg {
max-width: 100% !important;
}
.reveal .scaled-flowchart-td svg g.node,
.reveal .scaled-flowchart-td svg g.label,
.reveal .scaled-flowchart-td svg foreignObject {
width: 100% !important;
}
.reveal .scaled-flowchart-td p {
clear:both;
}
.reveal .centered {
text-align: center
}
.reveal .width75 {
max-width: 75%;
}
</style>
# OCR-D Produktiv
(Einführung zu Konzept und Benutzung)¹
_Robert Sachunsky, Uni Leipzig, 12.05.2021_
: https://hackmd.io/@bertsky/HyJgghd_d

1: basiert auf: Konstantin Baierer –<!-- .element: style="font-size:18px" -->
- https://dhd-ag-ocr.github.io/slides/OCR@vDHd-Z1.pdf
- https://github.com/kba/vdhd-2021-05-05
- https://github.com/kba/vdhd-2021-05-12
<!-- .element: style="font-size:18px" -->
---
## Projekthistorie
DFG-Projekt seit 2015 mit Ziel: Volltextdigitalisierung der VD-Bestände (16.-19. Jh.)
- 2015-2017: Bestandsaufnahme
- 2018-2020: Entwicklung von Prototypen
* 1 Koordinierungsprojekt
* 8 Modulprojekte (v.a. Unis, auch ASV)
- 2021-2023: Überführung in Produktivbetrieb
* 1 Koordinierungsprojekt
* 7 Implementierungsprojekte (v.a. Uni-Bibliotheken)
---
## Prioritäten
- Massenverarbeitung > Ergonomie
- Transparenz > Perfektion
- Module > Black-Box
- Spezifikationen > Konventionen
- Offenheit, Freie Software, Community
- noch nicht: Handschriften, Zeitungen, Gegenwartsdokumente
- noch nicht: Robustheit und Skalierbarkeit
---
## Massenverarbeitung
- Baut auf Standards (METS-XML, MODS, PAGE-XML, ALTO-XML, JSON-Schema, XML-Schema)
- Tools mit einheitlicher CLI (und Web-API…)
- Anschlussfähige Technologien (Python, Git, Docker)
- Austauschbare Komponenten und flexibel konfigurierbare Workflows
---
## Transparenz
- Github-Workflow: https://github.com/topics/ocr-d
- Release early, release often: https://github.com/OCR-D
- Offener Chat: https://gitter.im/OCR-D/Lobby
- Regelmäßig offene, virtuelle Treffen:
* zweiwöchentlich Mittwoch 14 Uhr: Offener OCR-D Tech-Call
https://hackmd.io/OOMgg3ZeSqK4vfKL1wRbwQ
(Technischer Austausch)
* monatlich jeden 1. Freitag: OCR-D & Co
https://ocr-d.de/en/2021/04/26/barcamp.html
(Barcamp-Format für OCR-D Veteranen und Neulinge)
- Umfassende zentrale Dokumentation: https://ocr-d.de
- Wiki für nutzergetriebene Dokumentation:
https://github.com/OCR-D/ocrd-website/wiki
- Im allgemeinen Kommunikation auf Englisch
---
## Komponenten
- Gängige OCR-Engines führen verschiedene Operationen vor und nach der "eigentlichen" Texterkennung aus, sind an bestimmte Workflows gebunden – nutzerfreundlich aber unflexibel
- Freie Workflow-Konfiguration (inkrementelle Annotation)
- 1 Schritt im Workflow → 1 Aufruf eines OCR-D-Prozessors
- Alternative Implementierungen für Prozessoren
_"Nimm die Binarisierung von Ocropus, die Segmentierung von Tesseract und die Texterkennung von Calamari"_
- Leichte Integration neuer Tools
---
## [Spezifikationen](https://ocr-d.de/en/spec)
- Verbindliche Vorgaben, wie sich die Prozessoren verhalten müssen
- Einheitliche Kommandozeilenschnittstellen
- Mit Schemasprachen Datenaustausch verifizieren
- Konventionen explizit und validierbar machen
- Referenzimplementierung https://github.com/OCR-D/core
* zum Entwickeln von spezifikationsgemäßen Prozessoren
(Python-API, Bashlib)
* allgemeine Nutzerwerkzeuge:
- `ocrd workspace ...`
- `ocrd process ...`
- `ocrd resmgr ...`
- `ocrd zip ...`
- `ocrd validate ...`
---
## [Installation](https://ocr-d.de/en/setup)
- Meta-Projekt https://github.com/OCR-D/ocrd_all
enthält alle OCR-D-Module
- Zielsystem: Ubuntu 18.04
* In Windows 10 per WSL installierbar
* Mac OSX: weitgehend kompatibel, aber nicht garantiert
- Auch als Docker-Image verfügbar: [`ocrd/all`](https://hub.docker.com/r/ocrd/all)
* plattformunabhängig, funktioniert in Windows, OSX, Linux, BSD …
* derzeit nur als "Fat Container" für CLI
* GPU-Nutzung nicht trivial (CUDA-Toolkit / Tensorflow / Python -Versionen…)
---
## [Dokumentation](https://ocr-d.de)
- alle Prozessoren haben ein mehr oder weniger detailliertes README
- alle Prozessoren unterstützen `--help`
* zeigt Docstrings, CLI und Parameter-JSON
* bspw.: `ocrd-olena-binarize -h`
- [Setup Guide](https://ocr-d.de/en/setup) beschreibt Installation
- [Workflow-Guide](https://ocr-d.de/en/workflows) beschreibt verfügbare Prozessoren und deren Zusammenspiel
* Klick auf den Prozessor-Namen öffnet Parameterliste
* Beispiele für komplette Workflows am Ende der Seite
- Fragen? Probleme? https://gitter.im/OCR-D/Lobby
---
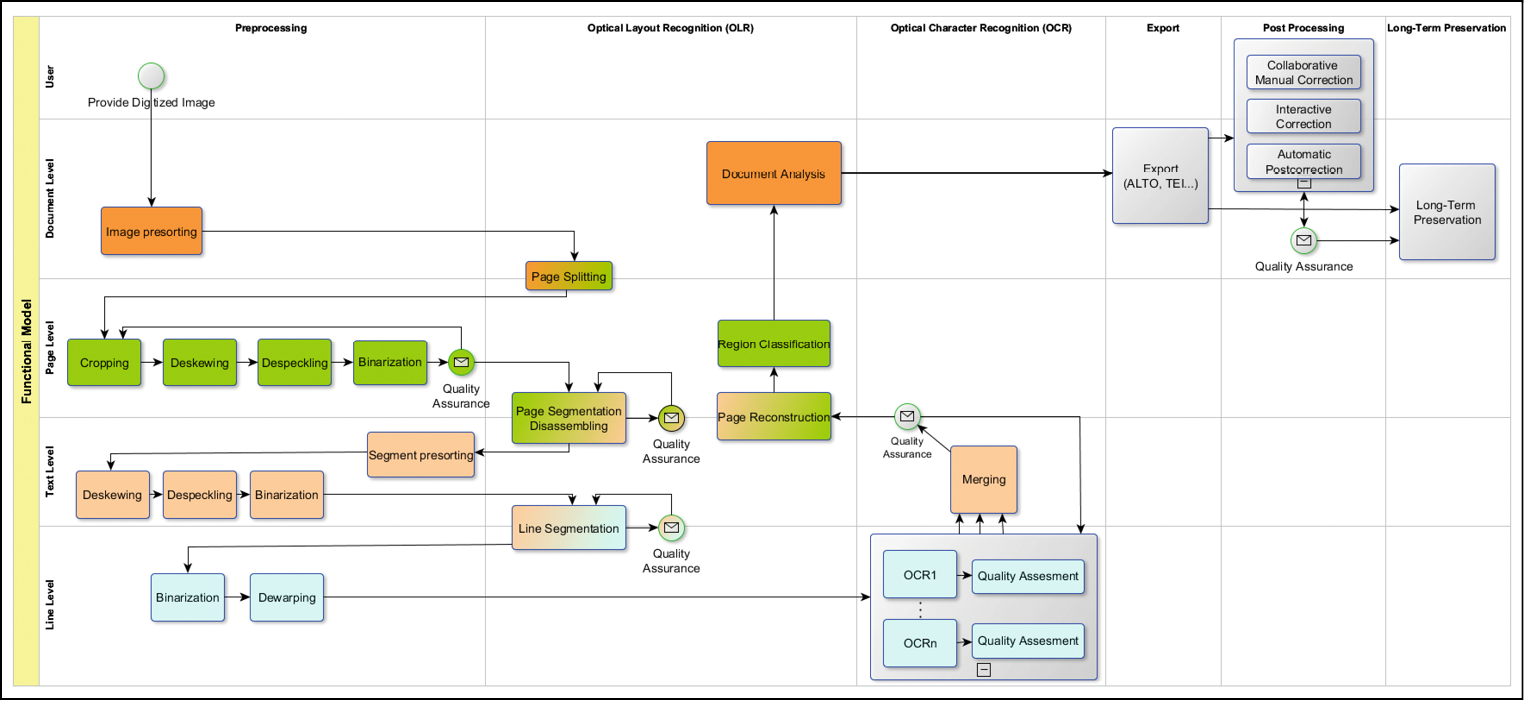
---
## [Begriffe](https://ocr-d.de/en/spec/glossary)
- **Prozessor**: Implementierung mit OCR-D-CLI für einen oder mehrere Schritte im Workflow
- **Workspace**: Verzeichnis mit einer `mets.xml`, die das Dokument und alle weiteren Dateien beschreibt
- **File Group**: Gruppe von Dateien/Annotationen im Workspace, entspricht weitgehend lokalen Verzeichnissen
- **Parameter**: Prozessor-spezifische "Knöpfe an denen man drehen kann", um die Verarbeitung zu steuern
---
## Demo
https://github.com/bertsky/ocrd-demo-2021-05-12
 Sign in with Wallet
Sign in with Wallet







