# Netflix Tech blogs
## Table of content
[TOC]
---
## Implementing Match Cutting
[Link to article](https://netflixtechblog.com/match-cutting-at-netflix-finding-cuts-with-smooth-visual-transitions-31c3fc14ae59)
The term [match cutting](https://hackmd.io/hC53pheET-aNdXejN_2J4Q?both#Match-Cutting) is explained in the terminology section.
Items in the Netflix catalogue (series/movies/shows) have millions of frames and to create manually match cuts, one has to label cuts and match them based on memory. This method misses out on lot of possible combinations and is very time consuming.
To automate selecting similar shots for transitions, we make use of neural networks.
A **frame** can be understood as a snapshot and a **shot** is a collection of frames.
### Approaches
#### Simplying the problem
1. Frames are visually similar within a single shot so only middle frame of each shot was considered.
2. Similar frames can be captured in different shots, so to remove redundancies, image deduplication was performed.
3. Keep frames having humans, discard others to keep things simple
#### Removing redundancies
1. **Shot de duplication**
Early attempts surfaced many near-duplicate shots.
Imagine two people having a conversation in a scene. It’s common to cut back and forth as each character delivers a line.
Near-duplicate shots are not very interesting for match cutting. Given a sequence of shots, we identified groups of near-duplicate shots and only retained the earliest shot from each group.
2. **Identifying near-duplicate shots**
Shots are put into an encoder model, which computes a vector representation of each shot and similarity is calculated using [cosine similarity](https://hackmd.io/hC53pheET-aNdXejN_2J4Q#Cosine-Similarity).
Shots with very similar vector representations are removed.
3. **Avoiding very small** shots
These can arise from a clip of the cast having a conversation, the camera shifts very frequently and can falsely create many such redundant clips.
___
### Rough implementation

___
### Match silhouettes of people using Instance segmentation

Output of segmentation models is a pixel mask telling which pixels belong to which object.
Basically the similarity between character-outlines is calculated.
Compute [IoU](https://hackmd.io/hC53pheET-aNdXejN_2J4Q#IoU) for two different frames, pairs with high IoU are selected as candidates.
### Action Matching using Optical Flow
Match cut involving continuation of motion of an object or person.
Intensity of the color represents the magnitude of the motion. Cosine similarity is once again used here.
Brought out scenes with similar camera movement.
---
:::info
End of Article 1
:::
---
## **Improving Video Quality with Neural Nets**
[Link to article](https://netflixtechblog.com/for-your-eyes-only-improving-netflix-video-quality-with-neural-networks-5b8d032da09c)
### Not much is given in article, so skip this if you want
### Why ?
As netflix is accessed by devices with different screen resolutions which work on different network qualities, video downscaling is deemed necessary.
A 4K source video will be downscaled to 1080p, 720p, 540p and so on, for different users.
### Approach
1. Preprocessing block
Prefilter the video signal prior to the subsequent resizing operation.
2. Resizing block
Yields lower-resolution video signal that serves as input to an encoder.

---
:::info
End of Article 2
:::
---
## **Scaling Machine Learning**
[Link to article](https://netflixtechblog.com/scaling-media-machine-learning-at-netflix-f19b400243)
1. Challenges of applying machine learning to media assets
2. Infrastructure components built to address them
2. Case study : To optimize, scale, and solidify an existing pipeline
### Infrastructure Components
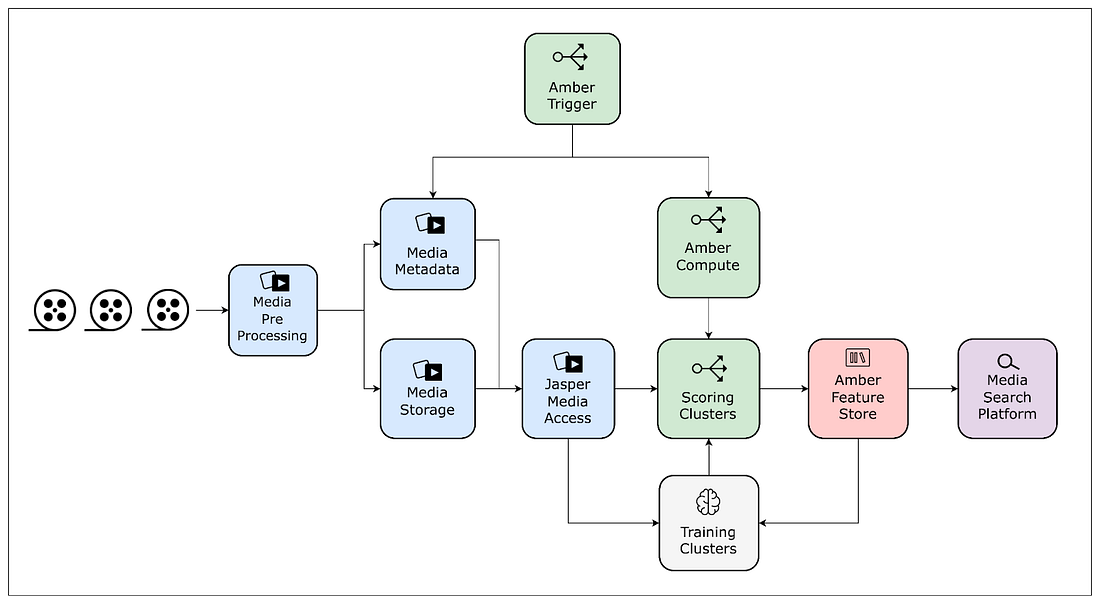
#### Jasper for Media Access
To streamline and standardize media assets
#### Amber Feature Store for Media Storage
[Memoizes](https://hackmd.io/hC53pheET-aNdXejN_2J4Q?both#Memoization) features/embeddings tied to media entities.
Prevents computation of identical features for same asset, enables different pipelines have access to these features.
#### Amber Compute for handling data streams
* Models run over newly arriving assets, and to handle the new incoming data, various trigger-mechanisms and [Orchestration](https://hackmd.io/hC53pheET-aNdXejN_2J4Q?both#Orchestration) components were developed for each pipeline.
* Over time this became difficult to manage, so to handle this Amber Compute was developed.
* It is a suite of multiple infrastructure components that offers triggering capabilities to initiate the computation of algorithms with recursive dependency resolution.
#### To lower computational Load
1. Multi GPU/ multi node [distributed training](https://hackmd.io/hC53pheET-aNdXejN_2J4Q#Multi-node-distributed-training). => [Notes for the same](https://drive.google.com/drive/folders/1qyXrT6OKb6hDFaUwOmt0My-ofO-MmLwA?usp=share_link)
3. Pre-compute the dataset
4. Offload pre-processing to CPU instances
5. Optimize model operators within the framework
6. Use file system to resolve data-loading bottleneck
### Scaling match cutting
:::success
Need to control amount of resources used per step
:::
### Initial Approach
#### Step 1 : Define shots
* Download a video file, and produce boundary shot metadata.
That is, divide a video into various shots.
* Materialize each shot into an individual file clip.
#### Step 2 : Deduplication
1. Extract representation/embedding of each file using an encoder model.
Use the encoder values (vector) to identify and remove duplicate shots (performing [de-duplication](https://hackmd.io/hC53pheET-aNdXejN_2J4Q?both#Removing-redundancies))
2. Surviving files are passed on to step 3.
#### Step 3 (vaguely mentioned in article)
Compute another representation per shot, depending on the flavor of match cutting
#### Step 4 : Score the pairs
Enumerate all pairs and compute a score for each pair of representations. Scores are stored along with the shot metadata
#### Step 5 : Sort the pairs
Sort the pairs based on similarity score, and use only the top k-pairs, **k** being the number of match-cuts required by design team.
### Problems with the initial approach
1. Lack of **Standardization**
The representations we extract in Steps 2 and Step 3 are sensitive to the characteristics of the input video files.
In some cases such as instance segmentation, the output representation in Step 3 is a function of the dimensions of the input file.
Not having a standardized input file format creat quality-matching issues when representations across titles with different input files needed to be processed together (e.g. multi-title match cutting).
2. Wasteful **repeated computations**
Segmentation at the shot level is a common task used across many media ML pipelines.
Also, deduplicating similar shots is a common step that a subset of those pipelines share.
[Memoizing](https://hackmd.io/hC53pheET-aNdXejN_2J4Q?both#Memoization) these computations not only reduces waste but also allows for [congruence](https://hackmd.io/hC53pheET-aNdXejN_2J4Q?both#Congruency) between pipelines that share the same preprocessing step.
3. **Pipeline triggering**
Triggering logic : whenever new files land, trigger computation
* Lack of standardization meant that the computation was sometimes re-triggered for the same video file due to changes in metadata, without any content change.
* Many pipelines independently developed similar bespoke components for triggering computation, which created inconsistencies.
---
### Final solution for scaling match cutting
#### **Standardized** video encoder
Entire Netflix catalog is pre-processed and stored for reuse. Match Cutting benefits from this standardization as it relies on homogeneity across videos for proper matching.
#### Shot segmentation and deduplication **reuse**
Videos are matched at the shot level.
Breaking videos into shots is a common task, the infrastructure team provides this canonical feature that can be used as a dependency for other algorithms.
Using this feature values were [memoized](https://hackmd.io/hC53pheET-aNdXejN_2J4Q?both=#Memoization), saving on compute costs and guaranteeing [coherence](https://hackmd.io/hC53pheET-aNdXejN_2J4Q?both=#Coherence) of shot segments across algos.

**Match cutting pipeline. Interactions are expressed as a feature mesh.**
---
:::success
End of article
:::
---
## Terminologies
### Match Cutting
Video editing technique, that acts as a transition between two shots using similar visual frames, composition, action etc.
In film-making, a match cut is a transition between two shots that uses similar visual framing, composition, or action to fluidly bring the viewer from one scene to the next.
### IoU
Also reffered to as the Jaccard Index.
Intersection over Union, has theoretical maximum value of 1, when both sets are equal.
J(A,B)= $A∪B \over A∩B$
### Cosine Similarity
To visualize, consider two vectors in 2D space. Thier cosine similarity is simply given by computing the cosine of two vectors.

[Video explaning cosine similarity](https://www.youtube.com/watch?v=e9U0QAFbfLI)
### Multi node distributed training
[Notes](https://drive.google.com/drive/folders/1qyXrT6OKb6hDFaUwOmt0My-ofO-MmLwA?usp=sharing)
Using many worker nodes to make use of parallelization to help speed up computation.
### Memoization
### Orchestration
Orchestration coordinates multiple microservices to achieve a common goal using a central platform like Kubernetes
### Congruency
congruency can be considered as a factor that influences the convergence of optimization methods
### Coherence
cohesion refers to the degree to which the elements inside a module belong together. In one sense, it is a measure of the strength of relationship between the methods and data of a class and some unifying purpose or concept served by that class.
---







