## 概述
在 [上一篇文章](https://blog.wssh.dev/posts/formal-verify-zero/) 中,我们介绍了形式化证明的逻辑学原理以及如何使用 wp 获得 VC 然后通过求解 VC 的可满足性获得程序是否正确。在本文中,我们将使用 [dafny 语言](https://dafny.org/) 探索如何在实战中进行形式化证明。使用 Dafny 的原因是该语言具备所有基础的形式化证明的功能,我们可以从使用该语言过程中复习到很多在上一篇文章内提及的概念,但是 Dafny 也帮助我们屏蔽了一些底层概念,我们不需要手动执行 `wp` 方法获得 VC,而且 dafny 会自动使用 z3 求解器帮助我们验证 VC。
在本文中,我们主要介绍基础的形式化证明的策略,并且给出 Bubble Sort / Quick Sort 和 Merge Sort 的案例。在本文的最后,我们将介绍笔者所属的 DeFi 领域中的一些简单的形式化证明案例。
## 基础策略
在进行形式化证明时,我们的第一步是理解待证明的代码实现,在阅读代码实现时,我们可以获得一些基础信息,我们成为 atomic properties,这些基础信息包括对入参的约束,函数输出的满足的属性,以及一些基础的 loop invariant。实际上这部分就是将 function specification 正确表述到 Dafny 语言中。比如 BubbleSort 返回已完成排序的列表需要证明返回值已完成排序和 permutation property(指返回值和输入值内的元素一致)。
当我们基于已有信息编写了基础的 function specification 和一些基础的 loop invariant 后,我们一般发现代码仍无法证明,此时我们就需要使用如下步骤:
1. 探索 basic fact,即一些基础的事实
2. 重复:
1. 使用 precondition method 产生 annotations
2. 将产生的 annotations 写入 Dafny 代码内观察是否可以推动证明
注意,上述步骤其实是一个启发式过程,我们无法保证最终代码是可以获得证明的。上述过程的本质是不断向 Dafny 代码补充信息以辅助 z3 证明。
## Bubble Sort
我们首先考虑最简单的数组排序方法,Bubble Sort。这是一种简单的排序方法,代码如下:

我们不难将上述代码翻译为如下 Dafny 代码:
```java
predicate Sorted(a: array<int>, lo: int, hi: int)
reads a
requires 0 <= lo <= hi <= a.Length
{
forall i, j :: lo <= i < j < hi ==> a[i] <= a[j]
}
predicate Partitioned(a: array<int>, l1: int, u1: int, l2: int, u2: int)
requires 0 <= l1 <= u1 <= l2 <= u2 <= a.Length
reads a
{
forall i, j :: l1 <= i < u1 <= l2 <= j < u2 ==> a[i] <= a[j]
}
method BubbleSort(a: array<int>)
modifies a
ensures Sorted(a, 0, a.Length)
{
if a.Length == 0 {
return;
}
var i := a.Length - 1;
while i > 0
{
var j := 0;
while j < i
{
if a[j] > a[j + 1] {
a[j], a[j + 1] := a[j + 1], a[j];
}
j := j + 1;
}
i := i - 1;
}
}
```
上述代码内包含了基础的 `Sorted` 函数和 `Partitioned`,这两个函数都是辅助后续证明的函数,注意上述函数都作用有 $[lo, hi)$ 的左闭右开区间。上述代码显然无法证明 `Sorted(a, 0, a.Length)` 的最终结果,这显然是因为我们没有编写足够的针对 `while` 循环的 loop invariant。我们的目标是增加这些 loop invariant。
第一步,我们首先增加一批最简单的针对循环变量 `i` 和 `j` 的基础属性,我们可以获得如下属性:
```java
while i > 0
invariant 0 <= i < a.Length
{
var j := 0;
while j < i
invariant 0 < i < a.Length
invariant 0 <= j <= i
```
这其实就是上文提到的显然的基础事实。接下来,我们可以通过另一个基础事实,根据最终的函数输出 `Sorted(a, 0, a.Length)` 和我们对 BubbleSort 的理解,我们可以发现内层循环和外层循环都满足 `invariant Sorted(a, i, a.Length)`,即对于从 `i` 开始的数组后半部分,我们都已经完成了排序。
但是增加了上述所有的 invariant 仍不可以证明,所以我们需要更进一步的 invariant。对于 Bubble Sort 而言,我们不难发现内层循环的特殊性,内层循环的冒泡特征会使得位于 `j` 索引的元素一定大于 $[0, j)$ 的元素,使用开始时定义的 `Partitioned` 函数表示为 `invariant Partitioned(a, 0, j, j, j+1)`。但是我们发现即时增加上述 invariant 后,仍是出现了 `Sorted(a, i, a.Length)` 无法证明的情况。
对于外层循环,我们可以为其添加一个也与 `Partitioned` 有关的属性,在 Bubble Sort 内,显然存在已完成排序部分和未完成排序部分,外层循环每次都会将 `i` 处理到正确的位置,所以 $[0, i]$ 部分是未完成排序部分,而 $[i+1, |a|)$ 部分是已完成排序部分,即 `invariant Partitioned(a, 0, i + 1, i + 1, a.Length)`。
但我们发现假如该不变量后,BubbleSort 函数仍无法完成证明。显然 $L_2$ 仍缺失部分属性。在上一篇文章内,我们曾获得如下 Path 联系了 $L_1$ 和 $L_2$:
$$
\begin{array}{l}
\text{@}L_2\\
S_1\text{ : }\text{assume} \quad j \ge i;\\
S_2\text{ : }i := i - 1;\\
\text{@}L_1: \text{Partitioned}(a, 0, i + 1, i + 1, |a|)
\end{array}
$$
上述 Path 实际上是在不满足 `j < i` 的情况下跳出循环的 path。我们对该部分进行 wp 推导:
$$
\begin{align*}
\mathrm{wp}&(L_2, S_1; S_2)\\
&\iff \mathrm{wp}(\text{Partitioned}(a, 0, i + 1, i + 1, |a|)), S_1; S_2)\\
&\iff \mathrm{wp}(\text{Partitioned}(a, 0, i, i, |a|), \texttt{assume } j \ge i))\\
&\iff j \ge i \to \text{Partitioned}(a, 0, i, i, |a|)
\end{align*}
$$
但是我们发现我们将 `invariant Partitioned(a, 0, i, i, a.Length)` 放入内层循环后,内层循环显示该不变量无法证明,原因如下:
```
bubbleSortWp.dfy(35,29): Error: this loop invariant could not be proved on entry
Related message: loop invariant violation
|
35 | invariant Partitioned(a, 0, i, i, a.Length)
| ^
bubbleSortWp.dfy(12,2): Related location: this proposition could not be proved
|
12 | forall i, j :: l1 <= i < u1 <= l2 <= j < u2 ==> a[i] <= a[j]
| ^^^^^^
```
实际上,这是因为我们给出了一个更加严格的不变量,这导致了无法证明。我们可以尝试放宽该不变量。我们可以使用另一条 Path:
$$
\begin{array}{l}
\text{@}L_1: \text{Partitioned}(a, 0, i + 1, i + 1, |a|)\\
S_1\text{ : }\text{assume} \quad i > 0;\\
S_2\text{ : }j := 0;\\
\text{@}L_2: ?\\
\end{array}
$$
我们发现由于 $S_1$ 和 $S_2$ 显然没有触碰 $L_1$ 内的变量,所以 $L_2$ 应该与 $L_1$ 一致,至此我们得到了如下完整版本的 Bubble Sort 内的所有不变量:
```dafny
method BubbleSort(a: array<int>)
modifies a
ensures Sorted(a, 0, a.Length)
{
if a.Length == 0 {
return;
}
var i := a.Length - 1;
while i > 0
invariant 0 <= i < a.Length
invariant Sorted(a, i, a.Length)
invariant Partitioned(a, 0, i + 1, i + 1, a.Length)
{
var j := 0;
while j < i
invariant 0 < i < a.Length
invariant 0 <= j <= i
invariant Sorted(a, i, a.Length)
invariant Partitioned(a, 0, j, j, j+1)
invariant Partitioned(a, 0, i + 1, i + 1, a.Length)
{
if a[j] > a[j + 1] {
a[j], a[j + 1] := a[j + 1], a[j];
}
j := j + 1;
}
i := i - 1;
}
}
```
由于 Dafny 底层就是使用了我们在上一篇文章内提及的 basic path 的证明方法,每一段 basic path 其实都是从 spec 或者 loop invariant 开始到 spec 或者 loop invariant 结束,所以这种 baisc path 方法存在“遗忘”属性,在某些情况下,我们需要将单个 loop invairant 写在多个位置。
## Quick Sort
快速排序是一种基于分而治之方法的排序方法,相比于 Bubble Sort 而言,Quick Sort 证明难度更高。
在介绍具体证明前,我们应该首先对 Quick Sort 有一个基础认识。该算法的最核心的步骤是选择一个元素作为 pivot,然后将所有大于该元素的数据放到 pivot 左侧而小于该 pivot元素放到右侧。理论上,pivot 是可以任选的,在此处我们定义区间最右侧元素 `a[hi - 1]` 作为 pivot。
具体过程中,我们会维护两个标签 `i` 和 `j`,然后扫描数组,扫描过程中满足以下关系:
```
[ <= pivot | > pivot | unscan element ]
i j
```
所以每当 `j` 发现 `a[j] <= pivot` 时,我们就会执行一次 `a[i]` 与 `a[j]` 的 swap 操作,并且将 `i` 自增。那么等到扫描到最后,我们可以获得:
```
[ <= pivot | > pivot | pivot ]
i hi-1(j)
```
此时我们可以执行 `a[i], a[hi - 1] := a[hi - 1], a[i];` 就可以完成将 `pivot` 放入正确位置,达成:
```
[ <= pivot | pivot | > pivot ]
```
的最终结果。我们一般称上述核心算法为 `Partition` 算法,我们首先证明此函数的正确性,我们先给出实现:
```dafny
method Partition(a: array<int>, lo: int, hi: int) returns (p: int)
requires 0 <= lo < hi <= a.Length
modifies a
ensures forall k :: lo <= k < p ==> a[k] <= a[p]
ensures forall k :: p < k < hi ==> a[p] < a[k]
ensures lo <= p < hi
{
var pivot := a[hi - 1];
var i := lo;
var j := lo;
while j < hi - 1
{
if a[j] <= pivot {
a[i], a[j] := a[j], a[i];
i := i + 1;
}
j := j + 1;
}
a[i], a[hi - 1] := a[hi - 1], a[i];
p := i;
}
```
由于后续我们会使用 `Partition` 在某一个数组上进行递归调用,所以此处我们要求输入完整数组,然后给定 `lo` 和 `hi` 对位于两者之间的元素进行排序,与上文定义类似,我们排序的具体位置是 $[lo, hi)$ 区间,该区间左闭右开。显然,我们的最终输出要满足如下条件:
```
[ <= pivot | pivot | > pivot ]
```
此处要额外注意 `p` 应该位于区间内,即 $p \in [lo, hi)$
上述算法写完后,我们发现无法证明,我们仍需要编写多个 invariant。根据上文对算法的介绍,我们可以发现 $[0, i)$ 区间一定小于 pivot 而 $[i, j)$ 区间一定大于 pivot,所以我们可以编写出如下 invariant:
```
while j < hi - 1
invariant forall k :: lo <= k < i ==> a[k] <= pivot
invariant forall k :: i <= k < j ==> pivot < a[k]
```
但我们发现仍是无法证明 `Partition` 的正确性,此时我们对文件执行 `dafny verify <file>` 命令,我们可以获得如下报错:
```
qsortExample.dfy(21,43): Error: index out of range
|
21 | invariant forall k :: lo <= k < i ==> a[k] <= pivot
| ^
qsortExample.dfy(22,50): Error: index out of range
|
22 | invariant forall k :: i <= k < j ==> pivot < a[k]
|
```
这说明 `k` 与数组的 `lo` 和 `hi` 关系没有建立,导致 dafny 证明器认为 `k` 有可能越界访问数组,所以此处我们还需要增加 `i` 和 `j` 与 `lo` 和 `hi` 的关系:
```
while j < hi - 1
invariant lo <= i <= j < hi
invariant forall k :: lo <= k < i ==> a[k] <= pivot
invariant forall k :: i <= k < j ==> pivot < a[k]
```
但上述代码仍出现无法证明的情况,所以我们此时需要研究一下 basic path,此处我们选择最短的 basic path,即 `j >= hi - 1` 的情况,此时我们实际上直接跳过了 `while` 循环内的内容。此处我们直接使用一种非数学的方法书写一下 baisc path,该 basic path 从 `while` 的最短路径直接跳出,即在 `j >= hi - 1` 的路径。但是由于函数 `lo <= i <= j < hi`,这意味着该路径其实就是 `j = hi - 1` 的情况。
```
pivot = a[hi - 1]
// while invariant
lo <= i <= j < hi
forall k :: lo <= k < i ==> a[k] <= pivot
forall k :: i <= k < j ==> pivot < a[k]
swap a[i] a[hi - 1] // a[i], a[hi - 1] := a[hi - 1], a[i];
p := i
// function post condition
forall k :: lo <= k < p ==> a[k] <= a[p]
forall k :: p < k < hi ==> a[p] < a[k]
```
我们可以看到相对于 post condition 而言,`while` 的 invariant 缺失了 `pivot` 与 `a[p]` 之间的关系。而 `p` 实际上就是 `hi - 1`,所以倒推出 `pivot == a[hi - 1]` 应该也在 invariant 内部。
至此,我们就获得了所有的 `while` invariant 内容:
```dafny
while j < hi - 1
invariant lo <= i <= j < hi
invariant pivot == a[hi - 1]
invariant forall k :: lo <= k < i ==> a[k] <= pivot
invariant forall k :: i <= k < j ==> pivot < a[k]
{
if a[j] <= pivot {
a[i], a[j] := a[j], a[i];
i := i + 1;
}
j := j + 1;
}
```
另一个我们一直没有在上文内提及的基础事实是无论 `Partition` 和 `QuickSort` 都是不会修改排序区间外的元素,所以此处我们可以引入一个 `predicate` 来表示数组 `s` 和 `t` 在 $[lo, hi]$ 之间是相等的。
```dafny
predicate EqRange(s: seq<int>, t: seq<int>, lo: int, hi: int)
requires |s| == |t|
requires 0 <= lo <= hi <= |s|
{
forall i :: lo <= i < hi ==> s[i] == t[i]
}
```
借助上述 `predicate`,我们可以将 `Partition` 的 spec 重写为如下内容:
```dafny
method Partition(a: array<int>, lo: int, hi: int) returns (p: int)
requires 0 <= lo < hi <= a.Length
modifies a
ensures lo <= p < hi
ensures forall k :: lo <= k < p ==> a[k] <= a[p]
ensures forall k :: p < k < hi ==> a[p] < a[k]
ensures EqRange(old(a[..]), a[..], 0, lo)
ensures EqRange(old(a[..]), a[..], hi, a.Length)
```
我们会发现上述 `Partition` 无法被证明,这是因为 `while` 的 loop invariant 出现了问题,我们可以简单增加如下 invariant 来完成证明:
```dafny
while j < hi - 1
invariant lo <= i <= j < hi
invariant pivot == a[hi - 1]
invariant forall k :: lo <= k < i ==> a[k] <= pivot
invariant forall k :: i <= k < j ==> pivot < a[k]
invariant EqRange(old(a[..]), a[..], 0, lo)
invariant EqRange(old(a[..]), a[..], hi, a.Length)
{
```
接下来,即使有了上述条件,我们发现 `QuickSort` 函数仍无法被证明。下文中的 `decreases hi - lo` 是用于 `QuickSort` 是可以中止的,根据 `if hi - lo <= 1` 的递归退出条件,我们不难得出 `hi - lo` 的递减性保证了递归会最终终止。
```dafny
method QuickSort(a: array<int>, lo: int, hi: int)
requires 0 <= lo <= hi <= a.Length
modifies a
ensures EqRange(old(a[..]), a[..], 0, lo)
ensures EqRange(old(a[..]), a[..], hi, a.Length)
ensures SortedRange(a, lo, hi)
decreases hi - lo
{
if hi - lo <= 1 {
return;
}
var p := Partition(a, lo, hi);
QuickSort(a, lo, p);
QuickSort(a, p + 1, hi);
}
```
但这个时候,我们发现可以为 `Partition` 函数补充一些 spec,我们发现在 `QuickSort` 函数中,后续的 `QuickSort` 接受的都是已经完成了 `Partition` 的数组,所以我们可以为 `QuickSort` 增加如下 `requires`:
```dafny
method QuickSort(a: array<int>, lo: int, hi: int)
requires 0 <= lo <= hi <= a.Length
requires Partitioned(a, 0, lo, lo, hi)
requires Partitioned(a, lo, hi, hi, a.Length)
ensures Partitioned(a, 0, lo, lo, hi)
ensures Partitioned(a, lo, hi, hi, a.Length)
```
实际上,上述 `requires` 也可以为 `Partition` 函数添加:
```dafny
method Partition(a: array<int>, lo: int, hi: int) returns (p: int)
requires 0 <= lo < hi <= a.Length
requires Partitioned(a, 0, lo, lo, hi)
requires Partitioned(a, lo, hi, hi, a.Length)
...
ensures Partitioned(a, 0, lo, lo, a.Length)
ensures Partitioned(a, lo, hi, hi, a.Length)
```
上述 spec 含义是对于 `Partition` 函数,对于接受的数组,我们要求输入数组的 $[0, lo)$ 内的元素小于 $[lo, hi)$ 内的元素,并且该不变量在函数的输入时和输出时都是成立的。这种函数不变量一般是证明递归等复杂交互的核心。当然,对 `Partition` 增加上述 spec 后,我们发现函数无法证明,这仍是因为 `while` 循环的 loop invariant 问题,我们可以直接添加如下 invariant 即可:
```dafny
invariant Partitioned(a, 0, lo, lo, a.Length)
invariant Partitioned(a, lo, hi, hi, a.Length)
```
当我们增加上述 loop invariant 后,我们可以发现所有的代码都完成了证明。在 Quick Sort 证明中,我们没有使用 wp 方法,这是因为 wp 方法面对一些复杂的数组操作时可能并不直观。此时我们只能依赖于一些基础理念,比如我们需要为递归提供有信息价值的不变量来辅助递归函数的证明。当然,此处也可以体现出很多代码无法证明的一个原因是 basic path 方法会丢失很多过去的信息,假如读者不注意这一点,在 loop invariant 处补充这些信息就会导致代码无法证明。
为了方便读者最终核对自己的代码版本与我的版本,此处笔者给出存储在 [gist 内的代码](https://gist.github.com/wangshouh/7386870ad0d2b293f39b6b4dec5a55ea)。
## Merge Sort
归并排序也是一种较为简单但时间复杂度也较低的排序方法,归并排序的原理可以使用下图表示。我们拿到一个数组后,我们首先将数组不断二分直到获得单个元素为止,然后使用单个元素进行从小到大的比较将其拼接为更大的数组,最后拼接完成意味着排序结束。

在 Dafny 内,我们首先使用 `merge` 过程的算法,即将多个数组拼接为一个更大数组的过程,也就是上图中的下半部分拼接的过程。
```dafny
predicate SortedRange(a: array<int>, lo: int, hi: int)
requires 0 <= lo <= hi <= a.Length
reads a
{
forall i, j :: lo <= i <= j < hi ==> a[i] <= a[j]
}
method Merge(a: array<int>, b: array<int>) returns (c: array<int>)
requires SortedRange(a, 0, a.Length)
requires SortedRange(b, 0, b.Length)
ensures SortedRange(c, 0, c.Length)
ensures c.Length == a.Length + b.Length
{
c := new int[a.Length + b.Length];
var i := 0;
var j := 0;
while i < a.Length && j < b.Length
invariant 0 <= i <= a.Length
invariant 0 <= j <= b.Length
invariant SortedRange(c, 0, i + j)
{
if a[i] <= b[j] {
c[i + j] := a[i];
i := i + 1;
} else {
c[i + j] := b[j];
j := j + 1;
}
}
while i < a.Length
invariant 0 <= i <= a.Length
invariant SortedRange(c, 0, i + j)
{
c[i + j] := a[i];
i := i + 1;
}
while j < b.Length
invariant 0 <= j <= b.Length
invariant SortedRange(c, 0, i + j)
{
c[i + j] := b[j];
j := j + 1;
}
return c;
}
```
在上述代码内,我们也编写了一些基础的 loop invairant 主要是一些限制循环变量范围的约束,以及一些前置条件,也就是 `SortedRange(a, 0, a.Length)` 和 `SortedRange(b, 0, b.Length)`,也包括了我们的预期 `invariant SortedRange(c, 0, i + j)`。但是我们可以发现 `invariant SortedRange(c, 0, i + j)` 是无法被证明的。此时我们需要补充额外信息来辅助 `SortedRange(c, 0, i + j)` 的证明。
此处我们可以使用 `wp` 方法,我们针对一个从 invariant loop 开始的 `if a[i] <= b[j]` 分支,然后为了尽可能简化 basic path,我们认为该比较不会跳出循环,而是直接返回 invariant loop。
```
SortedRange(c, 0, i + j)
c[i + j] := a[i];
i := i + 1;
SortedRange(c, 0, i + j)
```
我们使用 `wp` 方法,我们将 `i := i + 1` 代入可以获得 `SortedRange(c, 0, i + j + 1)`,所以我们的目标是证明:
$$
\text{SortedRange(c, 0, i + j)} \to \text{SortedRange(c, 0, i + j + 1)}
$$
在没有额外信息下,上述目标确实是无法证明的,我们发现只需要证明`c[i + j + 1] >= c[i + j]` ,而 `c[i + j + 1] = a[i]`,所以我们只需要证明 `a[i] >= c[i + j]`。此处我们可以进一步泛化,我们可以证明 `a[i]` 于目前 `c` 数组内的 $[0, i+j)$ 区间内的任意元素即可,这就带来了 `invariant forall k :: 0 <= k < i + j ==> c[k] <= a[i]`,但我们发现该 invariant 是无法证明的,使用 `dafny verify msort.dfy` 验证代码,我们可以得到如下报错:
```
msort.dfy(25,14): Error: this invariant could not be proved to be maintained by the loop
Related message: loop invariant violation
|
25 | invariant forall k :: 0 <= k < i + j ==> c[k] <= a[i]
| ^^^^^^
msort.dfy(25,54): Error: index out of range
|
25 | invariant forall k :: 0 <= k < i + j ==> c[k] <= a[i]
| ^
```
显然是因为 `i` 可能会越界访问导致的,所以此处我们可以将 invariant 修改为 `invariant i < a.Length ==> forall k :: 0 <= k < i + j ==> c[k] <= a[i]`。
此处可能有读者好奇为什么不能写为 `invariant i < a.Length ==> c[i + j - 1] <= a[i]`,实际上假如读者将上述 invairant 写入代码,也会得到的因为越界访问而无法证明的警告。在 `i = 0` 和 `j = 0` 的情况下,`i + j - 1` 为负数,这会导致越界访问,所以更好的解决方案就是编写一个更加泛化的结论。我们都已经编写了 `c[k] <= a[i]`,那么对应的我们也不难得出此处还需要补充 `invariant i < a.Length ==> forall k :: 0 <= k < i + j ==> c[k] <= b[i]`。当我们完成这两个 invairant 的编写后,我们可以发现 `while` 循环内的 `invariant SortedRange(c, 0, i + j)` 是可以得到证明的。
最后,我们需要进一步处理 `while i < a.Length` 和 `while j < b.Length` 的情况。正如本文常常提到的,由于 Dafny 被后使用了 baisc path 的方法,所以 dafny 在执行时会遗忘过去的 invariant。此处,我们可以直接为每一个 `while` 循环都补充:
```dafny
invariant i < a.Length ==> forall k :: 0 <= k < i + j ==> c[k] <= a[i]
invariant j < b.Length ==> forall k :: 0 <= k < i + j ==> c[k] <= b[j]
```
然后读者可以发现发现所有的 `SortedRange` 在增加上述两条 `invariant` 后都完成了证明。这也是本文一直强调的,在实际证明过程中,开发者也经常重复编写 invariant 来避免 basic path 方法导致的问题。
最后,我们编写完成 `Merge` 方法后,我们可以基于 `Merge` 构建 `MergeSort` 函数:
```dafny
method MergeSort(a: array<int>, lo: int, hi: int) returns (b: array<int>)
requires 0 <= lo <= hi <= a.Length
ensures SortedRange(b, 0, b.Length)
decreases hi - lo
{
if hi - lo <= 1 {
b := new int[hi - lo];
var i := 0;
while i < b.Length
invariant 0 <= i <= b.Length
invariant b.Length == hi - lo
{
b[i] := a[lo + i];
i := i + 1;
}
} else {
var mid := lo + (hi - lo) / 2;
var left := MergeSort(a, lo, mid);
var right := MergeSort(a, mid, hi);
b := Merge(left, right);
}
}
```
上述代码可以直接被证明而无需增加任何特殊的 spec。上述代码中的 `if hi - lo <= 1` 是跳出递归的终止条件,即假如不断 split 数组至数组内只存在一个元素时,我们终止递归返回数组。
## 智能合约案例
在上一节中,我们主要介绍了一些常见的数组排序算法的形式化证明,在本节中,我们将介绍一些在智能合约开发过程中,智能合约工程师会遇到的情况。此处主要摘取了我之前编写的 [Licredity](https://github.com/licredity/licredity-v1-core/) 内的部分案例。在未来的文章中,笔者会汇总更多案例来展示如何在实际智能合约开发工作中使用 Dafny 形式化证明工具。
### 内联汇编验证
在 Licredity 的外部审计过程中,审计工程师发现了在 `Position` 类型内存在漏洞。在此处,我们给出 `Position` 结构体的具体定义:
```solidity
/// @title Position
/// @notice Represents a margin position
struct Position {
address owner;
uint256 debtShare;
Fungible[] fungibles;
NonFungible[] nonFungibles;
mapping(Fungible => FungibleState) fungibleStates;
}
```
此处的核心是 `fungibles` 和 `fungibleStates` 实际上构成了一种被称为 enumerable set(可枚举集合) 的类型。简单来说,对于已经位于 `Position` 内的 `fungibles` 资产,更新逻辑是:
1. 假如需要更新的 `fungible` 不在 `fungibleStates` 内,那么我们将新的 `fungible` 写入 `fungibles` 和 `fungibleStates`
2. 假如需要更新的 `fungible` 已经位于 `fungibleStates` 内,那么我将直接更新 `fungibleStates` 内的数据
此处在 `fungibleStates` 内的 `FungibleState` 结构体定义如下:
```solidity
/// @title FungibleState
/// @notice Represents the state of a fungible
/// @dev 64 bits index | 64 bits empty | 128 bits balance
type FungibleState is bytes32;
```
我们会在 `FungibleState` 记录 `fungible` 在数组 `fungibles` 内的索引,利用该反向索引,我们可以获得某一个资产在数组 `fungibles` 内的位置,并进行下一步操作,比如删除该元素。
所谓可枚举就是指在后续代码内,我们其实可以直接通过遍历 `fungibles` 内的数据获得当前 Position 内的所有 fungible 资产的数量。由于 Licredity 是一个借贷协议,而 Position 内的 `fungibles` 和 `fungibleStates` 其实记录了用户作为担保品的所有的同质化代币的余额,我们需要遍历该部分数据获取用户当前的担保品的总价值。
此处我们主要观察 `removeFungible` 函数的原始实现,其原始实现如下(该版本内存在漏洞,读者可以看看能不能直接发现):
```solidity
function removeFungible(Position storage self, Fungible fungible, uint256 amount)
internal
returns (bool isRemoved)
{
FungibleState state = self.fungibleStates[fungible];
uint256 index = state.index();
uint256 newBalance = state.balance() - amount;
if (index != 0) {
if (newBalance != 0) {
state = toFungibleState(index, newBalance);
} else {
state = FungibleState.wrap(0);
// remove a fungible from the fungibles array
assembly ("memory-safe") {
let slot := add(self.slot, FUNGIBLES_OFFSET)
let len := sload(slot)
mstore(0x00, slot)
let dataSlot := keccak256(0x00, 0x20)
if iszero(eq(index, len)) {
sstore(add(dataSlot, sub(index, 1)), sload(add(dataSlot, sub(len, 1))))
}
sstore(add(dataSlot, sub(len, 1)), 0)
sstore(slot, sub(len, 1))
}
}
// update fungible state
assembly ("memory-safe") {
mstore(0x00, fungible)
mstore(0x20, add(self.slot, FUNGIBLE_STATES_OFFSET))
sstore(keccak256(0x00, 0x40), state)
}
isRemoved = true;
}
}
```
上述实现使用了内联汇编完成,对于部分初级工程师而言,这部分语义似乎不好理解。简单来说,当用户需要移除 `fungible` 资产时,我们首先在 `fungibleStates` 内读取该资产的状态,特别是该资产在数组 `fungibles` 内的索引。假如该索引为 `0` 则说明资产不存在,所以我们会直接跳出代码。但假如该资产存在非零索引,我们就会根据余额更新该资产在 `fungibleStates` 内的状态。假如用户 remove 后的余额不为 0,那么我们会直接使用如下代码更新 `fungibleStates` 内的余额,以下代码等效为 `fungibleStates[fungible] = state`。但假如用户 remove 后资产余额为 0,则我们需要将该资产从 `fungibles` 内移除来保持 `fungibles` 内只记录目前已有资产的性质。此处我们使用的方法其实是经典的 swap-and-pop 方法,即将待删除资产移动使用列表内最后的元素覆盖,然后直接删除最后的元素。在后文中,我们主要形式化证明 remove 后余额不为 0 的情况,也就是我们使用 swap-and-pop 删除数组元素的情况。
我们此处将其直接翻译为 dafny 内实现,但是第一步我们需要建模此处 `removeFungible` 所需要的 `fungibles` 和 `fungibleStates` ,此处我们使用的模型为:
```dafny
type Fungible = int
method RemoveFungible(
fungibles: seq<Fungible>,
fungibleStates: map<Fungible, nat>,
idx: nat
) returns (
newFungibles: seq<Fungible>,
newFungibleStates: map<Fungible, nat>,
removed: Fungible
)
requires idx < |fungibles|
ensures removed == fungibles[idx]
```
此处 `Fungible` 其实可以被建模为任意类型,因为此处我们的具体实现不需要考虑其实质类型,为了简化,我选择将 `Fungible` 使用 `int` 类型表示。与此对应,我们使用了 `seq<Fungible>` 建模 solidity 内的 `Fungible[] fungibles;`,使用 `map<Fungible, nat>` 类型对应 solidity 内的 `mapping(Fungible => FungibleState) fungibleStates;`。
另外上述 dafny 内的定义的 `RemoveFungible` 与 solidity 内的 `removeFungible` 的定义并不一致,这也是出于简化证明的角度。我们忽略了 `index == 0` 的情况,这种情况代表 remove 的 `fungible` 并不在 `fungibles` 内,函数会直接返回,对于这种简单情况,我们可以忽略。我们主要关注 remove 的 `fungible` 位于 `fungibles` 内部,此时我们会调用复杂的内联汇编进行处理。所以与之对应的,在 dafny 内,我们使用了 `idx` 直接代表待移除的 `fungible` 的索引,并且使用 `requires` 约定 `idx` 应该位于 `fungibles` 内部,并使用 `ensures` 保证 `removed` 获得的 `Fungible` 应该与 `idx` 在 `fungibles` 内的数值一致。
然后,我们将引入一个重要的关系。在前文中,我们提及 `fungibles` 和 `fungibleStates` 本质上构成了 enumerable set 关系。这个关系可以使用如下方法进行建模:
```dafny
predicate Distinct<T(==)>(s: seq<T>)
{
forall i, j :: 0 <= i < j < |s| ==> s[i] != s[j]
}
predicate ValidActive(fungibles: seq<Fungible>, fungibleStates: map<Fungible, nat>)
{
Distinct(fungibles)
&&
forall i :: 0 <= i < |fungibles| ==>
fungibles[i] in fungibleStates &&
fungibleStates[fungibles[i]] == i
}
```
其中 `Distinct` 用于描述 set 语义,保证集合中的元素不会重复,而 `forall i :: 0 <= i < |fungibles| ==>` 部分则适用于保证 `fungibleStates` 与 `fungibles` 之间存在对应关系,在 `fungibles` 内任何 Fungible 都位于 `fungibleStates` 内部,并且 `fungibleStates` 内记录的 index 与该资产实际在 `fungibles` 内的索引一致,即 `fungibleStates[fungibles[i]] == i`。
实际上更加完整的映射关系应该建模为:
```dafny
predicate ValidActive(fungibles: seq<Fungible>, fungibleStates: map<Fungible, nat>)
{
Distinct(fungibles)
&&
(forall i :: 0 <= i < |fungibles| ==>
(
fungibles[i] in fungibleStates &&
fungibleStates[fungibles[i]] == i
))
&&
(forall f :: f in fungibleStates ==>
(
fungibleStates[f] < |fungibles| &&
fungibles[fungibleStates[f]] == f
))
}
```
其中的 `forall f :: f in fungibleStates` 用来保证所有位于 `fungibleStates` 内的变量都在 `fungibles` 内正确记录。但是在本次形式化证明中,我们将不考虑该性质。因为在 Licredity 代码内,我们没有主动维护该映射,换言之,Licredity 代码内其实会出现 `fungibleStates` 内存在某种资产但是 `fungibles` 内并没有显示。这种特殊情况不会影响 Licredity 代码安全性。但注意对于其他协议而言,该映射不满足可能造成安全问题。
在有了上述 `ValidActive` 后,我们继续完成 `RemoveFungible` 的实现:
```java
method RemoveFungible(
fungibles: seq<Fungible>,
fungibleStates: map<Fungible, nat>,
idx: nat
) returns (
newFungibles: seq<Fungible>,
newFungibleStates: map<Fungible, nat>,
removed: Fungible
)
requires ValidActive(fungibles, fungibleStates)
requires idx < |fungibles|
ensures removed == fungibles[idx]
ensures ValidActive(newFungibles, newFungibleStates)
ensures |newFungibles| == |fungibles| - 1
ensures forall i :: 0 <= i < idx ==> newFungibles[i] == fungibles[i]
ensures idx < |newFungibles| ==> newFungibles[idx] == fungibles[|fungibles| - 1]
ensures forall i :: idx < i < |newFungibles| ==> newFungibles[i] == fungibles[i]
```
首先我们认为对于 `RemoveFungible` 而言,输入和输出都应该是满足核心不变量 `ValidActive` 的。然后,显然新数组 `newFungibles` 应该相比于原数组 `fungibles` 长度少 1。在上文内,我们也提到了 solidity 内的 `removeFungible` 函数使用了 swap-and-pop 的方式,该方法其实是基本可以保持数组原有的顺序的,在新数组内除了第 `idx` 个元素被替换为最后一个元素,其他部分的元素应该是与 `fungibles` 内是一致的。这就是最后三行 `ensures` 所表达的含义。
接下来,我们将上述内联汇编版本的 `removeFungible` 翻译为 dafny 内的语义等价版本,最核心的代码是 `sstore(add(dataSlot, sub(index, 1)), sload(add(dataSlot, sub(len, 1))))`。该部分的语义是将最后一个元素读取并写入到 `fungibles` 内待删除的位置。后续的代码主要用于修改 `fungibles` 的长度,等效为 `pop` 掉最后一个元素。我们可以使用如下语义表示:
```java
var lastElement := fungibles[|fungibles| - 1];
newFungibles := (fungibles[idx := lastElement])[..|fungibles| - 1];
```
上述代码内的 `fungibles[idx := lastElement]` 含义是将 `fungibles` 内的 `idx` 处的元素修改为 `lastElement`,然后类似 solidity 内的操作,我们直接修改 `newFungibles` 的长度丢弃最后一个元素。
实际上,只考虑最核心的骨架,上述 solidity 版本的 `removeFungible` 对应如下 dafny 实现:
```java
removed := fungibles[idx];
var lastElement := fungibles[|fungibles| - 1];
newFungibles := (fungibles[idx := lastElement])[..|fungibles| - 1];
newFungibleStates := fungibleStates;
```
在 solidity 版本内的 `removeFungible` 内的 `if (index != 0) {` 内我们没有更新 `fungibleStates` ,所以返回的 `newFungibleStates` 应该是与之前一致,此时我们发现 dafny 直接给出了报错。原因如下:
```
fungible.dfy(35,0): Error: a postcondition could not be proved on this return path
|
35 | {
| ^
fungible.dfy(30,21): Related location: this is the postcondition that could not be proved
|
30 | ensures ValidActive(newFungibles, newFungibleStates)
| ^
fungible.dfy(12,2): Related location: this proposition could not be proved
|
12 | forall i :: 0 <= i < |fungibles| ==>
| ^^^^^^
```
上述报错说明我们预设的 `ValidActive` 不成立,这其实是因为我们没有将 `fungibleStates` 内的 `lastElement` 内的对应的 `idx` 更新导致的,我们需要在 dafny 内将最后一行修改为:
```java
newFungibleStates := fungibleStates[lastElement := idx];
```
实际上,这也意味着我们在原始的 solidity 实现内需要增加如下代码:
```solidity
if iszero(eq(index, len)) {
// overwrite removed fungible's slot with the last fungible
let lastFungible := sload(add(dataSlot, sub(len, 1)))
sstore(add(dataSlot, sub(index, 1)), lastFungible)
// update moved fungible's state
mstore(0x00, lastFungible)
mstore(0x20, add(self.slot, FUNGIBLE_STATES_OFFSET))
let stateSlot := keccak256(0x00, 0x40)
sstore(
stateSlot, or(shl(192, index), and(sload(stateSlot), 0xffffffffffffffffffffffffffffffff))
)
}
```
其中对 `stateSlot` 的 `sstore` 就是更新 `lastFungible` 对应的索引的动作。上述修改可以参考 [Cyfrin C-2 / 7.1.2](https://github.com/Licredity/licredity-v1-core/commit/832d700152c336ed0a23bc2384e640cb30d8ce45) 提交。上述案例说明对于智能合约工程师而言,编写特定数据类型的 library 时,最后可以提前定义好数据类型的规范并将其写入 dafny 内部,接下来对于每一个编写的库函数,我们都可以在 dafny 内实现等价的 dafny 版本判断当前编写的 solidity 代码是否正确,主要是是否遗漏了一些更新逻辑。
### Stage 机制验证
这是一个 Licredity 内仍未修复的漏洞,该漏洞没有被人工审计发现,但是被 Agent 审计系统发现。在 Licredity 内,我们也使用了 stage 机制。所谓 stage 机制是一种简化的不基于 callback 的用于确定用户转入资产数量的机制,核心函数包括 `stageFungible`,该函数用于锁定某资产,当用户调用该函数时,我们会将目前 Licredity 内的该资产的余额缓存,然后用户可以直接向 Licredity 内转入资产,显然用户转入资产后,Licredity 内的余额会大于缓存系统内缓存的余额。我们在 `_popStagedFungibleAndAmount` 展示了如何计算用户在 `stageFungible` 完成后转入的资产数量:
```solidity
function _popStagedFungibleAndAmount() internal returns (Fungible fungible, uint256 amount) {
assembly ("memory-safe") {
fungible := tload(_stagedFungible.slot)
// clear staged fungible
tstore(_stagedFungible.slot, 0)
}
if (fungible.isNative()) {
amount = msg.value;
} else {
assembly ("memory-safe") {
// require(msg.value == 0, NativeValueNotZero());
if iszero(iszero(callvalue())) {
mstore(0x00, 0x2a4f6280) // 'NativeValueNotZero()'
revert(0x1c, 0x04)
}
}
amount = fungible.balanceOf(address(this)) - _stagedFungibleBalance;
}
}
```
上述代码的核心是 `amount = fungible.balanceOf(address(this)) - _stagedFungibleBalance;`,我们通过此代码计算用户到底在 stage 完成后向 Licredity 转入的资产数量。实际上,该计算也是 stage 机制最核心的不变量,即:
```
user transferIn = nowBalance - stageBalance
```
我们可以将其转化为 dafny 代码,以下代码内的 `nowBalance` 是代表 Licredity 合约自身的余额。注意,Licredity 本身也是一个 ERC20 代币合约,所以存在 `token == ADRESS_THIS` 的可能性。
```dafny
type Address = int
const ADDRESS_THIS: Address := 128
predicate Inv(token: Address, stageBalance: nat, nowBalance: map<Address, nat>, transferInAmount: nat)
{
token in nowBalance &&
ADDRESS_THIS in nowBalance &&
stageBalance + transferInAmount == nowBalance[token] // nowBalance - stageBalance = transferInAmount
}
```
此处我们使用 `nowBalance` 建模 ERC20 内的余额系统。目前来看,该机制似乎没有任何问题。我们希望对当前机制进行形式化证明,确保上述不变量是可以始终保持的。但是在 Licredity 内部,用户会有很多路径和各种调用流都会触及到上述不变量内的数据,比如 `depositFungible` / `increaseDebtShare` 等各种函数,理论上所有触及到 `nowBalance` 和 `stageBalance` 的函数都需要参与形式化。这些函数存在多种组合方式,难道我们需要枚举每一种调用流程来确定在任何调用流程下上述不变量都可以保持?
实际上是不需要的。在上一篇文章中,介绍代码形式化证明时,我们提到 loop invariant 的核心就是利用不变量控制了循环的状态空间,使得对单次循环的证明实际上可以被推导为对任意深度循环的证明。在此处,我们利用的同样的思想,我们只需要证明某一个函数,比如 `depositFungible` 在输入时可以保持 `Inv` 同时输出也可以保持 `Inv` 即可。当然,我们其实需要找到所有会修改不变量内状态变量的函数,并对这些函数进行逐个证明。目前来看,该过程很大程度上可以依靠一些自动化工具,本质上我们只需要搜索特定变量名即可,读者很容易借助 LLM 编写一个工具来完成该任务。
> 笔者实际上花了半个小时 基于 `slither-analyzer` vibe coding 了一个简单工具解析 solidity 合约然后直接从内部基于一套规则提取所有相关函数,但该工具目前暂时不完善,所以没有丢到 Github 内部,该工具的输出如下:
>
> ```
> === Entrypoint: Licredity.increaseDebtShare(positionId, delta, recipient) ===
> Call Tree:
> Licredity.increaseDebtShare(positionId, delta, recipient)
> W: fungible.balanceOf(address(this))
> Rule: fungible_balance_of
> └── BaseERC20._mint(to, amount)
> W: fungible.balanceOf(address(this))
> Rule: fungible_balance_of
> └── BaseERC20._transfer(from, to, amount)
> W: fungible.balanceOf(address(this))
> Rule: fungible_balance_of
> ```
>
> 其中 `W` 代表写入,而 `Rule` 其实一个启发规则集,比如 `mint` 函数和 `burn` 也会影响 `balanceOf` ,但是仅依靠机械式的搜索很难发现
我们对 `increaseDebtShare` 内有关 `Inv` 内状态变量的部分抽取出来。在 `increaseDebtShare` 内只有 `_mint(recipient, amount);` 一行核心代码会触及到 `Inv` 内的状态变量:
```dafny
method IncreaseDebtShare(
recipient: Address,
amount: nat,
stageBalance: nat,
nowBalance: map<Address, nat>,
transferInAmount: nat
) returns (updateBalance: map<Address, nat>)
requires recipient in nowBalance
requires Inv(ADDRESS_THIS, stageBalance, nowBalance, transferInAmount)
ensures Inv(ADDRESS_THIS, stageBalance, updateBalance, transferInAmount)
{
updateBalance := nowBalance[recipient := nowBalance[recipient] + amount];
}
```
我们发现上述代码是无法通过验证的,假如读者使用的是 vscode,那么可以按下 `F7`(在 MacOS 内是 `Control` + `F7` 案件),此时代码界面内会显示反例,如下:
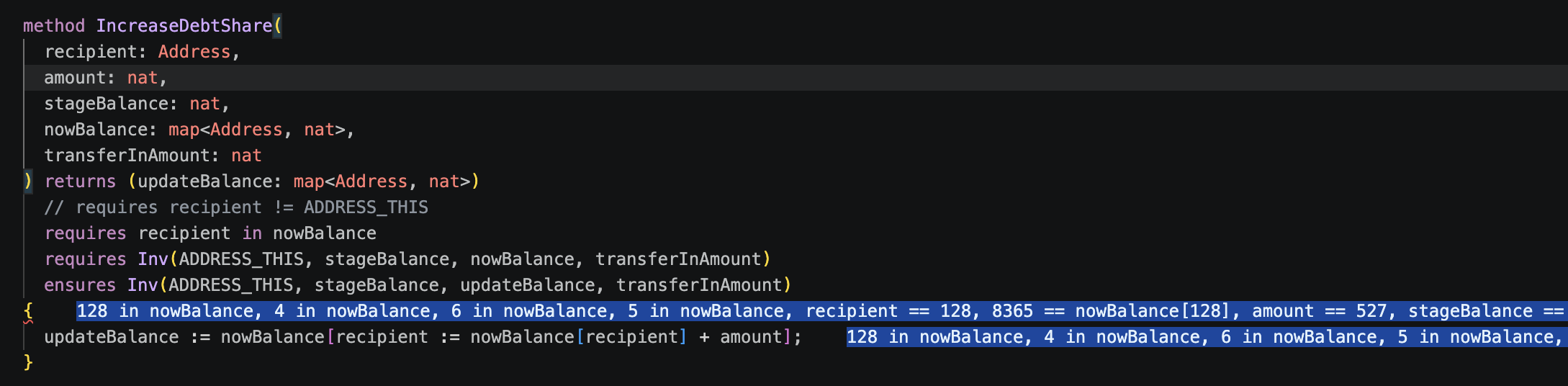
反例给出当 `recipient = 128` 时,该函数会打破不变量,此处的 `128` 其实就是我们在 dafny 内约定的 `const ADDRESS_THIS: Address := 128`。简单来说,当用户调用 `increaseDebtShare` 函数为 Licredity 合约 mint 代币时,我们的不变量就会被打破,这就产生了一个高危漏洞。读者可以尝试在 `IncreaseDebtShare` 内增加 `requires recipient != ADDRESS_THIS` 就会发现 `IncreaseDebtShare` 是可以被证明的。
接下来,我们简单证明一下 `decreaseDebtShare` 是否会打破上述不变量。在 solidity 实现内,我只需要关注如下代码:
```solidity
if (useBalance) {
position.removeFungible(Fungible.wrap(address(this)), amount);
_burn(address(this), amount);
// emit WithdrawFungible(positionId, address(0), Fungible.wrap(address(this)), amount);
...
} else {
_burn(_originalSender(), amount);
}
```
翻译为 dafny 如下:
```dafny
method DecreaseDebtShare(
amount: nat,
useBalance: bool,
stageBalance: nat,
nowBalance: map<Address, nat>,
transferInAmount: nat
) returns (updateBalance: map<Address, nat>)
requires Inv(ADDRESS_THIS, stageBalance, nowBalance, transferInAmount)
requires amount <= nowBalance[ADDRESS_THIS]
ensures Inv(ADDRESS_THIS, stageBalance, updateBalance, transferInAmount)
{
if (useBalance) {
updateBalance := nowBalance[ADDRESS_THIS := nowBalance[ADDRESS_THIS] - amount];
} else {
updateBalance := nowBalance;
}
}
```
此处需要注意对于 `decreaseDebtShare` 内的 `!useBalance` 分支,由于使用了 `_burn(_originalSender(), amount);` ,该代码并不会影响 Licreidty 合约的余额,而在上文介绍不变量时,我们已经提及 `nowBalance` 就代表 Licredity 合约自身的余额,所以此处我们选择了直接返回 `nowBalance` 作为 `updateBalance` 的值。
上述代码也是无法验证的,其实也是因为当 `useBalance = true` 时,`burn` 函数会直接修改 Licredity 合约的余额,该修改没有等效修改不变量的其他部分,这导致不变量被打破。上述两个证明其实都反映了对于一个依赖余额维持的不变量系统,假如出现了 `mint` 和 `burn` 操作,我们需要额外谨慎,因为 `mint` 和 `burn` 极有可能打破不变量。当然,上述代码也说明 Licredity 内的 stage 机制存在系统性缺陷,假如要修复,就需要重新设计机制,而不是小修小补。
> 其实 Licredity 内的 `exchangeFungible` 函数也会打破不变量,读者可以自行证明
在未来的博客中,我们会尝试证明 Uniswap v4 内的 balance delta 机制是正确的。通过上述两个案例,读者可以发现实际上证明某些 solidity 编写的机制是正确的在 dafny 内并不复杂,一般来说可以分为四个步骤:
1. 定义机制对应的核心不变量,或者不变关系
2. 在 dafny 内建模 solidity 内的数据类型
3. 寻找所有与核心不变量或不变关系有关的代码片段
4. 假设这些代码片段的入参满足不变量或不变关系,然后使用 dafny 语言编写语义等效于 solidity 代码的 dafny 代码,验证是否可以保证输出也是满足不变量或不变关系的
## 总结
在本文中,我们主要介绍了常见数组排序算法的形式化证明,在这部分中,我们特别强调了 basic path 的局部性属性,这会导致我们将重复编写一些 loop invairant 以保证 basic path 内包含充足的上下文。然后,我们介绍了两个智能合约的形式化证明案例,这些证明都是较为简单的,核心就是定义不变量、转义代码、证明不变量。







