# K8s與CNI的特性改進數據系統
很多新技術說穿了只是幾百年前的技術再包裝再組合,Docker就只是使用了Linux內建了幾百年的的cgroup,namespaces去實現基本的隔離再實現對每個namespaces路由規則,用手打指令也辦得到!,最後將開發環境壓成image直接在雲端展開,**但這種自動化程式打通了往雲端的最後一哩路所以就火紅了起來**,當然現在Docker公司也陷入困境找不到營利模式。[Docker 麻烦大了](https://www.infoq.cn/article/YlZXOE89K546iY6sKCG8)
關於新技術介紹方面;因小弟瀏覽眾多關於DataOps,AI,Spark與K8s文獻`發現"容器網路介面CNI"常是造成"分散式AI運算"瓶頸的關鍵`,加上本文是根據2019台灣資料工程年會小弟的演講內容撰寫與深入探討,`所以著重於network theory與兩種最重要的K8s CNI包括Flannel ,Calico 四種模式的詳細解說`,對於K8s基本概念POD,Service,Ingress,DNS,PV,PVC就不進行論述。
###### `Kubernetes` `AI` `Public Cloud`
#### 文章目錄
1. 雲端為何又紅了?這次真的會一直紅下去嗎?
1. 調度平台很多,為何用K8s?
1. K8s那些Feature可以提升Spark效能
1. 基礎K8s troubleshooting教學與GKE那些Feature可以提升Spark效能
1. 故事時間: Google與Apache的文化衝突
1. 那些年我們學過的計算機網路與Docker網路
1. 那些年我們學過的計算機網路與Docker網路
1. 故事時間:話說當年Google對付Docker的文化滲透戰
1. 那些年我們學過的計算機網路與K8s網路Flannel篇
1. 那些年我們學過的計算機網路與K8s網路Calico篇
1. 站在Google高層角度看AI演算法與系統優化
1. 矽谷新模式-台灣製造?與K8s現在與未來的玩法?
1. 鐵人賽致謝:
# AI/BigData生態系大事紀:
>大事紀中的事件在30天文章中都會陸續提到,這邊做個統整
Time | Event |
--------------|:-----:|
2008 |Hadoop成為Apache頂級專案,一個全新時代開始!|
2012 |Google Brain Team利用DistBelief與16000 CPU辨識貓咪|
2014 |GoogleNet-V1奪得ImageNet LSVRC競賽冠軍!|
2014/2 |Spark成為Apache頂級專案|
2014/5 |Docker Swarm計畫開始,合作夥伴Hortonworks目標將整個Hadoop生態系搬上Swarm|
2014/6 |Google Kubernetes 計畫開始,Google結盟CoreOS/Redhat|
2014/7 |Google Beam 計畫開始|
2014/8 |Docker公司賣掉起家厝Dot Cloud集中資源培養Docker Swarm|
2015 |CNCF基金會成立,Google/CoreOS/Redhat/Linux基金會成為創始成員|
2015/11 |Google Tensorflow計畫開始|
2016/2 |Google Beam捐給Apache基金會|
2017 |有鑑於Beam受到冷待遇Google要走自己的路,GCP K8s服務GKE正式啟用|
2017/11 |K8s整合Tensorflow項目kubeflow開始|
2017/11 |Docker CTO Solomon Hykes離職 Docker Swarm正式被Docker公司宣判死刑|
2018 |Google Cloud NEXT 2018,Google三隻箭射向Apache基金會,大K8s/AI/Big Data生態圈成形|
2018/1 |RedHat收購CoreOS|
2018/7 |Google晉升Linux基金會白金會員拿下董事會一個席位|
2018/10 |Docker Swarm重要支持者Hortonworks與Cloudera合併,Hortonworks在Nasdaq下市|
2019/5 |Twitter 宣布拋棄Apache Mesos,全面轉向 Kubernetes|
2019/5 |Docker公司宣布Steve Singh已辭去CEO職位,前Hortonworks的CEO Rob Bearden將接替他的位置|
2019/7 |IBM收購RedHat|
2019/10 |Google推出Tensorflow Enterprise|
###### tags: `Tag(Kubernetes)`
# 雲端為何又紅了?這次真的會一直紅下去嗎?(1)
一開始我們先討論一個問題,老資訊人應該都知道其實在7,8年前雲端就紅過一次 大概在2012年就有像Cloud Foundry這樣的成熟的Open Source PaaS軟體,那時也很多科技巨頭參與,但終究沒落,為何公有雲這次又紅了,甚至連整個矽谷最遲鈍的公司Oracle都推出公有雲!

**1.容器的出現**
首先是容器的出現,Docker的前身Dot Cloud公司為了解決他們自身問題,要嘛虛擬機VM閒的要命要嘛就是負載過重,所以他們發明Docker用以快速打包搬遷移植用戶的應用的來平衡OS的負載,很多人以為Docker只是輕量的VM,或是Docker是因為省去OS才能那麼輕量,這些都不完全正確,`Docker container正確的理解來說,它是作業系統的"特殊進程"`,不信嗎?我們用GCP開台Ubuntu 16.04 VM安裝DockerCE來做場實驗
```
sudo apt-get update
sudo apt-get -y install \
apt-transport-https \
ca-certificates \
curl \
gnupg-agent \
software-properties-common
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
sudo add-apt-repository \
"deb [arch=amd64] https://download.docker.com/linux/ubuntu \
$(lsb_release -cs) \
stable"
sudo apt-get update
sudo apt-get -y install docker-ce docker-ce-cli containerd.io
```
接著我們用 ps -A | grep -n docker 看一下這台VM,只有dockerd,dockerd就是docker的守護進程docker daemon,docker daemon負責通過Docker Server模塊接受Docker Client的請求,並在Engine中處理請求,然後根據請求類型,創建出指定的Job/container並運行

接著我們開一台容器 ubuntu:16.04
```
sudo docker run -it ubuntu:16.04 bash
```
這時我們再回VM看一下一樣使用 ps -A | grep -n docker

這時多了個進程名叫docker他的PID是5748,接著我們再起一台容器centos:7
```
sudo docker run -it centos:7 bash
```
再使用 ps -A | grep docker,又多了個同樣叫docker的容器進程他的PID是6065

接著我們用sudo docker ps 確認一下是否真的有兩個docker再運行

接著我們進去ubuntu與centos的docker容器看他有沒有省去OS


兩張圖可以看出來OS的File/lib都是在的,容器是有OS的File/lib,它所沒有的是OS的Kernel process,為了證明這件事我們在容器裡下ps -A

會發現只有兩個進程一個是ps一個是我們在前面docker run中下的bash,並沒系統進程在其中,我們回到VM下ps -A | wc -l計算進程數目

你會發現VM執行了127個進程,因為它是VM需要跑OS Kernel process,而Docker不用,有些喜歡追根究底的同學可能會問docker沒有跑OS Kernel process也能Run進程那我裝OS要幹嘛?事實上最底層還是有OS的假如你的Docker安裝在VM上Docker就是跑VM的Guest OS,裝在物理機上Docker就是跑物理機的Host OS,這裡來了個重點:我們能在Windows底下Run Linux VM那能不能在Windows底下Run Linux容器呢?不能!因為底層的OS Kernel process是Windows Kernel process!同樣的你也沒辦法把Ubuntu 18.04容器裝在Ubuntu 8.04的OS因為它的Linux OS Kernel process太舊了!最後附上一張跟磊哥借的VM與容器差別的架構圖。

今天的最後我們再來討論最後三個問題,你知道為什麼一些資訊安全專家說容器container是不安全的,從上面的架構圖你可以看出原因嗎?為什麼在container裡有些會改變OS Kernel process的指令(例如改變系統時間)不能使用?為什麼一個container每次只能運行一條進程呢?從前面的講解你找到原因了嗎?答案在。
# 雲端為何又紅了?這次真的會一直紅下去嗎?(2)K8s
**2.K8s的出現**
傳統的分散式AI平台Apache Yarn是圈地式調度,它直接裝在物理機上直接把這些物理機圈起來,這就是Yarn的資源,然後你可以透過Spark跑ML,SQL,DL或是透過Hadoop跑Batch Task,但你沒在跑上述任務時這些機器就在發呆,也沒法快速轉作Web, APP的Backend Server。
另一種是Docker Swarm,Docker Swarm也有Big Data領域三隻獨角獸之一的Hortonworks的支援`但其方案僅限於Docker Container,造成Docker公司與早期合作夥伴CoreOS/RedHat的決裂`,於是CoreOS/RedHat加入Google陣營,共同研發K8s,有Google大規模的運維經驗與RedHat對25年對伺服器OS的了解,還有CNCF基金會與Linux基金會的助拳,K8s最終打贏Docker Swarm一統雲容器調度生態系也是毫無懸念的。
K8s比起Yarn更加著眼雲端整體資源的治理,這點跟與Apache Yarn廝殺多年的Apache Mesos有點像,Apache Mesos也有Marathon架構可以兼容AI Task與一般App/Web Backend Task,實現一種早上跑WEB/APP Backend Server晚上跑AI 或是Batch Task的雲端資源治理理想,有點像一本書"北京摺疊描述的未來",未來的北京土地陽光水資源不足,於是將北京摺成三部分,早上中午是有錢人的北京,下午是中產階級的北京,深夜是底層百姓的北京,周而復始,充分利用所有僅存的資源,K8s也是為了實現這點不要讓機器發呆,不要讓資源不夠導致request沒辦法響應,不要讓單一機器過操導致提早損壞,同時要讓開發者更快的去迭代產品,更簡化維運人力,實現雲端治理終極理想。
CoreOS在2018年1月已被RedHat收購,成為旗下品牌

(圖片來源:北京折疊)
# 雲端為何又紅了?這次真的會一直紅下去嗎?(3)成本與工具
**3.成本考量**
1. 摩爾定律依舊狂奔,台積電的7奈米製程產能滿載,5奈米製程2020Q1就要開始生產,2奈米的目標已經喊出來!加上AMD新Server架構效能大爆發且採用台積電的7奈米製程的EPCY伺服器吸引到AWS,GCP,Azure的採用,導致Intel再也沒辦法擠牙膏了,一台伺服器用10年的時代就像青春的小鳥一樣一去不復返!`
1. 用K8s或者Serverless的思考: [Serverless:慢 15%,贵 8 倍?](https://www.infoq.cn/article/QfiSEJCymi68YlDfmfbT)
1. 再加上GPU/TPU/FPGA的層出不窮,我們來看一下以Nvidia的Tesla V100 GPU 16G PCI版本來說官方給的數據Double-Precision Performance是7 ,而上一代Nvidia的Tesla P100 GPU的Double-Precision Performance是4.7,兩者價格差不多,但性能提升了快1.45倍,`也就是說就算你完全沒用你的GPU你也必須負擔龐大折舊費用`,然而如果你用公有雲不但不用折舊明年相同價格性能還會自動提升,`最後我在2017年時看過一篇AWS新聞稿;他的意思是說從2006年AWS成立以來降價過50次從沒漲價過,`更何況現在2019年是雲端群雄價格戰殺翻天的年代,不學著用公有雲就太對不起新台幣上的小朋友了。
**4.Infrastructure as code and CI/CD tool的發展**
1. 藉由Infrastructure as code and CI/CD tool我們五分鐘就在GKE(Google K8s Engine)創造一個AI/Big Data群集,用完立即刪除,資料放在Google Storage或S3也不需要額外維持Ceph Cluster,使用費用極致壓縮,~~演示會放在Gitlab CI中展現~~。
1. 在此向各位致歉因我的文章都是用下班時間撰寫/研讀,而且基於敬業精神我不能使用公司的代碼,最終因時間不足再建構一套代碼所以演示取消
# 調度平台很多,為何用K8s?
這篇我們思考調度平台很多例如: Apache Yarn, Apache Mesos, Docker Swarm,為何用K8s?這裡簡單列4點,歡迎大家進行更多思考
* **1.更高明的設計(Borg & Omega) vs Docker Swarm**
比起它的主要競爭對手Docker Swarm ,K8s有更高明的設計 畢竟它包含了google多年運維經驗(Borg & Omega),這種工程經驗的累積與沉澱不是Docker這種年輕的新創公司可以比擬的
* **2.更年輕有活力的社群與外部創新或新創 vs 老邁Apache Mesos(2007)**
K8s有更年輕有活力的社群 K8s有滿滿的年輕人動不動就開會動不動就討論;CNCF基金會贊助很多學術研究,這是老邁的Apache Mesos完全無法追趕的,甚至有大量的外部新創/創新圍繞在周圍 例如:用於快速佈署的Helm多雲治理的Istio
* **3.支援多種容器 rkt runC LXC/LXD containerd…等**
另外K8s可以支援多種容器 rkt, runC, LXC/LXD, containerd,CRI-O 更有彈性,請大家追蹤[臺灣資料工程協會的FB](https://www.facebook.com/groups/dataengineering.tw/),說不定有一天在Cloudera工作的大大可以來台分享不同容器對AI/Big Data系統的影響
* **4.CNCF基金, Linux基金會, RedHat與Google支持**
K8s身後有CNCF基金, Linux基金會, RedHat與Google支持,RedHat更在早期大力參與代碼的編寫,在Github K8s Project中前10名代碼貢獻者其中有4位來自RedHat,使得這家有25歷史的Linux領域的老公司讓IBM捨得砸了1兆台幣併購
* **5.總結**
`Docker Swarm專案隨著Docker的聯合創始人兼技術長Solomn Hykes的離職已經被Docker公司放棄`,當初要將Docker Swarm結合Big Data Ecosystem的合作夥伴Hortonwork已經被Cloudera合併後消失在歷史舞台,而Apache Mesos垂垂老矣加上主力擁護者Twitter都轉向K8s,也走不動了,至於Apache Yarn在Cloudera推出兼容K8s的新架構必定會有一番新面貌,令人期待!,在2019的今天其實雲容器編排系統之戰早就結束很久了,就連當年叱吒整個矽谷擁有全世界無數Dev支持的Docker公司都無法對抗K8s,K8s未來很可能就像Linux,Andriod一樣永遠統治下去直到人類滅亡的那天,所以快點加入K8s吧!
# K8s那些特性可以提升AI系統性能(1)
本章開始歸納出5個K8s特性可以提升Spark效能,那接下來的4天我們就配合程式碼與解說來演示其中的概念,基於單篇15分鐘內讀完的原則故拆成四天讓大腦比較好吸收。
1. Namespace
1. Label and Label Selector
1. Taints and Tolerations
1. CPU Manager
1. Anti-affinity
### 1.Namespace
Namespace 的概念,很多程式語言都有Namespace(命名空間)的概念比如在C++中我們可以透過不同的Namespace(命名空間)創造兩個相同名子的變數Variable,Namespace在K8s也是類似的用法,比如我們可以創造一個命名空間叫做Intern 一個叫做Employee,就可以在各自Namespace(命名空間)跑各自的Spark不會衝突不用排隊不用考慮FIFO, RR, Priority,另外我們也可以給予兩個命名空間不同的計算資源CPU/GPU,這樣就算全公司都擠在同一個雲平台也不會產生實習生的程式排擠到資深人員或資料科學家的工作。
首先啟動一組GKE群集共有5個節點每個節點4CPU,3.6MEM,因為Saprk官方預設有啟動Anti-affinity機制一個node頂多跑一個Spark-Executor,若要一次跑多個Spark-Executor就得佈署多個node,至於為何要預設要開啟Anti-affinity後面文章會解說。
**`警告:K8s版本請小於1.13.10-gke.0,目前使用1.12.9-gke.15成功!`**

接著點上圖中的"連結"會SSH連線到GKE Master,並執行以下指令創造兩個namespace。
```
kubectl create namespace spark-intern
kubectl create namespace spark-employee
```

接著在下`kubectl get namespaces`,我們就可以看到剛剛創建的Namespace(命名空間)

接著我們幫它配置資源使用量,下面這段程式碼因為有用cat>> file << EOF context EOF包起來,你可以直接複製貼上不用進vim
```
cat >> StaffResource.yaml << EOF
apiVersion: v1
kind: ResourceQuota
metadata:
name: compute-quotas
namespace: spark-intern
spec:
hard:
requests.cpu: "3"
requests.memory: 4Gi
limits.cpu: "3"
requests.memory: 4Gi
---
apiVersion: v1
kind: ResourceQuota
metadata:
name: compute-quotas
namespace: spark-employee
spec:
hard:
pods: "5"
requests.cpu: "10"
requests.memory: 16Gi
limits.cpu: "10"
requests.memory: 16Gi
EOF
```
接著下`kubectl create -f StaffResource.yaml`運行yaml檔

接著我們要在兩個Namespace(命名空間)跑Spark官方的spark-pi程式,來看看兩者是否真的有同時處理沒有衝突,並且是否有依照我們所設定的資源數量進行運算,在這之前先幫spark開啟對應的權限serviceaccount與clusterrolebinding即K8s群集控制權。
```
kubectl create serviceaccount spark-intern -n spark-intern
kubectl create clusterrolebinding spark-intern --clusterrole=edit --serviceaccount=spark-intern:spark-intern -n spark-intern
kubectl create serviceaccount spark-employee --namespace=spark-employee
kubectl create clusterrolebinding spark-employee --clusterrole=edit --serviceaccount=spark-employee:spark-employee --namespace=spark-employee
```

接著下載Spark程式,解壓縮進入資料夾
```
wget http://apache.mirrors.lucidnetworks.net/spark/spark-2.4.4/spark-2.4.4-bin-hadoop2.7.tgz
sudo tar -xzf spark-2.4.4-bin-hadoop2.7.tgz
cd spark-2.4.4-bin-hadoop2.7
```
接著再找出K8s Master的IP,填入bin/spark-submit的--master參數後
```
K8sMaster="k8s://$(kubectl cluster-info | grep -n "Kubernetes master" | cut -f 6,6 -d " ")"
echo $K8sMaster
```

再來我們要來執行Saprk-pi任務,記得將echo $K8sMaster得到的字串取代bin/spark-submit的--master參數,這裡我們啟動兩個Terminal分開執行
```
bin/spark-submit \
--master <K8sMasterIP ex: https://35.200.234.221> \
--deploy-mode cluster \
--name spark-pi \
--class org.apache.spark.examples.SparkPi \
--conf spark.executor.instances=1 \
--conf spark.kubernetes.driver.limit.cores=1 \
--conf spark.kubernetes.executor.request.cores=10m \
--conf spark.kubernetes.executor.limit.cores=50m \
--conf spark.kubernetes.namespace=spark-intern \
--conf spark.kubernetes.container.image=ted00132/spark:v1 \
--conf spark.kubernetes.authenticate.driver.serviceAccountName=spark-intern \
local:///opt/spark/examples/jars/spark-examples_2.11-2.4.3.jar
```
```
bin/spark-submit \
--master <K8sMasterIP ex: https://35.200.234.221>\
--deploy-mode cluster \
--name spark-pi \
--class org.apache.spark.examples.SparkPi \
--conf spark.executor.instances=5 \
--conf spark.kubernetes.driver.limit.cores=1 \
--conf spark.kubernetes.executor.request.cores=100m \
--conf spark.kubernetes.executor.limit.cores=500m \
--conf spark.kubernetes.namespace=spark-employee \
--conf spark.kubernetes.container.image=ted00132/spark:v1 \
--conf spark.kubernetes.authenticate.driver.serviceAccountName=spark-employee \
local:///opt/spark/examples/jars/spark-examples_2.11-2.4.3.jar
```
接著用`kubectl get pod --all-namespaces或kubectl get pod -n spark-intern或kubectl get pod -n spark-employee`,就可以看到POD進程運行的狀況

接著我們可以看到兩組相同的Spark-pi程序分別在不同的namespaces命名空間執行並且依照我們給予的配額與POD/Spark-Executor數進行分散式運算,根據下圖我們可以看出`spark-intern中的Spark花了3分28秒才解出pi而spark-employee中的spark只花了25秒就解出pi;這跟我們給予的CPU配額與POD/Spark-Executor數呈現正相關`,喜歡追根究底的朋友可以用以下指令看POD/Spark-Executor實際的配置
```kubectl describe pod <pod-name or spark-executor-name> -n <namespace-name>```
實際的配置會跟我們再bin/spark-submit輸入的幾個 --conf參數一樣,並受到StaffResource.yaml所設定的配額限制,有興趣的朋友可以試試不同參數!最後附上執行結果圖。

最後到這裡已經寫了5740字基於篇幅考量許多參數,指令沒解釋清楚就麻煩各位大大發揮Google技能了!
# K8s那些特性可以提升AI系統性能(2)
### 2. Label and Label Selector
接下來是Label 透過Label我們可以將IO強大的節點分配給Data Source,擁有眾多計算能力的節點分配給AI系統,具體來說我們可以創造一個Label:GPU=K80並把它貼在有K80 GPU的節點上,並在我們Deployment,Statefulset的yaml中添加Label Selector加上GPU=K80字段,那POD運行時K8s系統就會幫我們把POD分配到有Label:GPU=K80的節點上,如果是使用Spark官方提供的bin/spark-submit方法只要在參數加入--conf spark.kubernetes.node.selector.`GPU=K80`即可。接著我們就在GCP上進行實作,為了示範方便我們就直接再Web操作而不是使用GCP SDK下指令,不然裝SDK又要一些時間,加上SDK不停改版有些API廢棄了Doc卻沒更新,不熟悉的朋友可能還會跑出一堆Bug。
**步驟A:**
在IAM申請GPU配額,申請後約1~2個工作天就會收到GCP回應

**步驟B:**
在GKE選GPU加速運算,並點擊更多選項,請注意並不是每個區域都有支援GPU運算

**步驟C:**
幫節點貼上GPU=K80標籤Label

**步驟D:**
進入Terminal下kubectl get node會看到兩個node,其一叫gpu-pool是包含gpu的K8s節點

**步驟E:**
使用kubectl describe node \<node-name\>就可以看到node貼的標籤

**步驟F:**
在spark-submit加入--conf spark.kubernetes.node.selector.GPU=K80,這樣K8s就會把spark-executor佈署到GPU節點比用Apache Yarn做簡單很多吧!
```
bin/spark-submit \
--master <Your K8sMaster IP> \
--deploy-mode cluster \
--name spark-pi \
--class org.apache.spark.examples.SparkPi \
--conf spark.executor.instances=1 \
--conf spark.kubernetes.executor.request.cores=10m \
--conf spark.kubernetes.executor.limit.cores=50m \
--conf spark.kubernetes.namespace=spark-intern \
--conf spark.kubernetes.container.image=ted00132/spark:v1 \
--conf spark.kubernetes.authenticate.driver.serviceAccountName=spark-intern \
--conf spark.kubernetes.node.selector.GPU=K80 \
local:///opt/spark/examples/jars/spark-examples_2.11-2.4.3.jar
```
**步驟E:**
執行後你會發現Task卡在Pending,這是因為GCP預設有幫GPU節點打上汙點,為什麼GCP要這樣做呢?與汙點的原理/用途?之後會說明,因為Spark官方參數還沒支援汙點容忍Tolerations技術所以我們先用去除汙點的方法

```
kubectl taint nodes <gpu_node_name> nvidia.com/gpu-
```
nvidia.com/gpu是key值,而後面-代表刪除汙點

```
kubectl get pods --all-namespaces
```

接著我們用`echo $(kubectl describe pods <spark-pod-name> -n <namespace-name> | grep Node:)`看Task是否真的跑在GPU節點上

運算時間就不寫了,畢竟只有`圖類處理的AI演算法在GPU上才會有比較好的效果`,而且Spark-pi應該沒支援GPU運算,這篇只是在示範開頭說的如何透過label將算力強大節點分配給特定計算型Task。
# K8s那些特性可以提升AI系統性能(3)
### 3. Taints and Tolerations
Taint讓我們可以在晚上時或CPU利用率較低時,我們可以透過汙染Taint的方式趕走節點上原本的POD/Task使它們集中在"沒有被汙染的節點上",`那麼那些被汙染,而空出來的節點拿去做計算或是訓練模型或是跑每天需要batch AI任務,甚至直接關閉用以節省成本。`
**實作說明:**
接著我們開始實作,我們要開有5個節點node的GKE群集,一開始會有很多Nginx分散在這5個節點中,我們要透過Taint機制,趕走特定節點的Nginx,使節點變成乾淨的節點避免,Backend Task 與AI Task/Batch Task混在一起產生大量Context Switch造成效能問題,服務延遲。Context Switch解釋可以參考陳鍾誠/羅習五老師的-[作業系統投影片-第四章](https://www.slideshare.net/ccckmit/ss-127408907),或是那些年我們讀的計算機理論課本。
**步驟A:**
建立nginx的yaml檔,我這yaml是透過`kubectl get deployment <deployment-name> -o yaml -n <namespaces> >> output.yaml`反向生成的,所以參數特多一般不用定義到如此仔細,其中有個參數replicas可以控制pod數量,這招反向生成yaml檔在Debug時常會用到,`這邊說一下K8s Debug三利器desrcibe, logs與 -o yaml`,後天我們會用三利器來做基礎的Troubleshooting,老樣子,內容有用cat>> file.name <<EOF EOF包起來程式碼直接複製貼上即可不用進vim。
```
cat >> nginx.yaml <<EOF
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
annotations:
generation: 1
labels:
app: nginx
name: nginx
namespace: default
resourceVersion: "26060"
selfLink: /apis/extensions/v1beta1/namespaces/default/deployments/nginx
uid: 7dd1f7c4-d84c-11e9-bf01-42010a8c004c
spec:
progressDeadlineSeconds: 600
replicas: 10
revisionHistoryLimit: 10
selector:
matchLabels:
app: nginx
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
creationTimestamp: null
labels:
app: nginx
spec:
containers:
- image: nginx
imagePullPolicy: Always
name: nginx
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
terminationGracePeriodSeconds: 30
EOF
```
**步驟B:**
接著使用apply Update Nginx的設定檔;apply與create的差異在於create通常用於第一次建立設定檔而apply用來創建或更新設定檔,細節請自行查閱K8s官方Doc,-f代表從file讀設定檔,接著我們看namespace=default底下的所有POD,到底佈署在那些節點Node上
```
kubectl apply -f nginx.yaml #or use kubectl create -f nginx.yaml
kubectl describe pods -n default | grep Node:
```

**步驟C:**
K8s很聰明地幫我們把10個Nginx POD/Task分散在5個節點Node上,現在我們希望空出節點5db71650-99r5就使用Taint汙染該節點;AI=Spark:NoExecute,Key=AI而Value=Spark最後NoExecute表示立刻驅逐該節點上沒有對應Tolerations的POD/Task。
```
kubectl taint node gke-standard-cluster-1-default-pool-5db71650-99r5 AI=Spark:NoExecute
```
**步驟D:**
接著我們在下一次`kubectl describe pods -n default | grep Node:`就會發現原本待在5db71650-99r5節點的Nginx都被趕走了,這時候我們就可以拿此節點來跑做AI或是跑每天需要batch任務不用擔心Backend Task 與AI Task/Batch Task混在一起產生大量Context Switch的問題,甚至直接關閉Node用以節省成本,最後因為Spark官方的bin/spark-submit方式還不支援Taints and Tolerations特性,所以必須用Spark Operator的方式,但這種方式有點小複雜,基於時程安排今天就不跑Spak-pi了

**步驟E:**
好奇的朋友可能會用`kubectl get pod -n default `發現有兩個Nginx的POD/Task停在Pending狀態而非正常的Running,這時候就要用我們開頭講的K8s Debug三利器來看看這些Pending的POD/Task為何卡住,特別注意logs指令後不用接POD而describe指令要接POD或是resource-type資源類型;因為logs是專門用來Debug POD/Task錯誤用而describe可以用來Debug任何resource-type資源類型
```
kubectl get pod -n <namespaces-name> #不加-n預設namespaces是default
kubectl describe pods <Nginx-POD-Name> -n <namespaces-name>
kubectl logs <Nginx-POD-Name> -n <namespaces-name>
```
最後回答昨天的問題,`為何GOOGLE要在GPU節點上加上Taints而不是使用Label,因為比起Label,Taints機制更有彈性`;比如NoExecute的強制驅離,NoSchedule的一定不能被調度,PreferNoSchedule的盡量不要調度,透過NoSchedule或NoExecute就可以防止一般Backend Task,例如:Nginx跑到GPU節點上來。
# K8s那些特性可以提升AI系統性能(4)
## 4.CPU Manager
CPU Manager, 讓Spark的executors獨佔CPU核心增加Cache命中率,減少讀取MEM次數,讀MEM不僅比較慢,同時MEM是所有CPU核心共用如下圖,假如CPU1在讀取MEM CPU2,CPU3,CPU4就得等待,讀一次記憶體莫約需要百個運算週期,同時Cache是CPU獨佔資源意味者CPU讀取Cache無需等待其他CPU,盡量讓程序命中Cache減少互相等待其他CPU讀取MEM時間可以有效減少POD/Task執行時間,另外CPU Manager也能避免多個POD/Task爭搶CPU資源而頻繁產生上Context Switch下文切換,`根據Kubeflow的機器學習調度平台落地實戰的測試指出CPUSET模式;即讓POD獨佔整顆CPU核心的狀況下效能會比CPUShare,高出20%效能。`

(圖片來源:http://tutorials.jenkov.com/java-concurrency/java-memory-model.html)
## 5. Anti-affinity
Affinity又翻作親和性,在那些年我們讀的計算機課本是這樣解釋的,讓同一個task或又稱作process盡量配置在同一個CPU核心;這樣可以提升Cache的命中率,畢竟task或又稱作process是有生命周期的她不會一直待在CPU裡,如下圖。

(圖片來源:羅習五-作業系統投影片 -- 第四章)
解釋完那些年我們讀的計算機課本中的Affinity那K8s的Affinity或Anti-affinity又是甚麼意思呢?首先我們要有認知K8s是分散式雲容器排程系統,它並不是OS(作業系統,例如:linux,ubuntu,redhat,windows),同時Docker也不是VM它沒有OS kernel process;在前面的章節[(Day3)](https://ithelp.ithome.com.tw/articles/10214958)我們有證明過Docker或容器只是OS中的一個特殊進程(task或又稱作process),所以此Affinity非彼Affinity,K8s作為分散式雲容器排程系統最重要的工作是將Docker/容器在多個節點中調度來調度去,所以這裡的Affinity當然是指節點Node間的Affinity而不是OS中的CPU間的Affinity。
望文生義在K8s中Anti-affinity的作用就是將SPARK POD/Task打散在不同的節點,提高HA避免單台物理機掛點全部SPARK POD/Task一起掛點,也避免全擠在一起對區域IO造成壓力,`在基于Kubeflow的機器學習調度平台落地實戰一文中指出Anti-affinity可以減少parameter server所在節點的網路壓力。`
Spark架構中並沒有parameter server的設計,所以所有工作,例如:A.主程序運行/B.任務分派/C.資源請求/D.狀態監控與更新/E.參數收集與廣播都是SPARK Driver在做;造成其Network IO量之大更甚parameter server,如果是支援向量機SVM這種少參數的AI算法就還好,反之像類神經網路NN這種參數量常常破千萬的AI演算法就不堪設想!`而且Spark只支持Sync同步式參數更新,也就是全部executors各自計算完成後會一起同步參數,這樣就會對網路設備瞬間造成壓力(Brodcast)`,透過Anti-affinity將SPARK POD/Task打散在多個網路設備物理拓樸中均分各種工作階段的壓力,誠如SPARK官網所推薦。

(圖片來源:Spark官網)

(圖片來源:spark學習-42-Spark的driver理解和executor理解)
## 參考
1.羅習五-作業系統投影片 -- 第四章
2.Kubeflow的機器學習調度平台落地實戰
3.spark學習-42-Spark的driver理解和executor理解
4.http://tutorials.jenkov.com/java-concurrency/java-memory-model.html
5.http://spark.apache.org/docs/latest/running-on-kubernetes.html
# 基礎K8s troubleshooting教學與GKE那些Feature可以提升Spark效能
根據80/20法則,你掌握這篇交的3個troubleshooting方法大概可以解決80%問題,剩下的得靠經驗/資訊素養去解決了,DevOps是很神奇的工作!
## 簡易K8s troubleshooting教學
**`警告:K8s版本請小於1.13.10-gke.0,目前使用1.12.9-gke.15執行Spark成功!`**
首先我開一台K8s集群,如下圖所示

接著我們下指令`kubectl get pods --all-namespaces`看看,恩,每個POD都是Running很好都正常!

接著我們取得Master IP,等下準備來跑Spark-pi做troubleshooting
```
K8sMaster="k8s://$(kubectl cluster-info | grep -n "Kubernetes master" | cut -f 6,6 -d " ")"
echo $K8sMaster
```

接著我們創造namespaces=spark-employee,服務帳號與對應的K8s控制權限serviceaccount, clusterrolebinding,這樣Spark主程序才有權限控制K8s做計算
```
kubectl create ns spark-employee
kubectl create serviceaccount spark-employee --namespace=spark-employee
kubectl create clusterrolebinding spark-employee --clusterrole=edit --serviceaccount=spark-employee:spark-employee --namespace=spark-employee
```

我們需要Spark binary中的spark-submit,這邊要注意一下如果連結失效要手動去找一下新版本,有些版本有Bug會被淘汰,像我之前用的2.4.3已經無法下載了。
```
wget http://apache.mirrors.lucidnetworks.net/spark/spark-2.4.4/spark-2.4.4-bin-hadoop2.7.tgz
sudo tar -xzf spark-2.4.4-bin-hadoop2.7.tgz
cd spark-2.4.4-bin-hadoop2.7
```
執行代碼如下,請自行更改Master IP
```
bin/spark-submit \
--master k8s://https://34.66.74.255 \
--deploy-mode cluster \
--name spark-pi \
--class org.apache.spark.examples.SparkPi \
--conf spark.executor.instances=2 \
--conf spark.kubernetes.driver.limit.cores=1 \
--conf spark.kubernetes.executor.request.cores=100m \
--conf spark.kubernetes.namespace=spark-employee \
--conf spark.kubernetes.container.image=ted00132/spark:v1 \
--conf spark.kubernetes.authenticate.driver.serviceAccountName=spark-employee \
local:///opt/spark/examples/jars/spark-examples_2.11-2.4.3.jar
```
接著觀察spark的log,發現卡在pending

接著我們下`kubectl get pods --all-namespaces`找出pending的那個spark-driver

接著我們用troubleshooting三利器之一的logs指令`kubectl logs spark-pi-1571214466683-driver -n spark-employee`,發現根本沒產生log,看來spark on k8s方案還有改善空間

前面的logs指令沒用,沒關係,接著我們用troubleshooting三利器之二的describe指令
`kubectl describe pods spark-pi-1571214466683-driver -n spark-employee`
OK!我們看到錯誤原因了"0/1 nodes are available: 1 Insufficient cpu.";沒有節點可以配置CPU不足

接著我們用troubleshooting三利器之三的-o yaml指令,看一下配置的yaml檔
```
kubectl get pods spark-pi-1571214466683-driver -n spark-employee -o yaml >conf
cat conf
```
李組長眉頭一皺發現案情不單純,yaml裡寫spark-driver需要1顆CPU

接著我們回頭再用troubleshooting三利器之二的describe指令,看一下節點狀況
`kubectl describe node `
發現CPU request已經高達83%,難怪無法再執行新的Task,同時觀察右邊可以發現那些POD占用CPU,發現是舊的spark-driver占掉51% CPU request

於是我們先刪掉舊的spark-driver
```
kubectl get pods --all-namespaces
kubectl delete pod spark-pi-1571213772960-driver spark-pi-1571214466683-driver -n spark-employee
```

我們在跑一次Spark-pi任務,任務執行成功花了25秒!本次troubleshooting教學到此結束,感謝大家!


## GKE feature for Spark
**1. Faster Deploy(5分鐘) vs Other**
提供雲端K8s服務的廠商很多,為何我們要選Google,相比於AWS與Azure的K8s SaaS服務部屬時間長達30分鐘,GCP的GKE部屬只要5分鐘,這意味著我們可以在要訓練模型時才快速模部屬節點,算完就刪掉非常節省。
**2. Master of K8s is free**
~~當然最棒的一點就是 GKE的Master of k8s is free ,不用負擔Master運維與成本~~。2020/5新消息Master要開始收費了
**3.Preemptible Node**
Preemptible node有穩定(50% Off) 但是它有個缺點只能存活小於24小時也就是可能算到一半節點就被cancel了 不過不用擔心spark本來就有容錯能力。
**4.Support Calico CNI**
在Intel與京東資深工程師分享的報告(Spark on Kubernetes: A case study from JD.com)中指出Calico可以有效提升Spark效能(後面會解釋Calico原理)。
**5.分鐘計費與綁約折扣**
當如果經過各種優化仍覺得Spark on GKE 效果不好可以直接刪掉節點費用是以分鐘為單位計算,當然如果覺得效果不錯Google也提供綁約3年最高50%以下折扣。
### 參考:
1.自身工作經驗
2.[GKE建立叢集網路政策](https://cloud.google.com/kubernetes-engine/docs/how-to/network-policy?hl=zh-tw)
3.https://cloud.google.com/kubernetes-engine/?hl=zh-tw
# 故事時間: Google與Apache的文化衝突(1)
終於來到第12天,看了那麼多專業文章我的腦袋都快爆了,來說點產業生態(ㄅㄚㄍㄨㄚˋ)吧!多多了解產業生態有幫助我們工程師提升職業生涯,比如說某人三年前聽學長姐講資料科學領域已經很擠了;滿地AI補習班,10份履歷有11份會DL/ML,加上Python易學難精一沒寫好效能就大爆炸,尤其Python是直譯語言非編譯語言,直譯語言那就只能靠User熟悉CPython的機制,所以說Python做研究可以;請新手寫Python做Production只能說你們家CTO心臟也挺大顆的當然也可能是你們家CTO`技術功深石補天所以不怕請新手寫Python`,聽完學長姊的話惦惦斤兩覺得自己只是成大的渣渣,那個被台科大踩在腳下的傢伙,同時也沒法接受D薪實習所以就不一窩蜂擠資料科學領域,反而跑去當DevOps寫寫Golang寫寫Yaml於是就有了這一系列混合了AI/DevOps/K8s/network與各種產業新知(ㄅㄚㄍㄨㄚˋ)的神奇系列文章產生。
好我們言歸正傳,話說當年Google發表了三篇論文Google FS、MapReduce、BigTable,一位來自JAVA領域的神人Doug Cutting就憑著Google的三篇"抽象的論文"實現了最早的Hadoop與MapReduce揭開了一個大時代的序幕,PS: Hadoop是Doug Cutting兒子的玩具大象。

(圖片來源:https://www.techgoondu.com/2015/12/30/its-still-early-days-for-big-data/)
到了2018 Hadoop正式滿10歲,從當年形單影隻的大象已經變成一個巨大的動物園如下圖,甚至誕生了三隻獨角獸Cloudera, Hortonworks, MAPR漫步其中,光Spark一個project就有23000 Start/20000 Fork,整個生態系加起來應該超過15萬Start ,Cloudera估值更一度達到41億美金,面對那麼龐大的商機同時自認大數據始祖的Google當然要分一杯羹阿!於是Google貢獻了Apache Beam希望也能擠進這個動物園,不過對於Google的舉動,整個Apache Hadoop的生態系的反應相對冷淡,`畢竟在Apache的文化中Google除了那三篇論文外就沒有重大code貢獻所以論資排輩稱不上可以主掌方向的大佬`,只有Flink熱切地回應Google舉動,當然其目的也只是為了藉Google資源幹掉主要競爭對手;就是我們今天的主角Spark。

(圖片來自https://www.dotnettricks.com/learn/hadoop/apache-hadoop-ecosystem-and-components)
我們觀察一下Beam Project如下圖,總共快23000次commits手筆之大投入工程力量之多也算上GitHub上的頂級專案,畢竟Hadoop花了10年也才累積22000次commits; `當然這跟Google快速迭代的工程文化有關`;相反的Apache保守很多,回歸主題Google花了那麼多資源而Apache Beam卻只有3200 Start不到2000 Fork,連我們的主角Spark的10之1都沒有,不得不說Apache Beam的情況令Google有點失望,然而商業上的損失對身家上千億美金的Google只是九牛一毛細胞中的細胞間質,大家都知道Google有20%文化,工程師可以花他們20%時間做自己喜歡的專案,所以Google每年累積沒結果的專案沒上千件也有上百件,每年這些沒結果專案所投入的金額恐怕都可以養好幾個台灣軟體產業,令Google眾人真正失望的其實是另一件事,`就是Google自豪的"軟體工程文化"`在Apache面前被毫不留情的碾碎,說好的大數據鼻祖呢?說好的軟體工程能力所向匹敵呢?`那個被所有軟體新創集體控告的軟體巨獸呢?`那個到任何領域都會把原本業者打得稀巴爛的Google呢?那個至高無上的Google呢?
>盛竹如:天地有情、人生無常,命運就像一張網讓人掙不開也逃不脫,一如蜘蛛活在自己編織的網中,吞噬獵物也等著被獵物吞噬,面對Apache無情的羞辱,到底Google會如何復仇呢,讓我們繼續看下去。

# 故事時間: Google與Apache的文化衝突(2)
前面說到Google自豪的`"軟體工程文化"`在Apache面前被毫不留情的碾碎,接著讓我們在換一個角度來看,比如Google工程師的奴隸階級,喔不,我是說Google工程師職位階級,Google工程師職位總共分為11個等級。
1,2,3,通常一般工程師
5,6則是資深工程師代表Google前10%菁英
8級是首席工程師,9級是傑出工程師
10級則到了Google院士一種至高無上的榮譽職務代表菁英中的菁英
而11級則是Google的工程之神至今只有兩位Jeff 與 Sanjay

(圖片來源:https://www.wired.com/2012/08/google-as-xerox-parc/)
每年Google的年輕工程師們最重要的一個平凡樸實無華且枯燥的慶典就是歌頌他們的天神Jeff Dean偉大且真實的事蹟比如說:
1. 當發生編譯錯誤時,編譯器會向Jeff道歉。
2. Jeff直接寫二進制機器碼,他寫源代碼,是為了給其他開發人員作參考。
3. X86-64規範裡有幾項非法指令,標誌著"秘密",它們其實是Jeff專用的。
5. 當Bell發明電話時,他看到了來自Jeff的未接來電
6. Apple的標誌啟發至"Jeff咬了一口的某種水果"
7. gcc的-O4優化選項其實是將你的代碼寄給Jeff重寫一下
8. Jeff依然孤獨地等待著數學家們解開他在Pi中隱藏的笑話
9. Google App Engine的服務器實際上是經過Jeff優化後的Nexus S手機
10. 當Jeff向以太網發送一個封包時從來不會有衝突,因為本來要和它有衝突的封包都默默退回了緩衝區
總之Jeff Dean是如此偉大沒有他就沒有今天的Google,他的辦公室就在Google CEO Sundar Pichai的隔壁,喔對了!`我忘了說Jeff Dean還有一個真實且偉大的事蹟;他就是Apache Hadoop領域天神Doug Cutting手上拿著的那三篇論文的作者`,也就是說這已經不是商業務利益問題了!這已經全面升級為Google與Apache之間宗教與文化的戰爭!那些異教徒竟然褻瀆了我們的神!
>盛竹如:天地有情、人生無常,命運就像一張網讓人掙不開也逃不脫,一如蜘蛛活在自己編織的網中,吞噬獵物也等著被獵物吞噬,面對Apache無情的羞辱,到底Google會如何復仇呢,讓我們繼續看下去。
>
## 參考:
1.Jeff Dean的傳奇人生:超級工程師們拯救谷歌
2.https://www.wired.com/2012/08/google-as-xerox-parc/
# 故事時間: Google與Apache的文化衝突(3)
日相安倍有三支箭振興經濟,Google為了對Apache復仇也有三支箭:1.資源調度與管理,2.人工智慧,3.靈活的資料儲存策略與收尋引擎
**1.資源調度與管理**
AI作為公司業務的一部分卻被排除在整體IT運籌之外,需要另外使用Yarn進行管理,從CTO/DevOps角度來看這很不方便,可是Apache Yarn掌控整個Hadoop生態系已無法撼動,該怎麼辦呢?那先全力培植K8s並成立CNCF基金會推廣甚至聯合Linux基金會,打擊跟Apache Yarn廝殺多年,與K8s同樣可以用於Microservices的Apache Mesos,結果大成功Mesos被打到連主力支持者Twitter都反水,Apache陣營出現第一個缺角。
**2.人工智慧**
開源DL, ML 框架TensorFlow,侵蝕Apache原先的AI業務,加上Keras封裝TensorFlow原始API成為更簡單易懂的高階API更掀起全民寫AI熱潮,此外K8s有原生支持TensorFlow即是Kubeflow更顯得如虎添翼,造成Apache陣營出現第二個缺口,結果就是多個雲端大廠EX:IBM, 百度, 京東的AI服務都是跑在K8s之下而非Apache Yarn。2019/10進一步推出TensorFlow Enterprise,提供優化與諮詢服務。

**3. 靈活的資料儲存策略與收尋引擎**
雖然Apache HDFS 雖然堅不可摧,但畢竟維持一個Object Storage Cluster成本太大了,冷資料存在GCP Storage,AWS S3/Glacier要分析時再下載顯得更便宜,至於熱資料當然就放在DB裡所以Google拉攏各種資料庫如下圖,例如: MongoDB(Document), Redis(Cache & Key Value), neo4j(圖像儲存), MySQL(K8s v1.3 support Huge Pages)建立更靈活的資料儲存策略,加上search Engin,EX: Elastic,第三個缺口妥妥的被打開,連最火熱的Apache Kafka都反水加入Google陣營。

**備註:**
其實Google開源K8s是為了打擊Docker Swarm,特別是拉攏當時被Docker公司背叛的CoreOS/Redhat,所以K8s的開源跟Apache Mesos,Apache Yarn沒有太多關係頂多是順道K一下Apache,不過Apache基金會創始人,主席與執行副總裁三人同時離職是真的。相反的沉寂多年的Linux創造者Torvalds過的倒是挺滋潤的,身材越來越有份量了;當然脾氣還是一樣大。
**計算機小學堂:人物篇**
Linus Torvalds的父親是名記者,母親是空手道高手,依照遺傳學理論Linus應該要成為一位有黑帶的運動領域記者或是熱愛採訪別人的運動員,`可惜天不從人願,Linus大佬有一位超級懶惰的大學教授外公,Linus的外公懶到連打程式碼都不願意!所以Linus的外公聰明的想到利用他的小Linus幫他把數學公式轉成程式碼輸入進計算機`,這就開啟了Linus大佬的計算機生涯,到大學Linus大佬終於有了第一台屬於自己的計算機,但是他覺得計算機裡的作業系統is not good,於是他花了9個月手刻了一套全新類UnixOS,`同時Linus大佬受到GUN之父Richard Stallman的精神感召於是將這套他手刻的OS開源,補上GUN計畫最後一塊版圖也是最難的部分OS kernel`;接著後面的事情大家都知道就不說了,`順道一題Linus大佬也是很有個性的人當初賈伯斯Jobs重回蘋果時曾邀請Linus大佬加入,可大佬終究是大佬對這種利益熏天做幾年光賣股票就可以身價破億的工作,才不屑做呢!`最後Linus大佬的故事告訴我們;有一個好爸爸(X),有一個懶外公(O)會幫助你成功!

## 參考:
1.某位資料領域大佬
2.作者腦洞大開
3.Linux,因業餘愛好而誕生
4.Linux之父Linus Torvalds:指頭數完了
5.https://blogs.apache.org/foundation/entry/statement-by-the-apache-software1
# 那些年我們學過的計算機網路與Docker網路(1)-序論
我們回來講容器網路,對於分散式AI運算來說網路是非常影響效能的關鍵,尤其在雲端網路都特別複雜,一台機架上有多少用戶都很難說,偏生網路又是共享資源不是獨佔資源相對單純。
`接下來的內容原則上都是大學泛資訊學群的網路課程範疇`,其實很多新技術只是舊技術稍微包裝後取個新名子用來方便行銷,例如:Andrew Tanenbaum 大師說: "交換器Switch是「現代橋接器Bridge」的另一個名稱,其中的差異是行銷手法多於技術因素"
俗話說沒吃過豬肉也看過豬走路,`為了避免被人笑土包子連資料中心的"機櫃都沒看過玩什麼K8s?`今天就貼一張: Google Data Center機架圖讓大家聞香,機架有很多種,通常就像下圖一排一排的長櫃,櫃子裡會塞滿滿的Server伺服器,最頂端通常會有一台TOR Switch連接該機櫃的所有伺服器形成一個物理上的區域網路,即Underlay網絡;而Overlay網絡則是透過虛擬化技術形成的邏輯網路例如:K8s的Flannle,接著多台Switch會連到一台區域核心Switch,多台區域核心Switch會在連到一群由好貴貴的Cisco頂級Router組成的核心Router群,一個資料中心的網路簡單理解就是這樣。

(圖片來源: Google Data Center)
見識完機櫃與資料中心,`這章開始我們要從那還在2G沒有Wifi的年代阿宅到底如何在打網路遊戲,一路講到Docker網路與K8s網路`,就像第一篇說的在計算機領域有些東西是不太會改變的,網路就是其中之一,這領域近年最大的改變大概就是VLAN進化成VXLAN,其他都沒有甚麼太多改變,Cisco依然稱王;您老大就是您老大,那些年我們一起背的OSI依然是那七層,TCP/UDP還是TCP/UDP,或許多了Flannel, Calico…等CNI介面,但底層的原理還是一樣,例如: K8s目前最奔的CNI(Container Network Interface)Calico來說,不過就是使用了Linux中內建了幾百年的老掉牙工具iptables將Docker的宿主物理機變成超大型路由器再配合2006年就出現的BGP (Border Gateway Protocol)協定管理這些超大型路由器。
訊號不夠好嗎?連線連不到嗎?你需要更多的天線!

### 參考:
1.https://www.youtube.com/watch?v=7pkNt3szF1A
2.https://www.projectcalico.org/
# 那些年我們學過的計算機網路與Docker網路(2)-宿網篇
如果從OSI開始講大概有人立馬關掉網頁或直接秒睡在電腦前簡直比Stilnox還好用,所以先從那些年WiFi還不普及,行動網路還在2G,阿宅們到底是如何打網路遊戲的!
首先我們的電腦需要一張網路卡,每張網卡都會有獨一無二的MAC地址,MAC地址總共有6位,前3位代表生產商編號,後3位代表產品編號,比如我們在windows底下cmd輸入ipconfig/all找到區域網路介面卡實體位置並複製前三位0C-54-15

再前往網站`https://mac.51240.com/`,輸入0C-54-15就會得到網卡製造商名稱Intel如下圖,如果我們在VMware裡下開台Linux下ifconfig會查到網卡製造商VMware。
成

回到主題,當每台電腦都有網路卡以後,我們還需要一台設備將所有電腦連在一起,這台設備通常叫Switch交換器或用更便宜的Hub集線器,Hub跟Switch差在哪裡呢?差別一個是有腦子的一個是無腦的,比如:小明要跟小華分享`那些年我們一起追的蒼井空`;封包從小明的電腦出來後到了Hub集線器,Hub是沒腦的網路設備它根本不知道哪台是小華的電腦,於是它就把封包進行廣播給區域網路內所有的設備,這時小華的電腦在監控特定端口看到封包就把它收進來,於是小明跟小華就完成了愛情動作片的傳送,`因為是用廣播的所以任何設備只要會解析這封包都可以一起觀賞愛情動作片`,而Switch交換器是有腦子的它會記住哪台是小華的電腦哪台是小明的電腦,所以可以準確地只將封包傳給小華,也避免大家都在傳片子造成廣播爆炸打崩網路。
有沒有很孰悉的感覺呢?那些年我們是不是常聽到有人大吼:超lag到底誰又在載片子了,馬的我的Penta Kill沒了!對此我的學長還氣到特地去學Wireshark(網路封包解析工具)去抓誰在傳/載片子,學長你都會解析封包了順道再考張CCNA證照如何?,**`真的是科技始終來自於人"性",人"性"是提升男孩學習動機的最大動力!`**
**網路小學堂**:為啥說HUB是無腦的網路設備?因為HUB是只實現OSI七層中的Layer1實體訊號發送,而MAC協定是在Layer2資料鏈結層,所以HUB根本沒法解析MAC地址,當然就無法記住哪張網卡是屬於哪台電腦摟!原理很簡單吧!
**K8s SaaS服務小學堂:**
在Day3我們說過Container只是OS的"特殊程序",跟VM有自己的獨立GuestOS不同,Container間會共用OS,這樣就會帶來資訊安全風險,比如:一個厲害的駭客先侵入一個不重要的Container在透過其入侵OS再入侵其他重要Container,雲端廠商為了避免這樣的資訊安全風險,所以會把Container放在VM的GuestOS上而非物理機的Host OS上,所以在GCP我們下ifconfig會查不出網卡製造商,`因為那是Google透過VM技術幫你虛擬出來的網卡不是實體網卡。
### 參考:
1.CCNA++
2.那些年的網路課本
2.趣談網路協定
3.https://medium.com/@fiberstoreorenda/do-you-know-the-difference-between-hub-switch-router-b74c2e8a8143
# 那些年我們學過的計算機網路與Docker網路-宿網篇(3)
有了Switch終於解決區網問題,同一區網的好碰有終於可以一起打世紀`但人終究是感情的動物整天網內互打會傷害友誼的,更何況我們又沒黨證整天網內互打並沒有好處可以撈,`那該怎麼辦呢?收山不玩遊戲了?當然不是,解決方法就是槍口一致對外,跑到Internet世紀帝國戰網團結一致一起打路人就行啦!
為了將我們的電腦連到Internet還需要一個網路設備Router路由器,Router會透過Port記住該封包是來自區域網路的哪台電腦並將封包的Source IP改成學校派發給宿舍的公有IP再發送到Internet中,同理來自Internet的封包也會經由相同的port返回對應的區域網路電腦,這種技術就稱為NAT網路位置轉換,舉個栗子,例如Router幫來自小明電腦的封包設為9487Port,這樣就算宿舍裡有9999人只要是從Internet發給9487 Port的封包,Router都會把他轉到小明的電腦,這裡再順道一提`那些年Router是非常昂貴的玩意,不像現在隨便幾千塊就有一台`,**所以Linux內有個Tool叫iptables可以把一般的電腦變成大型路由器,這個技術非常重要因為日後K8s就把這種技術發揚光大**,`它就是目前分散式AI系統在K8s中最高效的容器網路介面Calico的底層方法`,更詳細的內容我們會在Calico的章節詳細說明。
**網路小學堂:**
這裡再聊一個問題網路卡的MAC不是全球唯一嗎?為何不直接用MAC通訊還要分甚麼區網IP公網IP再換來換去,多一層轉換不是會造成效率損失?用IP是因為IP是有階層的,比如下圖屬於0開頭就是ClassA,10開頭就是Class B,140.118開頭就是天大地大台科大的,140.116開頭就是成大的,又比如說你寄信如果寫寄給J12345678那郵差不就得要登入全國戶政系統看J12345678住在哪?如果你寫台北市永和區中和路123號,信就會先發給台北市郵局再轉給永和區郵局再轉給負責中和路123號的郵差,這樣層層分級速度會快很多,也不需要一塊龐大記憶體記住所有設備的MAC位置。
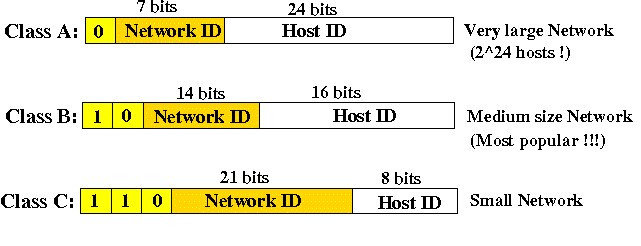
(圖片來源:http://www.mathcs.emory.edu/~cheung/Courses/455/Syllabus/4b-internet/IP-addressing2.html)
**網路小學堂:**
那你可能又有個疑問既然IP那麼好用,幹嘛還要MAC,因為在OSI模型中MAC在第二層,IP在第三層,如下圖,在區域網路中使用MAC定址可以減少網路封包封裝與解封裝的次數畢竟少一層嘛,而且從成本上考量;二層設備Switch的工程技術難度與價格遠低於三層設備Router,至少今天還沒有公司可以挑戰Cisco Router王者地位可見Router的工程難度。好!複習完那些年我們學過的計算機網路,明天開始我們就要把這些東西應用再Docker的網路。
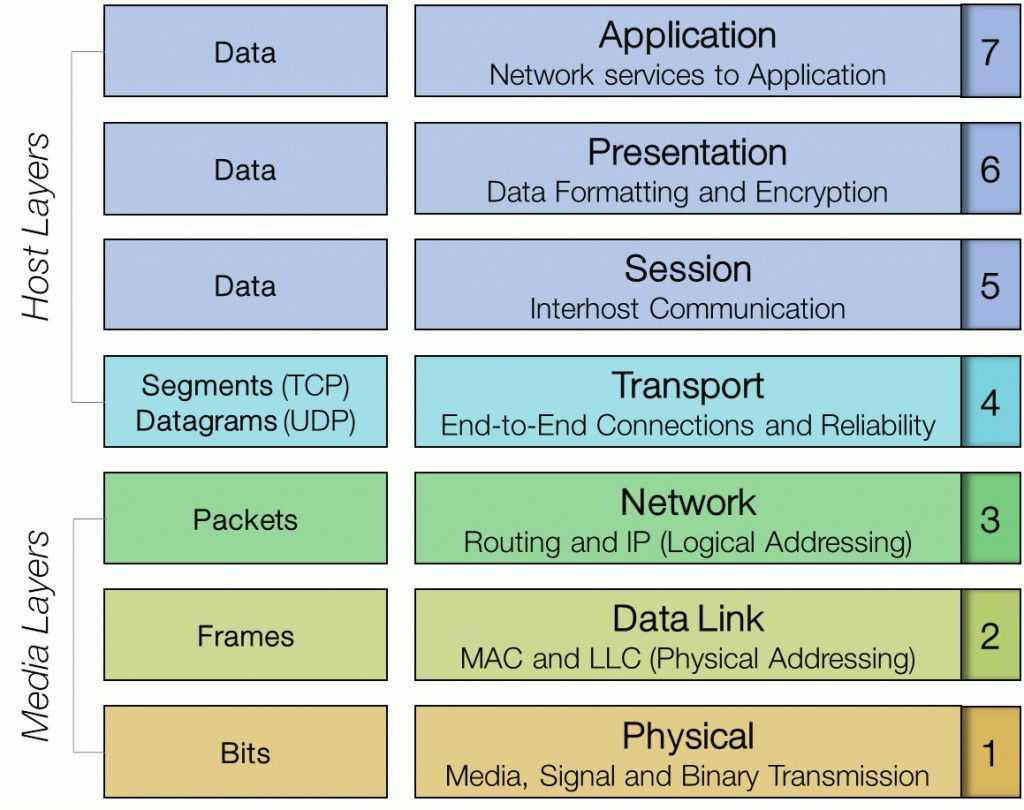
(圖片來源:https://www.coengoedegebure.com/osi-model/)
### 參考:
1.那些年的網路課本
2.趣談網路協定
3.http://www.mathcs.emory.edu/~cheung/Courses/455/Syllabus/4b-internet/IP-addressing2.html
4.https://www.coengoedegebure.com/osi-model/
# 那些年我們學過的計算機網路與Docker網路-Docker基礎篇(4)
如同我們在Day3展示,啟動docker後,會出現dockerd(docker daemon)程序幫我們啟動Docker0,而Docker0作用是充當網橋Bridge連接其他docker container,Bridge是甚麼呢?根據Andrew Tanenbaum 大師說法: “交換器Switch是「現代橋接器Bridge」的另一個名稱。其中的差異是行銷手法多於技術因素”,`所以這個Docker0其實就等同以前我們宿舍網路中的Switch`,這樣我們就可以在Docker中安裝世紀帝國來場網內互打,額!我是說安裝DB與Backend Server互相連線。

當然這樣還不夠的作為一個Backend Server當然要接受來自Internet的封包,要怎麼接收網路的封包,就像我們前面例子說的Router幫小明指定9487Prot所有從9487Prot進來的封包都會被Router丟給小明,同樣的我們也綁定一個port到宿主物理機上作為接口,這樣從宿主機80Port進來的封包都會被丟到eth0網卡再轉到Docker1-Backend Server的8080端口,反之從Docker1Backend Server 8080端口出來的封包也會被丟到宿主物理機eth0網卡在透過80端口再發向Internet基本上跟我們前面講的NAT原理是一樣的。只是這裡宿主物理機用iptables充當Router做NAT。
**Docker container小學堂:**
在Day3我們有證明過Docker container只是OS的一個特別程序,對Linux系統而言container也不是甚麼新鮮概念!,Docker container背後所使用的技術cgroup出現於2007年;Nnamespaces更老出現於2002年。
* cgroup
* 資源限制:CPU,Memory,Virtual Memory,例如給予0.5 CPU,1GB Memory
* 優先級:用來控制哪先程序可以優先被執行,在K8s中我們甚至可以決定當資源不足時那些程序可以先被停止
* namespaces
* 給予一個單獨空間
* PID:在namespaces內我們可以給予程序獨特的PID,像Docker container內第一個程序PID永遠是1
* 網絡:在Docker container內可以有獨立的網卡與網路管理
* Mount:可以Mount自己的文件系統/library
**Container 安全性:**
在Day3最後我們有問為何在Docker container一些系統指令不能執行,例如:更改時間,因為"時間"是無法被namespaces隔離的資源,物理宿主物理機上所有的Docker container都會共用同一時間,很多資源是無法被namespaces隔離這也是許多資訊安全專家說Docker container是不安全的原因,比如:駭客透過某種侵入一個不重要的Docker container並以神奇手法透過該Docker container修改了宿主物理機的時間,導致OS產生不可預知的錯誤後加以攻擊,所以一般公有雲廠商給你的Container 都是放在VM的GuestOS上而非物理機的HostOS;以保證安全性當然也帶來相對的性能損耗。
### 參考:
1.https://philipzheng.gitbooks.io/docker_practice/content/introduction/what.html
2.https://www.docker.com/
3.Docker基礎知識之namespaces,Cgroup
4.https://zh.wikipedia.org/wiki/Cgroups
5.https://en.wikipedia.org/wiki/Linux_namespaces
6.K8s神人張磊
# 那些年我們學過的計算機網路與Docker網路-Docker問題篇(5)
然而Docker預設的網路模型有兩個很大的問題
* 問題1: 多節點間網路消耗很大,基於NAT
* 問題2: 端口Port會很亂難管理
* 問題3: 不auto與開箱即用
**首先我們先看問題1**
在單節點的情況下我們可以很容易且低消耗的通過Docker0網橋進行跨Docker Container間的通訊,走二層網路每個Docker都有虛擬網卡配有MAC地址,但現在的AI任務常需要多節點共同運算;像吳恩達,Jeff Dean做個辨識貓的AI任務就花了16000顆CPU很明顯這16000顆CPU不會在同一台物理機裡,同時有時候我們也會需要如NoSQL這類型的分散式DB,或者我們需要提高backend service的HA可靠度於是將backend service打散在多個節點上,那在Docker的網路模型下該怎麼通訊呢?
`我們以Spark為例,現在有三個Spark Executor分佈在兩台節點或宿主物理機上,假設現在Node1上的Spark Executor1要跟Node2上的Executor3進行通訊,它們網路會長這樣子的Spark Executor1的Port :7070對應到Node1的Port :12345,Spark Executor3的Port :7070對應到Node2的Port :12347,這邊特別說明一點TCP底下Port是不能重復使用的所以Spark Executor2綁定在Node1的Port必須跟Spark Executor1不一樣。(如下圖)`

接著我們來仔細探討數據封包是如何被傳送的,Spark Executor1要發出一個TCP封包給Spark Executor3,一開始封包的Source會寫172.17.0.2:7070這是Spark Executor1的IP與Port;而Destination會寫Spark Executor3所在Node2的IP與對應的Port:12347(不是7070喔),透過Docker0封包會轉到Node1的eth0網卡。(如下圖)

`這時eth0收進封包進行NAT機制;因為Spark Executor1與Spark Executor3屬於不同區域網路且私有IP重疊`,Node1會修改封包Source IP為Node1本身的IP:1.1.1.1與對應的外部Port:12345(不是7070喔),就像我們Day17宿網篇講的Router幫小明的外部Port設成9487原理一樣。(如下圖)

>接著Node1再把封包丟給Node2的eth0網卡,Node2看到封包Destination的Port是12347就知道是給Spark Executor3的,於是Node2會再進行一次NAT修改封包Destination IP與Port為Spark Executor3的IP與Port即是172.17.0.2:7070,Source改成node2的IP與對應的外部Port即是2.2.2.2:12347,最後封包丟給Docker0網橋,Docker0網橋看到Destination=172.17.0.2:7070就會再丟給Spark Executor3這樣一次數據傳輸就完成拉!。(如下圖)

大家有沒有看出這個過程有很多問題!基於時程安排明天繼續(其實是小弟肚子裡墨水不夠怕撐不到30天XD)。
### 參考:
1.https://x.company/projects/brain/
2.趣談網路協議
3.http://spark.apache.org/docs/latest/running-on-kubernetes.html
4.https://en.wikipedia.org/wiki/Network_address_translation
# Days21那些年我們學過的計算機網路與Docker網路-Docker問題篇(6)
我們繼續昨天的問題兩個AI Task分散在兩台Node它們之間通過我們以前宿網玩線上世紀帝國相同的NAT方式互相連線,根據昨天提到的三張封包變化圖或見下圖,`我們會發現封包的Source IP與Destination IP被改變了三次`,依據OSI模型我們知道IP是封裝在Layer3,如果Router要改封包的Source IP與Destination IP它得解開Layer1封裝, Layer2封裝, Layer3封裝,才能修改IP接著Router在依照順序把Layer3, Layer2, Layer1封裝回去,`這些動作會消耗龐大的網路效能`,而且這個動作必須做兩次,順道一題眼尖的同學還會發現Spark Executor1與Spark Executor3的私有IP是一樣的;如果要讓私有IP不重疊得修改docker的config,但這會造成另一個問題。

接著回到主題;做了那麼多封裝解封裝這基本上是非常浪費計算機資源的,更別提Deep Learning演算法常有幾百個Task幾億個參數傳來傳去,光傳參數這動作就可以打癱瘓網路了,`而且Spark只支援Sync參數更新模式,沒有PS參數伺服器設計且所有事都是Driver做比如:主程式執行,與K8s間資源請求,子任務執行狀況監控,任務分配,參數收集,參數更新"廣播"`,總之負責Driver那塊的網路設備壓力之大可想而之!
>**網路小學堂:**
為何區域網路內都用MAC定址而非IP,就是因為MAC在二層可以減少封裝解封裝次數提升整體網路性能!
**接著我們探討Docker網路模型的問題2: 端口Port會很亂難管理**
這面這張圖,Spark預設端口是7070但Docker對應到宿主物理機後端口會變化,端口Port應該是由網管/維運/資安人員規畫,而不是Dev人員想用就用,更何況不是預設端口程式很容易出錯,加上Container的核心就是標準化固定化,用NAT的方式等於得讓Container去適應外部的變化,比如Spark Executor1必須知道Spark Executor3的端口改成12347而非預設7070封包才到的了就像那上圖中的Package A1:Destination是2.2.2.2:12347,這樣就違反Container的核心標準化固定化的精神了。

**問題3:不auto與開箱即用**
Docker Network預設的網段是172.17.0.0/16,同時他家的DHCP服務預設Docker1的私有IP是172.17.0.2,大概只有Docker的前身DotCloud這種PaaS會需要到/16那麼大的網段,如果你要縮小網段或是使網段之間不重疊”以節省網路資源”(原理等有空再補:D)就得手動更改config檔,但這樣就不auto拉!作為一位DevOps當然希望東西是開箱即用不用在那邊config改來改去。
### 參考:
1.那些年的網路課本
2.趣談網路協定
3.https://blog.csdn.net/zpf336/article/details/83006569
4.https://en.wikipedia.org/wiki/Encapsulation_(networking)
5.https://en.wikipedia.org/wiki/Network_address_translation
# 故事時間: 話說當年Google對付Docker的文化滲透戰
雖然Docker方案還存在許多問題但Docker公司並不在意,`它正在進一場驚天計畫只要成功就能把一位四皇拉下來`,它就會成為跟AWS,MS,Google,FB齊名的公司,這個計劃就是Docker Swarm。今天是鐵人賽第22天了,想必大家看了一堆技術文章也累了,剛好DevOps組有個Culture主題,我就藉此名目來講當年雲容器管理系統的`"文化洗腦戰"`內幕,看看Google如何透過`文化洗腦使K8s成為容器編排系統唯一標準。`
其實你若回到時間點當下其研究K8s與Docker Swarm的競爭,從技術觀點還真看不出來誰會贏;畢竟Docker除了自己還有Hortonwork還是這種已經在美股NASDAQ(那斯達克)上市的"硬底子"軟體公司支持,加上眾多的貢獻者,`技術層次其實是難分軒輊,但不管是Hortonwork還是Docker他們的文化影響力與行銷功力完全跟Google不在同一個等級。`
回顧一下2014,`這時Docker公司已經不滿足定位在container方案提供應商與PaaS商`OS:我不想當小船長我要當海賊王!,首先是把他們起家厝Dot Cloud賣掉,集中公司資源準備一場顛覆矽谷與整個世界IT領域生態的計畫,這個計畫一但成功Docker公司將成為與矽谷科技巨頭Google,AWS,MS,FB平起平坐的軟體科技公司,Solomn Hykesc則會得到與Linux創造者Linus Torvalds一樣的歷史地位, 這個計畫就是Docker Swarm。
這個計畫一推出立刻得到眾多新創廠商支持,`甚至得到Hadoop三隻獨角獸之一的Hortonwork的支持,準備將整個Hadoop Ecosystem搬上Docker Swarm打造一個前無古人後無來者的史詩級超級AI平台`,有了Hortonwork萬台節點管理經驗與眾多新創與開發者支持,`Docker公司離矽谷科技巨頭幾乎只剩一步之遙`,**`可惜理想是豐滿的現實是骨感的`**,Docker做錯了最致命的一個決策; Docker Swarm僅支持Docker容器不支援其他容器如:CoreOS的rtk容器,這也就是說Docker公司背叛了它的早期堅定盟友CoreOS/RedHat,Google高層知道Docker這個決定後露出一抹神秘微笑並宣布開源參考於自家Omega系統的K8s容器調度系統表示此系統會支援rtk,用以拉攏CoreOS/RedHat還有與RedHat淵源甚深的Linux基金會加入,`作為對Google的回報CoreOS/RedHat也立刻貢獻K8s最重要的的組件之一即Flannel容器網路模型也是目前K8s預設的網路模型。`
* 序曲
一場世紀大對決就此拉開序幕,面對Google與CoreOS/RedHat聯軍進攻,`Docker公司一點都不畏縮,Docker公司曾經在PaaS領域耕耘多年,同時Docker已成為container唯一標準這等於全世界的Dev都是Docker的盟友,對Docker的信仰早就深入每一位Dev的骨隨,而且許多錯過Google,AWS,FB崛起的創投紛紛都站在它這邊,這些創投比Docker更期待Docker成為海賊王`;回報他們給超過千倍的報酬,所以Docker有錢(創投)有人(全世界的Dev)有經驗(它是PaaS領域老公司),然而薑還是老的辣,Google不僅有Jeff Dean這種工程神話人物,對Google高層而言;`K8s更是他大AI/Big Data計畫中的最重要一塊版圖`,如果連Docker公司這種等級對手都解決不了別談撼動Apache Hadoop Ecosystem!,所以是Google高層是吃了砰陀鐵了心要集中一切資源徹徹底底的讓Docker Swarm消失在人們心中。
`這時候的Docker眾人還沉浸在Docker Project成功之中,他們雖然知道大鯨魚在對付他們,但大鯨魚每年執行的Project有成千上萬件到底能分出多少資源給K8s,而且就算只剩半壁江山對Docker這種小蝦米而言也是科技史上無前例的空前巨大勝利!`,然而他們不知道的是Google舞劍意在Apache Hadoop Ecosystem,Docker是進攻Apache Hadoop路上一定要徹底碾碎的石頭,同時Google老早暗度陳倉借CoreOS/RedHat之手把工程大軍開進關中了。接下來就吃瓜等Docker CTO Solomn Hykesc在烏江邊自殺了(離職)。
> 歷史小學堂:關中,即長安附近,在明代以前是各朝代的首都位置,關中平原四面環山有眾多險峻關口可防守,如:知名的三英戰呂布的虎牢關,然而關中平原內無險可守,所以一旦敵方大軍進入關中平原就代表一個朝代的滅亡。
* 文化洗腦之行銷戰
**`作為老牌廣告公司Google在行銷上(文化洗腦)的功力可不是蓋的,成立CNCF基金會以無限銀彈開始鋪天蓋地的行銷(文化洗腦),到處辦講座到處開研討會連學校與各種學術組織也進行滲透,比如大陸K8s頂尖高手張磊就是在學校裡被吸收成K8s專家,而且Google並沒有排除docker container技術,反向選擇借力使力,透過docker container打倒docker Swarm。`**
史蒂夫和戴夫都用CNCF追蹤docker container技術。史蒂夫鑽研最新docker container技術,戴夫精研如何成為最有效率的追番。史蒂夫 follow 大神 twitter 動態,掌握最新docker container消息。戴夫關注最新的貓咪影片。史蒂夫為極具潛力的container技術建立了關注列表,戴夫也有關注列表。為什麼史蒂夫和戴夫一樣是container高手?因為戴夫選擇報名了CNCF的年度大會,自動與世界潮流接軌。每當史蒂夫當講者時,戴夫都報名參加(繼續追番)效法史蒂夫成為docker container高手!
大家好我是Spark,你有沒有覺得管理docker container很難,或者不知道去哪學習更好的docker container管理技術,比如:你覺得docker swarm有很多缺點卻不知道如何改進,讓我來告訴你吧!今天我想用一分半鐘的時間來跟大家來分享一個超酷炫的docker container管理研討會,在CNCF舉辦的docker container管理研討會你可以吸收各種docker container管理知識,在CNCF研討會你可以跟全世界的docker container專家交流!CNCF研討會的實作教學也很簡單,只需要操作K8s即可解決全部關於docker container管理的儲存/網路/計算...資源管理問題!,接下來我來示範怎樣買CNCF研討會的門票!
* 今天
在2019的今天雖然rtk技術已經被CNCF基金會放棄但CoreOS已經完成了它的歷史定位,而它的母公司RedHat也被IBM砸1兆台幣併購完成一場傳說級的華麗轉型,相對的Docker Swarm失敗後Docker CTO,CEO相繼離職,Hortonwork陷入虧損最終被Cloudera(Hadoop生態系最大的獨角獸)合併永遠的消失在矽谷科技舞台,讓我們紀念它;Hortonwork沒了以後Hortonwork CEO跑去當Docker CEO,喔對了Hortonwork是Google的老對手Yahoo!班底創立的,讓我們再次紀念它,有沒有一種矽谷內派系鬥爭真恐怖動不動就要人家倒閉員工失業,好可怕啊!
### 參考:
1.磊哥爆的掛
2.作者的腦洞大開與在混跡Data/K8s領域時聽到的消息
3.https://www.youtube.com/watch?v=khMkrSjDmYc
4.Docker傳奇之Dot Cloud
# DevOps Culture與如何成為一位DevOps!
~~這兩天討論~~真實的DevOps的文化與Google的K8s深層文化洗腦戰法,邦友說想知道更多DevOps內幕,那我們再來講更多關於DevOps爆笑(辛酸)日常文化!,`最後會附上看了那麼多DevOps內幕文化依然要成為DevOps勇者,的`~~屠龍攻略~~`成為DevOps攻略`。
* 日常文化(一):
```
有一天小哥在湖邊砍柴,湖中突然出現一個新上任荷蘭籍副總女神
新上任荷蘭籍副總女神:那位小哥你掉的是金斧頭(Dev),還是銀斧頭(Ops)
小哥:我的斧頭(DevOps),在手上阿,我沒掉斧頭!
新上任荷蘭籍副總女神:你很誠實,我決定把三把斧頭(Dev, Ops, QA)都送給你,讓你獲得不受勞基法約束的神力,可以日以繼夜的工作沒有加班費!
小哥:啊啊啊~不要阿
```
* 日常文化(二):學校與公司的差異
```
學校老師:各位同學面對這問題我們要如何解決?
#同學:找人(DevOps)來解決問題
新上任荷蘭籍副總女神:各位同仁面對這問題我們要如何解決?
#同仁:解決提出問題的人(DevOps)
```
* 日常文化(三):某美國外商公司DevOps文化
```
新上任荷蘭籍副總女神:PM你上次找來的"忘了叫啥名子"的全端很不錯,幫公司節省了1個人力
#PM:感謝副總讚美
新上任荷蘭籍副總女神:最近有沒有新的cost down方法?
#PM:有阿~最近很流行DevOps
新上任荷蘭籍副總女神:那啥?說來聽聽
#:巴拉巴拉巴拉
新上任荷蘭籍副總女神:喔!我明白了就是能同時負責Dev, Ops, Qa的工程屍阿!這樣一次能節省更多人力!還不趕快找幾個進公司。
#PM: 遵命!
新上任荷蘭籍副總女神:對了,上次去部門走動管理時,見那些"我忘記名子的工程屍",都一副要死不活的模樣,弄點糖果/飲料/派對給他們,小朋友麻!你知道的需要哄一下
#PM: 沒問題,工程屍都難以溝通的,該辦些派對訓練一下他們表達能力,順便開些桌游吧!桌游可以強化邏輯,他們的邏輯都很奇怪!
新上任荷蘭籍副總女神:很好,剩下的你來處理,我先去研究企業戰略
#:副總您慢走,我一定弄最美式的公司文化,提升吸引優秀DevOps工程屍!
```
* 日常文化(四):面試職務
```
#PM:所以你開發還行吧
面試者:會寫NodeJS語言支援開發部門與Linux Script做些日常處理
#PM:喔!那很基本,那有維運經驗?
面試者:當K8s管理者兩年多,不過我們都用EKS,GKE,AKS居多,自建K8s到沒試過
#PM:恩,NoSQL/SQL的災難復原與轉移都會吧!我們公司資料很重要不能掉的!
面試者:啊我只會下SQL,其他是DBA負責的
#PM:嘖!那網路呢? CCIE有嗎?網路封包解析工具會用嗎?雲端整體規劃熟嗎?數據處理呢?大數據,AI有多少理解?
面試者:大哥你是不是拿錯面試清單拉,我不是來面試"總工程師"的!
#PM:甚麼總工程師?我是在面試DevOps,現在連小學生都在寫AI你竟然不會?你會甚麼你自己講好了。
```
* 日常文化(五):萬事達卡公司倒閉
```
在2050的某一天,萬事達卡公司宣布倒閉,因為出現了一種"萬事皆可作做,唯有情無價"的神秘DevOps生物取代了他們!
```

(圖片來源:萬事達卡)
* 日常文化(六):春聯篇
```
上聯:做好做滿下班晚
下聯:錢少事多被離職
橫聯:你才DevOps,你全家都DevOps!!!
```
* 日常文化(七):三隻小熊勝過一位臭皮匠

* 日常文化(八): 定義差異
`我們定義的DevOps,不重要所以說一遍即可`

`新上任荷蘭籍副總女神定義的DevOps,很重要所以要說三遍`
`新上任荷蘭籍副總女神定義的DevOps,很重要所以要說三遍`
`新上任荷蘭籍副總女神定義的DevOps,很重要所以要說三遍`

### 如何成為轉職成一位DevOps!
**參考至:How to transition into a career as a DevOps engineer:**
建議具有一定Dev或Ops能力的工程師閱讀,很少有公司會願意培訓剛畢業新人; 畢竟沒有外國老闆會花錢請只會CI Tool工程師,`而且培養在Dev,Ops與DevOps領域都有一定實力員工非常漫長。`
* Base Know how
* 計算機原理
* Ubuntu/Centos/Alpine基本操作, 作業系統原理, Linux script , 網路原理
* Docker Commend, Docker file
* CI/CD Tool
* Ansible, Gitlab CI, Circle CI...
* Programmer Skill
* 物件導向/函試編程, Restful API, 熟悉一門語言:
* GO, (推薦,學習曲線平滑,Google當靠山,熟了以後可以看看K8s的程式碼!如果你有空的話...)
* JAVA (老牌OO語言!值得擁有)
* C++ (真男人的硬核選擇,我精神上支持你!)
* Python (隨緣)
* Infrastructure Manage
* Cloud
* Clood基本知識:IAM, VPC, LB, 53, Storage Level, ServiceAccount...
* 都上雲了卻不用container,那為何不直接跟ISP租VM就好?而且便宜非常多!
* 都用container卻不用K8s好奇怪,而且公有雲廠商已經幫你處理掉K8s底層問題,我們只要專注上層應用!
* ~~傳統機房~~
* 不推薦!產業在衰退,資訊管理出來都快沒工作了!你還去跟他們一起擠?
>Linux小學堂:
Alpine Linux 是一套極小安全又簡單的作業系統,其大小僅4.79MB,是非常熱門的docker image選項,它不屬於Dpkg(apt)或RPM(yum)體系,必須使用獨特的apk --update add 安裝套件。

### 參考:
1.作者的腦洞大開
2.https://opensource.com/article/19/7/how-transition-career-devops-engineer
3.https://shareidea0103.blogspot.com/2019/05/blog-post_25.html
4.https://blog.wu-boy.com/2015/12/a-super-small-docker-image-based-on-alpine-linux/
5.https://www.alpinelinux.org/
# Flannel篇(上集)那些年我們學過的計算機網路與K8s網路
Day22的Google與Docker的文化戰講完了,接下來我們來看這個,看似普通卻默默影響整個矽谷歷史的K8s預設網路容器介面Flannel。
前面我們花了六天講解的Docker網路模型的缺陷,`Google給的策略是"扁平化網路",什麼是扁平化網路?`,`再說扁平化之前我們要先來""複習那些年我的學過的網路原理""`,一個網路IP分成兩個部分,NET ID(網路位)與HOST ID(主機位),以Class A為例,它有2^8=256個NET ID,而每個NET ID有2^24=16777216-2個HOST ID,NET ID就像大樓總門牌,比如:101大樓的總門牌是信義路三段147巷5弄7號,而HOST ID就是101裡面每個房間攤位的代號,比如:鼎泰豐在B1西區66櫃。
>**網路小學堂:**
為什麼每個每個NET ID(網路位)的HOST ID(主機位)的數量要減2呢?因為其一代表網段本身位置,其二代表廣播位置,就是這樣樸實無華且枯燥。

`而Google所說的扁平化意思是指我們不要一棟101了,我們要101間平房`,每間平房都配有一個IP地址,當一個封包出來我們看IP地址就知道Task是在哪個平房/節點上,而每間平房裡房間很少,進了平房一眼就能看到目標container,而不是進了101以後,再以101層都能聽到的聲音大吼(廣播broadcast)!鼎泰豐您在哪?然後鼎泰豐在以101層都能聽到的聲音(廣播broadcast)回答我在B1西區66櫃,回想一下我們再Docker宿網篇有提到以前大學宿舍為了省錢都用HUB,但HUB只會廣播(broadcast)`所以一有人上傳下載那些年我們一起追的蒼井空就會造成網路癱瘓`,所以縮小廣播範圍從整棟101到小平房可以大大提升網路效能。
當然真實雲端網路跟上面舉的例子是不一樣的雲端沒再用HUB,而且Docker內部是用Docker0當Bridge轉發訊息,Switch就是現代版的Bridge;他們都是有腦子的網路設備,轉發訊息時不需要廣播而是準確發送到對應container網卡的MAC地址,`但是當有新Docker Container啟動需註冊網卡MAC地址的ARP協議與動態配置私有IP的DHCP協議還是會用到廣播,所以縮小HOST ID數量(變成小平房)是有必要的;其實還有很多狀況會用到廣播`。
更重要的一點沒有一台物理機器可以容下/16,也就是2^16=65536個Task在同一台物理機裡,只有Docker前身Dot Cloud這種PaaS公司會有這種需求在一台物理機內跑2^16=65536個Task(參考[Day3](https://ithelp.ithome.com.tw/articles/10214958) Docker公司發明Docker的真正目的)。
>**網路小學堂:**
Docker的/16與K8s中Flannel的/24,到底是甚麼意思呢?首先我們要知道私有網段有三個
`10.0.0.0~ 10.255.255.255`
`172.16.0.0~ 172.31.255.255`
`192.168.0.0 ~ 192.168.255.255`
以Docker預設172.17.0.0/16來說前16碼是網路位(NET ID),後16碼是主機位(HOST ID),表示每個私有網段/區域網路可以容納2^16=65536-2個虛擬IP,假設現在有間公司有三個部門IT,財務,人資,`如果我們把三個部門都放在172.17.0.0網段可能發生IT部門網路高手去監控人資與財務的網路封包,於是我們要把172.17.0.0私有網段再拆成三個互相隔離的私有網段/區域網路`,而2^2=4大於3所以我們將網路位(NET ID)增加2位,而主機位(HOST ID)當然必須縮小2位,所以變成以下四個互相隔離的私有網段/區域網路
```
172.17.0.0
172.17.64.0
172.17.128.0
172.17.192.0
```
>在選其中三個分別配置人資/IT/財務,而這個技術就叫CIDR(無類別域間路由),`然而現在又有一個問題如果給你兩組IP:172.17.0.1, 172.17.64.1你要怎分辨它們是否在同一私有網段/區域網路裡面?有沒做過CIDR?所以我們用"/"符號去表示網路位(NET ID)有幾個還有是否做過CIDR。`
>**舉個栗子:**
在/16的情況(CICR前)172.17.0.1, 172.17.64.1它們在同一個私有網段/區域網路裡
在/18的情況(CICR後)172.17.0.1, 172.17.64.1它們在不同私有網段/區域網路裡
OK,我們回來Flannel,它將Docker的/16改成/24也就是說網路位(NET ID)有24位;主機位(HOST ID)32-24=8位,所以每個私有網段/區域網路可容納的2^8=256-2個IP給container,`同時將每個私有網段/區域網路分配在節點/物理機上`,如下圖。

`更重要的一點因為被切成不重疊的私有網段/區域網路所以所以節點/物理機之間不再需要NAT就能互相通訊,但還是需要些簡單路由轉發`,而不像Docker1預設的IP永遠是172.17.0.2造成IP重疊得用NAT方式解決如下圖Day19展示的狀況

**結語:**
解釋完Google扁平化的意思與Flannel的網路基本原理還有那些年我們學的網路原理,明天我們再來講Flannel在工程上實踐方式。
### 參考:
1.趣談網路協議
2.CCNA++2019
3.https://zh.wikipedia.org/wiki/%E4%B8%93%E7%94%A8%E7%BD%91%E7%BB%9C
4.https://www.ionos.com/digitalguide/server/know-how/cidr-classless-inter-domain-routing/
5.http://beej-zhtw.netdpi.net/07-advanced-technology/7-6-broadcast-packet-hello-world
# Flannel篇(中集)那些年我們學過的計算機網路與K8s網路
前面說完Google扁平化網路策略,再來講CoreOS實踐Flannel的三個模式
1. UDP
2. VXLAN
3. host-gw
我們先談UDP模式,首先Flannel會先在宿物理主機上,啟動一個flanneld的程序,這個程序會打開一個TUN的字符設備創造一張虛擬網卡flannel1或是flannel0, flannel1或是flannel0的工作是在OS kernel mode與user mode程序間跑layer3的虛擬網路傳送封包。

(圖片來源:趣談網路協定)
當container A發起一個網路封包要給container B,container A區域網路內的Docker0 Bridge見到此封包,會解封包看是否是同一個區網很明顯的A屬於172.1.8.1/24網段而B屬於172.1.9.1/24網段,`不是同一區網,這時Docker0 Bridge開始匹配路由規則發現要去172.1.9.1/24網段必須透過flannel1網卡`,於是將封包封給flannel1網卡,flannel1網卡收到封包會再跑layer3的虛擬網路傳送封包到flanneld,`flanneld再將封包使用UDP封裝,接著等待mode切換,等切換到kernel mode時則執行特權指令讓宿主物理機eth0網卡發送封包進實體網路`。
>**網路小學堂:**
>為啥flanneld是用UDP協定而非TCP協定呢?首先TCP標頭檔比較肥大,而且需要執行三項交握還得建立長連接,更重要的是會佔Port,而UDP都沒有以上缺點,這時好奇的朋友會問用UDP掉封包怎辦?基本是只要源頭Container使用TCP協定,就算發生了掉封包,原來的Container的TCP監控程式也會反覆發送封包!所以flanneld不擔心掉包問題
接著物理機A的eth0網卡與物理機B的eth0網卡是屬於同一私有網段/區域網段即192.168.100.0/24,所以直接走Layer2,網卡對網卡發送封包即可。
>**然而此模式存在一個問題:**
因為經過三次user/kernel mode轉換與加上Flanneld(flanneld daemon)是user mode等級process,如下圖,所以會產生大量context switch與mode切換等待,所以Flannel UDP模式效能很差,我們明天介紹改進版Flannel VXLAN模式!

(圖片來源:http://bamboox.online/k8s-12-flannel.html)
### 參考:
1.CCNA++
2.K8s神人磊哥
3.那些年我們一起讀的網路課本
4.網易雲服務首席架構師劉超
5.http://bamboox.online/k8s-12-flannel.html
6.https://rancher.com/blog/2019/2019-03-21-comparing-kubernetes-cni-providers-flannel-calico-canal-and-weave/
# Flannel篇(下集)那些年我們學過的計算機網路與K8s網路
好昨天我們講到CoreOS的Flannel UDP模式如何樸實無華且枯燥的解決container跨物理機通訊的問題,我們繼續講Flannel VXLAN模式 。
VXLAN過程跟UDP模式很像,但VXLAN在Linux Kernel process就有實作VTEP(VXLAN Tunnel Endpoint )也就是說`不像UDP模式flannel1/flanne0虛擬網卡還得透過虛擬layer3路由將封包丟給"flanneld",接著flanneld因為是屬於user等級process所以必須等待進入Kernel mode再將封包發給物理機實體網卡eth0再發向實體網路`,還有VTEP算是Kernel等級process非user等級,所以它也省去mode切換的等待時間,所以效能比UDP模式好很多!

(圖片來源:趣談網路協議)
首先VXLAN透過netlink告訴物理機Linux kernel建立一張VTEP的虛擬網卡flannel1,當flannel1收到來自docker0的封包時處理與上一章說的UDP模式也不一樣!`它現在是VXLAN的Endpoint,來源MAC會寫物理機A的網卡flannel1 MAC地址,目標MAC寫物理機B的網卡flannel1 MAC地址,在包上VXLAN的標頭檔`,同樣的為了避免的TCP的缺點我們還是選UDP發送這個封包。
`然而UDP是封裝在OSI 的Layer4,所以我們必須補上OSI 的Layer3的IP地址,不過我們沒有打算用IP來定址,畢竟我們在Day19就解釋過為什麼區域網路要用MAC定址而非IP定址,所以在最外層還是得補上物理機A的MAC`,有一點非常特別這裡只需要物理機A的MAC不需要B的MAC,因為封包流到能處理VXLAN的網路設備後,能解析VXLAN標頭的網路設備就會直接看VXLAN的標頭,直接將封包發網物理機B的flannel1網卡的MAC地址,所以它不需要物理機B的MAC,`等於兩個物理機A/B的flannel1被VXLAN虛擬在一個區域網路內;`當然flannel1也是VXLAN叫Linux kernel創造出來的虛擬網卡。
* **用VXLAN模式雖然比UDP模式高效,畢竟有了Linux kernel支援;少了很多模式切換與context switch,效能提高很多,但還是有缺點:**
1. 為了做隧道整個封包被封裝的太複雜了,如下圖,導致出了問題難定位難以工人智慧分析,好wireshark不用嗎?

(圖片來源:calico新手試用心得)
2. 你需要支援VXLAN的網路設備與高階網路專家來設定設些設備,這些專家薪水可高了,根據wiki顯示CCIE認證出現23年(1993~2016)來以來全球才累積51500位CCIE專家,而光2018年就有2.24萬位AI高手在頂級ML會議發表過論文,`足可見高階網路專家稀缺程度不亞於現在最夯的AI`。兩者都有一定水準的更是鳳毛麟角大概類似Jeff Dean大神這種等級,娘子快跟牛魔王一起看上帝。
* **為了改進上述兩個缺點於是出現了**
1. layer3路由方案`Flannel host-gw模式`與K8s layer3路由方案王者`calico方案`;這是一個純三層解決方案只做路由不做隧道,封包單純;出問題分析起來較容易,且使用Linux內建iptables非常高效率,在那些年的宿網篇我們有提過早年在連一般等級Router都很貴的年代,人們會用Linux的iptablesr將計算機/個人PC充當Router,明天我們先介紹Flannel host-gw 模式。
2. `我們花了那麼多篇幅講網路,一切都跟DataOps有關,就像在Day2說的一個簡單的VGG16 CNN模型就有1億3千萬個參數必須在眾多worker與parameter server/driveer傳遞;所以我們需要更高效且簡單的K8s CNI的方案!。
### 參考:
1.K8s神人磊哥
2.那些年我們一起讀的網路課本
3.網易雲服務首席架構師劉超
4.Calico新版上手體驗
5.https://itnext.io/an-illustrated-guide-to-kubernetes-networking-part-2-13fdc6c4e24c
6.https://rancher.com/blog/2019/2019-03-21-comparing-kubernetes-cni-providers-flannel-calico-canal-and-weave/
7.http://chansblog.com/tag/vxlan-tunnel-endpoint/
# Flannel篇(總集)那些年我們學過的計算機網路與K8s網路
Days26我們了解VXLAN模式雖然可以改進UDP模式效能,但還是有四個缺點:
1. VXLAN還是有20%~30%的效能損耗,這種損耗分散式AI中影響巨大
2. 隧道技術使封包複雜化,導致trouble shooting困難
3. VXLAN需要經驗豐富網路專家支援而這種專家跟頂級AI人員一樣稀缺
4. 小弟瀏覽眾多關於DataOps:AI與K8s文獻發現"容器網路介面CNI"常是造成"分散式AI運算"瓶頸的關鍵,以CNN模型來說,一個簡單的VGG16模型的就高達1億3千萬個參數必須在眾多worker與driveer/parameter server傳遞,所以我們需要更高效且簡單的K8s CNI的方案!
我們希望有基於Layer3路由技術的K8s CNI方案;不要隧道不要複雜的封裝與解封裝降低效能損耗,這就是Flannel host-gw模式,Flannel host-gw模式的概念也很簡單就是直接將物理機變成Router/Gateway,例如:`我們在物理機A加上路由規則要去containerB的網段172.17.9.0/24 必須透過物理機B(192.168.100.101)進去最後補上物理機A實體網卡名稱dev eth0`代碼如下
```
172.17.9.0/24 via 192.168.100.101 dev eth0
```
這樣containerA網段(172.17.8.0/24)就能訪問containerB網路網段(172.17.9.0/24),接著物理機B做相同動作加上對應路由規則,
```
172.17.8.0/24 via 192.168.100.100 dev eth0
```
跨容器網段互訪就完成了,其中沒有了隧道沒有了複雜的封裝與解封裝,不再需要flannel1虛擬網卡做轉發,而A/B物理機的路由表由flanneld(flannel daemon)負責維護,並把所有路由資料存在K8s的ETCD中。
>**K8s小學堂:**
ETCD是由Golang寫的key/value DB,在K8s生態中負責儲存相關service,POD, resource, DNS,路由資料。

根據大陸K8s神人張磊給的數據比起VXLAN模式20~30%的性能損失,在host-gw模式只有10%左右的性能損失,因為少了隧道沒有層層的封裝與解封裝,整個封包有變得乾淨俐落,也容易trouble shooting。
* 然而host-gw模式有很大的限制
1.`它必須待在同一個layer2區域網路`,如果是在同一個underlay物理layer2區域網路是最佳,若是使用overlay虛擬技術去形成layer2區域網路也免不了產生虛擬化開銷,對分散式AI這種依賴網路傳送參數的Task就不太優。
2.因為它沒有實作路由協議與路由器管理協議,物理機一多路由表會很大,`這種(N-1)^(N-1)關係也使得網路拓樸變成很龐大`,導致難管理或是跟Etcd間同步出現問題。

3. 我們檢查了一下GKE(Google雲端K8s服務)預設CNI並非flannel,所以得手動設定host-gw。
* 結論:基於以上3點我們認為Flannel host-gw模式還不夠好,明天要我們介紹K8s layer3路由方案王者`Calico`;Google...雲端廠商有支援Calico同時也是京東與Intel資深工程師在O'Reilly Strata Data Conference推薦的分散式AI運算用的K8s CNI方案。
### 參考:
1.K8s神人磊哥
2.那些年我們一起讀的網路課本
3.Spark on Kubernetes: A case study from JD.com
4.網易雲服務首席架構師劉超
5.https://prefetch.net/blog/2018/02/20/getting-the-flannel-host-gw-working-with-kubernetes/
6.https://rancher.com/blog/2019/2019-03-21-comparing-kubernetes-cni-providers-flannel-calico-canal-and-weave/
# Calico篇(上集)那些年我們學過的計算機網路與K8s網路
我們花了四天徹底的了解Flannel的原理,發現它理論上有不少缺點,事實上在分散式AI實際測試中Flannel,Weave也比不過Calico,接著我們來講Intel,京東的資深工程師與Google…等眾多雲服務廠商都推薦的K8s Calico原理。
`Calico的基本跟Flannel host-gw模式很像`,也是基於iptables將Linux物理宿主機變成Router/Gateway,單純的三層轉發沒有隧道;所以封包簡單而乾淨容易trouble shooting如下圖,`不同點在於Calico有實作路由器管理協議BGP(邊界閘道器協定Border Gateway Protocol),在大規模AI場景中也多了個BGP reflector幫忙管理路由表使之複雜度為O(n)而非Flannel host-gw模式的O(n^n)`,有了BGP reflector;Etcd就不用在管路由資訊了!Etcd已經很忙了;基本上節點數超過一定數量Etcd就會出現問題需要改設定檔,當然如果用公有雲如GCP因為K8s Master與Etcd是Google贈送的包含維護所以不用擔心,PS:省下一名高階K8s工程師的薪水新任荷蘭籍女神副總表示好開心阿!

(圖片來源:Calico新版上手體驗)
>**網路小學堂:**
>甚麼是BGP路由器管理協議,`由於BGP是很複雜的協議`屬於高階網路工程師的Know How所以這裡只簡單介紹一下,假設R集團有R1與R2兩間子公司想要直接互相訪問對方內網(10.0.1.0與10.0.2.0),他們會先跟ISP(EX:中華電信)申請AS號碼,例如:R1子公司是100而R2子公司是200,如下圖1所示,AS全稱是自治系统(Autonomous System)


(圖片來源:CCNA++)
>接著會透過iBGP協議串聯子公司內部路由器,透過eBGP協議連結對方路由器,兩間子公司透過ISP串聯內網就完成了,如上圖2。
好我們回來講Calico,`Calico有一點很巧妙因為全走3 layer路由了`;不再需要layer2區域網路了,所以跟Flannel的/24不一樣,`它貫徹Google的扁平化網路精神變得更扁平直接/32`,整個IP全部都是Days24網路小學堂說的NET ID(網路位),每個NET ID(網路位)底下剩1個HOST ID(主機位),這裡也不用減2了;因為區域網段剩1個IP,不需要廣播了同時網段就代表HOST ID本身。
`既然全走layer3路由當然也不需要Docker0充當Bridge/Switch當虛擬二層網路設備做轉發,所以省下了1個Docker0 Container與1個IP還有轉發消耗,因為沒了Docker0,在宿主物理機上必須幫每個Container虛擬一張網卡VethX連到Container內部的網卡eth0`,整個架構會變成下圖

(圖片來源:趣談網路協議)
>**假設現在Container A1要跟Container B2通信:**
封包從Container A1 eth0出來跳到veth1匹配物理機A的路由規則,接著我們在Days15不是有說過資料中心長相,一個機櫃頂端會有個TOR switch串連所有機櫃裡的物理機,現在A與B是在同一機櫃所以A與B是在同一個underlay區域網路;無須隧道無須NAT,封包直接走區域網路發到物理機B的eth0實體網卡在進行路由匹配,發往對應的Veth2虛擬網卡,Veth2對應到Container B2 eth0網卡,通訊完成!。
### 參考:
1.K8s神人磊哥
2.網易雲服務首席架構師劉超
3.CCNA++
4.Spark on Kubernetes: A case study from JD.com
5.https://docs.projectcalico.org/v2.0/getting-started/kubernetes/tutorials/simple-policy
6.https://rancher.com/blog/2019/2019-03-21-comparing-kubernetes-cni-providers-flannel-calico-canal-and-weave/
7.[Docker網絡方案Calico新版上手體驗](https://edgedef.com/2016/12/10/docker-%E7%BD%91%E7%BB%9C%E6%96%B9%E6%A1%88-calico-%E6%96%B0%E7%89%88%E4%B8%8A%E6%89%8B%E4%BD%93%E9%AA%8C/)
# Calico篇(下集)那些年我們學過的計算機網路與K8s網路
前面我們說過Calico透過一些巧妙甚至欺騙的方式降低網路複雜度達到`"Google的扁平化網路的方向"`,例如:讓每個Docker網段只剩一個Container的/32技術,甚至連Dokcer0 Bridge/switch都省掉,讓Container直接跟宿主物理機Linux Kernel通訊,這種方式雖然不太適合微服務但很適合分散式AI,畢竟如果依照Flannel的邏輯一台物理機最多可以有254個服務(就是Host ID數量2^8-2=254),那宿主物理機豈不是要虛擬254張網卡對應254個Container,想想這畫面多美麗啊,對一台物理機下一個ifconfig指令跳出254+1(local)+N(實體)張網卡的資料,`您家的網路工程師一定會稱讚您!這是個偉大發明突破他對物理機與網路的想像力!`
當然除此之外 Calico還解決了Flannel另一個網路複雜度的問題,例如:當年吳恩達與Jeff Dean辨識貓咪的實驗中,他們使用了16000顆CPU與無數台物理機,如果照Flannel host-gw模式的思維:每台Docker的宿主物理機都必須有到其他台物理機的路由規則,那整個網路模型的複雜度會是O(n^n),若一物理機台有16顆CPU,那16000顆CPU需要有1000台物理機,`總共會有1000^1000=100萬條路由規則`,如下圖或參考Flannel總集的說明,更何況維護路由表的工作是Etcd在做,根據某K8s高手經驗談超過200台Etcd集群就會出問題。

Calico為了解決Flannel host-gw的網路複雜度O(n^n)與Etcd瓶僅還有Etcd使用的Raft算法效率問題,它實做了BGP路由器管理協定,同時因為Linux kernel有支援BGP協議,所以沒有模式切換(user mode/kernel mode)產生的效能耗損問題,Calico的路由表更新方式可以拆成兩個部分:
1. 宿主物理機啟動BGP Speaker服務將宿主物理機內因container所產生的路由變化透過iBGP協議給BGP reflector知道。
2. 機櫃頂端的TOR switch啟動BGP reflector服務將機櫃形成一套AS(自治系統),將AS(自治系統)內的路由變化透過eBGP(走TCP)給其他BGP reflector知道。
經過以上兩點整個網路被拆成N對1與1對N,於是網路複雜度被降成O(n),再次備註BGP是很複雜的協定這裡只是簡單講解不完全正確,就像以前數學老師說三角形內角和永遠是180度,但在高等數學中三角形內角和只有在平面是180度,在曲面會大於180度在凹面會小於180度。
好了以上就是京東與Intel資深工程師在O'Reilly Strata Data Conference推薦的分散式AI運算用的K8s CNI Calico預設模式全部內容,跟Flannel host-gw模式一樣,都要所有宿主物理機必須在同個Layer2網路的缺點(無論實體虛擬都可以),若要跨Layer2則必須使用Calico IPIP模式建立隧道與各種封裝但根據磊哥說網路效能會掉到跟Flannel VXLAN模式(20%~30%耗損)差不多,這還不如乾脆用Google的GKE預設CNI,所以這裡就不介紹Calico IPIP模式。
明天我們要講最後一章:`站在Google高層角度看AI演算法與系統優化
### 參考:
1. 聽完眾大老分享後自行領悟
# 站在Google高層角度看AI演算法與系統優化
最後講AI系統與演算法,因為小弟曾在安控上班所以用CNN為例,現在請各位抬頭看一下camara,有沒有感受到來自美國總統雷根(Reagan)的關懷,頭上突然多了一串分數,哎喲你的分數好像有點低;偷偷告訴你~~捐血~~捐款給美國總統雷根(Reagan)可以提高分數喔!

(圖片來源:美聯社)
我們把時間點拉回2011年,加利福尼亞溫暖且燦爛的陽光灑在Google山景城的總部,一位高級研究員拿著一本神秘研究報告走進某位Google高層的辦公室,接過研究員的報告這位高層靜靜的看了起來;腦中不斷閃過他學生時代曾經做過的AI研究與拿到全美最佳學士論文獎的情景,最終他闔上報告同時也下定決心成立Google最高層級秘密計畫Project X團隊。
Oh yeah! 我們贏了,來自多倫多大學的博士生Alex大喊!幾個月前他還是連能否準時畢業的都不知道的博士生,現在他成了2012 ImageNet LSVRC影像辨識比賽的冠軍,他望向其他嘴巴都快掉下來的競爭對手笑的合不攏嘴,此時在幾千公里外的Google總部一場最高級別的會議正在進行,經過一番討論過後Google的高層們決定讓他們其中一位成員同時也為此事規劃許久;傳說中Doug Cutting 大神手上拿著的那三篇Hadoop創世論文的作者`Jeff Dean與他的秘密計畫Project X的團隊成員吳恩達教授與高級研究員Greg Corrado一起建立Google下一代AI系統`並將團隊名稱改成Google Brain,由於傳統ML算法例如: K-mean, SVM, KNN, RF移植到GPU困難同時Google內部也沒有那麼多GPU;高層們也不打算買一堆GPU去贊助他們的競爭對手Nvidia,`所以高層們希望Google Brain團隊發展一套"能通吃所有ML算法的AI系統"支援Cloud業務的擴展而不是成為一家專精CNN與GPU的安控公司`,Google Brain團隊首期目標是發展一套分散式CNN算法並搭配所有ML算法都能通用的CPU的系統,還要在下次ImageNet LSVRC比賽獲得冠軍!






































>Google日前發表最新研究成果Tiny Video Networks(TVN),這是一套辨識和理解影片的類神經網路模型,號稱辨識長度為1秒的影片,在GPU上只需要10毫秒,在CPU上則需要37至100毫秒,相較於過去作法用數十、數百層的卷積類神經網路(CNN),在CUP和GPU上都需要數千毫秒(新聞來源:AI趨勢周報第107期)
### 參考:
1. 小弟過去的投影片
2. [AI趨勢周報第107期:Google發表輕量影片理解模型,辨識1秒長的影片只要10毫秒](https://www.ithome.com.tw/news/133954)
2. https://ai.google/research/teams/brain/
# 矽谷新模式-台灣製造?與K8s現在與未來的玩法?
這裡要說一句公道話台灣的資訊科系畢業的工程師真的能力扎實又便宜!
**矽谷新模式-台灣製造?**
現在矽谷都掀起將研發團隊放在台灣或是中國的熱潮,雖然台灣或是中國工程師英文能力遠不如印度而且工資還貴了四倍(成本計算在下表),但工程質量遠勝印度; `而且內行人都知道,編寫代碼成本很低軟體上真正可怕的成本是debug/troubleshooting/optimize/integrate/SLA/Scaling/CleanCode,所以矽谷那些真正精明的軟體公司寧可多花四倍成本,將軟體外包給中國或台灣團隊也不要給英文頂尖且價格只要四分之一的東南亞團隊,新聞:波音事故與印度軟體工程文化,請自行Google

(圖片來源:硅谷看上中国N线城市"码工":只拿1/3薪水,肯加班无怨言)

(資料來源:硅谷看上中国N线城市"码工":只拿1/3薪水,肯加班无怨言)
>**大陸與台灣工程師薪水比較:**
7820X30.5(匯率)=238510看似比台灣新鮮人貴,但是但是!!!您知道的中國共產黨是靠勞工階級支持上台,`所以大陸的勞動合同對勞工的保障勝過台灣的勞基法,而且中國企業幫勞工提列的五險一金(40%~55%)也遠高於台灣的勞保(3206÷45800=7%,勞保局資料),還有大陸企業相關稅法非常繁雜苛刻,員工離職也高且調薪幅度大,雖然存在996制度降低開支但長期過勞的員工生產力能多好?`,所以長遠來看台灣軟體工程師比較便宜尤其高階更甚,您看看阿里,騰訊資深工程師動輒四五百萬台幣以上的股票+年薪!,為什麼台灣人到大陸薪水至少1.5倍喊起,`因為大陸定義台灣人是"外籍勞工"所以中國企業不用支付台灣人五險一金`可以變相要求企業主提高你的薪水,還有盡量簽12個月無年終的勞動合同除非你在阿里騰訊這種頂級公司,畢竟台灣人是外籍勞工如果今天公司片面取消年終獎金你壓根沒輒。
參考:[阿里 P10、騰訊 T4、華為 18,互聯網公司職級、薪資、股權大揭秘](https://www.infoq.cn/article/0*dh8y7jcxcDc0YJFXq1)
>**黑色幽默:過勞**
>我Team公司旅遊同團有兩個大陸工程師,在遊覽車上聽到他們的對話
A:現在老了沒法熬夜一到10點就想睡
B:對阿老了沒法像大學一樣熬夜玩耍,我天天都要早睡
A:B你今年幾歲
B:24歲你呢?
A:我26歲
我跟另一個3X歲天天熬夜的台灣工程師面面相覷,你們也太誇張才二十多歲就跟老頭沒兩樣,下次你們會不會躺在加護病房跟我們視訊?!
[GitHub 上破 10 萬顆星!工程師寫程式控訴中國「996」血汗加班制度](https://buzzorange.com/techorange/2019/04/01/996-icu-github/)
**K8s的玩法**
可以很難很高檔,`例如:像在美國上班的大大的玩法!小弟非常佩服他對K8s有如此深厚的了解!他的系列文寫得真是太棒了!,當然K8s也可以很簡單很基本;像我曾待過一個Team他們的GKE-K8s Admin是國外名校出身的行政人員借調過來的(他很聰明為人又和善,後來被高薪挖走了)`,我接手以後雖然沒有多少K8s經驗更沒看過K8s Source Code,但憑著對計算機,網路與DB的基礎知識進行若干優化,Resquest反應時間也少了75%,順利在User沒抱怨/沒資料不一致的情況7分鐘內完成K8s生產環境的自管DB擴容/資料遷移,品質跟DB SaaS供應商看齊。
**K8s未來玩法!:**
Container不是甚麼新概念,Docker也只是使用Linux的cgroup,namespaces去實現基本的隔離,但這種隔離資訊安全性太差,所以不能可在公有雲上這樣玩!基本上GKE,AKS,EKS都是先建VM再開K8s`(其實我們在前面章節進入GKE節點查詢網卡時就有發現這是透過VM產生的虛擬網卡)`,但這樣會失去某些優點,所以張磊在"Docker vs Kubernetes,容器生態圈現狀如何?"一文中提到現在科技巨頭們在想新的方法 Serverless化K8s;把K8s底層API屏蔽起來,不讓用戶接觸就減少資訊安全風險,而且學習這些底層API也太困難對用戶並不友好;你想想如果可以一鍵更換K8s各種底層組件那該有多好!有興趣的朋友可以直接看原文。
[Docker vs Kubernetes,容器生态圈现状如何?](https://www.infoq.cn/article/J7mIyLAUvPWYkoLyC8vF)

(年輕人你渴望力量(高薪)嗎?我這裡有本K8s秘笈)

(感謝Tacet提供)
## 參考:
1. [矽谷企業的東方秘密武器是「中國工程師」](https://buzzorange.com/techorange/2019/10/17/engineer-in-china/)
1. 阿里 P10、騰訊 T4、華為 18,互聯網公司職級、薪資、股權大揭秘
1. Docker vs Kubernetes,容器生態圈現狀如何?
1. Serverless:慢 15%,贵 8 倍?
1. GitHub 上破 10 萬顆星!工程師寫程式控訴中國「996」血汗加班制度







