# 【vMaker Edge AI專欄 #07】TinyML (MCU AI) 運行效能誰說了算?

作者:Jack OmniXRI, 2023/07/17
在電影「食神」中,唐牛和史蒂芬周同時選了佛跳牆來爭奪食神地位,結果唐牛抗議對方抄襲動作,結果裁判說:「比賽就是這樣的!好像跑步游泳一樣,還不是你做什麼他就做什麼!有什麼好抗議的?抗議無效!」。同樣地,在AI晶片或神經加速處理器(Neural Network Processing Unit, NPU或Deep Learning Accelerator, DLA)領域中,大家也都說自家的晶片世界最棒,對手看不到車尾燈,難道沒有一個較為公正衡量晶片運行(推論)效能,就像手機跑分軟體一樣,讓大家比較信服的基準嗎?
其實在AI晶片領域中所謂的「**效能**」,可能因關心的重點不同而會有不同定義和解讀。分別可從硬體每秒可執行乘加的次數(又可細分FP32,FP16及INT8等)、對於特定模型在指定推論精度下每秒可執行次數或推論一次所需時間(包含有無模型優化處理)、特定模型推論功耗(推論一次耗費焦耳數)、每瓦特可執行乘加指令次數及其它特定規範時的表現,甚至有用每塊美金獲得算力來當成基準。所以常會遇到誰也不服誰,老王賣瓜自賣自誇的現象。
目前較被大家接受的就是ML Commons[1]所提出的MLPerf規範,其中包含訓練及推論兩大項,而推論部份又可細分為資料中心(Datacenter)、邊緣(Edge)、行動(Mobile)及微型(Tiny,大多為MCU)。前不久(2023/6/27)才剛公佈了Tiny v1.1測試結果報告[2],其中也包括了台灣新唐科技(Nuvoton)及臺灣發展軟體科技(Skymizer)提交的亮眼成果。接下來就幫大家解讀一下這份報告,讓大家能更了解未來單晶片運行AI的方向及可行性。
## 1. 評測場景及項目
目前ML Commons在Tiny部份先前已經過三輪(v0.5, v0.7, v1.0)測試,此次公佈的是v1.1結果[2]。測試時分為封閉(Closed)及開放(Open)型式,前者依官方規範測,而後者廠商可提出依自己規範測試更優的結果,不過不是每輪評測都會有開放型式。
目前主要評測項目如Fig.1 所示,共有四個項目,包含關鍵字偵測(Keyword Spoting, KS)、視覺喚醒字(Visual Wake Words, VW)、影像分類(Image Classification, IC)及異常偵測(Anomaly Detection, AD)。而每個項目都是採單串流資料(Single Stream)方式進行,即推論完一筆再取下一筆進行推論。依照不同項目,分別使用對應的資料集和模型,並在指定的推論品質下進行評量。
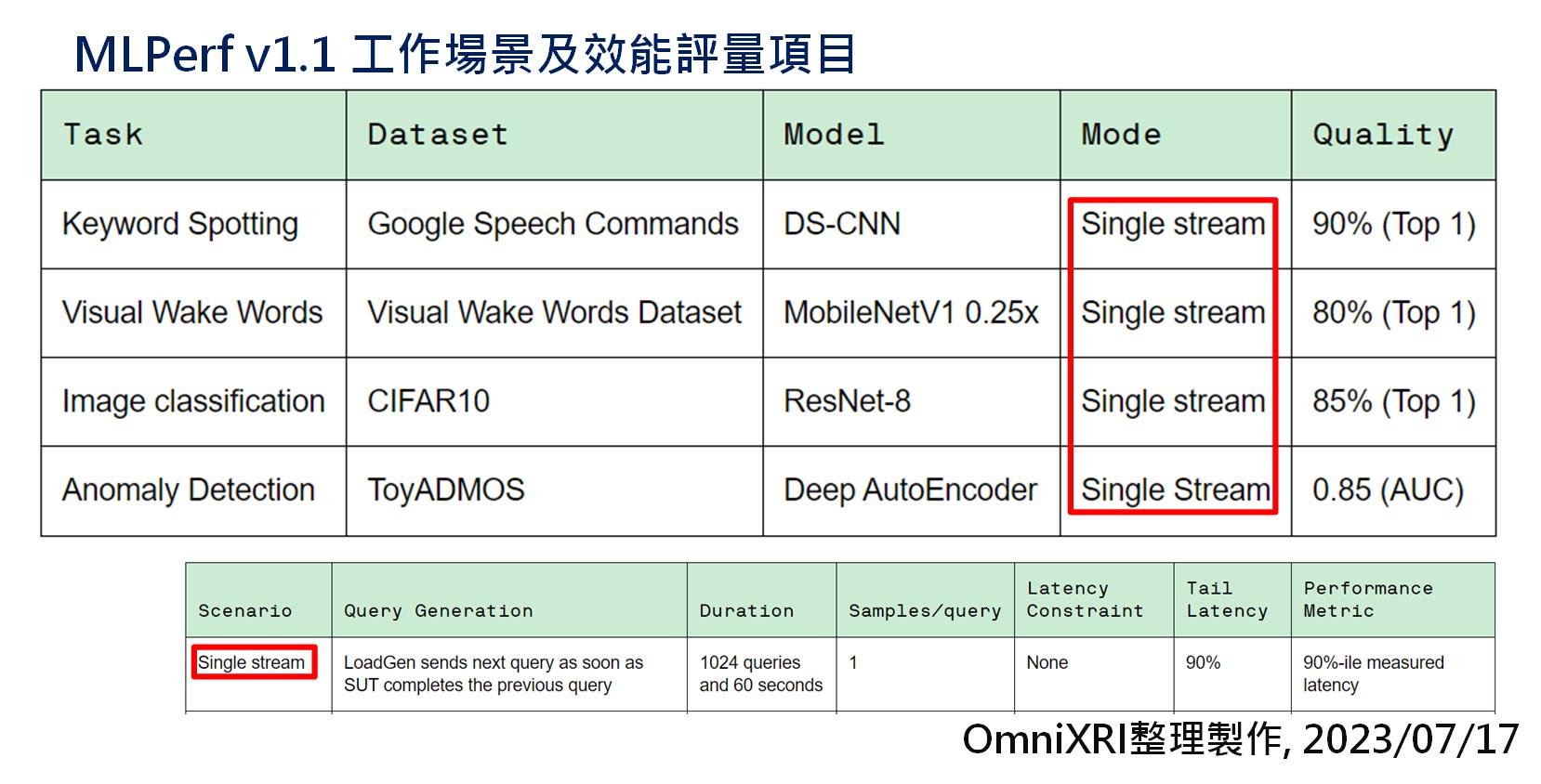
Fig.1 MLPerf v1.1 工作場景及效能評量項目。[2](OmniXRI整理製作, 2023/07/13)
## 2. 參與評測公司、硬體及軟體
本次參與評測的項目共有32項,以下依不同項目分別介紹。
* **參與評測公司:** 共有10家,Krai, Nuvoton(新唐科技), STMicroelectronics(簡稱STM), Skymizer(臺灣發展軟體科技), cTuning, fpgaconvnet, Plumerai, Syntiant, Robert Bosh GmbH, kai-jiang(個人)。
* **參與評測開發板:** 共有14種,規格下如下所示。
* STM NUCLEO-H7A3ZI-Q, Arm Cortex-M7(DSP+FPU) @280MHz
* STM NUCLEO-L4R5ZI, Arm Cortex-M4(DSP+FPU) @120MHz
* STM NUCLEO-U575ZI-Q, Arm Cortex-M33(DSP+FPU) @160MHz
* STM NUCLEO-G0B1RE, Arm Cortex-M0+ @64MHz
* STM DISCO-F746NG, Arm Cortex-M7(DSP+FPU) @216MHz
* Nordic nRF5340 DK, Arm Cortex-M33(DSP+FPU) @128MHz
* Nuvoton NUMAKER-M467HJ, Arm Cortex-M4F @200MHz
* DIGILENT Cora Z7, Arm Cortex-A9 @667MHz
* DIGILENT ZC706, Arm Cortex-A9 @650MHz
* DIGILENT ZedBoard, Arm Cortex-A9 @650MHz
* DIGILENT ZyBo, Arm Cortex-A9 @650MHz
* Infineon CY8CPROTO-062-4343W, Arm Cortex-M4 (DSP + FPU) @150MHz
* Syntiant NDP9120, HiFi3+M0 @30.7MHz/98.7MHz
* ZCU106, RISC-V @20MHz
* **主要CPU規格:** 共有7大類。只有1項使用RISC-V,1項為MCU+NPU,其餘皆是Arm Based。Cortex-M為單晶片(MCU)等級,Cortex-A為微處理器(MPU)等級晶片,用於手機或單板微電腦。
* Arm Cortex-M0+ (1項)
* Arm Cortex-M33 (4項)
* Arm Cortex-M4/M4F (13項)
* Arm Cortex-M7 (7項)
* Arm Cortex-A9 (4項)
* Syntiant HiFi3+M0 (2項)
* RISC-V (1項)
* **主要軟體及函式庫:** 共有9種。
* Skymizer ONNC
* MicroTVM
* Plumerai Inference Engine
* Syntiant TDK+SDK
* Bosch Hardware-Aware Lowering Engine(HALE)
* STM X-CUBE-AI
* fpgaConvNet(Model+Optimiser)
* Arm CMSIS-5
* TVM
## 3. 評測結果:
由於晶片等級落差頗大,單從推論時間(毫秒ms)及能耗(微焦耳uJ 比較可能會有點不公平,所以這裡依CPU等級及工作頻率來分會更清楚些。Fig. 2分別列出各等級中推論速度表現最好的。如果想了解更完整測試資料可參考[2]。
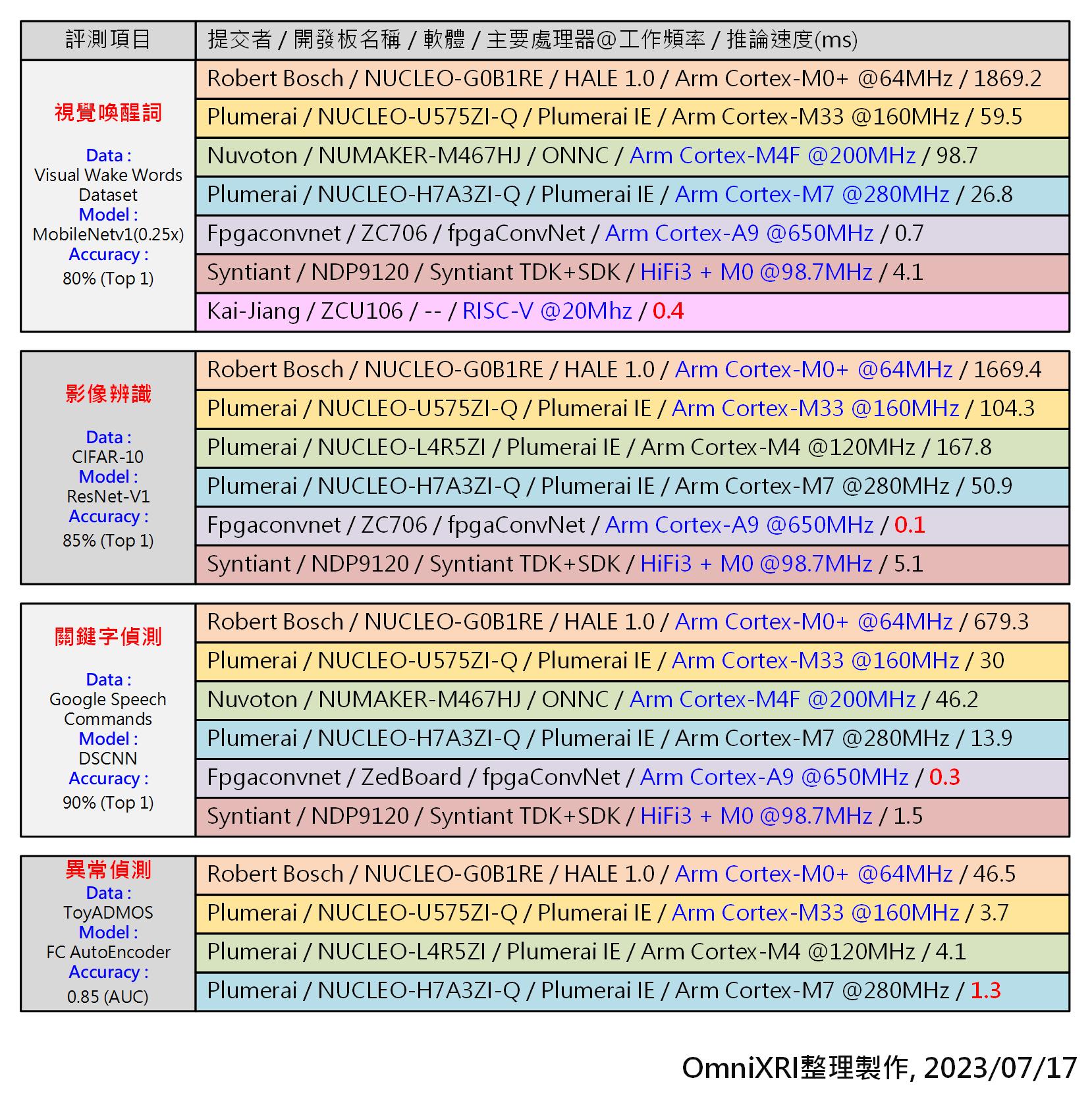
Fig.2 MLPerf Tiny v1.1各等級CPU及不同應用表現最佳清單。[2](OmniXRI整理製作, 2023/07/17)
台灣這次也有兩家廠商提交3個項目,其主要規格如下:
* 台灣新唐科技(Nuvoton), Nuvoton NUMAKER-M467HJ, ONNC, Arm Cortex-M4F @200MHz。
* 臺灣發展軟體科技(Skymizer)
* NUCLEO-L4R5ZI_zephyer, STM NUCLEO-L4R5ZI, ONNC, Arm Cortex-M4 @120MHz
* NUCLEO-L4R5ZI_mbed-os, STM NUCLEO-L4R5ZI, ONNC, Arm Cortex-M4 @120MHz
這3項底層部份都是使用Skymizer的ONNC來進行推論優化,其中新唐在Cortex-M4等級評比中,在視覺喚醒詞和關鍵詞偵測部份獲得最快推論速度,不過由於此次評比的Cortex-M4大多是120MHz,所以使用200MHz會略勝一疇。若把Skymizer的兩項升速到200MHz時,則其表現會接近新唐的MCU,表示其ONNC的性能已達世界水準,值得台灣其它有生產Arm Cortex-M4 MCU的廠商參考。
註:此次使用的ONNC為較新商用版本,而非Github上開源的版本[3]。
另外從此次提交的項目亦可看出Arm Cortex-M4已成為TinyML的主流,若推論仍不夠快時,則可再提升到Cortex-M7。而新上市的Cortex-M33效能已高過Cortex-M4,略低於Cortex-M7,讓使用者有多一點性價比的選擇空間。
## 4. 深入了解測試規範
若想要更深入了解其測試規範的朋友可以參考官方釋出的論文[4],或官方Github提供的完整測試規範[5]。目前MLPerf在手機SoC晶片(Arm Cortex-A等級CPU)AI測試部份略嫌少了些,如果有興趣了解的朋友可參考[6]。
## 小結
在邊緣智能(Edge AI)裝置及智慧物聯網(AIoT)應用中使用單晶片(MCU)來運行AI(TinyML)已是現在進行式,透過此次的評比結果,可讓大家更了解各家晶片性能及模型優化工具的進展,未來隨著MCU+NPU的普及,相信下一次的評比結果可能就有更大躍升,就讓大家一起期待吧!
## 參考文獻
[1] ML Commons
https://mlcommons.org/
[2] ML Commons, Benchmarks - Inference: Tiny v1.1 Results
https://mlcommons.org/en/inference-tiny-11/
[3] Skymizer, Github - Open Neural Network Collection - ONNC/onnc
https://github.com/ONNC/onnc
[4] MLCommons, MLPerf Inference Benchmark
https://arxiv.org/abs/1911.02549
[5] MLCommons, MLPerf Tiny Inference Rules
https://github.com/mlcommons/tiny/blob/master/benchmark/MLPerfTiny_Rules.adoc
[6] 許哲豪,AI晶片如何評比效能
https://omnixri.blogspot.com/2019/03/ai.html
## 延伸閱讀
[A] 陸向陽,【Benchmark】要如何衡量TinyML專案的執行效能?
https://makerpro.cc/2022/03/how-to-measure-the-performance-of-tinyml-projects/
[B] 陸向陽,TinyML效能基準測試:MLPerf Inference:Tiny 0.7版觀察
https://makerpro.cc/2022/07/the-review-of-mlperf-inference-tiny-version-0-7-benchmark-for-tinyml-performance/
[C] 許哲豪,MCU攜手NPU讓tinyML邁向新里程碑
https://omnixri.blogspot.com/2022/10/mcunputinyml.html
[D] 許哲豪,有了TinyML加持MCU也能開始玩電腦視覺了
https://omnixri.blogspot.com/2022/12/tinymlmcu.html
**本文同步發表在[【台灣自造者 vMaker】](https://vmaker.tw/)**
---
OmniXRI 整理製作,歡迎點贊、收藏、訂閱、留言、分享,
###### tags: `vMaker` `Edge AI` `TinyML`







