# AlphaGo Zero
by Alvin
# 前言
1997年5月 IBM 的 "Deep Blue" 超級電腦擊敗了西洋棋世界冠軍卡斯巴羅夫。此刻電腦西洋棋正式宣佈『任務達成』。
傳統桌遊中幾乎就只剩圍棋是電腦無法勝任的,那時很多專家以為電腦可能要好幾十年後才能打敗人類。
大約20年後,Google 的 DeepMind 團隊推出了所謂的AlphaGo 電腦圍棋程式,在2016的三月打4-1敗了韓國圍棋大師李世乭。
但DeepMind團隊覺得這樣還不夠好,近一步的研發出 AlphaGo Master,在網路上 50-0 打敗了各國的圍棋專家、五月又 3-0 擊敗世界冠軍柯潔。
事實上 AlphaGo Master 的框架已經跟一開始的 AlphaGo 差很多,但 DeepMind 那時還未發佈相關的技術論文。
這個月 DeepMind 終於發佈了新論文,介紹 AlphaGo 的最終版本 AlphaGo Zero。 AlphaGo Zero 不但比 AlphaGo Master 強很多(100局中有89局獲勝),更驚訝的是它的訓練資料中沒有使用任何人類的圍棋棋譜或戰術!
原來,已是棋王的AlphaGo欲脫俗成仙,條件是先移除人類的沾污。
---
# 背景
根據賽局的分類,像是圍棋或西洋棋的棋都屬於零和、完美資訊、序列、離散、非合作博弈。
也就是說,有兩個互相競爭的玩家,會輪流從有限集合選下棋動作,一方獲勝就是令方輸,兩方都看得到整個棋盤,沒有任何隱藏因素會影響你下棋位址對棋盤的改動,而且棋盤狀態能完全決定獲勝與否。
理論上,這類的遊戲的完美解可以用所謂的 min-max search。min-max search 有效能問題,因此就有 alpha-beta search + iterative pruning。想法就是減少搜尋樹需要被探索的地方。但這樣仍無法產生夠強的圍棋AI。
2006 Remi Coultan https://hal.inria.fr/inria-00116992/document 對電腦圍棋搜尋樹太龐大的問題提出了一半的解答。他們提出用 Monte-carlo Tree-search(MCTS)來有效模擬最佳步法。
而 2016 AlphaGo 基於 MCTS,進一步加上 self-play 的概念,並使用深度學習。這三樣合在一起,就使得電腦圍棋突破極限,打敗了人類。
2017的AlphaGo Zero一樣就是MCTS + self-play RL + deep neural network,但整個架構乾淨許多,而且沒有使用額外的資訊(棋譜)預先訓練。接下來我們來看看 AlphaGo Zero的架構。
---
# AlphaGo Zero 技術
持續和自己下棋(self-play)。每局中的每一輪,用類神經網路主導的 MCTS 搜尋選這輪的棋步。類神經網路持續的訓練,優化兩個目標:輸出的動作機率(move/action probabilities)要近似前面下棋中的MCTS動作機率,還有輸出的狀態價值(value estimates)近似下棋中遇到的狀態是否最後導致獲勝或失敗。
----
### AlphaGo Zero 樹搜尋
### Monte-Carlo 樹搜尋(Monte-Carlo Tree Search,MCTS)
一顆搜尋樹(search tree)裡有『節點』和『邊』,節點為狀態(棋盤狀態),邊為動作。某節點的邊就可以對應獨一的狀態動作對(state-action pair)。建立搜尋樹的過程我們稱之謂樹搜尋(tree-search)。一開始這顆樹只有一個節點(所謂的根節點),從根節點我們會慢慢的探訪新的節點,把它門加進樹裡面。節點會有一些關鍵的節點資訊存在,像是走訪次數、價值等。
MCTS 是一個大迴圈,有四步驟:
1. 選擇(Selection):這裡選擇是指,從根節點R開始,連續向下一個子節點直到葉子節點L結束。(葉子就是沒有子節點可以選的節點。)
2. 擴充(Expansion):從L的子節點選出幾個節點把它門加入樹裡面。(用來選子節點的方式或函數稱謂 "tree-policy"。)
3. 模擬(Simulation):從L開始,快速地把結果模擬出來。這種模擬稱謂一個 "rollout",模擬中選步的策略稱謂"rollout policy"。最簡單的 rollout-policy就是隨機選步。
4. 反向傳播(Backpropagation):用模擬結果更新R->L的節點資訊。
### AlphaGo 樹搜尋 - 步驟
AlphaGo Zero的樹搜尋為一個簡化版的 MCTS。
1. **選擇**: 從根節點開始,連續選步(邊)走到下一個子節點,直到遇到葉節點為止。
* 選子節點的規則為UCT (Upper Confidence Bound (UCB) for Trees):
* 選動作(邊)$a = \mathrm{argmax}_a Q_{(s_t, a)} + U_{(s_t, a)}$。(註:選子節點和選要走的邊是相同意思的。)
* Q 為邊上的一個統計值,是這邊底下的子樹的平均價值。各個邊的 Q 會在搜尋的過程中被跟新,初始化時是 0。
* U為所謂的「信賴上界」,代表我們對目前邊上Q值的信賴。
$U_{(s, a)} = c_{puct} P_{(s, a)} \frac{\sqrt{\sum_b N_{(s, b)}} }{1 + N_{(s, a)}}$
這裡N為這邊之前被選過幾次,及為走訪次數。走越多的邊信賴上線就越小。我們可以把U想成是一個各邊有的加分條件,讓比較沒走訪過得邊有加分條件,這樣比較容易被選到。
2. **擴充和評估**: 走到葉節點 $s_L$ 後就要拿給類神經網路做評估。類神經網路回傳的是這狀態的各個動作的動作機率 $\mathbf{p}$ 以及這狀態的價值估計$v$。
* **邊值初始化(擴充)**: 用$\mathbf{p}$初始化 $s_L$ 所有的邊
* 假設 $A$ 為動作集合,為**所有 $a\in A$** 製造一樹邊 ($s_L, a$) 並且初始化統計值 N, W, Q 和 P
* N=0: 走訪次數
* W=0: 此樹邊指向的子樹裡的價值合
* Q=0: W 除 N,子樹的平均價值
* P=$p_a$ + [$\mathrm{Dir}$ if $s_L$ is root]: stored *prior probability* of taking action $a$ at state $s_L$
* add Dirichlet loss to root node to encourage exploration
3. **反向傳播**:
* 用$v$更新根節點到$s_L$路徑中各邊 ($s_t$, $a_t$) 的統計值
* $W_{(s_t, a_t)} = W_{(s_t, a_t)} + v$
* $N_{(s_t, a_t)} = N_{(s_t, a_t)} + 1$
* $Q_{(s_t, a_t)} = \frac{W_{(s_t, a_t})}{N_({s_t, a_t})}$
---
## 選下一步的棋
搜尋做到一定程度後(論文是固定1600個迴圈),就可以用算出來的統計值下這一步的棋。假設這一盤現在的狀態為 $s_0$,也就是 MCTS 的根節點,那:
* 在 $s_0$ 的狀態下,選棋步a的機率分佈為 $\pi(a | s_0 ) = \frac{ {N_{( s_0 , a )}}^{\frac{1}{\tau}} }{ \sum_{b \in A_{s_0}}\ {{N_{ (s_0 , b)} }}^{\frac{1}{\tau}} }$
* $\gamma$ 為一個『溫度』常數。溫度月低,這機率分佈會集中在N最高的a。
* 論到下一步棋時,新的搜尋開始不需要從無開始,可以沿用對應到下的棋步的子樹。
---
## 訓練類神經網路:
類神經網路同時估計策略和價值函數
* 過去自己打自己的每一局的每一布可以當作一筆訓練資料 $(s_t, \pi_t, z_t)$
* $s_t$: 當時盤狀
* $\pi_t$: 當時MCTS後的動作機率值
* $z_t$: 1或-1,如果這步的玩家也是最後這局的贏家則1,否則 -1
* 抽幾筆 $(s_t, \pi_t, z_t)$ 當作一個訓練batch。類神經網路是同時估計策略和價值,策略的部份就是靠 $\pi_t$ 訓練,價值的部份就是靠 $z_t$ 訓練。
* Loss function: mean-squared error 和 cross-entropy loss 的合(論文是選擇平等加權)。
For single example from time-step $t$, $(s_t , \pi_t , z_t )$, $\mathcal{L} = (z_t-v)^2 + (-\mathbf{\pi_t}^{\intercal}\mathrm{log}\mathbf{p}) + c\|\theta\|^2$
$(\mathbf{p}, v) = f_\theta(s_t)$, $c$ 為 L2-regularization的常數
# AlphaGo("AG") 和 AlphaGo Zero ("Zero")的差別
* AG 用兩個類神經網路,分別估計策略函數和價值函數。Zero 用一個多輸出的類神經網路。
* Zero 的樹搜較單純,把傳統的 MCTS 的 expand 和 simulate 簡化了許多。
* 葉節點的子節點一律展開,不像原版有用一個 tree-policy 模型去判斷要展開哪些
* 當初 AG 有用類神經網路的評估去加強 MCTS 模擬出來的價值估計(兩個不同的價值估計做加權平均),而 Zero 是選擇捨棄模擬這步驟,用網路的評估完全代替模。
* AG 的策略網路是先用棋譜和 supervised-learning 的方式做初始化。Zero 沒有這樣做。
---
# 用策略迭代(Policy Iteration)的角度看 AlphaGo Zero
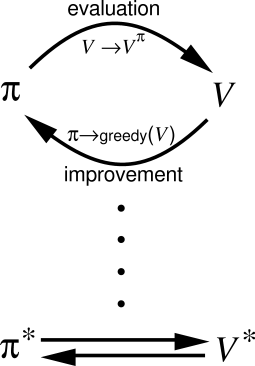
<sup>來源:http://incompleteideas.net/sutton/book/ebook/node46.html</sup>
典型的策略迭代演算法如上圖片所示,利用目前的策略函數去算出一個新的價值函數(策略評估),再用新的價值函數導出新的策略函數(策略改進),這樣相輔相成用使得兩函數趨近於最佳。
AlphaGo Zero 自己對自己的學習演算法可以視為一種近似策略迭代的演算法,這裡用MCTS的計算和類神經網路的學習來做一種間接的策略評估和策略改進。

## 參考及延伸閱讀
* [DeepMind AlphaGo Zero 網誌](https://deepmind.com/blog/alphago-zero-learning-scratch/)
"AlphaGo Zero: Learning from scratch"
DeepMind Blog Post
* [AlphaGo Zero paper](https://www.nature.com/articles/nature24270.epdf?author_access_token=VJXbVjaSHxFoctQQ4p2k4tRgN0jAjWel9jnR3ZoTv0PVW4gB86EEpGqTRDtpIz-2rmo8-KG06gqVobU5NSCFeHILHcVFUeMsbvwS-lxjqQGg98faovwjxeTUgZAUMnRQ)
Silver, D. et al. *Mastering the game of Go without
human knowledge* Nature. (2017)
* [原AlphaGo paper](https://storage.googleapis.com/deepmind-media/alphago/AlphaGoNaturePaper.pdf)
Silver, D. et al. *Mastering the game of Go with deep neural networks and tree
search* Nature. (2016)
* [Paper discussing using MCTS in Go](http://www0.cs.ucl.ac.uk/staff/d.silver/web/Publications_files/grand-challenge.pdf)
Gelly, S. et al. *The Grand Challenge of Computer Go:
Monte Carlo Tree Search and Extensions* Communications of the ACM. (2012)
* [MCTS survey](https://www.researchgate.net/publication/235985858_A_Survey_of_Monte_Carlo_Tree_Search_Methods)
Browne, C. et al. *A Survey of Monte Carlo Tree Search Methods* IEEE Transactions on Computational Intelligence and AI in Games. (2012)
* [Policy Iteration 介紹](http://incompleteideas.net/sutton/book/ebook/node46.html)
Sutton, R. et Barto, A. *Reinforcement Learning: An Introduction*
 Sign in with Wallet
Sign in with Wallet







