---
robots: index, follow
tags: NCTU, CS, 共筆, 計算機組織, 吳凱強
description: 交大資工課程學習筆記
lang: zh-tw
dir: ltr
breaks: true
disqus: calee
GA: UA-100433652-1
---
計算機組織--吳凱強
=====
`NCTU` `CS`
[回主頁](https://hackmd.io/s/ByOm-sFue)
# Syllabus
- English course
- focus on review
- Need to know: Digital Circuit Design, HDL
- Book: `David A. Patterson and John L. Hennessy, Computer Organization and Design - The Hardware/Software Interface, 4th Edition, Morgan Kaufmann, 2009.`
- Score
- 3 Exam (65%)
- Quizzes (10~15%)
- Team Project (10~15%) (4-5 lab)
- hardware/software **interface**
- Taiwan REQUIRED
- require
- Verilog
- Digital Circuit Design
- 參考資源
- [Computer Arithmetic](https://chi_gitbook.gitbooks.io/personal-note/content/computer_arithmetic.html)
- [黃婷婷老師:計算機結構Computer Architecture](https://hackmd.io/s/rkloHgHcx)
# Course
## Ch0
- Tick-Tock Model (for CPU)
- Manufacturing process tech
- Microarchitectures (CS can focus on)(ex. Skylake, Haswell)
- Architect vs Coder
- Algorithms
- OS
- Computer Organization
- faster, more scalible
- Gate
- Logic Gate
- AND
- OR
- NOT
- XOR
- NOR
- NAND
- Memory
- MUX
- Regiest
- Latch
- Flip-Flop
- Processor
- Computer
- Machine Organization

- Software ↑ (OS, Assembler[ch2], Compiler...)
- Instruction Set Architecture
- Hardware ↓ (Processor[ch3], Memory, IO...)
- High Level -Compiler-> Assembly -Assembler-> Machine Language -Machine Interpretation> Control Signal
- ISA
- Complex instruction set computer (CISC)
- Intel x86
- Intel IA-64
- Reduced instruction set computer (RISC)
- ARM
- MIPS **(we used)**
### What do we learn
- How programs are translated into the machine language
- And how the hardware executes them
- The hardware/software interface
- What determines program performance
- And how it can be improved
- How hardware designers improve performance
- What is parallel processing
## Ch1 Computer Abstractions and Technology
#### Computer Revolution
Classes
- Desktop
- Server
- Network based
- High capacity, performance, reliability
- Embedded
- Hidden as components of systems
- stringent power/performance/cost constraints
Why changes
- IC design
- ECL -> CMOS
- Shrinkage of feature size -> increasing transistor numbers in a chip
- SOC (System on Chip)
- Manual design -> electrical design automation by CAD tools
- communication
- LAN -> WAN
- wireless tec-
- embedded computers
Reducing Power
$Power = CapcitiveLoad * Voltag^2 * Frequency$
- Suppose CPU has
- 85% of capacitive load of old CPU
- 15% voltage and 15% frequency reduction
$$
\dfrac{P_{new}}{P_{old}} =
\dfrac{C_{old}*0.85*(V_{old}*0.85)^2*F_{old}*0.85}{C_{old}*V_{old}^2*F_{old}} = 0.85^4 = 0.52
$$
- Power wall
- We can’t reduce voltage further
- We can’t remove more heat
- What else?
#### Multiprocessors
- Multicore microprocessor
- More than one processor per chip
- Requires explicitly parallel programming
- Compare with instruction level parallelism
- Hardware executes multiple instructions at once
- Hidden from the programmer
- Hard to do
- Programming for performance
- Load balancing
- Optimizing communication and synchronization
**AMD 可能要重返榮耀啦~~**
#### Performance
- Algorithm
number of operations executed
- Programming language
numbers of machine instructions
- Processor and memory system
how fast instrucion executed
- I/O system (including OS)
how fast I/O
#### Response Time and Throught
- Response time
- Throughput
- total wark done per unit time
- e.g. tasks/transactions/... per hour
- affected by
- Replacing the processor with a faster version
- Add more processor
- **Facus on response tim for us** (easiset)
Relative Performance
(performance = 1/execution time)
- Elapsed time
- total response time
- e.g. Processing, I/O, OS overhead, idle time
- CPU time
- time spent processing
- comprises user CPU time and system CPU time
- CPU Clocking (時脈)
$$
CPU Time\\ \\ = CPU Clock Cycles * Clock Cycle Time\\ \\ = \dfrac{CPU Clock Cycles}{Clock Rate}
$$
- Clock Cycles and CPI (Cycles per Instruction)
$$
Clock Cycles = Instruction Count * CPI\\
CPU Time = Instruction Count * CPI * Clock Cycle Time\\
=\dfrac{Instruction Count * CPI}{Clock Rate}
$$
- Weighted average CPI (每個CPI還是可能不一樣)
$$
CPI = \dfrac{Clock Cycles}{Instruction Count}\\=\sum_{i=1}^n{CPI_i*\dfrac{Instruction Count_i}{Instruction Count}}
$$
Performance Summar:
$$CPUTime = \frac{Instruction}{Program} * \frac{ClockCycles}{Instruction}*\frac{Seconds}{ClockCycle}$$
### SPEC
measure performance
- Pitfall: Amdahl’s Law
## Ch2
### Instruction Set
- different computers have different instruction set
- [MIPS](www.mips.com) (million instruction per second)
- three operands (三個運算元)
- `add a, b, c` # a = b + c
- e.g. `f = (g + h) - (i + j);`
become
```
add t0, g, h
add t1, i, j
sub f, t0, t1
```
- 32 * 32 bit register
- use for frequently accessed data
- 0 to 31
- 32 bit data callled a "word"
- if not enough to used, put back to memory
- Assembler names
- $t0, $t1, ..., $t9 for temporary
- $s0, $s1, ..., $s7 for saved
- Design Principle 2: Smaller is faster
- f = (g + h) - (i + j)
```
add $t0, $s1, $s2
add $t1, $s3, $s4
sub $s0, $t0, $t1
sw $s0 #save word back to memory
```
- To apply arithmetic operations:
- Load values from memory to registers
- Store result to memory
- Memory is byte addressed
- Each address identifies 8bit data
- words are aligned in memory
- Address must multiple of 4
- MIPS is Big Endian
- most siginificant byte at least address of MSB
- ex. 0x2a4d77fe:
- (3)LSB fe 77 4d 2a MSB(0)
- e.g. g(\$s1) = h(\$s2) + A[8]\($s3)
```
lw $t0, 32($s3) #load word
add $s1, $s2, $t0
```
- e.g. A[12] = h + A[8]
```
lw $t0, 32($s3)
add $t0, $s2, $t0
sw $t0, 48($s3) #store word
```
### Register vs Memory
- faster to access than memory (go by IO)
- using memory will used more instruction
- compiler must use register for variables as much as possible
### Immediate operands
`addi $s3, $s3, 4`
- no `subi`
- MIPS register 0 ($zero): constant: 0
- cannot be overwritten
- useful for common operations
- e.g.
`add $t2, $t2, $zero`
### signed/unsigned
Binary integers
- $2^{n-1}$ can't be reqresented
- highest char for + or -
- x' + 1 = -x
sign extension:
if 32bit + 16bit, adder 需要 32bit
two's component:
- 正數擴展就直接在前面加 0
- 負數擴展就直接在前面加 1
- In MIPS:
- addi
- lb, lh (MSB start?)
- beq, bne
- e.g. `lw $s1, 4($t0)`
MIPS R-formate Instruction
- used 32 bit represent an instruction
- shamt: 左右移動
- funct: 如果 6bit 的 op 不夠用, 以 funct 延續
- e.g. add, sub, ...
MIPS I-type Instruction
- Immediate arithmetic
- rt: destion or source, depend on op
- immediate: $-2^{15}$ to $2^{15}-1$
- Address: offset added to base address in rs
- e.g. branch

### op
shift
- sll: shift left (logical)
- srl: shift right
- and, andi: bitwise and
- or, ori: bitwise or
- **nor**: bitwise not (a nor b == not (a or b))
- beq rs, rt, L1: branch, if(rs==rt) branch to instruction labeled L1
- ben: branch, if(rs!=rt)
- j: jump
### Branch
```C++
if (i == j) f = g+h;
else f = g-h
```
```assembly
bne $s3, $s4, Else (如果成立,就不會跳到Else) (bne是如果不成立,就branch)
add $s0, $s1, $s2
j Exit
Else: sub $s0, $s1, $s2
Exit: ...
```
```C++
while(save[i] == k) i+=1;
```
i in $s3, k in $s5, address of base in $s6
```assembly
Loop: sll $t1, $s3, 2 (index 往後移)
add $t1, $t1, $s6 (找 index 的值)
lw $t0, 0($t1)
bne $t0, $s5, Exit
addi $s3, $s3, 1
j Loop
Exit:...
```
### Basic Blocks
A basic block is a sequence of instructions with
- No embedded branches
- No branch targets
- A compiler identifies basic blocks for **optimization** (compiler 最容易認出這段)
### conditional operation
- slt rd, rs, rt: if(rs < rt) rd = 1; else rd = 0;
- slti rt, rs, constant: if(rs < constant) rt = 1; else rt = 0;
- Combination with beq, bne
```assembly
slt $t0, $s1, $s2 #if($s1 < $s2) $t0 = 1; else $t0 = 0;
bne $t0, $zero, L #if($t0 != 0) branch to instruction labeled L;
```
### Procedure Calling
1. place parametr in registr
2. transfer control to procedure
3. acquire storage for procedurw
4. perform procedure's operations
5. place result in register for caller
6. return to place of call
### Register
- zero
- at: reg 1, reserved for assembler
- v0, v1: reg 2,3 result value
- a0 - a3: argument
- t0 - t9
- s0 - s7
- k0, k1: reg 26,27, reserved for OS
- gp: reg 28, global pointer for static data
- sp: stack pointer
- fp
- ra
### Procedure Call Instructions
- Procedure Call: jump and link
``jal ProcedureLabel``
- Address of following instruction put in $ra
- jump to target address
- Procedure return: jump register
``jr $ra``
- copies $ra to program counter
- can also be used for computed jumps (e.g. case/switch statements)
### Leaf Procedures
- e.g 一般函式
### Non-Leaf Procedures
- procedure that call other procedure
- nested call, caller needs to save on stack
- its return address
- any arguments and temporaries needed after the call
- restore from the stack after the call
- e.g 遞迴函式
// 看不懂QQ
## Ch3
### ALU
- Computer must deal with:
- Operation: 加減乘除 overflow
- Floating-point
### Adder
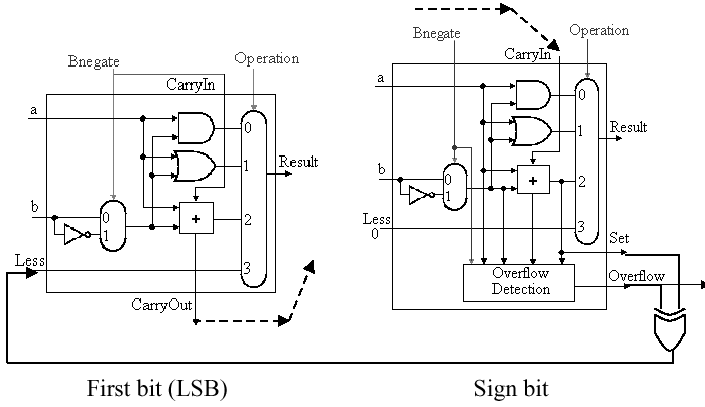
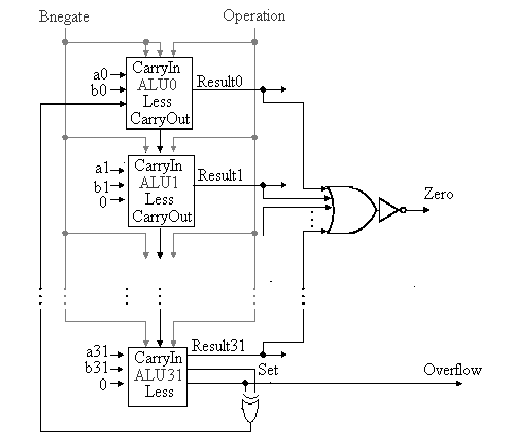
- Check overflow
- adder:
- +V + -V or -V + +V => no overflow
- -V + -V = + => overflow
- +V + +V = - => overflow
### Multiplier
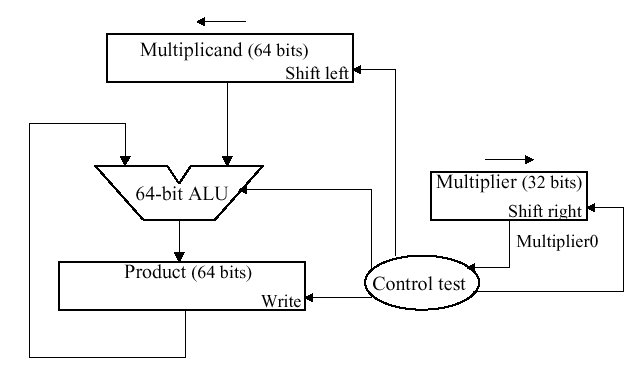
- 實做
- 每次檢查 multiplier[0] & multiplicand
- 若 multiplier[0] == 0 -> 把 0 放到 ALU
- 若 multiplier[0] == 1 -> 把 multiplicand 放到 ALU
- ALU 將原來的答案加上剛剛放的數字
- multiplicand 右移
- multiplier 左移
- 重複做32次(MISP的位數)
- Optimized
- [Booth's algo](https://zh.wikipedia.org/wiki/%E5%B8%83%E6%96%AF%E4%B9%98%E6%B3%95%E7%AE%97%E6%B3%95)
- 可平行處理
- multiplicer 每一bit都拉條線給ALU
- Wallace flow(概念上可平行, but 硬體可能會過耗)
- pipline
- special register
- HI: most-significant 32 bits
- LO: least-significant 32 bits
- instruction
- mult (sign) / multu (unsign) (product in HI/LO)
- mfhi / mflo (move from HI/LO to rd) (can test HI for overflows)
- mul rd, rs, rt (rs * rt = rd)
### Division
dividend = divisor * quotient + reminder
- 用減法比大小
- 將divisor shift到最高位
- 將dividend放到 remainder
- 每次將remainder - divisor放到 Remainder
- 若差 > 0 => Remainder不動,商數左移並加一
- 若差 < 0 => Remainder+divisor, 商數左移加零
- 持續33次
- Optimized
- 無法平行:每次結果需要上次的答案
- SRT division
- MISP
- div / divu
- no overflow or divide-by-0 checking
- mfhi / mflo
### IEEE floating point
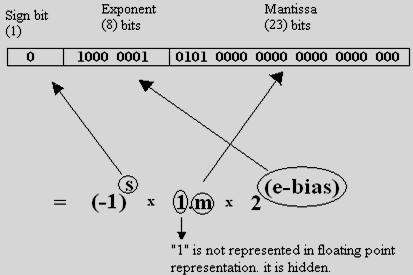
- single
- 8 bits exponent
- 23 bits fraction
- bias: 127
- actual exponent = 1-127 = -126
- Exponents 00000000 and 11111111 reserved
- smallest value
- exp: 1-127 = -126(因為0是保留的)
- frac: 000..0 = 1 => 010 => 1.010
- $2^{-126} to -2^{-126}$
- biggest value
- exp: 254 - 127 = 127(255保留)
- frac: 111..1 = 1.1111... = 2
- $-2\times2^{127} to 2\times2^{127}$
- approx $2^{–23}$
- double
- 11 bits exponent
- 52 bits fraction
- bias: 1023 bits
- approx $2^{–52}$
- 特別數(
- Denormal Numbers
- exp: 00000000
- Gradual Underflow
- 這裡的數字的 frac 都是 0 開頭 => 001 = 0.001
- so if frac = 0 => it's 0 (有+0&-0)
- Infinities and NaNs
- exp: 11111111
- frac = 0 => inf
- frac != 0 => Not a Number
- FP Adder Hardware
1. 比較精確度(shift to smaller exp)
2. 數字部分相加
3. normalize & overflow checking
4. round & renormalize
- 多個 cycles
- can be pipelined
- FP Multi
1. add exponent but +127 (因為表示式的關係)
2. 數字部分相乘
3. normalize & overflow checking
4. round & renormalize
5. determin sign
- MISP
- lwc1, ldc1, swc1, sdc1


// 以上...偷懶中...
...
## Ch4
### Introduction
- 影響效能:
- Instruction Count:
- ISA
- compiler
- CPI, Cycle time
- hardware
- MIPS(介紹兩種)
- simplified version
- more realistic **pipelined** version
- Simple subset
- Memory reference: lw, sw
- Arithmetic/logical: add, sub, and, or, slt
- control transfer: beq, j
### Instruction
- PC(program counter) -> instruction memory, fetch instruction (用來儲存指令行號,可以是下一步指令,也可能是 beq 要跳到的地方)
- register numbers -> register file, read register(用 register 編號存取讀寫 register)
- 分工
- ALU
- 數學計算 (add...)
- 計算 mem 位址 (load/store)
- 計算要跳到的地方 (beq, j)
- Access data memory (load, store)
- PC 在給出下一個指令(PC+4) 或者剛剛存的 Address(如果 beq 有跳到其他地方了話)
- Simple CPU

### Build Datapath
- Datapath:
- CPU 裡操作 data 跟 address 的元件
- e.g. register, ALU, mux...
- Instruction Fetch

- 如果是正常狀態了話,PC會收到 4,自然就會去到下一個指令
- 如果有 beq 了話,PC會收到要跳到的地方,所以後面會加一個 adder 的控制器
- Instruction
- R-type:
- 2 register operands
- arithmetic/logic operate

- I-type
- R-type 少拉一條就好了
- load/store
- ALU sign-extend(計算 16bit outset 的)
- Read data 出去的會是 base 位址,sign-ext 出去的會是 offset,在用 ALU add 算出最終位址
- Load: mem 讀值,更新 register
- Store: 把 register value 寫入 mem

- branch
- compare operands
- ALU, 減法,檢查 zero
- 計算目標位址
- sign-extned 移位(因為指令裡的位址是16bit,可是PC的是32bit,因此要做擴張)
- shift left 2 places (因為指令裡的位址沒有考慮到儲存空間的大小(類似編號),實際上取值是要編號*空間大小(4))
- add to PC+4 更新位址

- 組合各 element
- 每個 ele 一次只能做一個 function
- 切 instruction 和 data memories
- multiplexers 暫存 data sourse 之後用在不同的 instruction

- ALU control (用 op code 分三類)
- Load/Store: add(base + offset)
- branch: sub (用減法算大於小於)
- R-type: 原運算子

- Main Control Unit

- Jump

- need extra control signal to decode op code

### Performance
- Longest delay determines clock period
- 關鍵路線(最長鍊):load instruction
- Instruction memory -> register file -> ALU -> data memory -> register file (最長鍊)
- 對不同指令的各種時期並不彈性
:::warning
design principle:
Making the common case fast
:::
- **pipeline**
### pipeline
- 重疊執行:用平行方式加速
- 5 stages
- IF: instructure fetch from mem
- ID: instructure decode & reg read
- EX: ALU execute
- MEM: access mem
- WB: write back

- Hazards (風險)
- Structure Hazards
指令跟值都存在 reg 裡,會產生衝突 => 將指令(Instructure)的 reg 與 數值(data)的 reg 分開來存
- Data Hazards
要存取之前的資料,可是要的資料還沒產生
- Bubble
當要使用的值還沒產生時,需要等到產生時才能做下一個指令,等待的動作就會塞 bubble

- Forwarding
再把值存入 reg 前,其實我已經把它算出來了,所以應該其實已經可以拿來用了
- R-type: 在 exe 後就有值了
- Load/Save: 在 mem 後就有值了
- Coding Scheduling
在排列指令時,把不影響的指令提前,讓要wait的指令後移


- Control Hazards
控制面,下一個指令該去哪裡 (branch 會遇到)
- branch 需要運算完才能知道下一個指令是什麼
- pipeline 還是需要等到 ALU 運算完才能知道要跳到哪裡 (still on ID)
- MIS pipeline
- 在 pipeline 就做好比較並計算出要跳到的地方
- 加入硬體
- [Branch Prediction](https://zh.wikipedia.org/wiki/分支預測器)
- 先猜一個 branch 來用,猜對可以繼續做,猜錯再改
- static
直接預測不跳
直接預測跳
- dynamic
根據歷史經驗改變
### Pipeline Register
暫存每一階段的 pipeline 值

- Control


### Forwarding
- ID/EX.RegisterRs: ID 到 EX 的暫存器

- and 用到 sub EX/ME
- or 用到 sub ME/WB
- add & sw 用到 Reg
- Forward condition


### Double Data Hazard
若同時兩行都需要用到 forwarding 時,每次 forwarding 都使用較近的
- e.g.
```
add $1,$1,$2
add $1,$1,$3
add $1,$1,$4
```

### Load used Hazard
- 需要 insert bubble

- 判斷依據

- Bubble 插入方法:
- 讓 ID/EXE Reg 值為 0 => EX/MEM/WB 就不會工作
- 阻止 PC 跟 IF/ID 的更新
- 越早檢查到要加bubble較好,因為加 bubble 需要有代價
- 也許 compiler 改變 code 的順序,可以將之後的 code 拿來先做 (跟要 bubble 的 code 沒有關係時),取代 bubble 功能
### Branch/Control Data Hazard
先猜,等跑完 branch 後,檢查猜得對不對,若否,再重新跑隊的 branch

### Dyminac branch predict
- 1-bit branch predict
- 紀錄上次 branch 跳到哪裡,這次就跟著跳
- 2-bit branch predict
- 紀錄上兩次,如果是:
- 連續兩次相同的,branch 跳成那種
- or 其他計算方式
### Branch Delay Slot
如果之前有指令可以放在 branch if 的下面當 branch 的 bubble,那原來的 bubble 就不會浪費掉 (compile 要做的優化)
- From before
上一個的指令與之沒有關係,可以放在 if 下面執行 (可以減少 clock cycle)
- From target
branch 完可能會跳到上面,所以先將會跳到的指令以下不用 flush 的指令放在 bubbl,這樣不管猜對猜錯,都不用再做 flush (不能減少 clock cycle,可是可以不用 flush)
- From fall-through
branch 完可能會跳到上面,所以先將會跳到的指令以下不用 flush 的指令放在 bubbl,這樣不管猜對猜錯,都不用再做 flush (不能減少 clock cycle,可是可以不用 flush)

- Cache
### Expection
- Exception
- 從 CPU 裡發出
- Interrupt
- 從 外部 送入

- 如何處理

## Ch5
### Locality
- temporal locality
- 被 access 的物件短時間內會被再次存取
- spatial locality
- 短時間內會存取現在被 access 的物件附近的物件
- Advantage of Locality
- memory hierarchy
- 加速 disk 存取
- disk -> DRAM(main mem) -> SRAM(cache mem)
- 名詞
- block: copy 的單位(一次不止 copy 要 access 的長度,可以加速 spatial locality)
- hit: 從 cache 裡有找到東西
- miss: 找 cache 發現沒有
### Large storage memory hierache
- SRAM
- Static RAM
- DRAM
- Dynamic RAM
- Disk
- Non-volatile 非揮發
- Flash Storage
- NOR flash: NOR gate
- NAND flash
- DRAM(Dynamic Random Access Memory)
- rectangular array
- Burst mode: faster
- [Double data rate](https://en.wikipedia.org/wiki/Double_data_rate)(DDR)
- Quad data rate(QDR)

### Cache Memory

- hierarchy 與 CPU 最靠近的 mem
- 存在 cache 裡的資料是 存在 memory 裡的資料的子集合
- 查找一個 mem 值時,先找 cache,若有直接用,沒有才去 memory 裡查找
- each bit:
- tag: 確認 cache 的值是否正確
- valid: 確認這個 mem 裡是否有值
- 計算長度
- 假設
- 一個 word 由 4 byte 組成
- 一個 block 由 m words 組成
- cache 長度是 n
- ...
- 效能
- 每個 block 若能塞入越多 bytes => 拿東西的時候比較容易hit => 降低 miss rate
- 但若是 fix-sized cache
- 大 block => cache 中的 block 數量更少 => 增加 miss rate
- pollution: 搬太多了 => 浪費空間
- larger miss penalty
- block size 大 => copy 時更耗能
### Cache Miss
- stall pipeline
- 從下一層把 block 抓出來
- Instruction cache miss
- 重啟 instruction fetch
- Data cache miss
- 真的跑下去抓資料(原來先問 cache 有沒有)
### write hit (寫入的地方有 cache)
- write-through
再做寫入時,為了同步 cache 和 mem,要同時寫入 cache 和 mem,可是反而會讓所需時間更長
=> 先寫入 buffer
- write-back
- dirty: 紀錄被寫過的 cache 叫做 dirty
- 持續記錄每一個 dirty (多 dirty bit 判斷)
- 之後 dirty 若要被取代 -> 記得要把 dirty 寫回 mem
- write Allocation
發生 write miss(要寫的資料不在 cache 裡)
- write around(write no-allocate): 寫入 mem 但沒有 fetch 到 block
- allocate on miss(write allocate): 寫入 mem 但有 fetch 到 block
### Performance
- FastMAT
- ...
- Main Memory Supporting Caches (sample)
- address of transfer(指向到 address 上): 1 bus cycle
- DRAM access(挖 DRAM 資料): 15 bus cycle
- Data transfer(將 data 傳回 cache): 1 bus cycle
- cache block: 4 word => 要 copy 4 word 到 cache 上
- DRAM: 1 word => DRAM 一次只能 access 一個 word
- bus: 1 word => 每次 bus transfer 只有一個 word
- => Misspenalty: $1 + (15+1)\times4=65$ bus cycle
- => Bandwidth: $(4\times4)\div65=0.25$ Byte/cycle

- Cache Performance
- 程式執行時間
- 包含 cache hit 時間
- mem stall cycles
- 主要在 cache miss


- instructure cache 一定會執行 => 1
- data cache 只有在 data access 的指令下才會執行 => 0.36
- AMAT = Hit time + Miss rate * Miss penalty
- Average memory access time(AMAT)
- Hit time: 在 cache 抓的成本
- Miss rate: 沒有在 cache 上抓到的比率
- Miss penalty: 沒在 cache 上抓到,要回到 mem 抓的成本
- Summary
- 降低 CPI
- 增加 clock rate
- 除了 CPI 外,架構也很重要
- e.g. Instructure-cache 與 Data-cache 分開做
### Associativity (把多個 cache 組合成一群)
可以減少 miss,but 會需要 search
- Fully Associative => <span style="color:red">模擬出來效能最好</span>
- n-way set associtive => n 次比對
- direct mapped (1-way)


- 要塞新的東西時:
- 先找沒用過的 cache
- 找 Least recently used (LRU)
- 最久沒被 search 的
- 最小,最快
- random cache
### Multilevel Caches
- 處理器和記憶體二者之間的快取有兩個天然衝突的性能指標:速度和容積
- 一級快取靠近處理器一側,二級快取靠近記憶體一側。當一級快取發生失效時,它向二級快取發出請求。如果請求在二級快取上命中,則資料交還給一級快取;如失效,二級快取進一步向記憶體發出請求。對於三級快取可依此類推。
- Primary cache
- 主要設計考量最小化 hit time
- Level-2 cache services cache
- 減少 main mem 的 miss rate
- Main memory services L-2 cache misses
- L-3 cache
### [Out-of-order CPUs](https://zh.wikipedia.org/wiki/乱序执行)
- 當指令抓取,無法在同一個 clock 內找到資料時(e.g. 需要到 disk 抓)
- 把這筆 instruction 塞到 buffer 裡,繼續做下一個指令
- 只有在指令是 Independent 時,才能做 out-of-order
### Dependability
- Reliability(可靠性): MTTF
- Service interruption(服務中斷): MTTR

- Availability(可用性): $MTTF / (MTTF+MTTR)$
- 降低 MTTF
- 增加 MTTR
### Virtual Memory
- 每個 program 被分配到一個 virtual mem
- CPU 和 OS 再轉譯 program 的 virtual mem 到真實的 mem
- page: 在 VM 裡的 block
- page fault: VM 翻譯時 miss 了
- 如果 page miss 時
- 需要花很多時間到 disk 抓資料
- minimize page fault rate
### Page Table
<p style="color:red">一個 program(process) 就會有一個 page table,也就是說 virtual address 以上的東西的是因 program 而異</p>
紀錄位置而非 data
- PTEs: page table entries
- Page Fault Penalty
- 如果 page fault,page 就會去 disk 找資料(page fault 了話,data 一定在 disk)
- 耗時
- OS 處理
- CPU 裡的 Page table register 會指向在 mem 裡的真實位址
- (所有的 virtual address 都要先經過 page table 轉成 phy address)
- 如果指向的地方是 mem:
- 會儲存 phy address
- 會儲存 status bit (e.g. dirty, valid...)
- 如果不是 mem:
- 會儲存 disk 位址 (swap space on disk)

- Replace
- LRU (LRU Approximation Algorithm)
- Reference bit(use bit) 剛用到這個 PTE 時會被設成 1
- OS 一段時間會把所有 use bit 設成 0
- use bit == 0 的人會被 replace
- Disk write 很花時間
- Write-through 是不切實際的
- use write (用 dirty bit)
- BUT page table is too big => too slow
- 使用 [TLB](https://zh.wikipedia.org/wiki/轉譯後備緩衝區)
- cache of PTE in CPU
- Translation look aside buffer
- TLB 是 Page table 的一個 subset
- => 如果 TLB 有 hit,Page table 就一定有 hit
- 也有可能都 miss => 要去 Disk 找
- TLB miss
- Page table in mem
- 抓回 TLB
- page fault
- OS 把 data 從 disk 更新 page table 跟 TLB

- TLB & cache
- Physical address cache
1. 從 TLB 找 physical address
2. 到 cache 找 data
- [參考](https://www.ptt.cc/bbs/Grad-ProbAsk/M.1297706545.A.44B.html)
- Virtually addressed cache (不常用)
- 直接到 cache 找 data
- 比較複雜
- 因為不同的 program 會有不同的 virtual address,可是 cache 是共用的,所以可能會造成 program A 的virtual address 不小心與 program B 的 virtual address 相同,導致 program A cache 回來的 data 被 program B 誤用
- => virtual 可能就會需要加入是哪個程式的 cache 了

### Memory Protection
不同的 tasks 可以共用 virtual address spaces
?????
### Memory Hierarchy
四規則
- Block placement
- Direct mapped
- n-way set associative
- Fully associative
- 越高 associative 能夠有越小的 miss rate <- 比下面的重要
- 越高 associative 會增加 complexity, cost, and access time
- Finding a block
- 
- Virtual memory
- 可以減少 miss rate
- Replacement on a miss
- LRU
- Random
- Virtual memory(LRU approximation)
- Write policy
- Write-through
- 同時更新 cache 與 mem
- 需要 write buffer
- Write-back
- 只更新 cache
- 當 block 將要被更新時,才同步回 mem
- 需要紀錄 dirty
- Virtual memory
### Sources of Misses
- Compulsory misses
- Capacity misses
- Conflict misses
### Cache Trade-offs
- 增加 cache size
- capacity misses 降低
- access time 增加
- 增加 associativity
- conflict misses 降低
- access time 增加
- 增加 block size
- compulsory misses 降低
- miss penalty 增加
- 對非常大的 block size,可能會因為 pollution(搬太多了 => 浪費空間) 而增加 miss rate
### TLB, Page Table and Cache
- TLB 是 Page Table 的 subset
- Cache 的 index 是用 phy address 做的,所以若 page fault -> map 不到 phy address 自然就無法去 cache 找
- [參考](http://derdoc.info/portfolio/NMSU/CS473/site/cache-vm.html)

### [Cache Coherence](https://en.wikipedia.org/wiki/Cache_coherence) (可能出現在平行處理, 多核心)
若兩個 CPU 需要用到同一個 physical address space...
- coherence(相干性): P1 寫入 X 後,P2 讀取 X
- Problem
- cache 是分開的,不同的 cache 指向同一個 mem
- 當其中一個被改到時,因為還沒寫入 mem,另一個會沒有一起更新
- 處理方法
- [Snooping](http://www.infoq.com/cn/articles/cache-coherency-primer)
- 當有寫入 cache 時,Broadcast 到其他的 cache 說這個 mem 是 invalidate
- 如果寫入的 cache 是 invalidate,就一定要到 mem 重新抓取
- [Directory-based](http://ithelp.ithome.com.tw/articles/10158488)
- 比較複雜,延遲較大
- 但在多處理器系統內延展性較高
### Memory Consistency
- ?????
- 兩個 write 不能換順序 <- 這頁唯一看得懂的 QQ
### Pitfalls
- 陷阱
- ...
### Conclusion
- 快的記憶體會比較小,慢的會比較大
- 可是我們想要又快又大
- => 使用 cache 技術
- locality
- 一個 program 常常會一直讀寫特定小範圍近的 data
- => 使用 spacial locality 概念
- Memory hierarchy
- L1 cache - L2 cache - ... - DRAM memory - disk
## Ch6 Parallel Processors from Client to Cloud
**multi core vs. faster uniprocessor**
### Difficulity
- Partitioning (分工)
- Coordination (協調)
- Communications overhead (通訊開銷)
### Amdahl’s Law
- 定義 : 針對電腦系統裡面某一個特定的元件予以最佳化,對於整體系統有多少的效能改變
- 不可平行的運算(Sequential part) 會限制到平行運算的速度
- E.g. 100 processors, 90 倍 speedup
- $T_{new} = T_{parallelizable}/100 + T_{sequential}$
- $Speedup = \frac{1}{(1-F_{parallelizable})+F_{parallelizable}/100}=90$
- Solving: $F_{parallelizable} = 0.999$
- 得知 sequential part 會是總任務的 0.1%
- E.g.2 10 個數字連加,並且將兩個 10*10 的 matrix 相加
- 10 連加無法平行,matrix 可以
- 1 processor: $(10+100)\times t_{add}$
- 10 processors: $10×t_{add} +100/10×t_{add} =20×t_{add}$
### Strong vs Weak Scaling
- Strong scaling:
- problem size fixed
- 改變處理器的規模
- ex. 用同一個問題一直壓你
- 可以測出 processor 效能
- Weak scaling
- problem size 與 processor 成比例
- 要多額外手續才能平行處理是 weaks scalimg
- ex. 保持問題與 processor 成比例
- 測出效能
### Instruction and Data Streams

- SPMD: Single Program Multiple Data
- 在一個 MIMD computer 上的平行程式
- 不同處理器的 Conditional code
### Multithreading
- multiple threads 來執行可平行的程式
- 複製 registers, PC, etc.
- thread 間的 Fast switching
- Fine-grained multithreading
- 每個 cycle 都換一做另一個 thread 的事
- 交錯執行指令
- 如果一個 thread stall,也換別的 thread
- Coarse-grained multithreading
- 只有在 long stall 才換 thread
- Simultaneous(同時) Multithreading
- 多個 issue 動態規劃
- 把 thread issue 全部完全重新規劃

### Future of Multithreading
- 電源考量
- 簡單多線程 (高時脈很耗電)
- cache miss 產生的延遲
- Thread switch 可能會最有效
- 多個 single core 可能造成資源共享(share resources)更有效
### Roofline Diagram \快結束了/

- 兩種優化
- 優化最高值 (peak floating-point performance)

- 優化斜率

-----
# Design principle
1. **Simplicity favors regularity** (簡單有利於規則化)
- regularity makes implementation simpler
- simplicity enables higher performance at lower case
2. **Smaller is faster**
- c.f. main memory: millions of locations
3. **Make the common case fast**
- small constants are common
- immediate operand avoids a load instruction
4. **Good design demands good compromises(好的設計需要好的折衷)**
- different formats complicate decoding, but allow 32-bit instructions uniformate
- Keep formats as similar as possible
5. **Moore's Law**
- 18 or 24 月,硬體效能增加一倍
- 微處理器的性能每隔18個月提高一倍,而價格下降一倍
6. **parallel**
7. **pipe line**
# Exam
- \答案是錯的喔/,之後再補
- 
- How to set ALU for SEQ
- 
- 
- 會考每個元件到底是做什麼的
- ch4 所有的 why not
- why not in ID stage
- 如果放在 pipeline 之前放,
- 


{%youtube ejIYIcISwRE %}
# Chat
> ㄎㄎ
> 以下開放崩潰
> QQ
# Reference
[https://chi_gitbook.gitbooks.io/personal-note/content/zuo_ye_xi_tong_gai_lun.html](https://chi_gitbook.gitbooks.io/personal-note/content/zuo_ye_xi_tong_gai_lun.html)
 Sign in with Wallet
Sign in with Wallet







