# 第八講:記憶體管理
> 本筆記僅為個人紀錄,相關教材之 Copyright 為[jserv](http://wiki.csie.ncku.edu.tw/User/jserv)及其他相關作者所有
* 直播:
* ==[Linux 核心設計:記憶體管理(一) - 2019/4/11](https://www.youtube.com/watch?v=kY3g2r03erk)==
* ==[Linux 核心設計:記憶體管理(二) - 2019/4/14](https://www.youtube.com/watch?v=0oABzHrZDPY)==
* ==[Linux 核心設計:記憶體管理(三) - 2019/7/1](https://www.youtube.com/watch?v=9Kj7TBrvP-8)==
* 詳細共筆:[Linux 核心設計:記憶體管理](https://hackmd.io/@sysprog/linux-memory)
* 主要參考資料:
* [Slab allocators in the Linux Kernel:SLAB, SLOB, SLUB](https://events.static.linuxfound.org/sites/events/files/slides/slaballocators.pdf)
* [SLUB DEBUG原理](http://www.wowotech.net/memory_management/427.html)
* [The Art and Science of Memory Allocation](http://www.cs.unc.edu/~porter/courses/cse506/s16/slides/malloc.pdf)
* [The Page Cache](http://www.cs.unc.edu/~porter/courses/cse506/s16/slides/page-cache.pdf)
* [Page Frame Reclaiming](http://www.cs.unc.edu/~porter/courses/cse506/s16/slides/pfra.pdf)
* [Linux 核心設計:Memory](https://hackmd.io/@RinHizakura/rJTl9K5tv) (前人上課筆記)
* [Linux kernel and driver development training](https://bootlin.com/doc/training/linux-kernel/linux-kernel-slides.pdf)
> 本文使用的原始碼為 Linux 6.15 版本
---
記憶體管理是 Linux 核心中最複雜的組件之一,其設計與實作深刻地關聯到計算機結構、多樣的記憶體配置器 (slob/slab/slub)、行程與執行檔的樣貌、虛擬記憶體的對應機制與例外處理、記憶體映射,以及不同硬體架構如 UMA 與 NUMA 等議題。
本課系統性地探討這些議題,從基礎原理到核心策略,再到現代電腦架構下的新挑戰。
---
## 本課目標
記憶體管理涉及對計算機結構、多種記憶體配置器、行程樣貌、虛擬記憶體對應、例外處理,以及不同硬體架構的深刻理解。本課將探討以下核心議題:
* **虛擬記憶體原理**:深入了解 Memory Management Unit (MMU / 記憶體管理單元)、Translation Lookaside Buffer (TLB)、Cache (快取) 及 Page Fault (分頁錯誤) 的運作機制。
* **核心配置策略**:探討 Linux 核心如何因應不同的計算機架構,設計出如 slob、slab、slub 等記憶體配置器。
* **核心 API 與關聯**:解析 `vmalloc`, `kmalloc`, `kmem_caches`, shared memory 之間的內在聯繫與使用場景。
* **Swap 機制**:了解 Swap (交換空間) 的運作原理、Overcommit (過度承諾) 策略及其在現代電腦中的應用與權衡。
* **效能觀察與追蹤**:學習如何使用工具觀察並分析 Linux 核心的記憶體使用情況。
* **現代挑戰**:探討 Page Cache、Reverse Mapping (RMAP)、Kernel Same-Page Merging (KSM) 與 Huge Memory 等進階議題。
---
## 1. 記憶體管理基礎:從抽象到實體
記憶體管理的核心挑戰在於如何將應用程式的「邏輯地址空間」高效且安全地映射到有限的「實體記憶體」。
### 1.1 Process 的記憶體視圖
從一個 Process 的角度來看,其虛擬地址空間被劃分為兩個主要區域:
1. **User Mode (使用者模式)**:供應用程式程式碼執行,佔用較低的位址空間。
2. **Kernel Mode (核心模式)**:供作業系統核心執行,佔用較高的位址空間。
以 32 位元系統為例,總共 4GB 的位址空間通常被劃分為 3GB 供 User Mode 使用,1GB 供 Kernel Mode 使用 (經典的 3:1 切割)。在特定場景下 (如需要處理大量相機資料的手機系統),也可能採用 2:2 的切割方式,以提供更大的 Kernel 緩衝區。
```graphviz
digraph AddressSpace {
rankdir=LR;
node [
shape=none,
fontname="Helvetica",
fontsize=12,
margin=0
];
AddressSpace [
label=<
<TABLE BORDER="0" CELLBORDER="0" CELLSPACING="0" CELLPADDING="5">
<TR>
<TD><B>high</B></TD>
<TD></TD><TD></TD>
<TD><B>low</B></TD>
</TR>
<TR>
<TD></TD>
<TD BGCOLOR="#f9c290" BORDER="1" align="center" width="1">Kernel Mode<br/> 1 GB</TD>
<TD BGCOLOR="#a8d5e2" BORDER="1" align="center" width="3"> User Mode <BR/> 3 GB</TD>
</TR>
</TABLE>
>
];
}
```
從 User Mode 進入 Kernel Mode 的途徑主要有兩種:
* **System Call (系統呼叫)**:應用程式主動請求核心服務。
* **Interrupt (中斷)**:由硬體發出,如計時器中斷或網路卡中斷。
#### 使用者模式 (User Mode) 記憶體佈局
User Mode 的記憶體空間內部又被細分為多個 `Section (區段)`,各自有不同用途:
```graphviz
digraph AddressSpace {
rankdir=LR;
node [
shape=none,
fontname="Helvetica",
fontsize=12,
margin=0
];
AddressSpace [
label=<
<TABLE BORDER="0" CELLBORDER="0" CELLSPACING="0" CELLPADDING="5">
<TR>
<TD><B>high</B></TD>
<TD></TD><TD></TD><TD></TD><TD></TD><TD></TD><TD></TD><TD></TD><TD></TD><TD></TD><TD></TD><TD></TD><TD></TD>
<TD><B>low</B></TD>
</TR>
<TR>
<TD></TD>
<TD BGCOLOR="#f9c290" BORDER="1" align="center" width="1">Kernel<br/> (1 GB)</TD>
<TD BGCOLOR="#E1E100" BORDER="1" align="center" width="3"></TD>
<TD BGCOLOR="#a8d5e2" BORDER="1" align="center" width="3">stack<BR/>⭢</TD>
<TD BGCOLOR="#E1E100" BORDER="1" align="center" width="3"></TD>
<TD BGCOLOR="#a8d5e2" BORDER="1" align="center" width="3">memory<BR/>mapping<BR/>segment</TD>
<TD BGCOLOR="#E1E100" BORDER="1" align="center" width="3"></TD>
<TD BGCOLOR="#a8d5e2" BORDER="1" align="center" width="3">heap<BR/>⭠</TD>
<TD BGCOLOR="#E1E100" BORDER="1" align="center" width="3"></TD>
<TD BGCOLOR="#a8d5e2" BORDER="1" align="center" width="3">.bss<BR/>segment</TD>
<TD BGCOLOR="#a8d5e2" BORDER="1" align="center" width="3">.data<BR/>segment</TD>
<TD BGCOLOR="#a8d5e2" BORDER="1" align="center" width="3">.txt<BR/>segment</TD>
<TD BGCOLOR="#E1E100" BORDER="1" align="center" width="3"></TD>
</TR>
</TABLE>
>
];
}
```
* **Stack (堆疊)**:儲存函式呼叫時的區域變數、返回位址等,從高位址向低位址增長。
* **Memory Mapping Segment (記憶體映射區)**:用於映射檔案或裝置,如透過 `mmap()` 系統呼叫。
* **Heap (堆積)**:用於動態記憶體配置,由 `malloc`、`free` 等函式管理,從低位址向高位址增長。
* **BSS (Block Started by Symbol)**:儲存**未初始化**的全域變數和靜態變數。
* **Data (資料區)**:儲存**已初始化**的全域變數和靜態變數。
* **Text (程式碼區)**:儲存可執行的機器指令,通常是唯讀的。

#### 核心模式 (Kernel Mode) 記憶體佈局
Kernel Mode 的空間同樣被劃分以管理不同的核心資源:
```graphviz
digraph AddressSpace {
rankdir=LR;
node [
shape=none,
fontname="Helvetica",
fontsize=12,
margin=0
];
AddressSpace [
label=<
<TABLE BORDER="0" CELLBORDER="0" CELLSPACING="0" CELLPADDING="5">
<TR>
<TD><B>high</B></TD>
<TD></TD><TD></TD><TD></TD><TD></TD><TD></TD><TD></TD><TD></TD><TD></TD>
<TD><B>low</B></TD>
</TR>
<TR>
<TD></TD>
<TD BGCOLOR="#f9c290" BORDER="1" align="center" width="1"> 高記憶體<BR/>kmap 區</TD>
<TD BGCOLOR="#f9c290" BORDER="1" align="center" width="1">永久<BR/>kmap 區 </TD>
<TD BGCOLOR="#E1E100" BORDER="1" align="center" width="3"></TD>
<TD BGCOLOR="#f9c290" BORDER="1" align="center" width="1">vmalloc 區 </TD>
<TD BGCOLOR="#E1E100" BORDER="1" align="center" width="3"></TD>
<TD BGCOLOR="#f9c290" BORDER="1" align="center" width="1">直接映射區 </TD>
<TD BGCOLOR="#E1E100" BORDER="1" align="center" width="3"></TD>
<TD BGCOLOR="#a8d5e2" BORDER="1" align="center" width="3">User<br/> (3 GB)</TD>
</TR>
</TABLE>
>
];
}
```
* **highmem kmap area**:用於在 32-bit 平台上,當實體記憶體超過可線性映射的 `lowmem` 範圍後,必須透過臨時 `kmap` 映射才能存取的部分。
* **permanent kmap area (pkmap)**:一組預留的小範圍映射,用來對 highmem page 做「長期、global」的映射。
* **vmalloc area**:用於配置 **虛擬上連續** 但 **實體上不連續** 的大塊記憶體。
* **Linear (direct) mapping area**:直接映射部分的實體記憶體。
### 1.2 VMA (Virtual Memory Area)
Linux Kernel 使用 `mm_struct` 來描述一個 Process 的記憶體,其中包含一串 **`vm_area_struct` (VMA)**,每個 VMA 代表一段連續、權限相同的虛擬記憶體區域 (如 Text 段、Heap 段)。
* **搜尋優化**:為了加速 Page Fault 處理 (判斷位址是否合法),Linux Kernel 在 `mm_struct` 中同時維護了兩套結構:
- **Linked List**:用於遍歷所有節點。
- **Red-Black Tree (紅黑樹)**:用於 $O(\text{log}\ n)$ 快速搜尋。
* **現代 (Linux 6.1+) - Maple Tree**:為了支援更高的並發性 (Concurrency) 並減少 Lock Contention (鎖競爭),現代 Kernel 引入了 **Maple Tree** (RCU-safe range based B-tree) 來取代紅黑樹和 Linked List。<center><img src="https://hackmd.io/_uploads/SydxQyKwWe.png" alt="image" width="65%" /></center>
### 1.3 位址映射三部曲:從邏輯到實體
在 Linux 中,一個位址從被程式使用到最終存取硬體,會經過以下轉換過程:
1. **Logical Address (邏輯位址)**:在機器指令中使用的位址,由一個 Segment number 和一個 Offset 組成。這是 Intel x86 架構為了相容性而保留的設計。
2. **Linear Address (線性位址)**:邏輯位址經過 segment 轉換後的結果,是一個 32 位元或 64 位元的數值。
3. **Physical Address (PA / 實體位址)**:線性位址經過 MMU 的 `page table` 轉換後,最終在實體記憶體匯流排上傳輸的位址。

> 也可參考 [MIT 畫的圖](https://pdos.csail.mit.edu/6.828/2009/lec/x86_translation.svg)。
> [!Note]**Linux 的簡化**:
> 為了跨平台相容性,Linux 核心內部將 Logical Address 和 Linear Address 視為一體 (GDT 中定義的 Segment 其 Base = 0、Limit = 4GB,幾乎等同於沒有使用 Segmentation),統稱為 `Virtual Address (虛擬位址)`,從而簡化了開發者的心智模型。
### 1.4 Page Fault (分頁錯誤):不只是「錯誤」
Page Fault 是實現虛擬記憶體的關鍵機制,**不應單從「錯誤」的字面意義理解**。當一個 process 存取一個尚未與實體記憶體頁框 `(Page Frame)` 建立映射的虛擬位址時,MMU 會觸發此例外,核心會介入處理。Page Fault 主要分為三類:
* **Minor Fault**:
* **定義**:映射關係不存在,但對應的 page 已在記憶體中 (例如,在另一個 process 的快取中,或是已從 Disk 讀入但尚未建立映射)。
* **後續**:核心只需建立 `PTE (Page Table Entry)` 的映射即可,成本較低。
* **Major Fault**:
* **定義**:該 page 不僅沒有映射,而且資料已不在主記憶體中。
* **後續**:需要從 disk 等慢速儲存裝置中讀取回來 (例如,被 swap out 的 page)。這涉及 I/O 操作,成本非常高。
* **Invalid Fault**:
* **定義**:存取一個非法的記憶體位址 (如權限不符、位址不存在),最終導致 `Segmentation Fault`。
* **後續**:process 會被終止。

> [!Note]**Lazy Allocation (延遲配置) 的體現**:
> Linux 普遍採用的 `Lazy Allocation` 和 `Copy-on-Write (CoW / 寫入時複製)` 策略,都高度依賴 Page Fault 機制。系統在 `malloc` 時僅是分配虛擬位址空間,直到第一次寫入該空間時,**才透過 Minor Fault 真正配置實體記憶體 page**。
---
## 2. 核心實體記憶體管理策略
為了高效管理實體記憶體,Linux 核心發展出了多層次的管理策略。
### 2.1 Bootmem:系統啟動的先行者
在系統啟動初期,完整的記憶體管理系統尚未建立。此時,核心使用一種稱為 `bootmem` 的**簡易配置器**。它本質上是一個 `bitmap (位元圖)`,用來追蹤哪些實體記憶體 page 已被使用,但效率低落且易產生外部碎片。
### 2.2 Buddy System (夥伴系統):解決外部碎片化
一旦系統完成基本初始化,`buddy system` 就會接管實體記憶體的管理。
* **核心思想**:將所有空閒的記憶體 page 分組管理,每組包含大小為 $2^N$ 個連續 page 組成的 `block` (此處 $N$ 稱為 `order`)。Linux 核心在編譯時期定義了 11 個 order (0 到 10),因此最大的區塊是 4MB ($4\text{KB} \cdot 2^{10}$)。
* **配置**:需要申請 `n` 個 page 時:
1. 從能滿足需求的最小 $2^k$ 的空閒列表中取出一塊 ($2^k \ge n$)。
2. 如果該塊大於所需,則會將其對半分割:
* 一半用於滿足需求。
* 另一半 (即它的 "buddy") **放入下一級更小的空閒列表中**。
* **釋放**:釋放記憶體時,系統會檢查其 buddy 是否也空閒。若是,兩者將**合併 (Coalescing)** 成一個更大的塊,並回歸到上層的空閒列表。此過程會遞迴進行。
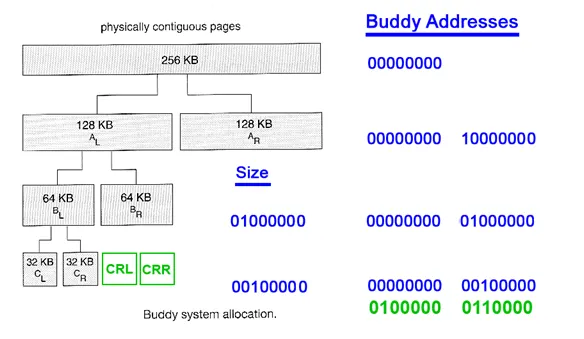
> 來源:[Operating Systems — Buddy Memory Allocation](https://medium.com/@boutnaru/operating-systems-buddy-memory-allocation-fcbb476eefe4)
> [!Tip]**Buddy System 如何解決問題?**
> * **解決效率問題**:申請記憶體時,可直接到對應大小的列表尋找,將 $O(N)$ 的掃描變成了近 $O(1)$ 的查找,效率極高。
> * **解決碎片化問題**:其核心機制在於 **「合併」**。這個機制能持續將小的空閒碎片整合成大的連續區塊。
* **相關資料結構**:
`/include/linux/mmzone.h`
```c=845
struct zone {
...
/* NR_PAGE_ORDERS = 11 種 order size */
struct free_area free_area[NR_PAGE_ORDERS];
...
};
```
```c=117
struct free_area {
struct list_head free_list[MIGRATE_TYPES]; // 該 order 下的可用連續空間,有區分不同類型的 block
unsigned long nr_free; // 可用 free block 數量
};
```
* **關鍵程式碼實作**:
主要圍繞在 `mm/page_alloc.c`:
* **記憶體配置 (Allocation)**:`__alloc_pages()`呼叫 `rmqueue()` 來從 `free_area` 中找到合適的記憶體區塊。
```c=1744
__rmqueue_smallest(struct zone *zone, unsigned int order,
int migratetype)
{
unsigned int current_order;
struct free_area *area;
struct page *page;
/* 從請求的 order 開始,向上尋找第一個擁有空閒區塊 的 free_area */
for (current_order = order; current_order < NR_PAGE_ORDERS; ++current_order) {
area = &(zone->free_area[current_order]);
page = get_page_from_free_area(area, migratetype);
/**
* 1. 將 current_order 的區塊從 free_list 移除
* 2. 將其分割成兩個 order-1 的 buddy
* 3. 其中一個 buddy 會被放回 `order-1` 的 `free_list`,
* 另一個則繼續向下分割,直到達到請求的 `order`。
* (實作以 while loop 取代遞迴)
*/
page_del_and_expand(...);
...
return page;
}
return NULL;
}
```
* **記憶體釋放與合併 (Free & Coalescing)**:`__free_one_page()`:
```c=797
static inline void __free_one_page(struct page *page, ...,
unsigned int order, ...)
{
...
/**
* 實作以 while loop 取代遞迴,
* 將釋放的區塊與其 buddy 合併,並向上層 order 移動。
*/
while (order < MAX_ORDER - 1) {
...
/* 計算要釋放的 page 的 buddy 頁的實體記憶體位址 */
buddy = find_buddy_page_pfn(page, pfn, order, &buddy_pfn);
if ( /*buddy 不存在、非空閒、... */ )
goto done_merging; // 若 buddy 不可合併,直接跳出迴圈
...
/* 將 buddy 從它所在的 free_list 中移除,為稍後的合併做準備 */
__del_page_from_free_list(buddy, zone, order, ...);
...
/* 計算合併後的新區塊資訊 */
...
order++; // 準備進入下一輪迴圈
}
done_merging: /* 將最終的區塊加入到它最終歸屬的 order 的 free_list */
__add_to_free_list(page, zone, order, ...);
...
}
```
可以透過以下指令觀察 `buddy system` 的狀態:
```shell
$ cat /proc/buddyinfo
```
雖然 `buddy system` 有效地緩解了 External Fragmentation (外部碎片化),但以 page 為最小單位也帶來了 **Internal Fragmentation (內部碎片化)** 的問題。
---
## 3. 核心物件配置器:Slab Allocator 家族
### 3.1 Slab Allocator 的存在理由
* **引入 Slab 原因**:`buddy system` 以 Page (通常為 4KB) 為最小單位,對於 **核心中大量存在的小型資料結構** (如 inode、dentry 等) 而言,直接分配一個完整的 page 會造成巨大的浪費。
* **核心思想**:Slab 分配器像是記憶體的「零售商」。它先向 `buddy system`「批發」一個或多個連續的 Page (稱為一個 `slab`),然後在內部將其切割成許多大小相同的小物件 (`object`),再「零售」給核心的其他子系統。
### 3.2 設計哲學的演進:SLOB, SLAB, SLUB
Linux 核心歷史上存在三種 Slab 分配器的實作,各有其設計哲學與權衡:
1. **slob (Simple List of Blocks):為精簡而生**
* **設計理念**:盡可能緊實 (as compact as possible)。無內部碎片。
* **作法**:
* 僅維護幾個簡單的 `free list`。
* 配置時採用 `first-fit` 策略,在本質上容易產生嚴重的外部碎片化。
* **優缺點**:程式碼極為簡單,記憶體開銷小,但在多核環境下因全域鎖而效能不佳。
* **應用**:主要用於資源極度受限的嵌入式系統。

2. **slab:為快取友善 (Cache-Friendly) 而生**
* **設計理念**:盡可能對 CPU 快取友善 (as cache friendly as possible),在效能評測 (benchmark) 中表現優異。源於 Sun Microsystems 的 [Solaris 作業系統論文](http://static.usenix.org/event/usenix01/full_papers/bonwick/bonwick.pdf)。
* **作法**:
* 維護複雜的 queue 來追蹤物件的「冷熱」狀態。
* 為每個 CPU 設計了本地快取 (`per-CPU cache`) 以減少多核下的鎖競爭。
* **優缺點**:效能評測表現優異,但 queue 管理複雜,管理結構本身開銷較大,且對 `NUMA` 架構支援不佳。

```graphviz
digraph kmem_cache_layout {
// Global graph settings
rankdir=TB;
margin=0;
nodesep=0.5;
splines=polyline;
// Default node style
node [shape=box, style=filled, fillcolor=white, width="2", fontname="Helvetica", fontsize=18];
edge [color=black, arrowhead=vee, arrowsize=1.2, penwidth=2, fontsize=16];
// Cache chain and kmem_cache levels
cache_chain [label="cache_chain", fillcolor=lightblue, group=0];
kmem1 [label="kmem_cache", fillcolor="#87CE49", group=0];
kmem2 [label="kmem_cache", fillcolor="#87CE49", group=0];
kmem3 [label="kmem_cache", fillcolor="#87CE49", group=0];
temp2 [ label = "temp2", style = "invis" , group=0];
page_t [label="page", fillcolor=lightblue, group=0];
// Status nodes
full [label="full", fillcolor=yellow, group=1];
partial [label="partial", fillcolor=yellow, group=1];
empty [label="empty", fillcolor=yellow, group=1];
// Detailed page entries as HTML tables to mimic shading
node [shape=plaintext, margin=0];
entry1 [label=<
<TABLE BORDER="0" CELLBORDER="1" CELLSPACING="0" COLOR="white">
<TR>
<TD WIDTH="20" HEIGHT="25" BGCOLOR="black" port="portL"></TD>
<TD WIDTH="20" BGCOLOR="black"></TD>
<TD WIDTH="20" BGCOLOR="#D0D0D0"></TD>
<TD WIDTH="20" BGCOLOR="#D0D0D0"></TD>
<TD WIDTH="20" BGCOLOR="black"></TD>
<TD WIDTH="20" BGCOLOR="#D0D0D0"></TD>
</TR>
</TABLE>
>, group=2];
temp1 [ label = "temp1", style = "invis" , group=2];
entry2 [label=<
<TABLE BORDER="0" CELLBORDER="1" CELLSPACING="0" COLOR="white">
<TR>
<TD WIDTH="20" HEIGHT="25" BGCOLOR="#D0D0D0" port="portL"></TD>
<TD WIDTH="20" BGCOLOR="black"></TD>
<TD WIDTH="20" BGCOLOR="#D0D0D0"></TD>
<TD WIDTH="20" BGCOLOR="#D0D0D0"></TD>
<TD WIDTH="20" BGCOLOR="black"></TD>
<TD WIDTH="20" BGCOLOR="#D0D0D0" port="portR"></TD>
</TR>
</TABLE>
>, group=2];
entry3 [label=<
<TABLE BORDER="0" CELLBORDER="1" CELLSPACING="0" COLOR="white">
<TR>
<TD WIDTH="20" HEIGHT="25" BGCOLOR="black" port="portL"></TD>
<TD WIDTH="20" BGCOLOR="#D0D0D0"></TD>
<TD WIDTH="20" BGCOLOR="black"></TD>
<TD WIDTH="20" BGCOLOR="black"></TD>
<TD WIDTH="20" BGCOLOR="#D0D0D0"></TD>
</TR>
</TABLE>
>];
entry4 [label=<
<TABLE BORDER="0" CELLBORDER="1" CELLSPACING="0" COLOR="black">
<TR>
<TD WIDTH="70" HEIGHT="25" BGCOLOR="white" port="port1">Object</TD>
<TD WIDTH="50" BGCOLOR="white" port="port2">void*</TD>
<TD WIDTH="70" BGCOLOR="black" ><FONT COLOR="white">Object</FONT></TD>
<TD WIDTH="50" BGCOLOR="black" ><FONT COLOR="white">void*</FONT></TD>
<TD WIDTH="70" BGCOLOR="white" port="port5">Object</TD>
<TD WIDTH="50" BGCOLOR="white" port="port6">void*</TD>
<TD WIDTH="70" BGCOLOR="white" port="port7">Object</TD>
<TD WIDTH="50" BGCOLOR="white" port="port8">void*</TD>
<TD WIDTH="70" BGCOLOR="black" ><FONT COLOR="white">Object</FONT></TD>
<TD WIDTH="50" BGCOLOR="black" ><FONT COLOR="white">void*</FONT></TD>
<TD WIDTH="70" BGCOLOR="white" port="port11">Object</TD>
<TD WIDTH="50" BGCOLOR="white" port="port12">void*</TD>
</TR>
</TABLE>
>];
// Edges:chaining kmem_cache
cache_chain -> kmem1 -> kmem2 -> kmem3 [style="bold"];
kmem3 -> temp2 [style="invis"];
temp2 -> page_t [style="invis"];
// Edges to status nodes
kmem2:e -> full:w;
kmem2:e -> partial:w;
kmem2:e -> empty:w;
full:s -> partial:n [style="invis"];
partial:s -> empty:n [style="invis"];
// Partial links to page and free list
partial:e -> entry1:portL:w [label="partial", arrowhead=vee];
entry1:s -> temp1:n [style="invis"];
partial:e -> temp1:w [arrowhead=none];
temp1:w -> entry2:portL:n [label="freelist", arrowhead=vee];
partial:e -> entry2:portL:w [label="page", arrowhead=vee];
entry1:s -> entry2:n [style="invis"];
// Chain of page entries
entry2:portR:e -> entry3:portL:w [label="next", arrowhead=vee];
// splines=ortho;
page_t:e -> entry4:port1:s [label="freelist", constraint=false];
entry2:portL:sw -> entry4:port1:nw [arrowhead=none, style="dashed"];
entry2:portR:se -> entry4:port12:ne [arrowhead=none, style="dashed"];
kmem3 -> entry4:port1:nw [style="invis"];
entry4:port2:s -> entry4:port5:s [style="dashed"];
entry4:port6:s -> entry4:port7:s [style="dashed"];
entry4:port8:s -> entry4:port11:s [style="dashed"];
// Rank constraints
{ rank=same; kmem1; full; entry1;}
{ rank=same; kmem2; partial; temp1;}
{ rank=same; empty; entry2; entry3;}
{ rank=same; entry4; temp2;}
}
```
3. **slub (Unqueued Slab Allocator):為執行效率與簡潔而生**
* **設計理念**:相較於 SLAB,SLUB 選擇犧牲一些記憶體空間上的彈性 (例如不支援 object packing),以換取更簡潔的設計。其目標是提升真實世界的執行時間效能 (execution-time friendly) 與可維護性,並對 NUMA 架構提供更好的支援。
* **作法**:
* **簡化 Metadata**:`slub` 拋棄了 `slab` 複雜 queue 管理機制,**將大部分 slab 管理資訊 (如 `freelist` 指標) 直接儲存在 `struct page` 結構中**、或是 `slab` 自身未被使用的空間內,大幅減少了外部 metadata 所需的記憶體開銷。

* **關鍵資料結構**:
* **kmem_cache**:slab 配置器的主要描述符。
`mm/slab.h`
```c=258
struct kmem_cache {
struct kmem_cache_cpu __percpu *cpu_slab;
...
/* 定義一個特定大小與類型的 object cache */
unsigned int size; /* 含 metadata 的 object 大小 */
unsigned int object_size; /* 實際要求分配的大小 */
...
unsigned int offset; /* 用來取得下一個 free object */
...
int refcount; /* kmem_cache_destroy() 使用 */
void (*ctor)(void *object); /* Object 建構子 */
...
struct list_head list; /* List of slab caches */
...
/* 指向 各 CPU 的 slab 的節點,內含自己的 partial slab 列表 */
struct kmem_cache_node *node[MAX_NUMNODES];
};
```
* **kmem_cache_cpu**:每個 CPU 一份的本地快取。在多核心系統上,優先從此處分配,可以避免快取鎖競爭,並提升 cache hit rate。
`mm/slub.c`
```c=383
struct kmem_cache_cpu {
void **freelist; /* 指向 slab pool 中,下一個可用 object */
unsigned long tid; /* Globally unique transaction id */
struct slab *slab; /* 指向當前的活躍 slab */
...
};
```
* **kmem_cache_node**:對應 NUMA 節點的結構,每個節點會維護一個自己的 partial slab 列表 (`partial`),存放部分被使用的 slab。
```c=424
struct kmem_cache_node {
spinlock_t list_lock;
unsigned long nr_partial;
struct list_head partial;
...
};
```
* **初始化與引導 (Initialization & Bootstrap)**:
初始化 `kmem_cache` 本身存在一個「雞生蛋,蛋生雞」的問題:**為了管理 `kmem_cache` 物件,我們需要一個 `kmem_cache`**。核心採用了引導程式來解決。
* **建立與銷毀 Cache (`kmem_cache_create()` / `kmem_cache_destroy()`)**
* **建立 (create)**:當核心模組需要一個新的 object cache 時,會呼叫 `kmem_cache_create()` 巨集,導向函式 `__kmem_cache_create_args()`:負責處理建立快取的完整邏輯。
* **銷毀 (destroy)**:銷毀時會減少其引用計數 (refcount)。當計數歸零,便呼叫 `__kmem_cache_shutdown()` 釋放所有相關的 slab page 回到 buddy system。
* **分配流程 (`kmem_cache_alloc()`)**:SLUB 的分配流程遵循一個清晰的層級結構,以追求最高效率。其入口函式 (`kmem_cache_alloc()` -> `slab_alloc_node()`) 是一個內聯函式,將快速路徑直接整合到呼叫端,避免了函式呼叫的開銷。
1. **快速路徑 (Fast Path)**:此路徑在 `__slab_alloc_node()` 中實現。它會嘗試直接從當前 CPU 的 `kmem_cache_cpu` 中取得一個 object。這是一個無鎖 (lockless) 操作,透過原子性的 `cmpxchg` 指令更新 `freelist` 指標,效率極高。絕大多數的記憶體分配都在此完成。
2. **慢速路徑 (Slow Path)**:若 CPU 本地快取已空 (`freelist == NULL`)、或當前 slab 不符合 NUMA 節點要求,則會進入由 `___slab_alloc()` 函式處理的慢速路徑。
* **釋放流程 (`kmem_cache_free()`)**:釋放是分配的逆向過程,同樣以效率為優先,區分了快速與慢速路徑。其入口為 `kmem_cache_free()`,核心邏輯在 `do_slab_free()` 中決定路徑。
1. **快速路徑 (Fast Path)**:此路徑的觸發條件是:**被釋放的物件 (`object`) 正好隸屬於當前 CPU 的活躍 slab (`c->slab`)**。這是最高頻且效率最佳的情況 (例如,剛分配就釋放)。系統會透過一個無鎖的原子操作,直接將物件加回當前 CPU 的 `freelist` 的頭部,無需任何鎖競爭。絕大多數的釋放操作都在此完成。
2. **慢速路徑 (Slow Path)**:若物件不屬於當前 CPU 的活躍 slab,則必須進入由 `__slab_free()` 函式處理的慢速路徑。此路徑的核心是將物件安全地歸還給它原本的 `slab`,並根據歸還後 `slab` 的狀態,決定下一步操作。
> 詳細操作的程式碼過於佔篇幅,移至 [Slub 的操作](https://hackmd.io/@Jaychao2099/slub_op)。
* **應用**:由於其設計簡潔、效能卓越且對多核架構友好,SLUB 已成為目前 Linux 核心的 **預設** 記憶體分配器。
> 延伸閱讀:[slab 記憶體配置器](https://hackmd.io/@sysprog/linux-slab) - jserv
### 3.3 Hoard Allocator:使用者空間的經典設計借鏡
[Hoard](http://hoard.org/) 是一個為 multi-thread 應用設計的 **高效能、高可擴展性** 的 **user space 記憶體配置器**。儘管它運作於 user space,但其精巧的設計思想,特別是在處理並行 (concurrency)、鎖競爭 (lock contention) 和快取行為 (cache behavior) 方面的策略,對於理解 Linux 核心中如 `slab` 和 `slub` 等現代配置器的演進非常有啟發。
#### 核心挑戰 (Core Challenges)
在深入 Hoard 的設計之前,必須先理解一個高效能記憶體配置器需要應對的四大核心挑戰:
1. **記憶體碎片化 (Fragmentation)**:分為**內部碎片 (Internal)** (配置的區塊大於請求大小造成的浪費) 與**外部碎片 (External)** (大量不連續的小塊可用空間無法滿足較大的配置請求)。
2. **配置與釋放延遲 (Allocation and Free Latency)**:`malloc` 和 `free` 操作本身的速度。在多核心環境下,這與鎖的競爭和同步機制 (Synchronization) 息息相關。
3. **實作複雜度 (Implementation Complexity)**:一個過於複雜的配置器難以維護與除錯。
4. **快取行為 (Cache Behavior)**:配置器如何與 CPU 的快取階層互動,直接影響效能。不佳的設計會導致 **錯誤共享 (False Sharing)**,嚴重拖慢系統速度。
:::success
Hoard 的設計就是為了在這些相互衝突的目標之間取得一個巧妙的平衡。
:::
#### Hoard 的核心設計與策略
Hoard 的架構主要圍繞著 `Superblocks` 和分層的 `Heaps` 概念。
1. **Superblocks**:記憶體區塊化管理
`Superblock` 是 Hoard 管理記憶體的基本單位,其概念與 `slab` 相似。
* **結構**:一個 `Superblock` 是由一或多個從 OS 取得的、**虛擬記憶體上連續的 page** 組成的大區塊。
* **同質化物件**:一個 `Superblock` 內部會被切分成許多大小 **完全相同** 的物件 (object)。簡化了管理,但也是 Internal Fragment 的來源。
* **依大小分類**:Hoard 會維護多種類型的 `Superblock`,每種類型對應一種物件大小。為了簡化管理並將 Internal Fragment 控制在一定範圍內 (例如 < 50%),物件大小通常會向上取整到 2 的冪次方。
> 例如,一個 5-byte 的請求會從一個存放 8-byte 物件的 `Superblock` 中獲得空間。
* **可用列表 (Free List)**:每個 `Superblock` 內部都維護一個可用物件的 linked-list,並採用 **LIFO (後進先出)** 順序。這個串列的指標直接儲存在可用的物件空間內,無需額外空間。
2. **分層的 Heap**:Per-CPU 與 Global
* **分層的 Heap 設計**:應對多核心環境下的鎖競爭。
* **Per-CPU Heaps**:每個 CPU 核心都擁有一個獨立的本地 Heap。大部分的配置和釋放操作都在這個本地 Heap 中完成,由於只有該 CPU 會存取,因此**幾乎沒有鎖競爭**。
* **Global Heap**:系統中存在一個所有 CPU 共享的全域 Heap。
* **配置流程**:
1. **嘗試本地**:當一個 thread 需要記憶體時,它首先會在其對應的 Per-CPU Heap 中尋找合適的 `Superblock` 來配置。
2. **求助全域**:如果本地 Heap 中沒有可用的空間,它會嘗試從 Global Heap 中取得一個閒置的 `Superblock`,並將其納入自己的本地 Heap。
3. **向 OS 申請**:如果連 Global Heap 都是空的,配置器才會透過 `mmap()` 向作業系統申請新的 page 來建立一個全新的 `Superblock`。
* **作用**:確保了在通用情況下,thread 總是在無競爭的本地環境中運作,**只有在資源耗盡時才需要存取有鎖的 Global Heap**,大幅提升了擴展性。
3. **Allocation (配置) 與 Free (釋放) 流程**:
* **配置 (`malloc`)**:
1. 根據請求大小,找到對應的 `Superblock` 類型 (例如,請求 200 bytes,會找到管理 256-byte 物件的 `Superblock`)。
2. 從該 `Superblock` 的 LIFO Free List 中彈出 (pop) 一個可用物件並返回。
3. 若 `Superblock` 為空,則遵循前述的「本地 $\rightarrow$ 全域 $\rightarrow$ OS」流程。
* **釋放 (`free`)**:
1. Hoard 透過一個極為高效的數學技巧來定位物件所屬的 `Superblock`。假設 `Superblock` 大小為 8KB ($2^{13}$ bytes) 且總是 page alignment,對於一個給定的物件位址,只需將其**低 13 位元遮罩 (mask out)**,即可立即得到其所屬 `Superblock` 的 base address。
2. 將釋放的物件推入 (push) 該 `Superblock` 的 LIFO Free List 中。

4. **LIFO 的理由:快取局部性 (Cache Locality)**:
> [!tip] 採用 LIFO 策略是基於對 CPU cache 的深刻理解:
> 一個剛被釋放的物件,其所在的記憶體位置很可能仍然是 **熱的 (hot)**,也就是說它還存在於 CPU 的 L1 或 L2 快取中。立即將其重新配置給下一個請求,可以避免昂貴的從主記憶體重新載入資料到快取的延遲,從而提升效能。
5. **鎖定 (Locking) 與並行處理 (Concurrency)**:
雖然 Per-CPU Heap 的設計大幅減少了競爭,但 **鎖依然是必要的**。關鍵在於:**一個在 CPU A 上配置的物件,完全有可能在 CPU B 上被釋放**。當 CPU B 要釋放一個屬於 CPU A 的物件時,它必須:
1. 找到物件所屬的 `Superblock` (透過位元遮罩)。
2. 從 `Superblock` 的 metadata 中得知它屬於 CPU A 的 Heap。
3. **鎖定 CPU A 的 Heap**,然後安全地將物件放回 Free List。
雖然這引入了跨核心的鎖定,但 Hoard 的設計 **確保了這種情況相對不頻繁**,且遠勝於所有 CPU 競爭一個全域鎖的傳統作法。
6. **快取一致性 (Cache Coherence) 與 錯誤共享 (False Sharing) 的應對**:
>[!Caution] **錯誤共享 (False Sharing)** 是多核心程式設計的效能殺手:
> 當兩個不同 CPU 上執行的 thread,各自存取不同的資料,但這些資料恰好位於同一個 Cache Line 時,一個 CPU 的寫入操作會導致另一個 CPU 的 Cache Line 失效,**即使後者根本不關心被寫入的資料**。這會**引發不必要的 cache synchronization 和 Memory bus 流量**,造成效能急劇下降。
* **Hoard 的應對**:
* **空間隔離**:Per-CPU Heap 的設計從根本上讓不同 CPU 的配置操作發生在不同的記憶體區域 (`Superblock`),自然地避免了將一個新的 Cache Line 同時分配給多個 CPU。
* **歸還原主**:將釋放的物件歸還到它 **原始的 `Superblock`**,確保了來自不同 thread 的、生命週期交錯的物件不會被混雜在同一個 `Superblock` 中,從而降低了未來發生 False Sharing 的機率。
---
## 4. 核心虛擬記憶體區塊配置
### 4.1 kmalloc vs. vmalloc:組合肉的藝術
當核心需要記憶體時 (自己使用),主要有兩個 API 可供選擇:
| API | 實體記憶體 | 虛擬記憶體 | 主要用途與限制 |
| :-- | :--- | :--- | :--- |
| `kmalloc` | **保證連續** | 連續 | 由 `buddy system` 直接分配。適用於大多數核心配置,特別是需要 `DMA (Direct Memory Access)` 的場景,因為 DMA 控制器通常需要實體連續的記憶體。 |
| `vmalloc` | **不保證連續** | **保證連續** | <ol><li>當需要大塊記憶體但 `kmalloc` 因找不到足夠大的 **實體連續** 空間而失敗時使用。</li><li>`vmalloc` 會在實體上不連續的 Page 中分配記憶體,然後透過修改 **核心的 Page Table**,將這些分散的實體page對應到一段連續的虛擬位址空間。就像將許多「碎肉渣」黏合成一塊完整的「組合肉」。</li><li>不適用於需要實體連續的 DMA。</li></ol>|
一般策略是,小於 128 KB 的請求使用 `kmalloc()`,大於此值的則考慮使用 `vmalloc()`。
```graphviz
digraph kmem_cache_layout {
size="4!";
rankdir=TB;
margin=0;
nodesep=0.5;
splines=spline;
// Default node style
node [shape=box, style=filled, fillcolor=white, width="2", fontname="Helvetica", fontsize=18];
edge [color=black, arrowhead=vee, arrowsize=1.2, penwidth=2, fontsize=16];
// Cache chain and kmem_cache levels
cr3 [label="cr3", fillcolor="#FF9797", group=0];
vm_struct [label="vm_struct", fillcolor="#FF9797", group=0];
// Detailed page entries as HTML tables to mimic shading
node [shape=plaintext, margin=0];
pgd [label=<
<TABLE BORDER="0" CELLBORDER="1" CELLSPACING="0" COLOR="white">
<TR>
<TD WIDTH="70" HEIGHT="25" BGCOLOR="#87CE49">pgd_t</TD>
<TD WIDTH="70" BGCOLOR="#87CE49">pgd_t</TD>
<TD WIDTH="70" BGCOLOR="#87CE49">pgd_t</TD>
<TD WIDTH="70" BGCOLOR="#87CE49">pgd_t</TD>
</TR>
</TABLE>
>, group=1];
pages [label=<
<TABLE BORDER="0" CELLBORDER="1" CELLSPACING="0" COLOR="white">
<TR>
<TD WIDTH="90" HEIGHT="25" BGCOLOR="#87CE49" port="port1">page</TD>
<TD WIDTH="90" BGCOLOR="#87CE49" port="port2">page</TD>
<TD WIDTH="90" BGCOLOR="#87CE49" port="port3">page</TD>
<TD WIDTH="90" BGCOLOR="#87CE49" port="port4">page</TD>
</TR>
</TABLE>
>, group=1];
mem [label=<
<TABLE BORDER="0" CELLBORDER="1" CELLSPACING="0" COLOR="white">
<TR>
<TD WIDTH="40" HEIGHT="25" BGCOLOR="yellow"></TD>
<TD WIDTH="30" BGCOLOR="#003D79" port="port1"></TD>
<TD WIDTH="70" HEIGHT="25" BGCOLOR="yellow"></TD>
<TD WIDTH="30" BGCOLOR="#003D79" port="port2"></TD>
<TD WIDTH="50" HEIGHT="25" BGCOLOR="yellow"></TD>
<TD WIDTH="30" BGCOLOR="#003D79" port="port3"></TD>
<TD WIDTH="60" HEIGHT="25" BGCOLOR="yellow"></TD>
<TD WIDTH="30" BGCOLOR="#003D79" port="port4"></TD>
<TD WIDTH="30" HEIGHT="25" BGCOLOR="yellow"></TD>
</TR>
</TABLE>
>, group=1];
cr3:s -> vm_struct:n [style="invis"];
cr3:e -> pgd:w;
vm_struct:s -> pages:w [label="pages"];
pgd:s -> pages:n [style="invis"];
pages:port1:s -> mem:port1:n [style="dashed"];
pages:port2:s -> mem:port2:n [style="dashed"];
pages:port3:s -> mem:port4:n [style="dashed"];
pages:port4:s -> mem:port3:n [style="dashed"];
{ rank=same; cr3; pgd;}
// { rank=same; vm_struct; pages;}
}
```
`include/linux/vmalloc.h`
```c=52
struct vm_struct {
struct vm_struct *next;
...
struct page **pages; // page 列表
unsigned int nr_pages; // page 數量
...
};
```
<center><img src="https://hackmd.io/_uploads/ByO3dbq_-g.png" alt="image" width="80%" /></center>
---
## 5. 使用者空間與核心空間的互動
### 5.1 malloc 的底層實作
當你在 User Space 呼叫 `malloc()` 時,它並不是一個直接的系統呼叫,而是由 C 標準函式庫 (如 glibc) 提供的函式。glibc 的 `malloc()` 實作會根據申請記憶體的大小採取不同策略:
* **小塊記憶體**:透過 `brk()` 或 `sbrk()` 系統呼叫,移動 `heap` 的頂端指標 (`program break`) 來擴展堆空間。glibc 內部會維護自己的 memory pool 來管理這些小塊分配,以避免頻繁陷入核心。
* **大塊記憶體**:當申請的記憶體超過某個閾值 (如 128KB) 時,glibc 會轉而使用 `mmap()` 系統呼叫,向核心申請一段匿名的私有映射空間。
### 5.2 Page Cache 與檔案 I/O 的深層連結
當應用程式讀寫檔案時,為了提升效率,Linux 並不會讓每次 I/O 操作都直接存取 Disk。相反,它會 **利用主記憶體的一部分** 作為 **Page Cache (頁面快取)**。
#### 統一的抽象:Address Space
Linux 透過 `address_space` 這一抽象概念來統一管理所有可以被 paging 的物件。無論是行程的匿名記憶體 (`anon_vma`),還是檔案的內容 (`inode`),它們都被視為一個 `address_space`。這個 `address_space` 內部的資料被切割成一個個 `page`。
#### 追蹤檔案分頁:Radix Tree
當一個檔案的內容被讀入記憶體時,核心需要一個高效的資料結構來追蹤「檔案的第 N 個位移量」對應到「哪一個實體的 Page Frame」。Page Table 不適用於此,因為檔案可能非常巨大。Linux 在此使用了 `Radix Tree`。
`Radix Tree` 是一種空間優化的 `Trie`,非常適合用來儲存稀疏的、以整數 (此處是 page index) 為 key value 的對應關係。能以接近 $O(1)$ (取決於樹高) 的時間快速查找到特定檔案位移對應的 page。
<center>
<img src="https://hackmd.io/_uploads/BkSfdzyEge.png" alt="radix" width="55%" />
</center>

#### Dirty Page 與非同步 write back
1. 當應用程式寫入檔案時,資料通常只會被寫入 Page Cache,同時該 page 在 `Radix Tree` 中會被標記為 **Dirty**。
2. 核心並不會立即將其寫回 Disk,而是由一個稱為 `pdflush` 的 kernel thread (或其後繼者) 在稍後 (通常 > 30 秒?) 非同步地將這些 Dirty Page 寫回。
3. 應用程式也可以透過 `fsync()` 或 `fdatasync()` 系統呼叫來強制立即 write back。

#### 解決區塊大小不匹配:Buffer Head
* **問題**:Disk 的 `block size` (如 512 bytes) 和記憶體的 `page size` (如 4KB) 通常不匹配。如果只修改了一個 page 中的一小部分,寫回整個 4KB 的 page 是沒有效率的。
* **解決**:核心為每一個被快取的 page 引入 `buffer_head` 結構。一個 4KB 的 page 會對應到 8 個 `buffer_head` (每個代表 512 bytes)。當寫入發生時,只有對應的 `buffer_head` 會被標記為 dirty,write back 時也只會寫入被標記的區塊。
<center>
<img src="https://hackmd.io/_uploads/S1Zf6fyVle.png" alt="image" width="60%" />
</center>
> [!tip]**mmap 的特殊情況:為何會標記所有 `buffer_head`?**
>
> 上述的精準標記只適用於 `write()` 這類系統呼叫,因為 **核心無法知道** 使用者究竟修改了透過 `mmap()` 映射的記憶體分頁中的哪一個 byte。
> * **`write()` 的場景**:使用 `write()` 時,向核心提供了完整的資訊 (要寫入的資料和長度)。核心擁有 **byte 級別的精確資訊**。
> * **`mmap()` 的場景**:修改 `mmap()` 映射的記憶體時,這是一個在 user space 的直接記憶體存取操作,核心並不知情。核心只能透過硬體產生的 **Page Fault (以整個 page 為單位)** 來被動感知到「這個 page 被寫入了」。由於硬體無法告知是 page 中的「哪個 byte」被修改,核心只能採取 **最保守但安全的策略**:假設整個 page 都已被修改。
> **延伸閱讀**:[第六講:不僅是個執行單元的 Process - 記憶體管理相關機制](https://hackmd.io/@Jaychao2099/Linux-kernel-6#%E8%A8%98%E6%86%B6%E9%AB%94%E7%AE%A1%E7%90%86%E7%9B%B8%E9%97%9C%E6%A9%9F%E5%88%B6)
### 5.3 現代的 user space 配置器 (jemalloc, tcmalloc, mimalloc)
隨著多核處理器和大規模雲端應用的普及,傳統的 `glibc malloc` 在高併發場景下有時會成為效能瓶頸。為此,業界巨頭開發了更高效能的記憶體配置器:
* **[tcmalloc (Thread-Caching Malloc)](https://github.com/google/tcmalloc)**:由 Google 開發,核心思想是為每個 thread 提供一個本地快取,極大地減少了 thread 之間的鎖競爭。
* **[jemalloc](https://github.com/jemalloc/jemalloc)**:由 Jason Evans 開發,並被 Facebook 大量採用與支持。它在 `tcmalloc` 的基礎上,對空間利用率和避免碎片化做了更多優化,旨在實現可預測的效能。
* **[mimalloc](https://github.com/microsoft/mimalloc)**:由 Microsoft Research 開發,其設計目標是成為一個 **完全無鎖 (lock-free)** 的通用記憶體配置器,透過精巧的設計避免了傳統配置器在高併發下的鎖爭用問題,並在多種真實世界的應用負載下展現出優異的效能。
這些現代配置器通常可以透過 `LD_PRELOAD` 機制在不重新編譯應用程式的情況下替換掉系統預設的 `malloc`,從而直接提升效能。
---
## 6. 記憶體回收與交換機制
### 6.1 核心問題:當記憶體不足時
現代作業系統 (如 Linux) 的設計精髓在於高效地管理有限的實體資源,以滿足近乎無限的應用程式需求。記憶體管理是其中最具挑戰性的一環。當系統中所有可用的實體記憶體 (Physical Memory) 都被佔用,而又有新的記憶體請求時,核心 (Kernel) 必須啟動 **記憶體回收 (Memory Reclaiming)** 機制。
這個機制的核心目標是:在對系統效能影響最小的前提下,智慧地釋放出一些目前「價值較低」的 Page Frame,以供新的、更重要的任務使用。
### 6.2 基本策略:Overcommit 與 Swap
為了最大化記憶體利用率,Linux 核心採用了幾項關鍵策略:
#### 1. Overcommit (過度承諾)
* **概念**:Linux 核心預設允許系統中所有行程 (Process) 申請的虛擬記憶體 (Virtual Memory) 總量可以遠大於實際可用的實體記憶體。
* **動機**:基於一個重要的經驗觀察——「**多數程式在申請了大量記憶體後,並不會立即或同時使用所有部分**」。這個被稱為 **Lazy Allocation** 的指導原則,避免了因程式一次性申請大塊記憶體而導致的「假性」記憶體耗盡,從而顯著提高了實體記憶體的利用效率。
* **系統調校**:可透過修改 `/proc/sys/vm/overcommit_memory` 檔案來調整:
* `0` (預設值):heuristic 演算法,通常會允許合理的 Overcommit,但會拒絕明顯會耗盡記憶體的巨大請求。
* `1`:永遠允許 Overcommit,核心對記憶體申請「照單全收」。
* `2`:永不允許 Overcommit,已分配的虛擬記憶體總量不能超過 `Swap 空間 + 指定比例的實體記憶體`。
#### 2. Swap (交換空間)
* **概念**:為了支撐 Overcommit 機制,當實體記憶體壓力過大時,核心會選擇一些「最不常用」的 page (通常是 **anonymous (匿名) page**),將其內容暫時寫入到 disk 上一個被稱為 **Swap 空間** 的特定分割區或檔案中,然後將該實體 Page Frame 釋放出來給其它程式使用。
* **運作流程**:
* **Swap Out (換出)**:
1. 核心將一個 Page 的內容寫入 Swap 空間。
2. 透過 **RMAP** 找到所有指向該實體 page frame 的 PTE,並清除其 `PTE_P` (Present) 位元,使其失效。
3. 成功釋放該 Page Frame 以供他用。
* **Swap In (換入)**:
1. 當 process 再次嘗試存取已被換出的 Page 時,由於其對應的 Page Table Entry (`PTE_P` 位元) 已被標記為「不存在 (Not Present)」,會觸發一次 **Major Page Fault**。
2. 核心會中斷 process,從 Swap 空間將 Page 內容重新讀回一個 **新的** 實體 Page Frame,更新 page table 映射,然後才讓 process 繼續執行。
### 6.3 Page Frame 的回收:分類與策略
當核心決定要回收記憶體時,它首先需要對系統中所有的 Page 進行分類,以決定回收的優先順序。
#### Page 的類型
1. **Unreclaimable (不可回收)**:
* 核心自身運作必需的 Page
* 被 process 鎖定 (pinned) 的 Page
* 正在進行 I/O 操作的 Page
2. **Syncable (可同步/可丟棄)**:指 **Page Cache** 中的內容,即檔案資料的記憶體快取。
* **Page 是乾淨的 (Clean,未被修改)**:核心可以直接 **丟棄** 它。
* **Page 是髒的 (Dirty,已被修改)**:核心必須先將其內容 **同步 (sync)** 寫回disk,才能釋放它。
3. **Swappable (可交換)**:**匿名記憶體頁 (Anonymous Pages)**,沒有對應的後備檔案,因此在回收前 **必須被 Swap Out 到 Swap 空間**。
* process 的 Stack、Heap
* 透過 `mmap()` 建立的私有匿名映射
* `tmpfs`
* 共享記憶體 (shared IPC memory)
4. **Discardable (可拋棄)**:某些快取分配器中未使用的 page,可直接拋棄。
#### 回收策略
核心會基於 **LRU (Least Recently Used)** 的近似演算法來選擇回收對象。系統維護著兩個主要的 Page 列表:
* **Active List**:存放近期被頻繁存取的「熱」頁。
* **Inactive List**:存放很久未被存取的「冷」頁。
核心主要會從 `Inactive List` 的尾端開始掃描,尋找最佳的回收候選者。
> [!tip]**核心如何偵測 Page 是否被使用?**
> * **硬體輔助**:PTE 中的 **Access Bit**:
> * 當 CPU 存取某個 Page 時,硬體會自動設定這個位元。
> * 核心會週期性地清除所有 Page 的 Access Bit,稍後再回來檢查。
> * **狀況一**:當一個 page 的 Access Bit 被設定,表示它在近期被存取過 (熱的),它會被移至 `active list` 的頭部。
> * **狀況二**:下一輪掃描時,該位元沒有被重新設定,表示它在近期未被存取 (冷的),可以將其從 `active list` 移至 `inactive list`,成為回收的優先候選者。
### 6.4 核心挑戰:Reverse Mapping (RMAP)
當核心從 Inactive List 中選定一個實體 Page Frame 準備回收時,面臨一個挑戰:
> **「這個實體的 Page Frame,被系統對應到哪些 process 的哪些虛擬位址?」**
回答這個問題的過程,就稱為 **Reverse Mapping (RMAP)**。這之所以困難,因為一個實體 page 可能被多個行程透過 Copy-on-Write 機制共享。如果核心要 Swap Out 這個共享的 Page,它必須有能力找到 **所有指向這個實體 Page 的 PTE,並將它們全部標記為「不存在」**,否則系統狀態將會錯亂。
早期的 Linux 核心缺乏高效的 RMAP 機制,在記憶體壓力大時,只能透過遍歷所有 process 的頁表來尋找,效能極差。後續版本引入了精密的資料結構來高效地追蹤這些反向映射關係:
#### 1. 匿名頁的反向映射 (Anonymous Page RMAP)
對於 process 的 Heap、Stack 等匿名 page,Linux 使用 `anon_vma` 結構來管理。
* 當一個匿名 page 被首次映射時,核心會建立一個 `anon_vma` 結構。
* process 的 `VMA` 和該 page 對應的 `page descriptor` 都會指向這個 `anon_vma`。
* `anon_vma` 內部使用一個環狀鏈結串列 (circular linked list) 或 紅黑樹 (RB tree),將所有共享此 page 的 VMA 串連起來。
* 當需要回收此 page 時,核心只需 **走訪 `anon_vma` 中的linked-list 或 RB tree**,就能快速找到所有相關的 VMA 並解除映射 (unmap)。

> 在 page descriptors 下,會有兩個欄位紀錄 physical page 的屬性:
> `include/linux/mm_types.h`
> ```c=73
> struct page {
> ...
> struct address_space *mapping;
> ...
> atomic_t _mapcount;
> ...
> }
> ```
> * **`mapping`**:可能指向 address_space 結構 (file/device) 或 anon_vma (anonymous),least significant bit 會紀錄這個屬性 (1 == 指向 anon_vma)。
> * **`_mapcount`**:紀錄有多少共享的 vma。-1 表示未被映射,0 表示只有一個映射,1 以上則表示分享的數量。
> [!note]COW 帶來的挑戰與 `anon_vma` 的演進
最初的 `anon_vma` 設計在處理寫入時複製 (Copy-on-Write, COW) 時會有效能上的缺陷。
> **問題根源**:一個 `anon_vma` 會串連起所有 **曾經** 共享同一個匿名頁的 VMA。
> **問題場景**:
> 1. 父行程 `fork()`,此時父、子行程的 VMA 都被加入到同一個 `anon_vma` 的 linked list 中,共享同一個實體 page。
> 2. 子行程對該 shared page **寫入**,觸發 COW。
> 3. 核心為子行程分配一個 **新的實體 page**,並更新子行程的page table。
> 4. **缺陷**:此時,**舊的實體 page** 所關聯的 `anon_vma` linked list 中,**依然包含著子行程的 VMA**。當核心未來想要回收這個舊的實體 page 時,它依然會去遍歷一個實際上已經與此 page 無關的 VMA (子行程的 VMA),造成了不必要的效能浪費。
>
> **解決方案:引入中介層 `anon_vma_chain` (AVC)**
> `include/linux/rmap.h`
> ```c=83
> struct anon_vma_chain {
> struct vm_area_struct *vma; // 指向它所屬的 VMA
> struct anon_vma *anon_vma; // 指向它「訂閱」的 anon_vma
> struct list_head same_vma; // 將同一個 VMA 的所有 AVC 串起來
> struct rb_node rb; // 作為紅黑樹的一個節點,被插入到 anon_vma 的樹中
> ...
> };
> ```
> * **核心思想**:**增加一層間接性**,以極低的成本來斷開共享關係。
> * **結構演變:**
> * **舊設計**:`VMA -> anon_vma` (一個 VMA 直接指向一個共享的 anon_vma)
> * **新設計**:`VMA -> anon_vma_chain (AVC) -> anon_vma` (一個 VMA 指向一個 **私有的** AVC,再由 AVC 指向共享的 anon_vma)
> ```graphviz
> digraph memory_layout {
> size="4!";
> rankdir=TB;
> fontsize=12;
> node [shape=box, style=filled, fillcolor=white, width="2", fontname="Helvetica", fontsize=18];
> edge [penwidth=3];
> pdesc [shape=plaintext, margin=0, label=<
> <TABLE BORDER="0" CELLBORDER="1" CELLSPACING="0" COLOR="black">
> <TR>
> <TD COLSPAN="3" BORDER="0" ALIGN="CENTER">Physical page descriptors</TD>
> </TR>
> <TR>
> <TD WIDTH="180" HEIGHT="25" BGCOLOR="white"></TD>
> <TD WIDTH="20" BGCOLOR="#3670b7"></TD>
> <TD WIDTH="180" BGCOLOR="white"></TD>
> </TR>
>
> </TABLE>
> >];
> anon [label="anon\nvma", shape=hexagon, width=1, fillcolor="#59DAD1", color="#5daacd"];
> avcA [label="anon_vma_chain\n(AVC)", shape=ellipse];
> rbtree [label="rb_root", shape=ellipse];
> avcB [label="anon_vma_chain\n(AVC) (fork)", shape=ellipse];
> vmaA [shape=trapezium, label="vma", fillcolor="#aac46c", color=olivedrab];
> vmaB [shape=trapezium, label="vma (fork)", fillcolor="#aac46c", color=olivedrab];
> ptA [shape=plaintext, margin=0, label=<
> <TABLE BORDER="0" CELLBORDER="1" CELLSPACING="0" COLOR="black">
> <TR>
> <TD WIDTH="70" HEIGHT="25" BGCOLOR="white"></TD>
> <TD WIDTH="20" BGCOLOR="#3670b7" port="LA"></TD>
> <TD WIDTH="60" BGCOLOR="white"></TD>
> </TR>
> </TABLE>
> >];
> vm [label="Virtual memory", color="white"];
> ptB [shape=plaintext, margin=0, label=<
> <TABLE BORDER="0" CELLBORDER="1" CELLSPACING="0" COLOR="black">
> <TR>
> <TD WIDTH="90" HEIGHT="25" BGCOLOR="white"></TD>
> <TD WIDTH="20" BGCOLOR="#3670b7" port="LA"></TD>
> <TD WIDTH="40" BGCOLOR="white"></TD>
> </TR>
> </TABLE>
> >];
> phys [shape=plaintext, margin=0, label=<
> <TABLE BORDER="0" CELLBORDER="1" CELLSPACING="0" COLOR="black">
> <TR>
> <TD WIDTH="180" HEIGHT="25" BGCOLOR="white"></TD>
> <TD WIDTH="20" BGCOLOR="#3670b7" port="PA"></TD>
> <TD WIDTH="180" BGCOLOR="white"></TD>
> </TR>
> <TR>
> <TD COLSPAN="3" BORDER="0" ALIGN="CENTER">Physical memory</TD>
> </TR>
> </TABLE>
> >];
> pdesc -> anon [color=olivedrab, arrowhead=normal];
> anon -> rbtree [color="#59DAD1", arrowhead=normal];
> rbtree -> avcA;
> rbtree -> avcB;
> anon -> avcA [style=invis];
> anon -> avcB [style=invis];
> vmaA -> avcA [color=olivedrab, arrowhead=normal];
> avcA -> vmaA [color=olivedrab, arrowhead=normal];
> avcA:n -> anon [color=mediumpurple, arrowhead=normal, dir=backward];
> vmaB -> avcB [color=olivedrab, arrowhead=normal];
> avcB -> vmaB [color=olivedrab, arrowhead=normal];
> avcB:n -> anon [color=mediumpurple, arrowhead=normal, dir=backward];
> vmaA:s -> ptA:LA:nw [color=slateblue, arrowhead=normal];
> vmaA:s -> ptA:LA:ne [color=slateblue, arrowhead=normal];
> vmaB:s -> ptB:LA:nw [color=slateblue, arrowhead=normal];
> vmaB:s -> ptB:LA:ne [color=slateblue, arrowhead=normal];
> ptA:LA:s -> phys:PA:n [label="Page Tables", color=slateblue, arrowhead=normal];
> ptB:LA:s -> phys:PA:n [label="Page Tables", color=slateblue, arrowhead=normal];
> ptA:e -> vm:w [style="invis"];
> vm:e -> ptB:w [style="invis"];
> { rank = same; avcA; avcB; }
> { rank = same; vmaA; vmaB; }
> { rank = same; ptA; ptB; vm; }
> { rank = sink; phys; }
> }
> ```
> **COW 場景下的新運作流程:**
> 1. **初始共享**:`fork()` 時,父、子行程的 VMA 各自獲得一個私有的 `anon_vma_chain` (AVC),但這兩個 AVC 都指向 **同一個 `anon_vma`**,代表它們依然共享著 page。
> 2. **COW 發生**:當子行程觸發 COW 時:
> 1. 核心為子行程分配一個 **新的實體 page** 和一個 **新的 `anon_vma`**。
> 2. 核心只需 **修改子行程 VMA 指向的 AVC**,讓這個 AVC 轉而指向新的 `anon_vma`。
> * **關鍵:父行程的 VMA 和其 AVC 完全不受影響。** 它們依然維持著指向舊 `anon_vma` 的關係。
>
> **帶來的效益:**
> * **精準的反向映射**:當核心要回收父行程的 **舊實體 page** 時,它會遍歷與之關聯的舊 `anon_vma` 的資料結構 (紅黑樹)。
> 1. 對每一個找到的 `anon_vma_chain` (AVC) 進行 **驗證**,檢查其內部的 `anon_vma` 指標是否仍指向當前的 `anon_vma`。
> 2. 子行程的 `AVC` 會 **驗證失敗** (COW 時,已被修改指向了新的 `anon_vma`)。
> 3. 識別出無效的「過期」連結,**跳過對子行程的操作,並將其從樹中安全移除**。
> 4. 最終,只有那些驗證成功的、真正還在映射此頁的 VMA (例如父行程自己) 會被處理。
> * **低廉的 COW 成本**:斷開共享關係的成本極低。核心只需修改子行程私有的 AVC 結構中的一個指標,而無需對可能被大量行程共享的 `anon_vma` 資料結構進行複雜且需要全局鎖定的修改,大幅提升了系統在 `fork()` 和 COW 密集場景下的效能。
>
> `nclude/linux/mm_types.h`
> ```c=779
> struct vm_area_struct {
> ...
> /* VMA 覆蓋 [vm_start; vm_end) 的 virtual address */
> unsigned long vm_start;
> unsigned long vm_end;
> ...
> struct mm_struct *vm_mm; // 所屬的 address space
> ...
> struct list_head anon_vma_chain; // 所屬的 AVC
> struct anon_vma *anon_vma;
> ...
> struct file * vm_file; // 檔案映射
> ...
> }
> ```
> > 延伸閱讀:[The case of the overly anonymous anon_vma](https://lwn.net/Articles/383162/)
#### 2. 檔案頁的反向映射 (File Page RMAP)
##### 問題:檔案映射比匿名映射更複雜
1. **部分映射**:process 通常只映射檔案的一部分,而非整個檔案。**線性掃描所有 VMA 會有很多無效的過濾操作**。
2. **大量共享**:像 `libc.so` 這樣的函式庫會被系統中幾乎所有 process 共享,導致 **VMA 列表極長,線性掃描效率低下**。
為了解決此問題,Linux 核心曾使用 **優先級搜尋樹 (Priority Search Tree, PST)** 來組織映射檔案的 VMA。
* PST 是一種以重疊區間為 key 的二元搜尋樹,涵蓋範圍較大的 VMA 作為父節點。
* 當要查找對應到檔案特定 page (例如第 N 頁) 的所有 VMA 時,可以透過 PST 進行 $O(log N)$ 的快速搜尋,有效過濾掉不相關的 VMA。

> [!caution]**注意**:
> PST 後來在較新的核心版本中已被更高效的 **紅黑樹 (rbtree) 為基礎的區間樹 (interval tree)** 所取代,但其解決問題的思路是一致的。
> 參考:[rbtree based interval tree as a prio_tree replacement](https://lwn.net/Articles/509994/)
RMAP 不僅是 Swap 機制的基石,也是現代核心進階功能如 **KSM (Kernel Same-page Merging)** 的基礎。
> 延伸閱讀:[Reverse Mapping (rmap)](https://www.slideshare.net/AdrianHuang/reverse-mapping-rmap-in-linux-kernel)
---
## 7. 現代記憶體管理議題
### 7.1 Kernel Same-Page Merging (KSM)
在虛擬化環境中,可能會同時執行數十個相同的 Guest OS,其記憶體中存在大量內容完全相同的 page。**KSM** 是 Linux 核心提供的一種 **記憶體去重複技術**。它會週期性地掃描記憶體,尋找內容完全相同的 page,並將它們合併為一個單一的、CoW 的實體 page,從而大幅節省記憶體。KSM 的實現高度依賴於高效的 `RMAP` 機制。
> 延伸閱讀:[內核同頁合併](https://docs.kernel.org/translations/zh_TW/admin-guide/mm/ksm.html)
### 7.2 Huge Memory (巨量記憶體)
在現代伺服器、雲端和超級電腦應用中,TB 等級的記憶體已成常態。傳統的 4KB Page Size 會導致 Page Table 過於龐大、TLB Miss 頻率增加等問題。為此,Linux 引入了 **Huge Pages** 的支持 (大小可以是 2MB、1GB 或更大),可以顯著減少 Page Table 的大小和 TLB 的壓力,對資料庫、虛擬化等大記憶體應用有著顯著的效能提升。
---
## 8. 實驗與觀察
### 8.1 追蹤機制:使用 Ftrace
`ftrace` 是內建於 Linux 核心的強大追蹤工具,可以用來觀察記憶體管理行為。
1. **啟用核心選項**:`CONFIG_FUNCTION_TRACER=y`, `CONFIG_DYNAMIC_FTRACE=y`。
2. **掛載 debugfs**:`ftrace` 的控制介面位於 `/sys/kernel/debug/tracing/`。
3. **設定事件**:監聽 `kmem` 子系統的事件。
```shell
$ cd /sys/kernel/debug/tracing
$ echo "kmem:kmalloc" > set_event
$ echo "kmem:kfree" >> set_event
```
4. **啟用追蹤**:
```shell
$ echo 1 > tracing_on # 啟用
$ echo 0 > tracing_on # 停用
```
5. **觀察日誌**:`cat /sys/kernel/debug/tracing/trace`。
### 8.2 查看硬體拓撲:使用 lstopo
對於 `NUMA` 架構,了解硬體拓撲至關重要。可以使用 `hwloc` 套件中的 `lstopo` 工具來視覺化硬體拓撲,清楚地看到系統有多少個 NUMA 節點、CPU 核心分佈以及各級快取結構。
* **文字模式**:`$ lstopo -v`
* **圖形化**:`$ lstopo`
---
## 結論
Linux 核心的記憶體管理是一個在不斷演進的複雜系統,充滿了基於現實世界需求的工程權衡:在效能與資源開銷之間權衡 (Slab vs. Slub),在靈活性與碎片化之間權衡 (Buddy System),在記憶體利用率與系統穩定性之間權衡 (Overcommit)。理解這些核心概念與其背後的設計哲學,是掌握 Linux 核心乃至現代計算機系統運作原理的必經之路。
---
## 待整理與延伸閱讀
* [Hack-The-Virtual-Memory](https://github.com/holbertonschool/Hack-The-Virtual-Memory):一系列關於虛擬記憶體的實作挑戰。
* [Process Address Space](https://www.slideshare.net/AdrianHuang/process-address-space-the-way-to-create-virtual-address-page-table-of-userspace-application-251425396):關於 process address space 與 page table 建立的詳細簡報。
* [Physical Memory Management](https://www.slideshare.net/AdrianHuang/physical-memory-managementpdf):深入探討實體記憶體管理。
* [Memory Compaction](https://www.slideshare.net/AdrianHuang/memory-compaction-in-linux-kernelpdf):Linux 核心中的記憶體緊縮技術。
* [Linux PSI (Pressure Stall Information)](https://igene.tw/pressure-stall-information-intro):解讀與應用 Linux 的壓力停頓資訊指標。
---
回[主目錄](https://hackmd.io/@Jaychao2099/Linux-kernel)







