Creating Accessible Reports with Optical Character Recognition (OCR)
=====================================
---
<sub>_Note: This blog covers the extraction of information from a pdf composed of images, rather than text. **Do not use OCR for anything but image files.** If your file is text, then [use '**pdfminer**'](https://github.com/official-inquiries/tools). If you are not sure whether your document contains text or images, just try to copy and paste text out of it. If you can highlight copy and paste text, then it is a text document, you should [use pdfminer.](https://github.com/official-inquiries/tools)_</sub>
---
Storing text as scanned images is a sure way to lock up the information in them. When documents are stored as images, computers have a hard time reading them, so all automatic search (by browser or with a viewer) is fruitless.
Specialized technology called Optical Character Recognition (OCR) is slowly being perfected that allows machines to read text. In the future, OCR may allow us to search for text within images automatically, but right now, machines need quite a bit of help.
This blog provides instructions for using OCR to produce a nice clean text file, from a pdf that was saved as images. I worked on the US Senate’s 2014 report [“Climate Change: The Need to Act Now.”](https://github.com/official-inquiries/climate-action-us-senate-2014/tree/master/archive)
Once you are done with this page you should have a text file equivalent to what would be produced by '**pdfminer**' from a text-based pdf. You can then use the main instructions for tidying your file, adding markdown annotation, and posting on the Official Inquiries website. Please scan this page entirely before starting.
# Some things you should know before you start:
Sometimes documents are published in several formats -- make sure that the document you want to share with the world is not published elsewhere as text. If it is, then get that text file!
Before putting the document through OCR, make sure that it is composed entirely of images. Many documents are a mix of image pages and text pages. If the document has both text and image pages, then start by putting the document through **'Pdfminer'** as detailed [here](https://github.com/official-inquiries/tools). Then look at the output from pdfminer. The pages that are images will be blank, and will need to be replaced by OCR output, the pages that are text will be more accurate than OCR, so do not replace these.
Also, in order to produce a clean text, it will be necessary to compare output of an OCR program side-by-side with the original document. This does not have to be tedious -- This a good time to actually (re-)read the document closely and learn all about its valuable contents! The output from OCR should be legible, but will not be perfect.
It is easier to stay interested and spot errors if you are learning about the contents. If just scan, or you already know what is supposed to there, your brain will tend to see what is supposed to be there, and you will miss errors, a lot like what happens when you read your own writing.
## Managing Expectations for OCR
OCR will require some manual correction. Running a spellechecker helps, but a spellchecker will not find wrongly rendered numbers, or misspelling of proper names and many other errors. For example, at least in my document, I found that **'Tesseract'** OCR liked to turn the pronoun “I” into the number “1.”
So, using OCR involves a fair bit of work, especially when:
* The image is blurry or faded
* The font style is unusual.
* The font is in italics. (though some OCR programs deal with italics pretty well)
Still, you should basically be able to read the raw OCR output. If the raw OCR output is simply illegible after following all the tips below, then you may want to pick another report to share with the world!
# Running Your Document Through OCR
The easiest way to assess the amount of work in front of you is just to run the document through an OCR program like [Tesseract, which is free and easy to install.](https://github.com/tesseract-ocr/tesseract/wiki)
### Our recommendation for OCR programs -- Tesseract *(possibly supplemented with Google Vision)*
After looking at a number of programs (see discussion at bottom), I ended up using both Tesseract and Google Vision, which turned out to be able to do different things well. Tesseract was able to convert most pages well enough that only minor corrections were necessary, and gave better results than Vision, overall. Still, Vision was very useful for plugging some gaps in Tesseract's functionality. For example, Tesseract's performance on reading italics was awful, while vision's overall inferior performance was not greatly diminished by italics or blurring.
Thus, I recommend simply correcting rough patches with Google Vision's easy web interface , rather than spending time setting up the vision API.
Note: The programs that were reviewed were all free. If you have access to proprietary OCR software by all means test to see if it outperforms tesseract, but there is no such thing as a perfect OCR program, yet. Many specific files are clean enough that many OCR programs will be able to read them well, but an image of faded blurred text in a strange font will cause problems for any program.
It may be surprising to hear that Tesseract was superior, given google's reputation as a leader in artificial intelligence applications, but Tesseract is very good as freeware goes and its development was generously supported by tech giants. We will try to keep current on any changes in either product.
Now lets look at the process of actually getting output from an OCR program.
## Prepare For OCR
### Install Tesseract
Install Tesseract following the instructions for your OS [here.](https://github.com/tesseract-ocr/tesseract/wiki)
### Converting PDF to Image Files
To convert images to text using Tesseract, you will first need to save a PDF or other document as a tiff file. Make sure the resolution is high -- 300 bpi (bits per inch or greater.) Mac users can do this by opening the document in preview, and clicking File-> Save As, then selecting tiff from the dropdown menu of file types. PC users may want to use '**Imagemagick.**'
I ran into problems, here. I am a Mac user and so I tried to saved the PDF as a tiff file in preview. My Mac told me it could not save the whole document when I selected 300 bpi (there was plenty of space on the hard drive) but would let me save it at 200 bpi. The problem was that Tesseract's output at 200 bpi was useless. Quite a bit later, I realized that if I first broke the document into smaller pieces, Preview would allow me to save each of the smaller pieces at 300 bpi. I have no idea why this difficulty arose, but the change in resolution made all the difference, as you can see from the comparison pages below. Similar problems may arise if you attempt to use cloudconvert or other online converters, which are trying to conserve computation resources.
[]()
[]()
Clearly, it is worth waiting an extra few minutes for your computer to convert your pdf to high resolution images. If your machine refuses to save the whole document at 300 bpi, try saving a just a few pages at that resolution. If this works, then it means you have to break the document up.
Using Tesseract:
Simply save the tiff file under a clear name in a convenient folder. Open up a command line interface, and navigate into the folder containing your tiff and type: tesseract tiffname. Tessereact will automatically generate a txt file with the same name as your tiff.
Cross your fingers and open the tiff file. If it gives reasonable quality output then you are ready to begin correcting. If it gives useless output, then try to save the document with even higher bpi, or try google vision as detailed below. There are documents that OCR simply will not work very well on. If your document turns out to be one of these, then please post this bad news on github issue tracker. Perhaps in the future better OCR technology will come along, and you or somebody else can parse the document then.
# Using the Vision Web Interface as a Fallback Method
You may encounter a few spots where Tesseract gives poor results. **If** these spots are large enough, then it may be worth your time to paste these pages into Google Vision, assuming the Vision output proves to be better. This is especially likely to be true with faded images and sections written in italics or other unusual fonts.
The full version of Google Vision takes some time to set up and work with, but the vision website contains a testing page allows you to easily paste single images into a web interface.
Note that in practice this will only save you time if there are large stretches of the document where Tesseract gives poor results. For example in my document there were several pages where the type face inexplicably turned to italics for most of the page.
Here is faded photocopy, written partly in italics which is very hard for OCR, you can see the relative strengths pretty easily, here.
*Original text from pdf*
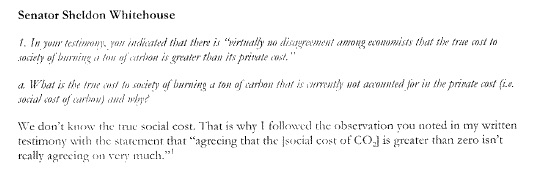
*Tesseract's Attempt*

Yowza! As you can see, Tesseract is truly awful at reading italics though it gets though the normal text easily.
*Vision's Attempt*

Vision is quite a bit better, but still not perfect at reading these faded italics. Still it was only worth my time to use Vision to get results for the pages that were mostly in italics. If a few lines of the page were in italics, then it was faster to just type fix these by hand.
I simply replaced Tesseract's hopeless attempts to read italics with Vision's attempts, and then corrected against the original document. This worked well.
To use vision, go to the vision page [here](https://cloud.google.com/vision/) and just drag a saved image of the page you would like to spotcheck into the window that looks like this: 
... and then wait for vision to process the file. Then click on the "text" tab. Output will appear and you can simply copy the text on the right.
Then replace the Tesseract output with google's output, assuming it is better.
To make a single image out of a pdf page, simply go to the pdf file and right click on the page that Tesseract had a hard time with. Select "save as" and then save it as an image file (vision can process all kinds of images.)
If you find that the Vision web interface is giving you far superior results for your whole document, then it might be worthwhile to go through the process of setting up the Vision API. At the time of writing, it does not seem that this will be the case for many users, but Google may improve Vision in the near future.
#### More Tips on Using Vision
If you do use Vision, be mindful of the fact that Vision will simply skip words and characters when it is not confident of its interpretation of them. This results in many skipped words. Therefore, it is especially important to read the output from Vision yourself -- a spell checker won't catch omitted words.
Fortunately this process is not as annoying as it sounds because Vision has ways of telling you when it skips words. When you get your text output, you will see the original image to the left with a bunch of funny green boxes scatted over it.
Like this:

Where there are no green boxes, Vision sees nothing. You will have to fill these spaces in yourself.
#### Tips for Correcting the Document:
Don't worry formatting the table of contexts -- this will be replaced when the document is posted on the website.
It is good if you are actually reading when trying to catch the errors. Many will be obvious, but some will be hard to catch unless you are paying attention to content.
Place the original and the OCR output in windows text to each other.
Change the line size on the OCR output so that it matches the original as closely as possible, allowing you easily move between one and the other.
View the OCR output in a nicely rendered font. If one is not used to reading the format that the text is displayed in, errors may not jump out at you. I found it much easier to spot errors when the OCR output was rendered in a familiar font with familiar margins.
Though it is a good idea to check all of the converted text against the original, be especially careful to check all numbers. It will not necessarily be obvious if they are wrong, just from looking at the original document.
Be on the lookout for confusuion between lowercase "L", capital "i" and number one -- i.e. l,I, and 1. OCR confuses these, for obvious reasons.
You may want to make sure that some parts of the document are not stored in text, elsewhere. This will be especially worthwhile if some of the pages are written in unusual font, or the scans are of poor quality. Pieces of official inquires, especially exhibits (e.g. records of legal proceedings, or news articles that were cited as part of the inquiry) can sometimes be found as separate text-based documents elsewhere.
### Formatting and Further Processing of the document:
You may be tempted to correct the formatting of the document at the same time that you check OCR errors. Generally, however, we are more efficient when we minimize the amount of task switching that we do. Keeping with this, I found it useful to concentrate on one thing at a time -- first correct any errors that were made during the OCR process, then worrying about formatting.
Please refer to the main instructions for contributors for specifics on formatting, adding markdown annotation, and posting on the Official Inquiries website.
## Other OCR Programs Tested
Google drive – You will read in some places that google drive can be asked to OCR uploaded documents and that this gives good results. In my experience, this resulted in loads of blank pages, mainly. Given the amount of people saying this, I have to believe that it works for some documents, but it certainly did not for the Senate Climate Action Report.
FreeOCR -- I saw nothing at which free OCR was better than Tesseract. My recommendation is not to waste your time.
Finereader -- Ditto.
## Finally...A Pep Talk
Don't get frustrated with your computer's poor reading ability. Modern neuroscience teaches us that we construct the world around us, often adding in a lot of detail -- the letters in your image file look clear to you because your advanced visual system makes them clear. Computers are still catching up to your highly evolved brain.
Instead of thinking about how much easier OCR conversion would be if your computer were smarter, think about how much easier it is than typing by hand, and marvel at how you manage to do the difficult job of figuring out what letters are there so easily.
 Sign in with Wallet
Sign in with Wallet







