# 後端資料庫效能優化
> 肝不好,人生是黑白的
DB不好,SRE是醒著的

## 大方向
Server Side 優化:
1. Caching
2. Connection Pool
3. ORM 存取優化
DB 操作本身的優化:
1. Query 的眉角
2. Config
3. 空間
## Server Side(1): Caching
在 Server 做 Caching,可以在犧牲「資訊即時性」的情況下,減少對資料庫的請求。常見的方式有以下:
1. 使用本地空間: 使用該 Server 實體的記憶體,適用於小型測試。
2. 另外架設快取服務:
1. Memcached: string-based
2. Redis:in-memory db
3. 搭配 DB 結構使用
* Materialized View
### 時機
針對統一型 API(所有人回應相同)
* 需求較輕:Cache
* ex: 文章列表(第一頁前50筆)
* 需求較重:Materialized View
* ex: 一年內每月消費報表
|id|user_id|related|amount|created_at
|---|---|---|---|---|
|1|132241|subscription|299|2021-01-03 22:30:49
|2|43923|purchase|30|2021-01-04 12:07:49
|3|43923|purchase|30|2021-01-05 03:03:41
|4|13948|purchase|3250|2021-01-05 08:39:50
|...|...|
|month|revenue|
|---|---|
|1|249,586|
|2|281,830|
|3|329,018|
|...|...|
針對單一型 API(每個人的回應不同)
* 需求較輕:Cache
* ex: 個人消費紀錄
* 需求較重:Materialized View (+ Cache)
* ex: 一年內每月消費報表 => 個人每月消費紀錄
|month|user_id|expense|
|---|---|---|
|1|10|203,193|
|1|1310|85,738|
|1|5841|21,000|
|...|...|
## Server Side(2): Connection Pool
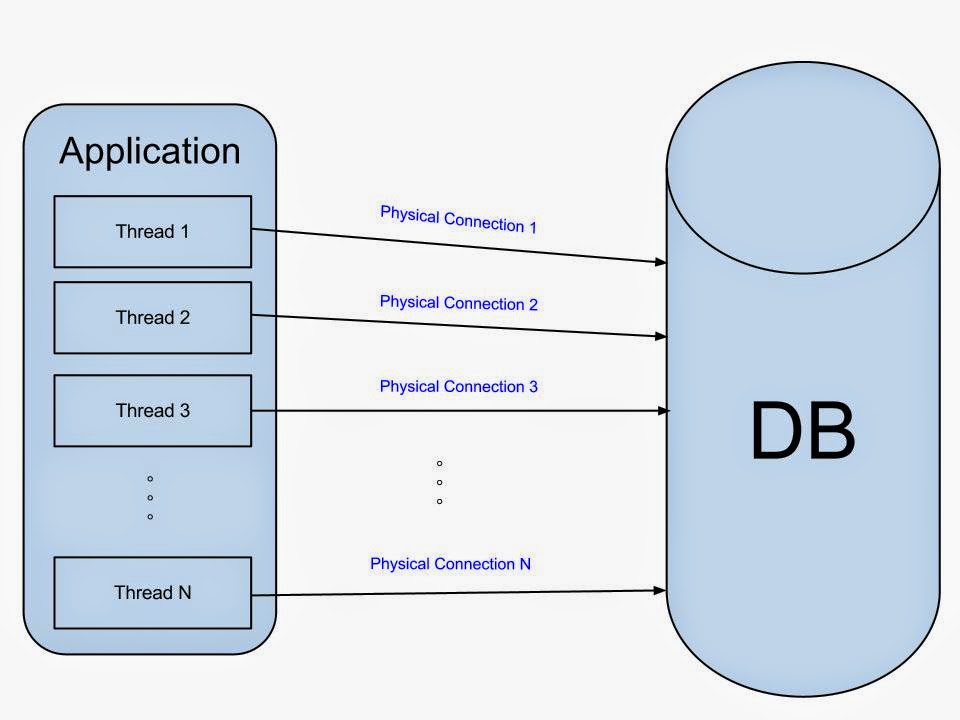

[Scaling Postgres connections](https://www.citusdata.com/blog/2017/05/10/scaling-connections-in-postgres/)
資料庫連線的建立成本很昂貴,每一個 connection 對 postgresql 都是一個 forked process,至少都會需要分配 10MB 。如果多個 Thread 都要建 connection時,其資源的耗費是龐大的。
每個連線都會消耗 DB 的記憶體,而且當請求完成時直接 close 掉,新的連線又要重新分配資源。
請求進行中,網路延遲跟結果運算其實都會導致 connection 閒置,零碎時間加起來其實很浪費資源。
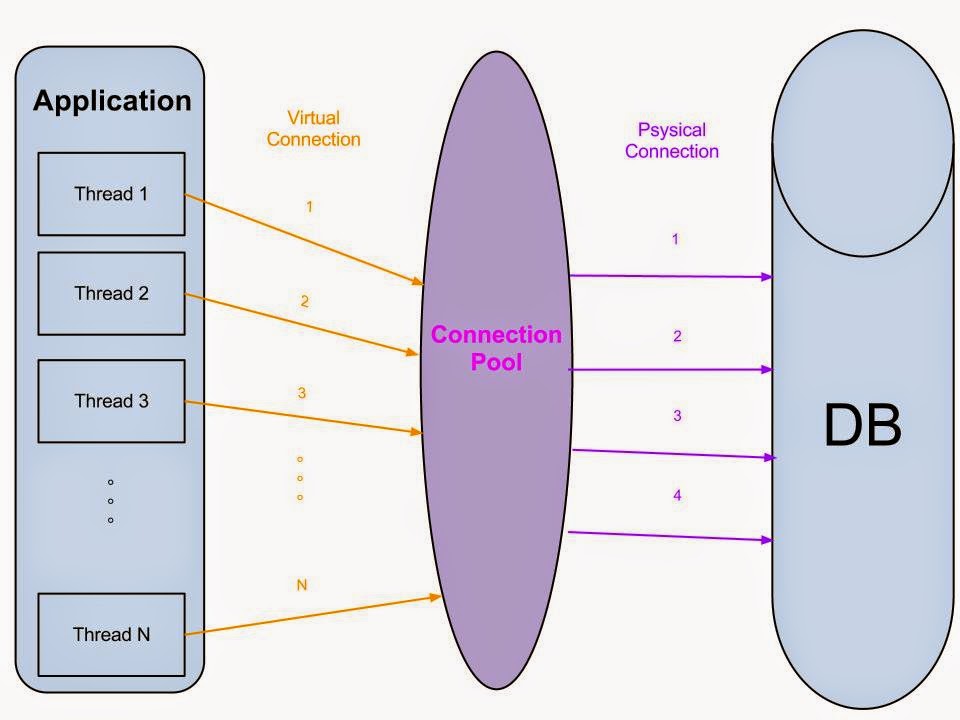
### Pooling 工具
主要都提供
1. 維持並重用連線。
2. 可設定與 DB 最大的連線數,避免超過DB所能負擔的連線數。
3. Pool 可幫忙驗證 Connection 是否正常。
pgPool2
~ 功能比較多樣,包含 Load Balancing、SQL Replication(資料同步到多台)等等
必須要另外架設一台實體
pgBouncer
~ 輕量化的「工具」,可以在設定在資料庫或是 App Server 都可以。
## Server Side(3): ORM 存取優化
### 避免 N+1 問題
```ruby=
# Rails
users = User.limit(10)
pictures = users.map{|user| user.profile_picture }
```
```ruby=
# User Load (1.6ms) SELECT "users".* FROM "users" LIMIT $1 [["LIMIT", 10]]
# Picture Load (0.3ms) SELECT "pictures".* FROM "pictures" WHERE "pictures"."id" = $1 LIMIT $2 [["id", 53], ["LIMIT", 1]]
# Picture Load (0.3ms) SELECT "pictures".* FROM "pictures" WHERE "pictures"."id" = $1 LIMIT $2 [["id", 54], ["LIMIT", 1]]
# Picture Load (0.2ms) SELECT "pictures".* FROM "pictures" WHERE "pictures"."id" = $1 LIMIT $2 [["id", 55], ["LIMIT", 1]]
# Picture Load (0.2ms) SELECT "pictures".* FROM "pictures" WHERE "pictures"."id" = $1 LIMIT $2 [["id", 56], ["LIMIT", 1]]
# Picture Load (0.2ms) SELECT "pictures".* FROM "pictures" WHERE "pictures"."id" = $1 LIMIT $2 [["id", 57], ["LIMIT", 1]]
# Picture Load (0.2ms) SELECT "pictures".* FROM "pictures" WHERE "pictures"."id" = $1 LIMIT $2 [["id", 58], ["LIMIT", 1]]
# Picture Load (0.1ms) SELECT "pictures".* FROM "pictures" WHERE "pictures"."id" = $1 LIMIT $2 [["id", 59], ["LIMIT", 1]]
# Picture Load (0.1ms) SELECT "pictures".* FROM "pictures" WHERE "pictures"."id" = $1 LIMIT $2 [["id", 60], ["LIMIT", 1]]
# Picture Load (0.1ms) SELECT "pictures".* FROM "pictures" WHERE "pictures"."id" = $1 LIMIT $2 [["id", 61], ["LIMIT", 1]]
# Picture Load (0.2ms) SELECT "pictures".* FROM "pictures" WHERE "pictures"."id" = $1 LIMIT $2 [["id", 62], ["LIMIT", 1]]
```
```javascript=
const articles = Article.findAll({
where: {
state: 'public'
}
})
const authorNames = articles.map(article => article.user.name)
```
#### 解法一:預先載入
```ruby=1
users = User.includes(:profile_picture).limit(10)
pictures = users.map{|user| user.profile_picture }
# User Load (251.9ms) SELECT "users".* FROM "users" /* loading for inspect */ LIMIT $1 [["LIMIT", 11]]
# Picture Load (3.0ms) SELECT "pictures".* FROM "pictures" WHERE "pictures"."id" IN ($1, $2, $3, $4, $5, $6, $7, $8, $9, $10, $11) [[nil, 53], [nil, 54], [nil, 55], [nil, 56], [nil, 57], [nil, 58], [nil, 59], [nil, 60], [nil, 61], [nil, 62], [nil, 63]]
```
```javascript
const articles = Article.findAll({
where: {
state: 'public'
},
include: User
})
articles[0]
// [{
// "name": "Kyle Mo: on Web performance",
// "id": 1,
// "userId": 1,
// "user": {
// "name": "Kyle Mo",
// "id": 1
// }
// }]
articles[0].user.id // does not trigger query
const authorNames = articles.map(article => article.user.name)
```
#### 解法二:
分開做搜尋
```ruby=
# Rails
users = User.limit(10)
# User Load (1.0ms) SELECT "users".* FROM "users" LIMIT $1 [["LIMIT", 10]]
picture_ids = users.map{|user| user.profile_picture_id }
pictures = Picture.find(picture_ids)
# Picture Load (13.7ms) SELECT "pictures".* FROM "pictures" WHERE "pictures"."id" IN ($1, $2, $3, $4, $5, $6, $7, $8, $9, $10) [[nil, 53], [nil, 54], [nil, 55], [nil, 56], [nil, 57], [nil, 58], [nil, 59], [nil, 60], [nil, 61], [nil, 62]]
```
```javascript=
// JS
const articles = Article.findAll({
where: {
state: 'public'
}
})
const userIds = articles.map(article => article.userId)
const authorNames = User.findAll({
where: {
id: userIds}
}).map(user => user.name);
```
### 注意其他眉角(EX: Rails)
#### 整合 ALTER 行為
```ruby
def up
add_column :table, :useful_foreign_key, :integer
add_index :table, :useful_foreign_key
add_column :table, :summary, :string
end
== Table: migrating ===============================
-- add_column(:table, :useful_foreign_key, :integer)
-> 2731.1005s
-- add_index(:table, :useful_foreign_key)
-> 2704.8428s
-- add_column(:table, :summary, :string)
-> 2819.9803s
== Table: migrated (8255.9236s) ======================
```
```ruby
def up
change_table :table, :bulk => true do |t|
t.integer :useful_foreign_key
t.index :useful_foreign_key
t.string :summary
end
end
== Table: migrating =================
-- change_table(:table, {:bulk=>true})
-> 2774.1011s
== Table: migrated (2774.1011s) ========
```
#### Locking Table
```ruby=
class ChangeACoupleOfColumnsInThing < ActiveRecord::Migration[5.2]
def change
remove_column :things, :column_one, :boolean
add_column :things, :column_two, :string, null: false, default: ''
end
end
== Table: migrating =================
-- remove_column(:table, :column_one)
-> 120.1005s
-- remove_column(:table, :column_two, :string, :default => '')
-> 8774.0013s
== Table: migrated (8894.1018s) ========
```
```ruby=
class ChangeACoupleOfColumnsInThing < ActiveRecord::Migration[5.2]
def change
change_table :sellers, bulk: true do |t|
t.remove :column_one, :boolean
t.column :column_two, :string, null: false, default: ''
end
end
end
```
[Locking when altering a table in PostgreSQL vs. MySQL](https://www.covermymeds.com/main/insights/articles/locking-when-altering-a-table-in-postgresql-vs-mysql/#:~:text=When%20you%20run%20an%20alter,needs%20to%20alter%20existing%20rows.)
## DB(1): CPU/運算時間
外部服務使用資料庫,最主要的瓶頸是「查詢/運算時間」。
### 檢驗
主要還是建議透過一些 APM (DataDog、NewRelic 等等),去挑出較慢的 Transaction。

### 檢視細節
```sql
EXPLAIN ANALYZE SELECT * FROM users;
QUERY PLAN
-------------------------------------------------------------
GroupAggregate (cost=185753.73..191351.57 rows=200 width=25) (actual time=2883.718..2885.135 rows=31 loops=1)
Group Key: t.user_id
CTE time_threshold
-> GroupAggregate (cost=39613.01..65579.99 rows=11908 width=25) (actual time=233.594..541.393 rows=2576 loops=1)
Group Key: records.user_id
-> Sort (cost=39613.01..39811.84 rows=79532 width=28) (actual time=233.482..254.666 rows=60486 loops=1)
Sort Key: records.user_id
Sort Method: external merge Disk: 2480kB
-> Seq Scan on records (cost=0.00..31235.40 rows=79532 width=28) (actual time=46.098..179.900 rows=60486 loops=1)
Filter: ((created_at >= '2021-10-08 10:00:00'::timestamp without time zone) AND (created_at <= '2021-10-28 15:59:59'::timestamp without time zone) AND (region_id = 2))
Rows Removed by Filter: 997836
```
:-1: Scan: 整個表看過一次
:+1: Index Search:只用 Index 尋找
### 1 - 適當的為欄位加 Index
Index(索引)是一種用來加速查詢速度的資料結構。一般是使用一種叫做 Btree 的二元樹結構,在資料庫中會佔用一些空間[^index_space]。

假設資料表具有一或多個索引,每當新增一筆資料,資料庫就會更新我們的 index,增加一些運算時間。
#### index 切勿過多
基本上任何修改到被 indexed 欄位的操作都會變慢[^slow_op]。但大家主要談論變慢的是 insert ,因為通常新增資料時造成的 index 運算會比較多一點[^slow_insert]。

一個資料表建議維持在最多 5 個 index 是最好。
#### 不要加在可以 NULL 的欄位
如果這樣做,當有很多列的那個欄位是 NULL 時,很容易導致 planner 去做 full scan。
### 2 - 減少 selection 中的方法呼叫/資料轉型
```sql=
explain analyze select id, to_char(created_at, 'YYYY/MM/DD')
from room_records
limit 3000
Limit (cost=0.00..73.50 rows=3000 width=40) (actual time=0.065..3.949 rows=3000 loops=1)
-> Seq Scan on room_records (cost=0.00..26012.65 rows=1061732 width=40) (actual time=0.063..2.811 rows=3000 loops=1)
Planning time: 0.217 ms
Execution time: 4.565 ms
```
```sql=
explain analyze select id, created_at::date
from room_records
limit 3000
Limit (cost=0.00..73.50 rows=3000 width=12) (actual time=0.012..2.347 rows=3000 loops=1)
-> Seq Scan on room_records (cost=0.00..26012.65 rows=1061732 width=12) (actual time=0.011..1.155 rows=3000 loops=1)
Planning time: 0.227 ms
Execution time: 2.986 ms
```
### 3 - 可能使得 planner 不看 index 的因素[^not_using_index]
1. Table 很小
2. 當搜尋的條件中不包含完整的複合 index
3. 搜尋所回傳的列數幾乎跟 Table 一樣大
4. 拿不完全相同的資料型態搜尋
5. 查詢中有 limit (不一定)
6. 使用負面搜尋( where `XXX is not null`、`XXX not in ('123', '456')` )[^scan_on_not_null]
7. 就你在鬧事沒加 index
### 4 - 不同資料型態造成的效能差異
[Optimizing with explain](https://dataschool.com/sql-optimization/optimization-using-explain/)
## DB(2): 空間
### 1 - 正規化
將資料表欄位關係標準化,來減少不必要欄位、避免更新異常。
規則有寬鬆至嚴格有
|階級|名稱|概念
|---|---|---|
|\-\-\-|沒有正規化|跟我的人生一樣
|1NF|第一正規化|除去重複群
|2NF|第二正規化|除去部份相依
|3NF|第三正規化|除去遞移相依
|:star:BCNF|Boyce-Codd正規化|除去功能相依造成的異常
|4NF|第四正規化|除去多值相依
|5NF|第五正規化|除去剩下相依
[正規化教學](http://cc.cust.edu.tw/~ccchen/doc/db_04.pdf)
### 2- Partitioning
分割大型的資料表,可以讓查詢去過濾更少的列數和 index 來找到資料。
[Postgres - Partitioning](https://www.postgresql.org/docs/10/ddl-partitioning.html#:~:text=2.-,Declarative%20Partitioning,used%20as%20the%20partition%20key.)
## DB(3): Config[^categories][^tuning]
[PG docs - config](https://www.postgresql.org/docs/12/runtime-config-resource.html)
[Configuring Memory on Postgres](https://www.citusdata.com/blog/2018/06/12/configuring-work-mem-on-postgres/)
```sql
select name, setting, unit, category, short_desc
from pg_settings
where name in ('shared_buffers', 'effective_cache_size', 'work_mem', 'maintenance_work_mem');
```
|config|解釋|
|---|---|
shared_buffers | 所有 process 使用的記憶體量。(建議:為 instance 記憶體的 1/4)
max_connection | 最多有多少 client 可以連線。建議使用 pooling 工具。
effective_cache_size | 會影響 planner 使用 index 的效率
work_mem | 影響 query 中複雜的 sort 效率
maintenance_work_mem | 影響 vacuum, create index, alter table 等系統性指令效率
[^categories]: [Config cates](https://www.pgconfig.org/#/?max_connections=100&pg_version=13&environment_name=WEB&total_ram=4&cpus=2&drive_type=SSD&arch=x86-64&os_type=linux)
[^tuning]: [Tuning PG config](https://wiki.postgresql.org/wiki/Tuning_Your_PostgreSQL_Server)
[^index_space]: [Postgres - Database Indexes table size syntax](https://www.postgresqltutorial.com/postgresql-database-indexes-table-size/)
[^slow_op]: [Why delete is slower when having index](https://stackoverflow.com/questions/3453833/sql-server-delete-is-slower-with-indexes#answer-3453853)
[^slow_insert]: [More index, slower insert](https://use-the-index-luke.com/sql/dml/insert)
[AWS - RDS Shared memory](https://aws.amazon.com/tw/blogs/database/resources-consumed-by-idle-postgresql-connections/)
[^not_using_index]: [When does PG not using index](https://www.gojek.io/blog/the-case-s-of-postgres-not-using-index)
[^scan_on_not_null]: [Why scan with "boolean is not null"](https://dba.stackexchange.com/questions/27681/unexpected-seq-scan-when-doing-query-against-boolean-with-value-null)







