# Stable Diffusion and Controlnet
In this guide, we'll outline how you can use existing, drawn, or modeled images -- like the rendering of our Learning Lab studio below -- and change them into completely new scenes.
<img src="https://files.slack.com/files-pri/T0HTW3H0V-F06JK9E8AJU/llangle2.png?pub_secret=9a84127f1a" alt="drawing" width="500"/>
<img src="https://files.slack.com/files-pri/T0HTW3H0V-F06JK3P5X40/mlsd___depth.png?pub_secret=f2b5d3b24d" alt="drawing" width="500"/>
# [Stable Diffusion](https://jalammar.github.io/illustrated-stable-diffusion/)
Stable Diffusion started as a latent diffusion model that generates AI images from text. It has since expanded out to a series of interconnected tools for creating image-to-image, text-to-video, and even video-to-video. At the moment, video outputs are still highly complex and frequently ineffective, so in this guide, we'll focus on image outputs only.
Stable diffusion works by taking a field of static noise and pulling an image out of the noise. This is why when you generate a number of images, they'll all be fundamentally similar, but end up quite different -- because no field of static is exactly the same as another.
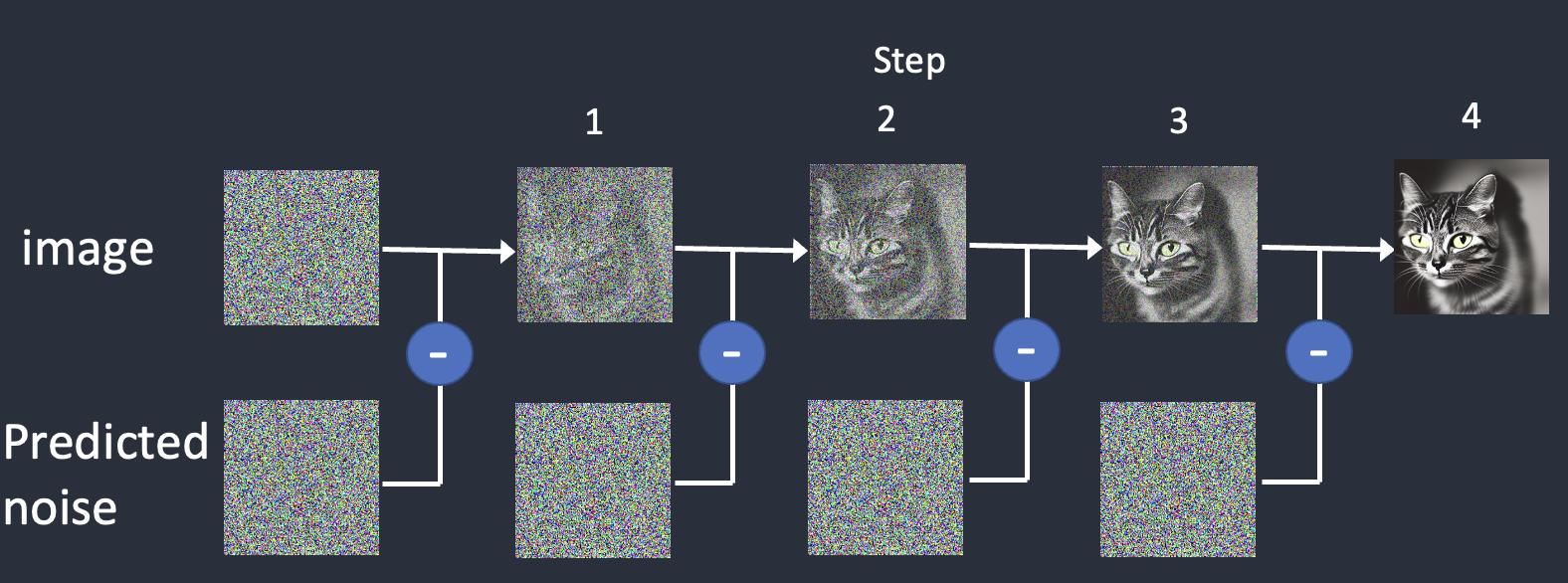
## Interfaces
A number of interfaces for Stable Diffusion exist out there, some of them will be more like Midjourney or Dall-E, in the sense that you won't maintain this creative control quite as much. [Playground.ai](https://playground.ai/) is one of these, its a mostly free build for stable diffusion that is hosted online and uses off-site servers to handle the processing.
[ComfyUI](https://github.com/comfyanonymous/ComfyUI) is another version, but in this case it runs locally and uses your computer's processors for handling the image generation.
The interface we'll be using is called [AUTOMATIC1111](https://github.com/AUTOMATIC1111/stable-diffusion-webui). This is arguably one of the harder ones to learn, but has the most adaptability.
<img src="https://files.slack.com/files-pri/T0HTW3H0V-F06J8UYFHH7/controlnet_image.png?pub_secret=cb47a5e4cc" alt="drawing" width="600"/>
This is completely free and installed through the command line. It runs primarily on Python -- but **requires no coding experience whatsoever**.
You can find guides here on how to install it:
* [Install guide for Macs](https://stable-diffusion-art.com/install-mac/)
* [Install guide for Windows](https://stable-diffusion-art.com/install-windows/)
* [Install guide for Google Colab](https://stable-diffusion-art.com/automatic1111-colab/)
* This option will work for anyone that has an older computer or finds that it doesn't really function on their own machine.
* Unfortunately, this option does require an upgraded Colab account and may cost money. *Running Stable Diffusion on the free level of Colab breaks the Terms of Service.*
## How it works
Now, we're actually getting to the core function of the tool. There are two main functions that we want to use, **Image interpretation** and **Image generation**. The interpretation process will use a tool call **Controlnet** and the generation process will be determined by the **Checkpoint Model**.
### [Controlnet](https://stable-diffusion-art.com/controlnet/)
Controlnet functions by taking in an image, interpreting specific elements of that image, and then passing that control information on to the checkpoint model.
<img src="https://stable-diffusion-art.com/wp-content/uploads/2023/02/openpose_overlay_person.png" alt="drawing" width="300"/>
In the case of the OpenPose tool, it interprets human poses and generates new characters in exactly those poses.
With the Segmentation tool, it breaks foreground, middle ground and background into unique sections. So below, you'll find the original image, it's interpretation and its output.
<img src="https://stable-diffusion-art.com/wp-content/uploads/2023/05/jezael-melgoza-KbR06h9dNQw-unsplash.jpg" alt="drawing" width="300"/>
<img src="https://stable-diffusion-art.com/wp-content/uploads/2023/05/image-137.png" alt="drawing" width="300"/>
<img src="https://stable-diffusion-art.com/wp-content/uploads/2023/05/image-141.png)" alt="drawing" width="300"/>
### [Checkpoint Models](https://softwarekeep.com/help-center/best-stable-diffusion-models-to-try)
Your Checkpoint Model will determine the style and occasionally the content of your output. It is important to note that there is no built-in censor on Stable Diffusion, so be careful when prompting, as you may generate unintended images.
Here are two checkpoint models, so you can see the how differently they portray the same set of prompts.


## How to Pull it all together
Now, if you've gotten this far, you'll probably get the notion that there's a ton of different ways you can mix and match these two tools. Below, you'll find an approach that it intended to interpret a scene and remix the setting of that scene.
To start, we can draw a few simple shapes -- for bonus points, you can use Blender to place 3D objects roughly within a scene. But taking a clean photo of a drawing on white paper would work basically just as well.

Next, we'll put this screenshot into Stable Diffusion, in the Controlnet drop down interface:
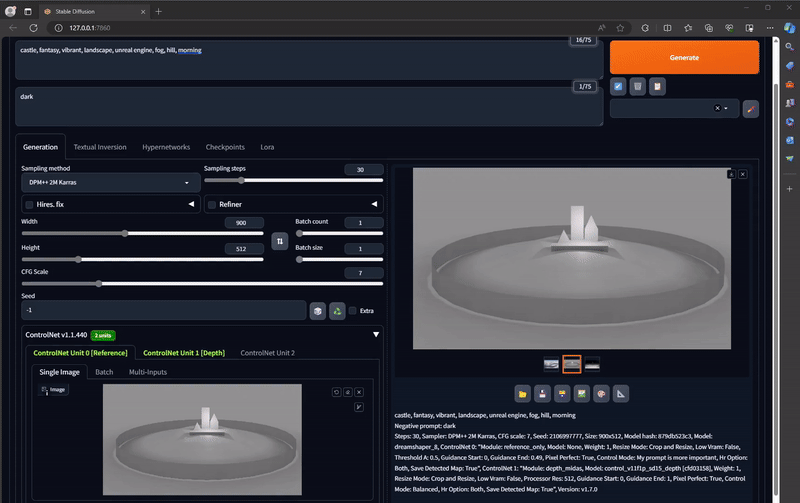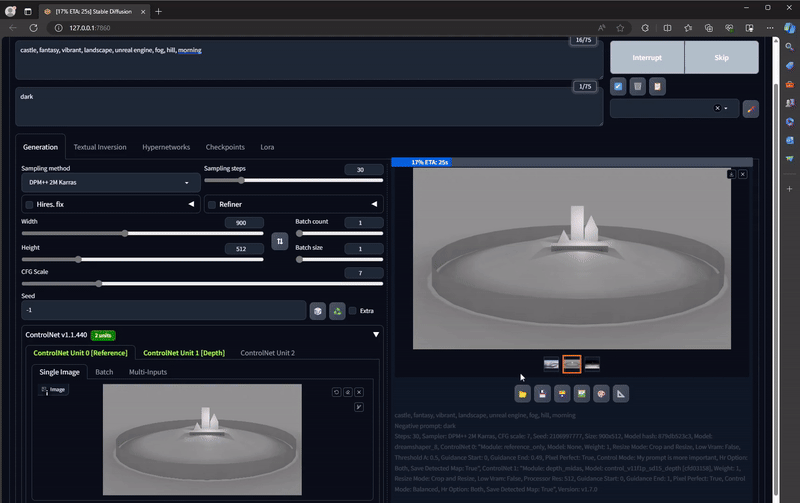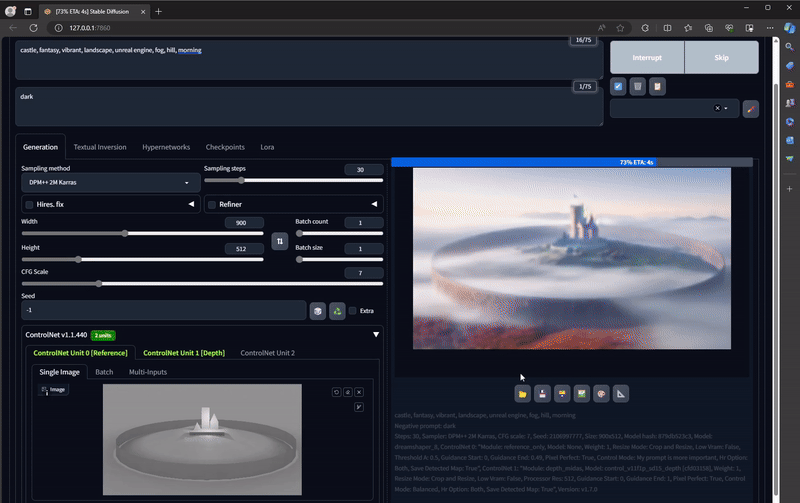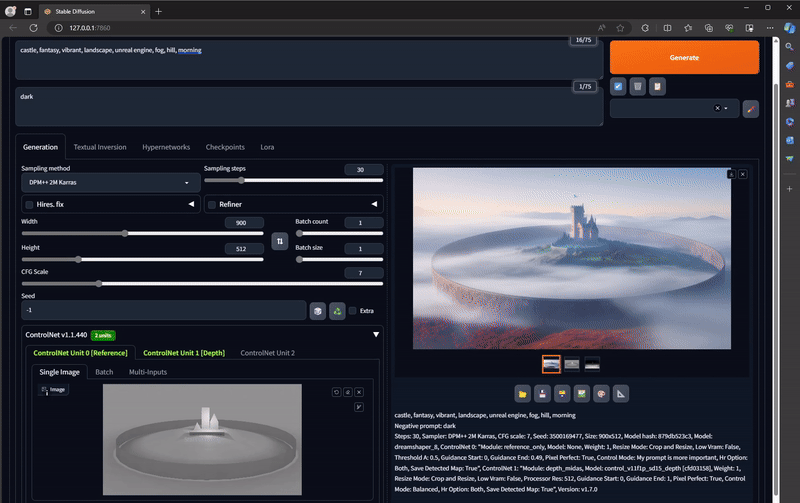
Check on:
* Enable
* MLSD
* Pixel Perfect
* Allow Preview
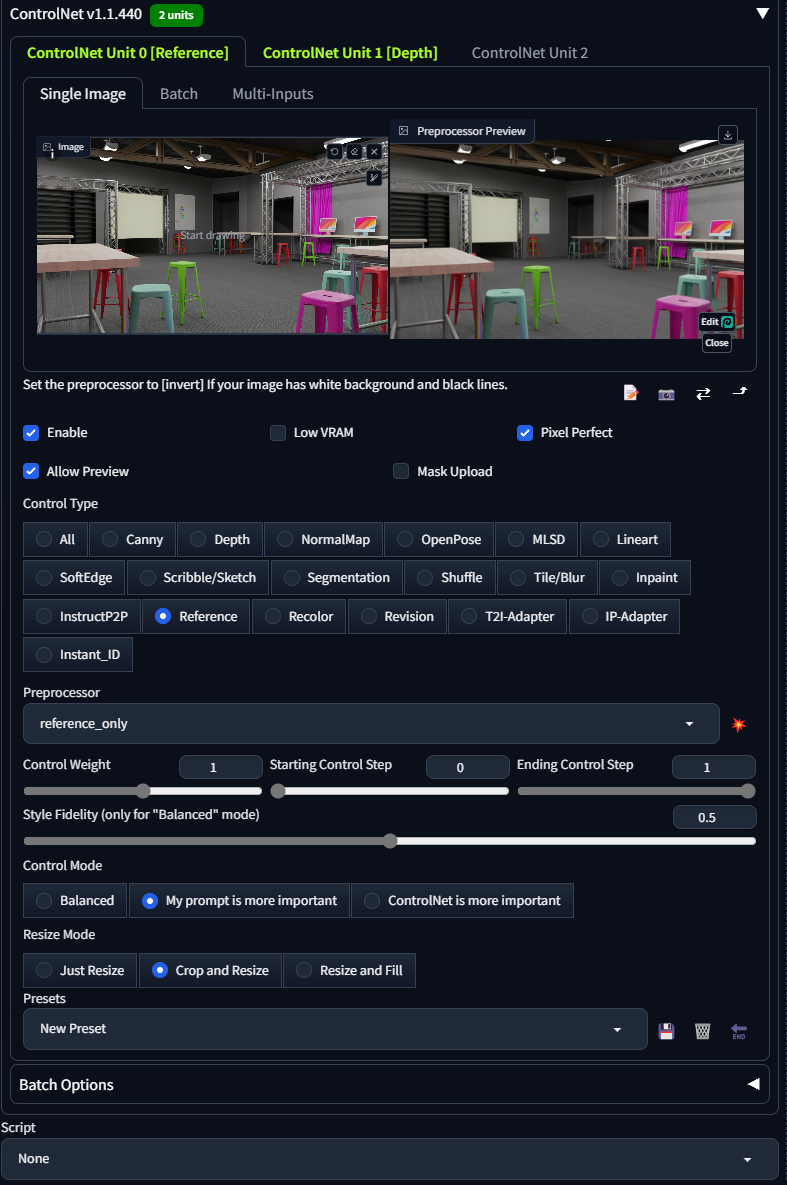
Then open the next Controlnet Tab and check on:
* Enable
* Depth
* Pixel Perfect
* Allow Preview
Finally, open the third Controlnet Tab and check on
* Enable
* Reference
* Pixel perfect
* Allow Preview
Now, we'll need to select a Checkpoint Model. The one I highly recommend is **Dreamshaper**, **Realistic Vision**, or **F222**. All of these will yield good looking results for a scene.
Finally, we'll craft a written prompt to tell Stable Diffusion what this scene should look like, and enter this into the **Prompt** field at the top of the interface.
Hit **Generate** and what comes out should be a fully crafted new image:
.
### Awesome, now what?
NEED: HOW TO DO THE SAME FUNCTION WITH PHOTOSHOP/OTHER STYLES OF IMAGES
NOTES ON GENERATING CHARACTERS
NOTES ON INPAINTING
# OpenCV for Video Processing
Another method of contending with this Interpretation/Generation relationship is the use of OpenCV -- OpenCV is a library of Computer Vision tools that are made for assessing the content of an image/video/camera input/anything kind of digital image.
 Sign in with Wallet
Sign in with Wallet







