# Metaformer is Actually What You Need for Vision [CVPR 2022]
- Paper: https://arxiv.org/abs/2111.11418
- Key idea: abstract the network architecture from high performing models like Transformers, MLP-Mixers etc. It is this network that gives good performance. They replace transformer, MLP-mixer etc with pooling to prove this statement.
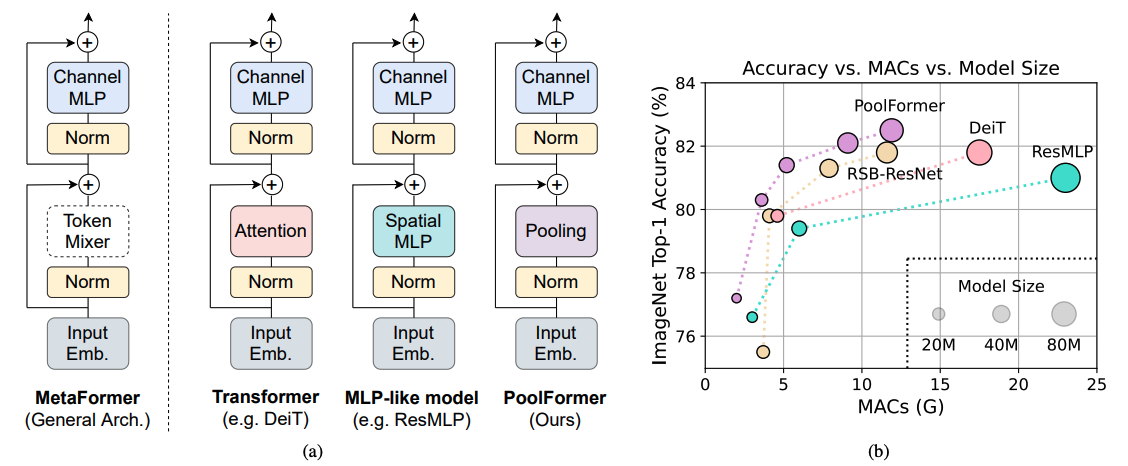
- The main thing to understand is [how pooling works](https://github.com/sail-sg/poolformer/blob/main/models/poolformer.py#L115-L126):
```python
class Pooling(nn.Module):
"""
Implementation of pooling for PoolFormer
--pool_size: pooling size
"""
def __init__(self, pool_size=3):
super().__init__()
self.pool = nn.AvgPool2d(
pool_size, stride=1, padding=pool_size//2, count_include_pad=False)
def forward(self, x):
return self.pool(x) - x
```
Normalization used is `GroupNorm` with `1` group i.e. same as layer norm:
```python
class GroupNorm(nn.GroupNorm):
"""
Group Normalization with 1 group.
Input: tensor in shape [B, C, *]
"""
def __init__(self, num_channels, **kwargs):
super().__init__(1, num_channels, **kwargs)
```
Then:
```python
...
def __init__(self, norm_layer = GroupNorm, ...):
...
self.norm1 = norm_layer(dim)
self.token_mixer = Pooling(pool_size=pool_size)
...
def forward(self, x):
...
x = x + self.drop_path(self.token_mixer(self.norm1(x)))
...
```
### How `use_layer_scale` works (taken from https://arxiv.org/abs/2103.17239)
Key idea is to have almost no contribution from the residual layer at the start of the training and then use learnable parameters to decide how much contribution should come from the residual layer.
```python
layer_scale_init_value=1e-5
if use_layer_scale:
self.layer_scale_1 = nn.Parameter(
layer_scale_init_value * torch.ones((dim)), requires_grad=True)
self.layer_scale_2 = nn.Parameter(
layer_scale_init_value * torch.ones((dim)), requires_grad=True)
def forward(self, x):
if self.use_layer_scale:
x = x + self.drop_path(
self.layer_scale_1.unsqueeze(-1).unsqueeze(-1)
* self.token_mixer(self.norm1(x)))
x = x + self.drop_path(
self.layer_scale_2.unsqueeze(-1).unsqueeze(-1)
* self.mlp(self.norm2(x)))
```
The confusing part is the dimensions of output after `self.norm1` (B,C,H,W) and `self.layer_scale_1` (C,1,1).
It works because `torch.rand(C,1,1) * torch.rand(B,C,H,W)` is the same as `torch.rand(1,C,1,1) * torch.rand(B,C,H,W)`
To do:
- Understand `ceil_mode` and `count_include_pad` in `nn.AvgPool2d`
###### tags: `vit`