# Elasticsearch (一) - 基本概念

Elasticsearch 是一個分散式的搜尋引擎,建立在全文搜尋引擎庫 Apache Lucene 的基礎上。而 Elasticsearch 透過提供 Restful 介面的方式來隱藏 Lucene 複雜的搜索理論,使其可以被快速的架設和使用。
此外,Elasticsearch 具有很高的可擴充性和可用性,使其在儲存、索引和搜尋都非常快速、容易。
<!-- more -->
## 資料格式
Elasticsearch 的資料格式和關聯式資料庫有幾分相似,但還是有區別的,下面我們就來介紹 Elasticsearch 的資料格式以及與關聯式資料庫的關係和差異。
### Field
Field 類似於關聯式資料庫的 Column,是 Elasticsearch 儲存資料的最小單位。例如 : name、phone、address 等等。
### Document
Document 是由多個 Field 組成的,類似於關聯式資料庫的 Row 是由許多 Column 組成。而 Document 是索引和搜尋資料的最小單位。每個 Document 都有一個唯一的 ID 作為識別。
Document 的格式通常是 Json 格式,例如 :
```json=
{
"name":"Max",
"location": "Taiwan"
}
```
Document 裡的 Field 是沒有模式的,也就是說 Field 可以是一個 Document、Array 等等,例如 :
```json=
{
"name":"Max",
"location": {
"Country":"Taiwan",
"County":"Taipei"
},
"members": ["Tom","Frank"]
}
```
### Type
Type 類似於關聯式資料庫的 Table,一個 Document 必須隸屬於一個 Type。
#### Mapping
Mapping 類似於關聯式資料庫的 Schema。
~~這裡有一個和關聯式資料庫的不同是,在同一個 Type 中的不同 Document 允許擁有不同的 Mapping (就是關聯式資料庫的 Schema),也就是說 Field 的數量和名稱都可以不一樣。~~
在 Elastitcsearch 6 以後已經不支援同一個 Type 有不同的 Mapping Type,請見下方 [Mapping Type 的移除](#Mapping-Type-的移除)。
### Index
Index 類似於關聯式資料庫的 Database,一個 Type 必須隸屬於一個 Index。
### Mapping Type 的移除
Mapping Type 在 Elastitcsearch 6 以後已經逐漸被移除了,Mapping Type 要求同一個 Type 裡的每一個 Field 如果名稱相同就必須使用相同的 Data Type,因為同一個 Index 下的所有 Type 的資料是共享的。
例如,`deleted` 可能會是 date 或是 boolean,以往關聯式資料庫不同 Table 是獨立的就可以自行依照需求設定,而 Elasticsearch 受限於 Mapping Type 就一定要用一樣的 Data Type。
針對需要建立相同名稱的 Field 但是不同的 Data Type,官方提出了一個替代的方案,就是 `一個 Index 一個 Document`。
### 上述資料格式的關係如下圖所示 :

## 系統架構
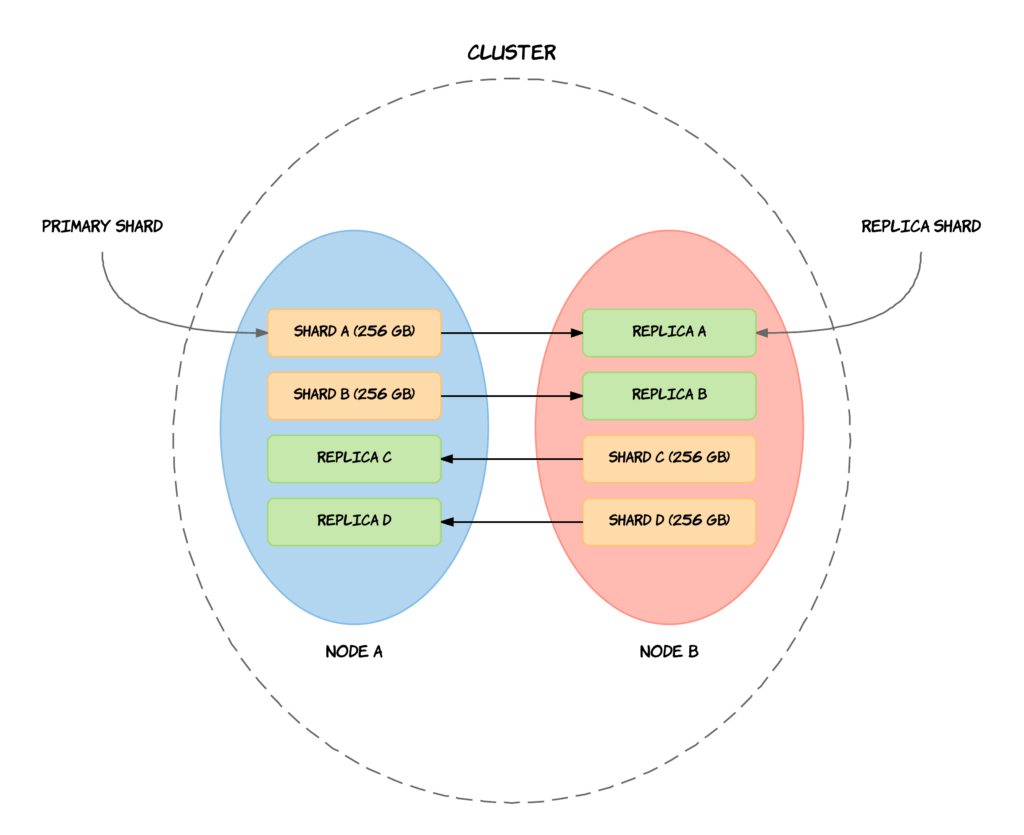
Elasticsearch 採用了分片(Sharding) 的概念將資料拆分到不同的節點 (Node),而整個系統由多個節點組成並且每個節點各保留一部份的資料,這些由多個節點組成的系統稱為叢集 (Cluster)。
### Node (節點)
一個節點代表一個 Elasticsearch 的實體,所以透過一次啟動多個 Elasticsearch 的實體可以將這些實體連接在一起,這些連接在一起的實體就稱為叢集。
### Shard (分片)
分片有助於橫向的擴展以提升記憶體容量,並會盡可能平均的被分配到各節點上。一個 Index 預設會被拆分為 5 個分片,而分片也是資料從一個節點移動到另一個節點的最小單位。
### Replica (複製)
Elasticsearch 會把分片進行複製作為備份使用,稱為複製分片(Replica Shard),而被複製的分片就稱為主分片(Primary Shard)。所以如果預設一個 Index 會被拆分成 5 個分片,則複製之後就會有 5 個主分片和 5 個複製分片,總共 10 個分片。
此外,主分片和複製分片不會出現在同一個節點上以防止節點故障。
### Cluster Status
Cluster 的系統狀態總共有以下三種 :
#### Green
所有主分片和複製分片都已經分配成功,若有一個節點故障資料也不會遺失,但是狀態會變成 Yellow。
#### Yellow
所有主分片已經分配完成,但是有至少一個主分片的複製分片沒有被分配成功。例如只有一個節點則複製分片沒辦法被分配到其他節點,這就會違背了上面提到的主分片和複製分片要在不同節點上。
所以如果主分片所在的節點發生故障了,此時他的複製分片跟他在同一台就會造成資料遺失,則狀態就會變成 Red。
#### Red
至少有一個主分片沒有就緒,也就是找不到對應的複製分片做為新的主分片,此時查詢的結果就會出現資料遺失的情況。
## 索引方式
Elasticsearch 採用反向索引來建立資料的索引,相對於反向索引當然也有正向索引,下面我們就來說明一下兩者的區別。
### 正向索引 (Forward Index)
正向索引或稱正排索引,是以 Document 的 ID 為索引,表中紀錄的是每個 Document 中的每個字段的訊息。主要是用於以 ID 取出整個 Document,例如關聯式資料庫就是用這種方式來做查詢。
正向索引的方式結構較簡單且較好維護,當對 ID 查詢時效率會很高。
### 反向索引 (Inverted Index)
反向索引或稱倒排索引,是以字段或單詞作為索引,表中紀錄的是每個字段或單詞出現在哪個 Docuemnt。
反向索引在建立表時會較為複雜且較不好維護,但是在查詢字段或單詞時,速度會非常快。
然而,反向索引雖然對於關鍵字搜尋的效率有非常大的幫助,但是對於像是聚合 (aggregation)、排序 (Sorting) 和字段的查詢來說效率就沒那麼好了。
反向索引只知道每個單詞對應哪個 Document,並不知道 Document 的內容。如果要做排序或聚合等等的統計就要每次都去取得 Document 的內容,可想而知會非常耗時。
### 範例
我們使用以下兩個句子分別透過正向索引和反向索引來建立索引。
1. I am who i am
2. Who are you
#### 正向索引
對於正向索引而言,當要找到 who 這個單詞時,就要掃描所有的 Document。然而這樣的作法可想而知是行不通的,沒有辦法快速的回傳結果。
| Doc ID | Value |
|:------:|:-----------------:|
| 1 | I, am, who, i, am |
| 2 | who, are, you |
#### 反向索引
對於反向索引而言,當要找到 who 這個單詞時,直接用 who 作為索引就可以查到在哪個 Document 裡面有,非常快速就可以回傳結果。
這裡需要注意的是 Elasticsearch 在建立反向索引時,會自動的將英文的大寫全部轉換成小寫,所以在查詢上可能會有輸入大寫查不到的問題,這部分會在後續介紹查詢時介紹如何解決。
| Value | Doc ID |
|:-----:|:------:|
| i | 1 |
| am | 1 |
| who | 1, 2 |
| are | 2 |
| you | 2 |
### Doc Values
Doc Values 是用來解決反向索引無法得知 Document 內容的一種方式。透過將反向索引取得的結果映射到 Document ID,就可以知道每個 Document 有哪些內容。這個映射的過程又稱為轉置。
Doc Values 會在建立索引時和反向索引一起被建立,建立好後就可以依照需要的情境來使用不同的方式快速進行查詢。例如 : 搜尋就會用反向索引,而要計算一些統計數據就可以用 Doc Values。
| Doc ID | Value |
|:------:|:-------------:|
| 1 | i, am, who |
| 2 | who, are, you |
## Summary
Elasticsearch 屬於非關聯式資料庫的文件資料庫,雖然看似和關聯式資料庫結構很像但實際上卻是不同的概念。從關聯式資料庫轉換到非關聯式資料庫需要一點時間適應他們的差異。
Elasticsearch 採用了反向索引的概念使他的處理速度非常快也非常強大,是一個非常適合用來做全文檢索的工具。
## 參考
[1] [在ElasticSearch中,集群,節點,分片,Indices(索引),replicas(備份)之間是什麼關係?](https://www.zhihu.com/question/26446020)
[2] [Elasticsearch的由來、理及應用場景分析](https://codertw.com/%E4%BC%BA%E6%9C%8D%E5%99%A8/162774/)
[3] [介紹超強大的分散式搜尋引擎 Elasticsearch](https://its-security.blogspot.com/2018/02/introduction-elasticsearch.html)
[4] [Elasticsearch 基本概念 & 搜尋入門](https://godleon.github.io/blog/Elasticsearch/Elasticsearch-getting-started/)
[5] [全文搜索引擎 Elasticsearch ](https://www.ruanyifeng.com/blog/2017/08/elasticsearch.html)
[6] [ElasticSearch從入門到精通](https://www.itread01.com/content/1546464245.html)
[7] [Elasticsearch倒排索引原理](https://kknews.cc/zh-tw/code/pyo59ep.html)
[8] [ElasticSearch索引原理淺析(DocValues 和 Fielddata)](https://www.jianshu.com/p/04837bf5863f)
[9] [深入理解 ElasticSearch Doc Values](http://www.majiang.life/blog/deep-dive-on-elasticsearch-doc-values/)
[10] [elasticsearch大小寫無法使用term查詢的問題](https://www.jianshu.com/p/a86074177585)
###### tags: `Elasticsearch` `NoSQL`
 Sign in with Wallet
Connect another wallet
Sign in with Wallet
Connect another wallet