# Topic Presentation 1 - Meta Learning for AutoML
**Group 9**
**0811326 沈琮育**、**311554046 林愉修**
Video: [Meta Learning Tutorial AAAI 2021 Part3 AutoML Video][1]
## least square error



## newton's method



## entropy






## 自動調整hyperparameter


## bayesian optimization





## AutoML

## Warm Starting

* **Idea**
Instead of starting randomly, let it starts from the configurations that were successful on similar tasks, which are able to remarkably minimize the number of evaluations. In order to do this, we need a way to measure task similarity.
* **How to measure task similarity?**

* [Hand-designed (statical) meta-features that describe (tabular) datasets][2]
* [Task2Vec: task embedding for image data][3]
* [Optimal transport: similarity measure based on comparing probabiltiy distributions][4]
* [Metadata embedding based on textual dataset description][5]
* [Dataset2Vec: compares batches of datasets][6]
* [Distribution-based invariant deep networks][7]
* **Warm-starting with kNN**

One thing we can do is called kNN approach, which has been successful for a very long time. Given a new task, we select the prior similar tasks and start the search from the pipeline or the architecture that work well on that prior similar task for the new task.
* **Probabilistic Matrix Factorization**

Another thing we can do is probabilistic matrix factorization (PMF), which combines the idea of collaborative filtering (Recommender systems) and Bayesian optimization.
Predicting the performance of configurations on a new task can be view as a collaborative filtering problem. We can use PMF to embed different configurations in a latent space based on their performance across different tasks.
Given $N$ configurations and $T$ tasks, the performace of each combination can be represented in a matrix $P\in \Bbb R^{N\times T}$, and we learn latent representation using matrix composition (the information about how configurations compare to each others) and reuse it to build a new search space that is easier to model, we then use PMF to predict the missing value in $P$. We can combine with acquisition function like EI (Expected Improvement) to guide the exploration in configuration search space.
* **[DARTS: Differentiable NAS][9]**

> NAS is the abbreviation for "Neural Architecture Search". The optimization algorithm that is often used in neural architecture search is "Gradient descent" and "Reinforcement learning".
DARTS uses the gradient-based optimization, it searchs over a continous and differentiable search space by softmax function to relax the discrete space.
It starts with fixed structure, which the user has to provide, states (tensors) with links in between, and the links can be refer to many different option of layer, giving these links a weight $\alpha_i$, this creates the space of the possible neural networks, thus we can use bilevel optimization to find the optimized network architecture.
* [Warm-started DARTS][10]

Instead of starting from user-defined architecture, we can learn a good model to start from, which means we can train a initial model on one dataset and trasfer to other datasets, so the finding of the architecture would be more efficient.
## Meta-models

These are models that are trained to build entire new models or to learn good model components (eg. activation function).
* **Algorithm selection models**

* **[Learning model components][15]**

* **[Monte Carlo Tree Search + reinforcement learning][14]**

* **[Neural Architecture Transfer learning][13]**

* **[Meta-Reinforcement Learning for NAS][12]**


Instead of training a neraul architecture for a specific task from scratch, we want to transfer some of the prior tasks information, which is useful, to train the neural architecture for the new task.
* **[MetaNAS: MAML + Neural Architecture Search][11]**

Rememeber in DARTS, we have to learn $\alpha_i$, here we learn these $\alpha$ using a meta-learning algorithm called MAML (Model-Agnostic Meta Learning), optimize these $\alpha$ along with the meta-parameters $\Theta$ (initial weights) and after we learn this over a number of tasks, we can warm-start DARTS.
## Survey Topic
### Hardware-Aware Efficient NAS
* **Motivation**
Designing Convolutional Neural Networks for mobile devices is challenging since the models have to be small and fast, yet still accurate while the design space is very large and computationally expensive.
* **Papers**
* [MnasNet: Platform-Aware Neural Architecture Search for Mobile][16]
* [FBNet: Hardware-Aware Efficient ConvNet Design via Differentiable Neural Architecture Search][17]
* [Single-Path NAS: Design Hardware-Efficient ConvNets in less than 4 Hours][18]
* [EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks][19]
* [Searching for Efficient Neural Architectures for On-Device ML on Edge TPUs][20]
[1]: https://drive.google.com/file/d/1ZAIt8X1c7VA9CDC_JxwxuB0j3972CuSi/view "Google Drive"
[2]: https://arxiv.org/abs/1810.03548 "Arxiv"
[3]: https://arxiv.org/abs/1902.03545 "Arxiv"
[4]: https://www.microsoft.com/en-us/research/publication/geometric-dataset-distances-via-optimal-transport/ "Microsoft"
[5]: https://arxiv.org/abs/1910.03698 "Arxiv"
[6]: https://www.ismll.uni-hildesheim.de/pub/pdfs/jomaa2019c-nips.pdf "ismll"
[7]: https://arxiv.org/abs/2006.13708 "Arxiv"
[9]: https://arxiv.org/pdf/1806.09055.pdf "Arxiv"
[10]: https://arxiv.org/abs/2205.06355 "Arxiv"
[11]: https://arxiv.org/abs/1911.11090 "Arxiv"
[12]: https://arxiv.org/abs/1911.03769 "Arxiv"
[13]: https://proceedings.neurips.cc/paper/2018/file/bdb3c278f45e6734c35733d24299d3f4-Paper.pdf "Neurips"
[14]: https://arxiv.org/pdf/1905.10345.pdf "Arxiv"
[15]: https://arxiv.org/pdf/1710.05941.pdf "Arxiv"
[16]: https://openaccess.thecvf.com/content_CVPR_2019/papers/Tan_MnasNet_Platform-Aware_Neural_Architecture_Search_for_Mobile_CVPR_2019_paper.pdf "CVF"
[17]: https://openaccess.thecvf.com/content_CVPR_2019/papers/Wu_FBNet_Hardware-Aware_Efficient_ConvNet_Design_via_Differentiable_Neural_Architecture_Search_CVPR_2019_paper.pdf "CVF"
[18]: https://arxiv.org/abs/1904.02877 " Arxic"
[19]: https://arxiv.org/abs/1905.11946 "Arxiv"
[20]: https://openaccess.thecvf.com/content/CVPR2022W/ECV/papers/Akin_Searching_for_Efficient_Neural_Architectures_for_On-Device_ML_on_Edge_CVPRW_2022_paper.pdf "CVF"
# Topic Presentation 3 - Hardware-Aware Neural Architectures Search
**Group 9**
**0811326 沈琮育**、**311554046 林愉修**
**survey topic**
1. FBNet: Hardware-Aware Efficient ConvNet Design via Differentiable Neural Architecture Search
2. MnasNet: Platform-Aware Neural Architecture Search for Mobile
3. Once-for-All: Train One Network and Specialize it for Efficient Deployment
**content structure**
* Introduction
* Why this is important
* Background knowledge
* Existed works
* Possible future direction
## FBNet: Hardware-Aware Efficient ConvNet Design via Differentiable Neural Architecture Search
### prior knowledge
1. FLOPS:
每秒浮點運算次數,亦稱每秒峰值速度(英語:Floating-point operations per second;縮寫:FLOPS)。
2. SGD:
準確梯度下降法,(stochastic gradient decent)。
SGD 是最單純的gradient decent 方法,利用微分的方法找出參數的梯度,往梯度的方向去更新參數(weight),即:
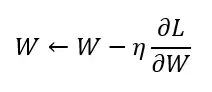
W 為權重(weight)參數
L 為損失函數(loss function)
η 是學習率(learning rate)
∂L/∂W 是損失函數對參數的梯度(微分)
3. NAS (Neural Architecture Search):
* goal
NAS 的目的就是希望可以有一套演算法或是一個框架能夠自動的根據我們的需求找到最好的 neural architecture,而我們的搜索目標有可能會是根據 performance,或是根據硬體資源限制 (hardware constraints) 來進行搜索。
* Searching contain three parts
(1) Search Space
(2) Search Strategy
(3) Performance Estimation

* Illustration of manual ConvNet design.

* Reinforcement Learning based neural architecture search.

* Disvantages
4. DNAS (Differential Neural Architecture Search)
### introduction

In the past, many works use reinforcement learning (RL) to guide the search and a typical flow.
## MNASNET: Platform-Aware Neural Architecture Search for Mobile
## Once-for-All: Train One Network and Specialize it for Efficient Deployment
 Sign in with Wallet
Sign in with Wallet







