---
GA: UA-159972578-2
---
###### tags: `R` `recommenderlab` `Recommendation System` `推薦系統`
# recommenderlab套件介紹
Reference: [Michael Hahsler(2011). "recommenderlab: A Framework for Developing and Testing Recommendation Algorithms."](https://cran.r-project.org/web/packages/recommenderlab/vignettes/recommenderlab.pdf)
# 推薦系統基本觀念—Collaborative Filtering(協同式過濾)
## 1. User-based Collaborative Filtering(UBCF)
### Memory-based CF
+ 採用「全部」或巨量的使用者資料去進行推薦→佔記憶體
+ 推薦系統通常是在線上進行運算,因此上述特性會不利於演算速度
### 原理
+ 假設:擁有相似偏好的人會對項目有相似的評分標準。
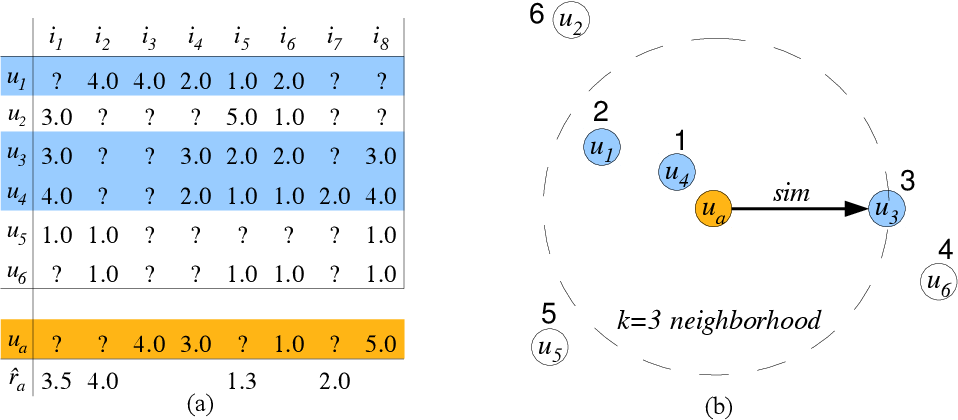
+ 從與 $u_a$ 相似的 $k$ 個( $k=3$ )鄰居( $u_4 , u_1 , u_3$ )的評分紀錄中計算出(e.g.平均) $u_a$ 的缺失項目( $i_1 , i_2 , i_5, i_7$ )評分,進而取前幾高 $\hat{r}_a$ 做推薦。
+ 如何計算相似度?
1. Pearson Correlation Coefficient
+ 即統計學常用之相關係數:r
+ 公式:
3. Cosine Similarity
+ 計算各點之間的Cosine角度,角度愈小欲相似。
+ 公式:
+ 如何找出鄰居(Neighborhood)?
1. KNN(k-nearest-neighbors)演算法:以新點為中心距離K個最近的點中,哪種類別最多即為該類別。
2. 給定一個Similarity Threshold值來選出相似的人
+ 計算 $u_a$ 的評分( $\hat{r_a}$ ):
+ 簡易版公式:
+ 加權版公式:
+ 鑑於在 $k$ 人之中,仍有與 $u_a$ 距離的差異,因此需增加權重(Weights)
+ $S_a$ 為 $u_a$ 和 $u_i$ ($i$ within $k$ neighbors) 的相似度
+ 移除個人評分上的偏誤(為了讓每個user的評分權重一樣):
+ Normalization(常態化):Z-score
+ Center the row:
## 2. Item-based Collaborative Filtering(IBCF)
### Model-based CF
+ 採用部分的(Reduced Similarity Matrix by $k$)使用者資料去學習一個Compact Model
+ 因為模型小( $n$ x $k, k ≪ n$ ),較有效率
+ 應用上可以完全地達成預先運算(fully precomputed)
### 原理
+ 假設:喜歡i品項的人也會喜歡與i品項有相似的特徵的項目。
+ 將 $u_a$ 有的評分( $i_1 , i_5, i_8$ )與Similarity Matrix前 $k$ 高( $k=3$ )的評分矩陣拿去做加權總和(Weighted Sum),算出 $u_a$ 其他缺失項目的評分,並取前幾高的 $\hat{r}_a$ 做推薦。
+ Similarity Matrix:

+ 計算評分的公式:
+ 移除個人評分偏誤的方法同UBCF
### Other model-based approaches
I. Slope One algorithm (Lemire and Maclachlan 2005)
II. Latent Factors approach using matrix decomposition (Koren, Bell, and Volinsky 2009)
## 3. Using 0-1 Data
### 真實情境
1. 我們拿到的資料有很大的機率都是Binary的資料(有/無購買商品),不一定都有Ratings
2. 我們不知道消費者沒有購買商品,是因為哪種情況?
+ 不需要
+ 不知情
+ 不喜歡
### 推薦演算法的因應作法
網站流量資料中,我們只知道該頁面是否被預覽的資訊(Binary Data)
+ 1:使用者喜歡此項目(非缺失項目)
+ 0:使用者不喜歡此項目/使用者不知道此項目存在(缺失項目)
因此在0-1 Case中,
+ 缺點:非缺失項目全部都是1,將無法計算Pearson correlation或Cosine similarity
+ 解方:使用Jaccard index
+ 另一種Similarity的衡量方式(只專注在1的情況)
+ $,$ where X and Y are the sets of the items with a 1 in user profiles $u_a$ and $u_b,$ respectively.
### 基於關聯規則(Association Rules)的0-1 Data
+ 與IBCF相似(使用條件機率similarity)
+ 可以預先運算
+ 關聯規則的重要評估指標:
+ $support(X → Y) = support(X ∪ Y) = Freq(X ∪ Y)/|D| = \hat{P}(E_X ∩ E_Y)$
+ $confidence(X → Y)=support(X ∪Y)/support(X)=\hat{P}(E_Y|E_X)$
#### 應用於推薦系統上
1. 找出所有匹配 $X → Y, X ⊆ T_a$ 的規則
2. 推薦N個獨一(unique)、擁有最高 $confidence$ 的 $right-hand-sides (Y)$規則
## 4. 評估方法
### 1. 評估預測評分值(Ratings)
+ MAE:
+ RMSE:
### 2. 評估Top-N的推薦
+ 混淆矩陣(Confusion Matrix)
| actual \ predicted | negative | positive |
| -------- | -------- | -------- |
| negative | a (TN) | b **(FP)** |
| positive | c (FN) | d **(TP)** |
+ Accuracy: $,\frac{TP+TN}{Total}$
+ MAE: $,\frac{TP+FN}{Total}$
+ **Precision:** $,\frac{TP}{TP+FP}$
+ **Recall:** $,\frac{TP}{TP+FN}$
+ E-measure:$, α$ controls the trade-off between precision and recall.
+ F-measure:
# `recommenderlab`的功能
## 1. 建立資料
+ 資料轉換
+ `as(data, "realRatingMatrix")`:模型使用
+ 查看資料
+ `getRatingMatrix(data)`:取得矩陣內容
+ `as(data, "list")`:推薦的items可以用list查看
+ `as(data, "data.frame")`:用data frame的形式查看
```{r}
# 製作評分資料
m <- matrix(sample(c(as.numeric(0:5), NA), 50, replace=T,
prob=c(rep(.4/6,6),.6)), ncol=10,
dimnames=list( user=paste("u", 1:5, sep=""),
item=paste("i", 1:10, sep="")))
## 轉換資料型態
r = as(m, "realRatingMatrix")
getRatingMatrix(r)
identical(as(r, "matrix"),m) # TRUE
```
```
u1 . 4 . . 4 . . . . 1
u2 . . . . . . 1 0 . .
u3 . . . 4 . 1 3 1 . .
u4 3 . . . 0 . . 3 2 .
u5 . 0 . 5 0 0 . 1 . 1
```
## 2. 移除評分偏誤
+ `normalize(data)`:Center the row
+ 會使極端評分(只評0分和5分)、中性評分(都評2~3分)的人變得沒有差別
+ `normalize(data, method="Z-score")`:Z-score
+ 若想保留不同user的評分級距資訊,使用此法較合理(平均數為0,標準差為1)
+ `denormalize(data)`:還原常態化
```{r}
r_m = normalize(r)
getRatingMatrix(r_m)
```
```
u1 . 1.00 . . 1.00 . . . . -2.000
u2 . . . . . . 0.50 -0.500 . .
u3 . . . 1.75 . -1.25 0.75 -1.250 . .
u4 1 . . . -2.00 . . 1.000 0 .
u5 . -1.17 . 3.83 -1.17 -1.17 . -0.167 . -0.167
```
## 3. 視覺化評分資料分佈
+ `image(data, main="Title")`
```{r}
image(r_m, main = "Normalized Ratings") # 馬賽克圖
```

## 4. 製作0-1 Data
+ `binarize(data, minRating)`
+ 設定 ≥ minRating 以上的評分為1,其餘為0
```{r}
r_b <- binarize(r, minRating=4) # 只有4以上的評分會被記為1
as(r_b, "matrix")
```
```
i1 i2 i3 i4 i5 i6 i7 i8 i9 i10
u1 FALSE TRUE FALSE FALSE TRUE FALSE FALSE FALSE FALSE FALSE
u2 FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
u3 FALSE FALSE FALSE TRUE FALSE FALSE FALSE FALSE FALSE FALSE
u4 FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
u5 FALSE FALSE FALSE TRUE FALSE FALSE FALSE FALSE FALSE FALSE
```
## 5. 模型製作與預測
### 查看所有推薦演算法
+ ` recommenderRegistry$get_entries(dataType = "realRatingMatrix")`
### 建立一般模型
+ `Recommender(data, method)`
### 建立驗證模型
+ `evaluationScheme(data, method="split", train, given, goodRating)`
+ method:
+ split:切割train/test資料
+ train:設定training data的比例
+ cross:交叉驗證
+ k:做k回交叉驗證
+ given:數字(要放入幾個items訓練模型)
+ 每個user有多個items的評分,given決定模型在看了n個評分後,就去猜unknown items的評分。
+ 由於訓練時會保留了一些known data,因此可以計算error。
+ 若填入負數,表示扣除該數字,放入全部的資料(all-but-n)。
+ goodRating:一種threshold,決定多少以上算是好的評分。
+ `evaluate(scheme, method="POPULAR", type = "topNList", n=c(1,3,5,10,15,20))`
+ 可以取代predict的功能,直接幫你跑完結果。
+ 一次做top-1, top-3, ...到top-20的模型。
### 預測模型
+ `predict(model, newData, type)`
+ model:做完Recommender(data, method)之後的變數。
+ type:評分方式
+ topN, ratings, ... 依據不同model方法而不同。
+ 可以用`names(getModel(model))`查看。
+ type選擇使用topN時,可直接省略type,並設定n:直接選擇predict n個結果。
+ `bestN(predict, n)`:選取TopN中最高的n個。
### 評估模型
+ `calcPredictionAccuracy(predict, unknowData)`:計算RMSE/MSE/MAE
+ `getConfusionMatrix(evaluate)[[1]]`:計算TP/FP/FN/TN/precision/recall/TPR/FPR
+ `avg(evaluate)`:看平均的表現
```{r}
# 建立evaluationScheme
e = evaluationScheme(Jester5k[1:1000], method="split", train=0.9,
given=15, goodRating=5)
# create recommender
r1 = Recommender(getData(e, "train"), "UBCF") # training data
r2 = Recommender(getData(e, "train"), "IBCF")
# prediction
p1 = predict(r1, getData(e, "known"), type="ratings") # testing data
p2 = predict(r2, getData(e, "known"), type="ratings")
# evaluate
error <- rbind(
UBCF = calcPredictionAccuracy(p1, getData(e, "unknown")), # unknown data
IBCF = calcPredictionAccuracy(p2, getData(e, "unknown")))
```
```
RMSE MSE MAE
UBCF 4.71 22.1 3.77
IBCF 5.36 28.7 4.25
```
```{r}
scheme = evaluationScheme(Jester5k[1:1000], method="cross", k=4,
given=3, goodRating=5)
results = evaluate(scheme, method="POPULAR", type = "topNList",
n=c(1,3,5,10,15,20)) # evaluate top-1, top-3, top-5, top-10, top-15 and top-20
avg(results)
```
```
TP FP FN TN precision recall TPR FPR
1 0.457 0.543 16.7 79.3 0.457 0.0392 0.0392 0.00644
3 1.242 1.758 16.0 78.0 0.414 0.0934 0.0934 0.02112
5 2.053 2.947 15.1 76.9 0.411 0.1486 0.1486 0.03536
10 3.944 6.056 13.3 73.7 0.394 0.2835 0.2835 0.07299
15 5.653 9.347 11.5 70.5 0.377 0.3921 0.3921 0.11270
20 7.066 12.934 10.1 66.9 0.353 0.4801 0.4801 0.15639
```
###
# 範例Demo
Jester線上笑話推薦系統
+ 5000份匿名評分資料
+ 1999年4月到2003年5月
## 1. 讀取資料
```{r}
data(Jester5k)
Jester5k
set.seed(1234)
r = sample(Jester5k, 1000) # 因為資料太大改用隨機抽樣的 # 71682 obs.
```
```
5000 x 100 rating matrix of class ‘realRatingMatrix’ with 362106 ratings.
```
## 2. 敘述性統計
+ `rowCounts()`:user總共評價幾筆資料
+ `rowMeans()`:user的平均評分
```{r}
rowCounts(r[1,]) # 70筆
rowMeans(r[1,]) # user’s rating average: 2.58
hist(getRatings(r), breaks=100)
hist(rowCounts(r), breaks=50)
hist(colMeans(r), breaks=20)
```
我們發現資料有很大的評分偏誤:

多數人評價了70筆或全部的笑話:

平均評分的分數接近左偏的常態分佈:

## 3. 移除評分偏誤
```{r}
hist(getRatings(normalize(r)), breaks=100) # remove bias
```

## 4. 比較模型與表現評估
```{r}
set.seed(2016)
# validation scheme
scheme = evaluationScheme(
Jester5k[1:1000], method="split", train = .9,
given=-5, goodRating=5);
# list of algorithm: random items, popular items, user-based CF, item-based CF, and SVD approxi- mation.
algorithms <- list(
"random items" = list(name="RANDOM", param=NULL),
"popular items" = list(name="POPULAR", param=NULL),
"user-based CF" = list(name="UBCF", param=list(nn=50)),
"item-based CF" = list(name="IBCF", param=list(k=50)),
"SVD approximation" = list(name="SVD", param=list(k = 50)))
# comparing top-N
results <- evaluate(
scheme, algorithms, type = "topNList",
n=c(1, 3, 5, 10, 15, 20))
```
+ ROC曲線(TPR vs FPR)
+ 對於ROC曲線,我們希望找到TPR高且FPR低的點(左上角),代表猜對的多、猜錯的少
+ 但這兩者剛好是一個trade-off,不能兩全其美
+ 因此可依據domain knowledge去決定應選擇何種組合
```{r}
plot(results, annotate=c(1,3), legend="bottomright")
```

上圖的線為不同的推薦演算法;數字代表推薦TopN個商品。
隨著推薦個數(TopN)愈多,TPR和FPR皆會上升(猜得愈多,猜中/猜錯的次數都會變大)。
結論:UBCF表現最佳且遠高於Based line的Random演算法(亂猜,機率0.5)。
+ Precision vs Recall
```{r}
plot(results, "prec/rec", annotate=3, legend="topleft")
```

+ 評估Ratings
```{r}
# evaluating & comparing rating error
results = evaluate(scheme, algorithms, type = "ratings")
plot(results, ylim = c(0,100)) # Plotting the results shows a barplot with the RMSE, MSE and MAE
```

透過互動式App感受推薦系統的樣貌→ [ShinyApp](https://mhahsler-apps.shinyapps.io/Jester/) by Michael Hahsler.
 Sign in with Wallet
Connect another wallet
Sign in with Wallet
Connect another wallet