---
tags: Research
---
# Cache Coherency & I/O ordering
## Cache Coherency
在多處理器的機器上,每個 CPU 都有自己的 cache,以彌補 CPU 和主記憶體(Main memory) 之間較慢的存取速度,當一個特定資料首次被特定的 CPU 讀取時,此資料顯然不存在於該 CPU 的 cache 中 (即 cache miss),意味著 CPU 需要自主記憶體中讀取資料 (為此,CPU 通常要等待數百個 cycle),此資料最終將會存放於 CPU 的 cache 中,這樣後續就能直接自 cache 上快速存取,不需要再透過主記憶體。因為每個 CPU 上的 cache 資料是 private 的,因此在進行寫入操作時,會造成其他 CPU 上的 cache 資料不一致的問題。
e.g.

> 取自 [MIT 6.004 L25: Cache Coherence](https://www.youtube.com/watch?v=83jOKVb_HTM&ab_channel=SilvinaHanonoWachman)
1. Core0 load memory from address `0xA`,資料內容為 2
2. Core2 store memory to address `0xA`,更新資料在自己的 cache 上,並在稍後補回 memory,而更新內容為 3。
3. Core2 的更新 Core0 並不知道,因此 Core0 還以為 `0xA` 上所存的資料是 2,但顯然這份資料已經過時。
為了確保所有 CPU 上的 cache 資料是一致的,當某個 CPU 進行寫入操作時,它必須保證其他 CPU 已將資料從他的 cache 中移除 (方可確保一致性),僅在移除操作完成後,此 CPU 才能安全的修改資料。專門處理一致性協定統稱為 cache-coherence protocol。透過 cache-coherence protocol,任何一個 CPU 要寫入資料前,都要先確保其他 CPU 已 invalid 同一位置的 cache 後 (希望寫入的 CPU 廣播 invalidate,其它 CPU 回 invalidate ack), 才能寫資料到自己的 cache,並在稍後補寫回 memory。
## Cache Coherent Interconnect
在介紹 cache-coherence protocol 前,先講解不同 CPU 間是如何進行溝通的。CPU 之間的溝通主要是透過 [system bus](https://en.wikipedia.org/wiki/System_bus),system bus 主要是用來連接 CPU、主記憶體和其他 I/O 設備,因為 CPU 中的 cache 進行 cache coherency 時,也是透過 system bus 來廣播 Probe Read 以及 Probe Write 請求,其他 CPU 也是透過 system bus 進行相對應的回應。因此,我們也稱 system bus 為 Cache Coherent Interconnect。

> 取自 [OpenMP, Cache Coherence](https://inst.eecs.berkeley.edu/~cs61c/su20/pdfs/lectures/lec23.pdf)
## Cache Coherence protocol
這邊介紹兩種 cache-coherence protocol:
1. MESI protocol
2. MOESI protocol
在實作這兩種 cache-coherence protocol,會先定義一系列請求,這些請求有 CPU 對於自己的 cache 的請求,也有 CPU 對於其他 CPU 的 cache 的請求。定義如下:
* Read Hit: CPU 要讀取資料時,發現自己的 cache 中含有這份資料
* Write Hit: CPU 要寫入資料時,發現自己的 cache 中含有這份資料
* Read Miss: CPU 要讀取資料時,發現自己的 cache 中沒有這份資料
* Write Miss: CPU 要讀取資料時,發現自己的 cache 中沒有這份資料
* Probe Read: 某一 CPU 要讀取資料時,先去看其他 CPU 中的 cache 有沒有更新這份資料
* Probe Write: 某一 CPU 要寫入資料時,去看其他 CPU 中的 cache 是否存有這份資料
* Probe Read Hit: 其他 CPU 中的 cache 打算讀取這份資料,且該 CPU 含有這份資料
* Probe Write Hit: 其他 CPU 中的 cache 打算寫入這份資料,且該 CPU 含有這份資料
### MESI protocol
MESI protocol 就是為每一個 cacheline 標上狀態,狀態分為 MESI 三種:
1. Modified(M)
* 這份資料是最新且被修改過的,這份資料可以被寫回主記憶體
* 其他 CPU 上的 cache 沒有這份資料
* 在主記憶體中的這份資料是過時的
2. Exclusive(E)
* 其他 CPU 上的 cache 沒有這份資料
* 在主記憶體中的這份資料和 cache 中存有的這份資料是一樣的
* 其他 CPU 上的 cache 發 probe read 時,會將資料提供給他
3. Shared(S)
* 其他 CPU 上的 cache 必定含有同一份資料
* 在主記憶體中的這份資料和 cache 中存有的這份資料是一樣的
4. Invalid(I)
* cache 中存有的這份資料是過時的
#### CPU 對自己的 cache 下請求的狀態圖

> 取自 [OpenMP, Cache Coherence](https://inst.eecs.berkeley.edu/~cs61c/su20/pdfs/lectures/lec23.pdf)
#### 收到其他 CPU 上的 cache 下請求的狀態圖

> 取自 [OpenMP, Cache Coherence](https://inst.eecs.berkeley.edu/~cs61c/su20/pdfs/lectures/lec23.pdf)
實作上,用 3 個 bit 來表示該 cacheline 的狀態,分別是 valid bit、dirty bit 和 shared bit,由這三個 bit 來組合出 `MESI` 4 個不同的狀態:
| | Valid bit | Dirty bit | Shared bit |
| -------- | -------- | -------- | -------- |
| Modified | 1 | 1 | 0 |
| Exclusive | 1 | 0 | 0 |
| Shared | 1 | 0 | 1 |
| Invalid | 0 | X | X |
X = doesn’t matter
我們舉個例子來說明 MESI protocol 的流程:
1. Processor 0 對主記憶體中的 Block 0 進行讀取,因為 Processor 0 是第一個且第一次進行讀取,因此這個 cacheline 的狀態會設定成 `Exclusive`
2. Processor 1 想對 Block 0 進行讀取,他會發 Probe read 給 Processor 0,接著 Processor 0 會收到 Probe read hit,因為其 cache 中有 Block 0 的資料,Processor 1 從 Processor 0 讀取資料,並將其 cacheline 狀態設定成 `Shared`
3. Processor 0 想對 Block 0 進行寫入,Processor 0 含有 Block 0 的 cacheline 被設定成 `Modified`,他必須發 Probe Write 給 Processor 1,去看 Processor 1 的 cache 中是否含有 Block 0。接著 Processor 1 會收到 Probe write hit,因為其 cache 中有 Block 0 的資料。此時,Processor 1 含有 Block 0 的 cacheline 也會被設定成 `Invalid`,因為其資料已過時。
4. Processor 1 想對 Block 0 進行讀取,他會發 Probe read 給 Processor 0,接著 Processor 0 會收到 Probe read hit,因為其 cache 中有 Block 0 的資料。因為這個 cacheline 的狀態是 `Modified`,當收到 Probe read hit 時,會將這份資料寫回主記憶體中,並將狀態改為 `Shared`,接著 Processor 1 從 Processor 0 讀取資料,並將其 cacheline 狀態設定成 `Shared`
MESI protocol 的缺點就是每次發送 Probe read 讀到一個狀態為 `Modified` 的 cacheline 時,就要將資料更新回主記憶體,但將資料寫回主記憶體是非常浪費時間的。
### MOESI protocol
為了避免將資料寫回主記憶體,MOESI protocol 加入了一個新的狀態 Owner,並稍微修改 Shared 狀態的定義:
1. Owner(O)
* 其他 CPU 上的 cache 含有這份資料
* 在主記憶體中的這份資料和 cache 中存有的這份資料不一樣 (Owner 擁有的資料比較新)
* 其他 CPU 上的 cache 發 probe read 時,會將資料提供給他且不會寫回 memory
3. Shared(S)
* 其他 CPU 上的 cache 必定含有同一份資料
* 在主記憶體中的這份資料和 cache 中存有的這份資料**可能是**一樣的
#### CPU 對自己的 cache 下請求的狀態圖

> 取自 [OpenMP, Cache Coherence](https://inst.eecs.berkeley.edu/~cs61c/su20/pdfs/lectures/lec23.pdf)
#### 收到其他 CPU 上的 cache 下請求的狀態圖

> 取自 [OpenMP, Cache Coherence](https://inst.eecs.berkeley.edu/~cs61c/su20/pdfs/lectures/lec23.pdf)
實作上,用 3 個 bit 來表示該 cacheline 的狀態,分別是 valid bit、dirty bit 和 shared bit,由這三個 bit 來組合出 `MOESI` 5 個不同的狀態:
| | Valid bit | Dirty bit | Shared bit |
| -------- | -------- | -------- | -------- |
| Modified | 1 | 1 | 0 |
| Owner | 1 | 1 | 1 |
| Exclusive | 1 | 0 | 0 |
| Shared | 1 | 0 | 1 |
| Invalid | 0 | X | X |
X = doesn’t matter
我們一樣舉個例子來說明 MOESI protocol 的流程:
1. Processor 0 對主記憶體中的 Block 0 進行讀取,因為 Processor 0 是第一個且第一次進行讀取,因此這個 cacheline 的狀態會設定成 `Exclusive`
2. Processor 0 想對 Block 0 進行寫入,Processor 0 含有 Block 0 的 cacheline 被設定成 `Modified`,他必須發 Probe Write 給 Processor 1,但因為 Processor 1 的 cache 中有是空的,所以沒有任何改變。
3. Processor 1 想對 Block 0 進行讀取,他會發 Probe read 給 Processor 0,接著 Processor 0 會收到 Probe read hit,因為其 cache 中有 Block 0 的資料,Processor 1 直接從 Processor 0 讀取資料,並將其 cacheline 狀態設定成 `Shared`,而 Processor 0 上的 cacheline 狀態則會從 `Modified` 變為 `Owner`。
4. Processor 0 想對 Block 0 進行寫入,Processor 0 含有 Block 0 的 cacheline 從 `Modified` 被設定成 `Owner`,他必須發 Probe Write 給 Processor 1,去看 Processor 1 的 cache 中是否含有 Block 0。接著 Processor 1 會收到 Probe write hit,因為其 cache 中有 Block 0 的資料。此時,Processor 1 含有 Block 0 的 cacheline 也會被設定成 `Invalid`,因為其資料已過時。
5. Processor 1 想對 Block 0 進行讀取,他會發 Probe read 給 Processor 0,接著 Processor 0 會收到 Probe read hit,因為其 cache 中有 Block 0 的資料,Processor 1 直接從 Processor 0 讀取資料,並將其 cacheline 狀態設定成 `Shared`,而 Processor 0 上的 cacheline 狀態則會從 `Modified` 變為 `Owner`。
透過上述案例我們可以發現,整個過程中並沒有涉及到任何將 cache 中資料更新回主記憶體的動作,因此,MOESI protocol 成功解決要將資料寫回主記憶體的問題。
## Store Buffer
上面有提到,一個 CPU 要寫入資料前,必須發送 Probe write 去確保其他 CPU 已 invalid 同一位置的 cache,等到其他 CPU 回應 invalidate ack 後,才能寫資料到自己的 cache 中。

> 取自 [從硬體觀點了解 memory barrier 的實作和效果](https://medium.com/fcamels-notes/%E5%BE%9E%E7%A1%AC%E9%AB%94%E8%A7%80%E9%BB%9E%E4%BA%86%E8%A7%A3-memry-barrier-%E7%9A%84%E5%AF%A6%E4%BD%9C%E5%92%8C%E6%95%88%E6%9E%9C-416ff0a64fc1)
由上圖可知,這個設計確保資料的一致性,但是代價是寫入 cache 的速度較慢,因為某一 CPU 在等待其他 CPU 回應 invalidate ack 前必須閒置。為了縮短 CPU 等待 invalidate ack 的閒置時間,store buffer 的設計被引入,其實作如下:
1. CPU 0 不等 CPU1 回傳的 invalidate ack,先將更新資料寫入 store buffer,然後繼續處理其他事情,等之後收到 invalidate ack 再更新 cache 的狀態。因為在寫回 cache 前,最新的資料可能存在 store buffer,所以 CPU 讀資料的順序變成 store buffer -> cache -> memory。
2. CPU 1 收到 Probe Write Hit 立即回 invalidate ack,收到 invalidate 時,記錄到 invalidate queue 裡,先回 invalidate ack,稍後再處理 invalidate。
第一個實作機制稱為 **store buffer forwarding**,在更新資料時,CPU 會先將更新後的資料置於 store buffer 中,由於訊號發送是非同步,cache 和 store buffer 內部資料可能不一致,最新版本的資料會存在 store buffer 中,於是在讀取時的先後順序為 store buffer -> cache -> memory。
第二個實作機制稱為 **invalidate queue**,由於 store buffer size 很小,快速的更新資料會導致 store buffer 很快就被填滿。此時,CPU 依然要等待其他 CPU 回應 invalidate ack 才能繼續更新資料。另外,其他 CPU 在收到 invalidate 請求時,他可能仍然在處理其他的事情,無法立即處理 invalidate 請求及回應 invalidate ack,這樣的情況導致想進行寫入的 CPU 進入閒置狀態並等待其他 CPU 回應 invalidate ack。為了解決這個問題,invalidate queue 被引入,CPU 收到 invalidate 請求時,會先記錄到 invalidate queue 裡,先回 invalidate ack,稍後再處理 invalidate。

> 取自 [從硬體觀點了解 memory barrier 的實作和效果](https://medium.com/fcamels-notes/%E5%BE%9E%E7%A1%AC%E9%AB%94%E8%A7%80%E9%BB%9E%E4%BA%86%E8%A7%A3-memry-barrier-%E7%9A%84%E5%AF%A6%E4%BD%9C%E5%92%8C%E6%95%88%E6%9E%9C-416ff0a64fc1)
## Memory Ordering Problem
**store buffer forwarding** 和 **invalidate queue** 機制雖然縮短了 CPU 閒置的時間,但在某些情況下會產生 memory ordering 的問題,以下會利用實際案例進行說明。
### Store Buffer Forwarding 所造成的問題
我們的測試程式碼如下,初始情況假定 a 和 b 都為 0,且 a 在 CPU 1 的 cacheline 中,而 b 在 CPU 0 的 cache line 中,CPU 0 執行 foo(),CPU 1 執行 bar()。
```c
void foo()
{
a = 1;
b = 1;
}
void bar()
{
while(b == 0)
continue;
assert(a == 1);
}
```
假設程式執行順序如下:
1. CPU 0 執行 a = 1,發現 a 不在 cache 中(cache miss),便發送 Probe Write 給其他 CPU,同時將 a 的值 1 寫入store buffer
2. CPU 1 執行 while loop,發現 b 不在 cache 中(cache miss),便發送 Probe Read 給其他 CPU
3. CPU 0 執行 b = 1,因為 b 已在 cache 中且狀態是 `Exclusive`,故可以直接將值 1 寫入 cacheline,cacheline 狀態變更為 `Modified`,並發送 Probe Write (要注意這邊還沒有處理其他 CPU 回應的 invalidate ack 和 CPU1 對變數 b 的 Probe Read 請求)
4. CPU 0 收到 Probe Read 請求,將 cacheline 中的 b 的值 1 給 CPU 1,並將對應的 cacheline 狀態更改為 `Shared`
5. CPU 1 收到變數 b 的資料,並將消息中的 cacheline 放入到自身的 cache
6. CPU 1 從 cache 中載入 b 值,發現為 1,結束 while loop
7. CPU 1 執行 assert,首先從 cache 中讀取 a 值,發現為0,assert fail
8. CPU 1 收到來自 CPU0 的 Probe Write 消息,將 a 所在的 cacheline 設為 `Invalid` 並回應 invalidate ack 給 CPU 0
9. CPU 0 收到 invalidate ack,將 a = 1 寫入到 cacheline 中
如果程式按照上述的執行順序,那 CPU 0 看到的執行順序是先做 a = 1 再做 b = 1,但 CPU 1 看到的則是先做 b = 1 再做 a = 1,因為 CPU 1 先處理自己發出去的 Probe Read 的回應(b = 1)才處理 CPU 0 發過來的 Probe Write 請求(a = 1),對 CPU 1 來說,CPU 0 發生 I/O reordering。
store buffer forwarding 這個機制的問題在於他只保證某一 CPU 自身看到的執行順序,例如 CPU 0 看到的執行順序是對的,但對於其他 CPU 看到的執行順序則不保證。
這個問題的解決方式就是引入 memory barrier,測試程式碼如下,在 memory barrier 之後執行的寫入操作,必須先把 store buffer 的內容處理完成。對於 memory barrier,CPU可以有兩種策略:
1. 在執行 b = 1 之前,乖乖地停下來專門處理 store buffer
2. 將 b = 1 也寫入 store buffer 中,但把 b 寫入 cacheline 之前,要先把前面在 store buffer 中的資料處理完
```c
void foo()
{
a = 1;
memory_barrier();
b = 1;
}
void bar()
{
while(b == 0)
continue;
assert(a == 1);
}
```
這邊的案例使用第二種策略,程式執行順序如下:
1. CPU 0 執行 a = 1,發現 a 不在 cache 中(cache miss),便發送 Probe Write 給其他 CPU,同時將 a 的值 1 寫入store buffer
2. CPU 1 執行 while loop,發現 b 不在 cache 中(cache miss),便發送 Probe Read 給其他 CPU
3. CPU 0 執行 `memory_barrier`,將目前在 store buffer 中的 entry 做標記
4. CPU 0 執行 b = 1,雖然 b 已在 cache 中且狀態是 `Exclusive`,但 store buffer 中有被標記的 entry,所以不能直接將值 1 寫入 cacheline,故先將 b = 1 寫入 store buffer 但不作任何標記
5. CPU 0 收到 Probe Read 請求,將 cacheline 中的 b 的值給 CPU 1,並將對應的 cacheline 狀態更改為 `Shared`,但注意這邊 b 的值是 0,因為新的版本來在 store buffer 中,還沒寫到 cache
6. CPU 1 收到變數 b 的資料,並將消息中的 cacheline 放入到自身的 cache
7. CPU 1 從 cache 中載入 b 值,發現為 0,繼續 while loop
8. CPU 1 收到來自 CPU0 的 Probe Write 消息,將 a 所在的 cacheline 設為 `Invalid` 並回應 invalidate ack 給 CPU 0
9. CPU 0 收到 invalidate ack,將 a = 1 寫入到 cacheline 中,狀態更新為 `Modified`
10. CPU 0 在 a = 1 寫入 cache 後,可以將 b 的資料寫入 cacheline 中,但此時 b 資料所在的 cacheline 狀態已成為 `Shared`(CPU 1 的 cache 中也有一份),所以在寫入前要發送 Probe Write
11. CPU 1 收到來自 CPU0 的 Probe Write 消息,將 b 所在的 cacheline 設為 `Invalid` 並回應 invalidate ack 給 CPU 0
12. CPU 1 執行 while loop,發現 b 不在 cache 中(cache miss),便發送 Probe Read 給其他 CPU
13. CPU 0 收到 invalidate ack,將 b = 1 寫入到 cacheline 中,並將狀態改為 `Modified`
15. CPU 0 收到 Probe Read 請求,將 cacheline 中的 b 的值 1 給 CPU 1,並將對應的 cacheline 狀態更改為 `Shared`
16. CPU 1 收到變數 b 的資料,並將消息中的 cacheline 放入到自身的 cache
17. CPU 1 從 cache 中載入 b 值,發現為 1,結束 while loop
18. CPU 1 執行 assert,因為剛剛 a 所在的 cacheline 狀便被改為 `Invalid` 了,所以 CPU 1 會發送 Probe Read
19. CPU 0 收到 Probe Read 請求,將 cacheline 中的 a 的值 1 給 CPU 1,並將對應的 cacheline 狀態更改為 `Shared`
20. CPU 1 收到變數 a 的資料,並將消息中的 cacheline 放入到自身的 cache
21. CPU 1 從 cache 中載入 a 值,發現為 1,assert successfully
### Invalidate Queue 所造成的問題
若 CPU 需要對其他 CPU 發送 Probe Write 前,必須要先檢查 invalidate queue 中有無該 cacheline 的 invalidate 請求,若有,則需要先行處理。若不先處理invalidate queue 中對應的 Invalidate 消息直接對其他 CPU 發送 Probe Write,那麼,這次的寫入操作就會直接被送到 store buffer 中,後續 CPU 再進行處理時,store buffer 有寫該 cacheline 的請求,而 invalidate queue 有讓該 cacheline 狀態改為 `Invlaid` 的請求,那到底該以哪個為準 ? 若都以 store buffer 為準,假如 invalidate queue 中的請求是後於 store buffer 產生的,表示其他 CPU 後續又對該cacheline 進行了寫入,但此時 store buffer 中的舊值會被寫到 cacheline 且標示 `Modified`,這顯然是錯的。反之,以 invalidate queue 為準,那 store buffer 的請求後於 invalidate queue,那一樣也會產生錯誤。
舉個例子,測試程式碼如下,初始情況假定 a 和 b 都為 0,且 a 同時在 CPU 0 和 CPU 1 的cacheline 中,b 只在 CPU 0 的 cacheline 中。由此,a 對應的 cacheline 狀態為`Shared`,b 對應的 cacheline 狀態為 `Exclusive`,CPU 0 執行 foo(),CPU 1 執行 bar()。
```c
void foo()
{
a = 1;
memory_barrier();
b = 1;
}
void bar()
{
while(b == 0)
continue;
assert(a == 1);
}
```
假設程式執行順序如下:
1. CPU 0 執行 a = 1,發現 a 在 cache 中但 cacheline 狀態為 `Shared`,便發送 Probe Write 給其他 CPU,同時將 a 的值 1 寫入store buffer
2. CPU 1 執行 while loop,發現 b 不在 cache 中(cache miss),便發送 Probe Read 給其他 CPU
3. CPU 1 收到來自 CPU0 的 Probe Write 消息,將這個請求加到 invalidate queue中並立即回應 invalidate ack 給 CPU 0
4. CPU 0 執行 `memory_barrier`,將目前在 store buffer 中的 entry 做標記
5. CPU 0 收到 invalidate ack,將 store buffer 中的 a = 1 寫入到 cacheline 中,並將狀態改為 `Modified`
6. CPU 0 執行 b = 1,因為 store buffer 為空,沒有任何被標記的 entry,b 也已在 cache 中且狀態是 `Exclusive`,故可以直接將值 1 寫入 cacheline,將cacheline 狀態變更為 `Modified`
7. CPU 1 收到變數 b 的資料,並將消息中的 cacheline 放入到自身的 cache
8. CPU 1 從 cache 中載入 b 值,發現為 1,結束 while loop
9. CPU 1 執行 assert,從 cache 中讀取 a 值,發現為 0,assert fail
10. CPU 1 處理 invalidate queue 中的 Probe Write,將 a 所在的 cacheline 設為 `Invalid`
11. CPU 1 執行 assert,因為剛剛 a 所在的 cacheline 狀便被改為 `Invalid` 了,等同於 a 不在 cache 中,所以 CPU 1 會發送 Probe Read
從上述執行結果來看,引入了 invalidate queue 確實加速了 CPU 0 的執行,但即使加上了 `memory barrier`,對 CPU 1 來說,CPU 0 仍然發生了 I/O reordering。原因在於兩者對於 invalidate cacheline 的理解不一致,CPU 0 認為既然發出了 invalidate acknowledge,你的 cache 中就不會有 a 對應的 cacheline 了,因為那條 cacheline 被設為了 `Invlaid`,而 CPU 1 則認為將 invalidate 消息放入 invalidate queue,算是已經讓 a 的 cacheline 失效了。
為了讓這兩個 CPU 達成共識,我們仍然是透過 memory barrier,memory barrier 會要求該 CPU 必須先處理完在 invalidate queue 中所有的請求,修改後程式碼如下:
```c
void foo()
{
a = 1;
memory_barrier();
b = 1;
}
void bar()
{
while(b == 0)
continue;
memory_barrier();
assert(a == 1);
}
```
加入 memory barrier 後程式執行順序如下:
1. CPU 0 執行 a = 1,發現 a 在 cache 中但 cacheline 狀態為 `Shared`,便發送 Probe Write 給其他 CPU,同時將 a 的值 1 寫入store buffer
2. CPU 1 執行 while loop,發現 b 不在 cache 中(cache miss),便發送 Probe Read 給其他 CPU
3. CPU 1 收到來自 CPU0 的 Probe Write 消息,將這個請求加到 invalidate queue中並立即回應 invalidate ack 給 CPU 0
4. CPU 0 執行 `memory_barrier`,將目前在 store buffer 中的 entry 做標記
5. CPU 0 收到 invalidate ack,將 store buffer 中的 a = 1 寫入到 cacheline 中,並將狀態改為 `Modified`
6. CPU 0 執行 b = 1,因為 store buffer 為空,沒有任何被標記的 entry,b 也已在 cache 中且狀態是 `Exclusive`,故可以直接將值 1 寫入 cacheline,將 cacheline 狀態變更為 `Modified`
7. CPU 1 收到變數 b 的資料,並將消息中的 cacheline 放入到自身的 cache
8. CPU 1 從 cache 中載入 b 值,發現為 1,結束 while loop
9. CPU 1 執行 `memory_barrier`,`memory_barrier` 要求 CPU 1 必須先處理完 invalidate queue 中的請求,於是 Probe Write 的請求是關於 a 的,故將 a 對應的 cacheline 設為 `Invalid`
10. CPU 1 執行 assert,從 cache 中讀取 a 值發現是 `Invalid`,於是發出 Probe Read
11. CPU 0 處理來自 CPU 1 的 Probe Read,將 a 所在的 cacheline 設為 `Shared`,將 a 的資料送給 CPU 1
13. CPU 1 收到變數 a 的資料,並將消息中的 cacheline 放入到自身的 cache
14. CPU 1 從 cache 中載入 a 值,發現為 1,assert successfully
從上述執行結果來看,`memory_barrier` 再次保證了並行多處理器程式的執行達到預期結果。當然,使用 `memory_barrier` 後執行成本增加了,因為必須先處理 store buffer 或是 invalidate queue,而且以上問題也是在特定的執行順序下才會發生。不過,當執行次數夠多時,上述情形必然會發生,而且資料的正確才是我們最在乎的。
我們為了約束與 store buffer 和 invalidate queue,用到了`memory_barrier`。也就是說,CPU 執行指令中如果遇到了 `memory_barrier`,則需要處理 store buffer 和 invalidate queue。但其實從程式碼來看,`foo( )` 中的 `memory_barrier` 其實只需要處理 store buffer 的部分,而 `bar( )` 中的則只需要處理 invalidate queue 。有些 CPU 提供了更為細分的 `memory_barrier`,細分為 `read memory barrier` 和 `write memory barrier`,前者只會處理 invalidate queue,而後者只會處理 store buffer。顯然,只處理其中之一肯定比同時處理二者效率要高,不過約束就會更少,可能的行為也就越多。
## 實驗
參考 [I/O ordering 學習紀錄](https://hackmd.io/@butastur/rkkQEGjUN#Store-Buffer) 中的實驗,我們利用 [litmus7](http://diy.inria.fr/doc/litmus.html) 在硬體架構為 `arm64` 得機器上進進行實驗,實驗程式碼如下:
```
ARM arm000
"PodWW Rfe PodRR Fre"
Cycle=Rfe PodRR Fre PodWW
Relax=
Safe=Rfe Fre PodWW PodRR
Generator=diy7 (version 7.56.2)
Prefetch=0:x=F,0:y=W,1:y=F,1:x=T
Com=Rf Fr
Orig=PodWW Rfe PodRR Fre
{
%x0=x; %y0=y;
%y1=y; %x1=x;
}
P0 | P1 ;
MOV R0,#1 | MOV R1,#1 ;
STR R0,[%x0] | STR R1,[%y1] ;
LDR R0,[%y0] | LDR R1,[%x1] ;
exists (0:R0=0 /\ 1:R1=0)
```
該實驗程式碼是 [litmus7](http://diy.inria.fr/doc/litmus.html) 的語法,首先宣告兩個共享變數 x, y,且初始化為 0,接著,CPU 0 所做的事情是寫入 a = 1 和讀取 b,而 CPU 1 所做的事情是寫入 b = 1 和讀取 a,兩個 CPU 都是做一個 store 指令接著一個 load 指令,而這個實驗想驗證的是有沒有可能出現最後 CPU 0 讀到的 b 是 0,而 CPU 1 讀到的 a 也是 0 的情況。
### 實驗結果
利用 [litmus7](http://diy.inria.fr/doc/litmus.html) 執行上面提供的測試程式,並重複執行 1000000 次,結果如下:
```
Test arm000 Allowed
Histogram (3 states)
15 *>0:R0=0; 1:R1=0;
499994:>0:R0=1; 1:R1=0;
499991:>0:R0=0; 1:R1=1;
Ok
Witnesses
Positive: 15, Negative: 999985
Condition exists (0:R0=0 /\ 1:R1=0) is validated
...
Time arm000 0.38
...
```
根據上訴實驗結果,我們可以發現出現了 15 次 CPU 0 讀到的 b 是 0,而 CPU 1 讀到的 a 也是 0 的情況,代表其中一個或兩個 CPU 發生了 memory reordering 的情況,否則正常執行下至少會有一個 CPU 讀到的值為 1。
### 加入 memory barrier
為了測試 memory barrier 是否有效,我們在 store 指令與 load 指令之間加上 arm64 架構提供的 memory barrier 指令 `DMB`。
擷取 [ARM Compiler toolchain Assembler Reference Version 4.1](https://developer.arm.com/documentation/dui0489/c/arm-and-thumb-instructions/miscellaneous-instructions/dmb--dsb--and-isb):
> Data Memory Barrier acts as a memory barrier. It ensures that all explicit memory accesses that appear in program order before the DMB instruction are observed before any explicit memory accesses that appear in program order after the DMB instruction. It does not affect the ordering of any other instructions executing on the processor.
也就是說 DMB 保證在 DMB 之後 access memory 相關的指令都看得到 DMB 之前 access memory 相關的指令的結果。
加入 DMB 的實驗程式碼如下:
```
ARM arm000
"PodWW Rfe PodRR Fre"
Cycle=Rfe PodRR Fre PodWW
Relax=
Safe=Rfe Fre PodWW PodRR
Generator=diy7 (version 7.56.2)
Prefetch=0:x=F,0:y=W,1:y=F,1:x=T
Com=Rf Fr
Orig=PodWW Rfe PodRR Fre
{
%x0=x; %y0=y;
%y1=y; %x1=x;
}
P0 | P1 ;
MOV R0,#1 | MOV R1,#1 ;
STR R0,[%x0] | STR R1,[%y1] ;
DMB | DMB ;
LDR R0,[%y0] | LDR R1,[%x1] ;
exists (0:R0=0 /\ 1:R1=0)
```
### 實驗結果
利用 [litmus7](http://diy.inria.fr/doc/litmus.html) 執行上面提供的測試程式,並重複執行 1000000 次,結果如下:
```
Test arm000 Allowed
Histogram (3 states)
499998:>0:R0=1; 1:R1=0;
500000:>0:R0=0; 1:R1=1;
2 :>0:R0=1; 1:R1=1;
No
Witnesses
Positive: 0, Negative: 1000000
Condition exists (0:R0=0 /\ 1:R1=0) is NOT validated
...
Time arm000 0.46
...
```
透過實驗結果可以發現加入 memory barrier 之後,不再出現 CPU 0 讀到的 b 是 0,而 CPU 1 讀到的 a 也是 0 的情況。另外,也可以觀察到加入 memory barrier 之後的執行時間比之前還慢。由實驗證實,雖然加入 memory barrier 確實會影響效能,但為了保證資料的正確性,這是必要的犧牲。
## Memory (Re)Ordering
Memory ordering 發生的情況有兩種,一種是上面提到 cache 中的 store buffer forwarding 以及 invalidate queue 所造成的 reordering,稱為 `Processor reordering` 或 `CPU reordering`,另一種是 compiler 在做最佳化時將 load 指令和 store 指令重排所造成的 memory reordering,稱為 `Complier reordering`。這兩種 reordering 是可能同時發生的,如下圖所示,前者是在執行時期所發生的,而後者則是在編譯時期所發生。
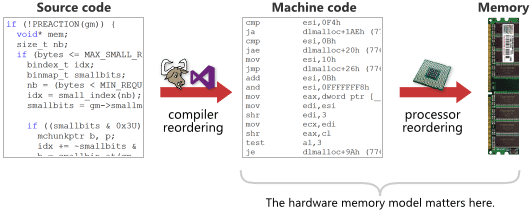
> 取自 [Weak vs. Strong Memory Models](https://preshing.com/20120930/weak-vs-strong-memory-models/)
## Complier Reordering
為了優化程式碼以提高效能,編譯器(compiler)可能在不改變程式行為的情況下重排指令。因為編譯器不知道什麼樣的程式碼需要 thread-safe,所以在優化時都會假設程式碼是單一執行序的,優化時只會保證單一執行緒的程式行為不改變並進行指令重排。但可想而知,程式明明是多執行緒卻被認為是單一執行緒而進行指令重排,必然會產生問題。而解決方法就是明確的告訴編譯器,在程式碼可能因指令重排而錯誤的部分不要進行重排。
舉個例子,考慮到以下程式碼:
```c
int x, y;
void foo()
{
x = y + 1;
y = 0;
}
```
我們透過 gcc 來編譯並比較有無最佳化的組合語言
### Without Optimization
```
$ gcc -S foo.c
$ cat foo.s
...
foo:
.LFB0:
.cfi_startproc
adrp x0, :got:y
ldr x0, [x0, #:got_lo12:y] // load y to x0
ldr w0, [x0] // load y to w0
add w1, w0, 1 // add w0 with 1 to w1
adrp x0, :got:x
ldr x0, [x0, #:got_lo12:x] // load x to x0
str w1, [x0] // store w1 to x
adrp x0, :got:y
ldr x0, [x0, #:got_lo12:y] // load y to x0
str wzr, [x0] // store 0 to y
nop
ret
...
```
### With O2 Optimization
```
$ gcc -S -O2 foo.c -o foo1.s
$ cat foo1.s
...
foo:
.LFB0:
.cfi_startproc
adrp x0, :got:y
adrp x1, :got:x
ldr x0, [x0, #:got_lo12:y] // load y to x0
ldr x1, [x1, #:got_lo12:x] // load x to x1
ldr w2, [x0] // load y to w2
str wzr, [x0] // store 0 to x
add w0, w2, 1 // add w2 with 1 to w0
str w0, [x1] // store w0 to x
ret
...
```
觀察兩份組合語言可以發現,在沒有最佳化下,程式會先做完 `x = y + 1` 的 store 指令接著再完成 `y = 0` 的 store 指令,但在利用 `O2` 最佳化的情況下,程式先做 `y = 0` 的 store 指令,再做`x = y + 1` 的 store 指令,因為程式把 y 的值先存在暫存器 `w2` 中,後續的計算直接從暫存器 `w2` 取值,這樣的指令重排並不會影響單一執行緒的資料正確性。
然而,在並行多執行緒程式中將可能導致資料的不正確,試想,如果程式中的 y 作用如果是 lock,在設成 0 之後其他執行緒才能進入 critical section 中更改 x 的資料,但在指令重排之後,某一執行緒把 y 先被設成 0,才改動 x 的資料,而另一執行緒看到 y 變成了 0,也馬上進到 critical section 中去改 x 的資料,同時讓兩個執行緒進入 critical section 修改同一份資料顯然違反了程式的正確性。
上面有提到,解決方法就是透過 compiler barrier,compiler barrier 的作用就是明確的告訴編譯器,不管進行何種最佳化手段,在 compiler barrier 出現後的讀寫操作都要確實地去記憶體位置上讀寫,不能用 barrier 之前的臨時結果(比如用 O2 最佳化後的測試程式用存在暫存器 `w2` 中的結果)。
## 四種 Memory Reodering
上述提到的都是 memory ordering 是由什麼造成的,而這邊要講的是當 reordering 發生時,**同一個** CPU 上的 load 指令和 store 指令是怎麼樣被重排的,可以分為以下四種,分別說明這四種 reordering 可能發生之問題:
1. LoadLoad Reodering
考慮到以下程式,Thread1 先會 sotre 更新後的 `b` 值 10,再 sotre 更新後的 `ready` 值 1,那 Thread2 先 load `ready`,接著檢查 `ready` 是否為 1,如果為 1 再 load `b`,就可以取得最新版本的 `b` 值。但如果 load `ready` 和 load `b` 對調,這樣就可能在 b 還沒更新時就讀取,因而讀到舊版本的 `b`。
```c
int ready, b
// Thread 1
b = 10
ready = 1
// Thread 2
while (!ready)
{
return b
}
```
2. StoreStore Reodering
考慮到以下程式碼,Thread1 會先 sotre 更新後的 `b` 值 10,再 sotre 更新後的 `ready` 值 1,那 Thread2 先 load `ready`,接著檢查 `ready` 是否為 1,如果為 1 再 load `b`,就可以取得最新版本的 `b` 值。但如果 sotre 更新後的 `b` 值 10 和 sotre 更新後的 `ready` 值 1 對調,這樣 Thread2 可能讀到 `ready` 是 1,接著 load `b`,但更新後的 `b` 值此時可能還沒 store,所以讀到的是舊版本的 `b`。
```c
int ready, b
// Thread 1
b = 10
ready = 1
// Thread 2
if (!ready)
{
return b
}
```
3. StoreLoad Reodering
考慮到以下程式碼,P1 會先 sotre 更新後的 `Flag1` 值為 1,接著 load `Flag2`,而 P2 會先 sotre 更新後的 `Flag2` 值為 1,接著 load `Flag1`。我們預期的程式行為是某一時刻只會有 P1 或是 P2 其中一個進入 critical section,然而,當兩個執行緒同時發生,或其中有一個發生 store 指令和 load 指令對調,那將可能導致 P1 和 P2 看到的 `Flag2` 和 `Flag1` 都為 0,一起進入 critical section。

4. LoadStore Reodering
考慮到以下程式碼,正常情況下,我們會預期 Thread1 或 Thread2 會有其中一個 assert 沒過,或兩個都過。然而,因為對於 Thread1 或 Thread2 單一執行緒來看,CPU 會認為 a 和 b 沒有任何 data dependency,那就很有可能對 load `a` 和 store `b`,或者是 load `b` 和 store `a` 進行亂序 (out-of-order) 執行。
```c
int a = 0, b = 0;
// Thread 1
assert(b == 0);
a = 1;
// Thread 2
assert(a == 0);
b = 1;
```
### 循序(In-order) 執行與亂序 (out-of-order) 執行
引用[並行程式設計: Atomics 操作](https://hackmd.io/OVPTyhEPTwSHumO28EpJnQ?view#Memory-Ordering-%E5%92%8C-Barrier)文中內容,在亂序 (out-of-order) 執行時,一個處理器真正執行指令的順序,是由可用的輸入資料決定,而非程式開發者在程式碼規範的順序。現代處理器可分 in-order 和 out-of-order 等二種實作。
- [ ] In-order processors (循序) 執行步驟
1. instruction fetch (IF)
2. 若指令的 input operands 可用 (例如已在暫存器中),則將此指令分派 (dispatch) 到適當的功能單元中。若一個或多個 input operands 不可用 (通常因為指令之間出現 data dependency,要等指令 access memory),則處理器會等待直到它們可用 (ID)
3. 指令被適當的功能單元執行 (IE)
4. 功能單元將結果寫回到 register file (CPU 的一組暫存器)
- [ ] Out-of-order processors (亂序) 執行步驟
1. instruction fetch (IF)
2. 指令被分派 (dispatch) 到 instruction queue (ID)
3. 指令在 instruction queue 中等待,直到 input operands 可用 (一旦 input operands 可用,指令即可離開 instruction queue,即便更早的指令尚未執行)
4. 指令被分派到適當的功能單元並執行 (IE)
5. 執行結果被放入 queue 中,而非立即寫入 register file
6. 只有所有更早請求執行的指令的執行結果被寫入 register file 後,指令執行的結果才被寫入 register file (即執行結果重排,讓執行看起來是有序的)
由上可見,亂序執行相比循序執行能夠避免等待不可用的 input operands (即上述 in-order 執行的第二步),從而提高執行速度。現代電腦系統中,處理器執行的速度遠高於主記憶體,in-order 處理器花在等待可用資料的時間中,out-of-order 處理器已可處理大量指令。
總結 out-or-order 處理器的流程:
* 對單個 CPU 來說,instruction fetch (IF) 是循序的 (藉由 queue 實作)
* 對單個 CPU 來說,指令執行結果也是依序寫回 register file (也藉由 queue 實作)
## Hardware Memory Model
由於底層處理器硬體的實作以及使用的 toolchain 不同,發生的 memory ordering 種類也不同,hardware memory model 主要功能就是告訴使用者,在該處理器架構或是該 toolchain 上執行程式時,會發生哪些類型的 memory ordering,而這邊強調的是 CPU reodering,而不是 compiler reodering。

> 取自 [Weak vs. Strong Memory Models](https://preshing.com/20120930/weak-vs-strong-memory-models/)
參考 [Weak vs. Strong Memory Models](https://preshing.com/20120930/weak-vs-strong-memory-models/),文中作者將 memory model 分為四種:
1. Really weak: 四種 reordering 都可能發生,也就是說在不改變單執行緒程式行為的情況下,可任意對 load 指令和 store 指令進行重排。
2. Weak with data dependency ordering: 可能存在 `Storeload` 和 `StoreStore`,只要沒有資料相依關係,對指令的執行順序沒有要求。
3. Usually strong: 只存在 `StoreLoad` reordering
4. Sequentially consistent: 所有 load 指令和 store 指令都不能重排,前面執行的指令所更新的結果,後面的執行的指令都會看到。
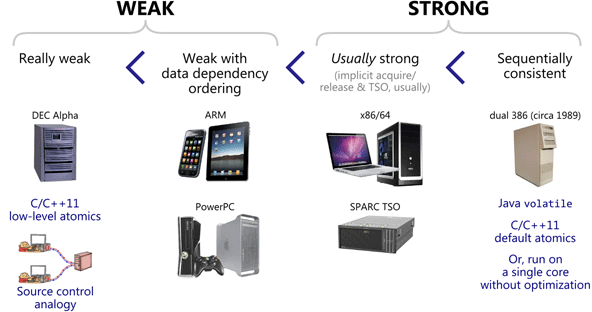
> 取自 [Weak vs. Strong Memory Models](https://preshing.com/20120930/weak-vs-strong-memory-models/)
## TSO(Total Store Order)
TSO 是一種 Usually strong 的 memory model,只允許 `StoreLoad` reordering 發生,主要應用於 x86 和 x64 硬體架構下。
為何唯獨 `store` 指令後接 `load` 指令這種情況,被 x86 允許重排呢?因為寫入一則資料的動作若尚未完成,一般沒多大影響,反之,如果讀取一則資料的操作沒完成,就可能對後面依賴這個資料的指令造成影響,因此 CPU 會優先保證讀取操作的完成。
## Reference
* [從硬體觀點了解 memory barrier 的實作和效果](https://medium.com/fcamels-notes/%E5%BE%9E%E7%A1%AC%E9%AB%94%E8%A7%80%E9%BB%9E%E4%BA%86%E8%A7%A3-memry-barrier-%E7%9A%84%E5%AF%A6%E4%BD%9C%E5%92%8C%E6%95%88%E6%9E%9C-416ff0a64fc1)
* [OpenMP, Cache Coherence](https://inst.eecs.berkeley.edu/~cs61c/su20/pdfs/lectures/lec23.pdf)
* [並行程式設計: Atomics 操作](https://hackmd.io/@sysprog/concurrency-atomics)
* [並行程式設計: 執行順序](https://hackmd.io/@sysprog/concurrency-ordering#Memory-Consistency-Models)
* [I/O ordering 學習紀錄](https://hackmd.io/@butastur/rkkQEGjUN#Store-Buffer)
* [為什麼需要 memory barrier](https://zhuanlan.zhihu.com/p/55767485)
* [Weak vs. Strong Memory Models](https://preshing.com/20120930/weak-vs-strong-memory-models/)
 Sign in with Wallet
Connect another wallet
Sign in with Wallet
Connect another wallet