---
title: "Challenges in Data Cleaning and Transformation: Mistakes, Confusion, and Solutions - Iris Chen"
tags: PyConTW2023, 2023-organize, 2023-共筆
---
# Challenges in Data Cleaning and Transformation: Mistakes, Confusion, and Solutions - Iris Chen
{%hackmd H6-2BguNT8iE7ZUrnoG1Tg %}
<iframe src=https://app.sli.do/event/ou5c1wACz8nAGN8bJC5jnY height=450 width=100%></iframe>
> Collaborative writing start from below
> 從這裡開始共筆
---
[toc]
---
[slides](https://docs.google.com/presentation/d/e/2PACX-1vSXyJm9M-BUzaZfAlfH6ZBwpr15Gw5OtlVTJFqBsW9-t0XN6Ns2A5xmS4a1d0c_IS5tOn2-uRTWkMBe/pub?start=false&loop=false&delayms=3000)
## Introduction
> 任務:優化影片推薦系統
> 背景:公司在幫OTT平台做推薦
優化有2個方向
+ Method1:更強的模型 -> 逼近模型預測的上限
+ Method2:改善資料品質 -> 提升模型預測的上限
發現目前資料的品質比較有問題,所以從Method2著手,改善資料品質
需要清理的地方
### Data Cleaning Method
1. text pruning:去除贅字之類的
2. Name normalization: 包括多國語系的電影,會使用不同語言,名稱需要做normalization
3. Data enrichment:引入外部資料來改善缺失值問題
## Data Cleaning Process
+ 在每一個不同的清理步驟,都會有不同版本的處理方式
+ 路徑會有很多種
### Text Pruning
舉例:玩具總動員
Name, Reason for Messiness
+ `玩具 總動員` -> extra spaces
+ `玩☆具☆總☆動☆員` -> weird punctuation
- `(熱門首播)玩具總動員`-> redundant words
**光是在text pruning的部分就做了很多實驗,所以有很多版本的codes&data**
### Name Normalization
- 同個名字在不同語言不同國家之下的不同表示方式
- e.g. 石原里美, 石原聰美
- 可能會包含暱稱
- e.g. 李奧納多(Leo)
### Data Enrichment
許多資訊為空缺
- 使用外部資料
- 可以讓資訊更完整
- 可能會產生新的欄位
- 問題:要使用哪裡的資料?
- IMDB or Filmarks?
- 問題:取代 or 加入?
- 格式差異
- 部分欄位加入 -> 選擇哪些欄位?
### Summary
- Source Selection
- Method Combination
- Detailed Step Experiments
## Challenges
### Challenge 1. Effective Data Quality Monitoring Strategies
使用[MLflow](https://mlflow.org/)來記錄各個實驗結果
需要監測的數值:
* Row count
* Duplicate Rate
* Distinct Rate
Data Quality 相關工具:
- [Data-DIFF](https://github.com/datafold/data-diff)
- [Pandas Profiling](https://github.com/ydataai/ydata-profiling)
- (講者主推)[PipeRider](https://www.piperider.io/):確保開發過程中Data的正確性
### Challenge 2. Data pipeline Management
一開始把所有步驟都寫在同一個file
- 問題:
- 檔案肥大、難以管理
- 在測試的時候難以確定是哪個因子影響推薦結果的影響
工具:
- [Airflow](https://airflow.apache.org/)
- [Dagster](https://dagster.io/)
- [Prefect](https://prefect.io/)
- (講者主推)DBT
- 建立簡單 Unit Test 檢查欄位是否正常
- Lineage Graph (類似 Airflow 的 DAGs)
Using DBT to standardized the ETL proccess
- 每一個方法(text pruning, name normalization, etc)都是獨立的
Lineage Graph (DBT上的其中一個講者推薦的feature)
- 根據Model執行順序產生示意圖
- 示意圖: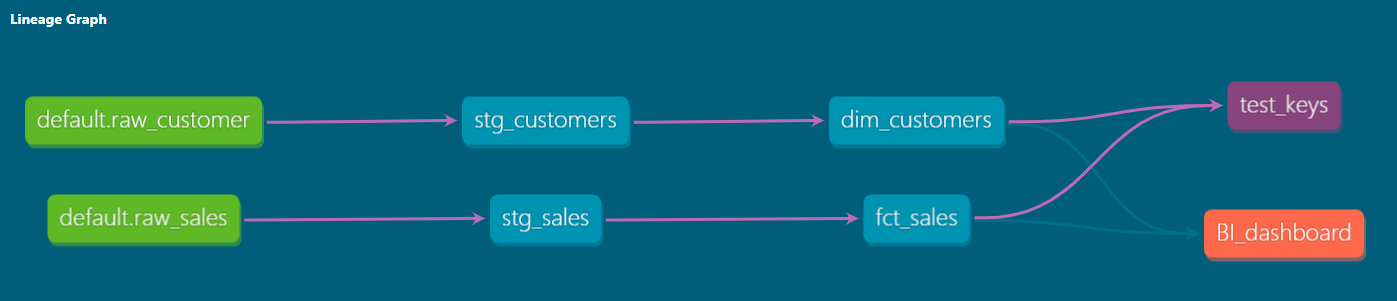
DBT + PipeRider Compare
- 展現Before and After
- e.g. row 的數量變化
- example: 增加去除贅字的function後, 對資料的影響
The collaboration with InfuseAI
- InfuseAI is the owner of PipeRider
|Order | Table | Rows | Column |
|--| -------- | -------- | -------- |
|2| text_pruning | 4761 | 6(+0) |
|1| name normalization | 4761 | 6(+0) |
|3|data_enrichment|1000|6(+0)|
## Conclusion
1. Effective Data Quality Monitoring Strategies -> **PipeRider**
2. Data Popeline Management -> **DBT**
https://github.com/KKStream/dbt_imdb
Below is the part that speaker updated the talk/tutorial after speech
講者於演講後有更新或勘誤投影片的部份