# Machine Learning NOTE
## MISC
### activation function

### over/under-fitting
- 解決high variance/over-fitting:增大樣本集。Variance的引入可以理解成樣本集不夠全面,訓練樣本的分佈與實際數據的分佈不一致造成的。擴大樣本集,甚至使用全量的數據,可以盡量使得訓練集與應用模型的數據集的分佈一致,減少variance的影響。
- 解決high bias/under-fitting:提升模型的複雜性。通過引入更多的特徵、更複雜的結構,模型可以更全面的描述概率分佈/分界面/規則邏輯,從而有更好的效果。
**The plot below gives us a clear picture** — as the predicted probability of the true class gets closer to zero, the loss increases exponentially:

### compute vs store
分佈式機器學習中的分佈式不僅包含**計算**,還涉及**存儲**。首先,計算的分佈式就是要把問題切開,分佈地去解決。對於機器學習的問題,切問題包括對訓練數據和訓練模型的切分。切分數據意味著減少計算量,而切分模型的方式決定了計算和通信的拓撲。理想情況下,機器學習問題的模型可以不做切分,但這並不滿足分佈式計算可擴展的要求。一方面隨著數據量的增大,模型規模可能增大到超出單機內存,另一方面模型本身也變地越加複雜。那麼如何對數據和模型進行合理的剖分呢?一個原則是盡量同時,即在切分數據的同時盡量保證切開的模型大小均衡以及通信較優。
- [Gradient Descent](https://ithelp.ithome.com.tw/articles/10198147)
## Distributed Training
### Ps-worker distrubuted computing
1. Efficient communication:
由於是異步的通信,因此,不需要停下來等一些機器執行完一個iteration(除非有必要),這大大減少了延時。為機器學習任務做了一些優化(後續會細講),能夠大大減少網絡流量和開銷
2. Flexible consistency models:
寬鬆的一致性要求進一步減少了同步的成本和延時。parameter server允許算法設計者根據自身的情況來做算法收斂速度和系統性能之間的trade-off。
3. Elastic Scalability:
使用了一個分佈式hash表使得新的server節點可以隨時動態的插入到集合中;因此,新增一個節點不需要重新運行系統。
4. Fault Tolerance and Durability:
我們都知道,節點故障是不可避免的,特別是在大規模商用服務器集群中。從非災難性機器故障中恢復,只需要1秒,而且不需要中斷計算。Vector clocks保證了經歷故障之後還是能運行良好;
5. Ease of Use
全局共享的參數可以被表示成各種形式:vector,matrices或者相應的sparse類型,這大大方便了機器學習算法的開發。並且提供的線性代數的數據類型都具有高性能的多線程庫。
### **Messages**
一條message 包括:時間戳,len(range)對kv.
$[ v c ( R ) , ( k1, v1) , . . . , ( kp, vp) ] kj∈ Ra n dj ∈ { 1 , . . . p }$
$[vc(R),(k1,v1),...,(kp,vp)]kj∈Randj∈{1,...p}$
這是parameter server 中最基本的通信格式,不僅僅是共享的參數才有,task 的message也是這樣的格式,只要把這裡的(key, value) 改成(task ID, 參數/返回值)。
由於機器學習問題通常都需要很高的網絡帶寬,因此信息的壓縮是必須的。
**key的壓縮**:因為訓練數據通常在分配之後都不會發生改變,因此worker沒有必要每次都發送相同的key,只需要接收方在第一次接收的時候緩存起來就行了。第二次,worker不再需要同時發送key和value,只需要發送value和key list的hash就行。這樣瞬間減少了一般的通信量。
**value的壓縮**:假設參數時稀疏的,那麼就會有大量的0存在。因此,為了進一步壓縮,我們只需要發送非0值。parameter server使用Snappy快速壓縮庫來壓縮數據、高效去除0值。
**Sequential**:這裡其實是synchronous task,任務之間是有順序的,只有上一個任務完成,才能開始下一個任務;
**Eventual**:跟sequential相反,所有任務之間沒有順序,各自獨立完成自己的任務,
**Bounded Delay**:這是sequential跟eventual之間的trade-off,可以設置一個ττ作為最大的延時時間。也就是說,只有>τ>τ之前的任務都被完成了,才能開始一個新的任務;極端的情況:
=0,情況就是Sequential;
=∞,情況就是Eventual;
對於機器學習優化問題比如梯度下降來說,並不是每次計算的梯度對於最終優化都是有價值的,用戶可以通過自定義的規則過濾一些不必要的傳送,再進一步壓縮帶寬cost:
1. 發送很小的梯度值是低效的:
因此可以自定義設置,只在梯度值較大的時候發送;
2. 更新接近最優情況的值是低效的:
因此,只在非最優的情況下發送,可通過KKT來判斷;

### **Worker group**
還有一個特點就是,上述架構圖中,worker也劃分了group,這樣做的作用是使得PS可以支持多任務的並行運算,比如,可以有一個group是線上服務的,有一個是線下訓練的,這樣,線上服務就可以無縫直接利用線下訓練的結果了。當然,還有一個邏輯上的命名空間的概念,不同的work group可以在同一個命名空間下,這樣,多個work group就可以為同一個任務服務了。
* Distributed Subgradient Descent

* ps-worker workflow

* Delayed Block Gradient

### Distributed strategy
1. **In-graph replication**:只構建一個client,這個client構建一個Graph,Graph中包含一套模型參數,放置在ps上,同時Graph中包含模型計算部分的多個副本,每個副本都放置在一個worker上,這樣多個worker可以同時訓練複製的模型。TensorFlow教程中的使用多個GPUs訓練[cifar10分類模型](https://link.zhihu.com/?target=https%3A//www.tensorflow.org/tutorials/deep_cnn%23training_a_model_using_multiple_gpu_cards)就屬於這個類型,每個GPUs上的計算子圖是相同的,但是屬於同一個Graph。這種方法很少使用,因為一旦client掛了,整個系統就全崩潰了,容錯能力差。
2. **Between-graph replication**:每個worker都創建一個client,這個client一般還與task的主程序在同一進程中。各個client構建相同的Graph,但是參數還是放置在ps上。這種方式就比較好,一個worker的client掛掉了,系統還可以繼續跑。
3. **Asynchronous training**:異步方式訓練,各個worker自己幹自己的,不需要與其它worker來協調,前面也已經詳細介紹了異步訓練,上面兩種方式都可以採用異步訓練。
4. **Synchronous training**:同步訓練,各個worker要統一步伐,計算出的梯度要先聚合才可以執行一次模型更新,對於In-graph replication方法,由於各個worker的計算子圖屬於同一個Graph,很容易實現同步訓練。但是對於Between-graph replication方式,各個worker都有自己的client,這就需要係統上的設計了,TensorFlow提供了[tf.train.SyncReplicasOptimizer](https://link.zhihu.com/?target=https%3A//www.tensorflow.org/api_docs/python/tf/train/SyncReplicasOptimizer)來實現Between-graph replication的同步訓練。
- [Distributed tensorflow: the difference between In-graph replication and Between-graph replication](https://stackoverflow.com/questions/41600321/distributed-tensorflow-the-difference-between-in-graph-replication-and-between)
- [分布式tensorflow](https://blog.csdn.net/xymyeah/article/details/85268195)
- [TensorFlow in-graph replication example](https://gist.github.com/manuzhang/48fa9fe6de8bb9470f0b7092186a74b8)
- [Distributed Tensorflow medium](https://medium.com/@ntenenz/distributed-tensorflow-2bf94f0205c3)



### Between-graph replication
由於在TensorFlow中最常用的是Between-graph replication方式,這裡著重講一下如何實現這種方式。在Between-graph replication中,各個worker都包含一個client,它們構建相同的計算圖,然後把參數放在ps上,TensorFlow提供了一個專門的函數[tf.train.replica_device_setter](https://link.zhihu.com/?target=https%3A//www.tensorflow.org/api_docs/python/tf/train/replica_device_setter)來方便Graph構建,先看代碼:
```python=
# cluster包含兩個 ps 和三個 worker
cluster_spec = {
"ps": ["ps0:2222", "ps1:2222"],
"worker": ["worker0:2222", "worker1:2222", "worker2:2222"]}
cluster = tf.train.ClusterSpec(cluster_spec)
with tf.device(tf.train.replica_device_setter(
worker_device="/job:worker/task:%d" % FLAGS.task_index,
cluster=cluster)):
# Build your graph
v1 = tf.Variable(...) # assigned to /job:ps/task:0
v2 = tf.Variable(...) # assigned to /job:ps/task:1
v3 = tf.Variable(...) # assigned to /job:ps/task:0
# Run compute
```
使用tf.train.replica_device_setter可以自動把Graph中的Variables放到ps上,而同時將Graph的計算部分放置在當前worker上,省去了很多麻煩。由於ps往往不止一個,這個函數在為各個Variable分配ps時默認採用簡單的**round-robin**方式,就是按次序將參數挨個放到各個ps上,但這個方式可能不能使ps負載均衡,如果需要更加合理,可以採用**tf.contrib.training.GreedyLoadBalancingStrategy**策略。
採用Between-graph replication方式的另外一個問題,由於各個worker都獨立擁有自己的client,但是對於一些公共操作比如模型參數初始化與checkpoint文件保存等,如果每個client都獨立進行這些操作,顯然是對資源的浪費。為了解決這個問題,一般會指定一個worker為chief worker,它將作為各個worker的管家,協調它們之間的訓練,並且完成模型初始化和模型保存和恢復等公共操作。在TensorFlow中,可以使用tf.train.MonitoredTrainingSession創建client的Session,並且其可以指定哪個worker是chief worker。關於這些方面,想深入理解可以看一下2017 TensorFlow開發峰會的官方講解,其中也對分佈式TensorFlow的容錯機製做了簡單介紹。
### MNIST sync/async distributed compute
```python=
import tensorflow as tf
from tensorflow.contrib.learn.python.learn.datasets.mnist
import read_data_sets
tf.app.flags.DEFINE_string("ps_hosts", "localhost:2222", "ps hosts")
tf.app.flags.DEFINE_string("worker_hosts", "localhost:2223,localhost:2224", "worker hosts")
tf.app.flags.DEFINE_string("job_name", "worker", "'ps' or'worker'")
tf.app.flags.DEFINE_integer("task_index", 0, "Index of task within the job")
tf.app.flags.DEFINE_integer("num_workers", 2, "Number of workers")
tf.app.flags.DEFINE_boolean("is_sync", False, "using synchronous training or not")
FLAGS = tf.app.flags.FLAGS
def model(images):
"""Define a simple mnist classifier"""
net = tf.layers.dense(images, 500, activation=tf.nn.relu)
net = tf.layers.dense(net, 500, activation=tf.nn.relu)
net = tf.layers.dense(net, 10, activation=None)
return net
def main(_):
ps_hosts = FLAGS.ps_hosts.split(",")
worker_hosts = FLAGS.worker_hosts.split(",")
# create the cluster configured by `ps_hosts' and 'worker_hosts'
cluster = tf.train.ClusterSpec({"ps": ps_hosts, "worker": worker_hosts})
# create a server for local task
server = tf.train.Server(cluster, job_name=FLAGS.job_name,
task_index=FLAGS.task_index)
if FLAGS.job_name == "ps":
server.join() # ps hosts only join
elif FLAGS.job_name == "worker":
# workers perform the operation
# ps_strategy = tf.contrib.training.GreedyLoadBalancingStrategy(FLAGS.num_ps)
# Note: tf.train.replica_device_setter automatically place the paramters (Variables)
# on the ps hosts (default placement strategy: round-robin over all ps hosts, and also
# place multi copies of operations to each worker host
with tf.device(tf.train.replica_device_setter(worker_device="/job:worker/task:%d" % (FLAGS.task_index),
cluster=cluster)):
# load mnist dataset
mnist = read_data_sets("./dataset", one_hot=True)
# the model
images = tf.placeholder(tf.float32, [None, 784])
labels = tf.placeholder(tf.int32, [None, 10])
logits = model(images)
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=labels))
# The StopAtStepHook handles stopping after running given steps.
hooks = [tf.train.StopAtStepHook(last_step=2000)]
global_step = tf.train.get_or_create_global_step()
optimizer = tf.train.AdamOptimizer(learning_rate=1e-04)
if FLAGS.is_sync:
# asynchronous training
# use tf.train.SyncReplicasOptimizer wrap optimizer
# ref: https://www.tensorflow.org/api_docs/python/tf/train/SyncReplicasOptimizer
optimizer = tf.train.SyncReplicasOptimizer(optimizer, replicas_to_aggregate=FLAGS.num_workers,
total_num_replicas=FLAGS.num_workers)
# create the hook which handles initialization and queues
hooks.append(optimizer.make_session_run_hook((FLAGS.task_index==0)))
train_op = optimizer.minimize(loss, global_step=global_step,
aggregation_method=tf.AggregationMethod.ADD_N)
# The MonitoredTrainingSession takes care of session initialization,
# restoring from a checkpoint, saving to a checkpoint, and closing when done
# or an error occurs.
with tf.train.MonitoredTrainingSession(master=server.target,
is_chief=(FLAGS.task_index == 0),
checkpoint_dir="./checkpoint_dir",
hooks=hooks) as mon_sess:
while not mon_sess.should_stop():
# mon_sess.run handles AbortedError in case of preempted PS.
img_batch, label_batch = mnist.train.next_batch(32)
_, ls, step = mon_sess.run([train_op, loss, global_step],
feed_dict={images: img_batch, labels: label_batch})
if step % 100 == 0:
print("Train step %d, loss: %f" % (step, ls))
if __name__ == "__main__":
tf.app.run()
```
### Distributed Problem

* **Identifying the right ratio of worker to parameter servers:** If one parameter server is used, it will likely become a networking or computational bottleneck. If multiple parameter servers are used, the communication pattern becomes “all-to-all” which may saturate network interconnects.
* **Handling increased TensorFlow program complexity:** During our testing, every user of distributed TensorFlow had to explicitly start each worker and parameter server, pass around service discovery information such as hosts and ports of all the workers and parameter servers, and modify the training program to construct tf.Server() with an appropriate tf.ClusterSpec(). Additionally, users had to ensure that all the operations were placed appropriately using tf.train.device_replica_setter() and code is modified to use [towers](https://www.tensorflow.org/tutorials/using_gpu#using_a_single_gpu_on_a_multi-gpu_system) to leverage multiple GPUs within the server. This often led to a steep learning curve and a significant amount of code restructuring, taking time away from the actual modeling.
### All-reduce

In the **ring-allreduce** algorithm, each of N nodes communicates with two of its peers **2*(N-1)** times. During this communication, a node sends and receives chunks of the data buffer. In the first N-1 iterations, received values are added to the values in the node’s buffer. In the second N-1 iterations, received values replace the values held in the node’s buffer. Baidu’s paper suggests that this algorithm is bandwidth-optimal, meaning that if the buffer is large enough, it will optimally utilize the available network.
## [Introducing Horovod](https://arxiv.org/abs/1802.05799)
- [Meet Horovod: Uber’s Open Source Distributed Deep Learning Framework for TensorFlow](https://eng.uber.com/horovod/)
The realization that a ring-allreduce approach can improve both usability and performance motivated us to work on our own implementation to address Uber’s TensorFlow needs. We adopted Baidu’s draft implementation of the TensorFlow ring-allreduce algorithm and built upon it. We outline our process below:
1. We converted the code into a stand-alone Python package called [Horovod](https://github.com/uber/horovod), named after a traditional Russian folk dance in which performers dance with linked arms in a circle, much like how distributed TensorFlow processes use Horovod to communicate with each other. At any point in time, various teams at Uber may be using different releases of TensorFlow. We wanted all teams to be able to leverage the ring-allreduce algorithm without needing to upgrade to the latest version of TensorFlow, apply patches to their versions, or even spend time building out the framework. Having a stand-alone package allowed us to cut the time required to install Horovod from about an hour to a few minutes, depending on the hardware.
2. We replaced the Baidu ring-allreduce implementation with [NCCL](https://developer.nvidia.com/nccl). NCCL is NVIDIA’s library for collective communication that provides a highly optimized version of ring-allreduce. NCCL 2 introduced the ability to run ring-allreduce across multiple machines, enabling us to take advantage of its many performance boosting optimizations.
3. We added support for models that fit inside a single server, potentially on multiple GPUs, whereas the original version only supported models that fit on a single GPU.
4. Finally, we made several API improvements inspired by feedback we received from a number of initial users. In particular, we implemented a broadcast operation that enforces consistent initialization of the model on all workers. The new API allowed us to cut down the number of operations a user had to introduce to their single GPU program to four.
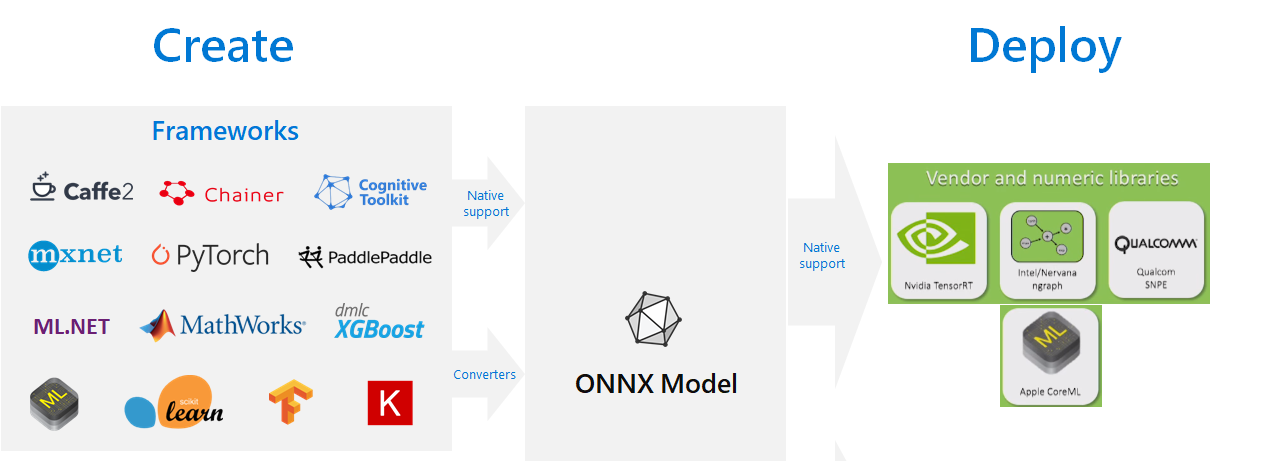
## [ONNX](https://onnx.ai/)
- ONNX is an open format to enable developers to more easily move models between one ML framework to another. Outside of the ML frameworks, ONNX also standardizes portability across converters, runtimes, compilers and visualizers. supports and to .
## ML Tracking
Make ML reproducible and easier to track metrics and params
- [mlflow note](https://docs.google.com/document/d/1LI2oIyI8_j9o87ANYowbzErPqrojqLL-qjyxh7RP5qY/edit)
- [comet-ml](https://www.comet.ml/)
## Hyper-parameter
> 首先,什麼是超參數(Hyper-parameter)?這是相對於模型的參數而言(Parameter),我們知道機器學習其實就是機器通過某種算法學習數據的計算過程,通過學習得到的模型本質上是一些列數字,如樹模型每個節點上判斷屬於左右子樹的一個數,或者邏輯回歸模型裡的一維數組,這些都稱為模型的參數。
>
> 那麼定義模型屬性或者定義訓練過程的參數,我們稱為超參數,例如我們定義一個神經網絡模型有9527層網絡並且都用RELU作為激活函數,這個9527層和RELU激活函數就是一組超參數,又例如我們定義這個模型使用RMSProp優化算法和learning rate為0.01,那麼這兩個控制訓練過程的屬性也是超參數。
## AutoML
> AutoML tends to automate the **maximum** number of steps in an ML pipeline—with a **minimum** amount of human effort and without compromising the model’s performance
### steps
- **Pre-processing**: for reading and pre-processing data.
- **Optimization**: for testing and cross-validating the models (Algorithm selection and hyperparameter tuning)
- **Prediction**: for making predictions.
### The Need for AutoML
1. Need to set up a team of seasoned data scientists who command a premium salar
2. Deciding which model is the best for your problem often requires more experience than knowledge.
## References
- [談談你對大規模機器學習這個領域的理解和認識?](https://www.zhihu.com/question/37057945)
- [How Facebook Scales Machine Learning](https://medium.com/@jamal.robinson/how-facebook-scales-artificial-intelligence-machine-learning-693706ae296f)
- [Katib: Kubernetes Native 的超參數訓練系統](https://blog.dongyueweb.com/katib:_kubernetes_native_%E7%9A%84%E8%B6%85%E5%8F%82%E6%95%B0%E8%AE%AD%E7%BB%83%E7%B3%BB%E7%BB%9F.html)
- [AutoML: The Next Wave of Machine Learning](https://heartbeat.fritz.ai/automl-the-next-wave-of-machine-learning-5494baac615f)
###### tags: `Note` `Machine Learning`
 Sign in with Wallet
Connect another wallet
Sign in with Wallet
Connect another wallet