# Processing 5 Billion Micropayments (at 100k TPS) with Vryx and Vilmo
Over the last few days, the first [Vryx](https://hackmd.io/@patrickogrady/rys8mdl5p) devnet processed **5 billion micropayments** at a sustained rate of **100,000 transactions per second (TPS)**. This test involved 10,000,000 active accounts (2,500,000 active every 60 seconds and 95,000 active every second) sending transfers to each other. The likelihood that a particular account was active in a transaction was given by a [Zipf-Mandelbrot Distribution](https://en.wikipedia.org/wiki/Zipf%27s_law) with a standard parameterization (`a=~1`, `b=~2.7`). The devnet was validated by 50 equal-weight instances (32 vCPU, 64 GB RAM, 100 GB io2 SSD) running Snowman Consensus across 5 regions (us-west-2, us-east-1, ap-south-1, ap-northeast-1, eu-west-1). Transactions were issued to 1 of 5 API nodes (1 per region) by a single issuer located in eu-west-1.
You can view the code that powered this devnet [here](https://github.com/ava-labs/hypersdk/pull/711). You can reproduce these results (or modify any of the configuration like the number of validators) in your own AWS account by [running this script](https://github.com/ava-labs/hypersdk/blob/dadbb8248d6b499eb38b14d6014a1e42a012e4d1/examples/morpheusvm/scripts/deploy.devnet.sh). If you don't want to deploy your own devnet but want to watch someone do it, you can check out this [video](https://youtu.be/O4Ahkj0_S6Q).
> This code is under active development and is not considered production-ready. If you run into any issues, please post them in the [HyperSDK repository](https://github.com/ava-labs/hypersdk/issues)!
## Proving Vryx Viability: Sustaining 100k TPS
In January, Ava Labs released [Vryx](https://hackmd.io/@patrickogrady/rys8mdl5p), a fortified decoupled state machine replication construction that provided a path to scale the throughput of each [Avalanche HyperSDK blockchain instance to over 100,000 TPS](https://www.theblock.co/post/274683/ava-labs-outlines-scaling-solution-vryx-in-plan-for-avalanche-to-reach-100000-tps). Providing a path and walking that path, however, are two different things. When translating a specification into running code, any engineer will tell you that unknown unknowns can sink any promising project (unforeseen issues with a design render an approach infeasible).
My first goal after the Vryx publication, for this reason, was to write a quick-and-dirty HyperSDK integration of Vryx to test the viability and performance of the core ideas proposed (can we hit 100k TPS on a multi-regional devnet?). [Tens of thousands of lines of code](https://github.com/ava-labs/hypersdk/pull/711) later, I am happy to report that the Vryx viability assessment was a success. Not only did the devnet sustain 100k TPS, it did so when deployed using a [script](https://github.com/ava-labs/hypersdk/blob/dadbb8248d6b499eb38b14d6014a1e42a012e4d1/examples/morpheusvm/scripts/deploy.devnet.sh) that anyone else could use to replicate the results (and to explore the performance of other configurations). While there were learnings that will be incorporated into Vryx, none of the learnings undermined the practicality of the approach or raised concern that Vryx would not work in a production setting.
Before reading further, please keep in mind that this is the **first** devnet configuration published for Vryx. **As soon as testing hit the performance goals set out prior to implementation, I decided to stop experimenting and publish the results.** In the coming months, I hope to answer questions like:
1) How much does throughput drop with more complex transactions?
2) How many transactions can be processed per second?
3) How many more validators can be added?
4) How many more regions can be added?
5) How many accounts can be used at a given TPS?
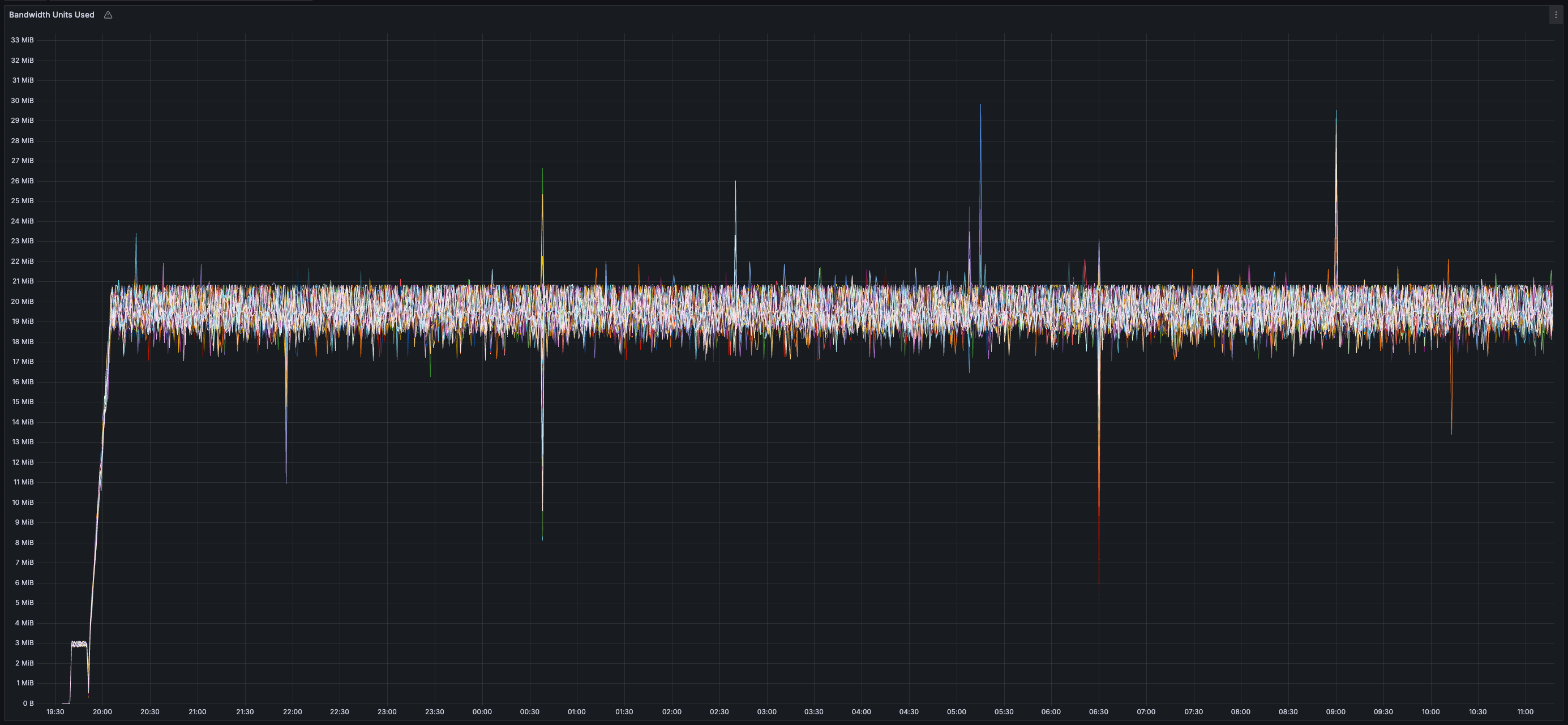
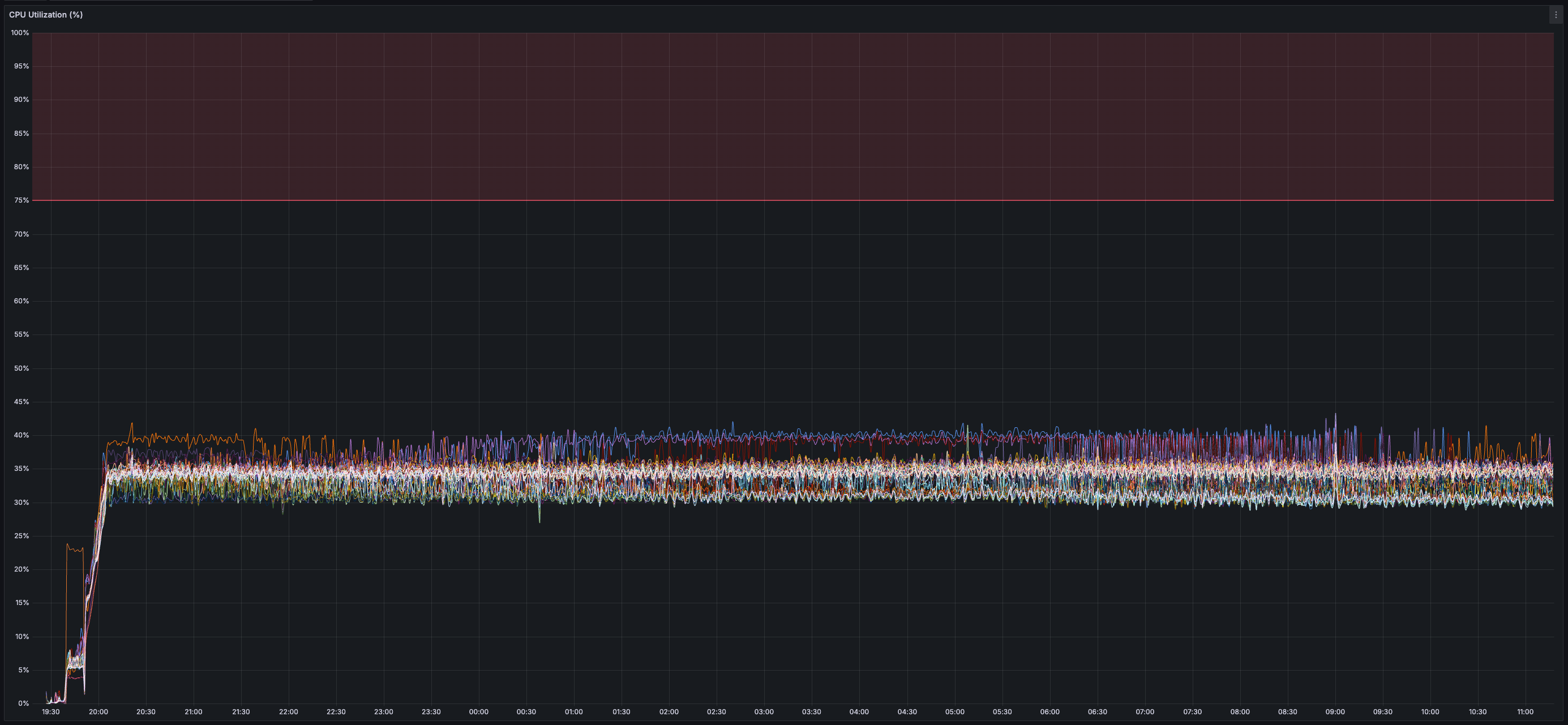
> Given this test only used ~35% of the validator CPU and ~13 MB/s of both inbound and outbound network bandwidth, I'd be surprised if this devnet configuration is the "limit" across any of these dimensions but will refrain from saying as much until there exist reproducible results demonstrating as much.
### Devnet Configuration
* _50_ equal-weight validators (c7g.8xlarge => 32 vCPU, 64GB RAM, 100GB io2 EBS with 2500 IOPS) deployed over 5 regions (us-west-2, us-east-1, ap-south-1, ap-northeast-1, eu-west-1) running Snowman Consensus
* _5_ API nodes (c7g.8xlarge => 32 vCPU, 64GB RAM, 100GB io2 EBS with 2500 IOPS) deployed over 5 regions (us-west-2, us-east-1, ap-south-1, ap-northeast-1, eu-west-1)
* _1_ transaction issuer (c7gn.8xlarge => 32 vCPU, 64GB RAM) in eu-west-1
* Transactions issued randomly to API nodes over a websocket connection (**never sent to validators directly**)
* _10,000,000_ active accounts
* _~2,500,000_ unique active accounts per 60 seconds
* _~95,000_ unique active accounts per second
* Account activity determined using a Zipf-Mandelbrot Distribution (_s=1.0001 v=2.7_)
* All transactions are transfers and each transfer has its own signature (Ed25519) that is verified by all participants
* All state changes are persisted to disk using Vilmo (more on this later)
* Accepted blocks and chunks pruned after reaching a depth of _512_
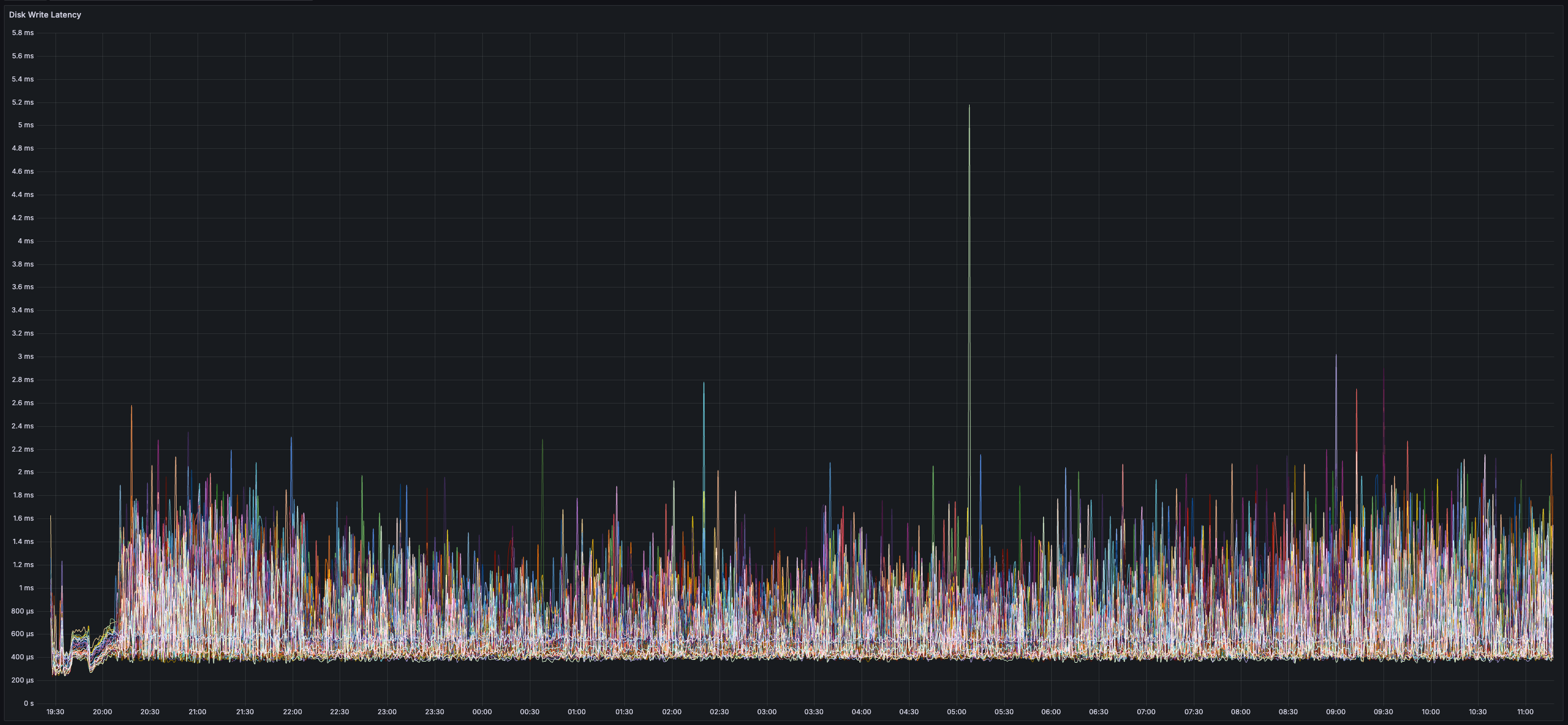
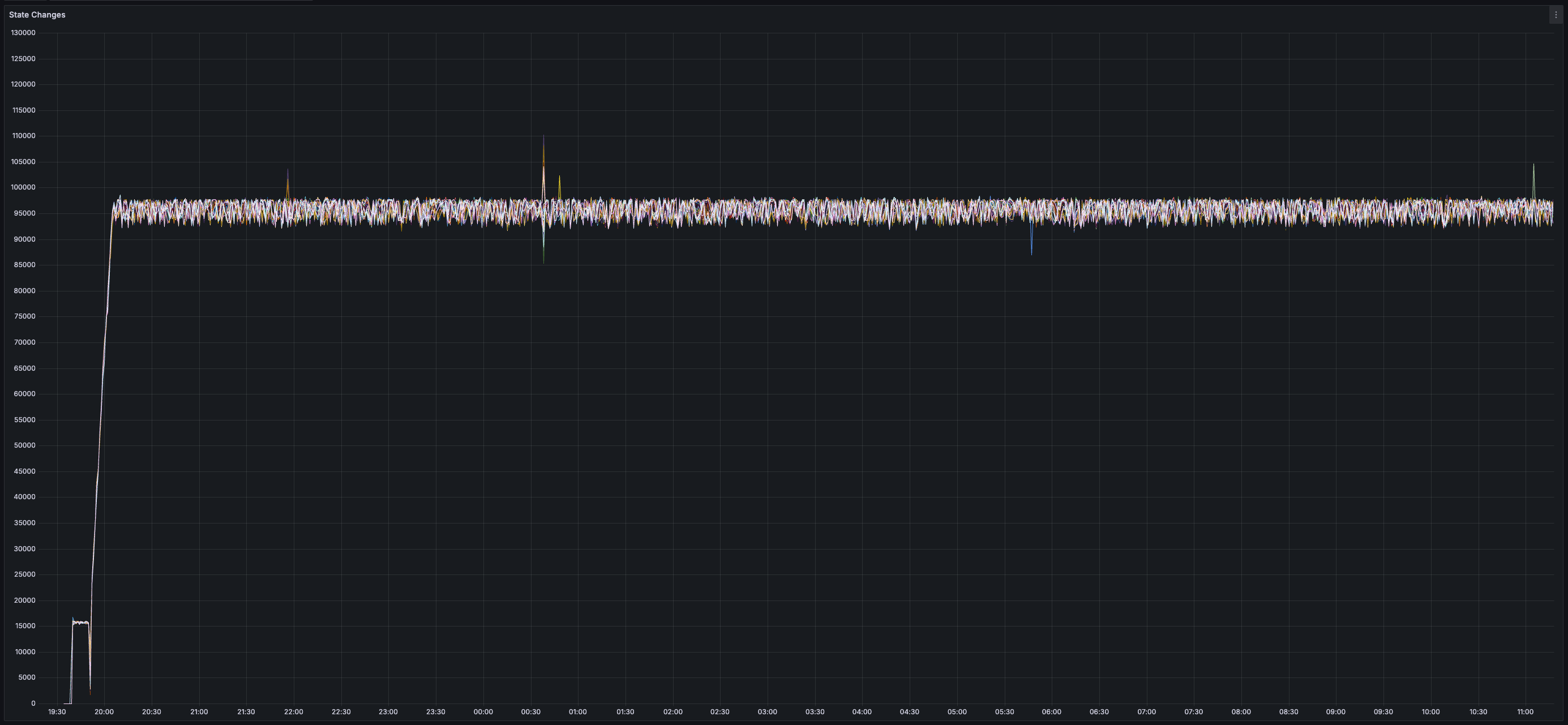
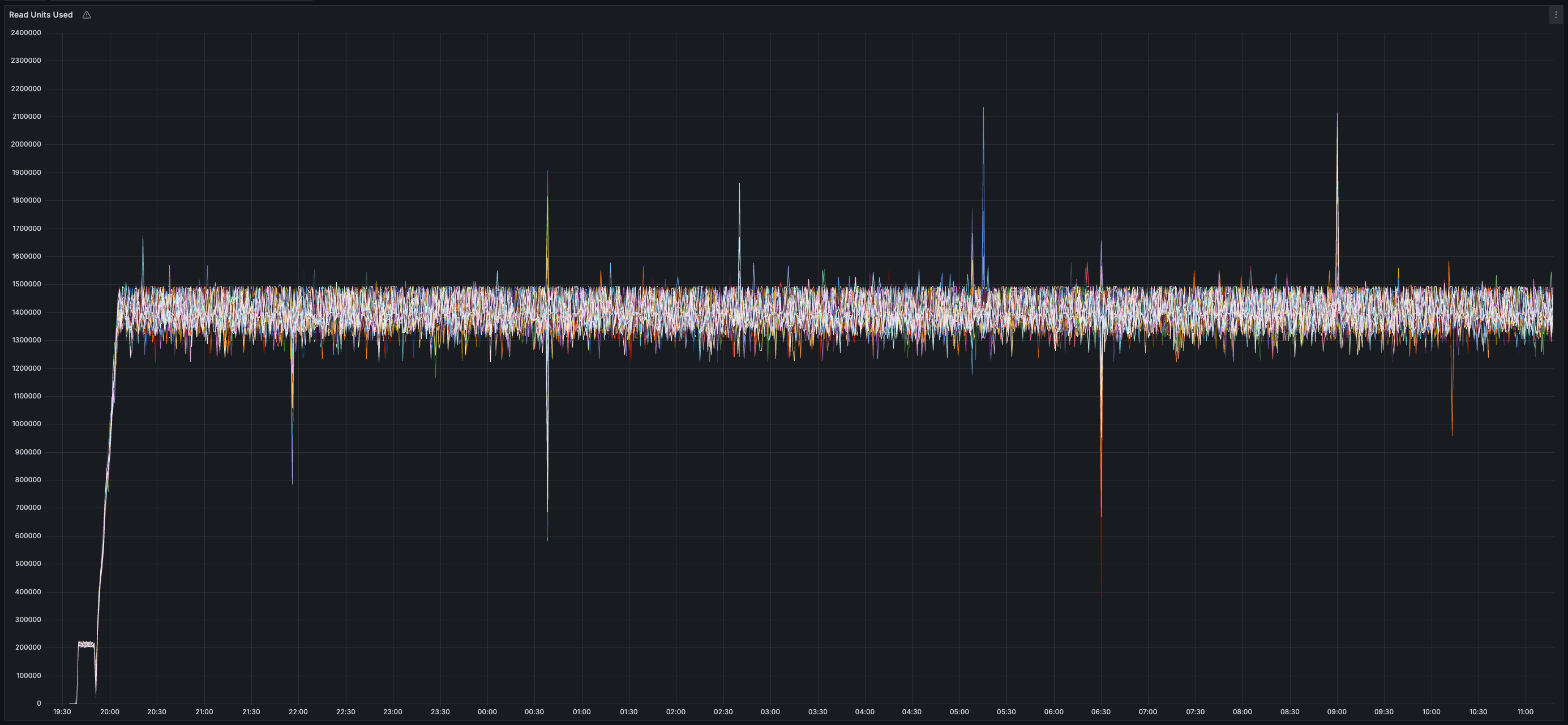
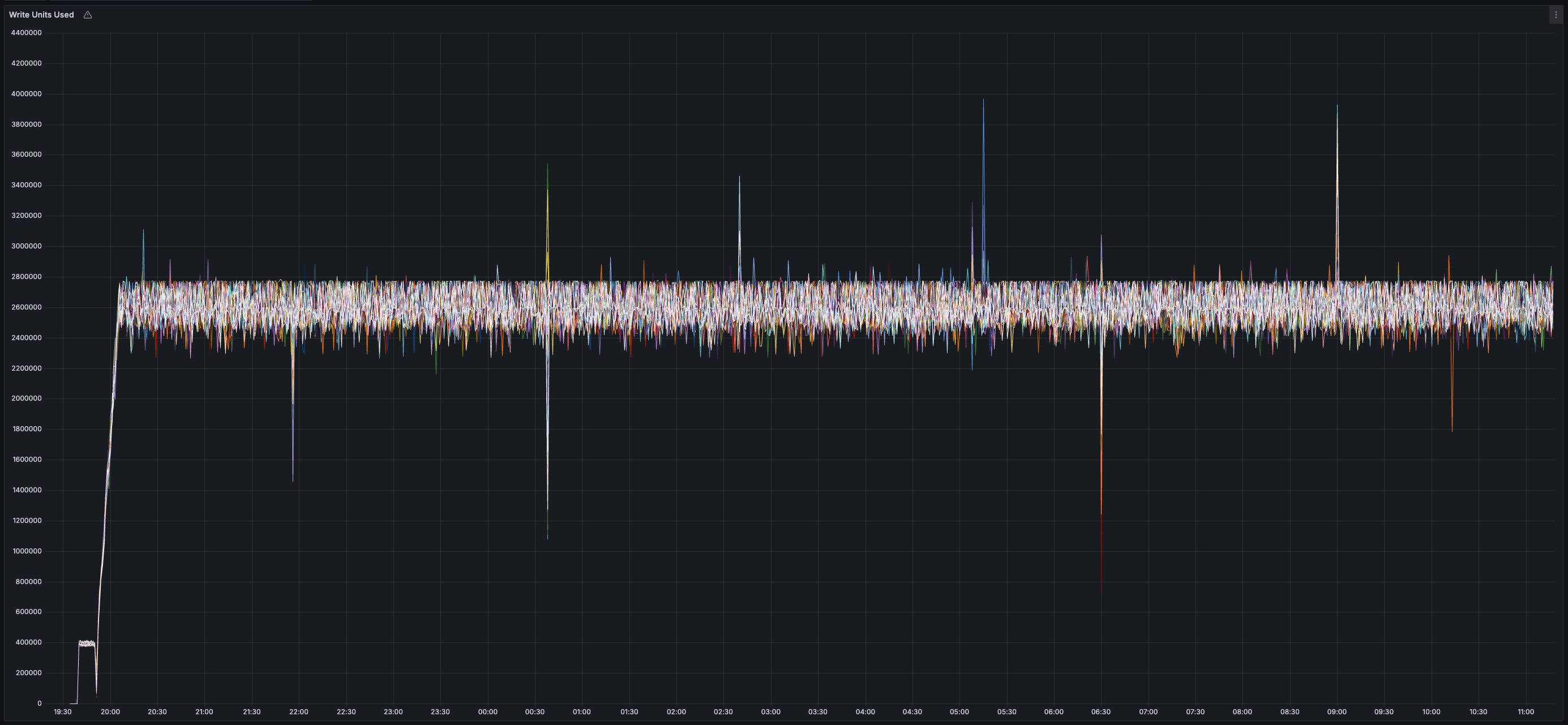
### Results
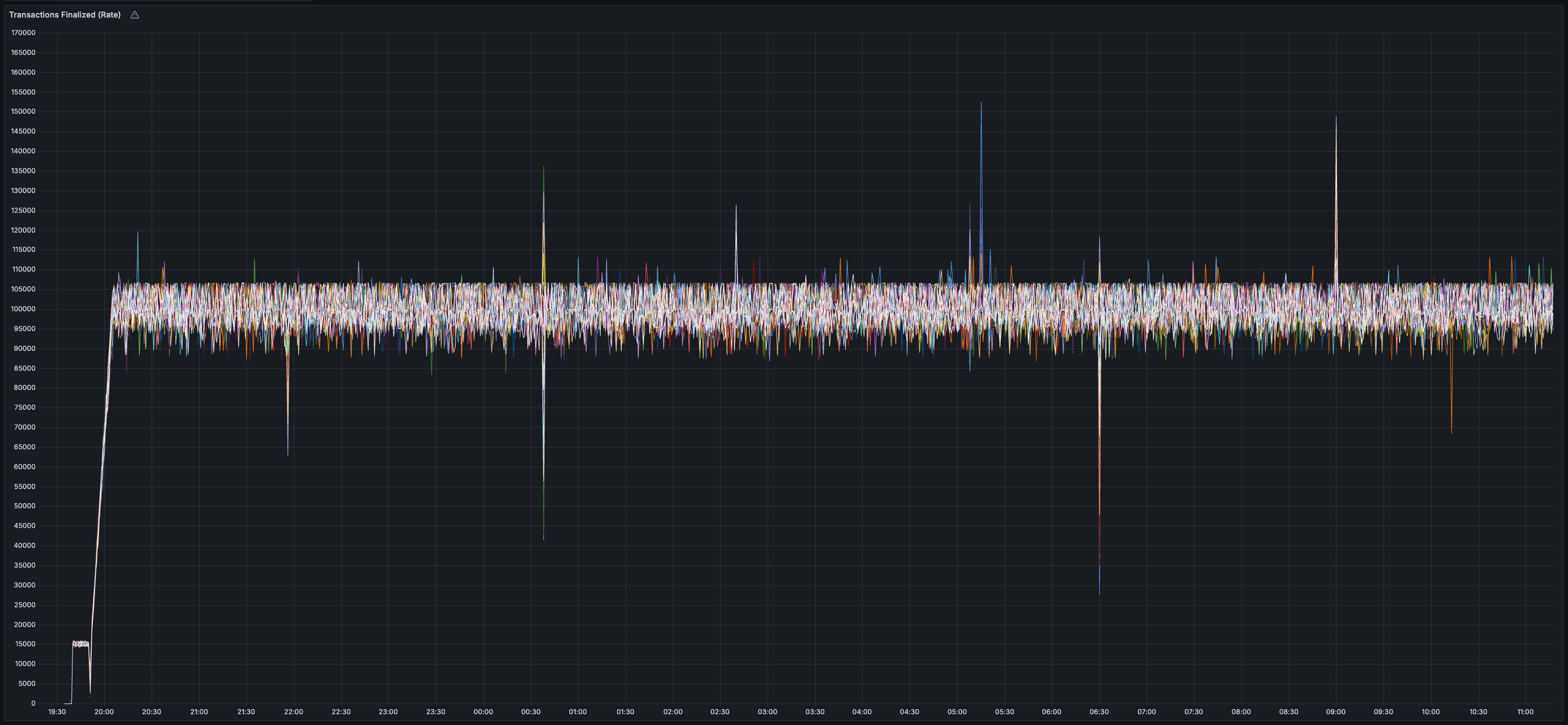
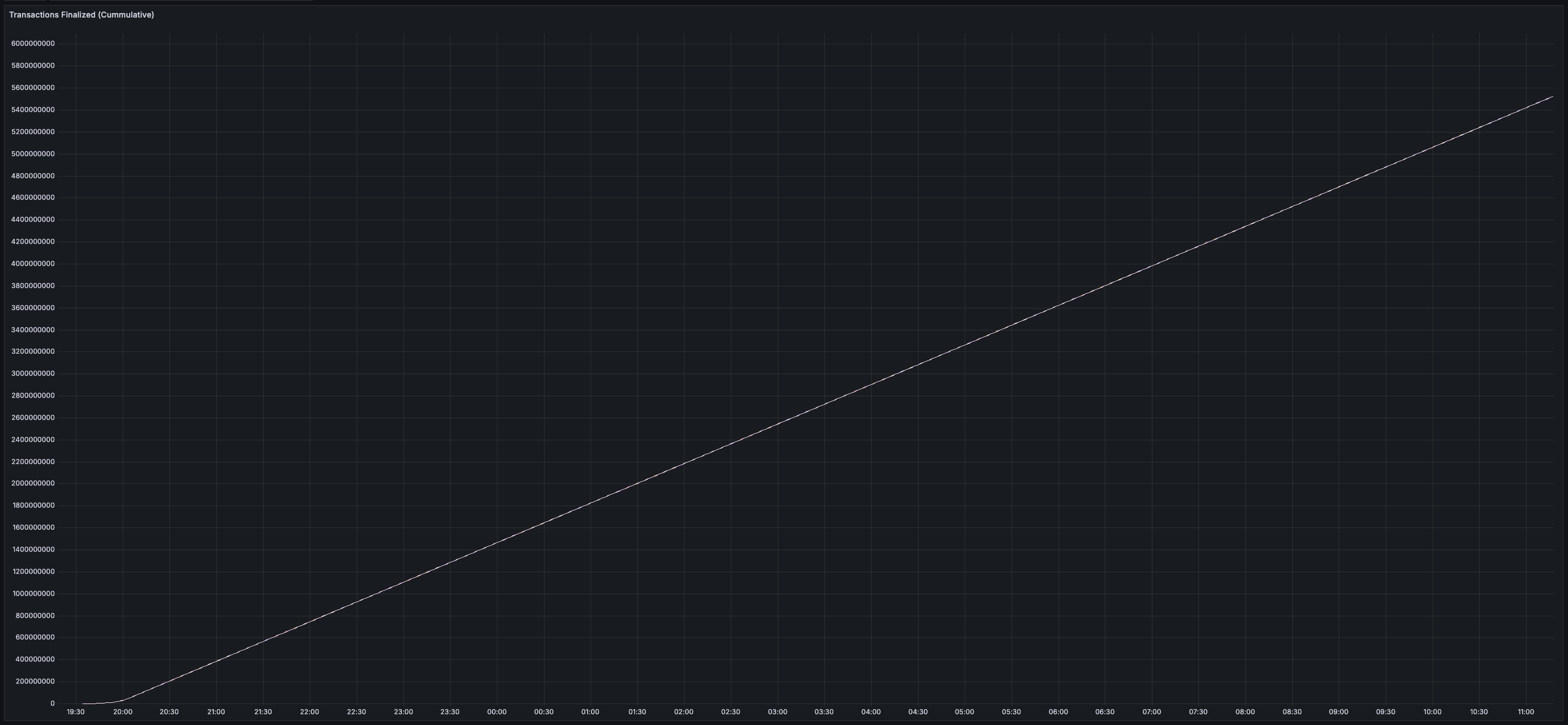
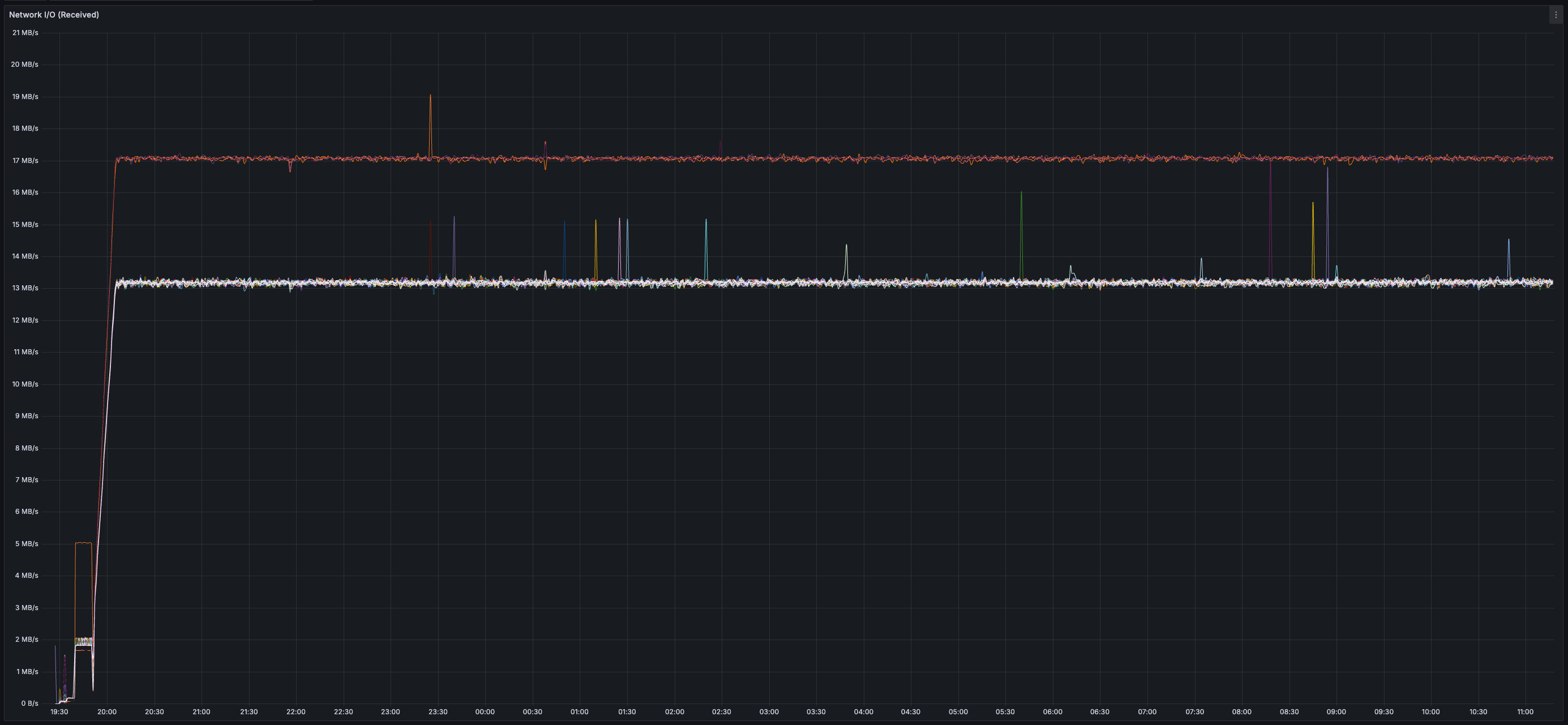
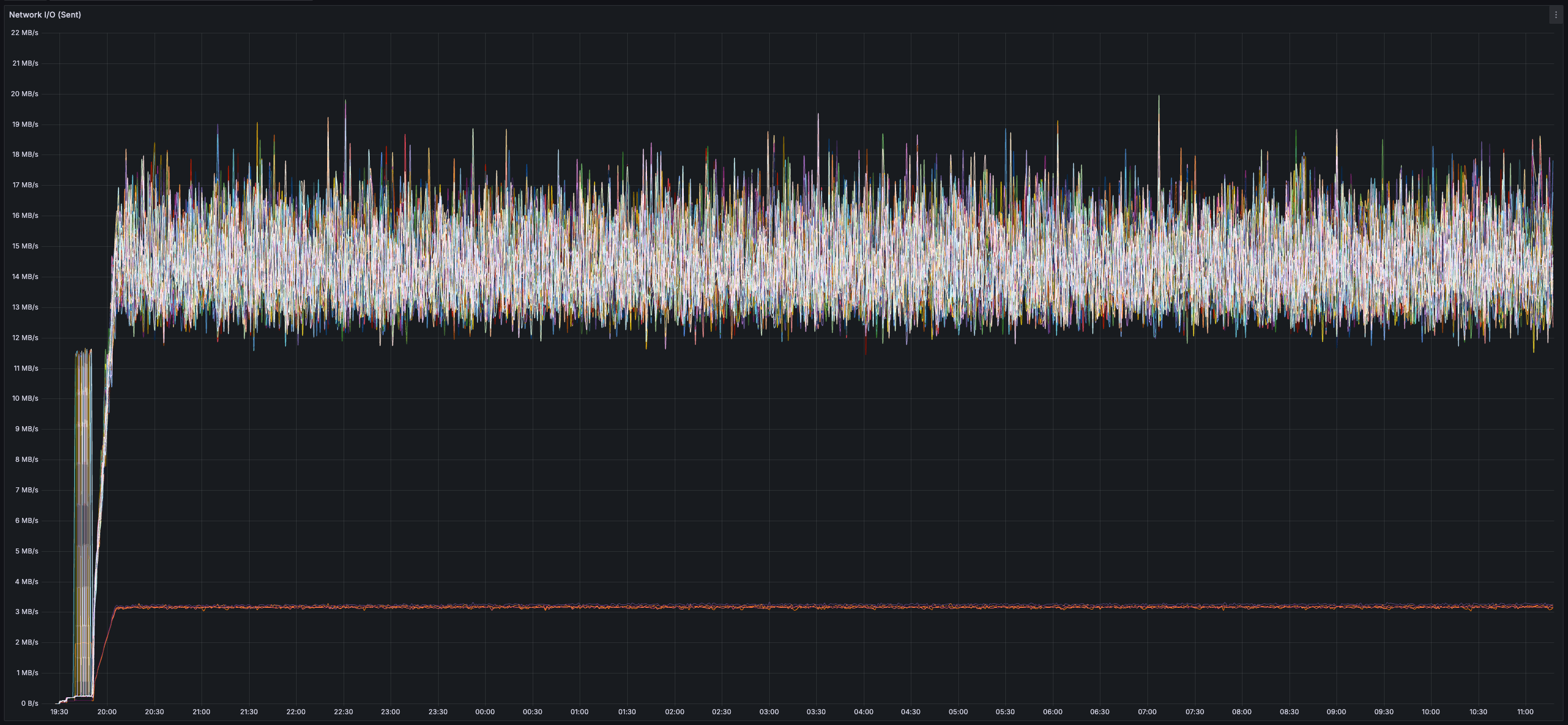
* _~20 MB/s_ of finalized transaction data
* _~13 MB/s_ of both inbound and outbound network bandwidth per validator (there is less than 20 MB/s of data sent between validators because all messages are compressed using zstd)
* Bandwidth usage is similar across all validators (no hotspots/imbalance)
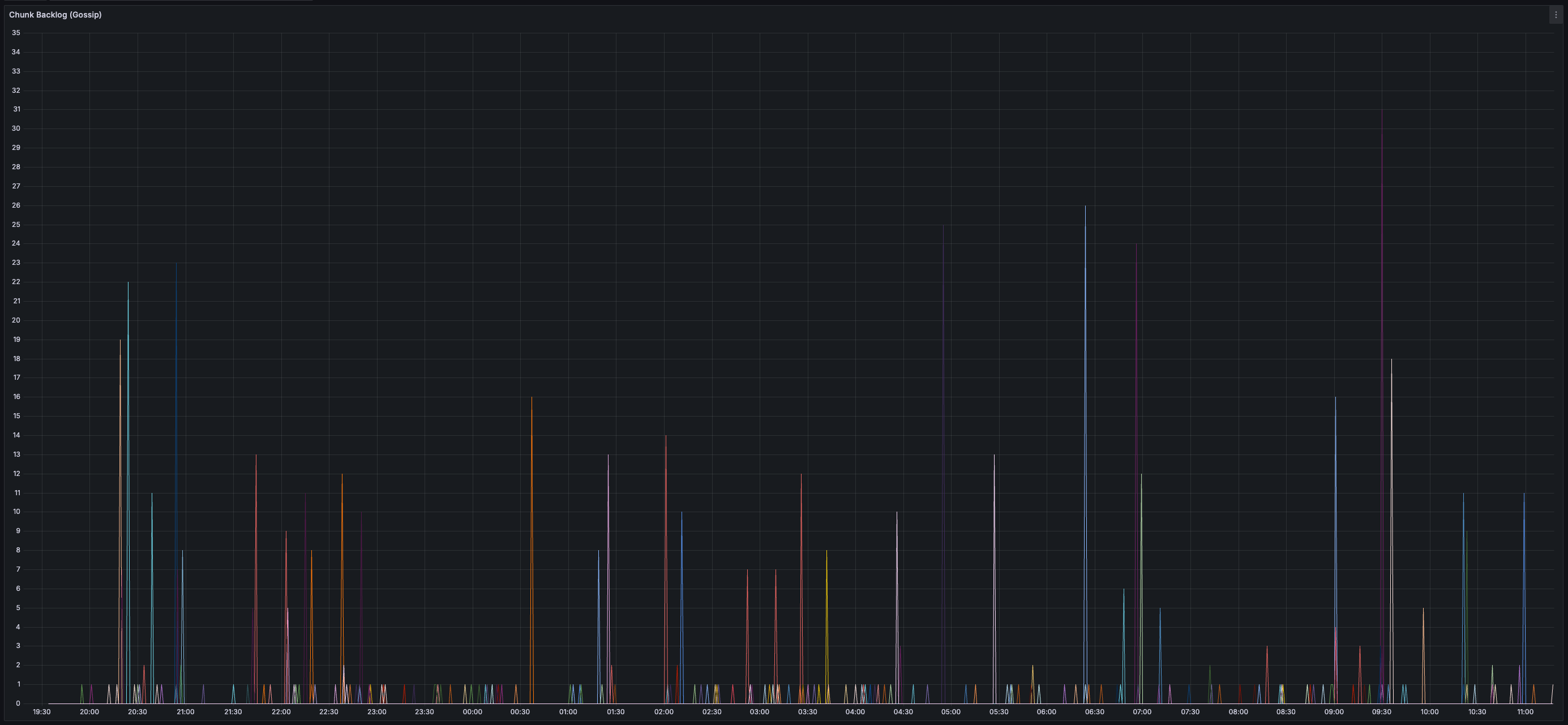
* _0%_ expiry and/or failure rate for transactions, chunks, and blocks
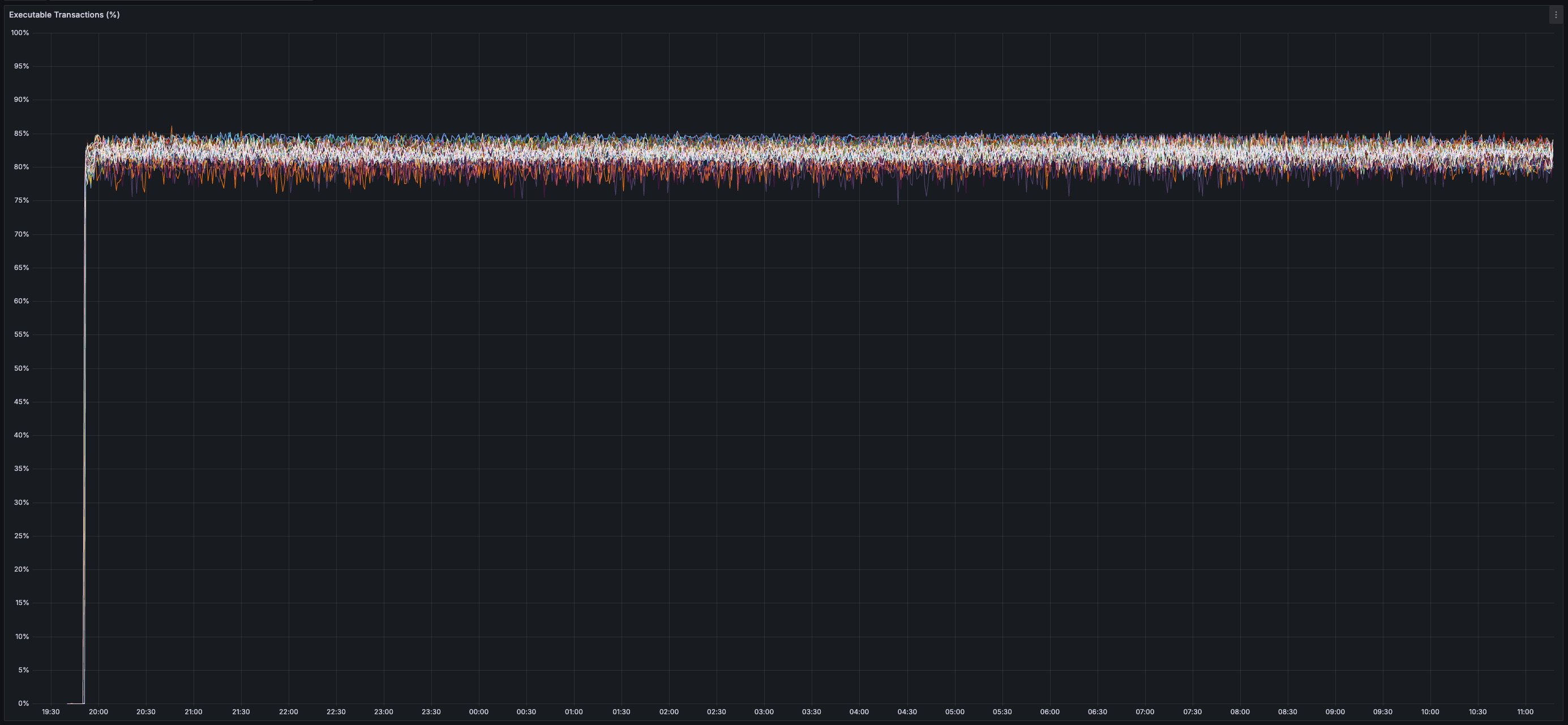
* _80%_ of transactions can be executed immediately (non-conflicting transactions are processed in parallel)
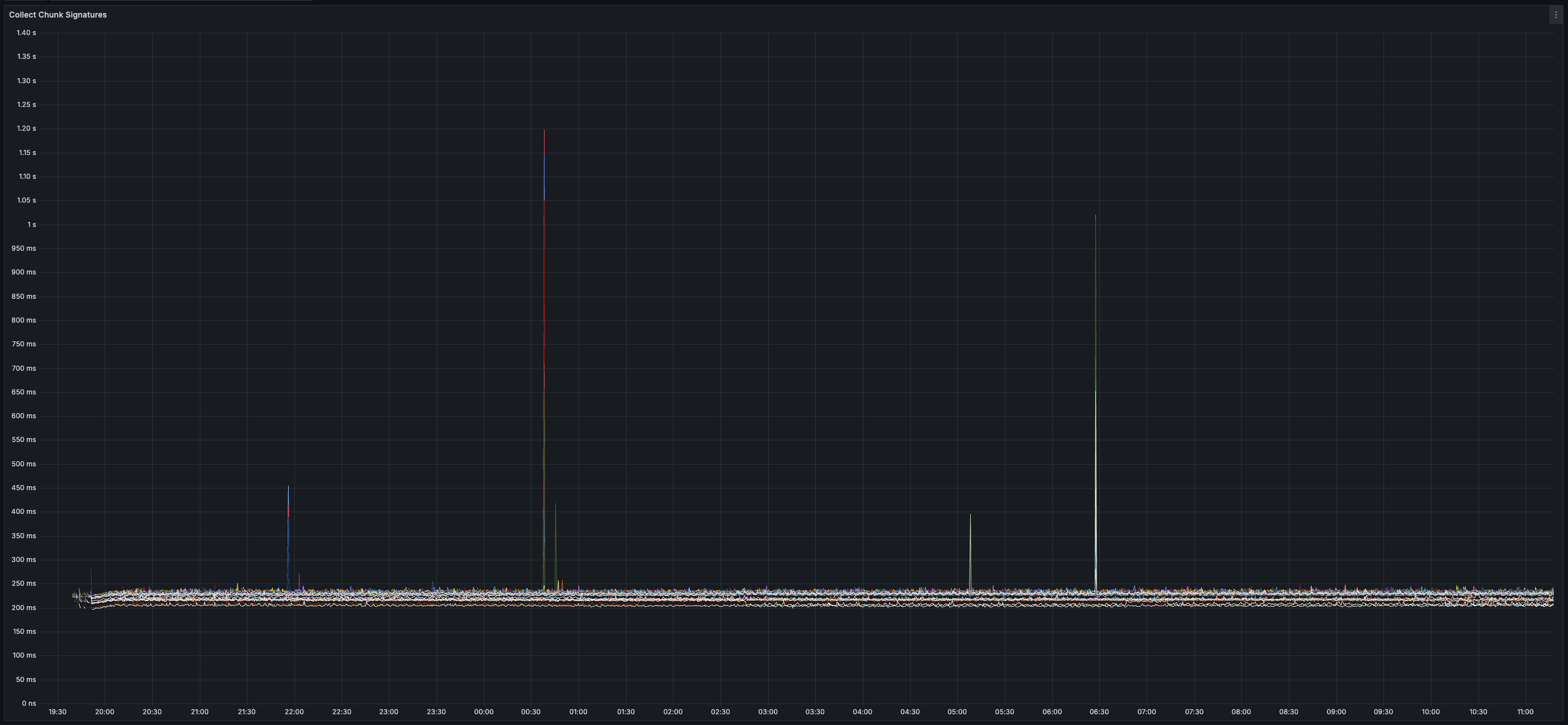
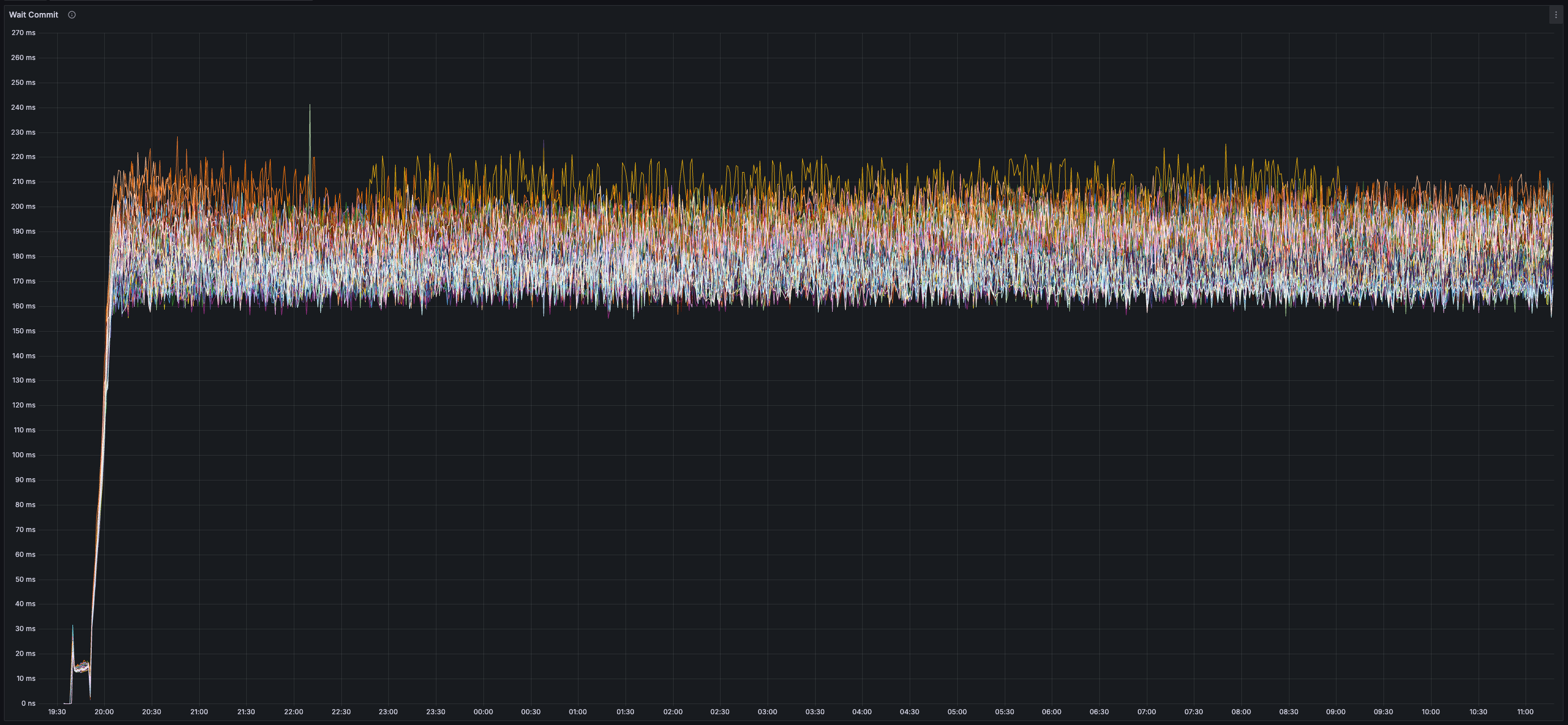
* _~230ms_ Time-To-Confirm Chunk (from production of chunk to generation of chunk certificate)
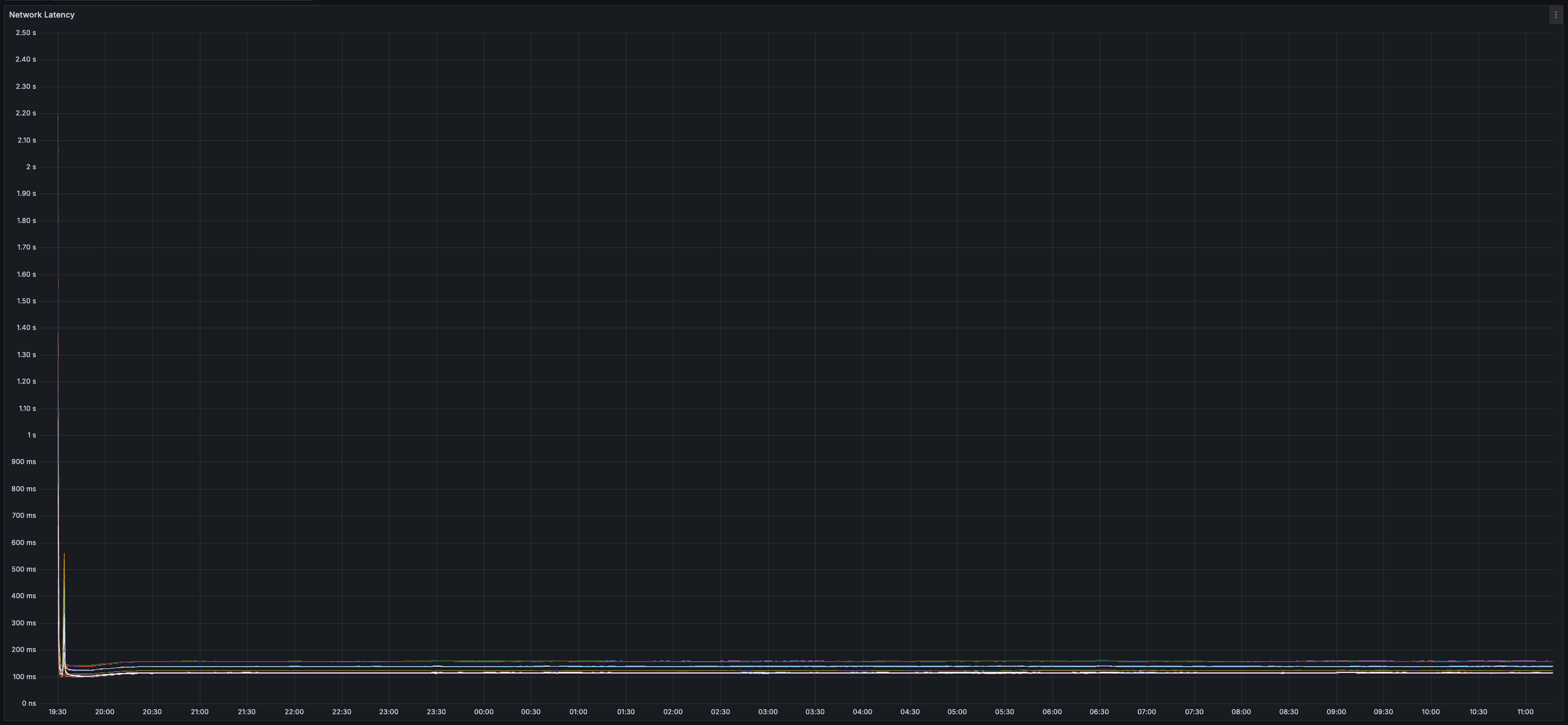
* _~700ms_ Time-to-Chunk Attestation (issuer sends transaction to API -> issuer receives notification from API that transaction is included in attested chunk)
* _~3.25s_ End-to-End Time-to-Finality (issuer sends transaction to API -> issuers receives notification from API that transaction is final)
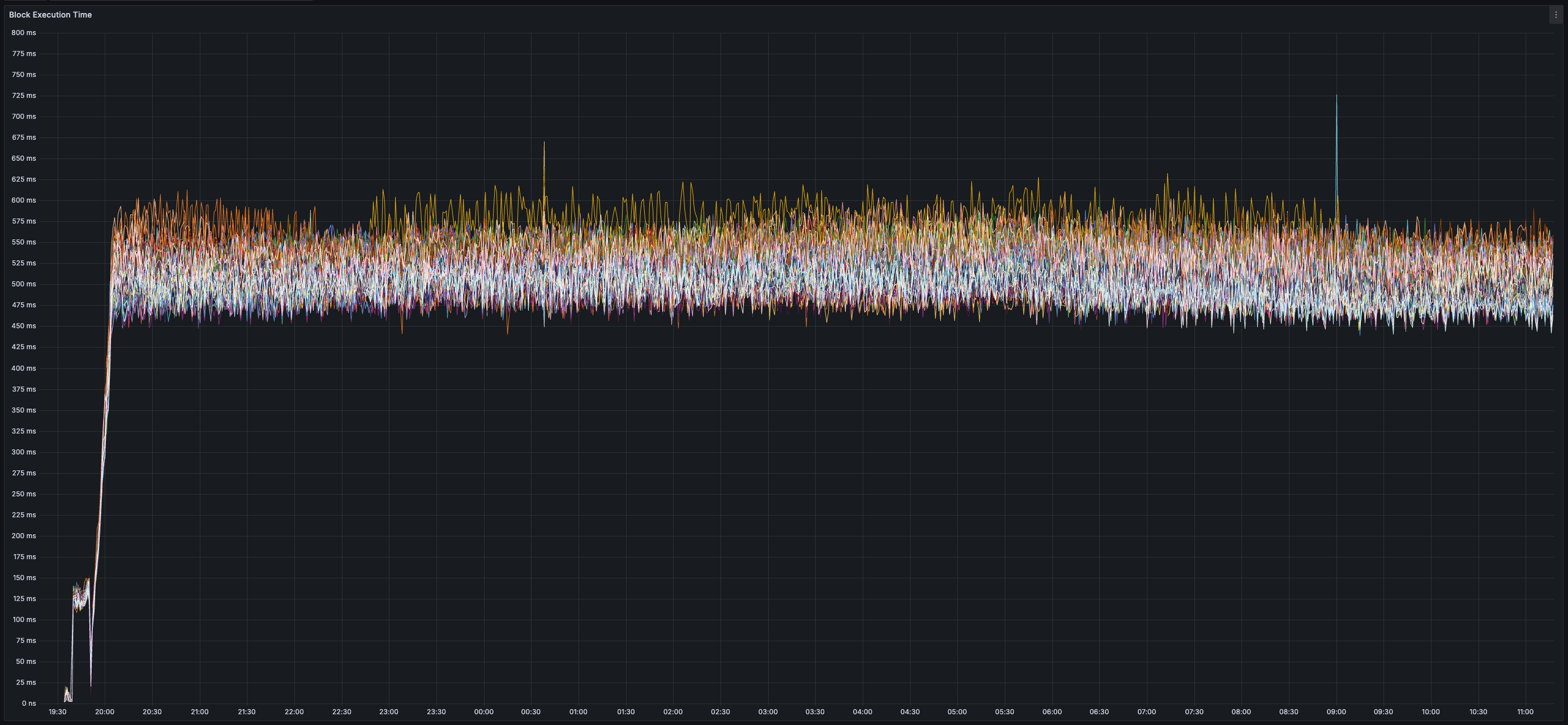
* _~35%_ CPU usage per validator
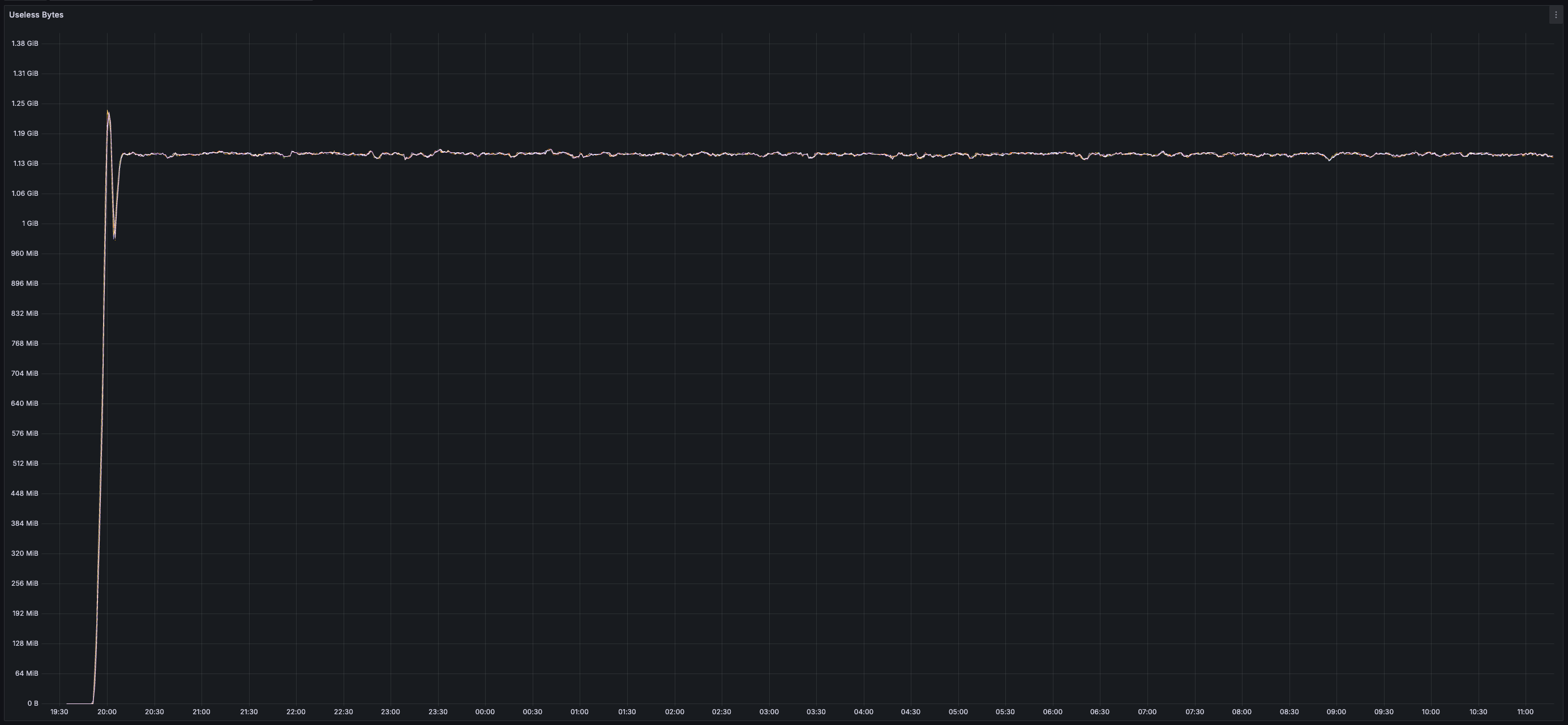
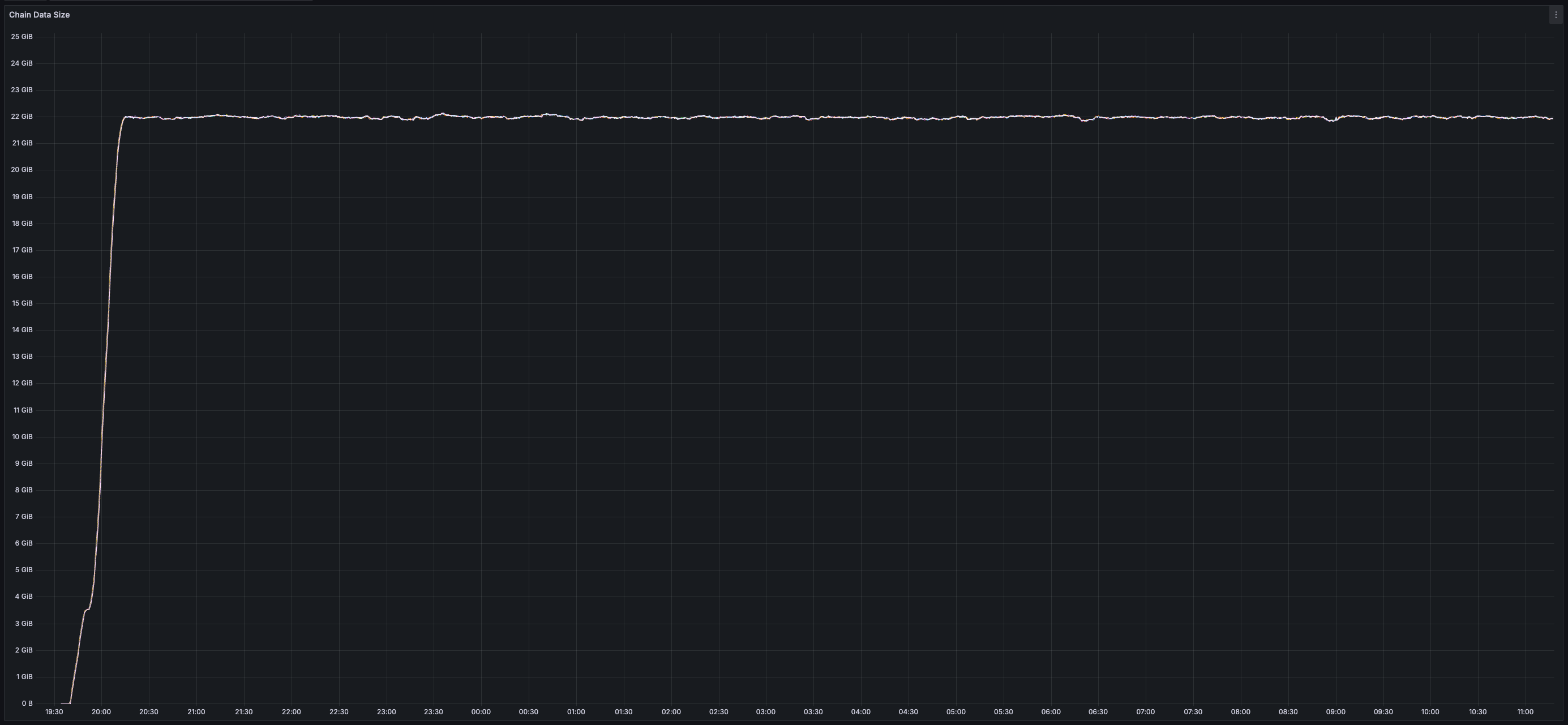
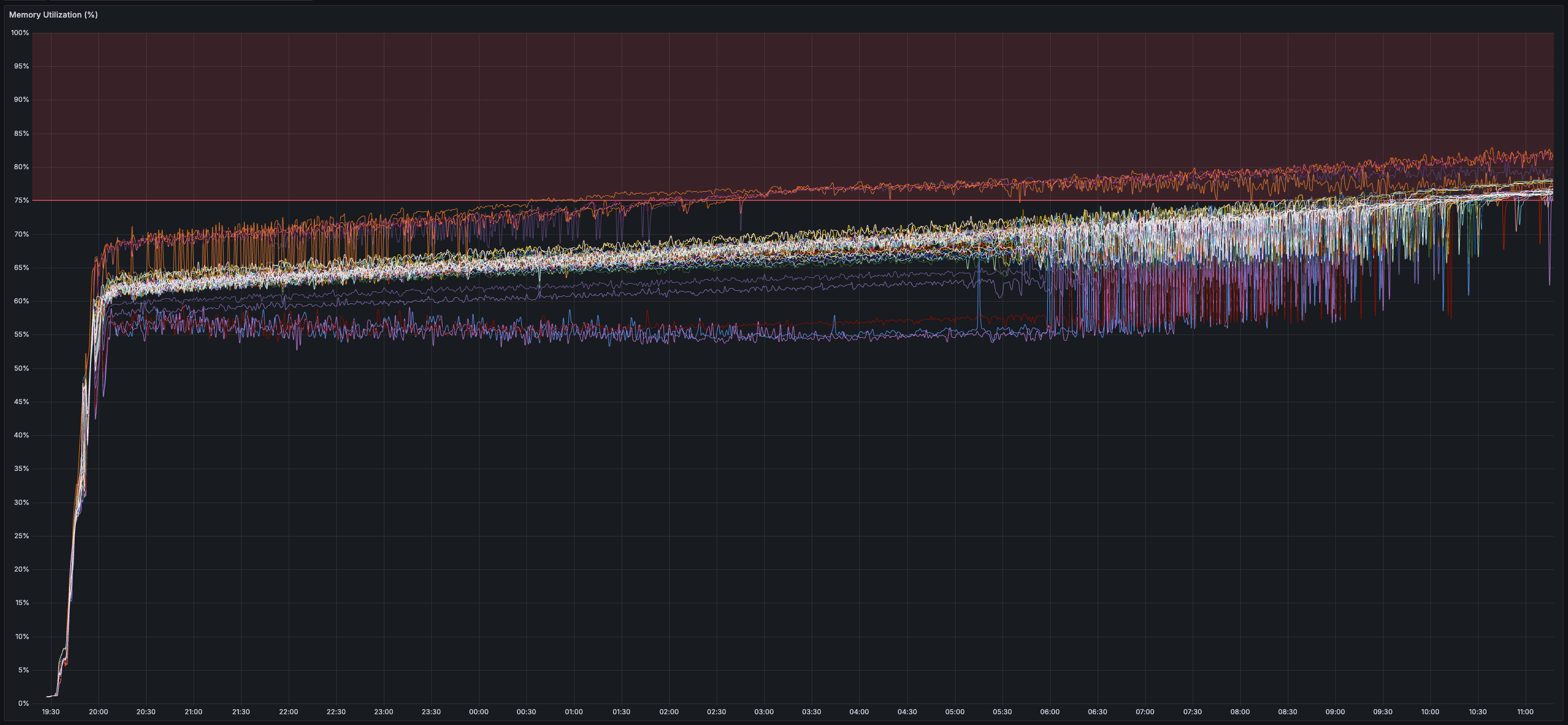
* _25 GB_ of disk space used per validator (blocks and chunks continuously pruned)
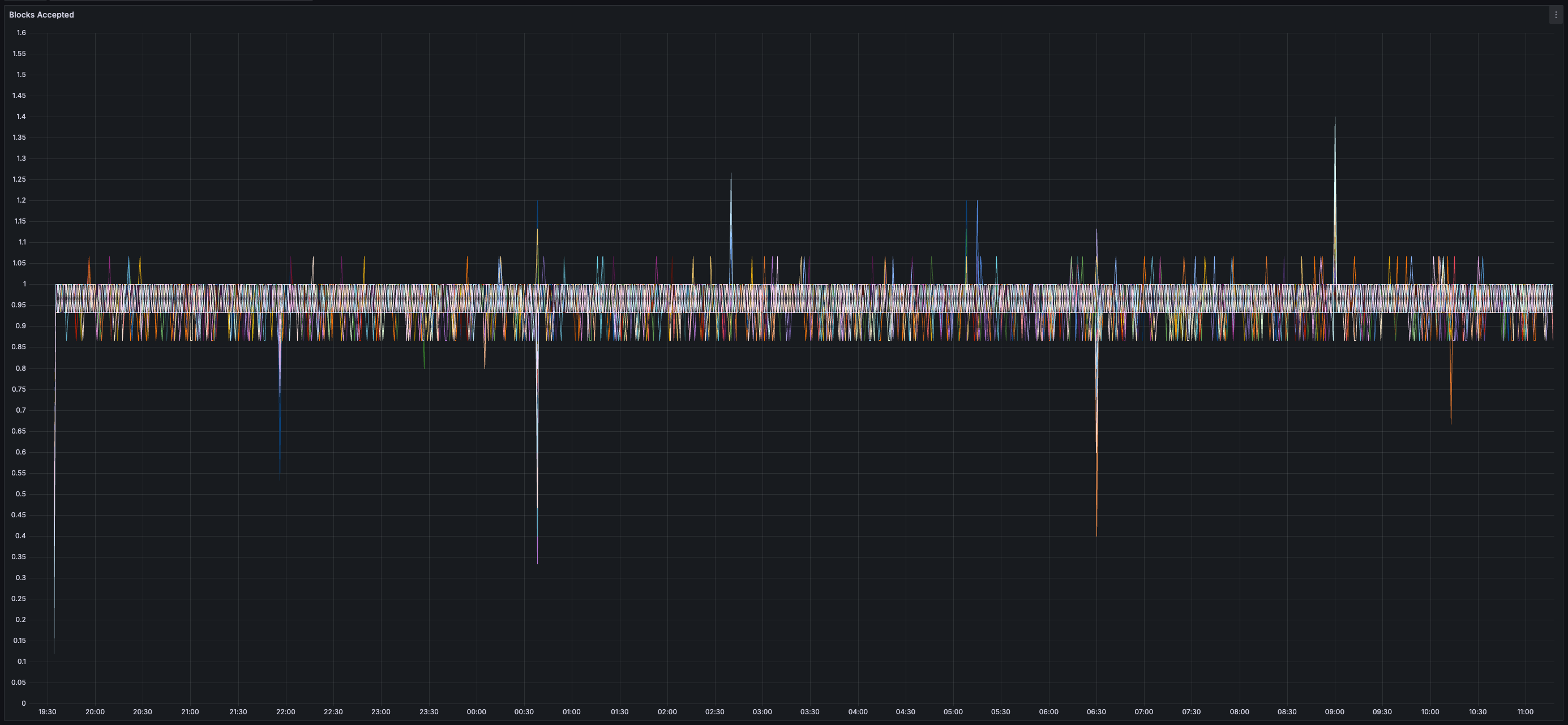
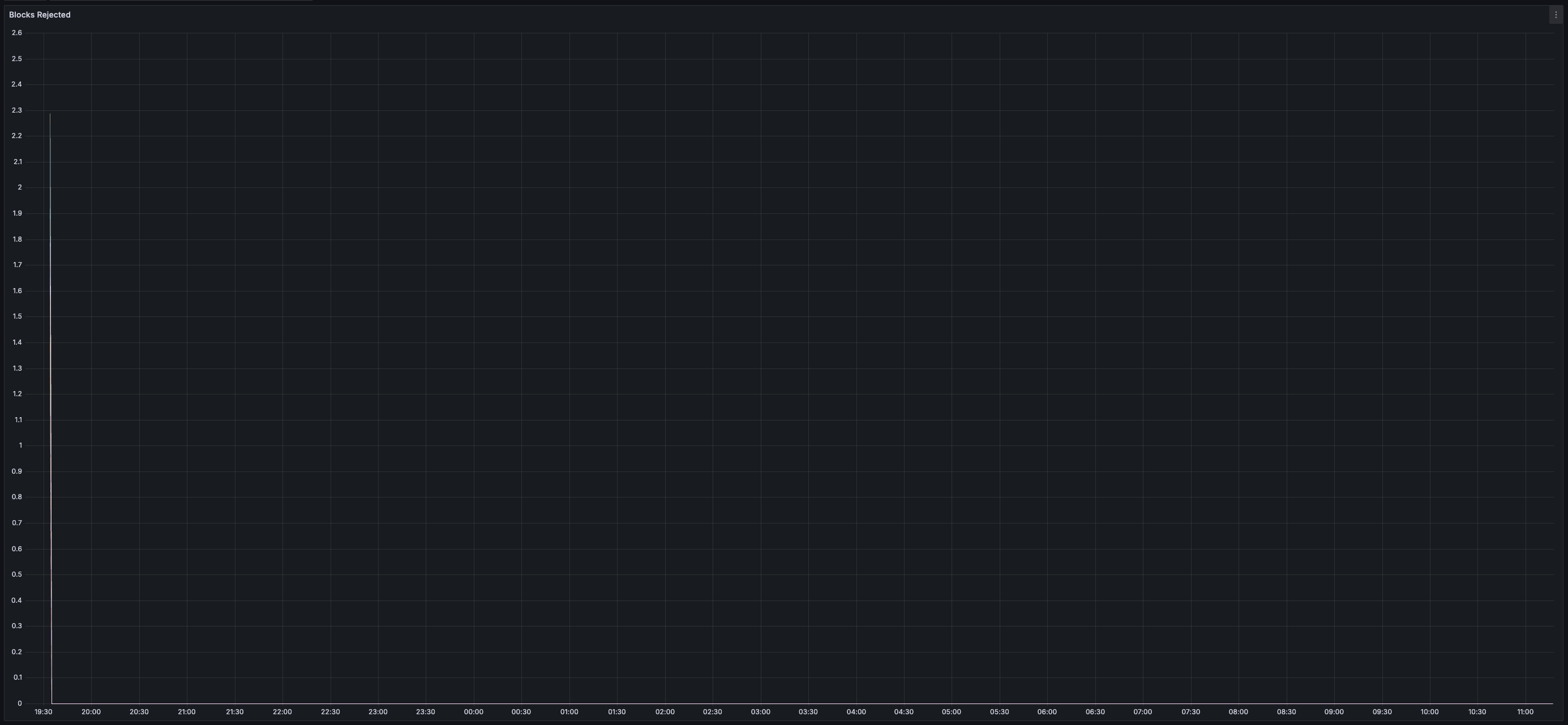
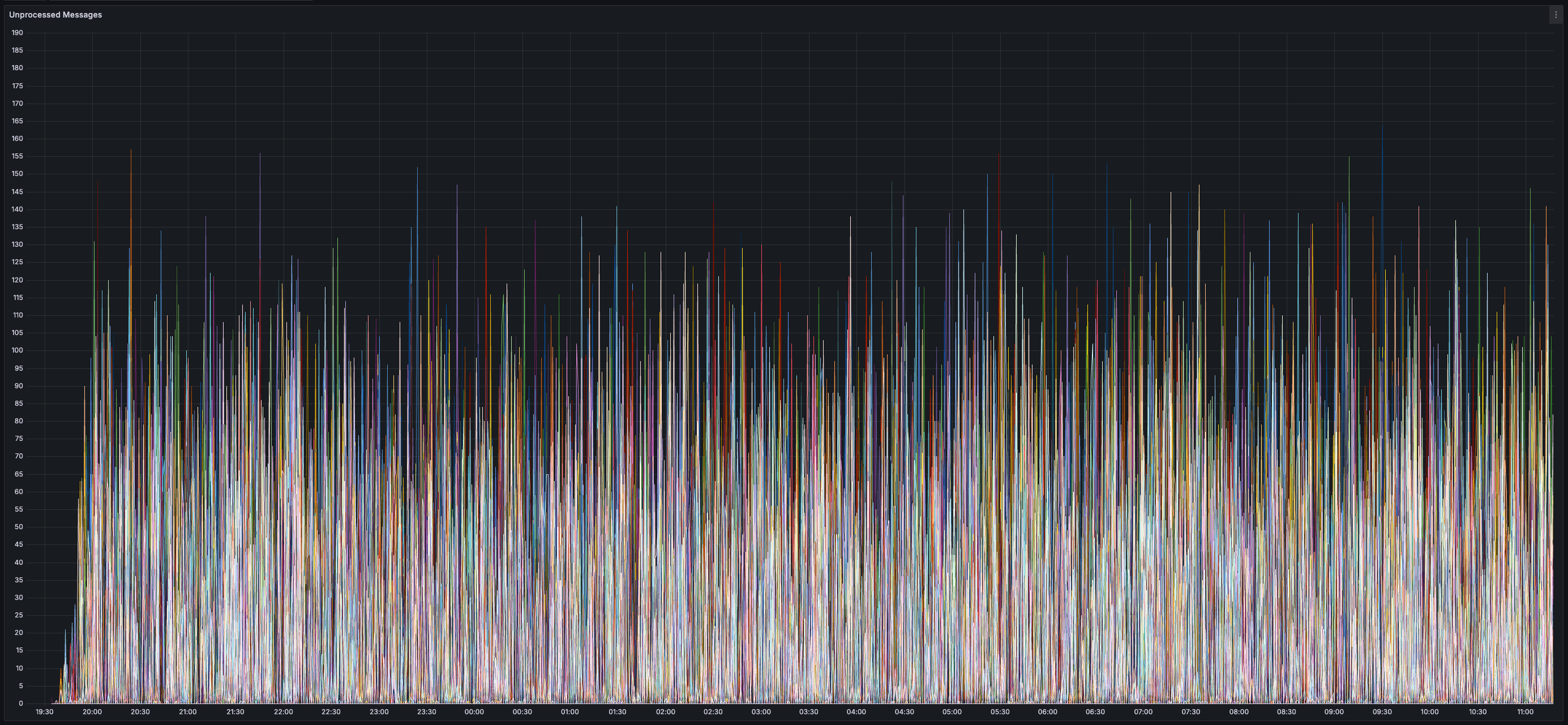
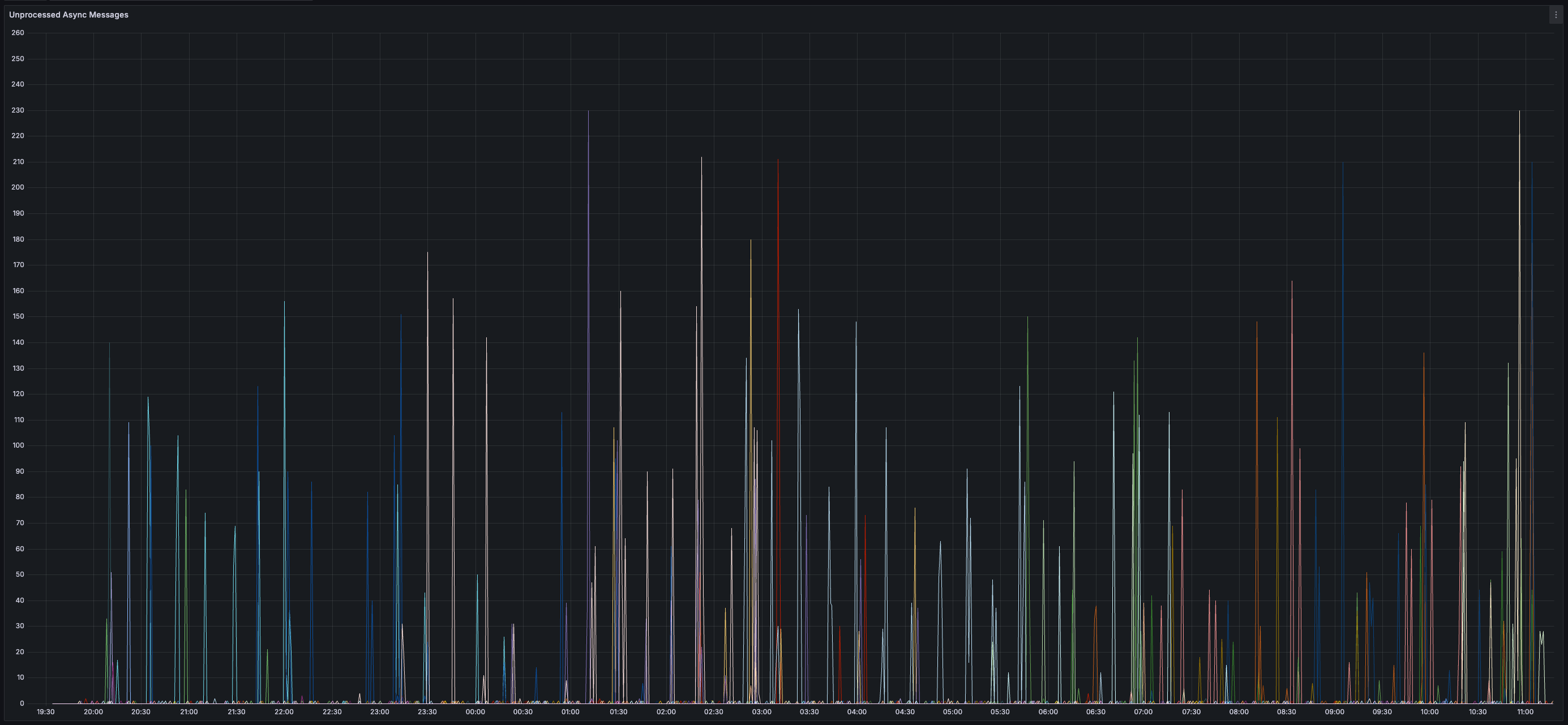
> You can view all collected metrics in the Appendix (at the bottom).
## Introducing Vilmo: Verifiable State Transitions and Sync without Merklization
> This is the first time that Vilmo has been discussed publicly. If you haven't heard of it before this moment, you didn't miss anything. Vilmo is a new database tailored for the HyperSDK that was borne from this research.
When designing the state storage layer for a blockchain, there are three primary capabilities that are typically considered:
1) proving the value of arbitrary keys in state
2) enforcing that state transitions are applied consistently amongst all parties
3) fetching the current state efficiently and verifiably from existing participants (to avoid re-execution of all state transitions)
When all these capabilities are required, most blockchains opt to [merklize their state](https://ethereum.org/en/developers/docs/data-structures-and-encoding/patricia-merkle-trie/) either once per block or once every few blocks (batched state updates can be more efficient). Once state is merklized, it can be efficiently represented by a single hash, the merkle root. If any values are modified, this root will change (i.e. two states will only have the same root if they have the same state). With this root, we can (1) generate a proof that any key-value (or range of key-values) is described by a root by providing a path of hashes from the root to the key-value in question. We can (2) enforce state transitions are applied consistently by checking whether this root (typically just 32 bytes) is the same as the root others have computed. We can (3) fetch the current state from existing participants by requesting a range of key-values from a given root and verifying the proof provided (this can even be done [on-the-fly as roots are updated](https://github.com/ava-labs/avalanchego/blob/7975cb723fa17d909017db6578252642ba796a62/x/merkledb/README.md?plain=1#L194) with some clever tricks). You can read more about the interesting properties of Merkle Tries [here](https://www.avax.network/blog/from-the-labs-handling-blockchain-state).
Merklization, however, is not "free". Each state update/read (not including any additional cost to update/maintain the underlying database that persists the merkle structure to disk) incurs a cost of `O(log(n))` and intermediate (inner) nodes must be maintained although they contain no workload data (just hashes of other nodes, which may be more intermediate nodes in a large trie). Most blockchains get around the `O(log(n))` complexity for each read by maintaining a [flat, key-value store](https://blog.ethereum.org/2021/05/18/eth-state-problems) that sits in front of the Merkle Trie, however, this approach requires storing a copy of all values and does nothing to reduce the cost of updating the Merkle Trie (in fact, it increases the cost because the value must be stored in both places). Others, have opted to store intermediate (inner) nodes in memory to avoid excessive disk writes or have opted to only update the merkle trie every `n` blocks to better amortize the cost of each update. Ava Labs has gone as far as building a [new database (Firewood)](https://www.avax.network/blog/introducing-firewood-a-next-generation-database-built-for-high-throughput-blockchains) to avoid the overhead of the underlying database managing the Merkle Trie on-disk (which has typically been done in an embedded database like LevelDB or RocksDB that isn't optimized for this workload).
Vilmo, the embedded key-value database that manages state on the HyperSDK, is an answer to the question: what if we don't require all of these properties? Specifically, what if we (1) don't need to prove the value of arbitrary keys in state but still want to (2) enforce state transitions are applied consistently and that (3) new nodes can efficiently fetch the current state from existing participants?
Vilmo optimizes for large (100k+ key-values) batch writes by leveraging a collection of rotating append-only log files. The deterministic checksum of the changes written in a single batch to a log file can then be used to compare the result of execution between multiple parties. When most of the data previously written to a log file is no longer "alive", the log file is compacted (rewritten) to only include "alive" data. When a batch is appended to an existing log file, (1) the checksum of the last batch is added to the checksum calculation of the new batch (so that the entire log file can be verified rather than just the latest batch) and (2) nullification entries are written for all keys that are no longer "alive" (to ensure they are not accidentally resurrected on restart if the logs that deleted said keys are rewritten). This allows for other parties to sync the last `n` log files from the chain to fully sync the latest state (by applying the modifications in order). Vilmo assumes that the operator keeps an index of all alive keys and the location of their values in-memory. Each log file is mmap-ed for fast access. You can review a preliminary implementation of Vilmo [here](https://github.com/ava-labs/hypersdk/tree/dadbb8248d6b499eb38b14d6014a1e42a012e4d1/vilmo). If you are familiar with WALs, you can think of Vilmo as a series of rotating WALs that are updated in a specific way.
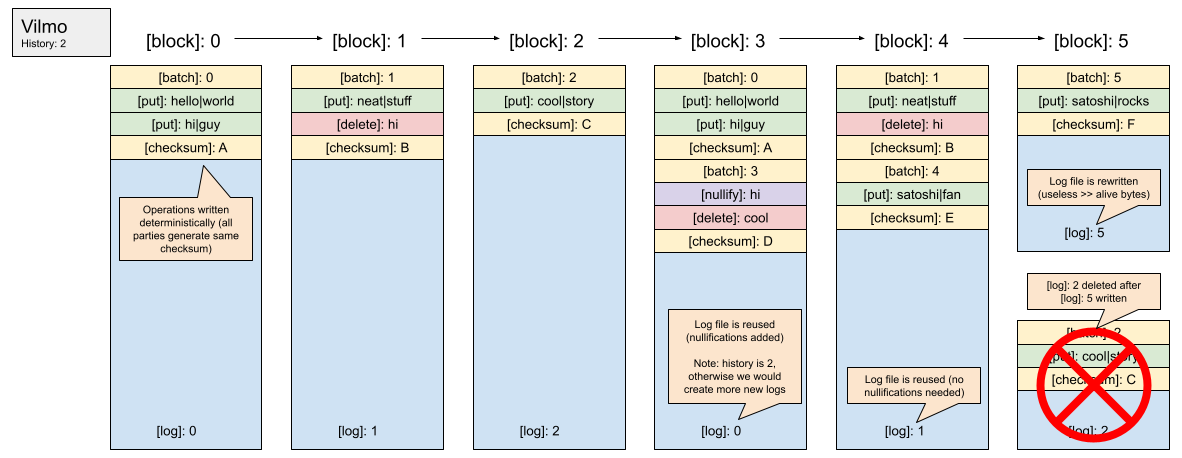
Vilmo compaction (when required) occurs during block execution and is synchronized across all nodes. The frequency of this compaction is tuneable (i.e. how much "useless" data can live in a log before cleanup), however, the timing of this compaction (during block execution) is not. This approach allows for a forthcoming implementation of state expiry and/or state rent to be applied during compaction (charging a fee to each key that is preserved during a rewrite). This fee would likely increase the larger the log file is to deter an attacker from purposely increasing the size of a single log file to increase the time compaction will take (Vilmo works best when log files are of uniform size). Exposing state compaction to the HyperSDK allows it to better charge for resource usage that is currently not accounted for in most blockchains (i.e. the cost of maintaining state on-disk).
## Is This Another "Bajillion TPS" Gimmick?
Anyone that has been around for more than a few days has seen a "TPS claim"...to be frank, why is this one any different?
**Transparency:** When publishing the results of a throughput test, the circumstances and context are everything. 100k TPS on a single machine is very different than 50 machines or 500 machines. Verifying signatures and persisting state changes to disk dramatically impact results. 10M active accounts put a very different stress on a system than 100 active accounts. Any throughput test must be adequately specified to carry any weight and you've been presented with detailed information about the network topology, the hardware used by each node, and the actual transactions issued (to reiterate again, only signed transfers are used in this test).
**Reproducibility:** Sharing an image of a throughput test or tweeting that it happened does not satisfy the burden of proof (or at least it doesn't in most industries). The code that is tested and the test itself should be available and reproducible by any observer on independent hardware. In the case of this setup, the code that was active on the devnet is available [here](https://github.com/ava-labs/hypersdk/pull/711) and the script that can be used to reproduce these results is available [here](https://github.com/ava-labs/hypersdk/blob/dadbb8248d6b499eb38b14d6014a1e42a012e4d1/examples/morpheusvm/scripts/deploy.devnet.sh).
**Attributable Tradeoffs:** When something seems too good to be true, it probably is. When designing the HyperSDK (and Vryx + Vilmo), non-zero cost tradeoffs were made to maximize throughput and minimize resource usage. Some of the more controversial tradeoffs include: (1) checksum-ing state instead of merklizing it, (2) storing an index of the disk location of all values in-memory, (3) requiring transactions to be committed before it is known whether they can be executed, and (4) charging fees for on-chain activity in 5 dimensions (bandwidth, compute, read, allocate, write). The path to best-in-class performance is not a set of zero cost compromises and requires careful consideration of the available design space to produce a set of tradeoffs that appeal at a given throughput level.
> If there are other qualities you think throughput tests should uphold that aren't mentioned here, please [reach out to me on X](https://twitter.com/_patrickogrady)! I've been considering something along the lines of **Production Plausible** but haven't quite found the right way to articulate it yet.
## Acknowledgements
Thanks to [Stephen Buttolph](https://twitter.com/stephenbuttolph), [Aaron Buchwald](https://twitter.com/AaronBuchwald), and [Darioush Jalali](https://twitter.com/darioush0) for their invaluable support during the initial implementation of Vryx. Your insightful feedback and novel ideas were instrumental to the success of this project.
Thanks to the entire [avalanche-cli](https://github.com/ava-labs/avalanche-cli) team for their work on supporting "single command devnet deployment" to make the these results reproducible with a single command.
## Appendix


 Sign in with Wallet
Connect another wallet
Sign in with Wallet
Connect another wallet