# 2020q1 Homework6 (sehttpd)
contributed by < `OscarShiang` >
###### tags: `linux2020`
## 測試環境
```shell
$ cat /etc/os-release
NAME="Ubuntu"
VERSION="18.04.4 LTS (Bionic Beaver)"
$ cat /proc/version
Linux version 5.3.0-40-generic (buildd@lcy01-amd64-024)
(gcc version 7.4.0 (Ubuntu 7.4.0-1ubuntu1~18.04.1))
$ lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 4
On-line CPU(s) list: 0-3
Thread(s) per core: 2
Core(s) per socket: 2
Socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 142
Model name: Intel(R) Core(TM) i5-7267U CPU @ 3.10GHz
Stepping: 9
CPU MHz: 3092.228
CPU max MHz: 3500.0000
CPU min MHz: 400.0000
BogoMIPS: 6199.99
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 4096K
NUMA node0 CPU(s): 0-3
```
## 作業要求
- [ ] 在 [高效能 Web 伺服器開發](https://hackmd.io/@sysprog/fast-web-server) 提到 epoll 的兩種工作模式 (level trigger vs. edge trigger),對照 [seHTTPd](https://github.com/sysprog21/sehttpd) 原始程式碼,解釋 epoll 工作模式的設定和在 web 伺服器實作的考量點 $\to$ 搭配程式碼實驗並說明
- [ ] 在 [sehttpd/src/http_parser.c](https://github.com/sysprog21/sehttpd/blob/master/src/http_parser.c) 裡頭維護著 HTTP 解析所用的狀態機 (state machine),能否推敲出其考量點呢?能否搭配 [第 8 週測驗題](https://hackmd.io/@sysprog/linux2020-quiz8) 提出縮減 branch/dispatch 成本的實作呢?
- [ ] [seHTTPd](https://github.com/sysprog21/sehttpd) 內部為何有 timer,考量點和具體作用為何?timer 為何用到 priority queue 呢?能否在 Linux 核心原始程式碼找到類似的用法?
- [ ] [Toward Concurrency](https://hackmd.io/@sysprog/Skh_AaVix) 提及 thread pool 的實作,lock-free/lockless 的 thread pool 的效益為何?在高並行的應用場域 (如 web 伺服器),可以如何發揮 thread pool 的效益呢?
- [ ] 解釋前述 `http-parse-sample.py` 運作機制,以及 eBPF 程式在 Linux 核心內部分析封包的優勢為何?
- [ ] 修改 [htstress.c](https://github.com/sysprog21/khttpd/blob/master/htstress.c) 並放入 git repository,學習 [wrk](https://github.com/wg/wrk) 和 [httperf](https://github.com/httperf/httperf) 的部分特徵,強化對 seHTTPd 伺服器的測試 (除了效能,也該涵蓋正確性測試,包含檔案存取),特別是 concurrency 和 multi-threading 等議題;
- [ ] 強化 seHTTPd 實作的例外處理,得以長時間持續運作,應修正各式程式邏輯、記憶體管理,和 I/O 事件模型處理相關的缺失;
- [ ] 參考上述 eBPF 範例程式,實作專門動態分析 seHTTPd 執行過程中 Linux 核心內部事件、系統呼叫,關鍵操作耗費的時間等等的工具;
- [ ] 引入 [thread pool](https://en.wikipedia.org/wiki/Thread_pool) 到 seHTTPd 探討對 web 伺服器的效能的影響,過程中應該充分量化各因素,尤其是在多執行緒的環境中 non-blocking I/O 搭配事件驅動程式設計的實作;
- [ ] 以 [sendfile](http://man7.org/linux/man-pages/man2/sendfile.2.html) 系統呼叫改寫 `src/http.c` 裡頭傳遞檔案內容的實作 (對應到 `serve_static` 函式),思考在高並行的環境中,檔案系統 I/O 的開銷及改進空間;
- [ ] 用 `$ grep -r TODO *` 找出 seHTTPd 的待做事項,予以列出並充分闡述具體執行方法,例如涉及動態記憶體管理、長期閒置連線的處理機制等等。
- [ ] 複習 [lab0](https://hackmd.io/@sysprog/linux2020-lab0) 裡頭針對 [Valgrind](https://valgrind.org/) 和建構其上的 [Massif](https://valgrind.org/docs/manual/ms-manual.html) 工具,用以分析 seHTTPd 的記憶體開銷,設計實驗讓 seHTTPd 得以長時間運作,並搭配各式工作負載 (work load)。
- [ ] 在你的開發環境中安裝 [Nginx](https://nginx.org/en/) 伺服器並比較由你強化後的 seHTTPd 和 [Nginx](https://nginx.org/en/) 的效能差異,試圖解釋針對 Linux 的改進空間
## web 伺服器設計的考量點
因為在典型的 `accept`, `read`, `write` 等等系統呼叫會導致程式 blocking,即使目前沒有資料傳入。
但是若直接將這些 socket 的 file descroptor 設定成 non-blocking 卻會讓程式無法分辨什麼時候要呼叫 `read` 以接收資料,進而導致收發資料的過程中發生錯誤。
為了監聽 file descriptor 的狀態,讓 server 可以在正確的時間點使用系統呼叫進行操作,我們可以使用 `select` 來監聽多個 file descriptor,以便在有資料傳送時才接收資料,但是 `select` 使用遍歷的方式檢查 `fd_set` 中的 file descriptor,且 `select` 最多只能監聽 1024 個 file descriptor,可以看到在使用 `select` 的限制。
而其替代方案就是使用監聽的時間複雜度為 $O(1)$ 且可以監聽更多 file descriptor 的 `epoll` 來實作。
## epoll 工作模式的考量
根據 [epoll(7) - Linux manual](http://man7.org/linux/man-pages/man7/epoll.7.html) 的敘述:
> The epoll API performs a similar task to poll(2): monitoring multiple
file descriptors to see if I/O is possible on any of them. The epoll
API can be used either as an **edge-triggered** or a **level-triggered**
interface and **scales well to large numbers of watched file
descriptors**.
在 epoll 系列的操作中有兩種工作的模式:
1. Level-triggered
2. Edge-triggered
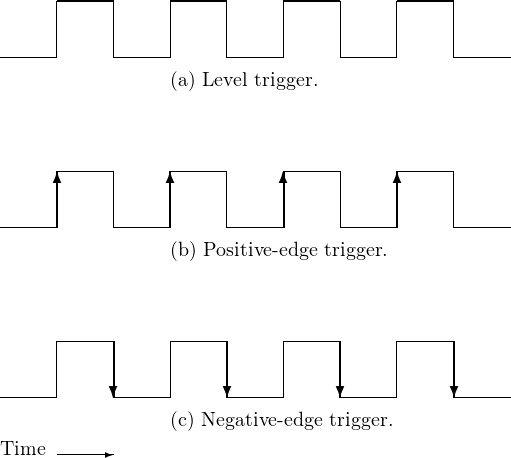
而在 Level-triggered 的工作模式下,只要 file descriptor 處於準備就緒的狀態,`epoll` 就會被觸發,就可能因此造成 client 傳送了一筆資料,但在 server 端會呼叫多次 `read` 讀取內容。
而與 server 設計考量較為符合的是第二種工作模式,因為我們使用 `epoll` 來監聽 file descriptor 狀態的目的在於讓 server 在真正需要讀寫的情況時才呼叫對應的系統呼叫來處理,所以我們關注的是狀態的轉變,只有在 file descriptor 從閒置的狀態轉為準備就緒時才進行操作。
所以在使用 epoll 進行監聽時,我們應該要選擇的工作模式應為 Edge-triggered
## 在解析 http 時使用的狀態機
在 `http_parser.c` 中針對不同的動作對應出不同的狀態,並設計 `struct` 來保存這些狀態:
```cpp
enum {
s_start = 0,
s_method,
s_spaces_before_uri,
s_after_slash_in_uri,
s_http,
s_http_H,
s_http_HT,
s_http_HTT,
s_http_HTTP,
s_first_major_digit,
s_major_digit,
s_first_minor_digit,
s_minor_digit,
s_spaces_after_digit,
s_almost_done
} state;
state = r->state;
```
其實作的目的與我們先前提到的 non-blocking 的讀寫行為有關。
因為在 non-blocking 的行為中,伺服器不會等待到資料寫入結束後才進行其他的處理,且在 server 執行時也可能會遇到連線不穩定或是封包缺失的問題,這就表示 `http_parser` 需要保存當前解析的狀態,以便在中斷解析後可以回復到之前的狀態繼續解析剩下的資料。
## 使用 computed goto 改寫 switch-case
在 [Computed goto for efficient dispatch tables](https://eli.thegreenplace.net/2012/07/12/computed-goto-for-efficient-dispatch-tables) 中有提到:因為 switch 還是會有判斷數值的處理,所以在執行效率上 `goto` 還是會比使用 `switch-case` 來得好,而且使用 `goto` 也可以避免使用 `switch-case` 帶來 branch miss 的損失。
所以我搭配 GNU extension 中提供的 [Labels as Values](https://gcc.gnu.org/onlinedocs/gcc/Labels-as-Values.html),在 `http_parser.c:http_parse_request_line` 中的加入 `conditions` 作為 label address table 讓其可以利用 `state` 來查表,並直接利用 `goto` 跳躍到對應的程式碼。
```cpp
const void *conditions[] = {&&c_start,
&&c_method,
&&c_spaces_before_uri,
&&c_after_slash_in_uri,
&&c_http,
&&c_http_H,
&&c_http_HT,
&&c_http_HTT,
&&c_http_HTTP,
&&c_first_major_digit,
&&c_major_digit,
&&c_first_minor_digit,
&&c_minor_digit,
&&c_spaces_after_digit,
&&c_almost_done};
```
接著將 `switch` 的部分取代為 `goto`
```cpp
goto *conditions[state];
```
接著利用 perf 觀察使用 computed goto 改寫後關於 branch prediction 的表現:
```shell
$ sudo record -e
branch-misses:u,branch-instructions:u ./sehttpd
$ ./htstress -n 100000 -c 1 -t 4 http://localhost:8081/
requests: 100000
good requests: 100000 [100%]
bad requests: 0 [0%]
socker errors: 0 [0%]
seconds: 3.839
requests/sec: 26047.527
$ sudo perf report
Available samples
12K branch-misses:u
14K branch-instructions:u
```
使用 switch-case 的版本:
```shell
$ sudo record -e
branch-misses:u,branch-instructions:u ./sehttpd
$ ./htstress -n 100000 -c 1 -t 4 http://localhost:8081/
requests: 100000
good requests: 100000 [100%]
bad requests: 0 [0%]
socker errors: 0 [0%]
seconds: 4.000
requests/sec: 24997.963
$ sudo perf report
Available samples
13K branch-misses:u
14K branch-instructions:u
```
可以看到 computed goto 版本的伺服器因為在 branch miss 的數量較使用 switch-case 版本少,所以執行的時間得到了改善。
接著因為在宣告 `state` 與 `conditions` 時裡面的名稱有高度的重疊,所以改以 X macro 的方式簡化宣告的程式碼
```cpp
#define state_code(X) \
X(_start), X(_method), X(_spaces_before_uri), X(_after_slash_in_uri), \
X(_http), X(_http_H), X(_http_HT), X(_http_HTT), X(_http_HTTP), \
X(_first_major_digit), X(_major_digit), X(_first_minor_digit), \
X(_minor_digit), X(_spaces_after_digit), X(_almost_done)
#define define_enum(name, code) enum { code(enum_entry) } name
#define enum_entry(entry) s##entry
#define define_label_array(name, code) void *name[] = {code(label_entry)}
#define label_entry(entry) &&c##entry
```
利用 macro 組合 enumerate 的變數與 label 並將 macro 作為變數傳到 `state_code` 這個 macro 中,展開後就會得到與上方宣告一樣的結果
設計 `dispatch()` 的 macro 來進行各種情況的程式碼跳躍。
```cpp
#define dispatch(i) \
do { \
if (i >= r->last) \
interrupt_parse(); \
p = (uint8_t *) &r->buf[pi % MAX_BUF]; \
ch = *p; \
goto *conditions[state]; \
} while (0)
```
因為將 for 迴圈的功能也實作在 `dispatch` 中,所以使用 computed goto 進行 `dispatch` 之前,也要處理字串迭代的更新。
但考慮到在進入 for 迴圈的時候並不會將 `pi` 遞增,所以為了讓進入迴圈前與進入迴圈後 `dispatch` 的行爲與原先 for 迴圈的實作一致,我將 `pi` 作為 macro 參數的參數帶入,讓其可以在兩種不同的情況做不同的處理。
## 引入 timer 的目的
因為在使用 server 的過程中,如果是用戶關閉瀏覽器,結束與伺服器連線時,伺服器可以透過檢查 read 與 write 的回傳判斷用戶是否以結束連線,從而主動關閉連線。
但是在用戶離線時,因為沒有發生讀寫,所以伺服器無法利用系統呼叫的回傳值來判斷,而通訊協定也並沒有針對這樣情況的處理,所以也無從判斷用戶已離線。
因此我們需要使用計時器的方式,在用戶超過一段時間未對伺服器傳送請求時關閉其連線。
在 timer 中使用 proirity queue 的用意在於,因為伺服器需要同時處理多個系統連線的請求,如果在操作的過程中能夠優先挑出即將超時的 request 來處理,就及時關閉超時的 request,並釋放相關的資源,減輕伺服器的負擔。
:::warning
「及時」是 "in time", 「即時」是 "real time",這兩個詞彙語意不同
:notes: jserv
:::
## 修正 seHTTPd 行為
### 以參數更改 port 與 root 位置
為了在執行 seHTTPd 可以具備更多的彈性,讓其可以依據執行時提供的參數更改 port 與 root 的位置,我使用 `<getopt.h>` 提供的 `getopt_long` 來分析輸入的參數。
接著建立使用 `getopt_long` 需要提供的 `optstring` 與 `longopts`。
根據 [getopt_long(3) - Linux manual](http://man7.org/linux/man-pages/man3/getopt_long.3.html) 的說明,進行設定:
```cpp
static const char short_options[] = "p:r:h";
static const struct option long_options[] = {{"port", 1, NULL, 'p'},
{"root", 1, NULL, 'r'},
{"help", 0, NULL, 'h'}};
```
接著在 `mainloop.c` 中使用 do-while 迴圈分析參數,並依據對應的參數進行設定:
```cpp
int next_option;
do {
next_option =
getopt_long(argc, argv, short_options, long_options, NULL);
switch (next_option) {
case 'p':
port = atoi(optarg);
break;
case 'r':
root = strdup(optarg);
break;
case 'h':
print_usage();
break;
case -1:
break;
}
} while (next_option != -1);
```
並建立參數使用的說明訊息
```cpp
static void print_usage()
{
printf(
"Usage: sehttpd [options]\n"
"Options:\n"
" -p, --port port number to be specified\n"
" -r, --root web page root to be specified\n"
" -h, --help display this message\n");
exit(0);
}
```
### 更改 `serve_static` 產生 `header` 的行為
在 `http.c:serve_static` 函式原本的實作中,為了產生 HTTP header,使用如下列的方式來串接字串:
```cpp
sprintf(header, "%sConnection: keep-alive\r\n", header);
sprintf(header, "%sKeep-Alive: timeout=%d\r\n", header, TIMEOUT_DEFAULT);
```
但在 [sprintf(3) - Linux manual](http://man7.org/linux/man-pages/man3/sprintf.3.html) 中有提到:
> Some programs imprudently rely on code such as the following
> `sprintf(buf, "%s some further text", buf);`
> to append text to buf.
> **However, the standards explicitly note that the results are undefined if source and destination buffers overlap** when calling sprintf(), snprintf(), vsprintf(), and vsnprintf(). Depending on the version of gcc(1) used, and the compiler options employed, calls such as the above will not produce the expected results.
所以我改用 `snprintf` 並將 `src` 指標利用 `len` 變數來做位移,避免 overlapping 的問題產生。
```diff
if (out->keep_alive) {
- sprintf(header, "%sConnection: keep-alive\r\n", header);
- sprintf(header, "%sKeep-Alive: timeout=%d\r\n", header,
- TIMEOUT_DEFAULT);
+ len += snprintf(header + len, MAXLINE - len,
+ "Connection: keep-alive\r\n"
+ "Keep-Alive: timeout=%d\r\n",
+ TIMEOUT_DEFAULT);
}
```
除了可以避免 `src` 與 `dst` 重疊的問題之外,因為有提供寫入長度的上限,所以也不會有 overflow 的情況發生。
因為使用 `len` 變數記錄了 `header` 字串的長度,在傳送內容的時候不需要重新呼叫 `strlen` 來計算字串長度,直接傳送 `len` 的數值即可。
## 參考資料
1. [Computed goto for efficient dispatch tables](https://eli.thegreenplace.net/2012/07/12/computed-goto-for-efficient-dispatch-tables)
2. [Labels as Values](https://gcc.gnu.org/onlinedocs/gcc/Labels-as-Values.html)
3. [getopt_long(3) - Linux manual](http://man7.org/linux/man-pages/man3/getopt_long.3.html)
4. [sprintf(3) - Linux manual](http://man7.org/linux/man-pages/man3/sprintf.3.html)